
|
11 |
Data Classification and Handling Policies and Risk Management Policies |
DATA SUSTAINS AN ORGANIZATION’S business processes and enables it to deliver products and services. Stop the flow of data, and for many companies, business comes quickly to a halt. Data drives online ordering, delivery schedules, allocation of resources, production lines, warehouse management, supply chain, and much more. The economy is driven by data. Those who understand its value and have the ability to manage related risks will have a competitive advantage. If the loss of data lasts long enough, the viability of an organization to survive may come into question. Fortunately, most outages and data disruptions are short in duration. But even short outages and data disruptions can be costly. For example, Forbes magazine wrote about a 30-minute outage that Amazon incurred on August 19, 2013. Speculation was that Amazon lost $66,240 per minute during the outage.
Data classification is a useful way to rank the value and importance of groups of data. The importance of the data and the type of value assigned will vary by organization. The value may be monetary, as certain data may be key to driving revenue. The value may be regulatory, as certain data carries legal obligations. The type of data categories (known as classifications) may vary greatly depending on the organization’s need. Data classification creates a standardized way of assigning data (or groups of data) to a classification. These data classifications then drive how data is appropriately handled. These policies and techniques feed into a risk management approach that helps prevent disruption of services.
This chapter discusses data classification techniques used by the government and within the private sector. It discusses ways of classifying data. It also discusses risk management approaches that include quality assurance, quality control, and key measurements.
This chapter covers the following topics and concepts:
• What data classification policies are
• What data handling policies are
• Which business risks are related to information systems
• What a risk and control self-assessment (RCSA) is and why it is important
• What risk assessment policies are
• What quality assurance (QA) and quality control (QC) are
• What best practices for risk management policies are
• What some case studies and examples of risk management policies are
Chapter 11 Goals
When you complete this chapter, you will be able to:
• Explain various data classification approaches
• Explain the difference between classified and unclassified data
• Describe common business classification techniques
• Understand the need for policies that govern data in transit and at rest
• Explain common business risks in a disaster
• Describe quality assurance
• Describe quality control
• Explain the difference between QA and QC
• Describe the relationship between QA/QC and risk management
Data Classification Policies
Data classification in its simplest form is a way to identify the value of data. You achieve this by placing a label on the data. Labeling data enables people to find it quickly and handle it properly. You classify data independently of the form it takes. In other words, data stored in a computer should be classified the same way as data printed on a report.
There is a cost to classifying data. Classifying data takes time and can be a tedious process. This is because there are many data types and uses. It’s important not to overclassify. A data classification approach must clearly and simply represent how you want the data to be handled.
When Is Data Classified or Labeled?
Classifying all data in an organization may be impossible. There has been an explosion in the amount of unstructured data, logs, and other data retained in recent years. Trying to individually inspect and label terabytes of data is expensive, time consuming, and not very productive.
There are different approaches that can employed to reduce this challenge. Here are several approaches used to reduce the time and effort needed to classify data:
• Classify only the most important data, that which represents the highest risk to the organization. Use a default classification for the remaining data.
• Classify data by storage location or point of origin. For example, all data stored in the financial application database could be considered to be for internal use only and thus classified as “confidential.”
• Classify data at time of creation or use; this technique relies on software that “hooks” into existing processes. For example, before an e-mail is sent, a pop-up box requires the e-mail content to be classified.
Regardless of the approach, the reason for classifying the data must determine the way it is secured and handled. The point is not just to classify data. The point is to classify data in order to manage risk.
The Need for Data Classification
You can classify data for different purposes depending on the need of the organization. For example, the military would have a very different classification need than the local grocery market. Both handle data, but handling requirements differ greatly. The more sensitive the data, the more important it is to handle the information properly.
An organization has several needs to classify data. The three most common needs are to:
• Protect information
• Retain information
• Recover information
Protecting Information
The need to protect information is often referred to as the security classification. An organization has to protect data when its disclosure could cause damage. Data classification drives what type of security you should use to protect the information. Data classification also helps define the authentication and authorization methods you should use to ensure the data does not fall into unauthorized hands.
Authentication is the process used to prove the identity of the person. Authorization is the process used to grant permission to the person. Both authentication and authorization control access to systems, applications, network, and data. Authentication makes sure you know who is accessing the data. Authorization makes sure you know the level of access that is permitted; for example, “read” versus “update.” When an individual is said to be an authorized user, it means that he or she received formal approval to access the systems, applications, network, and data.
All organizations have some form of data that requires protection. Any organization that has employees has sensitive personal information, which by law must be protected.
Retaining Information
An organization must determine how long to retain information. It’s not practical to retain data forever. When you purge and delete sensitive data, there’s less of a target for a future breach. Therefore, organizations should retain only data that is needed to conduct business. Data retention policies define the methods of retaining data as well as the duration.
You need to retain data for two major reasons: legal obligation and needs of the business. All organizations have some legal requirements to keep records, such as financial and tax records. Generally such records are retained for seven years in the United States. There are also business reasons to keep records, such as customer information, contracts, and sales records. Table 11-1 depicts a sample retention classification scheme.
There are records which there is no legal or business reason to keep. Many organizations require that such records be deleted at some point. Deleting this information helps the company cut down on storage costs and protects the information from accidental disclosure. The additional benefit of removing unneeded data is the reduction of legal liabilities. There is a general theory that unneeded data creates a liability for a company.
TABLE 11-1 Data classification for retention of information.

The key concept is “what you don’t know can hurt you.” As stated previously, there is an explosion of data across many businesses. Much of this data is unstructured, such as e-mails, call center recordings, other transactions, and even social media postings. Understanding what’s contained in every data file is impossible. This means that an organization may not fully understand the legal obligation or liability associated with handling every data item. In short, the less data retained, the less unknown liability exists.
Storage can be expensive for an organization. A corporate setting can have thousands of employees generating huge volumes of data. Retaining this data takes up valuable resources to back up, recover, monitor, protect, and classify. If you delete unneeded data, these costs are avoided.
![]() NOTE
NOTE
According to a legal memorandum by Ater Wynne LLP, each person in a corporate setting produces about 736 megabytes annually of electronic data. That equates to a stack of books 30 feet tall. Additionally, it’s estimated that e-mail accounts for 80 percent of corporate communications in the United States.
Given the volume of data produced, it is inevitable that sensitive data will show up where it’s not supposed to. A good example is e-mail. A service agent might try to help a customer by e-mail to resolve a payment problem. Despite the agent’s good intentions, the agent might include the customer’s personal financial information in the e-mail. Once that data is in the e-mail system, it’s difficult to remove. The person receiving the e-mail may have designated others to view the mail. Backups of the desktop and mail system will also have copies of the personal information. Wherever that data resides or travels, the information must now be protected and handled appropriately.
As discussed earlier, you can reduce the likelihood of accidental disclosure by routinely deleting data that is no longer needed for legal or business reasons. Classifying what’s important ensures that the right data is deleted. Without retention policies, vital records could be lost. The retention policy can use data classification to help define handling methods.
It’s important to work with management in determining the retention policy. It’s also important to work with legal staff. The legal obligations can change depending on the business context. Assume a service agent with a securities brokerage wrote an e-mail about a customer’s stock trade. This type of e-mail correspondence must be retained by law. The Securities and Exchange Commission (SEC) Rule 17a-4 requires all customer correspondence to be retained for three years. This is to ensure a record is kept in case of an accusation of fraud or misrepresentation. The SEC rule also says the correspondence must be kept in a way that cannot be altered or overwritten. This means the retention policy must specify how the data is to be backed up. An example is a requirement that data should be kept on write-once optical drives. Regulations make data classification even more important in defining proper handling methods.
A retention policy can help protect a company during a lawsuit. The courts have held that no sanction will be applied to organizations operating in good faith. This is true even if they lost the records as a result of routine operations. “Good faith” is demonstrated through a retention policy that demonstrates how data is routinely classified, retained, and deleted.
The need to recover information also drives the need for data classification. In a disaster, information that is mission-critical needs to be recovered quickly. Properly classifying data allows the more critical data to be identified. This data can then be handled with specific recovery requirements in mind. For example, an organization may choose to mirror critical data. This allows for recovery within seconds. In comparison, it can take hours to recover data from a tape backup. Table 11-2 depicts a sample recovery classification scheme.
There are various approaches, sometimes called “classification schemes,” to classifying data. A good rule of thumb is to keep it simple! A dozen classes within each scheme for security, retention, and recovery would be confusing. Employees cannot remember elaborate classification schemes. It’s difficult to train employees on the subtle differences among so many classes. A good rule is to use five or fewer classes. Many organizations use three classifications. Some add a fourth classification to align better to their business model and mission. While a fifth classification is rarer, this may be an indication that an organization has a high enough level of automation and a mature enough risk program to use the additional classification to better manage its data.
In a three-class scheme, the classes represent a lower and upper extreme combined with a practical middle ground. It’s also good to keep the class names short, concise, and memorable. Some classification requirements are influenced by specific legal requirements. In other cases, classification requirements will be driven by what the business is willing to pay for. For example, Table 11-2 indicates a recovery time of less than 30 minutes for critical data. This sample recovery scheme may not be appropriate for all organizations. For example, the scheme might be too expensive for an elementary school to implement. A Wall Street brokerage firm might find 30 minutes inadequate.
TABLE 11-2 Data classification for recovery of information.

A legal classification scheme to label data is driven primarily by legal requirements. Such schemes are often adopted by organizations that have a significant regulatory oversight or have had a significant legal or privacy viewpoint driving the data classification program. Regardless of the reason the organization adopts this approach, it’s important that as legal requirements change, the data classifications change with them. For example, the definition of privacy has changed over the years. If the objective of the classification is to maintain individual privacy as legally defined, as the law changes, so must the classification. Consider an individual’s home address. In some states the address alone is considered private information. In other states a home address is considered private only when combined with an individual’s name. This changing legal landscape can affect how data is classified and handled.
Stanford University offers a good example of a legal classification scheme to label data. The University Privacy Officer is listed as a contact point for questions on the data classification. The Chief Information Security Officer is listed as the key contact point for how the classes of data should be protected. It is a common practice to have privacy and security departments team up to create and manage data classification schemes. Stanford University has adopted the following data classification scheme:
• Prohibited Information—Information is classified as “Prohibited” if law or regulation requires protection of the information.
• Restricted Information—Information is classified as “Restricted” if it would otherwise qualify as “Prohibited,” but it has been determined by the university that prohibiting information storage would significantly reduce faculty/staff/student effectiveness.
• Confidential Information—Information is classified as “Confidential” if it is not considered to be Prohibited or Restricted but is not generally available to the public.
• Unrestricted Information—Information is classified as “Unrestricted” if it is not considered to be Prohibited, Restricted, or Confidential.
You can quickly see how the legal value placed on data determines use of the Prohibited and Restricted classifications. Examples of prohibited information are Social Security numbers, driver’s license numbers, and credit card numbers. Examples of restricted information are health records and passport numbers.
Military Classification Schemes
A security data classification reflects the criticality and sensitivity of the information. “Criticality” refers to how important the information is to achieving the organization’s mission. “Sensitivity” refers to the impact associated with unauthorized disclosure. A specific piece of data can be high on one scale but low on the other. The higher of the two scales typically drives the data classification. As data becomes more important, generally it requires stronger controls. The U.S. military classification scheme is used by a number of federal agencies.
The U.S. military classification scheme is defined in National Security Information document EO 12356. There are three classification levels:
• Top Secret data, the unauthorized disclosure of which would reasonably be expected to cause grave damage to the national security
• Secret data, the unauthorized disclosure of which would reasonably be expected to cause serious damage to the national security
• Confidential data, the unauthorized disclosure of which would reasonably be expected to cause damage to the national security
Any military data that is considered “classified” must use one of these three classification levels. There is also unclassified data that is handled by government agencies. This type of data has two classification levels:
• Sensitive but unclassified is confidential data not subject to release under the Freedom of Information Act
• Unclassified is data available to the public
Sensitive but unclassified is sometimes called “SBU.” It’s also sometimes called “For official use only” (FOUO) in the United States. The term FOUO is used primarily within the U.S. Department of Defense (DoD). Some examples of SBU data are Internal Revenue Service tax returns, Social Security numbers, and law enforcement records.
The Information Security Oversight Office (ISOO) oversees the U.S. government’s classification program. The ISOO produces an annual report to the president summarizing the classification program from the prior year. The report outlines what data has been classified and declassified each year. The 2012 report stated that of all the classified data, 24.8 percent was Top Secret, 61.4 percent was Secret, and 13.7 percent was Confidential.
Declassifying data is very important. It’s not practical to keep data classified forever. First, it’s better to focus limited resources on protecting a smaller amount of the most important data. Second, in democracies, we expect the government to be transparent. Unless there’s a compelling reason to keep a secret, the expectation is the information will be released to the public.
![]() TIP
TIP
Looking at the distribution of classification is a good exercise. By understanding the organization, mission, and nature of data handled, one can draw a general opinion of whether there’s an over- or underclassification of highly sensitive data. Overclassification of the most important data could mean using very expensive means to protect data that is not so important. Underclassification means the most important data may not be adequately protected.
The government routinely declassifies data. Declassification is a term that means to change the classification to “unclassified.” The declassification of data is handled in one of three programs run by the ISOO:

• Automatic declassification automatically removes the classification after 25 years.
• Systematic declassification reviews those records exempted from automatic declassification.
• Mandatory declassification reviews specific records when requested.
These three programs declassified 19.8 million pages of information in 2012, as illustrated in Figure 11-1. As you can see, the government is protecting more and more data. The amount could become overwhelming unless there are policies to reduce the amount of data the government protects.
Business Classification Schemes
The private sector, like the military, uses data classification to reflect the importance of the information. Unlike the government, there is no one data classification scheme. There is no one right approach to classification of data. Also like the military, data classification in business drives security and how the data will be handled.
Although there is no mandatory data classification scheme, there are norms for private industry. The following four classifications are often used:
• Highly sensitive
• Sensitive
• Internal
• Public
Highly sensitive classification refers to data that is mission-critical. You use criticality and sensitivity to determine what data is mission-critical. This classification is also used to protect highly regulated data. This could include Social Security numbers and financial records. If this information is breached, it could represent considerable liability to the organization. Mission-critical data is information vital for the organization to achieve its core business. As such, an unauthorized breach creates substantial risk to the enterprise.
Access to highly sensitive data is limited. Organizations often apply enhanced security and monitoring. Monitoring can include detailed logging of when records are accessed. Additional security controls may be applied, such as encryption.
Sensitive classification refers to data that is important to the business but not vital to its mission. If information is breached, it could represent significant financial loss. However, the breach of the information would not cause critical damage to the organization. This data might include client lists, vendor information, and network diagrams.
Access to sensitive data is restricted and monitored. The monitoring may not be as rigorous as with highly sensitive data.
The key difference between highly sensitive and sensitive is the magnitude of the impact. Unauthorized exposure of highly sensitive data may put the business at risk. Unauthorized exposure of sensitive data may result in substantial financial loss, but the business will survive.
Internal classification refers to data not related to the core business. The data could be routine communications within the organization. The impact of unauthorized access to internal data is a disruption of operations and financial loss.
Access to internal data is restricted to employees. The information is widely available for them, but the data is not released to the public or individuals outside the company.
Public classification refers to data that has no negative impact on the business when released to the public. Access to public data is often achieved by placing the data on a public Web site or through press releases. The number of individuals who are permitted to make data public is limited.
Many laws and regulations require you to know where your data is. These laws require you to protect the data commensurate to the risk to your business. Data classification is an effective way of determining risk. The organization is at greater risk when mission-critical data is breached. By classifying the data, you are able to find it quickly and define proper controls.
Developing a Customized Classification Scheme
You can often create a customized classification scheme by altering an existing one. Federal agencies cannot customize a scheme. This is because their classification schemes are mandated by law. Many security frameworks provide guidance and requirements to develop a classification. Some sources of guidance and requirements include the ISO, Control Objectives for Information and related Technology (COBIT), and Payment Card Industry Data Security Standard (PCI DSS).
Sometimes customizing a classification scheme is minor. This might include modifying the label but not changing the underlying definition. For example, the “highly sensitive” classification could equate to private, restricted, or mission-critical. It’s not the name that matters but the definition. Classification names can vary depending on the organization and the perspective of the creator. “Private” classification in one organization could mean “highly sensitive” in another. In still another it might mean “sensitive.”
When developing a customized data classification scheme, keep to the basics. You should consider the following general guidelines:
1. Determine the number of classification levels.
2. Define each classification level.
3. Name each classification level.
4. Align the classification to specific handling requirements.
5. Define the audit and reporting requirements.
You determine the number of classification levels by looking at how much you want to separate the data. One approach is to separate the data by aligning it to critical business processes. This helps you understand the business to better protect the assets. For example, a power plant may want to isolate its supervisory control and data acquisition (SCADA) systems. SCADA data helps run the facility. Special security and controls may be placed on these systems and data. This can be achieved by classifying the SCADA data differently than other types of data.
The definition of each classification level depends on how you want to express the impact of a breach. Federal agencies determine impact based on confidentiality, integrity, and availability. They assign a rating of low, moderate, or high impact to each of these. By applying a formula they can determine an impact. Organizations outside the government have adopted similar approaches. Table 11-3 depicts the basic impact matrix described in National Institute of Standards and Technology (NIST) Federal Information Processing Standard (FIPS) 199.
The FIPS-199 publication uses phrases such as “limited adverse effect” to denote low impact. For moderate and high impact, it uses “serious adverse effect” and “severe or catastrophic adverse effect.”
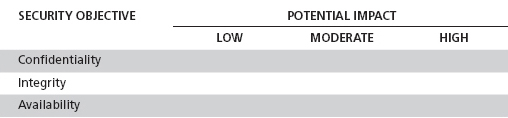
In the business world, impact definitions closely align with measured business results. For example, low risks can be defined as causing “operations disruptions and minimal financial loss.” An organization understands these terms because a financial scale can be used. For example, a low impact may result when $1 to $20,000 is at risk. A moderate impact might be defined as $20,000 to $500,000. A high-impact risk might be defined as $500,000 and above. The exact amounts vary depending on the size of the organization and its risk tolerance. Applying specific dollar amounts to impacts makes the definitions clearer.
The name of each classification level is usually taken from the definition itself. The important point is to select a name that resonates within the organization. You may also consider using a name that peer organizations adopt. This can help facilitate the exchange of approaches within the industry. The name can reflect leadership’s view of risk, such as classifying data as “proprietary” versus “sensitive.”
To align the classification to specific handling requirements is a critical step. Once you determine the classification level, you must apply the appropriate security control requirements. Consider combining the levels where there’s little to no difference in security requirements.
Audit and reporting requirements depend on industry and regulatory requirements. Many organizations are subject to privacy law disclosures. You should consider these reporting requirements when classifying data. For example, sensitive data for audit and reporting requirements can be assigned a special classification. This classification can include additional logging and monitoring capability.
Classifying Your Data
You need to consider two primary issues when classifying data. One issue is data ownership. The other issue is security controls. These two issues help you drive maximum value from the data classification effort.
The business is accountable to ensure data is protected. The business also defines handling requirements. IT is the custodian of the data. It’s up to the business to ensure adequate controls are funded and they meet regulatory requirements. The COBIT framework recommends that a data owner be assigned. The data owner is the person who would be accountable for defining all data handling requirements with the business. The data owner determines the level of protection and how the data is stored and accessed. Ultimately, the data owner must strike a balance between protection and usability. The data owner must consider both the business requirements and regulatory requirements.
The position of the data owner should be senior enough to be accountable. The data owner has a vested interest in making sure the data is accurate and properly secure. The data owner needs to understand the importance and value of the information to the business. He or she also needs to understand the ramifications that inaccurate data or unauthorized access has on the organization.
The data owner guides the IT department in defining controls and handling processes. The IT department designs, builds, and implements these controls. For example, if cardholder data is being collected, the data owner should be aware of PCI DSS standards. The IT department would advise the data owner on the technology requirements. Responsibility stays with the data owner to fund the technology. The duties and responsibilities of the data owner should be outlined in the security controls, or in security policies.
Determining the security controls for each classification level is a core objective of data classification. It would make no sense to identify data as “highly sensitive” or “Top Secret,” and then allow broad access. The data owner and IT department determine what controls are appropriate. The following is a sampling of the security controls to be considered:
• Authentication method
• Encryption
• Monitoring
• Logging
It’s up to the business to ensure adequate controls are funded and they meet regulatory requirements.
It’s important not to treat security controls as a “wish list” of technologies. For example, encryption is not necessary for all data. Encryption can be challenging and expensive. Be sure that all the technologies within the policies have a realistic way of being implemented. Otherwise, the security policies are viewed as unrealistic and may even be ignored. Table 11-4 depicts a simple approach to linking data classifications to security controls.

Data Handling Policies
One of the difficult exercises when defining access requirements is understanding exactly who has a clear need to use the information. It’s important that data handling policies assign responsibility for how the data is to be used. For example, data handling policies should limit what data is allowed to be printed. Another data handling concern is protecting data when it’s moved. The concern is that the data gets used in a way that is no longer protected.
As with data classification, the data owner must strike a balance between protection and usability. The data owner must consider both the business and regulatory requirements.
The Need for Policy Governing Data at Rest and in Transit
A discussion on how best to protect data at rest and in transit inevitably leads to the subject of encryption. There certainly is more to protecting data than just encrypting it. There’s an array of factors that must be considered, such as authentication, authorization, logging, and monitoring. However, the one topic that gets much attention is encryption. That’s due in part to the emergence of state privacy laws. The majority of states today have privacy laws that fall under two types of encryption requirements:
• Laws that require private data to be encrypted
• Laws that require notification of breaches when private data is not encrypted
Both requirements are driving businesses to adopt encryption. There are differences among state laws as to the level of encryption that’s required. For example, the California privacy law requires notification when private information that has not been encrypted is breached. The Massachusetts privacy law requires encryption of data, at rest or in transit, when it leaves the confines of a company’s network. Nevada privacy law mandates the use of PCI DSS, which requires cardholder data to be encrypted both inside and outside the company’s network.
![]() NOTE
NOTE
The term data at rest refers to data that is in storage. This includes data on a server, laptop, CD, DVD, or universal serial bus (USB) thumb drive. Any data that is stored is considered data at rest. The term data in transit refers to data that is traversing the network. That includes data on a private network, the Internet, and wireless networks. If the data is moving over any type of network, the data is in transit.
Regardless of your opinion about whether encryption is a good idea, encryption is a mandate for many organizations. You need to ensure that IT security policies addressing where and how encryption will be used are well defined within those policies.
Security policies need to be clear about when you should use encryption. The policies should also state the level of encryption that is acceptable. Sometimes when people discuss encrypting data within the network, they raise passionate arguments about the value of the protection obtained by encrypting data. Some argue there’s little value because absent stealing the physical hard drive, the data is automatically decrypted. Others argue that it’s another layer of control preventing access because the decryption process is controlled. Both are right. Sometimes the data is automatically decrypted and other times it is not.
Figure 11-2 illustrates both points of view. There are two scenarios presented. In both scenarios, a hacker breaches the environment. In scenario #1, a breach of the application leads to unencrypted data being exposed. In this case, encryption was of no value in protecting the information. In scenario #2, a breach of the operating system leads to a database file being stolen. In this case, the data remained encrypted, which significantly helped prevent the data from being exposed. Encryption of data within the network can offer valuable protection depending on the type of breach. The key factor is whether the encryption key becomes exposed in the process.
Now take a look at how this works in more detail. In scenario #1, a breach of the application allows the hacker to retrieve unencrypted data. The critical point here is that the application and/or database server have access to the encryption key. In this example, the database is decrypting the data. Alternatively, it could be the application that is decrypting the data. Either way, you are in essence asking the application to get the information and decrypt it for you. However, in scenario #2, the hacker has breached the operating system (OS), bypassing the application and database server. In this scenario, the hacker only has access to the file system. In other words, the hacker can retrieve the database files but they remain encrypted. Thus, no data has been breached.
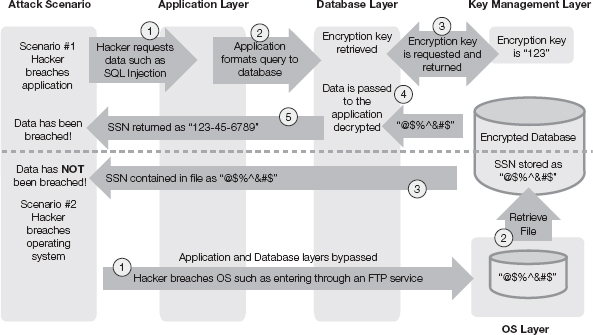
Encrypting data within the network does protect against many attacks but does not protect against a breach of the application. What makes scenario #2 a viable solution is that the key management layer is outside the application and database layer. Without the encryption key the data is unreadable. It would not make sense to encrypt the data on the server and leave the encryption key on the same server. That’s like leaving your car key in the ignition of your car. For encryption to be effective, security policies must establish core requirements and standards, such as:
• Encryption keys must be separated from encrypted data.
• Encryption keys must be retrieved through a secure process.
• Administrator rights at the OS layer do not give access to the database.
What’s generally accepted as best practice is that whenever sensitive data leaves the confines of the organization’s private network, the information should be encrypted. This is not consistently applied within many organizations. For example, suppose an organization encrypts all laptop hard drives. However, the organization may fail to encrypt e-mail, USB, or CD/DVD drives. In this case, it’s common to deploy a patchwork of encryption solutions. Many organizations fail to comply completely with encryption requirements. The use of the term “best practice” in this context recognizes that the level of success among organizations varies. This lack of full compliance to implement encryption is due to:
• Confusion over the new laws
• Cost to comply
• Lack of a standardized approach among vendor products
The IT industry is quickly adapting. New vendor products are beginning to offer encryption solutions. Today the encryption of mobile hard drives and encryption over the Internet are commonplace. For example, it’s common in many organizations to encrypt the hard drive of mobile devices, such as laptops and smartphones. This protects the sensitive information contained inside the device. If the device is lost or stolen, the information cannot be read. Also, encryption over the Internet is commonplace. For example, employees routinely connect to an office through virtual private network (VPN) solutions that encrypt all the traffic between the employees and the private network. Organizations with consumers who buy online routinely encrypt the consumers’ Web site sessions so they can enter their credit information safely.
Beyond mobile devices and traversing the Internet, sensitive information leaves the confines of a private network in other forms. These include backup tapes, CDs, thumb drives, and any other storage media. Encrypting backup tapes protects the data both at rest and as it’s being transported. If a tape is lost or stolen, the information is not breached. This is because the data cannot be decrypted without the key. Encrypting backup tapes is commonplace in industries such as financial services. Also, keep in mind that not all backups are well managed through elaborate data center processes. Many small offices make backups on very portable media such as mini tapes or portable hard drives. These backups also need to be protected. There’s a lack of consensus on best solutions to protect CD/DVD drives, thumb drives, and e-mail.
The IT security policies must state clearly how data is to be protected and handled. An organization can choose to lock out CD/DVDs or USB ports from writing data. An organization can also attempt to encrypt any information written to the drives. Both solutions have complexity, benefits, and drawbacks. It’s the chief information security officer’s (CISO’s) role to bring the organization to a consensus. Some organizations choose to accept the risk. That is becoming harder to do as privacy laws become more stringent.
Policies, Standards, and Procedures Covering the Data Life Cycle
Data has a life cycle like any IT asset. It’s created, accessed, and eventually destroyed. Between these states it changes form. It is transmitted, stored, and physically moved. Security policies, standards, and procedures establish different requirements on the data depending on the life-cycle state. The main objective is to ensure that data is protected in all its forms. It should be protected on all media and during all phases of its life cycle. The protection needs to extend to all processing environments. These environments collectively refer to all applications, systems, and networks.
Policies state that users of information are personally responsible for complying with policies, standards, and procedures. All users are held accountable for the accuracy, integrity, and confidentiality of the information they access. Policies must be clear as to the use and handling of data. For discussion purposes, this section outlines some of the policy considerations for data handling at different points:
• Creation—During creation, data must be classified. That could be simply placing the data within a common storage area. For example, a human resources (HR) system creates information in the HR database. All information in that database can be assigned a common data classification. Security policies then govern data owner, custodians, and accountabilities. Security procedures govern how access is granted to that data.
• Access—Access to data is governed by security policies. These policies provide special guidance on separation of duties (SOD). It’s important that procedures check SOD requirements before granting access. For example, the ability to create and approve a wire transfer of large sums out of a bank typically requires two or more people. The SOD would have one person create the wire and one person approve it. In this case, the procedure to grant authority to approve wires must also include a check to verify that the same person does not have the authority to create a wire. If the person had both authorities, that person could create and approve a large sum of money to himself or herself.
• Use—Use of data includes protecting and labeling information properly after its access. The data must be properly labeled and safeguarded according to its classification. For example, if highly sensitive data is used in a printed report, the report must be labeled “highly sensitive.” Typically, labeling a report “highly sensitive” means there will be data handling issues related to storage.
• Transmission—Data must be transmitted in accordance with policies and standards. The organization may have procedures and processes for transmitting data. All users must follow these procedures. This ensures that the data is adequately protected using approved technology, such as encryption.
• Storage—Storage devices of data must be approved. This means that access to a device must be secured and properly controlled. For example, let’s say mobile devices are encrypted. Once a device is approved and configured, access can be granted through normal procedures. Storage handling also relates to physical documents. “Highly sensitive” documents, for example, need to be locked up when not in use. They should be shared with those individuals authorized to view such material.
• Physical transport—Transport of data must be approved. This ensures that what leaves the confines of the private network is protected and tracked. The organization has an obligation to know where its data is. Also, it needs to know that data is properly protected. When possible, the data should be encrypted during transport. In the event of data media being lost or stolen, the data will then be protected. Many organizations use preapproved transport companies for handling data. These services provide the tracking and notification of arrival needed to meet the companies’ obligations.
• Destruction—Destruction of data is sometimes called “disposal.” When an asset reaches its end of life, it must be destroyed in a controlled procedure. The standards that govern its destruction make sure that the data cannot be reconstructed. This may require physical media to be placed in a disposal bin. These bins are specially designed to allow items to be deposited but not removed. The items are collected and the contents shredded. All users are required to follow procedures that have been approved for the destruction of physical media and electronic data.
IT security policies, standards, and procedures must outline the clear requirements at each stage of the data’s life cycle. The policies must be clear on the responsibilities of the user to follow them. They also need to outline the consequences of noncompliance and purposely bypassing these controls.
Identifying Business Risks Related to Information Systems
Risk management policies establish processes to identify and manage risk to the business. As risks vary depending on the organization, so do the risk policies that must be considered. Common across many organizations are risk policies that consider the value of the data (that is, data classification), types of risks, impact to the business, and effective measurement through quality control and quality assurance.
No matter the size of your organization, understanding data is vital to its success. It’s a simple fact that good decisions are more likely to come from good data. Data classification lets you understand how data relates to the business. Data classification drives how data is handled and thus is the foundation required for data quality. A well-defined data classification approach helps achieve good data quality. This is because data classification enables you to stratify data by usage and type. Understanding your data allows you to reduce risks and minimize costs.
Types of Risk
Much IT risk is operational risk. Operational risk is a broad category. It includes any event that disrupts the activities the organization undertakes daily. In technology terms, it’s an interruption of the technology that affects the business process. It could be a coding error, a network slowdown, a system outage, or a security breach. Data classification helps focus resources on those assets needed to recover the business. For example, data classification identifies what data is critical to resuming minimal operations. Figure 11-3 illustrates that point, with Tier 1 representing mission-critical applications. With mission-critical applications, data should be mirrored so it can be recovered quickly.
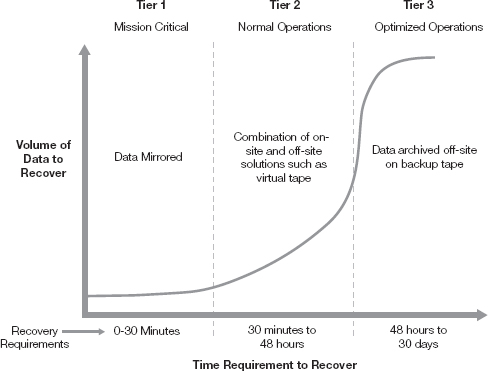
Notice the transition between Tier 1 and Tier 2. This is represented by the dotted line cutting across the curved line. In this case, only a small percentage of data needs to be recovered for minimum operations. Conversely, for optimized operations, a significant amount of data needs to be recovered. This is represented by the path of the curved line in Tier 3. However, this large amount of data is not as vital in the short term. Data classification allows you to stratify this data so the mission-critical data can be found quickly and recovered.
Physical, environmental, and technical hazards can disrupt IT operations. A physical hazard can be any physical threat, such as a fire within the data center. An environmental hazard can be an environmental event, such as a storm or earthquake. A technical hazard is a general category that covers other types of hazards. Data classification helps plan for many hazards. Such hazards might necessitate selecting a mirroring solution that copies mission-critical data across two data centers in two different locations.
Financial risk is the potential impact when the business fails to meet its financial obligations. Financial risk is often driven by a lack of adequate liquidity and credit for the business to meet its obligations. Financial decisions depend on financial data being accurate and available. Data classification builds processes that ensure the integrity of the information. When data is properly classified, you can identify financial information clearly. In addition, you can apply appropriate protection and handling methods.
Strategic risks may change how the organization operates. Some examples are mergers and acquisitions, a change in the industry, or a change in the customer. Understanding the sensitivity and criticality of your data brings you closer to understanding your customer and products. Stratifying your data through classification helps you understand what your core business truly is and what it is not.
The key take-away is recognizing that the process of data classification is more than a label or tag. It’s a review of how data drives your business. The benefit of data classification is identification of critical information assets and properly protecting those assets. The residual benefit is that you will understand your business and customers better.
Development and Need for Policies Based on Risk Management
Establishing a new risk-based management approach can be a daunting challenge. The objective of a risk-based approach is to focus on the greatest threats to an organization. IT security policies that are risk-based will focus on the greatest threats to business processes and promote a risk-aware culture. Policies, processes, and controls have more value when they reduce real business risk.
Compliance is more than adhering to laws and regulations. Regulators also want an organization to demonstrate that it can systematically identify and reduce risk. Policies based on risk management principles can achieve this. Security policies steer the organization within regulatory boundaries. Policies also need to reflect the organization’s risk culture, tolerance, appetite, and values. For example, the Health Insurance Portability and Accountability Act (HIPAA) requires a risk management and analysis approach. This promotes a thorough understanding of the risks. This understanding leads to the selection of appropriate safeguards. These safeguards are based on the level of risks faced by the organization.
Developing tools to make mathematical calculations of these factors provides a means of assessing the risk in an objective fashion. Table 11-4 is a simple example of this approach. Tools can inform the organization’s leadership of trends and emerging risks. But in the end they are only tools. There is no substitute for common sense. As much as they enlighten us, they can also cloud our judgment when they are followed blindly. An experienced leader knows to dig deeper when a model is saying something that doesn’t make sense.

The use of security policies based on sound risk management will help to educate the organization on tradeoffs that are implicit in the risk-reduction decisions. The following are some benefits of a risk management approach to security policies. Such an approach:
• Identifies possible costs and benefits of decisions
• Considers actions that may not be apparent to the leaders and forces alternative thought
• Provides analytic rigor to ensure an objective consideration of risk
Risk management that is rigorous and well executed helps leaders make choices that reduce risk over the long term. This is critically important. Reducing risks is not a one-time activity. Risk management is a continuous dialogue. As time passes, other pressing needs compete for resources, and support for the risk reduction effort wavers. An effective risk management system explains the risks in the context of the business. It justifies its priority and funding.
Risk management is a process of governance. It’s also a continuous improvement model. Figure 11-4 depicts a simple continuous improvement model for risk management. The following steps are cycled through each time a new risk is discovered:
1. Prioritize the risk; align the risk to strategic objectives.
2. Identify an appropriate risk response; sometimes this may require adjusting policies.
3. Monitor the effectiveness of the response and gauge the reduction in risk.
4. Identify residual and new risks whereby the cause of the risk is determined.
5. Assess risk to measure the impact to the organization.
This risk management continuous improvement model can be used to start a risk management program. In a startup you would begin by prioritizing all known risks. This means aligning the risks to strategic objectives. This process may cause a change in the risk management programs or policies themselves. This is vital to ensure the program drives value into the business.
Controlling risk to the business extends beyond daily operations. It is important that you understand risks that can affect how to recover and sustain your business.
Risk and Control Self-Assessment
A risk and control self-assessment (RCSA) is an effective tool in the risk management arsenal. It allows the organization to understand its risks and their potential effects on the business. It’s a formal exercise many organizations conduct annually.
An RCSA can be a time-consuming exercise requiring engagement from the business’s senior leadership and technology teams. However, the benefits are enormous. By the end of the day a common view emerges on the challenges and risks that face an organization, including:
• What the major known risks are
• Which of these risks will limit the ability of the organization to complete its mission
• What plans are in place to deal with these risks
• Who “owns” the management and monitoring of these risks
The RCSA process is often not well understood or leveraged. It contains the business leaders’ view of their risks. Consequently, they are an ideal source of information to support your risk management program. If you demonstrate how managing risks to data reduces the risks identified in the RCSA, you will get the attention of management and increased opportunity to win their support.
The RCSA contains detailed risk information that shows the impact on an organization in the event that key processes and technology are not available. You use the RCSA to develop risk management plans, such as where to place quality assurance and quality control routines. The RCSA also contains multiple scenarios. Each scenario details the risks and effects on the business. The main intent of an RCSA is to ensure that these risks are identified and assigned to an individual executive to manage.
The RCSA approach is not a standard used across all industries. While any organization can use the RCSA, and many use some form of it under a different name, it’s only one of many approaches used to manage risk. Which approach to use is less important than having a systematic approach to managing risk in the first place. That said, the RCSA can provide an organization with a new opportunity to identify and plan for unexpected or emerging risks. These may include new operational risks resulting from shifts in the regulatory or market environment. Additionally, this approach can be used as a means to align thinking about risk and awareness of it across the enterprise.
Risk Assessment Policies
A risk assessment is one of the most important activities that an organization performs. A risk assessment defines threats and vulnerabilities and determines control recommendations. It allows the organization to make informed decisions to invest in risk reduction. Risk-based decisions are the basis of most IT security policies.
Risk Exposure
A risk exposure is the impact to the organization when an event occurs. There are several ways to calculate risk exposure. Ideally, you want to quantify it within business terms, such as putting a dollar value on the losses. A generally accepted formula can be used to calculate exposure, as follows:
Risk exposure = Likelihood the event will occur × Impact if the event occurs
For example, if there’s a 50-percent chance that a $2 million loss may occur, the risk exposure would be $1 million (.5 × $2 million = $1 million). This calculation, plus other assessments, can lead to understanding the total risk exposure of a business unit.
You can use different analytical methods to determine likelihood and impact. These methods fall into two types: quantitative and qualitative. Quantitative methods involve using numerical measurements to determine risks. Measurements may include a range of measurements, such as asset value and frequency of the threat. A shortcoming of quantitative methods is a lack of reliable data. This can be overcome by reaching a consensus on the use of industry benchmarks.
Qualitative analysis involves professional judgment. This means making a well-educated guess, so to speak. Qualitative techniques may include questionnaires, interviews, and working groups. Qualitative analysis can be used to adjust measurement created through quantitative methods.
These are very powerful tools that allow you to have an engaged conversation on risk with the business. When presented with the risk exposure, the business can accept the risk or fund its mitigation. It’s important that you discuss with the business any assumptions made in determining the likelihood or impact. This serves two purposes. It validates your assumption. It also builds credibility for the analysis. This avoids the situation where the analysis is discarded as unrealistic.
Prioritization of Risk, Threat, and Vulnerabilities
When you combine the risk exposure and BIA you can see the direct impact on the business. This view of risk allows you to prioritize the risks. A risk management program creates a balance. The balance is between reducing the most likely events and mitigating risks with the greatest impact. Controls addressing one risk can impact other risks.
Security policies and controls can reduce reputational, operational, legal, and strategic risk. This is accomplished by limiting vulnerabilities and reducing breaches, which builds consumer confidence.
Risk Management Strategies
Once you identify a risk you choose a strategy for managing it. There are four generally accepted risk management strategies, as follows:
• Risk avoidance—Not engaging in certain activities that can incur risk
• Risk acceptance—Accepting the risk involved in certain activities and addressing any consequences that result
• Risk transference—Sharing the risk with an outside party
• Risk mitigation—Reducing or eliminating the risk by applying controls
Risk avoidance is primarily a business decision. You need to look at the risks and benefits to determine how important they are to the viability of the business. Government organizations may not have that option. A local police department, for example, cannot choose to stop policing because of the potential risks. An example of risk avoidance would be if a company moves its data center from Florida to Iowa to avoid the risk of hurricanes.
Risk acceptance is either a business or technology decision. The business needs to know about risks that impact its operations. If the business does not think it is feasible or cost-effective to manage the risk in other ways, it must choose to accept the risk. There are a host of daily technology risks that are accepted by the IT department. Hopefully, these risks have a low probability of impacting the business. From a practical standpoint, not all risks can be formally accepted by the business. The key is to have a process by which risks are assessed and rated. This rating can be used to determine who has the authority to accept each risk.
Risk transference is taking the consequences of a risk and moving the responsibility to someone else. The most common type of risk transference is the purchase of insurance. For example, you might purchase data breach insurance that would pay your expenses in the event of a data breach. Transferring a risk does not reduce the likelihood that a risk will occur. It removes the financial consequences of that risk.
There is no one list of mitigation strategies. The mitigation strategy depends on the risks, threats, and vulnerabilities facing the organization. A grocery market protecting customer credit cards has a different set of threats than a nuclear power plant. Their mitigation strategies will also differ.
However, all mitigation strategies have a common objective. This objective is prevention. The prevention of risks is less costly than dealing with their aftermath. To be effective, you must have a process in place to identify risks before they threaten the business. Risk management policies promote a series of efforts that allow an organization to be always self-aware of risks. The following is a sampling of those efforts:
• Threat and vulnerability assessments
• Penetration testing
• Monitoring of systems, applications, and networks
• Monitoring of vendor alerts on vulnerabilities
• Active patch management
• Effective vendor management and oversight
• Aggressive risk and security awareness
These methods reduce risk. They also provide a source of new information about the environment. This information can be used to design better solutions and understand limits of the existing environment. You can measure the impact of these effects in reduced risk to data integrity, confidentiality, and availability.
Vulnerability Assessments
Vulnerability assessments are a set of tools used to identify and understand risks to a system, application, or network device. “Vulnerabilities” is a term that identifies weaknesses in the IT infrastructure, or control gaps. If these weaknesses or control gaps are exploited, it could result in an unauthorized access to data.
There are a number of tools and techniques to perform vulnerability assessments. Here are a few examples:
• A penetration test on a firewall
• A scan of the source code of an application
• A scan of an operating system’s open ports
It’s important to understand that these are tools, not assessments. They are valuable tools identifying potential weaknesses. However, the assessment comes from the analysis of the results. The assessment must address the vulnerability. It must also address the impact to the business and cost of remediation.
Security policies define when and how to perform a vulnerability assessment. The following are typical steps to be followed:
1. Scope the assessment.
2. Identify dependencies.
3. Perform automated testing.
4. Analyze and generate reports.
5. Assign a rating.
You need to scope the assessment and understand the environment prior to any assessment work. This work involves both technical and business aspects. You need to understand what business processes are being used on the internal networks, plus what processes are being used externally through the firewall. Based on this information you can assess the security policies, standards, and procedures. This should provide a comprehensive baseline to compare the assessment results again.
A comprehensive vulnerability assessment looks at the processes end-to-end. This is more effective than just looking at processes on an isolated component. For example, assume your organization has a network of car dealerships across the state. Also assume there is a VPN network available to cross-check inventory and delivery of new cars. You conduct a vulnerability assessment. The assessment finds a control weakness that could prevent a car dealership from receiving new cars. That is a much more meaningful conclusion than, “XYZ server has open ports.”
Next, you identify dependent processes and technology that support each primary process. For example, remote access from home may be dependent on the security token. A security token is either a hardware device or software code that generates a “token” at logon. A token is usually represented as a series of numbers. A security token is extremely difficult and some say impossible to replicate. When assigned to an individual as part a required logon, the token provides assurance as to who is accessing the network. The home environment and the security token each create a potential vulnerability. The home and token both need to be discussed beyond the firewall.
It is important to understand how information is used. For example, the assessment should address employee access, use, and dissemination of information. Network and application diagrams are good sources of information.
The use of automated testing tools is best practice. They can scan a large volume of vulnerabilities within seconds. The key take-away is that the results must be examined and put into the context of the process and risk.
Automated testing tools call for you to rank threats in order of greatest risk. Classifying risks allows the organization to apply consistent protection across its asset base.
During analysis and reporting, you bring the data together and determine the business impact. Using the BIA results helps align risks to the business. For example, if the assessment includes a process that the business has already declared mission-critical, then the assessment can reflect that fact. This approach helps you assess vulnerabilities that deserve priority attention.
With the vulnerability analysis completed, it’s time to assign a rating. A vulnerability assessment rating describes the vulnerability in relation to its potential impact on the organization. The rating typically follows the same path as any risk rating adopted with other risk teams. You typically calculate the exposure, as discussed earlier in the section entitled “Risk Exposure.” Based on the risk exposure you assign a value. Then, using a scale, you can assign a rating such as low, moderate, or high, as discussed in Table 11-4.
You do not have to apply a report rating. You could rate the report based on risk exposure. More organizations tend to use the low, moderate, and high ratings. The feeling is that these ratings can more accurately reflect risk by applying professional judgment.
Vulnerability Windows
Vulnerabilities are weaknesses in a system that could result in unauthorized access to data. All software has some vulnerability. The goal is to produce code with the lowest number of vulnerabilities possible. That means designing code well and reducing defect rates. Equally important is closing vulnerabilities quickly once they are discovered. For commercial software, closing vulnerabilities often comes in the form of the vendor issuing a patch or an update release.
At some point vulnerabilities become known. This is called zero day. From that point to the point where a security fix can be distributed is the vulnerability window. For example, assume a new virus is found on a desktop. Your virus scanner and other preventative measures did not detect and prevent the virus. You discovered this vulnerability on March 1. You notified the vendor of the vulnerability on March 2. The vendor issued a new signature file to detect and prevent the virus on March 15. On the same day, you upgraded all the virus scanners with the new signature file. In this example you have a vulnerability window from March 1 to March 15. The zero day is March 1, which is the day the vulnerability became known.
Vulnerability can last for years when the distributed fix does not fix the root cause. When a vulnerability is exposed through a specific type of attack, you create a security fix. Later, however, you may discover that a different type of attack exploited the same vulnerability. It turns out that the original fix did not address the root cause of the vulnerability. The security fix of the first attack only cut off the original avenue of attack. This avenue of attack is also known as an “attack vector.” The fix did not resolve the root cause of the vulnerability.
Reducing the vulnerability window is important for an organization. It reduces the possibility of unauthorized data access and disclosure of information. That means working quickly with vendors and in-house development teams to identify fixes.
Patch Management
The objective of a patch management program is to quickly secure against known vulnerabilities. Patches are produced by the vendors of systems, applications, and network devices. The objective to patch quickly seems straightforward. However, implementing patches can be challenging. For a large organization with a diverse set of technologies, there may be a continual flood of vendor patches. The dilemma is that failing to apply the patch leaves a security vulnerability that a hacker can exploit. Applying every patch that comes your way may lead to incompatibilities and outages.
Security policies outline the requirements for patch management. These includes defining how patches should be implemented. The security policies also define how the patches should be tracked.
The key to success in patch management is to have a consistent approach to applying patches. This approach includes:
• Vetting
• Prioritization
• Implementation
• Post-implementation assessment
Vetting the patch is important to understanding the impact to your environment. Not all patches will apply to your environment. You must determine what security issues and software updates are relevant. An organization needs a point person or team responsible for tracking a patch from receipt to implementation. An asset management system helps inventory all system, applications, and network devices. This is used to track what assets have been patched.
Each patch needs to be tested to ensure its authenticity. It also needs to be checked as to whether it is compatible with the organization’s applications. Regardless of how well you tested the patch, systems may encounter an incompatibility. When that occurs, you will need to work with the vendor to resolve the issue. You could also find an alternative way to mitigate the vulnerability.
You need to determine the priority of the patch before you implement it. Security policies should provide guidance on how long any security vulnerability can go without being mitigated. The patch team should have clear guidance about how quickly critical patches must be applied. Critical patches are those that mitigate a risk that is actively spreading within the company. Generally, critical patches are applied within hours or days.
![]() NOTE
NOTE
The implementation should include a back-out plan, in the event the patch creates major problems. It’s not unusual to test patches on small populations of users before it becomes more widely distributed.
Once you assess the priority, you can schedule the patch. You typically schedule patches monthly or quarterly. You make all patches viewable, such as on a Microsoft SharePoint site, by key stakeholders. These stakeholders could be systems, application, and network administrators. This gives them the ability to review and comment on patch deployment. Security policies should identify the notification period before patches are applied.
At this stage the patch process is most visible to the organization. You need to assess the security of the patch management application itself periodically. By its nature, the patch management application needs elevated rights. The patch may need to be applied to every system, application, and network device. A breach of the patch management application can be devastating to an organization.
These patch management tools also provide a vital task of discovery. These tools can examine any device on the network and determine its patch level. Some of these tools are used for dual purposes, such as patch and asset management.
Perform a post-implementation assessment to ensure that the patch is working as designed. Patches can have unintended consequences. Problems with patches need to be tracked and the patch backed out, if necessary.
Quality Assurance Versus Quality Control
One method of measuring the effective of risk management is through quality assurance (QA) and quality control (QC) functions. These functions both measure defects, but in different ways. The idea is simple: If you are managing risks well, you should see fewer problems and fewer defects.
Given the number of definitions used in the industry to describe QA and QC, the differences can be confusing. The American Society for Quality (ASQ), a global association, defines these terms as follow:
• Quality assurance—The act of giving confidence, the state of being certain, or the act of making certain
• Quality control—An evaluation to indicate needed corrective responses; the act of guiding a process in which variability is attributable to a constant system of chance causes
Other standards such as COBIT adopt similar definitions. While the wording differs, the underlining core meaning is the same. The QA function “makes certain.” That is achieved at time of the transaction for process execution. Implied is that each transaction or process at a certain stage is validated to create that assurance. In contrast, the QC function “evaluates” the “responses” over time. Implied is that each transaction or process has already been executed.
In short, typically QA is a real-time preventive control. If a transaction or process fails a QA test, the defect is immediately caught. At that point, the defect can be corrected or rejected. In contrast, a QC function typically looks at defects over time and over a broader group of samples, as a detective control. In this way the QC process can capture lessons learned and improve the QA process.
As an example, consider an auto factory. The QA process tests various parts after they are installed, such as by turning on the radio to make sure it works. This will catch improper wiring of the radio. In contrast, the QC process looks at all the dealership reports of radio repairs and tests why the QA process failed to catch the defect. Assume most of the need for radio repairs results from a wire that comes loose over time. The QC process could note that additional testing of the wire connection is required in addition to turning on the radio.
Best Practices for Data Classification and Risk Management Policies
Risk management policies provide the framework for assessing risk across data classification and RCSA activities. The resulting risk assessment looks at how risk is managed end to end. This means that the risk assessment can examine how data classification affects data handling and the RCSA process. It can also identify control gaps between the quality assurance and quality control processes. Risk management policies identify the criteria and content of assessments. Risk management requirements may vary by industry and regulatory standards. When creating a data classification scheme, you must keep the following in mind:
• Keep the classification simple—no more than three to five data classes.
• Ensure that data classes are easily understood by employees.
• Data classification must highlight which data is most valuable to the organization.
• Classify data in the most effective manner that classifies the highest-risk data first.
The take-away is that there is no one common approach to defining risk and controls within an organization. Many of the same elements are there but repackaged in a different form. Regardless of what the plan is called, it’s important that the risk management policies promote a thorough understanding of the business. They should include a definition of its risks and the ability to ensure data is properly handled.
Case Studies and Examples of Data Classification and Risk Management Policies
The following case studies and examples examine the implementation of several risk-management-related policies. The case studies focus on the risks and policies outlined in this chapter. Risk management policies represent a broad category of risks. These case studies and examples focus on a single policy group, such as disaster recovery, and represent successful implementations.
Private Sector Case Study
On December 27, 2006, Microsoft learned of a vulnerability in the Windows operating system. It was a Windows Meta File (WMF) vulnerability that allowed code to be executed on an infected machine without the machine user’s knowledge. Microsoft immediately started working on a patch. Microsoft had planned to release the patch in January as part of its regular monthly security updates. After receiving feedback from the security community, the company released the patch on January 5, 2007. This was 10 days after the vulnerability was discovered.
That 10-day period is an example of a vulnerability window. It was the time in which no vendor solution was available to mitigate the risk.
This is an example of patch management policy working. It is a fair assumption that individuals responsible for patch management at organizations were monitoring events. Once the vulnerability was known, they reached out to their vendor, Microsoft. The monitoring of such an emerging industry threat would be part of a well-defined patch management policy.
Public Sector Case Study
The University of Texas posted a data classification standard on its Web site. The standard classified data as Category I, II, and III. Category I was defined as data that is protected by law or university regulations. Some of the examples cited were HIPAA, the Sarbanes-Oxley (SOX) Act, and the Gramm-Leach-Bliley Act (GLBA). Category II was defined as other data needing to be protected. Examples cited were e-mail, date of birth, and salary. Category III was defined as data having no requirements for confidentiality, integrity, and availability. These three requirements defined the categories to which the university’s data was assigned. The university cited security policies as the authority for the standard.
This is an example of a customized data classification scheme. The university tailored the scheme based on a review of critical data. The university determined that three classification levels were sufficient to meet regulatory requirements. In this case, the university called the data classification a standard. It could as easily have been labeled a policy. In either case, it clearly defined classification levels. It defined roles and responsibilities. It also defined scenarios, such as handling data on a professor’s blog. It was a good example of how data assessment and regulatory compliance can come together to create a data classification standard.
Private Sector Case Study
On January 24, 2014, Coca-Cola reported that personal information of up to 74,000 former and current employees had been exposed. The data was on laptops stolen from company headquarters in Atlanta. The company stated it had a policy requiring laptops to be encrypted. However, these laptops were in use without that control in place. The exposed information included employee names, Social Security numbers, driver’s license numbers, and other personal information used by the company’s human resources (HR) department.
Even if the details of the policy and the breach are unclear, this case does demonstrate multiple breakdowns in at least the following areas:
• Quality assurance (QA)
• Quality control (QC)
• Data classification
First, consider the QA aspect. How is possible that laptops were built and issued without complying with the company standards? Most standards require laptops to be built to specific requirements. In this case the policy was clear: Laptops were required to be encrypted. Yet that QA validation appears not to have occurred to ensure these laptops were encrypted before use.
Second, consider the QC aspect. A comprehensive QC program should have rated the potential for unencrypted laptops as a high risk. If so, testing the QA program by sampling laptops might have caught this defect in the laptop build process.
Third, consider data classification. Employee HR data is generally considered highly sensitive. It’s not clear exactly what data classification policy was in place. Assume, though, that the right data classification was in place, requiring such sensitive data to be encrypted. If that was the case, while it’s not a policy issue, it is a policy classification issue. Consequently, this would be a data classification handling violation. Ideally, controls enforcing the policy should prevent such data from being loaded to laptops or any portable media. Highly sensitive data usually must remain in a secure location. If that’s the case, having such data on the laptop is a violation of policy and improper handling of data according to its classification.
![]() CHAPTER SUMMARY
CHAPTER SUMMARY
You learned in this chapter how you can use data classification to identify critical data and protect it. The chapter reviewed military and business classification schemes. The chapter examined how these schemes apply to data handling policies. It examined the need to have policies govern data at rest and in transit. The chapter also discussed how data classification helps reduce business risks.
The chapter included discussion of risk management. It discussed how the risk control and self-assessment process (RCSA) can be leveraged to help gain support from executive management. The chapter also explored the differences between quality assurance and quality control. Also, you read in this chapter about how to use QA and QC techniques to measure the effectiveness of risk management policies.
Authorization
Automatic declassification
Confidential
Declassification
Highly sensitive classification
Internal classification
Mandatory declassification
Public classification
Risk and control self-assessment (RCSA)
Secret Security token
Sensitive but unclassified
Sensitive classification
Systematic declassification
Top Secret
Unclassified
![]() CHAPTER 11 ASSESSMENT
CHAPTER 11 ASSESSMENT
1. Which of the following is not a common need for most organizations to classify data?
A. Protect information
B. Retain information
C. Sell information
D. Recover information
2. Authorization is the process used to prove the identity of the person accessing systems, applications, and data.
A. True
B. False
3. You need to retain data for what major reasons?
A. Legal obligation
B. Needs of the business
C. For recovery
D. A and B
E. All of the above
4. What qualities should the data owner possess?
A. Is in a senior position within the business
B. Understands the data operations of the business
C. Understands the importance and value of the information to the business
D. Understand the ramifications of inaccurate data or unauthorized access
E. All of the above
5. In all businesses you will always have data that needs to be protected.
A. True
B. False
6. Risk exposure is best-guess professional judgment using a qualitative technique.
A. True
B. False
7. The lowest federal government data classification rating for classified material is ________.
8. Federal agencies can customize their own data classification scheme.
A. True
B. False
9. What is a process to understand business leaders’ perspective of risk called?
A. QA
B. QC
C. RCSA
10. Quality assurance is typically a detective control.
A. True
B. False
11. Generally, having five to 10 data classifications works best to cover all the possible data needs of an organization
A. True
B. False
12. Risk exposure can be expressed in the following manner: ________ = ________ × ________.
13. Data in transit is what type of data?
A. Data backup tapes being moved to a recovery facility
B. Data on your USB drive
C. Data traversing a network
D. Data being stored for later transmission
14. Encryption protects data at rest from all type of breaches.
A. True
B. False