
Chapter 7. The Application Aspect
Most applications today are, or should be, service oriented. With the core of your software product or application built as services, you will gain clarity, high cohesion, the ability to scale, and improved portability, and provide the basis for a platform.
I tend not to be too zealous about following strict community dictates just because, say, the RESTafarians demand things be done a certain way. I rather try to find the true, concrete advantage in some dicta, and then, if there is a practical value to it, I’ll choose to follow it. For example, it doesn’t do you much good if I simply insist that you religiously follow the HATEOAS (Hypermedia as the Engine of Application State) creed because it’s important, and you’re not beholden to me in any regard. There are plenty of times when it makes considerable sense to use verbs and not nouns, or to use ProtoBuf or Avro over hypermedia. There is no silver bullet, and there is no one perfect way. There are the constraints, tools, knowledge, and goals that you and your team have, and that’s the important thing to foreground. So please keep that in the back of your mind through this chapter.
In this chapter, we cover the fundamental guidelines for good service design that I use with engineering teams. Although there are certainly other helpful directions you can offer, these are what I find most pragmatic and useful. Doing just these will get you a very long way.
Embrace Constraints
It is not worth it to use marble for that which you don’t believe in, but it is worth it to use cinder blocks for that which you do believe in.
Louis Kahn
Frequently, the more that leaders express constraints to development teams, the more development teams complain. They don’t have time to adhere to all these requirements, they say.
In my view, design constraints are like meetings. People say they don’t like meetings and they want fewer meetings clogging up their day and wasting their time. I think what they really mean is that they don’t like ineffective meetings, in which the goal or purpose is not clear, the wrong participants have been invited (or not invited), there is no agenda and no clear outcome, and the decision rights are not stated. If you do those things, your meetings will be effective, and people will enjoy them, because they will be useful, meaningful, move your project forward, and make things happen.
So by way of analogy, I think design constraints are similar. If you are policing developers, specifying where they should place every last semicolon, harping on things that don’t truly make a material difference, and have not aligned the product organization around a shared voice for supporting the constraints you do state, no one is likely to appreciate that. But if you can express for teams the things that make a material difference, in a way that they can execute confidently, whether they like it or not, you’ll be effective.
Constraints are actually positive, and something I actively seek in the early stages of design. They can ground you, give your work a boundary, kind of like filling out a puzzle by starting with the corner pieces and the edges: they give you something you can count on, that can orient you, and that can inform other design decisions over which you can exercise more judgment or taste.
Your constraints might come in the form of a deadline, or data privacy laws, or regulatory compliance, or a specific customer requirement. If you approach these with an open mind, you can use them to gain advantage in and improve your designs. For example, in one project I designed with my team, the executive sponsor imposed an arbitrary six-month constraint on us, stating, “You have to get to market with something usable in six months; I don’t care what it is.” (This has actually happened to me three times on major projects, so I’ve come to expect it).
This was very unwelcome news for the engineering team. The project was a three-year overall endeavor and represented the core of our system. We wanted to work on the foundational aspects and ensure that the structural underpinnings were absolutely solid before going through all the UI work and other things that customers required, and so this created considerable distraction in our eyes. We grumbled because we thought it meant that we would never get to come back to the key abstractions that made the system so powerful. So, we decided to interpret the constraint in a positive way, out of sheer cussedness more than anything else: we didn’t want to give up our powerful abstraction for the deadline—so we didn’t. We had to build the subsystem in a different way to accomplish our one chosen use case for a minimum viable product (MVP), but still make progress toward the overall substructure, which was the purpose of the project in the first place. In the end, we didn’t compromise anything, and the deadline improved the design and tested it thoroughly. And being forced to test all the way through and build pipelines all the way through into production turned out to be terrific.
Decouple User Interfaces
Your software products and applications should be thought of as thin user interfaces on top of collections of services.
Ensure that the user interfaces feature responsive designs; that is, you should not assume that you know the user interfaces that will be needed for your applications. Although today most UI JavaScript frameworks such as Angular, Ember, and React make this straightforward, be sure to design the web UI to work across mobile devices, tablets, and desktops at a minimum.
User interfaces can frustrate your users if they are not thoughtfully designed with user goals in mind. Therefore, applying Design Thinking and Concept Models, discussed in Chapter 4, is imperative. The trick, however, is that while considerable thought must go into making them easy and even delightful to use, you must also consider them disposable. In general, the UI will change more frequently than other parts of your application. Marketing will come up with a new color scheme, and the commercial officer will come up with new retailing and merchandising schemes and A/B testing. The product managers will create new business partnerships, which means that your business application might suddenly need to surface on a gaming console, a car console, a voice agent, a watch, an Internet of Things (IoT) product, and so forth. These are all very different ways of interacting with the same set of business services. Your business services should not need to change too much or too often, just because your UI does.
Therefore, you must be sure to keep your UI very separate from your business services. Do not assume that you know what the interface will be, and assume that there will be many of them. The UI should just do the work of displaying results, and not perform “work.” This seems obvious, but it’s amazing how frequently I see it violated.
UI Packages
Following our deconstructive method, you can create “UI Packages.” At the start of your project design work, do not talk about “the UI” as if there were only one. This semantic misstep will lead you down a bad path. It closes down thinking, making an unconsidered, implicit assumption. It might be “mobile first” or “web” or whatever your thing is. Yes, of course you must settle on the one or three UIs realizations you will support for now. The point is to get to market. Just make sure that you are aware of implicit and unchallenged assumptions and decisions that aren’t being made explicitly as decisions. Be aware of what you have anchored and privileged as the “central term,” thereby casting the rest of the universe of possibilities as the secondary, ancillary, marginal, minor afterthoughts. You can do this in a matter of minutes. Just don’t skip it.
At the beginning of your project, regardless of what the product managers state as the only “requirement,” do right by them by considering the entire universe of UI possibilities that you are aware of. These might be web, table, mobile, gaming console, car console, headless, and a variety of IoT applications. Then, according to your current requirements, carve out the space for naming the UI package after only the ones your requirements call for. That is, instead of grouping “The UI Code” together (as if there were only one), you simply name it “web-mobile-xxx” for your responsive design for that UI as one channel among many possibilities. This leaves room in your concept for placeholders for other UI packages, such as “xbox-xxx,” which would need to surface the UI in C# code, maybe written by another team with a different skill set.
Doing this creates the quickest time to market and the best ability to parallelize work and keeps things nice and tidy, preventing overlap with engineering teams. It also allows those UIs to be updated and retired on their own timelines, and leaves a path for the UI packages that you might not need today but that can open up new revenue streams if you have left semantic space for it.
Consider what elements are only display and interaction, and don’t put anything else in the UI package. Then just use your UI to invoke your service APIs.
The other advantage of doing this is that you can create mock objects, demonstrate the UI in front of customers in a Design Thinking fashion, gain valuable feedback, and improve it quickly without a big lift.
On Platform Design
You keep using that word. I do not think it means what you think it means.
Inigo Montoya, The Princess Bride
Many software people today cheerfully throw around the word “platform.” A lot. In fact, it’s hard to find a business today that isn’t calling whatever it does a “platform” (which is often also “disruptive”). To me, the term “platform” is clear. It’s something that someone stands on. Your software is a platform if someone else can build on top of it a new useful application that does something your original system doesn’t. It’s a SaaS platform if they can do that without calling you. Otherwise, it isn’t: it’s just an application. Amazon Web Services (AWS) is a platform. Google Cloud Platform (GCP) is a platform. SalesForce is a platform. Facebook is a platform. Platforms prevail. They create an incredible business opportunity. They create a great balance between offering something useful out of the box, something that can change with the quickly changing times, and something that can be customized without you hiring a bunch of Scrum teams to add a bunch of awful conditional logic for routing specific customer behavior into the main code base over the course of a six-month development project.
In a famous memo Jeff Bezos wrote to his teams in 2002, which you can readily find discussed online, he basically said this: “Make sure everything you write is a service. Only communicate with any other teams’ products through service APIs. I don’t care what the implementation language is. If you don’t do this, you’re fired. Have a nice day.” That presumably short memo is arguably the thing that enabled a storage engine to become the Amazon Simple Storage Service (Amazon S3) service and Dynamo to become a distributed data service, and indeed is arguably responsible for creating all the various building blocks for what would then become AWS three short years later. AWS went on to grow from $0 in revenue to $26 billion in revenue in just over a decade. To be clear, there are only about 400 companies in the world with more revenue than that, and many of them have taken an order of magnitude more time to create it. Services are the way to scale, and they’re the way to create a platform.
Businesses, and the customers they serve, can realize the richest possibilities if you offer your software as a unified platform. The platform is not one corner of two or three services you expose to the outside world. It is the complete catalog of the services across your business, made available as APIs. Do not think, as some do, that “there is a services team, and they are the ones that build services and so I don’t build them.”
Like user interfaces, the core business services and the exposed external-facing services should be separated. Just like a UI, customer-facing services should do no work. In fact, these external APIs are just another UI, and should be designed and managed accordingly.
Your engineering teams must build services-first. Everything that might possibly be of use to anyone else should be considered as an API, and then exposed that way. One of the very first things your teams should do is consider in a list on the whiteboard or in Excel or whatever little tool the list of services that your application can and should be based around. It can’t be an afterthought. For every team, for everything you build, build it as a service.
Some people get religious about the implementation language. This is not a mature view in businesses of any size or import. Now more than ever, the implementation language doesn’t matter much, especially if you expose services. There are fun debates to be had over threading models and performance and scalability and portability, and how Java has become a teaching language, and something about Go, and so forth. I find these conversations insufferably boring. As a designer thinking like a business person, there is primarily one reason to care about the programming languages used in your platform work: human talent.
The protocol, too, is another element to consider in our deconstructed method. After doing this for more than 20 years, it becomes very apparent how much time we technologists spend rearranging the furniture for the flavor of the month. Everyone had to switch everything to SOAP. Then they hated SOAP and had to switch everything to XML. Then they hated that and had to switch everything to JSON. The clever minority touted ProtoBuf. Popular products like Cassandra used Avro, so a patch of proponents pop up around that. Soon something else will come along.
The point is that, like the UI, the API you expose via one or more protocols must be separate from the engine doing the work. Offering your services, at least as exposed to the external world, in a few protocols is a fine idea. At least expect that you will change them and put the seam of semantic separation in the right place. Consider the protocol, like the UI, as just a particular representation of how you get the message to the user; it’s not the message itself and it certainly is not the worker engine that does math to make the message. I think of protocols the way I think of stories and their presentations in different venues. You might have a story of Cinderella. That could be read in a book, or performed as a Broadway play, or done in a cartoon movie. But the story is the same. The story is your engine service that does the work. These different venues are your protocol. If some executive says that you should be making services with RESTful interfaces that exchange JSON, that’s fine. But just like the UI, it’s free and only takes seconds to simply name the protocol package after its implementation (“rest-json-xxx”) and then leave space in the code repository for “protobuf-xxx” and thereby remind yourself and everyone on your team to keep the separation of concerns (protocol as mere message delivery mechanism versus service doing the work).
Service Resources and Representations
It goes without saying that services must be thoughtfully designed. Because you have this basic structural idea of services in place, you need to consider how they will work together to orchestrate work flows, how they can scale and evolve independently, and how they can best support accomplishing user goals in a secure and fast manner. With the basic idea that you’re dividing your semantic real estate up into services, how shall you go about that division of neighborhoods?
Start with a simple word, usually a noun, that describes your idea. The idea might be “storage,” “distributed database,” “customer profile,” “products,” or other primary ideas in the system you’re designing. Capture these key words from the conversations you have; the main aspects will come up all the time.
Then consider the verbs. What are the things that people want to do to or with those nouns? At this point, you’re not coding anything or using some horrible heavy “enterprise architecture” software tool. Pencil and paper or a whiteboard is great here.
How you name things at this level is critically important. One of the most important things you will do in your design is to decide what to call things, and what ideas get names at all. Be certain you are not biting off too much semantic real estate with the name you give a concept. If you name your service HotelShopping, this means that a different service can be created to run VacationRentalShopping or MerchandiseShopping. Carefully consider these service names and talk with your colleagues to ensure that you are truly saying what you mean in the name, that the space the name takes up is actually supported by the service. Calling a service “Shopping” means it better allow the user to shop All The Things, which might not really be what you want.
Before you leave the pencil and paper stage, get inspiration and learn from the masters as a kind of test to see how your ideas look in comparison. Review popular APIs such as those at Twitter, AWS, Google, Microsoft, or Amazon Merchants, and see how they are constructed. A great resource to model your work after is the Google API explorer, which lists the available APIs for many of its products such as Gmail, Cloud services, Android, and more. You can examine how it has set up the APIs in AWS for a great lesson. These have been incredibly popular, scalable, and successful for years.
Although REST teaches us to be oriented around resources and representations—which means the nouns in your application, such as Guest, Hotel, Flight Route, Product, or what have you—sometimes it services as functions. You might have a function that calculates the currency exchange rate, or a Shopping service. The challenge with a “Shopping” service is that it already combines a few ideas, such as Customer, Product, Cart, and so forth. So this can become a monolith, and a service in name only if you aren’t careful.
But after you have considered the noun you’re starting with, consider what it might do, what actions it might take, and what might be done to it. With the aforementioned AWS API, Amazon Elastic Compute Cloud (Amazon EC2) allows you to “reboot instance,” or “create tags,” and so forth.
With Twitter, the API includes functions to post a tweet, delete one, search and filter, upload media content, receive a stream of tweets, and so forth. The idea of tweets is one distinct idea and its API has the constellation of related actions. The idea of advertising is separate and distinct. We know this because in the conceptual universe, tweets can (and they did when it first started) exist without the idea of an ad, and vice versa. So they are distinct ideas and have different users. If you consider the stick figures in a use-case diagram, we have two now: the regular Twitter user and the Advertiser. They want, and do, different things. So we can expect that their product managers might evolve their businesses independently. Making these distinct APIs in the system takes advantage of Conway’s Law, which is a great way to make sure your teams can work in parallel, efficiently, while minimizing the number of decision makers and communicators involved in any particular decision, allowing quicker movement.
Conway’s Law
In 1967 Melvin Conway wrote a paper analyzing how committees work. He concluded that, “organizations which design systems...are constrained to produce designs which are copies of the communication structures of these organizations.” Put simply, your software is going to be structured they way your teams are structured. I can attest to the veracity of Conway’s Law across many different organizations. So it can make your life much easier, and your software cleaner, if you organize on purpose the way that you want your product to be. To make your architecture work easier, talk to your boss regularly about the way that your teams are organized, and how well that aligns with the product roadmap.
It is a tenet of REST that you separate the representation from the resource. In service APIs, this generally means the protocol is not thought to be fixed to the idea in the application code. You might have a Product API, in which case the product is the resource. But you could return to the end user a variety of different representations of that resource, such as XML, JSON, HTML, or an image collection. Be sure to keep the representation separate from the resource in your code to keep things flexible.
Domain Language
At this stage, you’re not writing code, you’re making lists of the basic categories to see how they interact. You’re zoning the city: here’s the airport, here’s the train station, here’s the park, here’s the shopping center, here are the neighborhoods. Stay at that level for a moment to be sure you have the right ideas. This will prevent rework later.
The main thing is to be very clear on the words you use. The AWS API for EC2 features many “detach-" functions (such as “detach volume,” “detach VPN gateway”). It also features many “disable-” and “disassociate-" functions. Define your terms very carefully, reuse them as much as you can, and be rigorously consistent about them. Never say “find” in one part of your API and then “search” in another if they do roughly the same thing and it’s not immediately obvious what that difference is.
Here you are settling on your domain language, and it’s crucially important. Create a glossary of your key API words, whether they are “detach-,” “disable-,” or what have you. Do this from the point of view of an imagined new person on your team who has just joined as a new hire and needs to quickly get up to speed. Write out these key words, define them definitively, and prescribe their consistent use. For example, “get-” might always mean that you must pass a unique identifier in the request, and the operation is expected to return one or zero results. Then a “find-” operation might accept some search criteria and always return a collection.
API Guidelines
Some teams insist on making their own guidelines for engineers to follow when making an API. I would encourage you to make a short set of conventions that you want teams to follow across two vectors:
-
What are the domain-specific names or ideas or terms of art that are particular to your business that you want to make sure people use in the same way?
-
What are the specific guidelines you have regarding your internal use because of specific mechanisms your IT team has in place to handle cross-cutting concerns? These might include throttling based on customer tier, security gateways, and so forth. Those are not particular to your domain, but they are particular to your organization.
Beyond that, there is little point in re-creating the wheel. For general guidelines around developing services, someone else has already done it. There could be academic debates about the readability of code that puts its curly braces on a new line or not, but I recommend you save that for the pub, point people to well-considered API guidelines made by experts and publicly available, and get on with life. Here are a couple that you can review and then adopt:
-
IBM Guidelines for Watson: this one is great because it includes multilingual conventions, coding, and repository guidelines
The point is not that one way of writing curly braces is blessed by a celestial omnipotent power; the important thing is that everyone does it more or less the same way, whichever way that is.
For cases in which having clear guidance does make a material difference to your business, such as how you illustrate versioning, following the guidelines is very important but is illustrated in the public ones that I just listed.
The main point of following these guidelines is this: as you consider your API contours, ask yourself if you have created cacheable URIs. If they are cacheable and don’t violate out-of-band (like with using cookies) or create a split-brain scenario in which you have been sloppy about where certain required elements are implemented such that you need all of them to complete an action, you should be off to a better start than most.
Deconstructed Versioning
The proper versioning of your services is very important. Naive development teams state that the way to know a major change from a minor change is based around their personal volume of work: how many late nights they had or how much coffee they drank to get the release done. This is subjective, it’s about you and not your customer, and it’s far too slippery. Just because you had four teams working on something for six months, and that big effort is rewarded with cake and executive speeches at the end, does not make it a major version. It should be crystal clear what constitutes a major and minor version, because it has a big impact on your customers. As deconstructionist designers, we are always empathetically concerned with the customer view.
There’s a strong argument for the idea that there is no such thing as a “version” in software, that a new major “version” must simply be a new and distinct deployable artifact. This is the deconstructed way of service versioning, and it’s very simple and straightforward.
In general, you have a minor version change if your API has any of these changes, which should be considered (meaning, implemented and tested) as nonbreaking, backward-compatible changes:
-
Addition of output fields.
-
Addition of (optional) input parameters.
-
Changes to underlying models and algorithms that may result in different results and values.
-
Changes to string values, except string values that have special status as being structurally significant. A date is a structurally significant string; a name is not.
-
Generally expansions, such as increasing a field size limit, but depending on your legacy systems, be careful with this.
Foursquare does this well, and IBM followed suit for Watson. Services should include a major version in the path (/v1/) and a minor version as a required query parameter that takes a date: ?version=2019-3-27.
In general, you have a major version change if you will break clients. This means that you are not backward-compatible. This means that clients will need to update, which they cannot all do in the same magic instant when you cutover to the new API so that they can keep their businesses running. Therefore, you will need to run the current version and the new version at the same time, for some time (perhaps weeks, months, or even years). Therefore, a major version must be built and deployed separately, must run in a separate process from the prior version, and must be separately addressable. It must state explicitly in the URI what the major version number is. Therefore, it’s just part of the name, it’s just different software, and not really a “version” at all. But that’s in a way academic, and the practical thing to do is to include the major version number in the path, to leave room for breaking changes in new versions later.
Breaking changes include these sorts of things:
-
Deleting ideas/removing output fields
-
Addition of a required input parameter
-
Changes to parameter default values
-
Change of field names
-
Change of status codes
Even if certain fields are optional in your API, your clients building software on top of your API might consider them required for their use cases in their software, so deleting optional output fields is considered breaking. Changing structured data, which is used by clients for indexing and reporting and other built-around purposes, is a big deal, and so changes there mean a major version, too.
The obvious distinction here is that great teams consider what is major or minor from the customer’s perspective; weaker practitioners consider what was major or minor in their own experience of doing the development.
It would be lovely if it could go without saying that it is imperative to communicate clearly and repeatedly any breaking and nonbreaking changes to your API well in advance of when you impose them on your customers, whether they are internal or external. Alas, it does not.
Cacheability and Idempotence
There is a simple test I like to use when designing services, to make sure they have proper separation of concerns. Here it is: be certain that your URIs are all accessible and usable as planned from the cUrl program. That’s a good test to ensure that you are keeping business logic out of the UI, and that you aren’t baking session logic and state assumptions into protocol mechanisms where they don’t belong (such as in cookies—but you would never do that, would you?). I recognize that if you’re using special protocols such as ProtoBuf or Avro, you won’t be able to check it with cUrl, but that’s then a completely different matter because you will have an entire client SDK.
If you’re following that idea—that you always check if your services are properly accessible and usable from cUrl—you have good reason to believe that your service is cacheable by clients, which is a key tenet of REST.
If it’s cacheable, it’s also bookmarkable and easily readable, which comes in handy for clients, helps drive traffic, and makes working with your API easier and clearer. If it’s bookmarkable by clients, you can bookmark it yourself and make a “saved search” type feature very easily. You can also then easily perform producer-side caching to relieve pressure on your database and offer fast performance.
The cUrl test doesn’t prove it, but you want to make sure your services are idempotent. A function is idempotent if invoking it repeatedly produces the same result as invoking it once, without side effects. Except for “creationary” functions, they should be idempotent. That is, a PUT operation is not idempotent. You create a Customer row and that returns a 200 OK, and then attempting to create the same customer should return an error status that the resource already exists. Otherwise, the GET, PUT, DELETE, HEAD, OPTIONS, and TRACE invocations are idempotent in HTTP and should be in your APIs, too.
This is easily done. Again, with the plurality that our deconstructionist design highlights, never invoke your noncreationary services once in regression testing, but always at least twice with the same parameters. This makes sure that you are designing in a way that affords you the most flexibility with future clients, makes you most resilient to changes, and puts your dependencies where they belong without creating a split brain.
Make sure that your REST APIs are hypermedia-driven, such that they observe the HATEOAS principle.
Hypermedia as the Engine...
For a good overview of the RESTful HATEOAS principle, see the Spring page on the topic, or read Roy T. Fielding’s original dissertation, which I highly recommend.
This principle of REST is the one I see violated most often, and what then creates a variety of artificial constraints that make later extensibility, flexibility, reuse, change, or porting very difficult.
Independently Buildable
You should be able to build, test, and deploy each service independently from others. Building a service should be an automated job through a tool such as Jenkins, and the result should be a deployable artifact.
Rebuilding a client application, or UI package application, should not require that your services are rebuilt. Otherwise, they aren’t really services; they are part of your application monolith.
If you make a breaking change, it is likely that you will need to rebuild both your UI application and one or more services, but that job should be a separately defined job from the overall housing application’s build.
Give yourself the option to always be able to do the following:
-
Rebuild everything all at once
-
Rebuild only one specific aspect (UI packager aspect, service, orchestration, etc.).
That allows you to define an arbitrary collection of services and UI packagers to rebuild as necessary for whatever update you’ve made. This is the best intersection of keeping things quick and understandable. If you have to rebuild a lot of things because you changed one thing, you’re not getting much advantage. Part of what’s great about services that isn’t often mentioned is that rebuilding and subsequently redeploying only a small percentage of your application’s overall footprint means that a lot of things go much faster: building, testing, deploying, replicating. And it means that any new problems that you might have introduced are likely to have a very confined scope, or at least be more quickly identified.
Strategies and Configurable Services
Sometimes teams try to envision everything a user will need and create the service that includes all of those features. But this is pretty tough to do. And of course, you already know that some customers will need to set up some features differently. Allowing users to do this through a UI or an API is configuration. Users are not changing the behavior of the service; they are specifying certain things they want to see done in a certain way, and you have already afforded them the exact dials they will be able to twist.
Configurability in this way is great, but it still requires that you are able to sharply anticipate all of the things your users will need to be able to change in fairly fine-grained ways.
You might also consider configurability in another way. The traditional Gang of Four Strategy pattern should be your default, go-to solution for implementing any business logic. As a refresher, let’s quickly examine the Strategy pattern.
Deconstructionist designers assume that their current way of implementing is just one of many possible ways, and so they don’t just directly implement exactly what the requirements are. They pave a path forward for change and concurrent differences in behavior based on the channel, the client type, the customer, or anything.
The Strategy pattern allows you to define a family of algorithms that can achieve a result differently and allow clients to select the algorithm they want to use at runtime. This produces more flexible and reusable software. As a simple example, imagine that you have a sorting function. Computer scientists have written several different sorting algorithms to sort a list that each have different advantages, such as BubbleSort, MergeSort, and QuickSort. Instead of designing your sorting function by trying to know in advance what the best one to use must be and then giving up all the others, the Strategy pattern would always produce a sorted list, but allow clients to specify how to sort it themselves, as demonstrated in Figure 7-1.

Figure 7-1. The Gang of Four Strategy pattern
This is an important pattern in deconstruction and semantic design, and it serves as a kind of paradigm or kernel of this entire approach to system design. You first define a context, which calls the strategy interface to get its result, and the context is independent of the particular strategy employed in achieving the result.
The Strategy pattern represents the object-oriented tenet of composition over inheritance. Inheritance is frequently antithetical to deconstructed software designs. Inheritance in software creates rigid hierarchies, which are almost always reducable to arbitrary distinctions that fall apart when challenged, creating brittle and unmaintainable software. There are times when your domain is specifically about hierarchies, such as in a genealogy model or a military chain of command perhaps, and then it’s less cumbersome and a more natural fit. But in general, I try to avoid designing categories of assumed hierarchies in my data model, because too many times I have seen how difficult and expensive and time consuming it is to change them later. Instead of hierarchies, try compositions with associations such as tagging. Arranging your list of products via tags as opposed to categories can usually achieve the same apparent result and functionality, and it saves you the time it takes to design something in a false representation of the world.
The Strategy pattern is very simple and yet very powerful. As a rule, your services should implement their business logic as strategies. Even if the first Strategy you define is the only one you ever really use, you added only about five minutes of coding time to make the separation. But if someone within or outside your organization were ever to change their mind or have a different need at the same time, you’d have saved untold hours of development time and kept the code very neat, tidy, communicative, and easy to read and understand.
Another great way to support configuration is through a library such as Lightbend. It allows you to read from a local file or URL to get configuration settings. If you set this up from the beginning to allow many of your application features to be configurable, you can have different clients load their own settings, creating a very dynamic platform.
Application-Specific Services
In general, disallow the idea of “application-specific” services to creep into your vocabulary or engineering organization. I’ve seen teams far too many times assume that a service will only ever be used by the application or product whose inception first caused it to be written.
There is no real advantage other than the illusion of immediate convenience to defining something like an application-specific service. There is a certain hotel in Paris, the beautiful and artful Molitor, which actually started life as a community pool and not a hotel at all. The hotel was built around it later, and yet the community continues to use the pool today with no intention of staying at the hotel. Because the two services of the hotel and the pool are conceived independently, they can be managed separately with revenue recognized separately, or rolled up together, and the business model is more flexible. This is one way of seeing how the world reflects the advantages of not making too many assumptions.
A central tenet of deconstructive design is that we know that we don’t know how things will change and how people will want to use them in a changing world. The easiest way to make flexible, reusable, and easily maintained software is to not make any unnecessary assumptions about how things are yolked together. When you hear someone saying, “we know that no one will ever want to invoke this function outside of the context of this particular application,” that should send up red flags for you. Honestly, I don’t understand why people sometimes cling to this idea of “application-specific services.” It seems a necessarily arbitrary and unhelpful distinction.
If you think more generally, honoring the precepts discussed earlier, you’ll find that your product team is very happy with the many options for business capabilities you readily afford them.
Communicate Through Services
As in the famous Bezos memo of 2002, the way to achieve a fantastic platform is to ensure that all communication is done only through service interfaces. Services must own their own data. Other applications or services must not go through the “back door.” No team must ever read directly from another team (service)’s data store. Instead, they should go through the service interface. Do not allow teams to get another service’s data via direct linking, extended queries directly at the database level, shared memory, or vendor-specific data emulsion extensions.
Services own, and are responsible for, the data they have—the noun or function they represent in our domain. When a service is ready, all other applications should reuse it and not build their own that does the same thing, or with a slight variation.
This means that no two services in our domain should overlap and do the same job.
Expect Externalization
Throughout this book, I’ve begged for us to assume less in order to make better software. There is one case, however, for which making an assumption, or at least having a vague expectation, will do wonders for the robust resilience, performance, and scalability of your design. That is to expect that any service you write will be publicly available, externalized from your own organization and applications and used by other business units, and exposed out on the open internet.
Now there is a balance here of course. If for the near-term roadmap you have no reason to suppose that your service would be externalized, and you have a tight and hard deadline, it’s perhaps inappropriate to take the extra time to create a new public interface for your service, which would (as we discussed earlier) need to be separately built and deployed, and go through a perhaps cumbersome change request process and set up space in the DMZ and incur the cost of that compute and storage if no one is going to use it. The point is not to do all that, but do imagine that someone soon will ask you to do that, and that would cause you to do a few precautionary things first:
-
Ensure that you have a full set of security scans such as with a tool like Veracode. Running static scans and gaining insight from the reports on how you might accidentally be violating Open Web Application Security Project (OWASP) constraints is a rich source of data to help you prioritize security bugs lurking in your software and fix them now.
-
Ensure that you have properly designed your software to be scalable. Gaining data now by running load tests in automation regularly will give you a clear path for how far you would have to go make your service publicly available. If you imagine this scenario up front, you might take the time to design it more thoughtfully. Using just a few basic scaling techniques, such as asynchronous invocations, eventing, loose coupling, statelessness, and horizontal scalability up front can literally save your business and can help it prosper. Scaling means that the business can scale, too. It can become very expensive if you neglect to consider public-level scale. I have seen businesses that actually lost more money the more large customers they added because the services weren’t designed with big scale in mind, by which time it is too difficult to change. That’s the opposite of scaling a business. You don’t need to do more than is necessary; just consider these scalability techniques from the beginning, and then public or even global scale is much easier later. It’s mostly a matter of considering carefully how you manage state.
-
Carefully select how you address functions on the network.
Mostly what this means, though, is that you design for resilience.
Design for Resilience
Often when designing services, we consider only the Happy Path. That’s natural because the product team has described what it wants it to do, and so we go implement that. But we know things sometimes go awry, so we do logging and exception handling and monitoring.
The problem with doing only these things is that they don’t help the caller. In the case of logging and monitoring, we learn only after something blows up that it’s happened, and we rush onto a crit-sit call (or if it’s less severe, we put it on a priority list for later bug fixes). But we can do better and provide an answer to the customer now. We’re all accustomed to seeing 404 pages if we type a wrong URL. That’s better than nothing. But a 404 page that offers a search bar in it and a list of help topics is even better. In the event of a 500 Internal Server Error, a Bad Gateway error, a request timeout, or a rate limit violation, the improved response is not quite so clear. But we must consider those possible errors and design for them, just as we design the Happy Path.
A second point is that there is a spectrum here: things are not, in my mind anyway, totally up or totally down as much as they are functioning along a spectrum, across many different aspects of the system. We’re used to jumping if things are hard down. But many users experience very frustrating engagements with our software for a variety of reasons, including very long response times, or haphazard behavior, things that are not quite so readily identifiable as someone running through the halls screaming because the entire site is “hard down.”
Consider graceful degradation in your services up front, and throughout their life. Hystrix is a tool that was open-sourced by Netflix a few years ago and has been a good way to handle resilience features. But it required a lot of up-front configuration, which violates the deconstruction tenet of not trying to use a crystal ball to imagine every kind of failure and how it will happen and what the impact will be. So Hystrix is just in maintenance mode and no longer under active development. At the time of this writing, Netflix itself is moving toward a newer, more dynamic and lighter-weight framework suitable for functional programming called Resilience4j.
You can use a library like one of these, or roll your own, but either way, you must design for resilience, which means graceful degradation, compensation, and recovery. Your service functions and engineering team should have an answer for each one of these items in your services:
-
Where you will employ circuit breaking and how you will implement it? At heart, a Circuit Breaker pattern is essentially an implementation of the old Gang of Four Decorator pattern working with an Observable. The trick is not implementing the circuit breaker as much as it is determining the next-best state for your function to delegate to.
-
How you will allow rate limiting? This allows you to restrict the calling rate of some method to be not higher than two requests per second, for example. This is an important element in any service. If you think that your service is just to be used by internal customers and so you don’t need to consider rate limiting, I urge you to think again. Well-intentioned junior colleagues two cubicles over can accidentally launch a Denial of Service attack with a little improper loop logic that can flood or bring down your service. You won’t be able to responsibly plan for regular usage and future provisioning and costing if you don’t have a rate limiter in place for your services.
-
Bulkheading. This is related to rate limiting, but specifically restricts how many parallel invocations you will allow on a function at once.
-
Automatic retrying. If this request fails, can you automatically try again?
-
Response caching. We tend to think of caching strictly as a mechanism to improve performance. But it also can improve resilience. Caching in order to reuse a previous response for the same request is a great performance improvement and relieves pressure on the database, reduces network calls, and so forth. Caching responses as a resilience consideration is a powerful way to allow graceful degradation: think of how your application might answer user queries starting with “No, but...,” as in, “I can’t do exactly that right now because something is broken, but I can give you a related response to a similar question.”
-
Notification. Some companies have implemented a nice service wherein if you call into customer service and there are currently long wait times to speak with a representative, they can record your number in the system and call you back. Since HTTP/2 and WebSockets and push notifications and other advances in technology, websites and mobile apps can now do this, too. You can can implement a feature whereby there is no good cache and no good circuit breaker, but you can automatically call back the client later when you’re back up again. It’s not ideal of course, but it makes the customer feel more cared for than just blowing up in their lap with no clear next step.
The deconstruction tenet here is that exceptions are not exceptions. They happen all the time and the results of failures can obviously range from irritating to disastrous. If you treat the Happy Path as the privileged term and focus all your implementation effort there, and treat exceptions and failures as marginalized second-class citizens, they will eventually undermine you.
Adding these with a library such as Resilience4J will make your life, and your customers’ lives, so much easier.
Interactive Documentation
If you’re using RESTful services, publish Open API documentation (Swagger). The OpenAPI Specification was donated to the Linux Foundation in 2015. The specification creates a RESTful interface for easily developing and consuming an API by mapping all the resources and operations associated with it.
Doing this provides a variety of advantages:
-
It allows you to write a complete specification before you write any code.
-
It lets you visualize the operations in your APIs and allows internal developers and external consumers to quickly and confidently adopt your API.
-
It provides SDK and scaffolding generation.
-
It promotes test case automation by supporting response generation.
Also publish documentation guidance with your service so that others can use it without talking to you. We use services all the time on the web, and then when we turn around to make them, we forget our own personal experience and think we’re done when the code for the function is done.
Think of how you use something like Amazon S3. You don’t call Amazon and have meetings with them when you want to use Amazon S3; you just call the API. You can do that because AWS provides the documentation, examples, automated API keys and credential management, and other necessary functions to make this possible. That’s why it’s called a service. If you go to a taco stand and place your order and the guy at the counter invites you back into the kitchen to cook it yourself, that’s not food service, that’s outsourcing your kitchen.
As a rule, you should automatically add Swagger documentation to your services and publish them to a demo environment so that users can try them out interactively and see how to use them without hurting themselves or you. This will also help ensure strong contracts and efficient communications between your internal teams. Minimize the communication necessary to achieve this by automatically publishing the documentation at build time and deploying it as a step in your pipeline.
At a minimum, use GitHub as a model and publish Markdown describing your service with the service (not on some remote wiki). If you use Java and Maven, it’s a step up to use the Maven HTML site generator for each service with the Site Plugin. This will just put the documentation in the site folder, so make sure to include Wagon or another tool to then post your documentation to the proper public repository. This should be automated and easy given that your services are independently buildable and deployable.
Anatomy of a Service
There are a few basic kinds of services my teams and I find helpful.
The overarching rule is that services must have high cohesion, so each one represents one important noun in the domain or performs only one meaningful action. A service API can have many functions, but they should all be related around a single idea from the domain perspective.
UI Packages
The UI package is a service with the single job of displaying information to users and providing a means of input and user interaction. These services can be put together with building blocks of UI widgets or reusable UI components that can invoke orchestration services in their own process. For example, if you have a shopping service that returns a list of offers that a customer can pick from, you might want a corresponding Shopping UI widget in your JavaScript framework so that you can reuse it across various channels such as your public website or your onsite application for store employees as well as your voice agent call-in channel application. Your UI package service then becomes a collection of such reusable widgets.
Orchestrations
The UI package widgets will likely invoke the second layer of services, which are orchestrations. Orchestrations have the single purpose of representing a workflow and managing state for the end user. They should be designed from a business perspective. These services are called orchestrations because they are like the conductor in an orchestra who doesn’t play an instrument but pulls together all the different individual players to make a coherent whole. Orchestrations just perform the job of combining others that actually do the work (these we call engines, which we look at in a moment).
If you have a user experience (UX) team or knowledgeable product managers, work closely with them to determine the best workflow for a particular use case and map it out on a whiteboard or with a tool like Balsamiq so that it’s easy to change. Using Design Thinking techniques discussed earlier will help ensure that your workflow makes the most sense to your users: it’s very important to design workflows from the outside in or top down. Resist the temptation to start from code (bottom up). This will have the effect of dumping the database out onto your user. You want to be user-goal-oriented here, constantly asking yourself what the thing of value that the user is trying to do is, and how you help them achieve it most effortlessly.
Here are some guidelines for considering how to create your orchestration services:
-
Start with a clear definition of the user goal.
-
Consider this particular workflow at the same time that you consider a variety of related workflows so that you’re taking the holistic view and placing tasks where they best belong, not only for this particular goal, but in relation to all the things a user will want to do in your application. It’s crucial here to recall our theme of the importance of naming and the importance of picking the right levels of abstraction as you work with your concept. For example, you could decide that you have one user goal to Add Products and a second one to Edit Products and then create two workflows. This would be obvious and seems reasonable enough. But if you decided that, at a higher level of abstraction, the user wants to “Work with Products,” you might have a single display that lets them do both of those things that is more convenient, obvious, and less mentally taxing and time consuming for your user. This might make your design work more complex, but again the point is to keep it simple for your user, not necessarily for yourself.
-
Orchestrations might be step by step or rules driven. It’s probably easiest to start with the step-by-step process, but then to use that only as a starting point or input to a second round of refinements to discover if and how you should combine workflows. This will also reveal some complexities that might suggest to you that a rules-driven workflow approach makes the most sense here. Consider the tax application TurboTax. This is a rules-driven workflow. Although the goal is to get your taxes filed, it’s great software because the user input values might trigger different rules that show different screens. It’s nonlinear. It’s convenient for engineers to think in simple, linear, step-by-step processes, but this is rarely what’s best for a user.
-
Do not start with UI design here. This is a common mistake. You define your end goal, and a logical starting place based on the minimum amount of information a user needs to have to start achieving that goal. Then, fill in the necessary steps in between. The naive, or hasty, approach is to then make each one of those steps a screen. If your goal is to minimize friction or time-on-task for the user, they will be happier. So you have a prior step of conceptualizing the best way to design the UX after you have the clear goal and set of steps.
-
Mark clearly which steps are required and which are optional. Ask yourself how you can make the easy things easy and the difficult things possible. This is a hallmark of good workflow design. Doing this requires that you consider, as we do in deconstruction, the multitude of user personas: there is no such thing as “the user.” There are users in extremes: the three year old and the grandmother; the casual user and the one for whom it is mission critical; novices and power users; and users who need it heavily for a short period of time and then might not come back to it for several months. Look at your workflow through all of these lenses in order to determine the best way to conceive of the steps and screens (or voice commands).
-
Highlight any dependencies: what steps can be done at any point, and what steps absolutely require something prior to be done?
-
In deconstruction design, we always consider the opposite as early as possible, to free ourselves from unwarranted assumptions and do something delightful and innovative. Ask yourself what the world would look like if you didn’t have this workflow at all. Is that possible? How can you eliminate it altogether? What would have to be the case for you to do that and save your user all the time? Perhaps you can’t eliminate it altogether, but putting your team through this exercise will likely help you come up with ways in which you can simplify things for them. An obvious answer is how you can use automation, previously collected data, or a machine learning recommender engine to prepopulate as much as possible by guessing what the user would want to do. Then, if 7 times out of 10 they are just approving and going to the next step, you’ve saved them a lot of time.
-
Make sure that every task is rigorously defined in this one structure: verb/noun. The user is doing something to or with something. The task might be “Search Songs” or “Pick Room.”
-
Be sure to include the exceptions in your workflows, and not only the Happy Path.
As you draw out your workflow, you can use a tool such as SmartDraw to make sure you are defining the flow based around user goals and tasks before jumping into the UI design; they’re separate matters.
Engines
A third type of service we might call the engine. These are the services that do the work. They perform calculations, execute algorithms on data, run searches, invoke data services to persist changes, and save state.
When you design your engines, make sure they do one thing only. The engine might represent the Profile Persona service, the Offers service, the Cart service, or the Ordering service. Shopping and ordering are two different things, which we can know for certain by observing the world. Out walking around in the world, we can shop without buying anything. We might shop, take a rain check, and save this and submit it for ordering later without shopping again. Therefore, we know for certain that these are two distinct ideas, and should be two different services.
Separating ideas like this encourages you to make strong interfaces. We can see in that previous example that if we can place an order without shopping, as long as we have a well-formed order slip, that input to the Ordering service can be generated by a variety of possible other services or systems. The message can be created from the Cart service during checkout for a typical ecommerce flow, or generated by a third-party business partner channel, or by a voice agent. Keeping things well defined in this way is the best thing you can do to make your services portable. Because we know that we don’t know what the new business direction will be, portability is important. New executives come in and change direction, the cloud gets invented, car consoles get invented, NoSQL databases come on the scene and are initially fantastic and then get taken over by corporations that squeeze you for money and there’s pressure to switch. We know how this all goes. Making sure your services feature high cohesion and loose coupling is the best thing you can do to keep your business nimble and cost efficient.
Make engines stateless
As much as possible, engines should be stateless. This is generally an impossible goal given that the whole point of any software is to modify the state of some representation.
What you can do is to disallow developers from writing to a server’s local filesystem. Application developers should not implement code that allows users or systems to upload or transfer objects for storage on any server’s local filesystem. Doing so would create servers that hold state and are not automatically replicated. State MUST be held only by databases or specified object storage systems. Otherwise, the overall system’s resilience would be compromised.
System designers and developers should make local choices that support stateless interactions across use cases, anticipating that web and application servers will randomly fail partially or completely at any time; the system’s resilience design should support this.
Scaling engines
A primary goal in designing engines should be their scalability. The most inexpensive and quickest way to scale is horizontally, which means that you can replicate, as if off a conveyor belt, many exact duplicates of your services and deploy them alongside one another. These nodes are just some drone army that are indistinguishable from one another. You then have a set of load balancers send requests to servers with available capacity to do the work. Cloud providers let us define autoscaling groups, so that we can define triggers for specific thresholds to deploy a new copy of the service, add it to the load-balancer pool, and let it begin accepting requests. Then they can automatically scale back down again when demand is reduced in order to save costs.
You can’t do that when vertically scaling—adding more hardware capacity in terms of memory or processor power to the same service instance. This often requires approvals in a lengthy provisioning process, ordering new hardware, adding it to the available capacity, and making many potentially dangerous network changes. You therefore need to vertically scale months in advance of when you might actually need the additional capacity. In short, vertical scaling is not transparent and as fluid with your business in the way that horizontal scaling is. So horizontal scaling is far more preferable. It requires that you design your services thoughtfully around how you hold state, how much work you make each service do, and at what point in your design you do what work.
You must design your services to horizontally scale at the service level. That is, you don’t scale your entire application set at once. You might have a web server farm that is performing just fine, but the shopping engine services running your .NET code are performing complex calculations that take 200 ms and so you need to scale out only those nodes without adding any more web server nodes.
You can then allow your load balancers to execute the simplest round-robin algorithm to select which service it directs the request to. Of course depending on your load-balancing hardware or software, you can select more sophisticated algorithms that direct requests based on actual server capacity at that moment.
Every engine must have defined scale goals and clear current scale ceilings. These metrics should be expressed only in math and never in any other way. I have heard very senior folks in different organizations talk about whether the service is “scalable,” or claim that their service is “scalable.” This is nonsense, absolute fiddlesticks. It doesn’t even mean anything at all to say that. In the case of expressing scalability, there is only math representing the current ceiling, and the math structured the same way that represents the scalability goal (if they’re different). Scalability means that you can perform the same under additional load. This obviously means that you need to know what acceptable performance is, stated in terms of response time to the user, and then under what load. It’s obvious then how to represent scalability; state it like this in your design documents:
For 500 concurrent users, the response time to the end user agent will be under 2 seconds 80% of the time, 2 to 4 seconds 19% of the time, and 4 seconds or greater 1% of the time.
Change the numbers, of course, as you need for your business, but the structure of the sentence should be the same. But let’s unpack this a bit more. Notice that we state “to the end user agent.” That could mean the browser. This is differentiating because first, it’s user oriented, which we love; second, it’s clear. I have seen vice presidents argue vehemently over this because they weren’t clear on this precise point: response time to where? The engineering guy would proclaim he was within his SLA because the service responded to the load balancer in under two seconds, and the product guy would proclaim that doesn’t matter to the end user because they see the result several seconds later. Then, engineering claims that’s the network and the Wild West of the internet over which they have no control, and so forth. You can see where that goes: nowhere good. So if you do elect to define “at the end user agent,” you need to know how you will measure that consistently and store that data to track it, which is a great idea. It also means that you would need to carefully consider holistically all of the components in the stack for that service request, including the load balancer, the edge cache, the network, and your datacenter regions. You might then restate your goal as “in Europe” and have a different goal for “in the US.”
The best thing here is to, within your budget and timeline as appropriate, do the best job by your users. Don’t use this scalability sentence structure to “game the system” and look good in your metrics because of the fine print. People see through that pretty quickly and it doesn’t truly help your business. Instead, make aggressive goals and use them as a statement of work for yourself to examine and improve the different parts of your stack.
First, you need to have an understanding of your customer base. How many people are using it concurrently? What is the response time they require? What response time would delight them while still being cost effective for your business?
You then would need to have in place a good load test using a tool such as Selenium. But then you also would need to run that load test regularly, which would mean that you need to automate the execution and reporting of the load test results. You want to do this throughout development so that you can quickly spot which additional features or implementations affected your results. This means that you want to set up your load testing as early as possible and launch it even against your initial hello world engines. It’s a lot of effort to define and run and report load tests, and so putting this work up front instead of at the end means that you will get to do it many, many times before you actually go live, and so you’ll have a very clear understanding of your application when you need to most.
To state your scalability goals, you follow the same structure, but using the future tense. Now, you have a goal that’s measurable and testable, and you can show your success and be prepared if things begin trending downward.
High-Scalability Case Studies
There’s a website that’s been around for many years now that hosts case studies by different companies on how they scaled their systems. It’s called HighScalability.com and it hosts a section on “Real Life Architectures,” featuring articles about how the usual suspect companies like Netflix, Amazon, Twitter, and Uber faced certain scaling challenges and how they designed to scale better.
Another good way to scale engines is to consider where you can do work asynchronously (discussed in a moment). Again, this is more difficult for us because it makes things more complex, but it’s better for the end user in terms of performance.
Serverless
Serverless functions such as AWS Lambda, Microsoft Azure Functions, and Google Functions can also serve as a backbone for some of your engines, but you should employ these with caution. Recall that the person who invented the ship also invented the shipwreck. No benefit is free, and the cost of the convenience and scalability that serverless provides comes in the form of challenges in monitoring and permissions management, general confusion, and difficulties for team development.
Teams need to experiment, to try to test things. This is very easy to do with serverless. But you must make sure that testing a function in this way does not inadvertently cause you to forego the design process of considering whether serverless is really the best place for that function in your overall design.
The confusion comes in because until serverless matures, it remains a rather opaque part of your stack. You can use tools such as XRay in AWS to help understand the general metrics, but it can be difficult to integrate these with other monitoring tools your organization might have as standards, making it difficult to trace and piece together the overall behavior. There are other tools that you can employ such as IOPipe and Epsagon that might be of use in improving your observability.
The takeaway on serverless for now is that it will add considerable complexity to your architecture: everything is a trade-off and there are no silver bullets. So as you grow your serverless footprint, you will find a proliferation of satellite tools creeping into your stack like weeds, accidentally changing the landscape of your architecture. No tool solves everything for you. Considering up front how you are going to handle all the good old-fashioned concerns that you will always need to account for, including availability, monitorability, manageability, scalability, performance, cost, and security, is paramount.
Any time you go to use a new tool, remember that you still have all those concerns to account for, and imagine a kind of scorecard. Where one tool succeeds, another might stumble. This will help you to make the requisite trade-offs more purposefully.
Data Accessors
All data access must be through service APIs. These services are called Data Accessors. Data Accessor services are invoked by engines and interact with the data store for the engines to do the work.
We examine those more in detail in Chapter 8 because they’re a big topic on their own. I mentioned them here solely for completeness. For now, just know that there are services called Data Accessors and they are distinct services from engines.
Eventing
The most basic form of asynchronous processing is publisher/subscriber, or pub/sub. One component, the event producer, publishes an event to a queue or topic. A queue, here, stores that event and allows it to be read asynchronously by a single separate second component (the subscriber). A topic is like a queue that allows multiple subscribers to pick up the event.
The idea of publishing events to topics is a crucial one in deconstructed design. Fundamentally, the fact that there are multiple event subscribers, and they are free to come and go (subscribe and unsubscribe), free to process the event in their own time, in some way unbeknownst to the event producer, is a perfect vehicle for many of the concepts we’re working with. Because we know that we don’t know what something will mean, because we know that we don’t know the “correct” response (or assume that there is only one of them), and because we want to design systems to be incredibly scalable, pub/sub eventing fits the bill perfectly. It’s the architectural choice that makes the fewest assumptions about the world. It allows you the most scalability, flexibility, extensibility, loose coupling, and portability.
At the heart of this pattern is the event. Every event should be represented with the same idea: that there is a state change that just happened to this noun in the immediate past. In the hotel domain, for instance, you could conceive that “Guest Checked Out” is an important event. Others might be “Order Placed” or “Reservation Cancelled.” Notice that any human being who has ever stayed in a hotel is likely aware of these events. That’s the appropriate level for now: nontechnical, business oriented. Just take a few minutes to list out what some of the major and obvious events are in your domain.
When performing your domain analysis and representing your set of services as we discussed earlier in this chapter, take another pass through that work, viewing it through the lens of events. Examine each of your services and the ideas in your domain model and ask which of them can benefit from an event pattern. Just as you examined the domain model to ask how the verbs and nouns interact, consider too which services have strong associations with the events you have listed. This will lead you to some clear places where you can take advantage of events for the things they’re best at: loose coupling, perceived performance, scalability, extensibility, and portability.
Because managers run the orchestration of services, it is best to have the manager emit the significant events. The manager service places an event on a pub/sub topic so that multiple subscribers can respond, as shown in Figure 7-2.
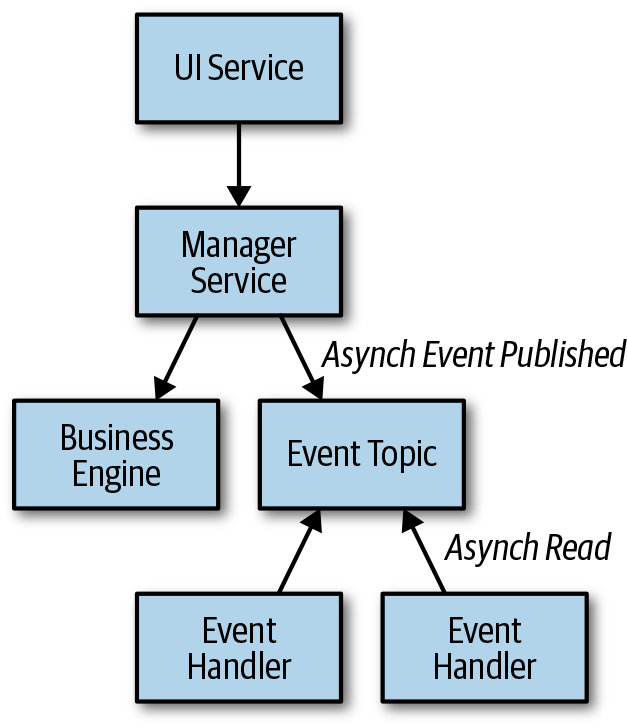
Figure 7-2. The basic anatomy of asynchronous service components
Managers should own their events, such that no other manager or subsystem should produce the same type of event. The Event Handler is an interface that listens to a topic to read events it subscribes to, performing filtering as necessary.
For all the benefits in perceived performance and scalability that pub/sub brings, after you have created a number of event producers and subscribers, it can be confusing to know exactly how your system is working. Before you create too many of these, it is therefore a good idea to create a master index file of all known event types and which orchestration services publish them. This is documentation, and not necessarily a central online registry. This will help teams know which events are already being generated, such that you might be able to easily add extensibility and customer customizations to your system by adding another subscriber to an existing event. This is one reason why it is best to start out with what in JMS is called a Topic (which allows multiple subscribers) rather than a Queue, which is a one-to-one publisher/subscriber mechanism.
Events should be lightweight messages that should not contain a copy of the complete current state. Instead, events should contain their header or metadata information and a reference ID that they can use to access a copy of the complete information should they require it. The Claim Check pattern is helpful here to get the current state from the system of record. Using this pattern prevents you from inadvertently “leaking” the system of record out into the many provinces of a complex system, maintaining the integrity of each service. It also means that you can maintain a tighter security boundary to help maintain compliance with the General Data Protection Regulation (GDPR) as well as Payment Card Industry (PCI), Personally Identifiable Information (PII), Service Organization Control 2 (SOC 2), and other important data privacy and security restrictions.
Enterprise Integration Patterns
A very helpful and informative book on integration patterns is Gregor Hohpe and Bobby Woolf’s Enterprise Integration Patterns. For more sophisticated interactions, you will find places to perform a Scatter-Gather or use Claim Check (these are patterns in the book that are overviewed on the website). It’s many years old now, and newer tools such as Apache Camel have been built using the patterns so you don’t need to implement them all from scratch. But much of the book is still quite relevant. It’s an excellent reference.
Asynchronous calls are wonderful, but use them wisely. You do not want to use asynchronous calls every place possible, for a few reasons:
-
First, they come with a cost of complexity. You need to create more infrastructure to support asynchronous systems like pub/sub.
-
More infrastructure can mean more cost.
-
You also will have a harder time monitoring and tracing requests through those systems after they are in place.
Many teams will default to simply assuming everything is synchronous because that’s by far the easier thing to implement. Be thoughtful and specific about where to use synchronous calls given the use case and your scalability needs. If your use case allows for a short time between interactions, you should almost certainly use asynchronous processing. For example, if the user places an order and then an email confirmation is required, the notification to the email system and then the sending of the email itself should occur in separate processes. Some use cases, such as this one, are obvious, to make the point.
There are some that are less obvious. If you need to scale to many thousands of requests per second, you might find even asynchronous queues for shopping read requests are valuable.
Structure of an Event Message
Every single event in your system should be structured in the same way to ensure that you capture everything consistently for processing. Table 7-1 shows an example.
| Attribute | Data type | Req’d | Description | Example |
|---|---|---|---|---|
|
|
String | Y |
Code that identifies the type of event |
ProfileModified, OrderCreated |
EventID |
String | Y |
Unique identifier for every event |
[UUID] |
CorrelationID |
String | N |
Identifier for finding relation to another event ID |
[UUID] |
Timestamp |
TS | Y | When the event was created |
03/27/2020 17:15:00Z00 |
EventContext |
Map | N |
Set of key/value pairs with context data specific to the event type |
ProfileID:1148652 |
EventName |
Structured String | Y |
The resource name, fully qualified and discoverable |
[discoverable address name] |
Make the UUIDs strings instead of native language UUID types for interoperability between services. After the translations happen in and out of the database and across service implementations in .NET, Java, and Python, you will wish they were strings.
In conclusion, use eventing liberally, but of course thoughtfully. We default to synchronous request/response models, as if we know the meaning, we know what should always happen. Instead, foreground asynchronous. This improves scalability and description of the system. But it also does something for you where you don’t need to decide the meaning: you allow the “import” of the event to be deferred. This is powerful because the business changes its mind frequently, the system evolves, different customers need different things, and things means something different to diverse audiences. Any reaction in your application should not be hardcoded. Use event handlers instead. This helps you model services as contextual agents, not static and predetermined and fixed essences. It’s a key tenet of deconstructed design.
Contextual Services and Service Mixins
When you design with eventing foremost in your mind, we tend to make things far more flexible and yet more solid. It pulls you away from obvious and wrong ideas, such that there could be the One True “Customer Profile" service to rule them all. Customers, products, all the things in this glorious and rich world are multi-dimensional and varied. When we try to lock them down we quickly are forced to make false statements about them in how we represent them in our classes, and this is where the trouble begins.
Consider the traveler. You have likely traveled many places for many reasons in your life. We can consider that we might go on a leisure trip with our sweethearts, and also go on a business trip with our colleagues. If we as service designers decide that there is a single profile for a person, we will be painted into a corner. For instance, if you book a room for two nights on a Tuesday for one person, we can assume that is business travel, whereas we might well assume that a booking for two people on a Friday is leisure. And perhaps they are. But the context here is king. The same traveler could (and frequently does) book both these trips, but have entirely different reasons for them.
The temptation, of course, is to continuously add to the same one Traveler or Customer table or the same one Product table, with their encompassing services becoming ever larger and more complex Swiss Army knives to try to support all these different use cases. In this model, different services will all put pressure on the same one bottleneck, and find it confusing to wade through dozens of optional input and output fields that only make sense in certain use cases. You eventually need to have a very complex rubric to understand how to make proper requests of such services. Instead, we want to take that rubric as metadata or documentation and break it out into actual functions on separate service implementations. To embrace this concept, we might call this manner of writing services “service mixins” or “contextual services.”
We do not define services in accordance with a unifying idea of the single Grand Narrative. Doing so would mean participating in perhaps not quite a fantasy, but a limited view that will have serious and costly ramifications for extensibility, and portability.
Instead, we ask what use cases this entity participates in, and in what contexts the entity might be required to store or share information. We might discover smaller, more specific related Personae services, wherein the single person with one tax ID has many different relevant modes of being in the world, and appears differently in your system in different contexts. Designing for that multiplicity will aggregate nuances that improve the richness of the system.
For example, instead of storing one single unified Traveler service, you might have a Business Traveler and a Leisure Traveler and a Bleisure Traveler service, all relating to the same unique identifier for the same individual actual human, but capable of recognizing that in different contexts the same person will have different needs and desires for communication, notifications, recommendations, and the relevant attributes that support those.
You might have a variety of brands in your company portfolio that cater to the economy segment and the luxury segment. You might have customers that plot against a 2x2 matrix of income level (low to high) and spend level (low to high).
Consider the way that, say, an unsupervised machine learning system will determine customer clusters based on runtime or historical behavior. You can use these ideas, or even the actual cluster results to help inform if not drive the design of your services.
Clustering
Clustering is an unsupervised machine learning technique. There are no defined dependent and independent variables that anchor the data. Instead, the patterns observed in the data are used to identify and then group similar data points into clusters.
In this way, we can design much richer, more targeted and helpful business systems. If you are in a modernization or digital transformation effort, in which you have the luxury of a strong historical understanding of your business, your customers, and your systems, consider using machine learning principles such as these to actually help define your modernized system. You might call this machine learning–driven design.
Performance Improvement Checklist
There are a few simple things that you can do to improve performance in your web applications. Hopefully, you do all this already and it’s obvious to everyone. I wish it were. I list them here for you as a kind of helpful checklist. They are general rules of thumb that you should always tick through; make sure they find their way into the Acceptance Criteria of your user stories.
-
On web APIs, collections must provide filtering, sorting, field selection, and paging to keep performance tight.
-
Use GZip compression. Add this configuration to your web server to enable it, and browsers that advertise that they accept GZip encoding in the request header will be sent the compressed version. This can save up to 70% of the response file size, reducing the time to return the response and reducing your network bill.
-
Combine and minify both CSS and JavaScript files. Instead of forcing the browser to make multiple network requests to many CSS files and many JavaScript files, use a tool to combine your JavaScript into one file and then minify it. Check out JSCompress, Gulp, Webpack, Blendid, or any others that might serve your purposes best.
-
Ensure that your image files are the same size as your <div> display containers. Do not rely on the browser to crop large images while needlessly sending and processing a lot of bytes that it will just throw away.
-
Tune your database. First, use indexes. If you are using a relational database and have columns listed in a WHERE, ORDER BY, or GROUP BY query, they should all be indexed and those indexes should be regularly rebuilt on a scheduled job. Second, run EXPLAIN to understand where the bottlenecks are in your database queries. Third, be sure that you do not have very long queries and queries with many joins. If you have more than just a few joins and that query is executed frequently, you should revisit that design. Fourth, denormalize data as necessary and have the data act as a kind of side car to the “System of Record” tables. Finally, move things up into a distributed cache.
-
Use a Content Delivery Network (CDN) like Akamai or AWS CloudFront to deliver your media. The fastest responding system is the one that’s never actually hit. That’s true for web servers as well as databases.
Again, we’re not trying to capture all the things you can do for performance tuning. That’s a whole (very long) book. Of course you need to design your system properly, use the right level and type of hardware, and so on. If you don’t do those things, adding CSS minification certainly won’t save you. These are just a few simple, obvious, easy, low-hanging-fruit type things to do. If you do just these and little else on top of an otherwise solid design, they’ll get you a great head start.
Separating API from Implementation
Often, teams know that they should separate the API from the implementation. In rushing to meet an aggressive deadline, they might simply create an interface and then implement it in a class in the same package. This also becomes a habit because, if you’re using .NET or Java, those languages provide the interfaces in the same package as the implementations. For example, List (the interface) and ArrayList (the implementation of List) are both in java.util. Of course, we are free to create our own implementation of List in our own package, so it makes perfect sense here. But this acts as a silent teacher that can prevent us from seeing a practical extensibility and portability advantage we could gain by more cleanly separating them.
When you design your system, put the interfaces for a subsystem together in a package, and then make that its own buildable JAR or binary. Then, create a second, separate project with that binary as a dependency and put your implementation there. What you’re doing is not assuming that your first implementation is the One True Light and The Way. Rather, you are assuming that this is one possible implementation of many. If you do this at the beginning of your project, it takes literally five minutes. And it opens the door to incredible extensibility for customers and other teams. Your service code remains mostly empty, with little real “business logic,” which is in the implementation. Your code becomes an empty container, the possibility for that business logic to be executed.
The model here is the set of interfaces that support Java Database Connectivity (JDBC). These ship with Java but do no work. The database vendors such as Oracle, Microsoft, and open source projects then create their own database drivers that know how to communicate with their specific databases. But they allow you as a developer to switch between database vendors without changing the interface. So you must have the class implementation binary on your classpath, and that binary should be a separate artifact. I’m suggesting to do the same thing up one level further, too, with your engine implementations.
Following this model will prove to be an incredible time saver later when a customer wants to do it their own way, when another team wants to reuse the system shell for their own purposes, when you need to port to another platform or provider, or when you need to make a significant version upgrade. It will allow for wonderful extensibility, helping turn your regular application into a true platform that supports multiple implementations.
If you are writing in an interpreted language such as Python, you can still do this. Python has duck typing (you can pass a walrus for a duck as long as it’s a quacking walrus) and as of Python 3 you can use Abstract Base Classes using the @abc.abstractmethod annotation and put these definitions in separate folders and packages from the implementations. Then, customers or other teams can provide their implementations that adhere to the same interface.
Languages
You might have more customers in Europe than North America, and APAC might be your fastest growing region. You might have a strong customer base in South America. You might be entirely run in London with no plans to expand beyond Brighton, but consider the multitude of languages, cultures, and diverse people in the world. English is only one language among many hundreds. When we default our application to English, and then later our Chief Strategy Officer wants to enter the Cuban market, we have to create a multimillion-dollar project that could have been free. Here are a few simple design rules of thumb for applications and services:
-
Externalize all strings from your code so that internationalization and localization is made easier. You might exempt logged strings from this because it becomes overbearing and hopefully no one but you is reading your logs. These strings can be externalized in resource bundles, in the database, or in text files.
-
For multiple languages, you can use an external service such as translations.com. That can get expensive depending on how much you use it. You can do a poor-person’s version of this using the terrific translate.google.com service to start to get an idea of your key/value translations and test it to make sure that it’s working properly. At the most rudimentary level, you’re looking for a few basic things:
-
When you specify another language, does it appear?
-
Are you using UTF-8 in your application code, database, and accept headers, so that non-Latin characters display properly, such as when you need to represent the German “Straßenbahn” or the French “ça va”?
-
Are you able to fully represent double-byte character sets, such as Mandarin, Japanese, and Korean?
-
Are you able to represent right-to-left languages such as Hebrew and Arabic?
-
-
Are you handling currency conversion properly? You can easily get a download once per day from Bloomberg or xe.com for current currency conversion rates. You must also handle the display of the currency properly (using dots and commas properly for the different locales, and so forth).
Use the Google Translate service to get a few strings of each of the kinds listed above, and test your user interface labels with each of the different locales.
Every service should have three clear, named owners: when you list the services in your service catalog, associate the business owner (the VP of product management for that area), the engineering leader, and the associated architect expert. Maintaining such a map of your service catalog will be valuable.
Don’t go overboard if you truly have zero customers from anywhere else in the world other than your neighborhood, and zero plans to ever get any. But doing just these few things now will set you up for a very well-designed system that will serve you well in an increasingly global commercial world.
Radical Immutability
As we create software in our development environment we must be sure that everything compiles and runs, and so we have references to what works and is allowed in development. These variables comprise database connection strings, caching locations, service endpoints, passwords, filesystem references, dependencies, and so forth. At worst, we write all of these references directly into the code and then make it someone else’s problem, such as a release engineering or release management team.
They might then have tools that rebuild your software after rewriting these strings, which can be a manual or automated process. If you have seen such processes fail catastrophically as I have, you step back and consider how this could have happened. The real question is, given all the many variables and considerable differences in environments about which we maintain a pretense of sameness, why doesn’t this happen more often?
We comfort ourselves that we have externalized our encrypted passwords and endpoint URIs and use an automated tool to rewrite these files as we deploy on through to certification, user acceptance testing, and production. We assume or hope that the binary artifact moving through these environments, which is getting rebuilt each time, is somehow the same. It is not.
This process is rife with opportunity for failure. This is a wonderful place for entropy to set it. There are small, barely noticeable changes that can offset the environment just enough to, when taken altogether, create a very different runtime than what we tested. Thus is the origin of the phrase “it works on my machine.”
I wouldn’t bother making this point except that in my 20-plus years in this business I have heard numerous developers say those words with apparent lack of any irony, as if that closes the case. Thus, the equation goes: it works on my machine == it works == no problem || someone else’s problem.
We want to avoid this confrontation, avoid problems in certification and User Acceptance Testing (UAT) and production, and have more assurance that our artifact will behave predictably. When you test and certify something, and then redo it, your test and certification are both invalidated, obviously. Yet we often behave as if this were perfectly normal, or acceptable, or perhaps we’re aware that it’s nonoptimal but shrug in conclusion, “Well, what’s a developer to do?”
Seek as much immutability in your design as you can. You minimize what you have to change if you design the change in. Instead of kicking the can down the road to this broken process, design your system as if it were a series of references to many varied and wild outside things.
The binary artifact you build must be as close as possible to what is tested, certified, and deployed to production. The way to do that is to never rebuild it: what you build in development is the same binary that is deployed in production. The only way to achieve that is to externalize every reference. Your software becomes smaller, does less, and becomes rather more like a schedule of references to external references. This means that your software is not the thing that does all the work; it is rather like a bill of lading. It’s a receipt list of packages. It does little, and looks more like a list of references to things it otherwise has little awareness of. Invert your software by extending the idea of dependency injection into more aggressive, radical territory.
One approach is to match your development environment as closely as possible to your production environment. Using containers such as Docker or a virtual box such as Vagrant helps with this.
An important element in this process is to use a universal package manager. Treat your own code as if it were not the center of the universe with some ancillary dependencies, but rather one element, flat alongside the dependencies. The role of your code is to pull them all together. Here are some of the commercial and open source tools from which you might benefit:
-
Apache Archiva (this has not been updated in a while, but it’s venerable, works, and is free)
Of course, this also means that you must use the same process to deploy the software across all environments. You must not have different deployment pipelines, and just as your deployment pipeline is software, too, you want to be sure to externalize strings and related references there, such that deploying to the QA environment versus the staging environment is a simple matter of changing a target name.
Another benefit of this radical configurability is that you get improved portability. It’s easier to move from one cloud provider to another, for example.
If you have problems with them at runtime, they are easily visible, and easily updated without a rebuild and redeploy process.
Specifications
Martin Fowler and Eric Evans invented a wonderful way to implement the frequently needed use case of searching for objects from a catalog that match certain criteria. For example, in an ecommerce application, you likely need to allow users to state their filtering or search criteria, and your code needs a fast and loosely coupled way to respond to the query. You might also need to validate a candidate list of objects to ensure that they are suitable for the task at hand. This is where the Specification pattern comes in. It is based on the real-world idea of shipping cargo and the separation of concerns of objects that get picked from the contractors doing the picking.
Original Specification Paper
You can read the original Specification pattern paper published in ACM here. The pattern is based (again, as so many good things are) on the crucial Gang of Four Strategy pattern. A more dynamic and sophisticated, but slower, version relies on a combination of Strategy and Interpreter. This paper goes into far more detail, variations, and applications than we do here.
Upon consideration, you can see that there are many applications for this pattern, beyond the ecommerce product filter/criteria search. These might include a set of candidate routes that an airline might propose to get travelers connecting flights from one city to another, or the right set of containers for certain kinds of products based on their size, whether or not they are perishable, or fragile, and so forth. Though it’s a bit abstract, I like to think of the Specification pattern as kind of related to the more mathematical Knapsack problem.
To realize the pattern, you create a specification that is able to determine whether a candidate object (such as a product in a catalog) matches some criteria. The specification features a method isSatisfiedBy(someObject) : Boolean, which returns true if all criteria are met by someObject. The important move in the Specification pattern is that you are treating the specification as a separate object from the candidate domain objects that use it. You create the search criteria independently and let the domain object inform you as to whether it satisfies them.
As usual, we want to start our design from the outside in. We want to write the dream client that we wish we could have, and then fill in the code that makes that client possible.
Consider a proposed use case from the travel domain. A guest wants to search for a hotel room based on criteria she specifies. She wants a hotel room that costs less than $800 with a size of at least 22 square feet that has an ocean view. We want a readable, maintainable, flexible, business-oriented client for our room finder service that might look like Example 7-1.
Example 7-1. Criteria client search
Criteria criteria = new RoomSearchCriteriaBuilder() .withPrice().being(lessThan).value(800).and() .withSquareMeters().being(largerThan).value(22).and() .withView().being(View.OCEAN).build(); List<HotelRoom> allRooms = ProductRepository.getRooms(); List<HotelRoom> matchingRooms = new ArrayList<HotelRoom>(); for (HotelRoom room : allRooms) if room.satisfies(criteria); matchingRooms.add(room);
This code builds a criteria based on the supplied user parameters and then searches the hotel for rooms that match those three criteria. Matches are then added to a results list to be passed back up to the user.
So we need a few classes to satisfy this dream client. As demonstrated in Example 7-2, first, we’ll make a Product interface and a HotelRoom implementation (this is just close/pseudocode to give you the implementation idea, it’s not meant to be perfect).
Example 7-2. Product basics
class Product {
double price;
public boolean satisfies(SearchCriteria criteria){
return criteria.isSatisifiedBy(this);
}
}
class HotelRoom extends Product {
int squareFeet;
View view;
}
enum View { GARDEN, CITY, OCEAN }
We also then must define our Criteria classes, as shown in Example 7-3.
Example 7-3. Search criteria listings
public interface SearchCriteria {
boolean isSatisfiedBy(Product product);
}
public class Criteria implements SearchCriteria {
private List<SearchCriteria> criteria;
public Criteria(List<SearchCriterion> criteria) {
this.criteria = criteria;
}
public boolean isSatisfiedBy(Product product)() {
Iterator<Criteria> it = criteria.iterator();
while(it.hasNext()) {
if(!it.next().isSatisfiedBy(product))
return false;
}
return true:
}
}
public class PriceCriterion implements SearchCriteria {
public PriceCriterion(Operator operator, double target){
//
}
public boolean isSatisfiedBy (Product product){
//do price check
}
}
Now we need to fill out the builders and connectors that are similar to what would be part of any Fluent API following the Builder pattern, as illustrated in Example 7-4.
Example 7-4. Builders
public class SearchCriteriaBuilder {
List<SearchCriteron> criteria = new ArrayList<>();
private PriceCriteriaBuilder priceCriteriaBuilder;
public PriceCriteriaBuilder withPrice() {
if(priceCriteriaBuilder == null)
priceCriteriaBuilder = new PriceCriteriaBuilder();
return priceCriteriaBuilder;
}
public PriceCriteriaBuilder and() {
return this;
}
public SearchCritera build() {
return new Criteria(criteria);
}
public PriceCriteriaBuilder {
Operator operator;
double desiredPrice;
public enum Operator { lessThan, equal, largerThan }
}
public PriceCriteriaBuilder being(Operator operator) {
this.operator = operator;
return this;
}
public PriceCriteriaBuilder value(double desiredPrice) {
this.desiredPrice = desiredPrice;
PriceCriteriaBuilder.this.criteria.add(
new PriceCriterion(operator, desiredPrice));
return PriceCriteriaBuilder.this;
}
}
Then, you can add the code for other criteria in the same manner.
The result is a very flexible system that allows you to develop and add to the design in a tidy and compatible manner. Things are loosely coupled and follow patterns that help your code communicate and stay maintainable.
A Comment on Test Automation
In a modern system, we really must radically automate testing.
There are times when we will need to do manual testing, but we should not rely on this as the primary practice of our testing department. We should have engineers who are not secondary to the application engineers, but who work right alongside them writing automated tests.
Just as a programmer would put writing unit tests first in Test-Driven Development (TDD), the test engineer should sit with the business analyst as the stories are written and provide input into the Acceptance Criteria to ensure that it is testable. Acceptance Criteria should be specific, measurable, and verifiable.
The tests are not ancillary to the code base as the marginalized term of that binary pair; they are written in code, are committed to the code repository, enjoy an automated pipeline, are versioned, and might not only be written before the code, as in TDD, but might also inform the stories themselves that are built.
As we have discussed, your test suite topology should include the following:
-
Unit tests written by developers
-
Canary/smoke tests
-
Integration tests
-
Regression tests
-
Load tests
-
Security penetration tests
That’s a big job. And they all need to be separated, automated, and treated as first-class citizens.
A Comment on Comments
Encourage your development teams (require them, in fact) to write comments about their code. Make them meaningful and helpful, not perfunctory or merely restating the obvious.
Anything that is checked in to the code repository—including YAML, CFTs, Python, Java, JS, CSS, RunwayDB scripts, pipeline scripts, machine learning code—anything someone will need to read and understand and use, all should have meaningful comments.
Have the developers secretly aim, however, to make comments unnecessary because their code is so well named with such high cohesion and behaves in such a clear and obvious way that anything they would write into the comments would be redundant. After they write the comments, encourage them to read over it and see whether, instead of making a comment, they can make some tweaks to the code to try to actually put comments into the working code itself to make it better.
Here are a few good examples taken from the Java APIs themselves, as some instructive examples of comments, but the ideas apply to any language:
- Enum
-
This is quite short but directive about a specific point of interest, and points the reader to considerable deeply detailed information in the JLS.
- UUID
-
This too is short and to the point, but clear on boundaries that would make a difference to the programmer, and points the user to an additional related class and an RFC for further usage implications.
- TimeUnit
-
This tells you exactly how things are defined within the class, gives examples for proper usage, and states what is and is not guaranteed.
- PhantomReference
-
Same. This is fantastic. The sweet spot.
- List<E> and Set<E>
-
These both are quite good. For both, it is for an interface, which is different. It gives an overview of what the interface provides so that you don’t need to read the code to find out; it does not speak beyond what it can for an interface that has different implementations (that’s the purpose after all). It has documentation for the type parameter (<E>). It talks about why Lists/Sets should exist at all, what is special about them in distinction with the other items in Collections, and how to use it.
- String
-
Clear guidance and examples on usage, implications, and equivalencies.
- Formatter
-
This is an interesting case that I call out for a specific reason. The JavaDoc alone must have taken a full week to write; it’s pages long. If you have to take a week to write the JavaDoc to explain usage like this, you have probably designed a class poorly, in a non-object-oriented way. In this case, however, it makes perfect sense because Formatter is specifically intended to replicate the 1970s C printf function, so the code looks like that on purpose. Thus, it has to take a week to write the JavaDoc. This is a rare case to illustrate longer doesn’t always mean better, but in this case it is appropriate. Hopefully, your developers won’t write books like this comment and don’t write classes that would require them doing so.
These are all great lessons for how to write proper comments. Most of these would not take forever to write and are helpful for maintainability, clarity, and efficiency for future developers.
Summary
In this chapter, we covered significant ground. We examined how to discover the services in your domain, the structure of services, how and when to add eventing, and how to use machine learning to go beyond pluggability into radical extensibility.
In Chapter 8, we examine the data aspect more specifically.