
Chapter 10
Bringing Named Data Networks into Smart Cities
Syed Hassan Ahmed1, Safdar Hussain Bouk1, Dongkyun Kim1 and Mahasweta Sarkar2
1School of Computer Science and Engineering, Kyungpook National University, Daegu, Korea
2Electrical & Computer Engineering Department, San Diego State University, San Diego, CA, USA
Chapter Menu
Introduction
Future Internet Architectures
Named Data Networking (NDN)
NDN-based Application Scenarios for Smart Cities
Future Aspects of NDN in Smart Cities
Conclusion
Objectives
- • To provide an overview of the Internet legacy and its role in envisioning a smart city.
- • To become aware of technology trends from traditional Internet to Future Internet.
- • To become familiar with Named Data Networking.
- • To discuss a set of Future Internet applications that can be considered as an integral part of any city to be referred as smart city.
10.1 Introduction
According to recent studies, it has been stated that by the year 2050, we will be having around 9 billion humans on the Earth, and almost 70% of them would be living in urban areas. This steady and consistent growth in the world population is alarming and indicates that we need to redesign our cities in terms of constructions, roads, medical assistance, and, on top of everything, our information and communication technology (ICT). For the past few decades, we have witnessed that the ICT services have been improving the lifestyle of laymen, for example, various medical advancements, communication advancements, and traveling facilities. Later on, we have seen rapid agricultural advancements. These are the basic needs of any human on Earth. Here it is worth mentioning that the communication technologies have been actively and passively serving the humanity from the day they came into being. For instance, we take examples of patient monitoring systems, surgery equipment, in-body sensors, and body area networks (BANETs). Also, we have seen noticeable work done by wireless sensor networks (WSNs), and the applications of the WSNs are unlimited. Similarly, the recent research in vehicular ad hoc networks (VANETs) has enabled us to have at least three types of services including safety, traffic control, and user applications. All these services are providing secure driving experience, less traffic congestion, and various entertainment applications, respectively, on roads. In short, the wired and wireless communication technologies have been improving our lifestyles, and today we are connected to the world, regardless of location, and altitude and depth on/off the Earth.
However, in the near future, we can assume that the current technologies may be insufficient to entertain the massive increasing demands of the users and consumers seeking the ICT services mentioned above or to be expected in the near future. Recently, the researchers and industry personnel have identified that “smart cities” is the potential solution. The smart cities concept is basically the emergence of the advancements that have been made in various fields. From the recent literature, it is hard to find the exact definition of this term. Furthermore, we have seen that various technologies are making our lives smarter than we have ever imagined before. Therefore, we believe that if we merge those technologies and enable them to communicate with each other for the benefits of citizens and government-oriented departments, we expect that future cities should be able to provide smart services to the humans living in that particular city. For instance, we want purified drinking water, and the level of pollution can be detected by deploying underwater sensor networks for pollution monitoring, and actuators can be designed similar to the filters in our houses. So whenever pollution is detected, the filtering process may start, and, as a result, we will not require individual filters to be installed in our house. Similarly, autonomous driving will be the next revolution in field automation. For example, autonomous ambulances and live monitoring of the patient in the absence of the doctor could be beneficial to the laymen as well.
Smart cities are expected to provide high quality living standards to all their citizens with main focus on a few key aspects such as smarter environment, smarter mobility, smarter connectivity, and smarter governance. When we say “smart,” we mean that security, privacy, robustness of the system, and availability of the services should be persistent. The main goal is to build a business-competitive and attractive environment by leveraging on the human capital of the city. For that reason, we state that the ICT builds a foundation of any city to be smart. Since, ICT can provide intelligent transportation systems (ITS), environmental monitoring, efficient utilization of energy sources, healthcare, public security, and e-commerce, today we are able to connect various devices and services using cloud computing (CC), Internet of Things (IoT), the Worldwide Interoperability for Microwave Access (WiMAX), and the Wi-Fi. Moreover, if we look into the revolutions in cellular networks, we have witnessed obvious advancements in the form of third generation (3G), Long-Term Evolution (LTE), and LTE Advanced (LTE-A). Beyond a shadow of a doubt, all these services have been enabling various service providers to make commercial products and providing consumers with remarkable on-move connectivity.
Nevertheless, from a technical point of view, a radical change has also been observed in the use of digital resources. For example, nowadays, users are interested in sharing the contents between connected devices rather than just being interconnected w.r.t remote devices. Also, the main purpose of today's connected devices is to share the Data. However, the current IP-based communications have increased latency in the content retrieval process due to its host-centric nature of communication. Although we have a variety of security protocols in almost every networking paradigm, we still receive spam. One reason is that while keeping our medium and host secure, we neglectthe content integrity, and as a result, despite the fact that we have good speeds of downloading, sometimes we get stuck in the retrieval process. These features will affect connection-oriented services that are expected to be a part of future smart cities. At the time of writing of this chapter, we argue that a new and changed perspective of ICT is required to make our future cities more robust, reliably connected, and support mobile applications. For instance, we have few recent works that focus on putting into practice content-centric approaches (i.e., Information-Centric Networks (ICNs)). To date, Palo Alto Research Center (PARC) proposed a promising Future Internet architecture named as CCN. The communication in CCN has been shifted from host centric to Data centric. In CCN, we have names for the contents instead of end-to-end devices. In later stages, the researchers from the University of California, Los Angeles (UCLA) in collaboration with Van Jacobson (the founder of CCN) proposed NDN. NDN further solves different issues faced by the previous ICN architectures and is considered the latest and reliable architecture with active project crew that provides up-to-date debugs and documentations regarding the NDN implementation.
In this chapter, we briefly describe the recently proposed Future Internet architectures followed by insight and discussion on NDN. In addition, we also describe the possible applicability of NDN in smart cities and its potentials. Before the conclusions, we also provide variant application scenarios for NDN-enabled smart cities and future research road map for researchers.
10.2 Future Internet Architectures
Recently, the researchers have put some efforts and have proposed preliminary architectures for Future Internet. In this subsection, we will put some light on some known ones as follows:
10.2.1 Data-Oriented Network Architecture (DONA)
The Data-Oriented Network Architecture (DONA), devised by UC Berkeley, is claimed to be one of the architectures that provide complete ICN solution [[1]]. In DONA, the type of naming is replaced from URL-based hierarchical naming to flat naming or hash-based naming. The hash-based naming in DONA helps consumer to verify the origin of the content as well as its integrity. The naming in DONA is based on the mapping between the content and principal's or publisher's name. The flat namespace of NCOs is in the form P:L, where P uniquely specifies the principal field globally and is the publisher's public key's cryptographic hash and L specifies the unique label of NCO. The naming granularity is the function of the principal, for instance, the principal can name the entire stream of a videoor an individual chunk within that video. The names are globally unique, flat, self-sufficient, and location and application independent. As the names are hash based, so the consumer requires external mechanisms (e.g., search engines) to provide name against the request for that content or in simple words the mapping between the human-readable names and hash-based names, because it is difficult for a human to remember hash-based names.
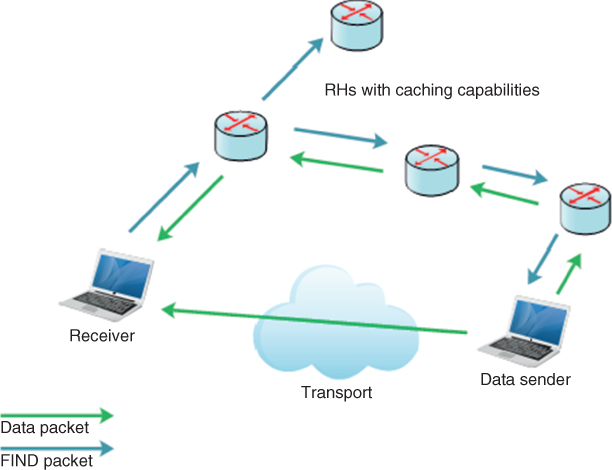
Figure 10.1 Data-oriented network architecture (DONA): overview.
In DONA, there are specialized servers called resolution handlers (RHs) that provide the name resolution. At least one logical RH exists at each autonomous system (AS) [[2]]. These RHs are divided into hierarchies for resolving names from top to bottom such as current inter-domain routing, as it can be seen in Figure 10.1. To advertise an NCO to the network, a principal (publisher) first contacts its local RH and forwards a REGISTER message along with the name of content. The local RH creates mapping to the principal. The local RH then broadcasts this registration information to all the neighboring and parent RHs, asking them to store a mapping between the address of RH that forwarded that information and NCO's name. So these registrations are followed up to the top hierarchy, that is, tier-1 and whole network become aware of that mapping. To find an item in the network, a subscriber forwards a FIND message to its local RH, which passes that message to upper tier until a mapping for the request is found. Pointers are followed in request to reach the publisher. When a publisher is reached, the reverse path order is used by the publisher toward the subscriber to deliver the content.
The subscriber mobility in DONA is handled simply by just resending the requests for content from a new location to new RH [[3]]. DONA follows out-of-the-band delivery of content that requires to reestablish a session with either the same publisher or a new publisher once the consumer moves from one RH to another RH. So the process is complicated. To handle publisher's mobility, DONA supports early binding for subscriber mobility in which the binding between the locator and publisher's identifier is created when publisher registers itself. So when a publisher moves, it simply registers itself with a new RH. It is only simple to serve requests under new RH, but requests under previous RH have to be resent or require a mechanism such as Mobile IP. This is one of the limitations of early binding in DONA [[4]].
10.2.2 Network of Information (NetInf)
Network of Information (NetInf) is a continuation of the EU Framework 7 Program-funded projects, Architecture and Design for the Future Internet (4WARD), and Scalable and Adaptive Internet Solutions (SAIL) [[5]]. The area of focus of SAIL project contains issues related to network transport, while 4WARD is related to naming and searching content. The NetInf names are flattish; they can reserve a hierarchical naming scheme and can also obtain the hash-based form [[6]]. The names are in the form ns://A/L hierarchical fashion, where A helps in global name resolution and L helps in local name resolution. Each of these parts can be normal string in the form of URI or it can be a hash.

Figure 10.2 Network of Information (NetInf) overview.
Name resolution and Data routing in NetInf can be performed in either coupled mode or decoupled mode, as illustrated in Figure 10.2. In decoupled mode, an entity called Name Resolution Systems (NRS) holds the mappings between the NCO names and locators to reach the NCOs. The NRS works in DHT fashion, and each of these NRS handles ![]() part resolution if local and
part resolution if local and ![]() part resolution if global. To advertise the content, a publisher sends the Publish message to its local NRS along with the locator. The local NRS makes a Bloom filter of the
part resolution if global. To advertise the content, a publisher sends the Publish message to its local NRS along with the locator. The local NRS makes a Bloom filter of the ![]() part that belongs to same authority
part that belongs to same authority ![]() and propagates the Publish message to upper-tier global NRS. Global NRS saves the mappings corresponded by local NRS. The subscriber can get the NCO by sending a Get message to its local NRS, which in return negotiates with global NRS for the locator of the NCO. The global NRS returns the locator information to local NRS, which delivers it to the subscriber. The subscriber queries the publisher for the NCO, and the publisher acknowledges the subscriber with the requested NCO [[7]].
and propagates the Publish message to upper-tier global NRS. Global NRS saves the mappings corresponded by local NRS. The subscriber can get the NCO by sending a Get message to its local NRS, which in return negotiates with global NRS for the locator of the NCO. The global NRS returns the locator information to local NRS, which delivers it to the subscriber. The subscriber queries the publisher for the NCO, and the publisher acknowledges the subscriber with the requested NCO [[7]].
In coupled mode, a routing protocol advertises the name of NCO to CRs. To get an NCO, a subscriber sends request message to its local CR, which propagates it to other CRs hop by hop. When there exists a match for the requested NCO, reverse path is utilized to deliver that NCO to the subscriber [[8]]. The request messages are aggregated at CRs to track back the subscriber for delivery of the content.
The subscriber mobility in NetInf is handled easily by resending the requests for an NCO under new local NRS. Publisher mobility is a bit difficult because when the publisher moves from one local NRS to a new one, the NR service needs to be updated right from the global NR to local NR [[9]].
10.2.3 Publish Subscribe Internet Technology (PURSUIT)
The Publish Subscribe Internet Technology (PURSUIT) is an extension of Publish Subscribe Internet Routing Paradigm (PSIRP) [[10]]. Both of these architectures provide a clean-slate approach to replace the current IP architecture. Both PURSUIT and PSIRP are funded by EU Framework 7 Program. In PURSUIT, the NCO is named by a flat naming scheme through concatenating two unique identifiers called scopeID and rendezvousID. The rendezvousID specifies the actual identity of the NCO, while the scopeID specifies the group to which an NCO belongs. Each NCO must belong to at least one scope, while an NCO can belong to multiple scopes with different rendezvous IDs [[11]]. The scopeID helps to define access boundaries of an NCO, for instance, a publisher can publish a photograph under “family” scope and “friends” scope, having distinct rights for each scope.
In PURSUIT, different rendezvous nodes (RNs) are implemented that combinely form Rendezvous Network (RENE) for name resolution in hierarchical distributed hash table (DHT) manner. As depicted in Figure 10.3, to advertise content to network, a publisher sends Publish message to its local RN, which disseminates it to upper-tier RENE. When a subscriber puts a request against an NCO, it sends a Subscribe message to its local RN that forwards it to upper-tier RENE, and it forwards it to RENE, which holds the binding. A route is constructed from publisher to subscriber when RN asks Topology Manager (TM) node to do it. TM node sends a message to publisher called Start Publish, which contains route. Publisher establishes route by exploiting this information and uses Forwarding Nodes (FNs) to forward NCO to the subscriber.

Figure 10.3 PURSUIT overview.
The subscriber mobility in PURSUIT is easy to handle [[12]]. Subscriber just moves to another network and resends the requests for content under new RN. Handling publisher's mobility is quite difficult [[13]]. Because when the publisher moves, then the topology information has to be resubmitted and changed from lower to upper-tier RENE.
10.3 Named Data Networking (NDN)
The NDN is providing its part to further enhance CCN project and is funded by the US Future Internet Architecture program. The notion of NDN is to transform the existing shape of Internet protocol stack by replacing the narrow thin waist with named Data, and under this waist different technologies for connectivity can be used, such as IP. A layer called strategy layer provides the mediation between the underlying technologies and the named Data layer.
The naming scheme used in NDN is human friendly, hierarchical, and resembles URLs; an example of such name can be /ait.asia/home/index.html. It is not obvious that NDN names must be human-readable or there must exist DNS or IP address in name; rather it can be a hash of a string. In NDN, the names of the NCOs are matched on the basis of longest prefix match, for example, /ait.asia/home/index.html. In such case, the name can be matched with the start and then further can be explored for any piece of information, for example, /ait.asia/home/index.html/v1/s1, which means segment-1 from version-1 of that file. After that the subscriber can apply a direct function by asking the next segment, that is, /ais.asia/home/index.html/v1/s2 or can go with the next sibling under that hierarchy. So it depends upon the exploration of the prefix matching with longest prefix match mechanism.
Another good thing about NDN naming is that the subscriber can ask for a content that has not yet generated. For this, a publisher advertises to network the prefix that it can provide a content with such prefix so anyone interested can ask for it. This helps applications where the content is generated dynamically, and its complete name prefix is not known in advance, such as dynamic or live video generation.
In NDN, there are two types of messages used for requesting and routing information, one is Interest message that a subscriber issues for a certain content and in return publisher provides Data to that subscriber. There are two Data structures (routing tables): FIB, PIT and a CS maintained at each content router (CR) in a hop-by-hop fashion for sending interests and replying with content. The FIB maps the interests received to forward them to interface(s) for publishers or other CRs having content in their caches. The PIT keeps track of the interests for which content is expected to be arrived. Lastly, the CS acts as a cache for the CR to keep the replica of the content that went through that CR.
The order of importance among FIB, PIT, and CS is that CS reserves the highestpriority and then PIT and lastly comes FIB in the priority list. When an interest is received for a content, initially CR checks its PIT whether the interest message for the same content has been received earlier; if so the interface over which interest was received is kept as a record in an entry in PIT keeping back track of the interface so that the multicast delivery can be performed for multiple subscribers asking for the same content. If not found in PIT, the second step is to check it into the CS; if found there then it is returned on the interface at which the interest was received, and interest is deleted. If content is not in CS and there is no entry in PIT, then CR makes an entry of it in PIT and forwards it to other CRs by creating an entry in FIB for this interest as depicted in Figure 10.4b. However, CCN has a different philosophy of treating incoming Interest packet, and it can be seen in Figure 10.4a.

Figure 10.4 Basic operational perspectives of CCN versus NDN. (a) Content-Centric Networking (CCN). (b) Named Data Networking (NDN).
Handling subscriber mobility in NDN is quite similar to that of other ICN approaches in which the subscriber reissues interest messages from new location, but the content against old interest messages are delivered to old CR. The publisher mobility is difficult to handle because the FIB entries have to be restated when a publisher moves from one CR to a new one. It becomes harder to handle publisher's mobility in very dynamic networks such as mobile ad hoc network (MANET). For this purpose, NDN employs Listen First, Broadcast Later (LFBL) protocol. In LFBL, a subscriber floods the interest message to all publishers. Any publisher having content against the interest checks the medium whether any other publisher has already replied with the content or not; if not then it sends the content to the subscriber.
10.4 NDN-based Application Scenarios for Smart Cities
As aforementioned, the NDN has been proved to be one of the most widely explored architectures of the Future Internet. The reason behind this research plethora is the support of NDN for various applications. In this section, we will focus on varying application perspectives that contribute to build a smart city (Figure 10.5).
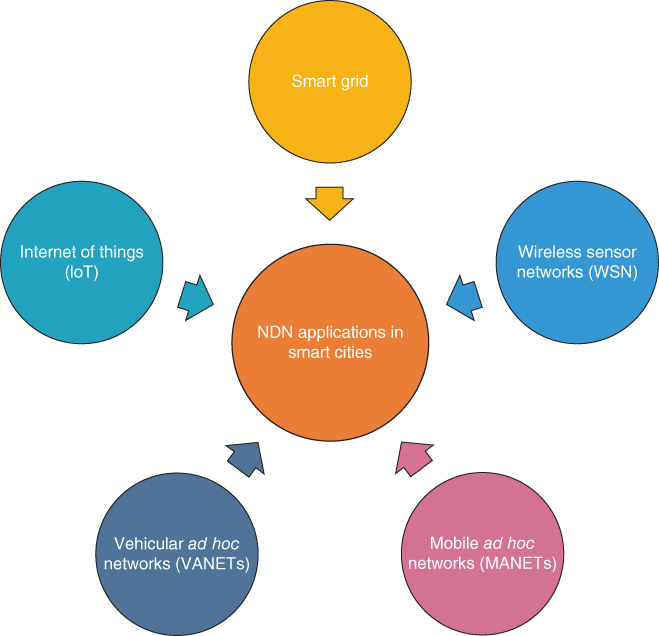
Figure 10.5 NDN potentials and applications.
10.4.1 NDN in IoT for Smart Cities
It took us a while to figure out the exact definition of an IoT system; currently we define IoT as the collection of small battery-operated devices having sensing, computation, and communication capabilities and are attached with the objects (i.e., anything). IoT enables those devices to connect with each other via Internet. These connections between devices make them smarter to exchange and process the information to/from other devices autonomously or with partial intervention of the humans. Rather than a point-to-point communication scenario, the massive size of network in terms of numerous devices does have a focal point on Data. Thus, the smart applications for IoT argue for the contextual type of information generated either reactively or proactively by those devices [[14]]. Here we state the following key issues with such type of networks:
- • Naming and addressing each device in dynamic fashion
- • Protocols and algorithms to ensure energy efficiency
- • Self-organization and network management
- • Interoperability standards and network scalability
- • Network and service discovery
- • Cloud connections and their computation
- • Minimum latency in real-time communications
- • Dynamic partitioning and merging of the network
- • Scalable security solutions
- • Mechanisms for a push-based communication.
As aforementioned, IoT has been recently researched due to its support to a huge collection of applications. Hence, the Future Internet architecture, that is, NDN, has also shown some potential and is worth to be investigated in the IoT. For example, in [[15]], the authors proposed ICN architecture for IoT. In the context of this work, the IoT contents are addressed using the names, and the concept as a home automation system was implemented. Also, the implementation in this work used the push-based communication mechanism.
Similarly, in [[16]], the authors used push-based communication methodology for an IoT traffic using Future Internet architecture. Initially, the authors described the subscription scenario where subscription is done by sending an Interest message that uses the hierarchical name for the desired content without creating the PIT entry for each interest forwarded. The reason for not creating the PIT entry is that no Data is immediately expected for this interest. However, the authors mention that PIT entry creation will avoid the Interest looping.
Another proposal that analyzes the application of NDN in IoT is presented in [[17]]. It suggests that complete ICN mechanism cannot be implemented on IoT nodes because of their power, sensing, processing, and memory constraints. Therefore, some functionalities, that is, security and caching options, are delegated to the third-party trusted nodes. Furthermore, the optimal caching can be achieved by only storing the latest sensed information that is achieved by using the counter or sequence numbers. In [[18]], experiments were performed with NDN implementation on IoT deployment in multiple office buildings.
Precisely, most of the IoT proposals just focused on the simple scenarios where the Interest is used to subscribe for Data and the Data is sent for that subscription period. Generally, there is periodic sensing in the IoT application, but the Data may also be generated in response to the event detected by the sensors; this is called unsolicited emergency notification [[19]]. The application requires this notification to be pushed in the network, either in unicast or multicast manner. However, there should be CCN proposals that implement the unsolicited emergency message communication support along with the solicited Data communication in IoT. There are several other issues that must be addressed when adopting CCN in IoT, and the authors are suggested to explicitly refer the related work.
10.4.2 NDN in Smart Grid for Smart Cities
Still the research community has diverse definitions of a smart grid; however, in the context of this chapter, we define it as follows: smart grid integrates advance communication, control and automation, computer-based technology, and systems that manages, regulates, and brings the responsive and resilient utility electricity network. The grid connects the power generation sources and manages the electricity demand in a reliable, sustainable, and economic manner. Balanced demand-based supply of electricity is one of the main objectives of smart grid because most of the electricity generation relies on fossil fuels that increase the amount of harmful gases in the environment. The smart grid is a system of systems consisting of many components (refer Figure 10.6), including, but not limited to, the following:
- • Smart meters: The utility meters enabled with communication technology to connect energy consumers and the providers to automate billing, regulate demand, and detect faults to speedy recovery.
- • Smart electricity generation: There are several power generation sources ranging from renewable to the one that consume fossil fuels. Smart electricity generation system optimally generates electricity to meet the demand with minimum cost and carbon emission.
- • Smart power distribution: The power distribution system connects the power generation sources with the consumers through distribution lines and smart substations. It has self-optimizing, self-healing, and self-balancing capabilities to automatically predict and detect power failures in real time.
- • Smart substations: It controls and monitors the critical and noncritical operational Data, that is, battery status, transformer status, breaker information, power factor performance, security, and so on.
- • Information and communication technologies: Provide means for all the components to interact with each other to conserve energy by efficiently utilizing, distributing, and generating the electricity.

Figure 10.6 Components of the smart grid.
Recently, ICN architectures and their effectiveness have been investigated in the smart grid systems to investigate their feasibility and effectiveness. For instance, Katsaros et al. [[20]] promote the use of ICN in smart grid applications and suggest the use of publish-/subscribe-like communication to ease the smart grid control with simple and secure Data sharing. The smart grid also uses many-to-many Data communication approach between devices and applications; therefore, ICN is envisioned to be a proper communication architecture for smart grids in future. Currently, the ICN framework is used as an overlay on smart grid communication to enable seamless and robust communication.
Similarly, in [[21]], the authors implemented the ICN-based communication infrastructure, called C-DAX, to support Data communication in the smart grid. They proposed the C-DAX architecture, and its components and plan have fully functional lab demonstration as well as porting the implementation to the actual smart grid system in the Netherlands.
10.4.3 NDN in WSN for Smart Cities
Wireless Sensor Networks (WSN) is an integral part of IoT as the collection of large number of small battery-operated devices capable of sensing and communicating (see Figure 10.7). The WSN consists of inexpensive and large number of devices spread or installed in the sensing area that monitor the environmental or physical parameters, that is, humidity, temperature, pressure, vital signs, water salinity, soil moisture, and so on. A typical tiny sensor node consists of the following components connected as a single component:
- • Communication
- • Computing
- • Sensing
- • Power source
- • Actuation.
The operations that consume the battery power are wireless communication, sensing, processing, and listening. Therefore, a node must have to efficiently schedule its operations. Along with the longer lifetime, the WSN must self-configure and self-organize itself due to dynamic network architecture resulted by the node failures [[22]]. Several routing solutions and proposals have been presented in pastto achieve energy efficiency, self-configuration, and self-organization. Researchers in the area of WSN may further review [[23, 24]].
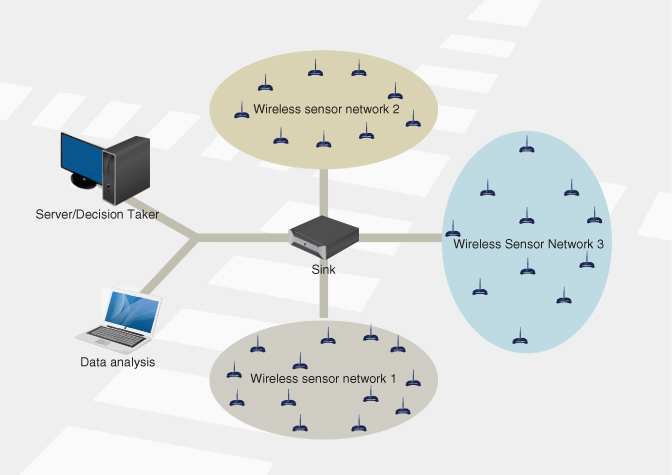
Figure 10.7 Generic overview of WSN deployment.
Recently, the Future Internet architectures have been investigated in WSN. In [[25]], Rawat et al. implemented the CCN-named Data communication stack in Contiki [contiki] operating system. Contiki is one of the operating systems for WSNs and embedded systems that contain resource-constrained devices. The implementation considers the hierarchical naming (similar to CCN) consisting of the name prefix followed by the content attributes as follows:
Prefix:
Content Attributes:
The implementation uses Interest and Data messages of 102 bytes to match the IEEE 802.15.4 frame that is 127 bytes long (127–25 (bytes MAC header) =102 bytes). Processing steps of these messages are modified to suit the processing capabilities of the WNS nodes. CCN PIT, FIB, and CS are also implemented accordingly. Moreover, the Future Internet implementation in Contiki is evaluated through simulations and real deployment using synthetic monitoring applications for varying network sizes.
Singh and Sharma [[26]] implemented the content-centric environment for WSN in Wieslib [[27]]; that is, library of algorithms form heterogeneous sensor networks. CCN implementation for WSN is named as CCN-WSN, which implements the hierarchical naming, Interest message, Data message, PIT, CS, and FIB. Evaluation of this flexible implementation of CCN-WSN demonstrates the suitability of CCN in WSN. The CCN architecture for WSN was proposed in [[28]]. The architecture is divided into two tiers; first tier manages the heterogeneity devices that comprise the WSN (sensor node, sink, remote server). CCN is enhanced with some changes to the forwarding strategies to improve Data collection. The second tier is the modified, lightweight, and shortened CCN forwarding strategy encompassing forwarding Data structures (FIB, CS, and PIT), messages (Interest and Data message), transmission, and techniques for message retransmission.
The above discussed solutions are the preliminary CCN implementation and their validations in WSN. However, a more serious attention of researchers is required to propose more energy-efficient CCN-based solutions for WSNs.
10.4.4 NDN in MANETs for Smart Cities
MANET is an autonomous, infrastructure less, self-healing, self-organizing, dynamic topology, and multi-hop nature network of mostly battery-operated nodes. Varying applications are precisely presented in Figure 10.8. These characteristics of the network make Data delivery between source and destination node more challenging. Due to its multi-hop nature and dynamic network topology, Data dissemination is with less control overhead to conserve energy and more reliability. There have been a lot of research to resolve these issues; however, the issues are still pending and the research is still ongoing. There is a lot of literature and books available on the topic, and the readers can go through the following very recent articles to get the quick information about the topic [[29, 30]].
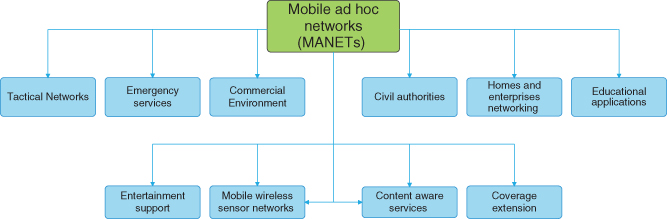
Figure 10.8 Different applications and services supported by MANETs.
After the invention of a new future emerging network paradigm, which substitutes the traditional IP-based, location-dependent, and host-centric networks with the name-based, location-independent, and Data-centric network, researchers investigated those in MANETs. For instance, in [[31]], the authors proposed the NDN-based new Data forwarding scheme for MANETs named LFBL. LFBL uses three-way message exchange (announce the name prefixes, forward Interest, and return Data) that is supported by NDN. Initially, a node disseminates the network-wise request carrying the name of the Data requested by the application. Any node with the requested named Data sends a response packet, backward to the requesting node. Next, the Data receiving node sends the acknowledgement (positive or negative) packet. Similarly, Mahmood and Manivannan [[32]] implemented the CCN on laptops running Linux OS creating on-demand MANET. The CCN Data structures that are implemented include CS, MetaData registry, and Interest table. The large MANET for emergency and tactical scenario with hierarchical architecture, group mobility, and operation is considered in this work. Initially, the publisher disseminates the meta-content information that is disseminated through gateway nodes at the upper layer of the hierarchy in each group and recorded at each node's registry in each group. The node sends Interest to gateway node and the gateway replies with the matching content if it has the copy. Otherwise, the Interest is sent to other gateways to find the content, which makes these gateways responsible to publish and deliver Data. Furthermore, in [[33]], the authors pointed out the fundamental approaches to identify the fundamental points in the design of content-centric MANET (CCM). The performance and efficiency of the identified design is evaluated through modeling. Announcement of content availability, sending query to find the content, and fetching the content are three major operations that are considered in the modeling space. There are three schemes that are identified in the paper to retrieve content in MANET. The first is reactive flooding, where the requesting node floods the requested message to find the content, service, or location of the content or service provider node. In this case there is no announcement; just a node floods the query message and the content provider replies with Data or service in a unicast manner to the requesting node. The second proposed design is the proactive flooding, where each node periodically floods the resource or content availability in MANET. The requesting node just listens to the periodic announcements, and then the request and content delivery are performed in a unicast manner. The third and the last CCN design for MANET uses Geographic Hash Tables (GHT). This design assigns a key to each resource in the network, and the hash operation through this key may provide a pair of two-dimensional (![]() ) coordinates. The node first announces the pairs (resource, host) to the nodes closest to the resource key. The requester first computes the hash of the resource that it is interested in, which provides the location of node(s) holding the pair of (resource, host). The query is forwarded in a unicast manner to these nodes through GPSR protocol. The content fetch operation is performed once the resourcehost information is retrieved. The fetch and content forwarding are unicast operations. Content availability, latency, and overhead cost are modeled by the authors.
) coordinates. The node first announces the pairs (resource, host) to the nodes closest to the resource key. The requester first computes the hash of the resource that it is interested in, which provides the location of node(s) holding the pair of (resource, host). The query is forwarded in a unicast manner to these nodes through GPSR protocol. The content fetch operation is performed once the resourcehost information is retrieved. The fetch and content forwarding are unicast operations. Content availability, latency, and overhead cost are modeled by the authors.
In [[34]], Content-centric fasHion mANET (CHANET) has been proposed. The CHANET architecture provides detailed processing of the broadcast nature Interest and Data messages and many features for 802.11 based MANET including:
- • Hierarchical naming
- • Content segmentation and reassembly (content divided into chunks)
- • Content advertisement (periodically by fixed providers, e.g., access point)
- • Content discovery (interest message) and delivery (Data message)
- • Retransmission request (Int-Ack message).
CHANET brings simplicity and robustness by using the broadcast nature of CCN messages. Nodes overhear the broadcasted messages and defer time to reduce the number of collisions. The Interest and retransmission request message forwarding decision is made by the node itself that receives the messages. It indirectly provides the retransmission request (embedding acknowledgments in the Interest packets) and sequence control mechanism. The consumer-provider mobility is inherently implemented and supported by the scheme.
Meisel et al. [[35]] propose the CCN scheme for MANETs that avoids the message loss in MANETs. The scheme uses the neighborhood information and defers time to achieve this goal. Detection of neighbors is done by periodic overhearing of the communication activities of the neighbors. If a node does not hear any periodic advertisement or any communication activity, the link to that neighbor is considered broken. The Interest and Data messages may be broadcasted or unicasted. In the case of broadcasted messages, time-to-live (TTL) value is used; however, TTL is not considered for the unicast messages. If a node has any content, it is advertised by that node. Intermediate nodes that receive these content advertisements may record all the paths toward the content source in FIB. Another Interest flooding control scheme, called neighborhood-aware interest forwarding (NAIF), for NDN-enabled MANETs has been proposed in [[36]]. NAIF initially prunes the ineligible forwarders because it selects the potential forwarders from the forwarder set based on Data retrieval rate and its distance to the content provider.
Cianci et al. [[37]] and [[38]] implemented the content-centric design for MANET's one handheld device called SCALE. The authors use nodeID to reflect its geographic coordinates, content name, and several other parameters to achieve content communication. The demo supports three functions: publish, subscribe, and query the content. The Data in cache is indexed based on the content instead of content name.
As most of the MANET nodes are battery operated, mobile, and communicate without infrastructure support, the CCN solution must be efficient in content discovery, reliably forwarding messages, and support security. The proposed solutions just focus on the application and testing of CCN architecture, and more solutions are required to support reliability and efficiency of CCN messages and alleviate bandwidth congestion resulting from the broadcast nature of network.
10.4.5 NDN in VANETs for Smart Cities
VANETs are reality of the near future and play a vital role in everyday life by providing services, for example, safety and comfort of passengers on the drive and infotainment. VANETs support various sets of applications as shown in Figure 10.9. The vehicular network comprises vehicles with communication capabilities. One of the most prominent characteristics of VANET is its highly dynamic topology that makes it challenging to propose any efficient and promising communication solution. Along with that it is also proved by many researchers that TCP/IP communication protocol stack is inefficient for mobile networks. This is the reason that a separate protocol stack for VANETs called the “wireless access in vehicular environments” (WAVE) [[39]] has been proposed. WAVE supports Data exchange without the TCP/IP overhead, through WAVE short message protocol (WSMP) that was designed for safety critical and control messages.
Figure 10.9 Application overview of VANETs.
Recently, there has been a lot of research with the intention to reliably communicate emergency information, traffic status, vehicle sensory Data, and infotainment information in a nonhost-centric manner by using information-centric communication mechanism. Content-centric approaches are briefly discussed and summarized in [[38]]. Here, we discuss and summarize the very recent NDN-based schemes for VANETs.
The very first proposal in [[40]] employs named Data communication mechanism to collect vehicles' sensory Data from the mobile vehicular network. This information may be used by the manufacturing or related companies to provide vehicle management, safety, and alert information to the drivers or owners of the vehicles or companies. A hierarchical naming scheme with company, type of information, country, state, and so on is used to request this sensory information.
Since, NDN uses hierarchical naming with general components to identify the contents. The formal naming scheme for vehicular networks to represent spatial and temporal vehicular information has been proposed in [[41]]. This naming scheme is used by vehicular applications to communicate contents between vehicles and the infrastructure. The vehicular network information is identified by the following naming scheme:
TalebiFard et al. [[42]] proposed a content-centric communication scheme for autonomous vehicles, named “CarSpeak.” CarSpeak-enabled autonomous vehicles communicate sensory information from neighboring cars as well as the sensor installed on the static infrastructures, for example, RSU, road side buildings, and so on using the content-centric Interest–Data mechanism.
Due to the broadcast nature of the wireless faces, collision of Interest and Data messages is inevitable. Amadeo et al. [[43]] introduced different timers to avoid the NDN message collisions in an NDN-enabled vehicle-to-vehicle (V2V) multi-hop highway communication network. The timers include collision-avoidance timer, pushing timer, NDN-layer retransmission, and application retransmission timer. In collision-avoidance timer, a node randomly delays Interest of Data transmission between 0 and 2 ms. Push type messages are scheduled based on the pushing timer that is computed based on the transmitter-receiver distance, maximum transmission range, and minimum next-hop delay. NDN-layer retransmission timer (50 ms) and application retransmission timer are used to schedule the retransmission of NDN messages over the lossy wireless network.
A hierarchical Bloom-filter routing (HBFR) has been proposed for CCN-enabled VANET in [[44]]. HBFR identifies each chunk of the content object with hierarchal name, for example, /Category/Service-Name/Additional-Info/. The category shows the type of content based on its size, type, popularity, and so on. The service name identifies the Data services provided by the node(s) based on time sensitivity of the content. Additional-Info consists of any additional information about the content. The proposed HBFR framework adaptively performs reactive and proactive content discovery based on content characteristics. It uses Bloom filters to announce the popular prefixes, and the announcement is restricted within a geographical region. The network is divided into hierarchical geographic regions to restrict the distribution of messages to reduce overhead. Vehicles in a single region form a cluster, and every vehicle in that region is a member of that cluster. The contents' advertisement by a vehicle includes its region information, and it adds the content prefixes using Bloom filters in the content advertisements. These Bloom-filter-based advertisements are shared between regions to get full view of the contents and their respective regions to easily discover and communicate the desired content.
Amadeo et al. [[45]] proposed the content segmentation–reassembly and reliable content delivery scheme by scheduling the retransmission of Interests for the lost Data messages. For faster recovery of the lost Data messages, the Interest is retransmitted depending on the dynamic round-trip time (RTT) of Interest–Data exchange. Average RTT over multi-hop path is estimated as weighted moving average of RTT samples, and based on this information, retransmission time out is scheduled.
A last encounter content routing (LER) in [[46]] is an opportunistic geo-inspired routing scheme for CCN-enabled VANET. Each vehicle that runs LER maintains two tables named content list and last encounter list (LEL). The content list contains the list of all contents that the vehicle holds and is shared within 1-hop neighbors. LEL enlists the content information received from the neighboring vehicles and enlists the provider ID, encounter position, and time. A content provided by multiple vehicles have multiple entries in the LEL. The Interests are forwarded toward the location provided in the message.
The results of the vehicular NDN implementation over vehicles have been presented in [[47]]. The implementation uses various wireless faces, that is, Wi-Fi, WiMAX, IEEE802.11p, and so on, and the messages are transmitted over all the available faces to avoid the disruptions caused by the intermittent connectivity. The experiments have been performed when the vehicular network had no mobility, vehicles moved in platoon, and vehicles moved around the UCLA campus.
In [[48]], authors proposed the forwarding scheme that fetches Data from a plethora of providers using the digital map information. Navigo binds the NDN Data names to the producers' geographic area(s). It uses the shortest path algorithm to forward Interests to the geographic area of the potential provider. The authors also claim the application of adaptive best Data provider discovery and selection scheme from multiple geographic areas.
A RobUst Interest Forwarder Selection (RUFS) scheme for VANET has been proposed in [[49]]. RUFS mitigates the interest broadcast storm by selecting the suitable next-hop forwarder vehicle. In RUFS, each vehicle shares its satisfied interests' statistics with the neighboring nodes. This information is managed in the neighbors satisfied list (NSL).
The traffic violation ticketing (TVT) application for the CCN-enabled vehicular networks has been proposed in [[50]]. It discusses the utilization of CCN Interest and Data messages used by the cop vehicles to issue tickets to the vehicles that commit violations. Additional Data structures are maintained to achieve this application perspective. The same authors extended their work one step ahead and evaluated their smart traffic ticketing architecture with the support of NDN and named it as “SmartCop” [[51]].
Since naming any content also plays a vital role in searching latency and does affect the overall performance, we do need research efforts in this context. For example, the hierarchical and hash-based content naming scheme for vehicular networks is proposed and evaluated in [[52]]. This new naming scheme encompasses provider's identity, different components that represent the content attributes, and the spatiotemporal resolution of contents. A small hash component is also part of the name that helps to precisely identify the content. Along with that a compact trie-based name management scheme has been adapted to manage the content name to speedy search, delete, and add the name in the name prefix tables. Analysis shows that the proposed name management scheme is more suitable for the variable length name prefix management in CNN.
10.4.6 NDN in Climate Data Communications
In addition to the aforementioned applications, the researchers also explored the use of NDN in Climatic Data Communications. Similar to others, the NDN has also been foreseen as a potential solution in Data-intensive field such as climate science. Shannigrahi et al. [[53]] discussed the similarities and differences between the climate and high energy physics (HEP) use cases, along with specific issues that HEP faces and will face during LHC Run2 and beyond, which can be addressed by NDN.
The researchers have successfully tested NDN in the climate application domain [[54]]. To handle the various naming schemes used in climate applications, they designed and implemented translators that take existing names with arbitrary structure (produced by climate models or home grown) and translated them into NDN-compliant names. Depending on the original name structure, the translation can be fairly direct (e.g., Data that comply with the “Data Reference Syntax” from the Coupled Model Intercomparison Project) or complex (from home-grown naming schemes that require the analysis of metadata embedded in the dataset or even user feedback in order to construct proper NDN names).
Likewise, there are several features of NDN that can be beneficial to the HEP computing use case. For example, the Data sources publish new content to the network following an agreed-upon naming scheme. Data delivery is always performed in a pull mode, driven by the consumer issuing interest packets. Intermediate nodes in the network dynamically cache Data based on content popularity, ready to satisfy subsequent interests directly from the cache, thus lowering the load on servers with popular content. Combining this with the pull mode results in a multi-cast like Data delivery, possibly optimizing both the network utilization and server load. Similarly, the use of multiple Data sources simultaneously, as well as the native use of multiple paths between client and Data source, provide for robust fail-over in the case of network segment, node, or end-site failure.
HEP experiments using the Worldwide LHC Computing Grid (WLCG) have well-developed, hierarchical naming schemes in use, which already fit the NDN approach well. We can take this logical file name structure as a starting point for investigating the benefits of using NDN as the Data distribution and access network for HEP Data processing. In short, all these are active research areas today, where caching as well as forwarding strategies, naming schemes, multisourcing, and multipath forwarding need to be investigated from not only the network but also the application perspective.
10.5 Future Aspects of NDN in Smart Cities
There are different categories of future aspects in NDN that must be addressed; however, we divide them as per their related NDN components, including content (chunking, discovery, manifest, multihoming, etc.), naming (hierarchical, hash based, attribute based, name management scheme, etc.), Data Structures (PIT management, FIB management, etc.), NDN message forwarding, content caching, dynamic network topology (provider mobility, consumer mobility, effects of dynamic topology on content forwarding, etc.), and security and privacy. For instance, NDN research directions are briefly discussed in this section.
10.5.1 NDN Content/Data
Content can be any binary object or binary stream, such as a file of any type, audio stream, and video stream. In general, most of the research is focused on how to name a content and efficiently forward the content in NDN. There are some basics about the content that should be addressed, for example, chunking, manifest, and multihoming. Content chunking divides a large content into multiple small identifiable pieces to efficiently forward the content from the consumer to the provider. It also provides a means to evenly disperse the content in the distributednetwork caches. There is no NDN standard to divide a content into chunks of universally equal size. Some of the research works assume that a content chunk is equal to the size of an MTU. The fact is that the MTU size may vary based on the face type. Therefore, if a node receives multiple chunks of the content that do not fit the outgoing face, then the chunks require rearrangement. It also poses additional issues that need to be resolved for the NDN transport layer. These issues are enlisted, but not limited to, as follows:
- • Synchronization between different chunk providers or chunk sources
- • Receiver-driven synchronization
- • Cache management policies for chunks
- • Chunk-level security checks
- • Chunk-based or content-based identification
- • Content or chunk-based authentication
- • Content manifest.
The above said issues have influence and pose complexity to many other aspects that affect efficient content communication in NDN.
10.5.2 Naming Content/Data in NDN
Content object retrieval in NDN usually involves two stages: discovery and delivery of the content using Interest and Data messages. The content is discovered through its name that uniquely identifies it in the network. This is the reason that a content name is a mandatory TLV in the Interest and Data message. Interest message with a content name is used to discover content. The content delivery involves the rules to route contents on the network, and it also uses the content name to take routing decisions.
There are different ways to represent the name, including hierarchical, flat, and attribute-based “names.” The pros and cons, management, and respective issues related to each of these schemes are yet to be explored. However, here we will focus on the future directions concerning the hierarchical naming scheme used by the NDN architecture.
Due to the hierarchical nature of the naming scheme used in NDN, names can easily be aggregated and naturally have the longest prefix matching feature. Along with these inherent features, there are still some issues that need to be resolved. Following are the future research directions, but not limited to, that must be addressed:
- • The evaluation to measure the effectiveness and scalability to Internet level is yet required for hierarchical names.
- • Security information is not part of the NDN naming because it assumes explicit security provided by the content itself. Therefore, the hybrid schemes are required for NDN naming to provide security information within the name.
- • Longest prefix matching on name string is time consuming and requires feasible solutions to minimize the search time.
- • Efficient Data structures are required to optimize the memory usage for hierarchical names with varying prefix sizes.
- • Related to the previous point, the Data structure should also be effective enough to perform speedy management of hierarchical names such as adding and deleting the name prefixes because the arrival rate of the names can be much higher in the global scale Internet.
- • Number, position, and size of the hierarchical name components are not fixed, and inferring the name components is still application dependent. Hence, there is a need to standardize naming structure and inference of the rules.
- • There are some applications, for example, vehicular networks, WSNs, and so on where spatial and temporal scope contents are required. There are few schemes that discuss these issues; however, more research in this aspect is required.
- • Hardware-level implementation and management of hierarchical names is still a pending issue.
10.5.3 NDN Data Structures
The name prefixes are managed in PIT and FIB to forward Interest and Data messages in the network. NDN keeps track of many parameters, that is, NONCE list, dead NONCE list, timers, and so on to avoid routing loops. The incoming name plus face information and outgoing face plus prefix information are stored in PIT and FIB tables of NDN. These tables are refreshed and stale information is removed. The size of these tables and Data delivery rate are directly related to the refreshing duration. Therefore, it is required to test this effect in varying network scenarios, for example, wired, wireless, and dynamic topology networks. The size and look-up efficiency of these Data structures is still an open issue in NDN.
10.5.4 NDN Message Forwarding
NDN uses FIB and PIT to forward Interest and Data messages in the network. Basically, most of the Interest messages are forwarded through longest prefix matching within FIB. The Interest message is forwarded to face that is associated with the matching FIB entry. In the case of multiple outgoing faces, the forwarding strategy selects the most stable (Note: The description of most suitable depends on which parameter is being used to rank the outgoing face as most suitable, for example, Interest satisfaction rate, most recent activity over face.). However, there may be the possibility that a subset of the faces may be selected to forward interest message. Therefore, an efficient forwarding mechanism is required that not only selects outgoing face on FIB match but also considers network and neighborhood parameters.
Moreover, the Interest is forwarded between the consumer and the provider node through multiple paths, and the consumer may receive multiple copies of the Interest message at varying time instances. Normally, a provider or a caching node in NDN replies with Data to the first Interest message that it receives, and the following received copies of the Interest message are dropped by the provider node. In this case, there may be the possibility that the downstream direction in that path may not be suitable to forward Data message. Therefore, a provider node must hold the Data message and select that best path based on the path information received through multiple copies of the Interest message from different paths. The duration to hold the Data message and selection of the suitable path(s) is still an open issue and a possible future research direction.
The Interest overhead is one of the issues that should be mitigated in NDN [[55]]. An Interest message is forwarded by each node that receives the Interest message and has no PIT entry. This may lead to a very high Interest overhead, and that can be minimized by limiting the number of Interest forwarders to be investigated [[56]]. Additionally, the new transport modes should be examined that may include anycast (any to any), multicast (i.e., one to many), andconcast (i.e., many to one).
Likewise, distributed caching in NDN may also pose a situation where multi-provider for a single Interest is possible. In this case, the consumer must select the most suitable provider among the subset [[57]]. When an interest is issued for a content object that can be satisfied by the subset of providers, the synchronization between that subset of providers is necessary to increase the content transfer efficiency.
10.5.5 Content Discovery in NDN
NDN uses content name in the Interest message to discover the content in the network. As previously discussed, the interest messages are routed based on the longest prefix matching in content name tables, that is, PIT and FIB, which are maintained at each NDN-enabled node in the network. The provider node or any intermediate node that has the matching copy of the content in its cache sends the Data message to the consumer node following the reverse path. There is no location information available for the desired content provider in the network. One of the solutions to cope this problem is to maintain additional information regarding the content providers in the Data structure(s) based on the previously satisfied Interests. The next Interests demanding the same contents are forwarded toward those providers. However, if a node has no provider information available, then it follows the conventional CCN forwarding mechanism.
Our discussions so far have provided the base to explore the topic to answer the following questions:
- • How contents can be discovered with minimum overhead?
- • How to reduce content discovery delay?
- • What are the efficient methods to manage neighborhood or network-wide content information on a node?
- • What is the effect of content discovery on content communication efficiency in NDN?
- • Is content discovery feasible in highly mobile or highly dynamic topology networks?
10.5.6 NDN in Dynamic Network Topology
Dynamic network topology is defined as a network topology that varies over time due to node mobility, node failures, link failures, and so on. There has been a lot of research to handle network dynamicity in the past, and many solutions have been proposed for wired and wireless networks. It is argued that consumer mobility is inherently handled by most of the ICN architectures (especially CCN/NDN) because they use pull-based or consumer-driven scheme. Previously cited work mostly focuses on the consumer and/or provider mobility, where they try to achieve higher Interest satisfaction and delivery rate and minimize the latency. It is claimed in architecture documentations that NDN inherently handles the mobility by detaching the location information binding with the content. However, the receiver and provider's mobility may have a high impact on the Interest and Data message transmission. Another side effect of dynamic topology other than the Data-Interest message loss is that it leaves routing information traces in the tables at intermediate nodes, which may increase the communication delay due to high lookup cost. The issues related to provider mobility that are identified and need to be addressed are locating provider node all the time and maintaining the connectivity until complete content is received. In the absence of position information and route updates in NDN, it requires new mechanism(s) to cope with these issues. Another question that is waiting for an answer is the examination and the benefits of caching in dynamic topology networks. Additionally, the new schemes are required to ensure intactness of content in the presence of mobility.
10.5.7 Content Caching in NDN
Content caching is not a new topic in communications networks and has been intensively investigated in the past. Most of the studies are focused on caching in web applications and peer-to-peer networks. There are different caching schemes, that is, least frequently/recently used (LFU/LRU), most frequently/recently used (MFU/MRU), leave copy down (LCD), popularity-based caching, and so on, that are investigated in CCN. It is argued and serious concerns are discussed that extensive use of caching in CCN will not have considerable benefits. Therefore, more investigations are required to explore caching based on various communication patterns in CCN. Caching may pose more challenges on efficient cache size utilization when the network topology is unpredictable, and there is need to focus some research on investigating issues. The information popularity is another issue that must be investigated that how dynamic content popularity is decided.
To summarize the discussion, solicitation of in-network caching and replication schemes for CCN requires new paradigms that jointly investigate routing, forwarding, and cache management optimization, that is, effect of cache locations onrouting decisions, cache contention for varying information nature, and so on.
10.5.8 Security and Privacy
CCN claims to secure the content rather than the connection. In other words, instead of securing the connection between the sender and receiver, CCN inherently secures the content by sending security-related information along with the content itself. Now the question is, what is content security, or what are the security aspects related to the content in CCN?
CCN architecture requires public key cryptography (PKC) to bind a public key with content name. The PKC is also used by most of the ICN architectures to provide security and privacy features. Main focus of CCN is to secure the content object (either as whole content object or each individual chunk of the content object). However, it poses the following questions: Is it necessary to digitally sign and encrypt every content and how to decide which content should be encrypted or signed? To secure the content, a producer or generator of the content digitally signs the content, and the publisher's information is also provided within. This avoids third-party dependency. The consumer uses this supplementary information with the content object to detect the content integrity that the content object is tempered by any node during communication between producer to the consumer, and it also assures that the content is produced by the trusted publisher. The hierarchical names are human readable and can easily identify the publisher of the content. This can easily bind the name with the publisher. However, there must be some mechanism to verify whether the key associated with the name really belongs to the publisher or not.
As most of the ICN architectures, including CCN, rely on the PKC to provide security, then the paramount question is that who will be responsible for creating, distributing, and revoking these keys. In addition to that, if CCN relies on the trusted entities for name verification, then the key management can become a prime issue in CCN.
In mobile networks, especially ad hoc nature networks, the security and resolution of several security attacks is still a challenging issue. CCN claims and focuses on securing the content using public key encryption rather than the connection, which means that it promises that the content is same as it asserts. This may raise more privacy issues because the content name is advertised in the Interest messages. In infrastructure-supported wireless networks, the privacy and trust are alleviated due to various points of management in the network, for example, access routers. However, pure ad hoc and mobile networks without any infrastructure support require robust solutions to handle the privacy and security threats. The solutions can be more challenging in constrained device scenarios, for example, limited processing power, small memory, and limited bandwidth.
There are several security attacks that have been identified for CCN/NDN, and they require robust solutions to prevent those attacks, for example, denial of service (DoS), distributed DoS (DDoS), sniffing and watchlist, blackhole, flooding, and content pollution.
10.5.9 Evaluation Methods
Currently, many researchers are pursuing and publishing their solutions for CCN, and they evaluate their schemes through simulations and theoretical and empirical evaluations. There are only few schemes that have been empirically evaluated due to time, budget, access, and other limitations. However, most of the proposals have been proposed for a varying range of network scenarios (IoT, VANET, WSN, MANET, etc.) and simulated in the freely available or open-source simulators.
Most of the solutions are evaluated through simulations, and, along with that to keep fairness in evaluation, there should be standard or baseline network scenarios to be considered in the simulations. In addition to that, traffic load, content popularity, and different other metrics are also explored by the authors. To keep the fairness in simulation evaluation for the proposed schemes, it is necessary to have baseline scenarios and standard parameters. There may be additional challenges in CNN that should be explored because an active, ongoing research on the topic is being pursued around the globe.
10.6 Conclusion
Recently, it has been noticed that people are more interested to live in urban areas due to the more healthy and secure environmental technologies. Moreover, the connectivity among devices and oversees plays a vital role in transforming a smarter life in cities. On the other hand, the current IP-based Internet is facing a lot of delays and security issues due to the massive traffic and demand from the end-user. Therefore, we expect that in future smart cities, the current Internet will not be enough to handle the demands. Hence, we need to integrate the concepts of Future Internet into smart cities and check the feasibility of these emerging technologies.
In this chapter, therefore, we have enlightened the promising Future Internet architectures and their applications in smart cities. We also summarize the current advancements in the field of CNN and named Data networks that are relevant to the smart cities. We expect that our chapter will contribute and encourage our readers pursue the challenges and research road map provided in the end of the chapter.
Final Thoughts
In this chapter, we first discussed the legacy of the Internet architectures and the relevant recent developments. Furthermore, we introduced the Future Internet architectures and provided a brief introduction to the groundbreaking technologies. In addition, we also focused on the main objective of this chapter, that is, to provide an insight on NDN and its applicability in various applications that can be useful in building a smart city. In the end, we also enlist few of the existing challenges and research areas for NDN research community. We expect that our chapter will make our readers familiar with the basics of NDN and its applications.
Questions
-
1 What is the difference between IP-based and Named Data Networking?
-
2 What does DONA stand for and what are the naming characteristics of DONA in general?
-
3 What are the basic operational differences between content-centric and Named Data Networks? You may draw a flowchart diagram that shows the differences?
-
4 Describe any application of the Vehicular Named Data Networking for smart cities?
-
5 What are the existing challenges or future aspects of message packet forwarding in NDN?
References
- 1 Mazières, D., Kaminsky, M., Kaashoek, M.F., and Witchel, E. (1999) Separating Key Management from File System Security. Proceedings of SOSP '99, December 1999, Charleston, SC, USA, pp. 124–139.
- 2 Moskowitz, R. and Nikander, P. (2006) Host Identity Protocol Architecture RFC 4423, IETF.
- 3 Xylomenos, G., Ververidis, C.N., Siris, V.A., Fotiou, N., Tsilopoulos, C., Vasilakos, X., Katsaros, K.V., and Polyzos, G.C. (2014) A survey of information-centric networking research. IEEE Communications Surveys & Tutorials, 16 (2), 1024–1049.
- 4 Ghodsi, A. et al. (2011) Naming in Content-Oriented Architectures. Proceedings of ACM SIGCOMM Workshop Information-Centric Networking, August 2011, Toronto, Canada.
- 5 Dannewitz, C. et al. (2010) Secure Naming for A Network of Information. Proceedings of the 13th IEEE Global Internet Symposium '10, March 2010, San Diego, CA, USA.
- 6 D'Ambrosio, M., Dannewitz, C., Karl, H., and Vercellone, V. (2011) MDHT: A Hierarchical Name Resolution Service for Information-Centric Networks. Proceedings ACM SIGCOMM Workshop on Information-Centric Networking, ACM, New York, NY, USA, pp. 7–12.
- 7 Dannewitz, C., D'Ambrosio, M., Karl, H., and Vercellone, V. (2013) Hierarchical DHT-based name resolution for information-centric networks. Computer Communications, 36 (7), 736–749.
- 8 Eriksson, A. and Ohlman, B. (2007) Dynamic Internetworking Based on Late Locator Construction. 10th IEEE Global Internet Symposium.
- 9 Kutscher, D. et al. (2012) Content Delivery and Operations, Deliverable. SAIL 7th FP EU-Funded Project, May 2012.
- 10 Ain, M. et al. (2009) D2.3 - Architecture Definition, Component Descriptions, and Requirements Deliverable. PSIRP 7th FP EU-Funded Project, February 2009.
- 11 Bloom, B.H. (1970) Space/time trade-offs in hash coding with allowable errors. ACM Communications, 13 (7), 422–426.
- 12 Miller, V.S. (1985) Use of Elliptic Curves in Cryptography. Proceedings of CRYPTO '85: The Advances in Cryptology, August 1985.
- 13 Lagutin, D. (2008) Redesigning internet - the packet level authentication architecture. Licentiate's thesis. Helsinki University of Technology, Finland.
- 14 Miorandi, D., Sicari, S., De Pellegrini, F., and Chlamtac, I. (2012) Internet of things: vision, applications and research challenges. Ad Hoc Networks, 10 (7), 1497–1516, doi: 10.1016/j.adhoc.2012.02.016. ISSN: 1570-8705.
- 15 Waltari, O.K. (2013) Content-centric networking in the internet of things. MSc thesis. Department of Computer Science, University of Helsinki, http://hdl.handle.net/10138/42303 (accessed 16 December 2016).
- 16 Francois, J., Cholez, T., and Engel, T. (2013) CCN Traffic Optimization for IoT. 2013 4th International Conference on the Network of the Future (NOF), October 23–25, 2013, pp. 1–5.
- 17 Quevedo, J., Corujo, D., and Aguiar, R. (2014) A Case for ICN Usage in IoT Environments. 2014 IEEE Global Communications Conference (GLOBECOM), pp. 2770–2775.
- 18 Amadeo, M., Campolo, C., and Molinaro, A. (2014) Multi-Source Data Retrieval in IoT via Named Data Networking. Proceedings of the 1st International Conference on Information-Centric Networking (ICN '14). ACM, New York, NY, USA, pp. 67–76.
- 19 Shang, W., Bannis, A., Liang, T., Wang, Z., Yu, Y., Afanasyev, A., Thompson, J., Burke, J., Zhang, B., and Zhang, L. (2016) Named Data Networking of Things. Proceedings of the 1st IEEE International Conference on Internet-of-Things Design and Implementation, April 4–8, 2016, Berlin, Germany.
- 20 Katsaros, K., Chai, W., Wang, N., Pavlou, G., Bontius, H., and Paolone, M. (2014) Information-centric networking for machine-to-machine data delivery: a case study in smart grid applications. IEEE Network, 28 (3), 58–64.
- 21 Yu, K., Zhu, L., Wen, Z., Mohammad, A., Zhou, Z., and Sato, T. (2014) CCN-AMI: Performance Evaluation of Content-Centric Networking Approach for Advanced Metering Infrastructure in Smart Grid. Applied Measurements for Power Systems Proceedings (AMPS), 2014 IEEE International Workshop on, September 24-26, 2014, pp. 1–6.
- 22 Chai, W.K., Katsaros, K.V., Strobbe, M., Romano, P., Ge, C., Develder, C., Pavlou, G., and Wang, N. (2015) Enabling Smart Grid Applications with ICN. 2nd ACM Conference on Information-Centric Networking (ICN 2015), September 30–October 2, 2015, pp. 207–208.
- 23 Rault, T., Bouabdallah, A., and Challal, Y. (2014) Energy efficiency in wireless sensor networks: a top-down survey. Computer Networks, 67, 104–122.
- 24 Kafi, M.A., Djenouri, D., Ben-Othman, J., and Badache, N. (2014) Congestion control protocols in wireless sensor networks: a survey. IEEE Communications Surveys & Tutorials, 16 (3), 1369–1390.
- 25 Rawat, P., Singh, K.D., Chaouchi, H., and Bonnin, J.M. (2013, 2014) Wireless sensor networks: a survey on recent developments and potential synergies. The Journal of Supercomputing, 68 (1), 1–48.
- 26 Singh, S.P. and Sharma, S.C. (2015) A survey on cluster based routing protocols in wireless sensor networks. Procedia Computer Science, 45, 687–695.
- 27 Butun, I., Morgera, S.D., and Sankar, R. (2014) A survey of intrusion detection systems in wireless sensor networks. IEEE Communications Surveys & Tutorials, 16 (1), 266–282.
- 28 Saadallah, B., Lahmadi, A., and Festor, O. (2012) CCNx for Contiki: Implementation Details. Technical Report RT-0432, INRIA, p. 52.
- 29 Burke, J., Gasti, P., Nathan, N., and Tsudik, G. (2014) Secure Sensing Over Named Data Networking. Proceedings of the 13th IEEE International Symposium on Network Computing and Applications (NCA).
- 30 Baumgartner, T., Chatzigiannakis, I., Fekete, S.P., Koninis, C., Kröller, A., and Pyrgelis, A. (2010) Wiselib: a generic algorithm library for heterogeneous sensor networks, in Proceedings of the 7th European Conference on Wireless Sensor Networks (EWSN'10) (eds J. Sá Silva, B. Krishnamachari, and F. Boavida), Springer-Verlag, Berlin, Heidelberg, pp. 162–177.
- 31 Dorronsoro, B., Ruiz, P., Danoy, G., Pigne, Y., and Bouvry, P. (2014) Evolutionary Algorithms for Mobile Ad Hoc Networks, John Wiley & Sons, Inc.
- 32 Mahmood, B.A. and Manivannan, D. (2015) Position based and hybrid routing protocols for mobile Ad Hoc networks: a survey. Wireless Personal Communications, 83 (2), 1009–1033.
- 33 Reina, D.G., Askalani, M., Toral, S.L., Barrero, F., Asimakopoulou, E., and Bessis, N. (2015) A survey on multihop Ad Hoc networks for disaster response scenarios. International Journal of Distributed Sensor Networks, 2015, 1–16.
- 34 Attia, R., Rizk, R., and Ali, H.A. (2015) Internet connectivity for mobile ad hoc network: a survey based study. Wireless Networks, 21 (7), 2369–2394.
- 35 Meisel, M., Pappas, V., and Zhang, L. (2010) Ad Hoc Networking via Named Data. Proceedings of the 5th ACM International Workshop on Mobility in the Evolving Internet Architecture (MobiArch '10), ACM, New York, NY, USA, pp. 3–8.
- 36 Oh, S.Y., Lau, D., and Gerla, M. (2010) Content Centric Networking in Tactical and Emergency MANETs. IFIP Wireless Days (WD), 2010, October 20–22, 2010, pp. 1–5.
- 37 Cianci, I., Grieco, L.A., and Boggia, G. (2012) CCN - Java Opensource Kit EmulatoR for Wireless Ad Hoc Networks. Proceedings of the 7th International Conference on Future Internet Technologies (CFI '12), ACM, New York, NY, USA, pp. 7–12.
- 38 Bouk, S.H., Ahmed, S.H., Kim, D., and Song, H. (2017) Named-Data-Networking-Based ITS for Smart Cities. IEEE Communications Magazine, 2017, January 105–111, 55, 1.
- 39 Yu, Y.-T., Dilmaghani, R.B., Calo, S., Sanadidi, M.Y., and Gerla, M. (2013) Interest Propagation in Named Data Manets. International Conference on Computing, Networking and Communications (ICNC), 2013, January 28–31, 2013, pp. 1118–1122.
- 40 Varvello, M., Schurgot, M., Esteban, J., Greenwald, L., Guo, Y., Smith, M., Stott, D., and Wang, L. (2013) SCALE: A Content-Centric MANET. Computer Communications Workshops (INFOCOM WKSHPS), 2013 IEEE Conference on, April 14–19, 2013, pp. 29–30.
- 41 Detti, A., Tassetto, D., Melazzi, N.B., and Fedi, F. (2015) Exploiting content centric networking to develop topic-based, publish–subscribe MANET systems. Ad Hoc Networks, 24, Part B, 115–133.
- 42 TalebiFard, P., Leung, V.C.M., Amadeo, M., Campolo, C., and Molinaro, A. (2015) Information-centric networking for VANETs, in Vehicular Ad Hoc Networks, Chapter 17 (eds C. Campolo, A. Molinaro, and R. Scopigno), Springer-Verlag, pp. 503–524.
- 43 Amadeo, M., Campolo, C., and Molinaro, A. (2012) Content-Centric Vehicular Networking: An Evaluation Study. 3rd International Conference on the Network of the Future (NOF), 2012, November 21–23, 2012, pp. 1–5.
- 44 Yu, Y.-T., Li, X., Gerla, M., and Sanadidi, M.Y. (2013) Scalable VANET Content Routing Using Hierarchical Bloom Filters. 9th International Wireless Communications and Mobile Computing Conference (IWCMC), 2013, July 1–5, 2013, pp. 1629–1634.
- 45 Amadeo, M., Campolo, C., and Molinaro, A. (2013) Design and Analysis of a Transport-Level Solution for Content-Centric VANETs. Proceedings of the IEEE International Conference on Communications Workshops (ICC), 2013, June 9–13, 2013, pp. 532–537.
- 46 Yu, Y.-T., Li, Y., Ma, X., Shang, W., Sanadidi, M.Y., and Gerla, M. (2013) Scalable Opportunistic VANET Content Routing with Encounter Information. Network Protocols (ICNP), 2013 21st IEEE International Conference on, October 7–10, 2013, pp. 1–6.
- 47 Grassi, G., Pesavento, D., Pau, G., Vuyyuru, R., Wakikawa, R., and Zhang, L. (2014) VANET via Named Data Networking. IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), 2014, 27 April- 2 May 2014, pp. 410–415.
- 48 Grassi, G., Pesavento, D., Pau, G., Zhang, L., and Fdida, S. (2015) Navigo: Interest Forwarding by Geolocations in Vehicular Named Data Networking. IEEE 16th International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), June 2015, pp. 1–10.
- 49 Ahmed, S.H., Bouk, S.H., and Kim, D. (2015) RUFS: RobUst forwarder selection in vehicular content-centric networks. IEEE Communications Letters, 19 (9), 1616–1619.
- 50 Ahmed, S.H., Yaqub, M.A., Bouk, S.H., and Kim, D. (2015) Towards Content-Centric Traffic Ticketing in VANETs: An Application Perspective. Ubiquitous and Future Networks (ICUFN), 2015 7th International Conference on, July 7–10, 2015, pp. 237–239.
- 51 Ahmed, S.H., Yaqub, M.A., Bouk, S.H., and Kim, D. (2016) SmartCop: enabling smart traffic violations ticketing in vehicular named data networks. Mobile Information Systems, 2016, 1–12, Article ID 1353290, doi: 10.1155/2016/1353290.
- 52 Bouk, S.H., Ahmed, S.H., and Kim, D. (2015) Hierarchical and hash based naming with compact trie name management scheme for vehicular content centric networks. Computer Communications, 71, 73–83.
- 53 Shannigrahi, S., Barczuk, A., Papadopoulos, C., Sim, A., Monga, I., Newman, H., Wu, J., and Yeh, E. (2015) Named Data Networking in Climate Research and HEP Applications. Proceedings of the 21st International Conference on Computing in High Energy and Nuclear Physics (CHEP2015), April 2015, Okinawa, Japan.
- 54 Olschanowsky, C. et al. (2014) Supporting Climate Research Using Named Data Networking. LANMAN.
- 55 Ahmed, S.H., Bouk, S.H., Yaqub, M.A., Kim, D., and Gerla, M. (2016) CONET: Controlled Data Packets Propagation in Vehicular Named Data Networks. Proceedings of the 13th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, pp. 620–625.
- 56 Bouk, S.H., Ahmed, S.H., Yaqub, M.A., Kim, D., and Gerla, M. (2016) DPEL: dynamic PIT entry lifetime in vehicular named data networks. IEEE Communications Letters, 20 (2), 336–339.
- 57 Ahmed, S.H., Bouk, S.H., Yaqub, M.A., Kim, D., Song, H., and Lloret, J. (2016) CODIE: controlled data and interest evaluation in vehicular named data networks. IEEE Transactions on Vehicular Technology, 65 (6), 3954–3963.