
8 Architecting serverless parallel computing
There’s a secret about AWS Lambda that we like to tell people: it’s a supercomputer that can perform faster than the largest EC2 instance. The trick is to think about Lambda in terms of parallel computation. If you can divide your problem into hundreds or thousands of smaller problems and solve them in parallel, you will get to a result faster than if you try to solve the same problem by moving through it sequentially.
Parallel computing is an important topic in computer science and is often talked about in the undergraduate computer science curriculum. Interestingly, Lambda, by its very nature, predisposes us to think and apply concepts from parallel computing. Services like Step Functions and DynamoDB make it easier to build parallel applications.
In this chapter, we’ll illustrate how to build a serverless video transcoder in Lambda that outperforms bigger and more expensive EC2 servers.
8.1 Introduction to MapReduce
MapReduce is a popular and well-known programming model that’s often used to process large data sets. It was originally created at Google by developers who were themselves inspired by two well-known functional programming primitives (higher-order functions): map and reduce. MapReduce works by splitting up a large data set into many smaller subsets, performing an operation on each subset and then combining or summing up to get the result.
Imagine that you want to find out how many times a character’s name is mentioned in Tolstoy’s War and Peace. You can sequentially look through every page, one by one, and count the occurrences (but that’s slow). If you apply a MapReduce approach, however, you can do it much quicker:
-
You split the data into many independent subsets. In the case of War and Peace, it could be individual pages or paragraphs.
-
You apply the map function to each subset. The map function in this case scans the page (or paragraph) and emits how many times a character’s name is mentioned.
-
There could be an optional step here to combine some of the data. That can help make the computation a little easier to perform in the next step.
-
The reduce function performs a summary operation. It counts the number of times the map function has emitted the character’s name and produces the overall result.
NOTE It’s important to understand that the power of MapReduce in the War and Peace example comes from the fact that the map step can run in parallel on thousands of pages or paragraphs. If this wasn’t the case, then this program would be no different from a sequential count.
Figure 8.1 shows what a theoretical MapReduce architecture looks like. We’ll build something like this soon.

Figure 8.1 These are the steps a fictional MapReduce algorithm could take.
As you may have already guessed, real-world MapReduce applications are often more complex. In a lot of cases, there are intermediary steps between map and reduce that combine or simplify data, and considerations such as locality of data become important in order to minimize overhead. Nevertheless, we can take the idea of splitting a problem into smaller chunks, processing them in parallel, and then combining and reducing them to achieve the outcome you need, and we can do that with Lambda.
8.1.1 How to transcode a video
In the second chapter of this book, you built a serverless pipeline that converted video from one format to another. To do this, you used an AWS service called AWS Elemental MediaConvert. This service takes a video uploaded to an S3 bucket and transcodes it to a range of different formats specified by you. Our goal in this chapter is to do something crazy and implement our own video transcoder service using Lambda. Note that this is just an experiment and an opportunity to explore highly parallelized serverless architectures. Our major requirements for our serverless encoding service are as follows:
-
Build a transcoder that takes a video file and produces a transcoded version in a different format or bit rate. We want complete control over the transcoding process.
-
Use only serverless services in AWS, such as Lambda and S3. Obviously, we are not allowed to use an EC2 or a managed service to do transcoding for us.
-
Build a product that is robust and fast. It should be able to beat a large EC2 instance most of the time.
-
Learn about parallel computing and how to think about solving these problems.
The solution we are about to present works, but it’s not something we recommend running in a production environment. Unless your core business is video transcoding, you should outsource as much of the undifferentiated heavy lifting as possible in order to focus on your own unique problem. In most cases, a managed service like AWS Elemental MediaConvert is better; you don’t have to worry about keeping it running. Take this as just an exercise and an opportunity to learn about MapReduce and parallel computation (you never know when you might face a big problem that requires the skill you may pick up here).
8.1.2 Architecture overview
To transcode a file using Lambda, we need to apply principles of MapReduce. We are not implementing classical MapReduce here; instead, we are taking inspiration from this algorithm to build our transcoder.
An interesting thing about Lambda (that we’ve mentioned before) is that it forces us to think parallel. It’s impossible to process large video files in a Lambda function if you treat a single function like a traditional computer. You’d run out of memory and timeout quickly. If the video file is large enough, the function would either stop after 15 minutes of processing or exhaust all available RAM and crash.
To get around this, we decompose the problem into smaller problems that can be processed within Lambda’s constraints. The implication is that we can try the following to process a large video file:
We need to parallelize as much as possible to get the most out of our serverless super-computer. For example, if some segments are ready to be combined while others are still processing, we should combine the ones that are ready. Performance is the name of the game here. So, with that in mind, here’s an outline for our serverless transcoding algorithm that, let’s say, is designed to transcode a video from one bit rate to another:
-
A user uploads a video file to S3 that invokes a Lambda function.
-
The Lambda function analyzes the file and figures out how to cut up the source file to produce smaller video files (segments) for transcoding.
-
To make things go a little bit faster, we strip away the audio from video and save it to another file. Not having to worry about the audio makes executing steps 4-6 faster.
-
This step performs the split process that creates small video segments for transcoding.
-
Now comes the map process that transcodes segments to the desired format or bit rate. The system can transcode a bunch of these segments in parallel.
-
The map process is followed by a combine step that begins to merge these small video files together.
-
The final step merges audio and video together and presents the file to the user. We have reduced our work to its final output.
Here are the main AWS services and software that we will use to build the transcoder:
-
FFmpeg—In the first edition of our book, we briefly used FFmpeg, a cross-platform library/application created for recording, converting, and streaming audio and video. This is a powerhouse of an application that is used by everyone and anyone ranging from hobbyists to commercial TV channels.
We’ll use ffmpeg in this chapter to do the transcoding, splitting, and merging of video files. We’ll also use a utility called ffprobe to analyze the video file and figure out how to cut it up on keyframes. The ffmpeg and ffprobe binaries are shipped as a Lambda layer (http://mng.bz/N4MN), which allow other Lambda functions to access and run them. You don’t necessarily have to use Lambda layers (you can upload the ffmpeg binary with each function that will use it), but that is redundant, inconvenient, and takes a long time to deploy. Therefore, making ffmpeg available via a Lambda layer is the recommended and preferred approach.
Definition A keyframe stores the complete image in the video stream, while a regular frame stores an incremental change from the previous frame. Cutting on keyframes prevents us from losing information in the video.
-
AWS Lambda—It goes without saying that we’ll use Lambda for nearly everything. Lambda runs ffmpeg and executes most of the logic. We’ll write six functions to analyze the video, extract audio, split the original file, convert segments, merge video segments, and then merge video and audio in the final step.
-
Step Functions—To help us orchestrate this workflow, we’ll rely on Step Functions. This service helps us to define how and in what order our execution steps happen, makes the entire workflow robust, and provides additional visibility into the execution.
-
S3—We’ll use Simple Storage Service (S3) for storing the initial and the final video. We could also use it to store the temporary video chunks, but we’ll use EFS for that. The reason why we chose EFS is because it is easy to mount and access as a filesystem from Lambda. We’ll provide an alternative implementation that uses S3, but it is slightly harder to get right.
-
EFS—We’ll use the Elastic File System (EFS) for our serverless transcoder to store the temporary files that we generate. There will be a lot of small video files. Luckily, EFS can grow and shrink as needed.
-
DynamoDB—Although Step Functions help to manage the overall workflow and execution of Lambda functions, we still need to maintain some state. We need to know whether certain video chunks were created or can be merged. We’ll use DynamoDB to store this information. Everything that’s stored is ephemeral and will be deleted using DynamoDB’s Time to Live (TTL) feature.
Figure 8.2 shows a high-level overview of the system we are about to build. We will jump into individual components in the next section.
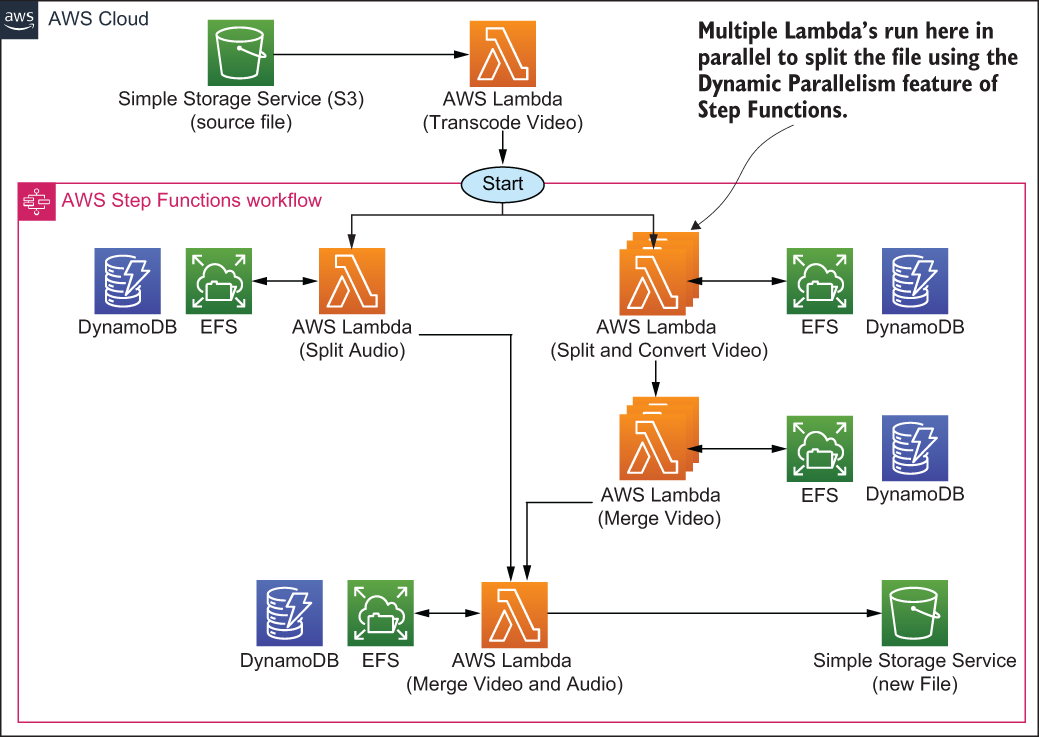
Figure 8.2 This is a simplified view of the serverless transcoder. There are a few more components to it, but we’ve avoided including them in this figure to focus on the essential elements of the architecture.
8.2 Architecture deep dive
Let’s explore the architecture in more detail. There’s nuance to the implementation and how things work. To avoid dealing with some pain later, let’s plan how we will design, build, and deploy the serverless transcoder. Before going any further, recall that the entire idea is to split a giant video file into many small segments, transcode these segments in parallel, and then merge them together into a new file.
8.2.1 Maintaining state
We’ll use DynamoDB to maintain state across the entire operation of the serverless pipeline. It’ll keep track of which videos have been created and which haven’t. To simplify the pipeline and, in particular, to simplify the code that monitors which segments have been created or transcoded, we are going to use a trick. (Before going any further, think about how you would keep track of all small video segments that have been created, transcoded, and merged given that segments will be created and processed in parallel.)
The trick is to create n^2 smaller video segments. Out of one large video file, we should generate 2, or 4, or 8, or 256, or 512, or more segments. Just remember to keep the number of segments at n^2. Why is this? The idea is that once we’ve created and transcoded our video segments, we can begin merging them in any order. Having n^2 segments easily allows us to identify which two neighbor segments can be merged. And, we can keep track of this information in the database.
We’ll create a basic binary tree that helps to make the logic around this algorithm a little easier to manage. Let’s imagine that we have 8 segments. Here’s how the process could take place:
-
Segments 3 and 4 are transcoded quicker than the rest and can be merged together (they are neighbors) into a new segment called 3-4.
-
Then segment 7 is created, but segment 8 is not yet available. The system waits for segment 8 to become ready before merging 7 and 8 together.
-
Segment 8 is created and segments 7 and 8 can be merged together into a new segment 7-8.
-
Then segments 1 and 2 finish transcoding and are merged into a segment 1-2.
-
The good news is that a neighboring segment 3-4 is already available. Therefore, segments 3-4 and 1-2 can be merged together into a new segment called 1-4.
-
Segments 5 and 6 are transcoded and are merged into a segment 5-6.
-
Segment 5-6 has a neighboring segment 7-8. These two segments are merged together to create segment 5-8.
-
Finally, segments 1-4 and 5-8 can be merged together to create the final video that consists of segments 1 to 8.
Because we have n^2 segments, we can keep track of neighboring segments and merge them as soon as both neighbors (the left and the right) become available. Another interesting aspect is that segments themselves can figure out who their neighbors are for merging. A segment with an index that is cleanly divisible by 2 is always on the right, whereas a segment that is not cleanly divisible by 2 is on the left. For example, a segment with an index of 6 is divisible by 2, therefore, we can figure that it’s on the right, and the neighbor it needs to merge with (when it becomes available) has an index of 5. Figure 8.3 illustrates how blocks can be merged together.

Figure 8.3 Segments are merged together into a new video. The beauty of our engine is that neighboring segments can be merged as soon as they are ready. There’s no need to wait for other, nonrelated, segments to finish processing.
DynamoDB is an excellent tool for keeping track of which segments have been created and merged. In fact, we will precompute all possible segments and add them to DynamoDB. Then we will atomically increment counters in DynamoDB to have a record of when segments have been created and merged. This allows the processing engine to figure out which blocks haven’t been merged yet and which need to be done next.
This is an important part of the algorithm, so it’s worth restating it again. Each record in DynamoDB represents two neighboring segments (for example, segment 1 and segment 2). The split-and-convert operation increments a confirmation counter each time a segment is created. When the confirmation counter equals 2, our system knows that the two neighboring segments exist and that they can be merged together.
This information and logic are used in the Split and Convert function and in the Merge Video function. Our algorithm continues to merge segments and increment the confirmation counter in DynamoDB until there’s nothing left to merge.
Our serverless transcoder kicks off once we upload a file into an S3 bucket. An S3 event invokes the Transcode Video Lambda and the process begins. Figure 8.4 shows what this looks like.

Figure 8.4 This is a basic and common serverless architecture. Invoking code from S3 is the bread and butter of Lambda functions.
The Transcode Video function performs the following steps:
-
Analyzes the downloaded video file and extracts metadata from it. Video keyframes are provided in this metadata.
-
Creates the necessary directories in EFS for all future segments that are going to be created.
-
Works out how many segments need to be created based on the number of keyframes.
Remember that we are always creating n^2 segments. This means that we may have to create some fake segments in DynamoDB. These will not really do anything. They are considered as segments that have already been created, so they don’t need to be processed.
-
Creates the necessary records in DynamoDB including any fake records that are needed.
-
Runs a Step Functions workflow with two different inputs. The first parameter tells Step Functions to run a Lambda to extract and save the audio to EFS. The second parameter is an array of objects that specify the start and end times of all segments that need to be created. Step Functions takes this array and applies the Map procedure. It fans out and creates a Lambda function for each object in the array, thus causing the original file to be split up by many Lambda functions in parallel.
The Transcode Video function is an example of a monolithic or “fat” Lambda function because it does a lot of different things. It may not be a bad idea to split it up, but that also comes with its own set of tradeoffs. In the end, whether you think this function should be kept together or not may depend on your personal taste and philosophy. We think that this function is a pragmatic solution for what we need to do, but we wouldn’t be aghast if you decided to split it.
8.2.2 Step Functions
Step Functions plays a central role in our system. This service orchestrates and runs the main workflow that splits the video file into segments, transcodes them, and then merges them. Step Functions also run a function that extracts the audio from the video file and saves it to EFS for safekeeping. The Lambda functions that Step Functions invoke include:
-
Split Audio—Extracts the audio from the video and saves it as a separate file in EFS.
-
Split and Convert Video—Splits the video file from a particular start point (for example, 5 minutes and 25 seconds) to an end point (such as 6 minutes and 25 seconds) and then encodes the new segment to a different format or bit rate.
-
Merge Video—Merges segments together after they have been transcoded. Multiple Merge Video functions will run to merge segments until one final video file is produced.
-
Merge Video and Audio—Merges the newly created video file and the audio file to create the final output. This function uploads the new file back to S3.
tip You don’t have to extract the audio from the video and then transcode just the video file separately. We decided to do that because in our tests, our system ran a bit faster when the video was processed on its own and then recombined with the audio. However, your mileage may vary, so we recommend that you test video transcoding with and without extracting the audio first.
Step Functions is a workflow engine that is fairly customizable. It supports different states like Task (this invokes a Lambda function or passes a parameter to the API of another service) or Choice (this adds branching logic).
The one important state that we’ll use is Map. This state takes in an array and executes the same steps for each entry in that array. Therefore, if we pass in an array with information on how to cut up a video into segments, Map runs enough Lambda functions to process all of those arguments in parallel. This is exactly what we are going to build. We will pass an array to a Split and Convert Lambda function using the Map type. Step Functions will create as many functions as necessary to cut the original video into segments.
Here comes the more interesting part. As soon as the segments are created, Step Functions begins calling the Merge Video function until all segments are merged into a new video. We’ll add some logic to the Step Functions execution workflow to figure out if Merge Video needs to be called. Once all Merge Video tasks are called and processed, Step Functions will take the result from Split Audio and from Merge Video and invoke the final Merge Video and Audio function. Figure 8.5 shows what this process looks like.

Figure 8.5 The Step Functions execution workflow does all the work in our transcoder. The video is split, converted, and merged again using two main functions and a bit of logic.
Now that you know what the Step Functions workflow does, let’s discuss each of the Lambda functions in more detail.
Step Functions runs the Split Audio Lambda function to extract audio from the video file. As we’ve mentioned, this step is done to accelerate the overall workflow because, from there on, the audio portion of the file isn’t considered, and only the video portion is transcoded to another bit rate. We don’t have to do this. We can leave audio and video together, but in our case, our testing showed that doing this improved the overall performance. The Split Audio function executes the following steps:
-
Extracts audio using ffmpeg and saves it to a folder in EFS.
-
Updates the relevant DynamoDB record to record that this was done.
-
Returns a Success message and additional parameters (like the location of the audio file) to the Step Functions orchestrator.
At a later stage, Step Functions invokes the Merge Video Audio function with the parameters that were returned by the Split Audio and Merge Video functions.
The Split and Convert Video function splits the original video file into a segment and converts that segment to a new bit rate or encoding. The original video file doesn’t get changed in this process; instead, the function merely extracts a segment between a start time and an end time, specified in the parameters that are passed to it. These parameters are worked out by the Transcode Video function.
Many hundreds of Split and Convert Video functions can run in parallel. Here are the main actions that it performs:
-
Using ffmpeg, the function creates a new video file from the original one.
-
It increments a confirmation counter in the appropriate DynamoDB record to specify that the segment exists.
-
If the confirmation counter is equal to 2, it then returns to the Step Functions workflow with a Merge message. Otherwise, it returns with a Success message, which stops the execution of that particular Step Functions parallel execution.
You may recall from the previous section that, with DynamoDB, each record represents two neighboring segments. When a record counter is incremented to 2, the function knows that the two neighboring segments exist. The function returns a Merge message to Step Functions, and Step Functions knows that it can begin calling the Merge Video for these segments.
Step Functions calls the Merge Video function when two neighboring segments are ready to be merged into a new single segment. The merge operation happens using ffmpeg, and the new segment is saved to EFS. Here’s what happens in a little more detail:
-
The Merge Video function is invoked with a number of parameters passed to it by Step Functions. These parameters include the left and the right segments.
-
Using ffmpeg, the left and right segments are merged to create a new segment. This new segment is saved to EFS.
-
DynamoDB confirmation is incremented. If there are two confirmations, then the function returns to the workflow with a Merge message.
-
However, if there are two confirmations and the last two remaining segments have been merged, the function returns with a MergeAudio message to the workflow.
As you can see, the Merge Video function creates a bit of a loop. It continues to merge segments, returns the Merge message, and causes Step Functions to invoke itself again. This happens until the last two segments are merged, then the return type is changed to MergeAudio. This is when Step Functions knows that it’s time to combine audio and video and invokes the Merge Video and Audio function.
The final function is Merge Video and Audio. It takes input from the Split Audio and Merge Video functions and merges the audio and the new video files together using ffmpeg. The new file is saved somewhere else (in another directory) on EFS. The function can also upload the new file to an S3 bucket for easier access.
8.3 An alternative architecture
You can build this serverless transcoder without using EFS (or Step Functions for that matter). In fact, our first iteration used only S3 and SNS to perform fan-out. We wanted to present you with an alternative architecture that shows that you don’t necessarily have to use Step Functions or EFS if you don’t want to. This section demonstrates that you can use SNS and S3 instead to achieve the same outcome. It’s nice that AWS provides so many building blocks that we can build our desired architecture in different ways.
Tip One reason for adopting a different architecture could be because you don’t want to pay for Step Functions and EFS. That is a reasonable concern. Using S3 is likely going to be much cheaper than using EFS and will probably perform just as well. Once you get the code working, using S3 is straightforward, and we don’t have a reason not to recommend it. Whether you should use SNS instead of Step Functions is a tougher proposition. SNS is cheaper, but you will lose a lot of the robustness and observability that you get with Step Functions. Perhaps the best solution is to use Step Functions with S3? We’ll leave it to you as an exercise to achieve.
This alternative implementation closely resembles what we created in the previous section except, as we mentioned, we’ll replace Step Functions with SNS and EFS with S3. Figure 8.6 shows what this architecture looks like.

Figure 8.6 The SNS and S3 architecture for the serverless transcoder
This architecture works well, but there are some improvements that can be made to it. For one, the implementation should be improved in case of errors such as the split or merge operation failing. Luckily, there is the Dead Letter Queue (DLQ) feature of Lambda that allows us to save, review, and even replay failed invocations. If you want a challenge, we invite you to implement DLQ for this architecture to make it more resilient to errors.
The second issue is observability and knowing what’s happening with the system. Step Functions provides some level of visibility, but things get a little bit harder with SNS. One tool you can use to help yourself is AWS X-Ray. This AWS service can help you understand the interactions of different services within your system. It goes without saying that CloudWatch is essential too.
Summary
-
MapReduce can work really well with a serverless approach. Lambda invites you to think about parallelization from the start so take advantage of that.
-
You can solve a lot of problems in Lambda and process vast amounts of data by splitting it up into smaller chunks and parallelizing the operations.
-
Step Functions is an excellent service for defining workflows. It allows you to fan-out and fan-in operations.
-
EFS for Lambda is an endless local disk—it grows as much as you need. You can run applications with EFS and Lambda that you couldn’t have run before. Having said that, S3 is still likely to be cheaper so make sure to do your calculations and analysis before choosing EFS.
-
When coming up with an architecture for your system, explore the available options because there will be different alternatives with different tradeoffs.