
Smart restaurants: survey on customer demand and sales forecasting
Abstract
Demand forecasting is one of the important inputs for a successful restaurant yield and revenue management system. Sales forecasting is crucial for an independent restaurant and for restaurant chains as well. In this chapter a comprehensive literature review and classification of restaurant sales and consumer demand techniques are presented. Sales prediction is very complex due to the impact of internal and external environment. However, a reliable sales forecasting methodology can improve the quality of business strategy. A range of methodologies and models for forecasting are given in the literature. These techniques are categorized here into seven categories, also including hybrid models. The methodology for different kinds of analytical methods is briefly described, the advantages and drawbacks are discussed, and relevant set of papers is selected. Conclusions and comments are also made on future research directions.
Keywords
1. Introduction
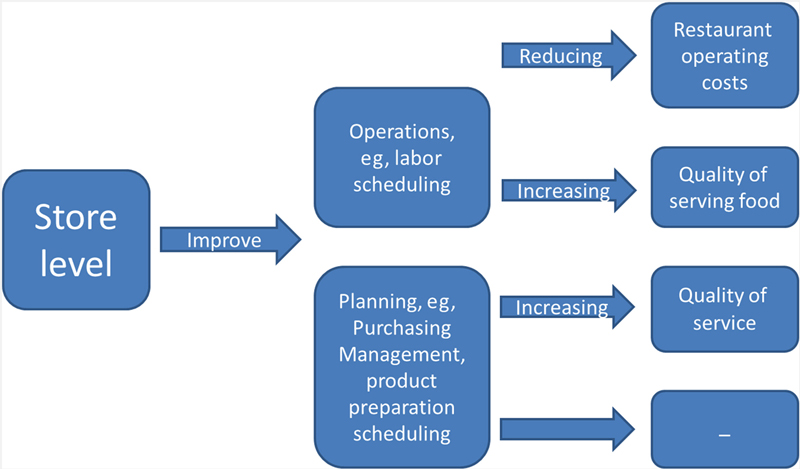

2. Revenue management

Table 17.1
Time Intervals in Which Restaurant Demand Should Be Predicted
| No. | Time Interval | Range of the Interval |
| 1 | Month | Next 12 months |
| 2 | Week | Next 4–6 weeks |
| 3 | Day | Next 7–10 days |
| 4 | Day part | Next 1–3 days |
Table 17.2
Variables That Can Be Used as Predictors
| No. | External Variable | Range or an Example of the Variable |
| 1 | Time | Month, week, day of the week, hour |
| 2 | Weather | Temperature, rainfall level, snowfall level, hour of sunshine |
| 3 | Holidays | Public holidays, school holidays |
| 4 | Promotions | Promotion/regular price |
| 5 | Events | Sport games, local concerts, conferences, other events |
| 6 | Historical data | Historical demand data, trend |
| 7 | Macroeconomic Indicators (useful for monthly or annual prediction) | CPI, unemployment rate, population |
| 8 | Competitive issues | Competitive promotions |
| 9 | Web | Social media comments, social media rating stars |
| 10 | Location type | Street/shopping mall |
| 11 | Demographics of location (useful for prediction by time of a day) | The average age of customers |
CPI, consumer price index.
3. Literature review
3.1. Multiple regression
3.2. Poisson regression
3.3. Box–Jenkins models (ARIMA)
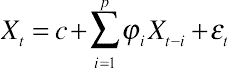

3.4. Exponential smoothing and Holt–Winters models
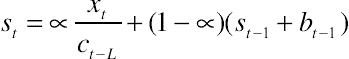

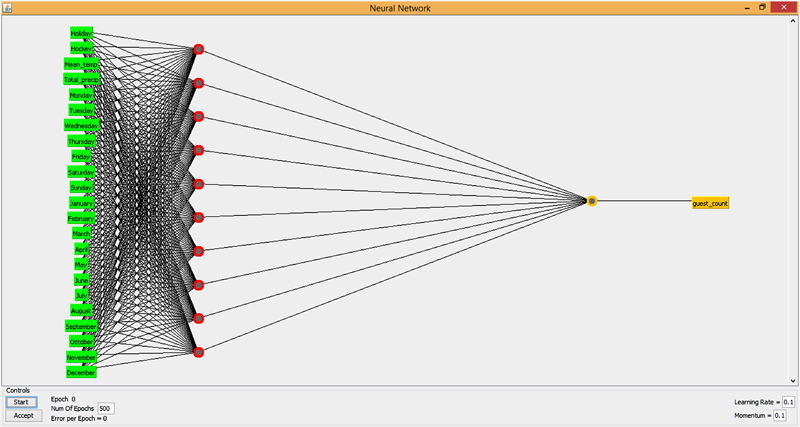
3.5. Artificial neural networks
3.6. Bayesian network model
3.7. Hybrid models
3.8. Association rules (market basket analysis)
4. Discussion of methods and data mining algorithms
Table 17.3
Summary of Sales/Demand Forecasting Methods
| Method | Description | Examples of Papers |
| Multiple Regression | Multiple Regression uses least squares to predict the unknown value of a dependent variable from the known value of two or more explanatory variables (predictors) | [26–30,34] |
| Poisson Regression | Poisson regression uses the Poisson distribution error structure and the natural logarithm link function | [32] |
| Box–Jenkins model (AR, MA, ARIMA) | The AR model specifies that the output variable depends linearly on its own previous values. The simple MA weights the past observations equally | [2,7,29,37,43] |
| Exponential smoothing and Holt–Winters models | Exponential smoothing uses exponentially decreasing weights over time | [3,27,38–41,43] |
| ANNs | ANNs use interactions in a network-processing architecture to automatically identify the underlying function that best describes the demand process | [45,46] |
| Bayesian Network Model | Bayesian Network can represent the probabilistic relationships between the variables | [47,48] |
| Hybrid Model | Hybrid models combine two different methods in one | [49,51] |
| Association Rules | Association Rules algorithms find frequent patterns in the data | [53–55] |
ANN, artificial neural network; AR, autoregressive; ARIMA, autoregressive integrated moving average; MA, moving average.
Table 17.4
Advantages and Disadvantages of Sales/Demand Forecasting Methods
| Method | Input Data | Output | Advantages | Disadvantages |
| Multiple Regression | Exogenous variables such as disposable income, the consumer price index, unemployment rate, personal consumption expenditures, housing starts | For example, restaurant sales/customer demand | + The decision maker can logically formulate the model based on a cause-and-effect relationship between the causal variables and future sales | − Multiple regression analysis can fail in clarifying the relationships between the predictor variables and the response variable when the predictors are correlated with each other − The relationship found between the dependent and independent variables may be spurious or can change over time, making it necessary to constantly update or totally redesign the model |
| ARIMA (Box–Jenkins models) | Historical time series demand/sales data | Long-term or short-term predictions of future demand/sales | + Do not need any external data | − The input series for ARIMA needs to be stationary, that is, it should have a constant mean, variance, and autocorrelation through time − These methods require improvements if the data are influenced by heterogeneity (eg, promotion) |
| Exponential Smoothing model, Holt–Winters models | Historical time series demand/sales data | Long-term or short-term predictions of future demand/sales | + Exponential smoothing generates reliable forecasts quickly, which is a great advantage for applications in industry + Do not need any external data |
− Method is influenced by outliers (sales/demand that are unusually high or low) |
| Bayesian Network Model | Particular set of variables | The probability of the variable, for example, high sale | + All the parameters in Bayesian networks have an understandable interpretation | |
| Neural Networks | For example, associated factors including seasonal impact, impact of holidays, number of local activities, number of sales promotions, advertising budget, and advertising volume can be used as input data. All the training and test data used in this study are required to be preprocessed. The input and output data used for training and the input data used for testing have to be preprocessed so that the data were mapped between [1, −1] | Sales amount can be chosen as the output data for the Forecasted results. An inverse transformation should be conducted on the results of the simulated forecast to restore the actual value of the forecasted sales condition | + Have high tolerance of noisy data + Ability to classify patterns on which they have not been trained + Can be used when there is little knowledge of the relationships between attributes and classes + They are well suited for continuous-valued inputs and outputs, unlike most decision tree algorithms + Are parallel; parallelization techniques can be used to speed up the computation process + Can model complex, possibly nonlinear relationships without any prior assumptions about the underlying data generating process + Overcome misspecification, biased outliers, assumption of linearity, and reestimation |
− Neural networks involve long training times and are therefore more suitable for Applications where this is feasible − They require a number of parameters that are typically best determined empirically, such as the network topology or structure. Constructing a good network for a particular application is not a trivial task. It involves choosing an appropriate architecture (the number of hidden layers, the number of nodes in each layer, and the connections among nodes), selecting the transfer functions of the middle and output nodes, designing a training algorithm, choosing initial weights, and specifying the stopping rule − Neural networks have been criticized for their poor interpretability |
| Association Rule Mining (Market Basket Analysis) | Transactional database (TDB) or Relational database (RDB). Given a minimum support (minsup) and a minimum confidence (minconf) | All association rules that satisfy both minsup and minconf from a dataset D | + Association rules that satisfy both minsup and minconf can help with discover factors that influence high/low demand |



ARIMA, autoregressive integrated moving average.