
7
KEYED HASHING

The hash functions discussed in Chapter 6 take a message and return its hash value—typically a short string of 256 or 512 bits. Anyone can compute the hash value of a message and verify that a particular message hashes to a particular value because there’s no secret value involved, but sometimes you don’t want to let just anyone do that. That’s where keyed hash functions come in, or hashing with secret keys.
Keyed hashing forms the basis of two types of important cryptographic algorithms: message authentication codes (MACs), which authenticate a message and protect its integrity, and pseudorandom functions (PRFs), which produce random-looking hash-sized values. We’ll look at how and why MACs and PRFs are similar in the first section of this chapter; then we’ll review how real MACs and PRFs work. Some MACs and PRFs are based on hash functions, some are based on block ciphers, and still others are original designs. Finally, we’ll review examples of attacks on otherwise secure MACs.
Message Authentication Codes (MACs)
A MAC protects a message’s integrity and authenticity by creating a value T = MAC(K, M), called the authentication tag of the message, M (often confusingly called the MAC of M). Just as you can decrypt a message if you know a cipher’s key, you can validate that a message has not been modified if you know a MAC’s key.
For example, say Alex and Bill share a key, K, and Alex sends a message, M, to Bill along with its authentication tag, T = MAC(K, M). Upon receiving the message and its authentication tag, Bill recomputes MAC(K, M) and checks that it is equal to the authentication tag received. Because only Alex could have computed this value, Bill knows that the message wasn’t corrupted in transit (confirming integrity), whether accidentally or maliciously, and that Alex sent that message (confirming authenticity).
MACs in Secure Communication
Secure communication systems often combine a cipher and a MAC to protect a message’s confidentiality, integrity, and authenticity. For example, the protocols in Internet Protocol Security (IPSec), Secure Shell (SSH), and Transport Layer Security (TLS) generate a MAC for each network packet transmitted.
Not all communication systems use MACs. Sometimes an authentication tag can add unacceptable overhead to each packet, typically in the range of 64 to 128 bits. For example, the 3G and 4G mobile telephony standards encrypt packets encoding voice calls but they don’t authenticate them. An attacker can modify the encrypted audio signal and the recipient wouldn’t notice. Thus, if an attacker damages an encrypted voice packet, it will decrypt to noise, which would sound like static.
Forgery and Chosen-Message Attacks
What does it mean for a MAC to be secure? First of all, as with a cipher, the secret key should remain secret. If a MAC is secure, an attacker shouldn’t be able to create a tag of some message if they don’t know the key. Such a made-up message/tag pair is called a forgery, and recovering a key is just a specific case of a more general class of attacks called forgery attacks. The security notion that posits that forgeries should be impossible to find is called unforgeability. Obviously, it should be impossible to recover the secret key from a list of tags; otherwise, attackers could forge tags using the key.
What can an attacker do to break a MAC? In other words, what’s the attack model? The most basic model is the known-message attack, which passively collects messages and their associated tags (for example, by eavesdropping on a network). But real attackers often launch more powerful attacks because they can often choose the messages to be authenticated, and therefore get the MAC of the message they want. The standard model is therefore that of chosen-message attacks, wherein attackers get tags for messages of their choice.
Replay Attacks
MACs aren’t safe from attacks involving replays of tags. For example, if you were to eavesdrop on Alex and Bill’s communications, you could capture a message and its tag sent by Alex to Bill, and later send them again to Bill pretending to be Alex. To prevent such replay attacks, protocols include a message number in each message. This number is incremented for each new message and authenticated along with the message. The receiving party gets messages numbered 1, 2, 3, 4, and so on. Thus, if an attacker tries to send message number 1 again, the receiver will notice that this message is out of order and that it’s a potential replay of the earlier message number 1.
Pseudorandom Functions (PRFs)
A PRF is a function that uses a secret key to return PRF(K, M), such that the output looks random. Because the key is secret, the output values are unpredictable to an attacker.
Unlike MACs, PRFs are not meant to be used on their own but as part of a cryptographic algorithm or protocol. For example, PRFs can be used to create block ciphers within the Feistel construction discussed in “How to Construct Block Ciphers” on page 55. Key derivation schemes use PRFs to generate cryptographic keys from a master key or a password, and identification schemes use PRFs to generate a response from a random challenge. (Basically, a server sends a random challenge message, M, and the client returns PRF(K, M) in its response to prove that it knows K.) The 4G telephony standard uses a PRF to authenticate a SIM card and its service provider, and a similar PRF also serves to generate the encryption key and MAC key to be used during a phone call. The TLS protocol uses a PRF to generate key material from a master secret as well as session-specific random values. There’s even a PRF in the noncryptographic hash() function built into the Python language to compare objects.
PRF Security
In order to be secure, a pseudorandom function should have no pattern that sets its outputs apart from truly random values. An attacker who doesn’t know the key, K, shouldn’t be able to distinguish the outputs of PRF(K, M) from random values. Viewed differently, an attacker shouldn’t have any means of knowing whether they’re talking to a PRF algorithm or to a random function. The erudite phrase for that security notion is indistinguishability from a random function. (To learn more about the theoretical foundations of PRFs, see Volume 1, Section 3.6 of Goldreich’s Foundations of Cryptography.)
Why PRFs Are Stronger Than MACs
PRFs and MACs are both keyed hashes, but PRFs are fundamentally stronger than MACs, largely because MACs have weaker security requirements. Whereas a MAC is considered secure if tags can’t be forged—that is, if the MAC’s outputs can’t be guessed—a PRF is only secure if its outputs are indistinguishable random strings, which is a stronger requirement. If a PRF’s outputs can’t be distinguished from random strings, the implication is that their values can’t be guessed; in other words, any secure PRF is also a secure MAC.
The converse is not true, however: a secure MAC isn’t necessarily a secure PRF. For example, say you start with a secure PRF, PRF1, and you want to build a second PRF, PRF2, from it, like this:
PRF2(K, M) = PRF1(K, M) || 0
Because PRF2’s output is defined as PRF1’s output followed by one 0 bit, it doesn’t look as random as a true random string, and you can distinguish its outputs by that last 0 bit. Hence, PRF2 is not a secure PRF. However, because PRF1 is secure, PRF2 would still make a secure MAC. Why? Because if you were able to forge a tag, T = PRF2(K, M), for some M, then you’d also be able to forge a tag for PRF1, which we know to be impossible in the first place because PRF1 is a secure MAC. Thus, PRF2 is a keyed hash that’s a secure MAC but not a secure PRF.
But don’t worry: you won’t find such MAC constructions in real applications. In fact, many of the MACs deployed or standardized are also secure PRFs and are often used as either. For example, TLS uses the algorithm HMAC-SHA-256 both as a MAC and as a PRF.
Creating Keyed Hashes from Unkeyed Hashes
Throughout the history of cryptography, MACs and PRFs have rarely been designed from scratch but rather have been built from existing algorithms, usually hash functions of block ciphers. One seemingly obvious way to produce a keyed hash function would be to feed an (unkeyed) hash function a key and a message, but that’s easier said than done, as I discuss next.
The Secret-Prefix Construction
The first technique we’ll examine, called the secret-prefix construction, turns a normal hash function into a keyed hash one by prepending the key to the message and returning Hash(K || M). Although this approach is not always wrong, it can be insecure when the hash function is vulnerable to length-extension attacks (as discussed in “The Length-Extension Attack” on page 125) and when the hash supports keys of different lengths.
Insecurity Against Length-Extension Attacks
Recall from Chapter 6 that hash functions of the SHA-2 family allow attackers to compute the hash of a partially unknown message when given a hash of a shorter version of that message. In formal terms, the length-extension attack allows attackers to compute Hash(K || M1 || M2) given only Hash(K || M1) and neither M1 nor K. These functions allow attackers to forge valid MAC tags for free because they’re not supposed to be able to guess the MAC of M1 || M2 given only the MAC of M1. This fact makes the secret-prefix construction as insecure as a MAC and PRF when, for example, it’s used with SHA-256 or SHA-512. It is a weakness of Merkle–Damgård to allow length-extension attacks, and none of the SHA-3 finalists do. The ability to thwart length-extension attacks was mandatory for SHA-3 submissions.
Insecurity with Different Key Lengths
The secret-prefix construction is also insecure when it allows the use of keys of different lengths. For example, if the key K is the 24-bit hexadecimal string 123abc and M is def00, then Hash() will process the value K || M = 123abcdef00. If K is instead the 16-bit string 123a and M is bcdef000, then Hash() will process K || M = 123abcdef00, too. Therefore, the result of the secret-prefix construction Hash(K || M) will be the same for both keys.
This problem is independent of the underlying hash and can be fixed by hashing the key’s length along with the key and the message, for example, by encoding the key’s bit length as a 16-bit integer, L, and then hashing Hash(L || K || M). But you shouldn’t have to do this. Modern hash functions such as BLAKE2 and SHA-3 include a keyed mode that avoids those pitfalls and yields a secure PRF, and thus a secure MAC as well.
The Secret-Suffix Construction
Instead of hashing the key before the message as in the secret-prefix construction, we can hash it after. And that’s exactly how the secret-suffix construction works: by building a PRF from a hash function as Hash(M || K).
Putting the key at the end makes quite a difference. For one thing, the length-extension attack that works against secret-prefix MACs won’t work against the secret suffix. Applying length extension to a secret-suffix MAC, you’d get Hash(M1 || K || M2) from Hash(M1 || K), but that wouldn’t be a valid attack because Hash(M1 || K || M2) isn’t a valid secret-suffix MAC; the key needs to be at the end.
However, the secret-suffix construction is weaker against another type of attack. Say you’ve got a collision for the hash Hash(M1) = Hash(M2), where M1 and M2 are two distinct messages, possibly of different sizes. In the case of a hash function such as SHA-256, this implies that Hash(M1 || K) and Hash(M2 || K) will be equal too, because internally K will be processed based on the data hashed previously, namely Hash(M1), equal to Hash(M2). Hence, you’d get the same hash value whether you hash K after M1 or after M2, regardless of the value of K.
To exploit this property, an attacker would:
Find two colliding messages, M1 and M2
Request the MAC tag of M1 Hash(M1 || K)
Guess that Hash(M2 || K) is the same, thereby forging a valid tag and breaking the MAC’s security
The HMAC Construction
The hash-based MAC (HMAC) construction allows us to build a MAC from a hash function, which is more secure than either secret prefix or secret suffix. HMAC yields a secure PRF as long as the underlying hash is collision resistant, but even if that’s not the case, HMAC will still yield a secure PRF if the hash’s compression function is a PRF. The secure communication protocols IPSec, SSH, and TLS have all used HMAC. (You’ll find HMAC specifications in NIST’s FIPS 198-1 standard and in RFC 2104.)
HMAC uses a hash function, Hash, to compute a MAC tag, as shown in Figure 7-1 and according to the following expression:
Hash((K ⊕ opad) Hash((K ⊕ ipad) M))
The term opad (outer padding) is a string (5c5c5c . . . 5c) that is as long as Hash’s block size. The key, K, is usually shorter than one block that is filled with 00 bytes and XORed with opad. For example, if K is the 1-byte string 00, then K ⊕ opad = opad. (The same is true if K is the all-zero string of any length up to a block’s length.) K ⊕ opad is the first block processed by the outer call to Hash—namely, the leftmost Hash in the preceding equation, or the bottom hash in Figure 7-1.
The term ipad (inner padding) is a string (363636 . . . 36) that is as long as the Hash’s block size and that is also completed with 00 bytes. The resulting block is the first block processed by the inner call to Hash—namely, the rightmost Hash in the equation, or the top hash in Figure 7-1.

Figure 7-1: The HMAC hash-based MAC construction
NOTE
The envelope method is an even more secure construction than secret prefix and secret suffix. It’s expressed as Hash(K || M || K), something called a sandwich MAC, but it’s theoretically less secure than HMAC.
If SHA-256 is the hash function used as Hash, then we call the HMAC instance HMAC-SHA-256. More generally, we call HMAC-Hash an HMAC instance using the hash function Hash. That means if someone asks you to use HMAC, you should always ask, “Which hash function?”
A Generic Attack Against Hash-Based MACs
There is one attack that works against all MACs based on an iterated hash function. Recall the attack in “The Secret-Suffix Construction” on page 131 where we used a hash collision to get a collision of MACs. You can use the same strategy to attack a secret-prefix MAC or HMAC, though the consequences are less devastating.
To illustrate the attack, consider the secret-prefix MAC Hash(K || M), as shown in Figure 7-2. If the digest is n bits, you can find two messages, M1 and M2, such that Hash(K || M1) = Hash(K || M2), by requesting approximately 2n/2 MAC tags to the system holding the key. (Recall the birthday attack from Chapter 6.) If the hash lends itself to length extension, as SHA-256 does, you can then use M1 and M2 to forge MACs by choosing some arbitrary data, M3, and then querying the MAC oracle for Hash(K || M1 || M3), which is the MAC of message M1 || M3. As it turns out, this is also the MAC of message M2 || M3, because the hash’s internal state of M1 and M3 and M2 and M3 is the same, and you’ve successfully forged a MAC tag. (The effort becomes infeasible as n grows beyond, say, 128 bits.)

Figure 7-2: The principle of the generic forgery attack on hash-based MACs
This attack will work even if the hash function is not vulnerable to length extension, and it will work for HMAC, too. The cost of the attack depends on both the size of the chaining value and the MAC’s length: if a MAC’s chaining value is 512 bits and its tags are 128 bits, a 264 computation would find a MAC collision but probably not a collision in the internal state, since finding such a collision would require 2512/2 = 2256 operations on average.
Creating Keyed Hashes from Block Ciphers: CMAC
Recall from Chapter 6 that the compression functions in many hash functions are built on block ciphers. For example, HMAC-SHA-256 PRF is a series of calls to SHA-256’s compression function, which itself is a block cipher that repeats a sequence of rounds. In other words, HMAC-SHA-256 is a block cipher inside a compression function inside a hash inside the HMAC construction. So why not use a block cipher directly rather than build such a layered construction?
CMAC (which stands for cipher-based MAC) is such a construction: it creates a MAC given only a block cipher, such as AES. Though less popular than HMAC, CMAC is deployed in many systems, including the Internet Key Exchange (IKE) protocol, which is part of the IPSec suite. IKE, for example, generates key material using a construction called AES-CMAC-PRF-128 as a core algorithm (or CMAC based on AES with 128-bit output). CMAC is specified in RFC 4493.
Breaking CBC-MAC
CMAC was designed in 2005 as an improved version of CBC-MAC, a simpler block cipher–based MAC derived from the cipher block chaining (CBC) block cipher mode of operation (see “Modes of Operation” on page 65).
CBC-MAC, the ancestor of CMAC, is simple: to compute the tag of a message, M, given a block cipher, E, you encrypt M in CBC mode with an all-zero initial value (IV) and discard all but the last ciphertext block. That is, you compute C1 = E(K, M1), C2 = E(K, M2 ⊕ C1), C3 = E(K, M3 ⊕ C2), and so on for each of M’s blocks and keep only the last Ci, your CBC-MAC tag for M—simple, and simple to attack.
To understand why CBC-MAC is insecure, consider the CBC-MAC tag, T1 = E(K, M1), of a single-block message, M1, and the tag, T2 = E(K, M2), of another single-block message, M2. Given these two pairs, (M1, T1) and (M2, T2), you can deduce that T2 is also the tag of the two-block message M1 || (M2 ⊕ T1). Indeed, if you apply CBC-MAC to M1 || (M2 ⊕ T1) and compute C1 = E(K, M1) = T1 followed by C2 = E(K, (M2 ⊕ T1) ⊕ T1) = E(K, M2) = T2, you can create a third message/tag pair from two message/tag pairs without knowing the key. That is, you can forge CBC-MAC tags, thereby breaking CBC-MAC’s security.
Fixing CBC-MAC
CMAC fixes CBC-MAC by processing the last block using a different key from the preceding blocks. To do this, CMAC first derives two keys, K1 and K2, from the main key, K, such that K, K1, and K2 will be distinct. In CMAC, the last block is processed using either K1 or K2, while the preceding blocks use K.
To determine K1 and K2, CMAC first computes a temporary value, L = E(0, K), where 0 acts as the key of the block cipher and K acts as the plaintext block. Then CMAC sets the value of K1 equal to (L << 1) if L’s most significant bit (MSB) is 0, or equal to (L << 1) ⊕ 87 if L’s MSB is 1. (The number 87 is carefully chosen for its mathematical properties when data blocks are 128 bits; a value other than 87 is needed when blocks aren’t 128 bits.)
The value of K2 is set equal to (K1 << 1) if K1’s MSB is 0, or K2 = (K1 << 1) ⊕ 87 otherwise.
Given K1 and K2, CMAC works like CBC-MAC, except for the last block. If the final message chunk Mn is exactly the size of a block, CMAC returns the value E(K, MN ⊕ Cn − 1 ⊕ K1) as a tag, as shown in Figure 7-3. But if MN has fewer bits than a block, CMAC pads it with a 1 bit and zeros, and returns the value E(K, Mn ⊕ Cn − 1 ⊕ K2) as a tag, as shown in Figure 7-4. Notice that the first case uses only K1 and the second only K2, but both use only the main key K to process the message chunks that precede the final one.
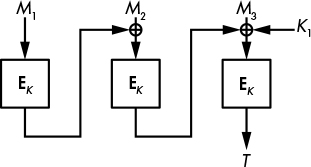
Figure 7-3: The CMAC block cipher–based MAC construction when the message is a sequence of integral blocks
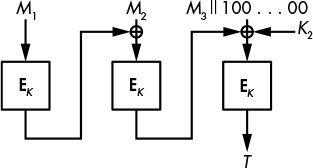
Figure 7-4: The CMAC block cipher–based MAC construction when the last block of the message has to be padded with a 1 bit and zeros to fill a block
Note that unlike the CBC encryption mode, CMAC does not take an IV as a parameter and is deterministic: CMAC will always return the same tag for a given message, M, because the computation of CMAC(M) is not randomized—and that’s fine, because unlike encryption, MAC computation doesn’t have to be randomized to be secure, which eliminates the burden of having to choose random IV.
Dedicated MAC Designs
You’ve seen how to recycle hash functions and block ciphers to build PRFs that are secure as long as their underlying hash or cipher is secure. Schemes such as HMAC and CMAC simply combine available hash functions or block ciphers to yield a secure PRF or MAC. Reusing available algorithms is convenient, but is it the most efficient approach?
Intuitively, PRFs and MACs should require less work than unkeyed hash functions in order to be secure—their use of a secret key prevents attackers from playing with the algorithm because they don’t have the key. Also, PRFs and MACs only expose a short tag to attackers, unlike block ciphers, which expose a ciphertext that is as long as the message. Hence, PRFs and MACs should not need the whole power of hash functions or block ciphers, which is the point of dedicated design—that is, algorithms created solely to serve as PRFs and/or MACs.
The sections that follow focus on two such algorithms that are widely used: Poly1305 and SipHash. I’ll explain their design principles and why they are likely secure.
Poly1305
The Poly1305 algorithm (pronounced poly-thirteen-o-five) was designed in 2005 by Daniel J. Bernstein (creator of the Salsa20 stream cipher discussed in Chapter 5 and the ChaCha cipher that inspired the BLAKE and BLAKE2 hash functions discussed in Chapter 6). Poly1305 is optimized to be super fast on modern CPUs, and as I write this, it is used by Google to secure HTTPS (HTTP over TLS) connections and by OpenSSH, among many other applications. Unlike Salsa20, the design of Poly1305 is built on techniques dating back to the 1970s—namely, universal hash functions and the Wegman–Carter construction.
Universal Hash Functions
The Poly1305 MAC uses a universal hash function internally that is much weaker than a cryptographic hash function, but also much faster. Universal hash functions don’t have to be collision resistant, for example. That means less work is required to achieve their security goals.
Like a PRF, a universal hash is parameterized by a secret key: given a message, M, and key, K, we write UH(K, M), which is the computation of the output of a universal hash function, denoted UH. A universal hash function has only one security requirement: for any two messages, M1 and M2, the probability that UH(K, M1) = UH(K, M2) must be negligible for a random key, K. Unlike a PRF, a universal hash doesn’t need to be pseudorandom; there simply should be no pair (M1, M2) that gives the same hash for many different keys. Because their security requirements are easier to satisfy, fewer operations are required and therefore universal hash functions are considerably faster than PRFs.
You can use a universal hash as a MAC to authenticate no more than one message, however. For example, consider the universal hash used in Poly1305, called a polynomial-evaluation hash. (See the seminal 1974 article “Codes Which Detect Deception” by Gilbert, MacWilliams, and Sloane for more on this notion.) This kind of polynomial-evaluation hash is parameterized by a prime number, p, and takes as input a key consisting of two numbers, R and K, in the range [1, p] and a message, M, consisting of n blocks (M1, M2, . . . , Mn). The output of the universal hash is then computed as the following:
UH(R, K, M) = R + M1K + M3K2 + M3K3 + ... + MnKn mod p
The plus sign (+) denotes the addition of positive integers, K i is the number K raised to the power i, and “mod p” denotes the reduction modulo p of the result (that is, the remainder of the division of the result by p; for example, 12 mod 10 = 2, 10 mod 10 = 0, 8 mod 10 = 8, and so on).
Because we want the hash to be as fast as possible, universal hash-based MACs often work with message blocks of 128 bits and with a prime number, p, that is slightly larger than 2128, such as 2128 + 51. The 128-bit width allows for very fast implementations by efficiently using the 32- and 64-bit arithmetic units of common CPUs.
Potential Vulnerabilities
Universal hashes have one weakness: because a universal hash is only able to securely authenticate one message, an attacker could break the preceding polynomial-evaluation MAC by requesting the tags of only two messages. Specifically, they could request the tags for a message where M1 = M2 = . . . = 0 (that is, whose tag is UH(R, K, 0) = R) and then use the tags to find the secret value R. Alternatively, they could request the tags for a message where M1 = 1 and where M2 = M3 = . . . = 0 (that is, whose tag is T = R + K), which would allow them to find K by subtracting R from T. Now the attacker knows the whole key (R, K) and they can forge MACs for any message.
Fortunately, there’s a way to go from single-message security to multi-message security.
Wegman–Carter MACs
The trick to authenticating multiple messages using a universal hash function arrived thanks to IBM researchers Wegman and Carter and their 1981 paper “New Hash Functions and Their Use in Authentication and Set Equality.” The so-called Wegman–Carter construction builds a MAC from a universal hash function and a PRF, using two keys, K1 and K2, and it returns
MAC(K1, K2, N, M) = UH(K1, M) + PRF(K2, N)
where N is a nonce that should be unique for each key, K2, and where PRF’s output is as large as that of the universal hash function UH. By adding these two values, PRF’s strong pseudorandom output masks the cryptographic weakness of UH. You can see this as the encryption of the universal hash’s result, where the PRF acts as a stream cipher and prevents the preceding attack by making it possible to authenticate multiple messages with the same key, K1.
To recap, the Wegman–Carter construction UH(K1, M) + PRF(K2, N) gives a secure MAC if we assume the following:
- UH is a secure universal hash.
- PRF is a secure PRF.
- Each nonce N is used only once for each key K2.
- The output values of UH and PRF are long enough to ensure high enough security.
Now let’s see how Poly1305 leverages the Wegman–Carter construction to build a secure and fast MAC.
Poly1305-AES
Poly1305 was initially proposed as Poly1305-AES, combining the Poly1305 universal hash with the AES block cipher. Poly1305-AES is much faster than HMAC-based MACs, or even than CMACs, since it only computes one block of AES and processes the message in parallel through a series of simple arithmetic operations.
Given a 128-bit K1, K2, and N, and message, M, Poly1305-AES returns the following:
Poly 1305(K1, M) + AES(K2, N) mod 2128
The mod 2128 reduction ensures that the result fits in 128 bits. The message M is parsed as a sequence of 128-bit blocks (M1, M2, . . . , Mn), and a 129th bit is appended to each block’s most significant bit to make all blocks 129 bits long. (If the last block is smaller than 16 bytes, it’s padded with a 1 bit followed by 0 bits before the final 129th bit.) Next, Poly1305 evaluates the polynomial to compute the following:
Poly 1305(K1, M) = M1K1i + M2K1n − 1 + ... +MnK1 mod 2130 − 5
The result of this expression is an integer that is at most 129-bits long. When added to the 128-bit value AES(K2, N), the result is reduced modulo 2128 to produce a 128-bit MAC.
NOTE
AES isn’t a PRF; instead, it’s a pseudorandom permutation (PRP). However, that doesn’t matter much here because the Wegman–Carter construction works with a PRP as well as with a PRF. This is because if you’re given a function that is either a PRF of a PRP, it’s hard to determine whether it’s a PRF of a PRP just by looking at the function’s output values.
The security analysis of Poly1305-AES (see “The Poly1305-AES Message-Authentication Code” at http://cr.yp.to/mac/poly1305-20050329.pdf) shows that Poly1305-AES is 128-bit secure as long as AES is a secure block cipher—and, of course, as long as everything is implemented correctly, as with any cryptographic algorithm.
The Poly1305 universal hash can be combined with algorithms other than AES. For example, Poly1305 was used with the stream cipher ChaCha (see RFC 7539, “ChaCha20 and Poly1305 for IETF Protocols”). There’s no doubt that Poly1305 will keep being used wherever a fast MAC is needed.
SipHash
Although Poly1305 is fast and secure, it has several downsides. For one, its polynomial evaluation is difficult to implement efficiently, especially in the hands of many who are unfamiliar with the associated mathematical notions. (See examples at https://github.com/floodyberry/poly1305-donna/). Second, on its own, it’s secure for only one message unless you use the Wegman–Carter construction. But in that case, it requires a nonce, and if the nonce is repeated, the algorithm becomes insecure. Finally, Poly1305 is optimized for long messages, but it’s overkill if you process only small messages (say, fewer than 128 bytes). In such cases, SipHash is the solution.
I designed SipHash in 2012 with Dan Bernstein initially to address a noncryptographic problem: denial-of-service attacks on hash tables. Hash tables are data structures used to efficiently store elements in programming languages. Prior to the advent of SipHash, hash tables relied on noncryptographic keyed hash functions for which collisions were easy to find, and it was easy to exploit a remote system using a hash table by slowing it down with a denial-of-service attack. We determined that a PRF would address this problem and thus set out to design SipHash, a PRF suitable for hash tables. Because hash tables process mostly short inputs, SipHash is optimized for short messages. However, SipHash can be used for more than hash tables: it’s a full-blown PRF and MAC that shines where most inputs are short.
How SipHash Works
SipHash uses a trick that makes it more secure than basic sponge functions: instead of XORing message blocks only once before the permutation, SipHash XORs them before and after the permutation, as shown in Figure 7-5. The 128-bit key of SipHash is seen as two 64-bit words, K1 and K2, XORed to a 256-bit fixed initial state that is seen as four 64-bit words. Next, the keys are discarded, and computing SipHash boils down to iterating through a core function called SipRound and then XORing message chunks to modify the four-word internal state. Finally, SipHash returns a 64-bit tag by XORing the four-state words together.

Figure 7-5: SipHash-2-4 processing a 15-byte message (a block, M1, of 8 bytes and a block, M2, of 7 bytes, plus 1 byte of padding)
The SipRound function uses a bunch of XORs together with additions and word rotations to make the function secure. SipRound transforms a state of four 64-bit words (a, b, c, d) by performing the following operations, top to bottom. The operations on the left and right are independent and can be carried out in parallel:
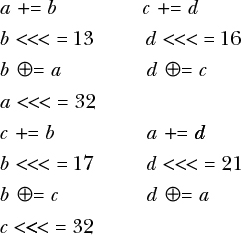
Here, a += b is shorthand for a = a + b, and b <<< = 13 is shorthand for b = b <<< 13 (the 64-bit word b left-rotated 13 bits.)
These simple operations on 64-bit words are almost all you need to implement in order to compute SipHash—although you won’t have to implement it yourself. You can find readily available implementations in most languages, including C, Go, Java, JavaScript, and Python.
NOTE
We write SipHash-x-y as the SipHash version, meaning it makes x SipRounds between each message block injection and then y rounds. More rounds require more operations, which slows down operations but also increases security. The default version is SipHash-2-4 (simply noted as SipHash), and it has so far resisted cryptanalysis. However, you may want to be conservative and opt for SipHash-4-8 instead, which makes twice as many rounds and is therefore twice as slow.
How Things Can Go Wrong
Like ciphers and unkeyed hash functions, MACs and PRFs that are secure on paper can be vulnerable to attacks when used in a real setting, against realistic attackers. Let’s see two examples.
Timing Attacks on MAC Verification
Side-channel attacks target the implementation of a cryptographic algorithm rather than the algorithm itself. In particular, timing attacks use an algorithm’s execution time to determine secret information, such as keys, plaintext, and secret random values. As you might imagine, variable-time string comparison induces vulnerabilities not only in MAC verification, but also in many other cryptographic and security functionalities.
MACs can be vulnerable to timing attacks when a remote system verifies tags in a period of time that depends on the tag’s value, thereby allowing an attacker to determine the correct message tag by trying many incorrect ones to determine the one that takes the longest amount of time to complete. The problem occurs when a server compares the correct tag with an incorrect one by comparing the two strings byte per byte, in order, until the bytes differ. For example, the Python code in Listing 7-1 compares two strings byte per byte, in variable time: if the first bytes differ, the function will return after only one comparison; if the strings x and y are identical, the function will make n comparisons against the length of the strings.
def compare_mac(x, y, n):
for i in range(n):
if x[i] != y[i]:
return False
return True
Listing 7-1: Comparison of two n-byte strings, taking variable time
To demonstrate the vulnerability of the verify_mac() function, let’s write a program that measures the execution time of 100000 calls to verify_mac(), first with identical 10-byte x and y values and then with x and y values that differ in their third byte. We should expect the latter comparison to take noticeably less time than the former because verify_mac() will compare fewer bytes than the identical x and y would, as shown in Listing 7-2.
from time import time
MAC1 = '0123456789abcdef'
MAC2 = '01X3456789abcdef'
TRIALS = 100000
# each call to verify_mac() will look at all eight bytes
start = time()
for i in range(TRIALS):
compare_mac(MAC1, MAC1, len(MAC1))
end = time()
print('%0.5f' % (end-start))
# each call to verify_mac() will look at three bytes
start = time()
for i in range(TRIALS):
compare_mac(MAC1, MAC2, len(MAC1))
end = time()
print('%0.5f' % (end-start))
Listing 7-2: Measuring timing differences when executing compare_mac() from Listing 7-1
In my test environment, typical execution of the program in Listing 7-2 prints execution times of around 0.215 and 0.095 seconds, respectively. That difference is significant enough for you to identify what’s happening within the algorithm. Now move the difference to other offsets in the string, and you’ll observe different execution times for different offsets. If MAC1 is the correct MAC tag and MAC2 is the one tried by the attacker, you can easily identify the position of the first difference, which is the number of correctly guessed bytes.
Of course, if execution time doesn’t depend on a secret timing, timing attacks won’t work, which is why implementers strive to write constant-time implementations—that is, code that takes exactly the same time to complete for any secret input value. For example, the C function in Listing 7-3 compares two buffers of size bytes in constant time: the temporary variable result will be nonzero if and only if there’s a difference somewhere in the two buffers.
int cmp_const(const void *a, const void *b, const size_t size)
{
const unsigned char *_a = (const unsigned char *) a;
const unsigned char *_b = (const unsigned char *) b;
unsigned char result = 0;
size_t i;
for (i = 0; i < size; i++) {
result |= _a[i] ^ _b[i];
}
return result; /* returns 0 if *a and *b are equal, nonzero otherwise */
}
Listing 7-3: Constant-time comparison of two buffers, for safer MAC verification
When Sponges Leak
Permutation-based algorithms like SHA-3 and SipHash are simple, easy to implement, and come with compact implementations, but they’re fragile in the face of side-channel attacks that recover a snapshot of the system’s state. For example, if a process can read the RAM and registers’ values at any time, or read a core dump of the memory, an attacker can determine the internal state of SHA-3 in MAC mode, or the internal state of SipHash, and then compute the reverse of the permutation to recover the initial secret state. They can then forge tags for any message, breaking the MAC’s security.
Fortunately, this attack will not work against compression function–based MACs such as HMAC-SHA-256 and keyed BLAKE2 because the attacker would need a snapshot of memory at the exact time when the key is used. The upshot is that if you’re in an environment where parts of a process’s memory may leak, you can use a MAC based on a noninvertible transform compression function rather than a permutation.
Further Reading
The venerable HMAC deserves more attention than I have space for here, and even more for the train of thought that led to its wide adoption, and eventually to its demise when combined with a weak hash function. I recommend the 1996 paper “Keying Hash Functions for Message Authentication” by Bellare, Canetti, and Krawczyk, which introduced HMAC and its cousin NMAC, and the 2006 follow-up paper by Bellare called “New Proofs for NMAC and HMAC: Security Without Collision-Resistance,” which proves that HMAC doesn’t need a collision-resistant hash, but only a hash with a compression function that is a PRF. On the offensive side, the 2007 paper “Full Key-Recovery Attacks on HMAC/NMAC-MD4 and NMAC-MD5” by Fouque, Leurent, and Nguyen shows how to attack HMAC and NMAC when they’re built on top of a brittle hash function such as MD4 or MD5. (By the way, HMAC-MD5 and HMAC-SHA-1 aren’t totally broken, but the risk is high enough.)
The Wegman–Carter MACs are also worth more attention, both for their practical interest and underlying theory. The seminal papers by Wegman and Carter are available at http://cr.yp.to/bib/entries.html. Other state-of-the-art designs include UMAC and VMAC, which are among the fastest MACs on long messages.
One type of MAC not discussed in this chapter is Pelican, which uses the AES block cipher reduced to four rounds (down from 10 in the full block cipher) to authenticate chunks of messages within a simplistic construction, as described in https://eprint.iacr.org/2005/088/. Pelican is more of a curiosity, though, and it’s rarely used in practice.
Last but not least, if you’re interested in finding vulnerabilities in cryptographic software, look for uses of CBC-MAC, or for weaknesses caused by HMAC handling keys of arbitrary sizes—taking Hash(K) as the key rather than K if K is too long, thus making K and Hash(K) equivalent keys. Or just look for systems than don’t use MAC when they should—a frequent occurrence.
In Chapter 8, we’ll look at how to combine MACs with ciphers to protect a message’s authenticity, integrity, and confidentiality. We’ll also look at how to do it without MACs, thanks to authenticated ciphers, which are ciphers that combine the functionality of a basic cipher with that of a MAC by returning a tag along with each ciphertext.