
9 Code Developer University
- AWS Glue and Amazon Athena
- Using EventBridge to connect system components
- Using Kinesis Firehose and Lambda for at-scale data processing
One idea that we’ve been mulling for a while has been a web app designed to help developers learn programming skills in a fun way with gamification and useful analytics. Our idea, let’s call it Code Developer University (CDU), evolved into a proof-of-concept website with a collection of interesting programming challenges for budding developers to solve and to build skills.
Each challenge would pose a problem. The student would have space to type in their solution and then submit it to our system for processing. The system would run the solution through a battery of tests and decide whether the solution passed or failed. If the solution failed, the user would have a chance to update their code and resubmit again. If the solution passed, the user would advance to the next challenge, receiving between 50 and 500 experience points (XP) based on the difficulty of the problem.
To make the entire experience more interesting and exciting, there would be elements of gamification baked-in throughout the system. For instance, experience points would be used to create various leaderboards. That way, users interested in a friendly competition would be able to compete for a top 10 position. The more challenges solved, the higher the score. These leaderboards would show the overall top 10 performers and then the best performers for each language like Python or JavaScript.
If a student wanted to dig into more data and perhaps see, search, and filter more advanced reports, that would be supported too. A student could, for example, look at the most common mistakes that other users make (anonymized, of course) and learn from that as well.
The original idea was lofty but doable. The key to building this project would be to lean on as many different AWS services as possible. That way we could focus on the unique aspects of the system and leave the rest of the undifferentiated heavy lifting, like authentication, to AWS. At the end, and as you will see, we used the following services to put everything together:
In this chapter, we focus specifically on data, leaderboards, and reporting for CDU. It’s a fascinating part of the system because it uses so many parts of the AWS ecosystem and because you can build something similar just as rapidly yourself. Other features of CDU are quite standard for a web app. There are user accounts, an HTML5 user interface, and all the basic bolts and bits you would expect. If you want to learn how to build such a system yourself, take a look at the first edition of this book, which describes a similar, albeit video-focused web application.
9.1 Solution overview
The leaderboard and reporting aspect of CDU is interesting because it is serverless, scalable, and, frankly, fun to implement. There are many serverless AWS services that make data collection, aggregation, and analysis possible without resorting to traditional reporting and data-warehousing products of yesteryear. Let’s take a look first at the requirements and then the overall solution.
9.1.1 Requirements listed
CDU is a website with user registration and account features, and the ability for users to access and try code exercises and receive points if they are successful in implementing and solving a coding challenge. To that end, the following sections provide a list of high-level requirements for CDU.
-
The user must be able to run their code solution and determine if it passes or fails the tests.
-
If the tests pass, then the solution is considered to be correct.
-
A correct solution awards the user some number of points, which are saved to the user’s profile.
-
There should be leaderboards and advanced reports for users to view.
-
The entire system must be serverless, event-driven, and as automated as much as possible (no intervention from the administrator should be needed to update leaderboards and reports).
-
Points are awarded for the programming language that is used to solve the challenge. For example, if the user codes in Python, then they get points allocated toward Python. If they use JavaScript, then points are allocated to their JavaScript score.
-
The user’s profile should show the overall score (sum of all previous points for all programming languages) and scores for each programming language individually. The user’s profile and scores should be updated in near real time.
-
The user shouldn’t receive points for the same challenge more than once.
-
CDU should feature a leaderboard that shows the top scorers across different programming languages (e.g., Python and JavaScript).
-
An overall leaderboard should show the top performers (regardless of the programming language) for last month, last year, and all time.
-
Leaderboards don’t need to be updated in real time, however, but they should refresh at least every 60 minutes. There should also be a way to refresh them on demand by the administrator.
-
Apart from the leaderboard, users should also have access to more in-depth reports that they can search and filter.
-
The exact implementation of the reports can be left to the data team; however, a basic report could show the best performers, similar to the leaderboard.
-
Reports should be refreshed at least every 60 minutes but could also be refreshed sooner (if needed) by the administrator.
-
Any user, not just the administrator, should have access to the leaderboard.
9.1.2 Solution architecture
Let’s now take a look at a possible architecture that ought to address our major requirements. Figure 9.1 shows most of the major architectural pieces. These include the following three main microservices:
We will break down the solution in the coming sections, but let’s take a look at the high-level architecture shown in figure 9.1. The Code Scoring Service runs a Lambda function that processes submitted code. If it passes the test, information is sent across to the EventBridge, which invokes two other microservices:
-
The Student Profile Service updates the student’s profile in the database and adds to the student’s overall score.
-
The Analytics Service processes and stores the user’s test data in S3, which later enables the creation of the QuickSight dashboards.
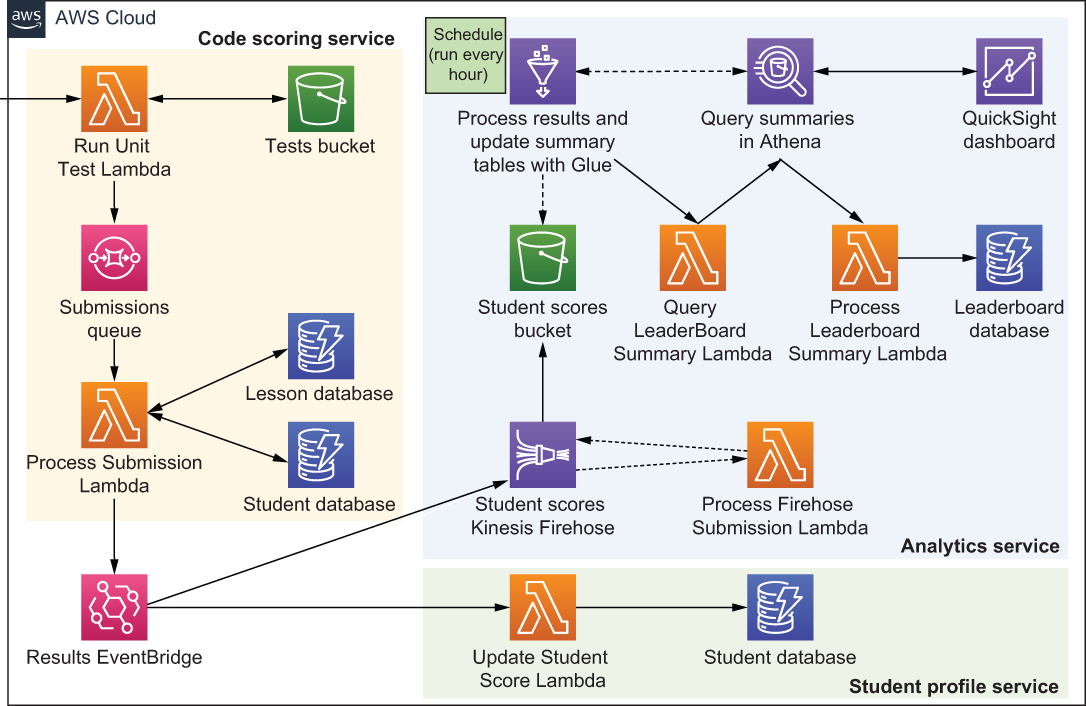
Figure 9.1 The architecture of Code Developer University (CDU) that’s responsible for scoring and leaderboards
There’s actually quite a bit that happens in the Analytics Service. It is covered in detail in section 9.4, but here’s a high-level overview of what actually takes place in this microservice:
-
The message (with the user’s solution) is pushed into Kinesis Firehose, which uses a Lambda function to modify the format of the message so that it can be processed later by other AWS services.
-
Kinesis then stores the newly processed message (as a JSON file) in an S3 bucket.
-
AWS Glue runs on schedule, which is set to trigger every 60 minutes. When that happens, Glue processes the aforementioned S3 bucket and updates a Glue Data Catalog (think: a table with metadata) that points to the data stored in S3.
-
Glue then triggers a Lambda function, which uses Amazon Athena to query the data stored in S3 via the Glue Data Catalog.
-
Once Athena finishes, it triggers another Lambda function that gets the result of the query and updates the appropriate leaderboards saved in DynamoDB.
-
Finally, there’s an Amazon QuickSight report that uses Athena to query the data in the S3 bucket when a user wants to see more information.
There’s a little more detail to all the services, and you may have other questions, which should be cleared up in coming sections. Read on!
9.2 The Code Scoring Service
The purpose of the Code Scoring Service is to receive submitted code from the user and run it against a set of tests. If tests pass, the Run Unit Test Lambda creates a submission, which it puts into the submissions queue. The submission is picked up from the queue by the Process Submission Lambda and is enriched with data from a couple of DynamoDB tables. Finally, the Process Submission Lambda pushes the newly enriched message on to Amazon EventBridge for consumption by other services in our system.
The actual design of the Code Scoring Service is fairly straightforward, but let’s take a look at its design in more detail. Figure 9.2 shows a closeup of the architecture beginning with the Run Unit Test Lambda. This Run Unit Test Lambda function is invoked via HTTPS (via the API Gateway) and receives a zip payload as part of the request body. The zip payload contains the user’s code submission and metadata, such as what challenge the user is attempting and what programming language is being used. The Lambda function looks up the appropriate test in the Tests bucket (it knows which test to grab based on the lesson name) and downloads that test file from S3.

Figure 9.2 The Code Scoring Service runs the user’s code and, if it’s successful, kicks of the rest of the chain of events in our system.
Now the Lambda function can execute the appropriate interpreter or compiler, run the unit test, and test the user’s submission.
The Run Unit Test Lambda by itself is not particularly complex. It needs to know how to run a unit test and then parse the result to figure out if it passed successfully or not. If the test failed, then the function sends back an HTTP response with the output from the interpreter or the compiler. Thus, the user can see the error message, fix the code issue, and resubmit. Otherwise, if it passes, the function sends back a celebratory message to the user and places a message containing the user’s submission on the Submissions SQS queue for further processing.
9.2.1 Submissions Queue
The Submissions Queue is an SQS queue that sits between the only two Lambda functions in this service. When a message is placed in the queue, it leads to an invocation of the Process Submission Lambda that retrieves the message and enriches it with more data before pushing it to the EventBridge. There are a few reasons we do this, including the following:
-
One of the requirements is to prevent the user from receiving points for the same challenge multiple times. The Process Submission Lambda needs to look up the Student DynamoDB table to figure out whether the user has already completed this challenge. If the user has already completed that challenge, then that is noted, and no points are earned.
-
Assuming that the student has solved the challenge for the first time and is supposed to receive points, the Process Submission Lambda also looks up how many points should be awarded from the Lesson database.
-
All of this information, including the message that came from the queue, is combined and pushed to Amazon EventBridge.
By now you might be thinking, “Why not do everything in the initial Run Unit Test Lambda?” The reason is to separate responsibility. The Run Unit Test function is intended to run code and figure out if it passes a test. The second Process Submission Lambda function has to perform database lookups and evaluate whether the student should be awarded points. As a rule of thumb, you should use multiple Lambda functions when you are dealing with different concerns rather than having everything lumped into one. Hence, this is the reason we created two functions and introduced a message queue between them.
Another question you may have is why we used SQS rather than have functions call one another directly. Our recommendation is never to have functions call each other directly unless you are using a feature called Lambda Destinations (which adds a hidden queue between two functions anyway). Lambda Destinations, however, only works for asynchronous invocations, so it wouldn’t have been possible in our case. The Run Unit Test Lambda was invoked synchronously via HTTP. The reason for having a queue between two functions is to reduce coupling (e.g., the two functions have no direct knowledge of one another) and to have an easier time handling errors and retries.
We also could have chosen to use Amazon EventBridge instead, but SQS was acceptable in this scenario. And, if we ever wanted to enable First-In First-Out (FIFO) queues at a later stage, we’d need to use SQS because EventBridge doesn’t support this feature, so that further weighed our decision.
The last action performed by the Process Submission Lambda is to push the message to Amazon EventBridge. As you may recall, this message contains the original submission made by the user together with additional details that consists of information on whether the experience points should be awarded to the user and the amount of those points (this information was obtained by looking up a couple of tables in the Process Submission Lambda function).
9.2.2 Code Scoring Service summary
The Code Scoring Service is a relatively trivial service apart, perhaps, from running the code provided by the user. Even then it’s not too difficult to unzip a file and run an interpreter (or a compiler) within Lambda. One important thing to mention is security. If you are running someone else’s code in a function, you must be prepared that someone will try to subvert it, find a vulnerability to exploit, and do something bad. Therefore, you must follow the principle of least privilege and disallow anything that isn’t critical to the running of your function. This should be a rule for all Lambda functions, but in this instance, you should be doubly careful and vigilant.
9.3 Student Profile Service
The Student Profile Service is small. Its purpose is to increment the number of experience points in the student record in the DynamoDB table. That way, the student can immediately see the cumulative score added to their tally and feel good about their achievement. This service consists of a single Lambda function that communicates with DynamoDB. This function receives an event from EventBridge, reads it, and updates the user profile if the user has received any points. Figure 9.3 shows what this basic service looks like.

Figure 9.3 The Student Profile Service is the simplest one in this entire architecture. It’s a Lambda function that writes to a Dynamo table.
You may remember that earlier (in section 9.1), we posed a question about keeping different tables in sync. Given that the Student Profile Service and the Analytics Service store similar data (namely the user’s score), what happens if one of the services goes down and falls out of sync with the other service? In other words, if there’s a fault in a service that causes a data mismatch, what can we do about it? There are a number of solutions you can think about implementing to address this problem:
-
Serial invocation—One approach is to make the Analytics Service and the Student Profile Service run in serial rather than parallel. That way your system would update the Student Profile Service first and then run through the update procedure in the Analytics Service (invoking it via another EventBridge). If the Analytics Service fails, the system would roll back the change in the Student Profile Service, and both services would continue operating in sync.
-
One source of truth—Alternatively, you could make the Analytics Service your source of truth and then simply copy the data over to the Student Profile Service. That way you could even delete all data in the Student Profile Service and regenerate it as many times as necessary from the Analytics Service.
-
Share the database—Both services could read and write to the same database. That would avoid some problems, but then, we no longer have a microservices architecture in which each service is responsible for its own view of the world. We would end up with a distributed monolith. It must be mentioned that in many circumstances having a distributed monolith is a fine and acceptable solution.
-
Orchestrator—Another approach is to have an orchestrator sit above the two services and monitor what is happening. If there is an error, the orchestrator could run additional actions to compensate for the issue (for example, retry or roll back).
Quite frankly, this is a common situation with a microservices-based approach. How do you keep services in sync without having all microservices coupled to a central database? There are different solutions to this problem but, as with anything in software engineering, they all have different trade-offs. In the case of CDU, we decided to update both services in parallel. If an issue were to occur, we would use the Analytics Service as our source of truth and regenerate the data needed by the Student Profile Service.
9.3.1 Update Student Scores function
The Update Student Score function is shown in listing 9.1. It performs three primary actions:
-
It parses the event received from the EventBridge that has the scores/data.
-
Updates the amount of XP gained for the topic like JavaScript or Python.
Listing 9.1 Updating the Student Score Lambda
'use strict';
const AWS = require('aws-sdk');
const sns = new AWS.SNS();
const dynamoDB = require('aws-sdk/clients/dynamodb');
const doc = new dynamoDB.DocumentClient();
const updateTotalXP = (record, lessons) => {
const date = new Date(Date.now()).toISOString();
const xp = lessons.filter(m => m.xp)
➥ .map(m => m.xp)
➥ .reduce((a, b) => a+b); ❶
const params = { ❷
TableName: process.env.USER_DATABASE,
Key: {
userId: record.username
},
UpdateExpression: `set
modified = :date,
xp.#total = :xp`,
ExpressionAttributeNames: {
'#total': 'total'
},
ExpressionAttributeValues: {
':date': date,
':xp': xp
},
ReturnValues: 'ALL_NEW'
};
return doc.update(params).promise();
}
const updateTopicXP = (record) => {
const date = new Date(Date.now()).toISOString();
const lesson = {
lesson: record.lesson,
topic: record.topic,
modified: date,
xp: record.xp,
isCompleted: record.isCompleted
};
const params = {
TableName: process.env.USER_DATABASE,
Key: {
userId: record.username
},
UpdateExpression: `set
modified = :date,
lessons = list_append(if_not_exists(lessons,
➥ :empty_list), :lesson), ❸
xp.${record.topic} =
➥ if_not_exists(xp.${record.topic}, :zero) + :xp`,
ExpressionAttributeValues: {
':lesson': [ lesson ], ❸
':empty_list': [], ❸
':zero': 0,
':date': date,
':xp': parseInt(record.xp, 10)
},
ReturnValues: 'ALL_NEW'
};
return doc.update(params).promise();
}
exports.handler = async (event, context) => {
try {
const record = event.detail; ❹
if (record.isCompleted) {
const user = await updateTopicXP(record);
if (user.Attributes.lessons.length > 0) {
await updateTotalXP(record, user.Attributes.lessons);
}
}
} catch (error) {
console.log(error);
}
}❶ Calculates the total XP for a user by summing up the XP for all of the lessons. This is woefully inefficient to do each time but OK for an example. Can you think of a better way?
❷ This params object has all the necessary attributes needed to update the relevant DynamoDB table. Note the ‘total’ in the ExpressionAttributeNames. It’s a reserved keyword so it has to be specified using ExpressionAttributeNames.
❸ This update expression appends a lesson to a list of lessons in DynamoDB. Otherwise, if a list doesn’t exist, a new and empty one is created.
❹ This function is invoked via the EventBridge. The parameter event.detail contains the information that was sent over from the Process Submission Lambda function in the previous section.
The Student Profile Service is a small microservice with a single Lambda function. Its purpose is to update a DynamoDB table and that’s pretty much as basic as you can get. The next service, however, is not as straightforward. Let’s take a look at it now.
9.4 Analytics Service
This is going to be a big one, so grab yourself a tea or a coffee before jumping in. If you recall, the purpose of the Analytics Service is twofold:
The data collected and processed by the Analytics Service must enable us to achieve those two aims. Let’s take a look at the architecture in figure 9.4. The steps that the Analytics Service takes are as follows:
-
The EventBridge service pushes a message from the Code Scoring Service on to the Student Scores Kinesis Firehose.
-
The Firehose runs a Lambda that processes and transforms each incoming message into a format that is palatable for Amazon Glue to work on later.
-
After the message is transformed by Lambda, Firehose stores it in an S3 bucket.
-
Every hour (or on demand) AWS Glue runs and crawls the messages stored in the S3 bucket. It updates a table within the AWS Glue Data Catalog with the metadata based on the crawl.
-
Once Glue is finished processing, the Query Leaderboard Summary function is run. The Lambda function invokes Athena that runs a query to work out the leaderboard.
-
Athena accesses Glue and S3 and extracts the relevant data for the query. Once the query is complete, the Process Leaderboard Summary Lambda is invoked.
-
This Process Leaderboard Summary Lambda function receives the result of the query from Athena, reads it, and updates the Leaderboard DynamoDB table.
-
Finally, the QuickSight Dashboard component uses Athena to execute queries based on what the user is trying to see in a QuickSight report.

Figure 9.4 The Analytics Service architecture includes Glue, Athena, DynamoDB, Kinesis Firehose, QuickSight, and Lambda.
You may agree that this is quite a lot to take in one go, so let’s break down the most interesting components. We’ll do that in the following sections.
9.4.1 Kinesis Firehose
Kinesis Firehose provides a way to capture and stream data into Elasticsearch, Redshift, and S3. AWS says that it’s the “. . . easiest way to reliably load streaming data into data lakes, data stores, and analytics services” (https://aws.amazon.com/kinesis/data-firehose/), which sounds perfect for our use case. Kinesis Firehose, unlike other Kinesis services, is serverless, meaning that you don’t need to worry about scaling partitions or sharding as is the case with, say, Kinesis Data Stream. It is all done for you automatically. Another nice feature of Firehose is that it can run Lambda for messages as they are ingested. Lambda can be used to convert raw streaming data to other, more useful, formats and this is exactly what we would do. In our use case, we can use a Lambda function to convert the messages to a JSON format that would later be read by the AWS Glue service before storing them in S3.
Listing 9.2 shows a Kinesis Firehose processing function that takes a message, processes it, creates a new record with a different set of fields, and pushes it back to Firehose for storage in S3. In this listing, we are extracting only a few properties from the original message because we don’t want to keep everything. For example, we may discard the user’s submitted source code because we care only if they’ve passed the test or not. There are a few things to keep in mind in this listing:
-
All transformed records must contain a recordId, result, and data. Otherwise, Kinesis Firehose rejects the entire record and treats it as a “transformation failure.”
-
The property called recordId is passed from Firehose to Lambda. The transformed record has to contain the same recordId as the original. A mismatch results in transformation failure (so, don’t make your own or append anything to it).
-
The property result must either be Ok (record transformed) or Dropped (record was dropped intentionally). The only other allowed value is ProcessingFailed if you want to flag that the transformation couldn’t take place.
-
The property data is your base-64 encoded transformed record.
Listing 9.2 Kinesis Firehose processing function
'use strict';
exports.handler = (event, context) => {
let records = [];
for (let i = 0; i < event.records.length; i++) {
const payload = Buffer.from(
➥ event.records[i].data, 'base64')
➥ .toString('utf-8'); ❶
const data = JSON.parse(payload); ❶
const record = { ❷
username: data.detail.username,
name: data.detail.user.name,
lesson: data.detail.lesson,
topic: data.detail.topic,
xp: data.detail.xp,
hasPassedTests: (data.detail.hasPassedTests || false),
runTests: (data.detail.runTests || false),
isCompleted: (data.detail.isCompleted || false),
time: data.time,
};
records.push({ ❸
recordId: event.records[i].recordId,
result: 'Ok',
data: Buffer.from(JSON.stringify(record)).toString('base64')
});
}
console.log(`Return: ${ JSON.stringify({records}) }`);
return Promise.resolve({
records
});
};❶ The original message that was pushed to Firehose. You can now extract the relevant bits you might want to save in S3.
❷ The record you create here and store in S3 will be JSON.
❸ All transformed records must contain a property called recordId, result, and data. Transformation is the ultimate goal for this Lambda.
Finally, you must ensure that your response doesn’t exceed 6 MB. Otherwise, Firehose will refuse to play along.
9.4.2 AWS Glue and Amazon Athena
AWS Glue is a serverless ETL (extract, transform, and load) service that can scour an S3 bucket with a crawler and update a central metadata repository called the Glue Data Catalog. You and other services can then use this metadata repository to quickly search for relevant information among the records scattered in S3. Glue never actually moves or copies any data. The tables with metadata it creates in the Glue Data Catalog point to the data in S3 (or other sources like Amazon Redshift or RDS). This means that the Data Catalog can be recreated from the original data if necessary.
Amazon Athena is a serverless query service that can analyze data in S3 using standard SQL. If you haven’t tried Athena, you have to give it a go. You simply point it to S3, define the schema, and begin querying using SQL. What’s even nicer is that it integrates closely with Glue and its Data Catalog (which takes care of the schema). Once you have AWS Glue configured and the Data Catalog created, you can begin querying Athena immediately.
Listing 9.3 shows how to perform a query. An important thing to note is that the query is asynchronous. You will not get a response once you’ve run it. You have to start the query execution and then, using CloudWatch events, react to when you get the result. Luckily everything can be accomplished with two Lambda functions. Listing 9.3 shows how to execute a query and listing 9.4 shows how to process it if you have hooked up CloudWatch events to respond.
Listing 9.3 Query Leaderboard Summary Lambda
'use strict';
const AWS = require('aws-sdk');
const athena = new AWS.Athena();
const runQuery = (view) => {
const params = {
QueryString: `SELECT * FROM "${view}"`, ❶
QueryExecutionContext: {
Catalog: process.env.ATHENA_DATA_SOURCE, ❷
Database: process.env.ATHENA_DATABASE ❷
}, ❷
WorkGroup: process.env.ATHENA_WORKGROUP ❷
};
return athena.startQueryExecution(params).promise();
}
exports.handler = async (event) => {
let promises = [];
promises.push(runQuery(process.env ❸
➥ .ATHENA_LEADERBOARD_VIEW_TOPICS)); ❸
promises.push(runQuery(process.env ❸
➥ .ATHENA_LEADERBOARD_VIEW_OVERALL)); ❸
const query = await Promise.all(promises);
console.log('Athena Query Id', query);
}❶ Views are supported by Athena and are as useful as regular SQL.
❷ Parameters such as the Catalog, Database and WorkGroup are set up in Athena when you configure it.
❸ Views are supported by Athena and are as useful as regular SQL.
Listing 9.4 shows a Process Leaderboard Lambda function that responds to a CloudWatch event that contains information about the query performed in listing 9.3. Note that the actual result (meaning the data itself) must be retrieved from Athena using the GetQueryResults API call. When the Process Leaderboard Summary function is invoked, only queryExecutionId is passed into it, but that’s enough to perform the GetQueryResults API call to get the data. The code in the following listing is quite lengthy because, apart from showing how to get a result out of Athena, it demonstrates how to update a DynamoDB table.
Listing 9.4 Process Leaderboard Summary Lambda
'use strict';
const AWS = require('aws-sdk');
const athena = new AWS.Athena();
const dynamodb = new AWS.DynamoDB.DocumentClient();
const getQueryResults = (queryExecutionId) => {
const params = {
QueryExecutionId: queryExecutionId
};
return athena.getQueryResults(params).promise(); ❶
}
const updateDynamoLeaderboard = (rows, index) => {
let transactItems = [];
const date = new Date(Date.now()).toISOString();
//
// Skip the first row because it's the label
// Data: [
// { VarCharValue: 'topic' },
// { VarCharValue: 'username' },
// { VarCharValue: 'name' },
// { VarCharValue: 'score' },
// { VarCharValue: 'rn' }
// ]
//
for (let i = 0; i < rows.length; i++) {
const row = rows[i].Data;
const params = {
TableName: process.env.LEADERBOARD_DATABASE,
Key: {
uniqueId: row[1].VarCharValue, //username
type: row[0].VarCharValue //topic
},
UpdateExpression: `set
#name = :name,
modified = :date,
#rank = :rank,
score = :score`,
ExpressionAttributeNames: {
'#name': 'name',
'#rank': 'rank'
},
ExpressionAttributeValues: {
':date': date,
':name': row[2].VarCharValue,
':score': parseInt(row[3].VarCharValue, 10),
':rank': parseInt(row[4].VarCharValue, 10)
},
ReturnValues: 'ALL_NEW'
}
transactItems.push({Update: params});
}
return dynamodb.transactWrite({TransactItems:transactItems}).promise();
}
exports.handler = async (event) => {
try {
if (event.detail
➥ .currentState === 'SUCCEEDED') { ❷
const queryExecutionId =
➥ event.detail.queryExecutionId;
const result =
➥ await getQueryResults(queryExecutionId);
result.ResultSet.Rows.shift(); ❸
if (result.ResultSet.Rows.length > 0) {
const maxItemsPerTransaction = 20; ❹
for (let i = 0; i <
➥ result.ResultSet.Rows.length/maxItemsPerTransaction; i++) {
const factor =
➥ result.ResultSet.Rows.length/maxItemsPerTransaction;
const remainder =
➥ result.ResultSet.Rows.length%maxItemsPerTransaction;
let data =
➥ result.ResultSet.Rows.slice(i*maxItemsPerTransaction,
➥ i*maxItemsPerTransaction + Math.max(maxItemsPerTransaction,
➥ remainder)); ❺
const update = await updateDynamoLeaderboard(data,
➥ i*maxItemsPerTransaction);
}
}
} else {
console.log('Query Unsuccessful');
}
} catch (error) {
console.log(error);
}
}❶ You need the QueryExecutionId to run GetQueryResults, then the result of the query is yours.
❷ We only ever want to retrieve the results and save them if the query executes successfully. Luckily, this parameter checks if it’s all good.
❸ The first row in the array contains labels for the columns (e.g., topic, score, etc.). Shifting that row removes it because we are only interested in the values.
❹ Updates in chunks of 20 items. DynamoDB can handle 25 items in a transaction, but we only do 20 here instead.
❺ We use a little bit of math to retrieve the necessary records (slice) from the array. This formula gets 20 or fewer rows to store in DynamoDB at a time.
Serverless architectures are typically push-based and event-driven. You should try to avoid polling whenever you can. We could have polled for the status of the query and then called the Lambda function to process the result, but it would have been more complex and error prone. Instead, we rely on CloudWatch events to get notified about the query state transition. Interestingly, this feature wasn’t always available, and people had to poll. There really was no other option, so it’s good to see AWS adding the necessary support and enabling our serverless dream to continue.
9.4.3 QuickSight
Amazon QuickSight is AWS’s Business Intelligence (BI) service in the vein of Tableau. You can use it to build dashboards of all kinds and embed them into your website. QuickSight has some really interesting features, like its ability to formulate answers using natural language (this is underpinned by machine learning).
Truth be told, however, at the time of writing, QuickSight is an underwhelming AWS service. It’s slow, reasonably pricey, and weirdly different enough from other AWS services to necessitate a steeper learning curve. Nevertheless, it is also serverless, and it allows us to stay within the AWS environment, which is an advantage. We hope that AWS substantially improves QuickSight over the coming months and years. If you are looking for a BI solution, you should have a look at QuickSight but evaluate other options too.
We used QuickSight to create dashboards that read data straight from S3 via Athena for the CDU. Describing how to use QuickSight is out of scope for this chapter, but it does have a fairly intuitive interface that you can click through. QuickSight isn’t supported by CloudFormation (at least at the time of writing this in the second half of 2021), so creating consistent, repeatable dashboards is challenging and that’s a bummer. However, if your data is in S3 and can be queried with Athena, you can always recreate your dashboards. The main thing is having the data in the right format and place, which you will have with the tools described in this chapter.
In summary, to build an Analytics Service, AWS services such as Kinesis Firehose, Athena, and Glue can be what you need. These are serverless services, meaning that you don’t have to think about scaling or managing them the same way that you’d need to think about Amazon Redshift. Nevertheless, if you decide to embark on a serverless journey with these services make sure to do your evaluation first.
Athena’s charges are based on the amount of data scanned in each query; Redshift is priced based on the size of the instance. There could be circumstances where Athena is cheaper, but Redshift is faster, so you should spend a little bit of time with Excel projecting cost. Nevertheless, in many cases, especially for smaller data sets, the combination of Athena and Glue is more than enough for most needs.
Summary
-
AWS has a variety of services and ways to capture, transform, analyze, and report on data relevant to your application.
-
Capturing, processing, and reporting on data using services such as EventBridge, DynamoDB, Amazon Glue, Amazon Athena, and Amazon QuickSight to build a web application with three microservices leaves us with a few takeaways, including the following:
-
Amazon QuickSight is slow (and it can be expensive). If you need to show leaderboards, cache them in something like DynamoDB for quick retrieval.
-
Glue and Athena are fantastic tools. Glue can index the data stored in S3, and Athena can search across it using standard SQL. The result is less “lifting” and coding for you.
-
Kinesis Firehose has a fantastic feature that allows you to modify records before they get to whatever destination they are going to. This is a fantastic feature that’s worth the price of admission.
-
Do not have Lambda functions call each directly unless you are using Lambda Destinations. Always use a queue like SQS or EventBridge if Lambda Destinations is not available.
-
EventBridge is an excellent message bus for use within AWS. Apart from not having FIFO functionality (this could change by the time you read this), it has a ton of excellent features, and we highly recommended it.
-