
Chapter 25. Scriptable Load Balancers
When scalability problems occur, there’s no time to go back and rearchitect or refactor an entire web service. Inevitably the service you’re responsible for will go down as a result of being overloaded. Sometimes, you’re hoping for a miracle in the form of an easily fixable, bad database query. Or maybe you’re able to simply scale up the number of workers. But what about when you don’t have the time, money, or people needed for solving the problem at hand? Luckily, there’s a new suite of tools that are making a name for themselves in small corners of our industry that can forever change the way we approach scalability and our roles as SREs: scriptable load balancers.
Scriptable load balancers are proxies that can have their request/response processing flow modified through a scripting language such as Lua. This opens new ways for infrastructure teams to shard applications, mitigate Distributed Denial of Service (DDoS) attacks, and handle high load. Small teams can now solve difficult or seemingly impossible problems in novel and elegant ways. The ability to add high-performance, custom logic to a load balancing tier isn’t new; however, the ability to do that at an organization of any size is. And that’s why scriptable load balancers could be game changing.
Scriptable Load Balancers: The New Kid on the Block
Look at almost any web service, and often you’ll find a load balancer being the first thing a request hits, as Figure 25-1 depicts.1 These servers act as proxies, receiving requests (HTTP or otherwise) and forwarding them to a specified pool of upstream servers. They have become ubiquitous for their value in improving resiliency and performance. Today, they’re often used for not much more than Secure Sockets Layer (SSL) offloading, simple caching, and distributing load across multiple upstreams.

Figure 25-1. Architecture of a typical web application with a user request hitting a load balancer before being routed to an application server.
Load balancers are highly capable, specialized components in our architecture. Their ability to process requests quickly and serve orders of magnitude more traffic than their upstreams is a powerful trait. Unfortunately, any attempt at adding complex application logic is quickly shut down by the restrictive configuration languages shipped with load balancers. There are application-aware load balancers (e.g., Facebook’s Proxygen2) that are able to peer into the content of a request (e.g., read headers) and act on it, but you need to custom-build these. The goliaths of the industry (Facebook, Google, etc.) recognize the value that application-aware load balancers can bring and have taken to writing their own. For the rest of the industry that can’t spare a team of people, we’re left without them entirely.
A few companies in the industry have begun to realize that there doesn’t need to be this dichotomy between traditional load balancers or application-aware, custom-built load balancers that take a team to support. This middle ground can be filled by scriptable load balancers. With scriptable load balancers you can modify the request/response processing flow (e.g., by modifying outgoing headers) through a scripting language such as Lua. You can write extensions in a high-level language to add application-aware functionality on top of the load balancer’s existing features.
The market for scriptable load balancers is still young. There are currently two main scriptable load balancer projects: OpenResty and nginScript. OpenResty is an Nginx C module with an embedded LuaJIT, created by Yichun “agentzh” Zhang. A steady community3 has grown around it, producing multiple libraries/modules; it’s been adopted by companies such as Cloudflare, Tumblr, and Shopify. Of the two, OpenResty has the largest community and powers upward of 10% of internet traffic.4 Closely following is nginScript, Nginx Inc.’s implementation of a JavaScript scripting engine in Nginx.
Why Scriptable Load Balancers?
Scriptable load balancers have numerous advantages over custom-built and conventional load balancers.
For starters, only a select number of organizations can spare the time and people necessary to build their own production-ready load balancer. More practically, few engineers have experience building a load balancer from scratch. Rather than spending time improving resiliency or performance, engineers will spend their time reinventing the wheel, building routing and request processing engines.
At the end of the day, the custom logic you add to the edge only makes up a fraction of what load balancers can do. Rebuilding that functionality is in no one’s best interest. Especially, when current capabilities are a moving target with constant improvements from the open source community.
Traditional load balancers don’t offer the same capabilities as scriptable load balancers. One drawback is that traditional load balancers ship with declarative configuration languages that make it difficult to express application logic. Sometimes, it’s even impossible to specify the desired behavior. Additionally, logic expressed through configuration is difficult to fully validate for correctness with tests. To compensate, many load balancers ship with a C-based plug-in system that allows developers to augment existing functionality through modules. These plug-in systems address many concerns, but they come with substantial, unnecessary downsides when compared to using an embedded scripting language. Without built-in memory safety, C is prone to memory faults (e.g., buffer overflow and segmentation faults), making it inherently unsafe. In contrast, a scripting language, such as Lua, can be sandboxed with strict runtime and memory guarantees. When writing a C module, developers can’t ignore lower-level details that aren’t immediately relevant to the logic at hand, a problem scripting languages don’t have.
Making the Difficult Easy
Load balancers act as gatekeepers to services, with every request passing through them. Their position in our web architecture enables powerful abstractions. This allows for solutions that aren’t typically available to SREs or infrastructure developers. For example, the ability to pause requests during deploys to avoid returning errors to customers or proxying requests to the correct data center is powerful for an SRE team, but difficult to achieve with existing frameworks and applications. Typical web frameworks such as Rails or Django are designed for serving traditional CRUD/REST requests. Although they can perform nontraditional operations, it comes at the cost of resiliency. The rest of this section will show how you can use scriptable load balancers to solve common infrastructure problems to great effect.
Shard-Aware Routing
When applications grow sufficiently large, their data becomes too big to be stored on a single node. The solution is to break the data into manageable chunks, referred to as shards, and spread it out among multiple nodes and/or databases. Sometimes, this is done internally by the database, and all that’s required to scale is adding more nodes to the database cluster. For the majority of applications, the data has to be logically partitioned depending on data models and access patterns.5
After an application is sharded, there’s no guarantee that processes can access every shard. To render a response, therefore, you need to ensure that a request is routed to a process that can access the required data. How a particular request is routed becomes an important problem to solve. Let’s now look at some common ways that you can route requests to the correct shard and how you can use scriptable load balancers to solve this tricky problem.
Routing requests with DNS
For data models that can be sharded by domain name (e.g., multitenant applications), you can use DNS to route to the correct shard. Every shard is given a unique domain that resolves to a process which can serve requests for the shard, as shown in Figure 25-2.
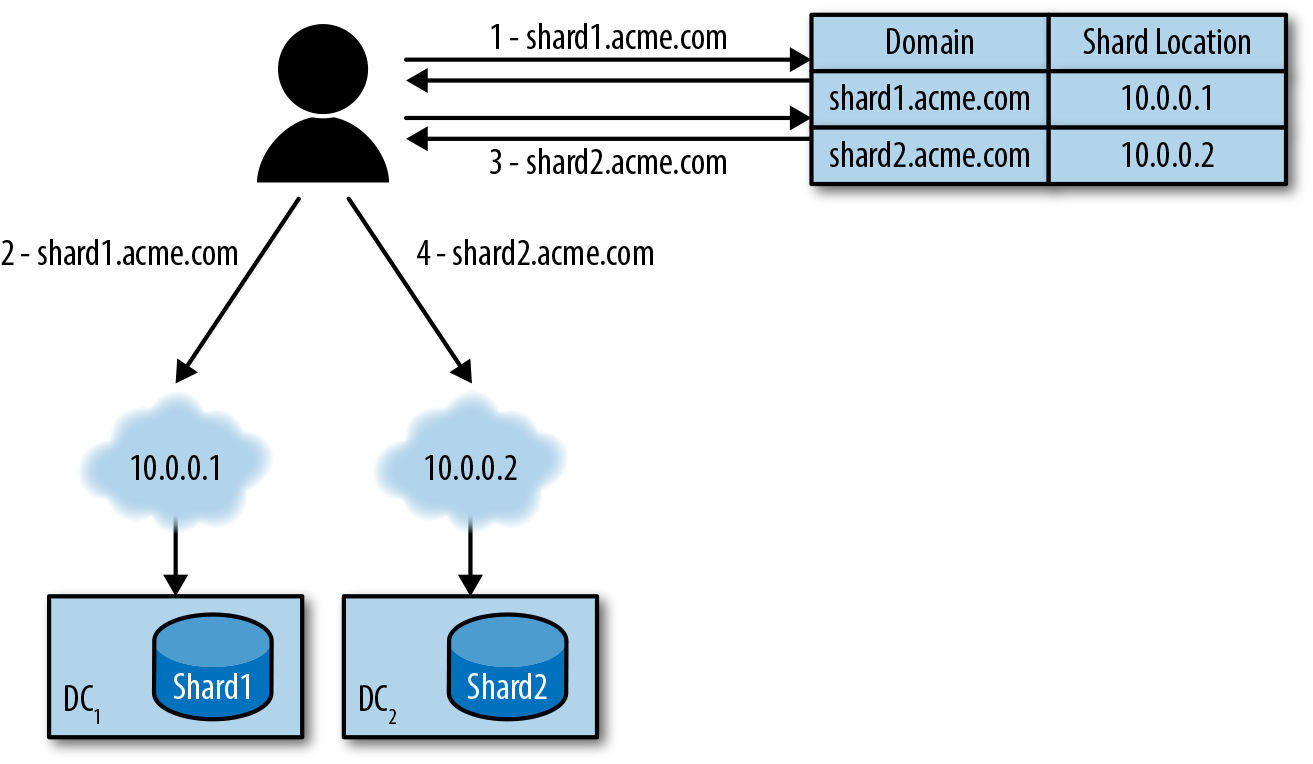
Figure 25-2. 1) Client requests DNS address of domain on a shard. 2) Client directs request to the IP returned by the DNS server to the location of the first shard. 3) Client requests DNS address of domain on a separate shard. 4) Client sends request to the corresponding DC.
The clear benefit of this method is its simplicity. Any application on the web is already using DNS. But, as we’re all too familiar, DNS comes with a whole host of problems. Convergence in changes to routing information can take unpredictably long times. Using DNS also limits what can be used to distinguish between shards (i.e., only a domain name).
Routing queries in the application
You can avoid the problem of ensuring that a request is routed to the correct process if every process can access all shards. As Figure 25-3 shows us, the logic of connecting and communicating with the correct database then becomes a responsibility of the application.
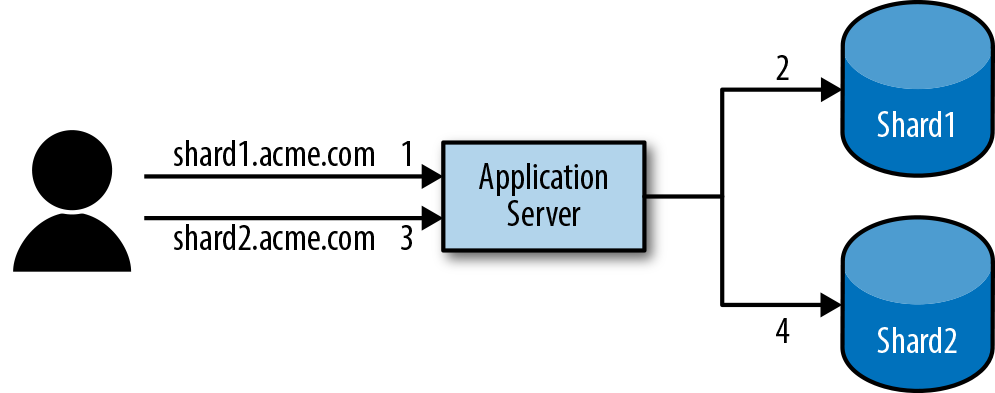
Figure 25-3. For every request, the app server connects to the necessary shard on the fly.
This adds nontrivial amounts of complexity and compromises the scalability of an application. When an application outgrows a single data center, the latency entailed in connecting across data centers makes connecting to every shard an expensive decision in terms of performance. Even when the added latency isn’t a problem, the number of connections each database and application process must manage leads to its own sets of problems (e.g., max connection limits).
Routing requests in the application
At the cost of added complexity, you can place shard routing logic in the application, as illustrated in Figure 25-4. When a request cannot be handled, the application proxies it to the correct shard. This is known as backhauling a request. Applications are now required to be able to backhaul traffic—potentially high volumes of it—to the correct process. Traditional web frameworks aren’t designed for proxying requests. To top it off, this sort of functionality isn’t easy to add.

Figure 25-4. 1a) Client sends a request for shard 1 to the closest data center. 1b) The app server connects to the local shard. 2a) Client sends a request for shard 2 to the closest data center. 2b) The app server in DC1 proxies the request to DC2, where step 1b is repeated locally.
Routing requests with a scriptable load balancer
Scriptable load balancers allow you to move all shard routing logic into the load balancing tier, enabling new routing possibilities and giving you the ability to completely abstract away the idea of sharding from applications. Processes are never made aware of requests they can’t serve, as depicted in Figure 25-5.
With full control of the request routing logic, you’re able to extract the desired shard from any combination of attributes or properties (e.g., Host, URI, and client IP). It’s even possible to query a database that gives insight about the shard to which a request belongs. With the other approaches to routing, the process directly affects how data models can be partitioned. For example, if you use DNS routing, data models without their own domain can’t be partitioned. Infrastructure concerns shouldn’t dictate the design of an application. Embedding routing logic in load balancers removes the leakiness of that abstraction.
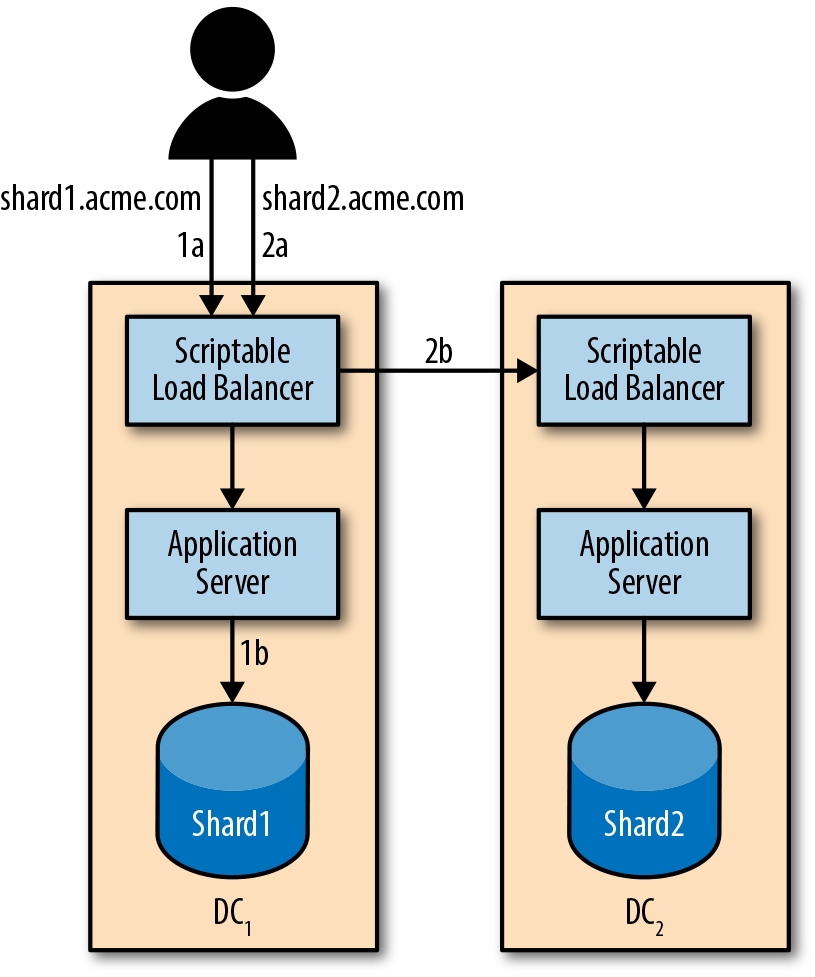
Figure 25-5. 1a) Client sends a request for shard 1 to the closest data center. 1b) The load balancer in DC1 proxies the request to the local shard. 2a) Client sends a request for shard 2 to the closest data center. 2b) The load balancer in DC1 proxies the request to DC2 where step 2 is repeated locally.
Ideally, applications are minimally aware of their own sharding. With routing in the load balancer, an application is able to hold little to no awareness of its own sharding. By separating these concerns, you can reuse sharding logic among multiple applications. Google’s Slicer6 is a prime example of this approach. Slicer is an autosharding service for applications. A core component is the transparency to upstream applications in how requests are routed to a particular shard through Google’s frontend load balancers and RPC proxy. The service is in production today, routing 7 million requests per second.
Harnessing Potential
The power in scriptable load balancers comes from the reuse of existing functionality. You don’t need to rewrite Transport Layer Security (TLS) negotiation or health checking when your load balancers already excel at these tasks. Oftentimes, internet specifications will even make room for modifications. HTTP caching is a good example of this. The RFC allows for custom Cache-Control header extensions that modify how and when a request is cached.7 Instead of writing a new caching proxy for fine-grained cache key control (e.g., including specific cookies in the cache key), a simpler script running in the load balancer can reproduce the exact same functionality.
Furthermore, load balancers specialize at routing and serving requests. An enormous amount of effort is invested in ensuring that they’re able to do this quickly, at high volume. With little effort, these same properties can be inherited by the modules added to scriptable load balancers. You can see this in Cloudflare’s Web Application Firewall (WAF)8 and Shopify’s Sorting Hat (L7 routing layer),9 which both measure performance in microseconds.
Case Study: Intermission
For most services, the ability to ship code into production quickly and easily is important. One component of being able to do that is zero-downtime deploys. As much as automation can lower the time it takes to perform disruptive maintenance, you can’t eliminate the downtime it takes entirely.
You can use scriptable load balancers to solve zero-downtime deploys or maintenance by adding the ability to enable/disable request pausing. Take, for example, an application that errors on any request during maintenance, as demonstrated in Figure 25-6.

Figure 25-6. The client request fails because the upstream service was unavailable during the maintenance window.
Request pausing is when a proxy waits before forwarding the request to the desired upstream. A request can be paused for a specified amount of time or toggled by a flag stored in a datastore. When the proxy resumes, requests are forwarded to their original target, as shown in Figure 25-7.
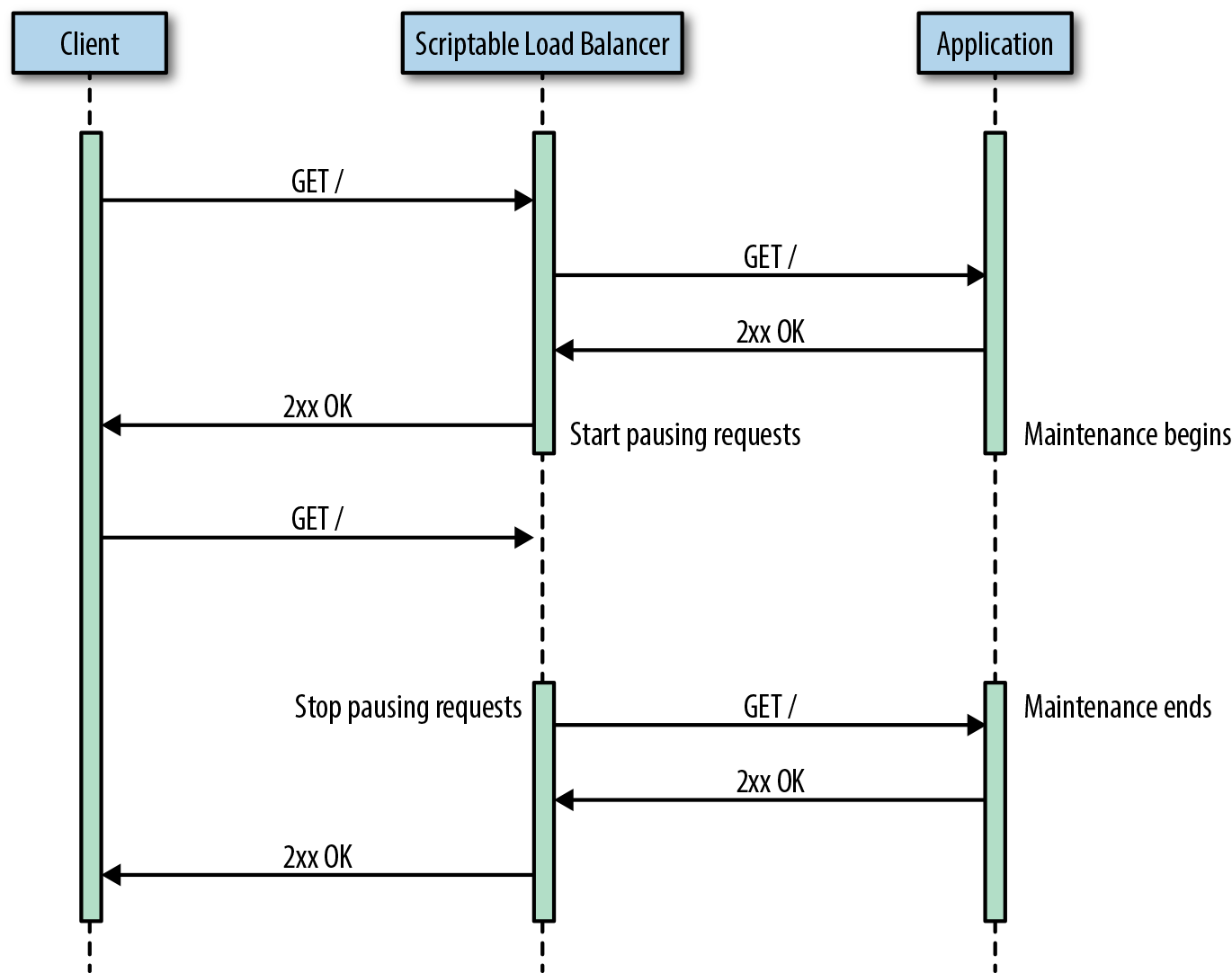
Figure 25-7. When the client request hits the load balancer, the load balancer waits until request pausing is disabled to forward it to the application.
Rather than failing a request, clients receive a slower response. Depending on the Service-Level Objectives (SLO), this can be the difference between staying within this month’s error budget or bursting through it. Scriptable load balancers can be programmatically instructed to start pausing requests for a service, track whether clients have disconnected, and slowly forward requests as the service comes online to avoid overloading upstream services.
Service-Level Middleware
Eliminating toil is one of the core principles in SRE.10 As organizations continue to adopt SRE best practices, more teams are moving to a product or service model to kick the ticket/ops cycle.
In the traditional ops model, engineers deploy and operate dependencies for each application. A traditional example of this would be a database. The ops teams would set up, and babysit, SQL servers for the applications they’re operating. With the product or service model, a dedicated team builds out an application-agnostic database as a service. This service is then exposed by an API/UI (e.g., what’s offered by cloud providers).
Although a product–service model is substantially better than toil and “operating snowflakes,” it still pushes the burden of interoperating with a provisioning service to applications. In some cases, this can quickly lead to high overhead. Calling out to a service requires that an application be aware of its existence. Picture an identity service that every application uses in order to authenticate requests. Each application is forced to hold awareness of the identity service, which leads to an increased maintenance burden and the overhead of calling to an outside service. With scriptable load balancers, product/service models aren’t the only way SRE teams can eliminate toil.
Middleware to the Rescue
Scriptable load balancers are typically the first component that touches a request. This makes them an ideal location for logic that affects multiple services. Rather than making RPC calls to outside services, applications can read headers added to the request before it was proxied. You can think of this model as middleware similar to those found in most web frameworks. A service-level middleware transparently operates on requests before they hit the upstream application. Product developers can free themselves of the overhead and complexity of calling to an outside service.
For certain problems, a middleware is a more natural solution.11 Take, for example, the identity service mentioned earlier. Rather than calling out directly to the identity service, an application can assume any request that has a certain header that has already been authenticated. The header could contain the scope and access the client has. The identity middleware removes the latency and complexity overhead of calling to outside services from within upstream services.
APIs of Service-Level Middleware
All but the most trivial of middlewares require some application-specific configuration (e.g., specifying a different cache key on a particular page). The immediate go-to solution might be to hardcode this configuration in the middleware code base. But, over time, the hardcoded configuration will likely diverge from reality and lead to easily avoidable outages.
To prevent divergence, it’s important to establish clear APIs through which applications can constantly communicate to downstream middleware. You can use custom HTTP request and response headers as the communication bus over which configuration is communicated. For data that doesn’t fit into the request/response flow, you can use an out-of-band message bus to propagate state to all load balancers.
Case Study: WAF/Bot Mitigation
It’s only a matter of time before a web service is targeted by a Distributed Denial-of-Service (DDoS) attack or exploited through automated bots.12 DDoS attacks can cause nasty outages, with serious downtime. Automated bots beating out human customers often leads to unhappy customers. Rather than developing the same antibot or DDoS mitigation tooling in each application, you can use scriptable load balancers to build a layer of protection against these threats and use them on all web-exposed services.13
Cloudflare has built a business providing such a layer with its web application firewall functionality. Any service behind its middleware gains the same benefits of protection against Open Web Application Security Project (OWASP) vulnerabilities, common DoS vectors, and zero-day exploits. When the danger or authenticity of a request is ambiguous, the middleware is able to redirect to a challenge-response test to validate that the request comes from a legitimate source.
Whereas previously protection against attacks below the application layer would require making a decision based on the scope of a single packet, scriptable load balancers allow you to make decisions after analyzing the entire transaction. Now you can optimize for user experience while keeping your services secure. The most important takeaway is that a WAF middleware, such as that offered by Cloudflare, allows for the concentration of work into a single service, from which benefits are reaped across multiple applications.
Avoiding Disaster
When SLOs are defined, they’re often focused on the internal failures of a service. SLA inversion is the idea that in order to get an accurate SLO of a service, you must take into account all direct (e.g., database) and indirect (e.g., internet routing) components on which the service depends.14 In many architectures, the load balancing tier is shared by multiple applications and services. Any resiliency compromises made in the load balancers affects the SLOs of all upstream applications. Given this reality, it’s paramount to focus on maintaining a high level of resiliency in scriptable load balancers.
With the numerous benefits offered by scriptable load balancers, it’s easy to overload load balancers with logic. The load balancers go from being a powerful solution for difficult problems to a hammer that’s looking for nails. As in all architectures, it’s important that logic placed into scriptable load balancers doesn’t add single points of failure or negatively affect availability. A particularly dangerous pitfall when you are using scriptable load balancers is mismanaging state. The rest of this chapter discusses how to best handle state on the edge.
Getting Clever with State
Through the previous examples, we’ve seen how powerful scriptable load balancers can be. Although past examples have focused on individual requests, in reality, when clients interact with our services, it’s typically through a series of requests that we often refer to as a session (e.g., a customer browses a shop, adds items to their cart, and then goes to checkout).
To be able to properly reason about a request, it’s important to know the context in which it’s being made. A single request to a slow-loading page can be business as usual, while a hundred in quick succession is a DoS attack. Storing state allows you to distinguish between these two events. If the way state is stored and accessed isn’t cautiously reasoned about, it can quickly lead to compromising the availability of our edge tier by adding a single point of failure or drastically increasing complexity.
Depending on which load balancers share the same database, the state stored represents a different snapshot of the world. If each load balancer were to talk to the same database on every request and the database offered consistent guarantees, we’d have a perfect understanding of the world. Depending on the number of processes, nodes, and data centers, such a setup would have impractical overhead and latency costs. Instead, it’s important to modify how you approach certain problems that require consistent, global views of the world.
Let’s take a throttling mechanism as an example. As Figure 25-8 illustrates, the throttle passes requests up to a certain limit for a given amount of time and blocks all subsequent requests until the next block of time. This sort of throttle typically requires having a single, consistent source of truth shared between all potential throttling points.

Figure 25-8. Each request is registered in a database shared by both load balancers.
An alternative to storing a counter in a shared data store would be to store the counter on each load balancer, as depicted in Figure 25-9, but divide the maximum throttle size by the number of load balancers receiving requests. If a single load balancer reaches the limit, all other load balancers are likely to have reached the same limit as well. What we lose in precision, we gain in resiliency.

Figure 25-9. Requests are only registered on the load balancer accepting the request.
Case Study: Checkout Queue
Online shopping websites will have checkout queues, similar to a brick-and-mortar store, as a form of back pressure to ensure the service doesn’t fail during high-write traffic events (e.g., a sale). Shopify has had to implement such a checkout queue to handle large flash sales brought on by high-profile merchants. The instinctive approach is to store a queue in a database that can be accessed by all load balancers. The queue would store the order of customers attempting to check out with a cart. Unfortunately, this queue database adds another potential source of failure and increases complexity.
Instead of storing the queue of customers in a database shared between multiple load balancing nodes, Shopify implemented a prioritized throttle that behaved similarly to a queue. This was done without any shared database, only a checkout queue entry timestamp, paired with some session state, stored in each customer’s browser through signed cookies.
Each load balancer has a throttle, similar to what we described earlier, deciding whether there’s enough capacity for a customer to check out. Customers are assigned a checkout entry timestamp when they first attempt to proceed to checkout. If the service is overloaded, customers poll in the background on a queue page. Figure 25-10 illustrates the flow of a customer going through a throttled checkout process.
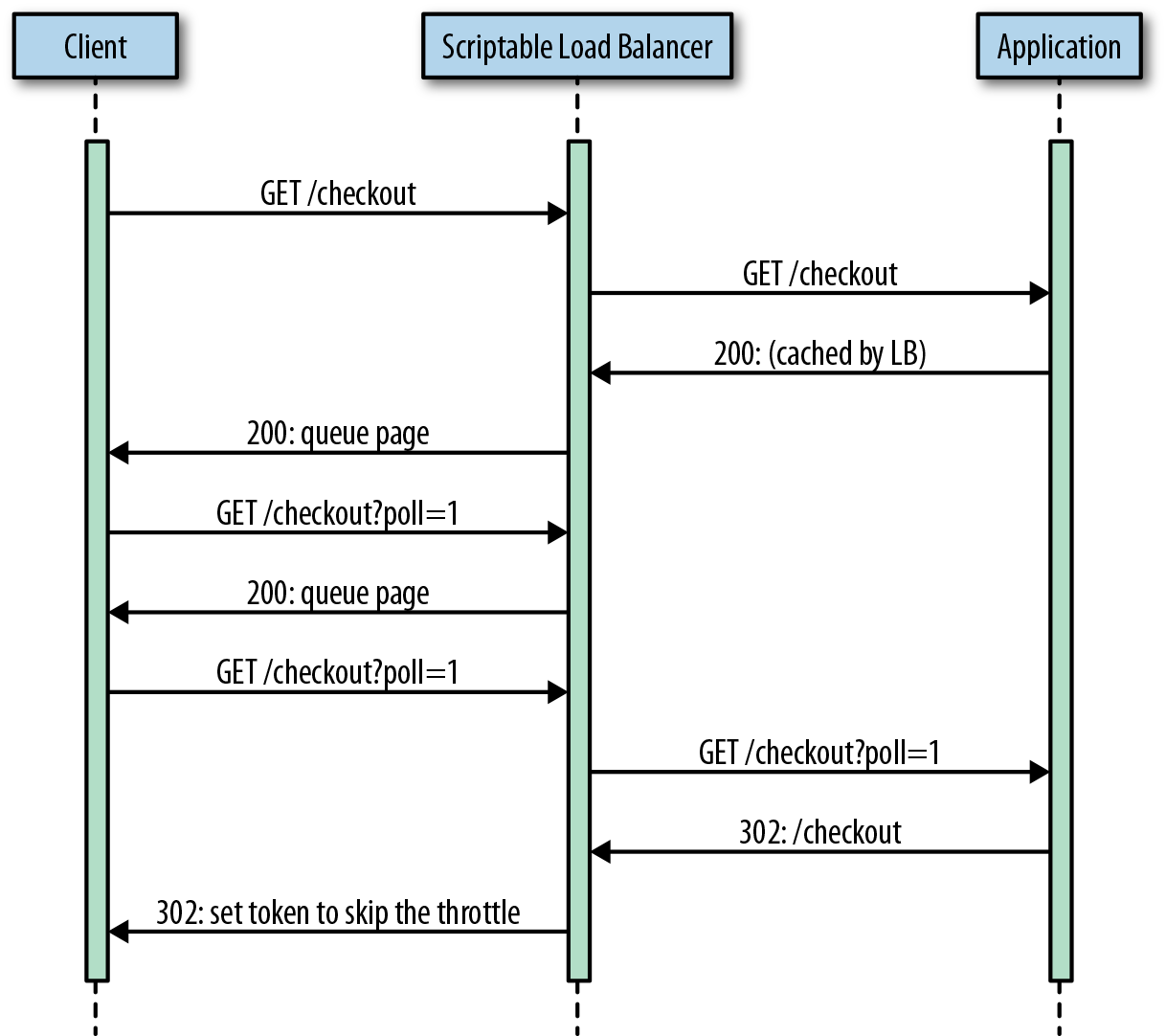
Figure 25-10. Request flow of a customer attempting to checkout, being throttled, and then eventually making it through the queue.
With each poll, individual load balancers modify their view of how long the queue is. They do this by updating the internal node timestamp that decides whether a customer is allowed to attempt to pass the throttle to checkout. The node timestamps are modified with a Proportional-Integral-Derivative (PID) controller that aims to maximize the number of requests passed to the throttle without exceeding its limit. With slight shifts in thinking of how and which state to store, suitable solutions for scriptable load balancers with better resiliency present themselves.
Looking to the Future and Further Reading
As with all new technology, scriptable load balancers aren’t perfect. Adding logic to the load balancing tier is a double-edged sword. Without effort and focus on resiliency, the consequences could be disastrous, lowering the availability of the applications we support. A byproduct of being new is that there isn’t a clear consensus on best practices.
Despite speed bumps, the ability for scriptable load balancers to improve resiliency and performance can’t be argued. There’s a real opportunity for scriptable load balancers to be a watershed moment and become a common tool in every SRE’s toolbelt. I hope this chapter convinces you to give them a try.
If you enjoyed the examples in this chapter, I encourage you to learn more about them. Scott Francis’s talk at NginxConf, “Building an HTTP request router with NGINX and Lua,” goes into detail about building a shard routing layer in Nginx with OpenResty. John Graham-Cumming as well as Marek Majkowski have spoken numerous times on how Cloudflare implements its WAF systems with scriptable load balancers.15,16 Intermission, the request pauser example, was inspired by a project by the same name built by Basecamp.17 Finally, I’ve written more in-depth about how the checkout queue throttling mechanism works in “Surviving Flashes of High-Write Traffic Using Scriptable Load Balancers.”18
For more general resources on load balancers, you can’t go wrong with Vivek Panyam’s “Scaling a Web Service: Load Balancing,”19 Matt Klein’s “Introduction to Modern Network Load Balancing and Proxying,”20 and the “Application Architectures” chapter in Practice of Cloud System Administration: DevOps and SRE Practices for Web Services.21
Contributor Bio
Emil Stolarsky is an infrastructure engineer with a passion for load balancers, performance, and DNS tooling. When he’s not analyzing flame graphs, you can find him listening to Flume and fighting his fear of heights in a nearby rock climbing gym.
1 Limoncelli, Thomas A., Strata R. Chalup, and Christina J. Hogan. (2014). “Application Architectures.” In Practice of Cloud System Administration: DevOps and SRE Practices for Web Services. Boston: Addison-Wesley Professional.
2 Shuff, Patrick. (2015). “Building a Billion User Load Balancer.” Talk at SREcon15 EU.
3 Netcraft. (2016). “September 2016 Web Server Survey.”
4 Roberts, John. (2016). “Control Your Traffic at the Edge with Cloudflare.” https://blog.cloudflare.com/cloudflare-traffic/.
5 Matsudaira, Kate. (2012). “Scalable Web Architecture and Distributed Systems.” In The Architecture of Open Source Applications Volume II: Structure, Scale, and a Few More Fearless Hacks. Ed. Amy Brown and Greg Wilson. (CC BY 3.0.)
6 Adya, Atul, et al. (2016). “Slicer: Auto-sharding for Datacenter Applications.” In Proceedings of the USENIX Conference on Operating Systems Design and Implementation. https://www.usenix.org/system/files/conference/osdi16/osdi16-adya.pdf.
7 Fielding, R., M. Nottingham, et al. (2014). “Hypertext Transfer Protocol (HTTP/1.1): Caching”. IETF Standards Track RFC.
8 Graham, John. (2014). “Building a Low-Latency WAF Inside NGINX Using Lua.” Talk at NginxConf.
9 Francis, Scott. (2015). “Building an HTTP Request Router with NGINX and Lua.” Talk at NginxConf.
10 Beyer, Betsy, et al., eds. (2016). “Part II. Principles.” In Site Reliability Engineering (O’Reilly).
11 Agababov, Victor, et al. (2015). “Flywheel: Google’s Data Compression Proxy for the Mobile Web”. In Proceedings of the USENIX Symposium on Networked Systems Design and Implementation.
12 Kandula, Srikanth, et al. (2005). “Botz-4-Sale: Surviving Organized DDoS Attacks That Mimic Flash Crowds”. In Proceedings of the USENIX Symposium on Networked Systems Design and Implementation.
13 Majkowski, Marek. (2016). “Building a DDoS Mitigation Pipeline.” Talk at Enigma.
14 Nygard, Michael T. (2007). “SLA Inversion.” In Release It! Design and Deploy Production-Ready Software (O’Reilly).
15 Graham, John. (2014). “Building a low-latency WAF inside NGINX using Lua”. Talk at NginxConf.
16 Majkowski, Marek. (2016). “Building a DDoS Mitigation Pipeline”. Talk at Enigma.
17 Intermission.
18 Stolarsky, Emil. (2017). “Surviving Flashes of High-Write Traffic Using Scriptable Load Balancers Part II”. Blog post.
19 Panyam, Vivek. (2017). “Scaling a Web Service: Load Balancing”.
20 Klein, Matt. (2017). “Introduction to Modern Network Load Balancing and Proxying.”
21 Limoncelli, Thomas A., et al. (2014). “Application Architectures.” In Practice of Cloud System Administration: DevOps and SRE Practices for Web Services. Boston: Addison-Wesley Professional.