
11
Working with Internal and External Data in SharePoint 2010
By Paul Olenick
At its highest level, SharePoint data falls into one of two categories: internal or external. This chapter covers tools, options, and considerations for accessing, surfacing, and manipulating data in various scenarios.
Although many core concepts remain the same, the story around working with data has improved significantly in SharePoint 2010. Lists have been enhanced in the areas of relationships and validation, and managing large lists (a known pain point in previous versions) has become easier with query throttling. The Business Data Catalog (BDC) has been overhauled, and introduces new concepts such as the external list, which allows end users to interact with external data as if it was internal (including the capability to write back to the data source).
SharePoint developers will be pleased to learn about amazing new features in SharePoint 2010 such as multiple APIs to accommodate just about any programming scenario, additional events to hook in to for firing their custom code, and support for LINQ. SharePoint 2010 (and supporting technologies) allow architects to plan for special considerations as well, such as working with data in the cloud, and working with SharePoint data while offline.
These enhancements (along with many others) represent a massive improvement in the experience of working with SharePoint data. They provide the architect with an even more robust set of tools to continue creating valuable, manageable, and responsible business solutions.
This chapter provides an introduction to core concepts, important improvements, and guidance on key design decisions related to working with data.
MANIPULATING INTERNAL DATA
With a few exceptions, internal SharePoint data is stored in lists and libraries. Indeed, the SharePoint list is one of the most fundamental constructs within SharePoint, but it is also one of the most powerful.
Out of the box, there is a capability to create complex views of list data, including grouping, filtering, totals, and more. Powerful field types (such as calculated columns, lookups, and managed metadata columns) can be employed to create dynamic and robust solutions. No-code workflows (either prebuilt, or those a user creates with SharePoint Designer) can be bound to lists to manipulate data, or kick off other processes. It is also now possible to enforce unique values for a column, which, in the past, required custom development to accomplish.
If requirements cannot be met with out-of-the-box list functionality, custom list definitions, custom field types, event handlers, and more can be developed to extend SharePoint lists to meet most any need.
INTEGRATING EXTERNAL DATA
Those who have worked with SharePoint in different business scenarios know that it is a platform offering many things to different organizations. It is a document repository, a content management system, a web authoring tool, a website, an intranet portal, an extranet, a collaboration tool, a solutions platform, and so on. As companies have realized the power and flexibility of SharePoint, some now view SharePoint as an information “hub.”
Enterprises typically have a myriad of separate systems with disparate data stores throughout their environments. SharePoint can be employed to sit in the middle, and connect to the various systems and data stores to surface, relate, contextualize, write to, and search this information. Even the most basic modern SharePoint deployment usually connects to Active Directory (AD), crawls various systems, file shares, Microsoft Exchange, and data stores with the Enterprise Search functionality, and interacts with line-of-business (LOB) applications through the Business Connectivity Services (BCS) — all without writing code.
SharePoint 2010 offers a rich set of new tools and features that allow integration and interaction with external data — in some cases, delivering the capability to work with the data as if it is native to SharePoint.
The following section explores new features and capabilities of SharePoint's workhorse — the SharePoint list.
LIST DATA PLATFORM CAPABILITIES
The updates to (and investment in) lists in SharePoint 2010 will undoubtedly have significant impact on architects and end users alike. Because lists represent one of SharePoint's fundamental building blocks, those who are using SharePoint are probably interacting with a list whether they know it or not. Improvements to lists in SharePoint 2010 include relationships and lookups, joins and projections, field validation, and tools for managing large lists.
Lists Relationships and Lookups
One of the pain points in previous versions of SharePoint was the limitation around working with lists as relational. By design, SharePoint lists are “flat,” and attempts to treat the data relationally often led to frustration. It was possible to create relationships between lists. However, there was no referential integrity. In SharePoint 2010, investment has been made in this regard, resulting in new features that allow more robust relationships between SharePoint lists.
Relationships between SharePoint lists are created using lookup columns. This concept is not new to SharePoint. However, the lookup column has undergone an overhaul in SharePoint 2010, making it a more robust solution for defining relationships.
Two major improvements for the lookup column are:
- The capability to display additional fields — In past versions of SharePoint, only one field from a lookup list could be displayed in the destination list views. There is now the capability to display additional fields from the lookup list.
- Referential Integrity — Lookup columns in SharePoint 2010 have an additional relationship setting where it is possible to define the desired behavior when a value is deleted from a lookup list.
![]() Referential integrity is not enforced on lookups configured to allow multiple values.
Referential integrity is not enforced on lookups configured to allow multiple values.
For example, Figure 11-1 shows a musical instrument manufacturer called Notable Instruments that has created two lists in its SharePoint site. The “Instrument Name” list contains a list of all the instruments it currently sells. The “Inst Family” list contains categories of instruments and their descriptions.

FIGURE 11-1: Lookup column with additional (projected) field
To create a relationship between these two lists, the manufacturer has added a lookup column in the “Instruments” list called “Inst Family” that looks up values from the “Instrument Family” list. This is shown in Figure 11-2.
Notice that an additional field called “Inst Family Description” has been selected in the column configuration. This field becomes available for display in the views for the “Instruments” list (see Figure 11-1). If you were creating this relationship via the API, this would be called a projected field (more on this later in this chapter).
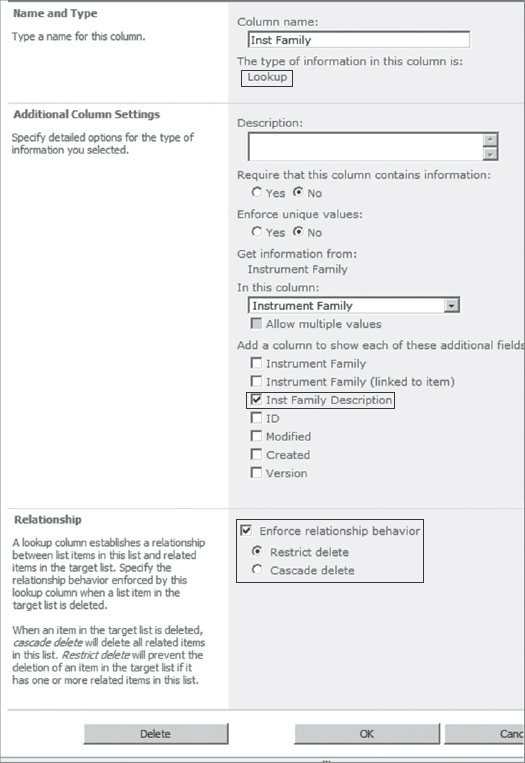
FIGURE 11-2: Lookup column configuration
Notice also that in “Relationship settings” in the lookup column, the “Enforce relationship behavior” checkbox is selected, and “Restrict delete” has been chosen. With this configuration, if an attempt is made to delete a value from the “Instrument Family” list, and that value has a related item in the “Instruments” list, the user will be presented with an error message, as shown in Figure 11-3.
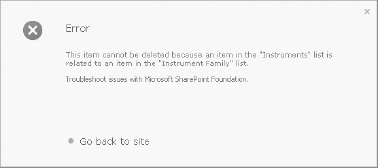
FIGURE 11-3: “Restrict delete” message
If instead, the “Cascade delete” option were selected, users would see a warning message indicating that all related items in the “Instruments” list would be deleted, as shown in Figure 11-4.
List Joins and Projections
Another valuable new functionality in SharePoint 2010 is the capability to create list joins for views and queries. Both the SPView and SPQuery objects have Joins and ProjectedFields properties that developers may use to define joins via the API.
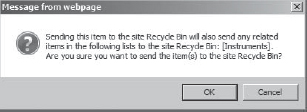
FIGURE 11-14 “Cascade delete” message
![]() It is outside the scope of this book to provide detailed examples. However, the book Professional SharePoint 2010 Development (Indianapolis: Wiley, 2010) has an excellent section on this subject, including code samples.
It is outside the scope of this book to provide detailed examples. However, the book Professional SharePoint 2010 Development (Indianapolis: Wiley, 2010) has an excellent section on this subject, including code samples.
Following are some important notes and limitations to keep in mind:
- Options for joins are limited to left and inner joins (no right joins).
- When creating a join, the field in the primary list must be a lookup column, and point to the field that is being joined on in the foreign list. This dictates that all joins will be performed on lists that already have a relationship by means of a lookup column.
Because of such limitations, more complex joins or requirements for a true relational database should still be accomplished using SQL Server, and can be integrated into SharePoint via the BCS.
List Validation
In prior versions of SharePoint, there were virtually no out-of-the-box options for validating user input within a list form. Instead, developers were tasked with developing client-side script (which sometimes meant unghosting list form pages), a custom form, an event handler, or an InfoPath form to handle validation requirements.
SharePoint 2010 now includes list validation. It is now possible to configure field validation out of the box at either the list level or site-column level. The aforementioned custom solutions are all still viable options, and should be evaluated if the out-of-the-box list validation proves insufficient for a given requirement.
Creating the validation formula will be familiar to those who have experience with formulas in Excel, or with SharePoint calculated columns. When a user submits the form, if the conditions are not met, users are presented with a configurable message.
Consider the following example, as illustrated in Figure 11-5 and Figure 11-6. The Human Resources department at a company creates a list called “PTO Request” from which employees can request days off. One of the fields users must fill out is “Desired Day Off.” The creator of this list would like to ensure that the user has entered a date in the future before the request is submitted. To do this, the creator has configured validation on the “Desired Day Off” column.
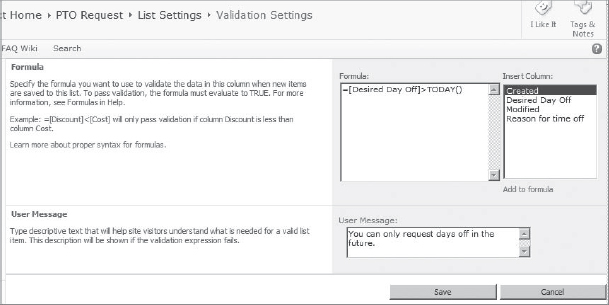
FIGURE 11-5: List validation message
Let's take a quick look at the simple logic of the validation. If the value in the “Desired Day Off” field is less than today's date, do not submit the request, and present the user with a message that reads “You can only request days off in the future.”
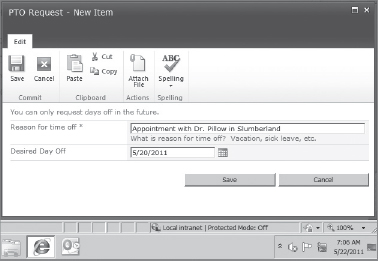
FIGURE 11-6: List validation configuration
This same validation configuration could be implemented via the API instead of the graphical user interface (GUI).
Large Query Throttling
Best practices and performance considerations regarding large SharePoint lists have always been hot topics in the SharePoint community. A statistic you are likely to hear regarding this subject is that performance will tend to degrade with more than 2,000 items. This number really refers to the number of items that Microsoft recommends retrieving in a view — the list itself can contain millions of items. To address this, SharePoint only allows views of 2,000 items or less. However, in other scenarios (such as accessing data via the API), governance via a list view will not suffice.
New to SharePoint 2010 is an administrative feature called query throttling. Query throttling enables SharePoint administrators to head off performance degradation by governing the number of items that can be returned when a query is executed. If a query returns a number of items in excess of this “list view threshold,” an error is thrown, and no results are returned.
Administrators configure query throttling via Central Administration at the application level by clicking Central Administration ![]() Manage Web Applications
Manage Web Applications ![]() Resource Throttling, as shown in Figure 11-7.
Resource Throttling, as shown in Figure 11-7.
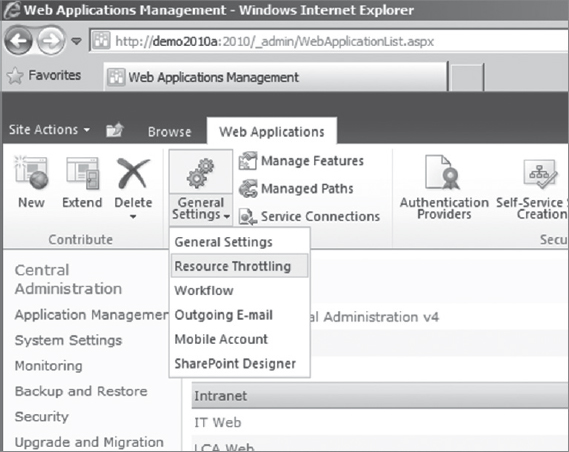
FIGURE 11-7: Resource throttling
As shown in Figure 11-8, a number of settings can be configured here, including the following:
- The maximum number of items that can be returned from a database operation (list view threshold). A separate threshold can be set for administrators.
- Whether to allow particular users to override the list view threshold when accessing lists via the object model.
- The maximum number of lookup, person/group, or workflow status fields that can be contained in a database request.

- A daily time window reflecting a period during which queries that surpass the list view threshold can be completed. (This allows for scheduling of maintenance operations during off-peak hours.)
This section has described new features and functionalities of the SharePoint list, which is the principal object for storing data within SharePoint. The following section takes you on a tour of the BCS, which is the new feature set that allows easy integration of data that resides outside of SharePoint.
BUSINESS CONNECTIVITY SERVICES
One of the things that makes SharePoint such a powerful platform is its capability to integrate and surface data from disparate systems throughout the enterprise. The key mechanism for accomplishing this is the BCS. This section describes key upgrades to the features set, delves into a few of the underlying constructs, and addresses security and authentication considerations.
Integrating External Data
The BDC was one of the most powerful feature sets in SharePoint 2007. It allowed administrators and developers to integrate LOB applications and other external data sources into their SharePoint 2007 applications. As powerful as the BDC was, there were major limitations. For example, the BDC was not available in the free version of SharePoint 2007, Windows SharePoint Services (WSS). Creating the application definitions required the authoring of complex XML files (or use of third-party tools to create them), and, out of the box, it did not support writing back to external data sources.
In SharePoint 2010, the BDC has been upgraded and renamed Business Connectivity Services (BCS). The BCS is a group of Features and services that allow the integration of external data. The enhancements to this Feature set are many, but a few of the major improvements are inclusion of BCS in SharePoint Foundation (the free version of SharePoint 2010), wizard-based configuration of BCS applications, and, most notably, BCS connections are read/write.
![]() See Chapter 29 for a deeper dive into the BCS.
See Chapter 29 for a deeper dive into the BCS.
External Content Types
The External Content Type (ECT) is a new concept to SharePoint. It is similar to a List Content Type in that it is a reusable set of metadata that can be used to drive lists that end users interact with. However, ECTs also contain information about authentication, connectivity to, and the desired behaviors (that is, CRUD operations) associated with their external data sources.
There are a few methods for adding ECTs to the BCS, including the following:
- Microsoft SharePoint Designer 2010 offers a wizard experience for defining and adding new ECTs.
- Microsoft Visual Studio 2010 ships with the Business Connectivity Services Model Designer that developers can use to define and package ECTs for deployment via the Solution Framework.
- Administrators can import application models as XML files into the BCS service application from Central Administration.
Once added, administrators can modify permissions, or add more Features such as actions and profile pages.
External Lists
External lists are the centerpiece of BCS from the perspective of the user experience. They allow end users to interact with external data as if it is a native SharePoint list. As such, users can create views of (including sorting, filtering, grouping, and so on), edit, add columns to, and otherwise manipulate external data as if it were any other SharePoint list.
As an example, let's say that an online fitness retailer uses SharePoint 2010 to host its intranet where it stores information about its various products. It has a separate custom Customer Relationship Management (CRM) application that is built on .NET with a SQL back end.
In the past, if employees were in the intranet and wanted to access customer information, they had to leave the intranet and open the CRM application. Using the BCS, an administrator could create an ECT defining a connection to the Customers table of the CRM application, create an external list based on the ECT, and end users would be able to view, add, edit, and delete customers from the database without ever leaving the portal.
This is obviously a simple example, but with some creativity and planning, this capability has vast potential for improving the way users work.
Security and Authentication Models
When allowing users to interact with external data in the real world, administrators must address security and authentication. Within the BCS service application, administrators assign permissions for the BCS objects. If users do not have permissions to the BCS object, they will not be able to view the external data, even if they have explicit access at the external system level. These permissions are assigned via Central Administration within the BCS service application.
BCS connections support three authentication models: Pass-Through, Single Sign-On, and RevertToSelf.
Pass-Through Authentication
Pass-Through authentication refers to a model in which the logged-on user's credentials are “passed through” to the back-end system for authentication. It is important to note that, in most cases, if a SharePoint environment is configured for NT LAN Manager (NTLM) authentication, and your external data source requires authentication, the request will fail.
This is because the request results in a double-hop scenario, as shown in Figure 11-9. The first “hop” is from the client computer to the SharePoint server, and the second “hop” is from SharePoint to the external system. This type of “delegation” is not supported by NTLM. Therefore, in most configurations, if Pass-Through is the desired authentication model, claims-based authentication or Kerberos must be used.
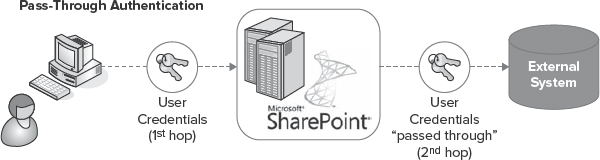
FIGURE 11-9: Pass-Through authentication
![]() For more information on claims-based authentication and Kerberos, see Chapter 19.
For more information on claims-based authentication and Kerberos, see Chapter 19.
Single Sign-On
Single Sign-On (SSO) is an ideal option for authenticating users to external systems for a number of reasons.
First of all, it avoids the double-hop problem by storing and mapping credentials within the SharePoint Secure Store Service (SSS) application. Technically, there are still two hops, but they are broken up into two discrete requests, as shown in Figure 11-10. The first is from the client computer to SharePoint. Then SharePoint makes a separate request to the external system using whichever account the administrator has mapped to the current user for this particular BCS application.

FIGURE 11-10: SSO with Secure Store Service
Another positive for using SSO is that users do not need permissions to the external data source at all. The administrator will assign a service account for this purpose with the minimum permissions necessary. The administrator can then map any number of users to this same service account.
There are performance gains with this model based on how connections from a single logon are handled versus multiple accounts. There is a downside to this approach, though. The external system will not know who has accessed it, because all requests will be made using a single service account. It is possible to work around this issue by using the UserContextFilter within BCS application models.
RevertToSelf
RevertToSelf is a holdover from SharePoint 2007. This model uses the identity of the IIS application pool for the given context to make the request. This will vary depending on from where or from what process the request is being made.
In the case of an external list, it would be the identity of the application pool for the application that is serving the page. This can pose real security risks, and, for this reason, in most scenarios, using RevertToSelf in a production environment is not considered a best practice. RevertToSelf is disabled by default, and administrators must enable it using the SharePoint 2010 management shell. Figure 11-11 shows this process.
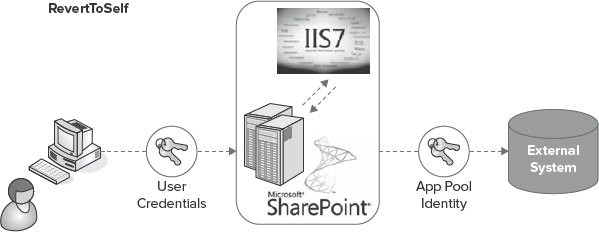
FIGURE 11-11: RevertToSelf authentication
DATA INTEGRATION EXTENSIBILITY
A connector must be developed in scenarios with requirements to connect to systems not directly supported by the BCS. You have two types of connectors to choose from: .NET Assembly Connectors and Custom Connectors.
The appropriate connector type for a given scenario will depend on the specifics of the requirement. In general, however, the choice will come down to flexibility versus ease of development and deployment.
.NET Assembly Connectors
The ease of developing and deploying .NET Assembly Connectors makes them an attractive option. SharePoint Designer and Visual Studio 2010 each have tooling to support development of connectors, and deployment to the BDC store is very simple using the ClickOnce mechanism. Also .NET Connector DLLs are stored in the BDC store, instead of the Global Assembly Cache (GAC), which, in some organizations, is desired (if not required).
.NET Assembly Connectors do, however, have two major limitations:
- .NET Assembly Connectors require one-to-one mapping of an ECT to a .NET Framework class.
- If changes are made to the back-end interface, the assembly must be recompiled and redeployed.
Custom Connectors
The Custom Connector is the more flexible approach when developing connectors. Unlike the .NET Assembly Connector, it is not necessary to map entities to .NET Framework classes. And, if changes are made to the back-end interface, it is only necessary to update the BDC model (XML configuration file), not the actual assembly.
The downsides to this approach are that the deployment process is more involved, there is no tooling to support development in Visual Studio or SharePoint Designer, and any DLLs must be deployed to the GAC.
This section described the framework and tooling available for developers to integrate data sources that are not supported out of the box. The next section covers a frequent business requirement found in SharePoint projects — data aggregation.
AGGREGATION
Part of why SharePoint is such a compelling repository to store an organization's data is the flexible options for surfacing it. When data residing in disparate locations is surfaced and displayed in a single list, this is called a roll-up or aggregation. This has always been a core concept in SharePoint. Consider the following scenarios:
- A law firm has an intranet with subsites for each practice area (litigation, real estate, and so on). Each of these sites has an “Announcements” section. Users have requested that all announcements from these separate sites automatically appear in one list on the home page of the portal.
- A non-profit organization has a partner extranet comprised of many site collections (one for each partner). It requires an easy way to view all of its partner agreements across these site collections.
- An electronics manufacturer wants to display a slideshow of only its newest products on the home page of its Internet site.
- A large pharmaceutical company is developing a new drug, and has created a team site specifically for this purpose. The team would like to display any content (regardless of format, source system, location, and so on) on this page if the project name appears anywhere in the title, body text, or metadata.
What all of these examples have in common is a requirement to surface information that does not necessarily reside in the same list or location. The methods for accomplishing the task of aggregating data can be roughly lumped into two groups: real-time aggregation and search-based aggregation.
Real-time Aggregation
Real-time aggregation refers to a roll-up that is based on a query against live data. Examples of this are utilizing the Content Query Web Part (CQWP), creating a custom web part that submits a Collaborative Abstract Machine Language (CAML) query, or configuring a Data View Web Part (DVWP) via SharePoint Designer.
Content Query Web Part
In SharePoint 2010, the CQWP remains one of the most powerful and useful out-of-the-box web parts developers and power users have in their arsenal. It is used to aggregate relevant information on a page by allowing users to create queries via a user-friendly user interface (UI). Because results are rendered using Extensible Stylesheet Language Transformations (XSLT), the display is completely flexible, and rich, interesting interfaces can be developed.
The biggest limitation in using the CQWP is that it is designed to be used only within a single site collection. That means that, out of the box, it is not possible to aggregate content from lists in different site collections.
Because it is such a useful and highly leveraged tool, there is a wealth of information on how to best utilize and configure the web part, which makes it an even more attractive option.
Data View Web Part
The DVWP has often been called the Swiss Army Knife of SharePoint. You can configure the DVWP to aggregate SharePoint data, customize the presentation of a list, display a list from another site collection, connect to RSS feeds or external applications, and more.
The main downside in using the DVWP is that it must be created using SharePoint Designer. For this reason, it is usually reserved for developers or highly technical power users. One other limitation (when using it for a roll-up) is that new lists will not appear in roll-ups automatically. Therefore, it is most useful when the data set is somewhat static.
Custom and Third-Party Web Parts
When requirements cannot be met with the out-of-the-box roll-up tools, there is always the option to create a custom web part. Typically a custom SharePoint web part used to aggregate content will utilize a CAML query or LINQ-to-SharePoint (see the section, “Working with Data,” later in this chapter for more on LINQ-to-SharePoint). Writing a custom web part offers the greatest flexibility and (unlike the DVWP or CQWP) does not necessitate knowledge of XSLT to format the display.
Many third-party products are similar to the CQWP in that end users are able to configure queries via a user-friendly UI. These web parts usually do not have the same limitations regarding multiple site collections, and the display can be formatted more easily than the CQWP. As with all third-party products, they should be evaluated while keeping in mind manageability, support, cost, and the overall development strategy for the SharePoint platform.
Search-Based Aggregation
Search-based aggregation involves creating a query to surface information from the search index. The easiest way to accomplish this is by configuring an out-of-the-box Search Core Results web part with a predefined (or “canned”) query. Search Core Results is the web part that appears on search results pages to render search results, but this web part can be added to any page and configured easily to surface data based on any search criteria.
The obvious limitation with this method is that the query does not return up-to-the-second results. The “freshness” of results will be determined by when the last crawl was completed.
Other than that limitation, search-based aggregation can be a fantastic alternative to other aggregation methods. Among the benefits are ease of configuration that would otherwise be complex (such as queries against unstructured data), along with the fact that it is the only of the out-of-the-box method that allows roll-ups to include items not stored in SharePoint (such as documents in file shares).
The next section covers the many methods now available to developers for accessing and working with SharePoint data.
WORKING WITH DATA
Most custom solutions that are built on or connect to SharePoint involve accessing, adding, updating, deleting, manipulating, or surfacing SharePoint data. To meet various business requirements, developers may find themselves accessing SharePoint data from any number of application types, including browser-based applications, Silverlight applications, Office applications, applications on a SharePoint server, and applications running on remote servers. To give developers the richest set of tools to cover different scenarios, SharePoint 2010 now has many data access technologies to choose from, depending on the situation. These include the server-side object model (OM), client OM, LINQ, and REST.
Server APIs
SharePoint has always offered an incredibly rich experience for developers writing code that runs on SharePoint servers. In SharePoint 2010, the story gets even better with an improved object model and support for LINQ.
Server-Side Object Model
The SharePoint server-side object model enables developers to write programs that access SharePoint objects such as lists, libraries, site collections, sites, and just about any SharePoint construct you can think of. The object model is quite large. However, it is rich and user-friendly. Most experienced .NET developers who are new to SharePoint are pleasantly surprised by how easy it is to complete programming tasks using the SharePoint Server OM.
LINQ-to-SharePoint
One of the improvements in SharePoint 2010 that developers have been eagerly awaiting is LINQ-to-SharePoint, which is a LINQ provider that translates LINQ queries into CAML queries. Developers no longer have to write CAML queries that many find to have an unfriendly, esoteric syntax. Now they can use the more universal and friendly LINQ to query SharePoint data.
Client APIs
Designing solutions that access SharePoint from external applications has become much easier in SharePoint 2010 thanks to the Client Object Model and REST.
Client Object Model
New to SharePoint 2010 is the client object model, which allows developers to program against SharePoint from .NET-managed applications, Silverlight applications, or from ECMAScripts (JavaScript, JScript) run from a browser using many of the types and members present in the server-side object model.
REST
Another new feature in SharePoint 2010 is the capability to access list data using Representational State Transfer (REST) style web services. Just like the legacy SharePoint 2007 Simple Object Access Protocol (SOAP) web services, REST provides data access functionality via remote URLs. Indeed, any application that can send REST URLs to SharePoint can access its list data. This data access mechanism has some major limitations, though — it can only be used to access list data and Excel Services data.
 SharePoint SOAP web services are still available. However, Microsoft recommends that working with SharePoint data remotely should be done using the new client object model whenever possible.
SharePoint SOAP web services are still available. However, Microsoft recommends that working with SharePoint data remotely should be done using the new client object model whenever possible.
Choosing a Data Access Technology
Table 11-1 and Table 11-2 serve as guides for choosing which data access technology to use for various scenarios.
TABLE 11-1: Data Access Technologies Decision Matrix (Part 1)
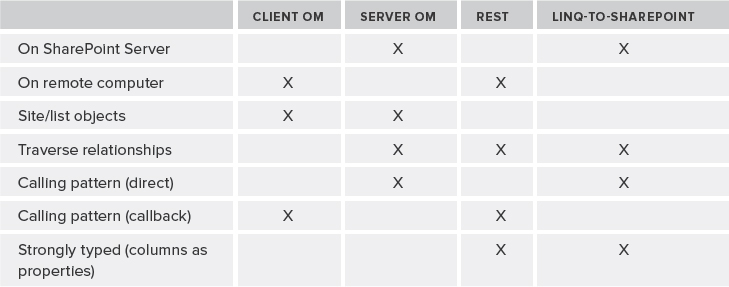
TABLE 11-2: Data Access Technologies Decision Matrix (Part 2)
| MANAGED CLIENT OMs | JAVASCRIPT CLIENT OM |
| Full URL context | Server-relative context only |
| StringCollection | String array |
| Null, Infinity | Nan, positive/negative infinity |
| Explicit FBA support | Context FBA support |
| Create, update, commit | Create, update, commit |
| No FormDigest required | Needs <SharePoint:FormDigest> |
| Standard server OM identity | No RoleDefinitionBindingCollection identity |
| SPWeb locale for comparisons | Invariant culture for comparisons |
Table 11-3 also lists the pros and cons of data access technologies for various scenarios.
TABLE 11-3: Pros and Cons of Data Access Technologies


Event Model
SharePoint 2010 improves upon the Microsoft Office SharePoint Server (MOSS) events model by adding receivers for new events. To name a few, there are now add and delete events on lists, and add events on websites. Additionally, there are new “synchronous after” events that provide a way to perform actions on a list after it has been submitted, but prior to rendering.
Further improvements to the event model include event binding at the site collection level, binding of XML event receivers at the site level, and a new class called SPWorkflowEventProperties specifically created to improve support for workflows.
This section outlined the various options developers now have for working with SharePoint data. The next section discusses various considerations for designing SharePoint solutions in the cloud.
INCORPORATING CLOUD DATA AND COMPUTE SERVICES
Many organizations are looking to the cloud to host their enterprise applications for ease of deployment, uptime, cost savings, and more. As you will read about in more depth in Chapter 22, Microsoft now has a Software as a Service (SaaS) offering called Office 365 that includes SharePoint Online. Though opting for SharePoint Online over an on-premises solution certainly has its advantages, it also presents various challenges — most notably regarding custom applications. To work around this limitation, some are architecting solutions that combine SharePoint 2010 with another of Microsoft's cloud offerings — the Windows Azure platform.
Developing Cloud-Based Data and Compute Services
Because custom development options are limited in SharePoint Online, and custom databases are not allowed, a common solution is to develop .NET services, deploy them to the Azure platform, and then consume those services from within SharePoint. A how-to on creating services and deploying them to Azure is outside of the scope of this chapter, but many resources are available online on how to do just that.
Incorporating Services into Your SharePoint Solution
A number of potential integration points exist between SharePoint and custom applications in Azure, some of which are described in Table 11-4.
TABLE 11-4: Points of Integration
| AZURE INTEGRATION | HOW IT'S DONE |
| SharePoint client object model | Interact with Windows Azure data in a list |
| Business Connectivity Services (BCS) | Model data from Windows Azure or build external list to SQL Azure |
| Silverlight | Create UI against Windows Azure services or data |
| Sandboxed solutions/SharePoint Online | Silverlight application leveraging Windows Azure deployed to site collection |
| Office custom client | Consume data directly from Windows Azure or BCS list exposing data |
| Standard/Visual web parts | Leverage services and data from Windows Azure |
| Open XML | Manage Windows Azure data in a document |
| REST | Use REST to interact with Windows Azure data to integrate with SharePoint |
| Office server services | Combine with Open XML to auto-generate docs (such as PDFs) on a server |
| Workflow/event receivers | State or events that tie into Windows Azure services, workflows, or data |
| LINQ | Use for querying Windows Azure data objects |
| Search | Federate search to include Windows Azure data |
| Source: “Connecting SharePoint to Windows Azure with Silverlight Web Parts” by Steve Fox (http://msdn.microsoft.com/en-us/magazine/gg309179.aspx) | |
For the purposes of this discussion, consider the following example. Notable Instruments, a musical instrument manufacturer, has created an e-commerce site that is hosted on SharePoint Online. As part of its solution, its system architect wants to store encrypted customer information in a custom database, and create a custom service to access and edit this data.
This is not an option in SharePoint Online, so a decision is made to host the custom service and data in Windows Azure, and host the back-end in SQL Azure. SharePoint will simply be the consumer of this service, and can surface and interact with the data in any number of ways, as shown in Figure 11-12.

FIGURE 11-12: SharePoint Online and Azure
![]() For more information on integrating SharePoint 2010 and Azure solutions, seek out Senior Evangelism Manager for Microsoft, Steve Fox, at http://blogs.msdn.com/b/steve_fox/.
For more information on integrating SharePoint 2010 and Azure solutions, seek out Senior Evangelism Manager for Microsoft, Steve Fox, at http://blogs.msdn.com/b/steve_fox/.
TAKING BUSINESS DATA OFFLINE
With the rollout of SharePoint 2010 and Microsoft Office 2010, users are no longer slaves to an Internet connection. There are now tools for users to work with SharePoint data (and data integrated into SharePoint) even when offline.
Using SharePoint Workspace
SharePoint Workspace 2010 is a client application that provides access to SharePoint 2010 content even when offline. For those familiar with the previous technology, it is the updated version of Microsoft Office Groove 2007. In addition to providing a client for interacting with SharePoint content, SharePoint Workspace 2010 can be used to create Groove collaboration workspaces and synchronized shared folders.
By using SharePoint Workspace 2010, users can view, edit, and add content in SharePoint 2010 lists and libraries while offline. When their PCs are back online, the content is automatically synchronized bi-directionally. This synchronization is optimized by sending only “update packets” (changes), as opposed to entire files over the network.
One of the most exciting features of SharePoint Workspace 2010 is the capability to interact with external lists (that is, SharePoint lists containing external data via the BCS). This functionality allows users to work with back-end data from their PCs, even when offline.
The desktop integration story for SharePoint Workspace 2010 is an impressive one. Workspace recognizes Windows credentials so that authentication and authorization to SharePoint content is seamless. Microsoft Lync is integrated, giving users the capability to view the presence information of others who have access to shared content, and instantly interact with them via instant messaging (IM), e-mail, video chat, or other methods, as shown in Figure 11-13.
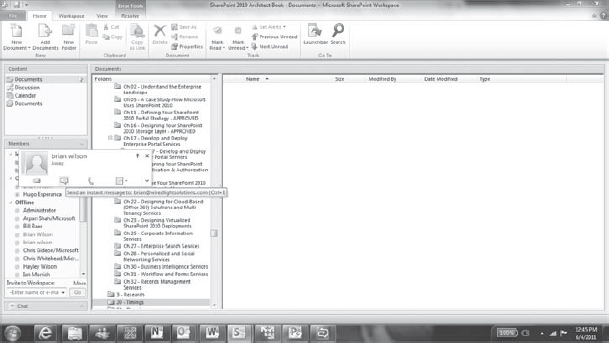
FIGURE 11-13: Workspace Lync integration
Being part of the Office suite (it is part of Microsoft Office Professional Plus 2010), SharePoint Workspace 2010 shares the familiar interface of the other Office products. Lastly, SharePoint Workspace data is searchable from Windows Desktop Search 4.0, as shown in Figure 11-14.
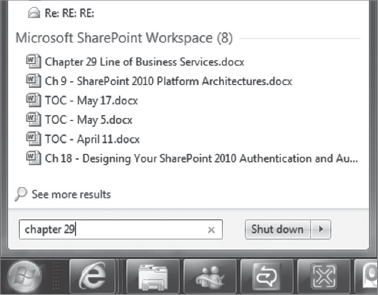
FIGURE 11-14: Workspace Search
Microsoft has also released SharePoint Workspace Mobile. It is part of Office Mobile on Windows Phone 7 devices. Using the mobile application, users can view libraries and lists; view, add, and edit documents from mobile devices; synchronize documents to a mobile device; and more.
SharePoint Workspace 2010 is a powerful tool that has obvious applications for any business whose employees operate outside of the office (think oil rig workers, traveling sales representatives, and so on).
Using Microsoft Office
Although Workspace is the premier tool for working with offline content, integration between Microsoft Office 2010 and SharePoint 2010 provides a limited (but useful) offline editing experience as well. Office 2010 includes the Backstage view. This is the area where users can manage documents and their metadata from within the Office client. Creating, sending, and editing metadata, as well as managing document versions, are some of the tasks you can complete from this area.
The Backstage view is located under the File tab in Office applications. When the need arises to work on a document offline — and Workspace is not an option — the Backstage view provides a subset of online functionality.
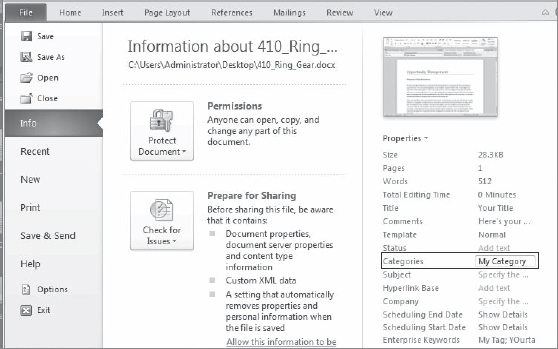
Consider a scenario in which a user is working on a document and must leave the office to catch a train. The user will not have access to the Internet during the commute, but final changes must be made to the document. That user can check out the document (to prevent others from making changes), download a local copy, make edits while offline, and when the user is back online, upload the document to the library as a new version. Where this gets interesting is that the user is able to make changes to the document metadata in this offline state as well.
Within the Backstage view, there is a list of properties, which include SharePoint metadata fields that are editable offline (Figure 11-15). It is important to note that, if it is a field type that supports auto-complete (such as a managed metadata field), the auto-complete will not be functional in this offline state. However, changes can still be made.
SUMMARY
SharePoint 2010 provides the architect with a truly impressive set of tools for working with data — both internal and external. New events allow custom reactions to list and site creation, and new APIs make it simple to access SharePoint data from various types of applications, including Silverlight and browser-based remote applications. The BCS and connector framework enable easy integration of data from almost any source, and external lists provide the capability to work with this data in native SharePoint lists. SharePoint 2010 also provides functionality to address special considerations, such as cloud solutions and the capability to work with data while offline.
These features and more represent a huge leap forward in working with data in SharePoint, thus allowing architects to design better, more integrated, and sophisticated solutions for their users.
As exciting as all the new tools described in this chapter are, successful SharePoint solutions start with a lot of good planning. Chapter 12 covers the non-technical aspects of creating SharePoint solutions, such as requirements gathering, working with stakeholders, navigating politics, and more.