
CHAPTER 9
Artificial Intelligence, Machine Learning, and Computer Vision
Steven Herman
Introduction
Living in the twenty-first century, readers of this book almost inevitably have heard about artificial intelligence (AI), machine learning (ML), and deep learning (DL). Advances in AI and computer vision in many ways accelerated Smart Manufacturing. Rapid growth of computing power has enabled completely new forms of software development, driven by data. This shift in paradigm, sometimes referred to as Software 2.0,1 can drive rapid innovation in the manufacturing sector and make development accessible to nonengineers.
With the deluge of articles mentioning artificial intelligence, machine learning, and deep learning, it is important to clarify the difference. Artificial intelligence refers to software performing tasks traditionally requiring human intelligence to complete. Machine learning is a subset of artificial intelligence wherein software “learns” or improves through data and/or experience. Deep learning is a subset of machine learning, usually distinguished by two characteristics: (1) the presence of three or more layers, and (2) automatic derivation of features.2 For the remainder of the chapter, I use the term machine learning unless the subject necessitates differentiation.
Exhibit 9.1 shows the relationship among AI, ML, and computer vision.3
While machine learning is often discussed as black magic, the underlying concepts are relatively simple mathematics. At its core, the algorithm checks whether a point is above or below a line; points above the line are shaded darker while points below the line are shaded lighter. The line itself is learned from training data by optimizing the number of points correctly classified by the algorithm. Most machine learning operates on a similar principle with a massively scaled up number of dimensions.

EXHIBIT 9.1 The relationship among artificial intelligence, machine learning, and computer vision
Exhibit 9.2 shows how a simple machine learning algorithm learns to differentiate between two clusters of points.
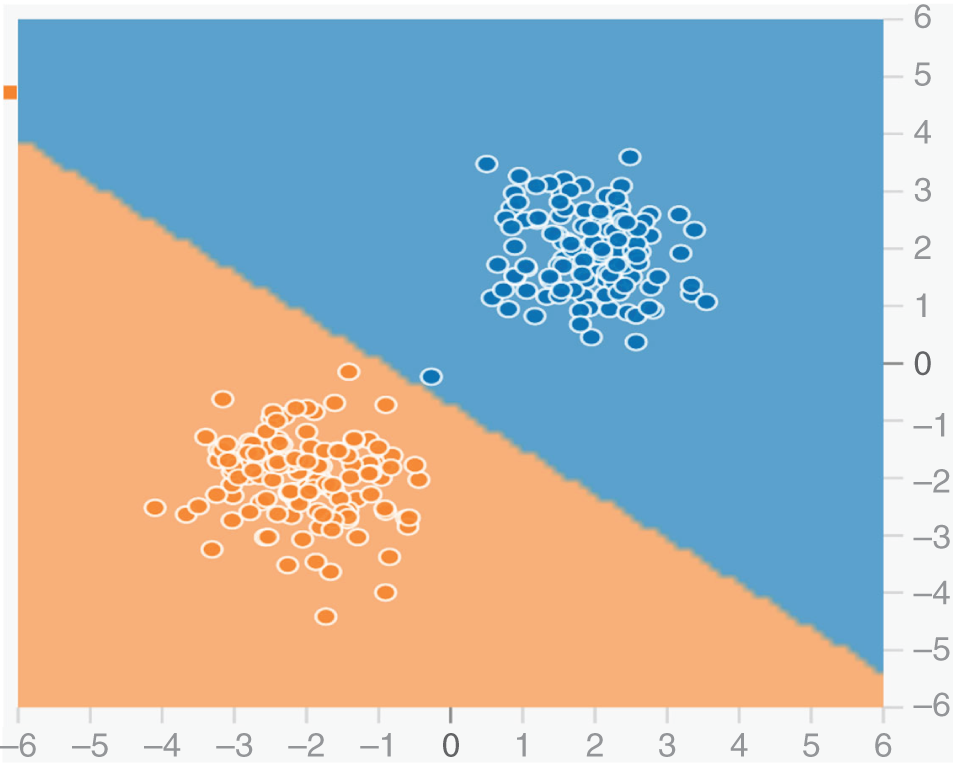
EXHIBIT 9.2 Learning to differentiate
Imagine instead that the inputs were sensor data from a machine and the outputs were whether the machine would fail within the next day, month, or year. The algorithm then learns to pick out changes and relationships in the data that might not be obvious. This is not hypothetical because many companies are already using machine learning to drive predictive maintenance, reducing unnecessary downtime and avoiding catastrophic failures. Problems, such as predictive maintenance, rarely arise in academia, being driven instead by the needs of businesses and processes. This opens vast opportunities for advances in machine learning by applying it to the problems encountered in manufacturing.
Beyond sensors, computer vision offers huge opportunities to collect additional data about processes and systems. Cameras can detect operators, machine state, defects, barcodes, and other vital information, providing greater insight into the manufacturing process. This information can drive process improvement and optimization. Modern computer vision is intertwined with machine learning because most state-of-the-art computer vision is built with machine learning models. In many cases, it is much easier, cheaper, and more accurate for a computer than a human to monitor these processes.
While machine learning was once the purview of large and exceedingly well-funded organizations, it is now increasingly accessible to every business. Many free or paid tools allow custom models to be built with minimal technical experience. These resources lower the barrier to entry, allowing low-cost data collection. The goal of this chapter is to demystify machine learning and computer vision while providing a jumping-off point for what is currently possible with artificial intelligence so you can implement it in your company.
History of AI and Computer Vision
Since the early days of computing, humans have obsessed over teaching computers to think. The term artificial intelligence was first coined for the Dartmouth Summer Research Project on Artificial Intelligence in 1956.4 From there, AI initially took off, spurred by cheaper computers, better algorithms, and funding. The perceptron, a precursor to modern neural networks, was invented only two years later in 1958. As the history of artificial intelligence progressed, it would follow a boom-bust cycle with AI “winters” exhibiting reduced research and funding, often followed by AI “springs” featuring renewed interest.
In the early years, success seemed imminent. Early achievements and funding created a generally optimistic view of artificial intelligence. Algorithms were developed to prove geometric and mathematical theorems, perform basic natural language tasks, and automate simple robotic tasks. In 1963, MIT received a $2.2 million grant from the Defense Advanced Research Projects Agency (DARPA), signaling intense interest in artificial intelligence. This optimism wouldn't last.
In the early 1970s, artificial intelligence saw its first winter, brought about by underperformance and a lack of progress. Limitations of computing power were one of the greatest driving factors. As funding collapsed, researchers turned away from neural networks toward logic and reasoning systems. These too proved difficult, requiring massive amounts of programmed knowledge about the world. In many ways, the first winter emphasized Moravec's Paradox: some tasks that are hard for humans are easy for computers while other tasks that are easy for humans are hard for computers.
Starting in the 1980s, artificial intelligence made a resurgence. The development of expert systems, or systems programmed using logical rules derived from domain experts, proved hugely successful and even commercially viable. With expert systems demonstrating commercial success, private funding poured into artificial intelligence research once again. Even neural networks saw a resurgence, driven by a focus on a new training mode, backpropagation, which drives almost all deep learning today.
Despite the advances of the 1980s, artificial intelligence proved fickle. Expert systems were brittle and difficult to maintain. Neural networks were still predominantly limited by computing power. Once again this led many to become disaffected with artificial intelligence. The second AI winter saw a round of funding cuts lasting through the early 1990s.
Starting in the early 1990s, advances in computing power started to drive artificial intelligence once again. Once artificial intelligence techniques achieved broad success in a particular field, they were often no longer labeled as artificial intelligence. Under the guise of data mining, robotics, optimization, and other new names, AI techniques were applied with great success. In 1997, Deep Blue beat Garry Kasparov, a reigning world champion, at chess. This signaled the success of artificial intelligence systems far outside their original domain. As AI progressed, many other games would fall to artificial intelligence mastery.
Heading into the 2000s, artificial intelligence continued to grow rapidly. The continuation of Moore's law and use of graphics processing units (GPUs) drove rapid increases in computing. By 2009, Google had started an autonomous car project, while 2010 saw the release of Siri on the iPhone 4s, with over 60 million units sold. Arguably, this was the moment artificial intelligence became mainstream.
As computers advanced, the success of computer vision would fall to machine learning. In 2021, AlexNet proved that deep convolutional neural networks (CNN) could beat the existing state of the art by a massive proportion in the ImageNet Large Scale Visual Recognition Challenge. With this new success, development surged, leading to multiple iterations of models and the dominance of CNNs in computer vision.
Computer vision saw rapid advancement with the application of deep neural networks. Object detection saw improvements with the development of Region-Based Convolutional Neural Network (R-CNN) features driving forward performance metrics in 2013. Iterative improvements would come with Fast R-CNN and Faster R-CNN, both improving inference time by 2015. While R-CNN derivatives would drive performance, lower-latency models based on single-shot detectors (SSD) would drive real-time object detection in 2015. While much of the progress was iterative, computer vision started to see machine–human parity on a number of tasks.
More recently, artificial intelligence has diversified its focus, taking on broad problems such as natural language processing, machine translation, and recommendation. In 2020, new techniques use more data and computation than ever before, while continuing to break existing records for accuracy. The gains in other areas of machine learning started to trickle back to computer vision with transformers, a model architecture originally developed for natural language processing, being applied to computer vision problems in 2020.5
From here, machine learning seems likely to grow well into the future. While concerns about the end of Moore's law have driven some uncertainty, specialized hardware has provided massive increases in the computation behind artificial intelligence. Further proliferation of computing power makes Edge machine learning and inference easier, while advances in computer vision create actionable data from images.
Understanding Machine Learning and Computer Vision
Types of Machine Learning
If the distinction between artificial intelligence, machine learning, and deep learning wasn't already confusing enough, machine learning algorithms can be broken up into three types, which can also be combined to form hybrid learning algorithms:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Supervised Learning. Supervised learning is the most straightforward learning problem to understand. It aims to mimic a teacher–student relationship through labeled data. In supervised learning, you provide one or more examples of the output expected for given inputs. Through the process of training, the model learns to generate results that are most similar to the training data. Supervised learning further breaks down into regression (predicting a quantity) and classification (predicting a label). While supervised learning is likely the most common form of machine learning, it isn't the best to utilize the data present with Big Data because the data often is unlabeled. In order to know the expected output, data must be labeled, which can be a time-consuming and expensive process. Advances in few-shot learning help alleviate this problem and despite the high initial cost of supervised learning, it can be hugely beneficial. Detecting product defects or safety violations using models can easily save thousands of dollars. Once developed, these models can often perform at a similar level to human evaluation, but scale much more easily.
Unsupervised Learning. On the opposite side, unsupervised learning requires no labeled data, instead learning patterns directly from the data. While unsupervised learning is excellent at pattern recognition and anomaly detection, it can be more difficult to apply to problems. Still, unsupervised learning can utilize Big Data more efficiently without requiring human interaction. This means that unsupervised learning can offer a lower upfront cost, although it is not universally applicable. Commonly, unsupervised learning is used for clustering and dimensionality reduction.
Reinforcement Learning. Reinforcement learning relies on an interactive environment that an agent can explore. The algorithm tends to learn by trial and feedback. Most commonly this is used for robotics, although recently it has been used for scheduling and chip design as well. While developments in reinforcement learning may well drive Smart manufacturing in the future, reinforcement learning is less commonly applied to problems and may require more specialized knowledge to produce.
Different combinations of these techniques can form hybrid learning algorithms. Semi-supervised learning combines supervised and unsupervised learning to utilize unlabeled data to improve results from a small labeled data set. Recently, semi-supervised learning has driven improvements in computer vision by allowing a better internal representation of images created over a larger unlabeled data set. Self-supervised learning utilizes an unlabeled data set for supervised learning. Usually, the raw data set is the expected result, while some modified data serves as the input. One example of this is natural language processing, where the model is often taught to predict a word removed from a sentence.
Common Computer Vision Tasks
In computer vision, there are a number of commonly researched tasks that machine learning currently dominates. Each task focuses on producing different information given an image. While some tasks, such as barcode scanning or motion detection, don't require machine learning, many more complicated tasks are solely viable with machine learning. Simple tasks may still provide large productivity gains; for example, color detection is an easy computer vision task, but may be utilized to generate machine status information without interfacing with proprietary protocols. For many tasks, computer vision is not only cheaper than other ways of solving the issue, but is also more generalizable. Image classification is the task of assigning a label to an image. This may be used to identify a state; for example, a model may classify machines as in-use, waiting for repair, or available. This could be used to identify defective products where the location of the defect isn't important to the process. Alternatively, image classification may look to recognize one of several pre-known objects in an image. In this case, it is called object classification.
Exhibit 9.3 shows an example of image classification at work.6

EXHIBIT 9.3 Image classification
If the location of an object is important, object classification can be combined with object localization to perform the object detection task. The goal of object detection is to determine both class and location of an object in an image, if one or more exists. This may be a simple problem like locating all the people in an image, or more complex like identifying different parts for counting as they pass on a conveyor belt. Object detection is often used alongside other computer vision techniques to determine the state of a given scene. For example, instead of building an image classifier to determine whether an employee is wearing the appropriate personal protective equipment, building an object detector to recognize hard hats, safety vests, and safety glasses would allow greater information about why the behavior is unsafe. In many cases, the last level of logic is based on either regulation or general knowledge, which should be directly coded rather than learned.
Exhibit 9.4 shows an example of object detection at work.7

EXHIBIT 9.4 Object detection
If object detection can be seen as an advanced form of object classification, image segmentation is a more advanced form of object detection. Image segmentation aims to divide an image into multiple parts based on some attribute. It can be broken into two main forms: instance segmentation and object segmentation. Object segmentation involves segmentation based on classes. It might provide segmented areas for the conveyor belt, metallic objects, and plastic objects in a given image. Instance segmentation generates separate segments for each instance of an object. Rather than three segments in the previous example, each nut, bolt, and tray would be identified as a separate segmentation mask.
Exhibit 9.5 shows an example of instance segmentation and object segmentation.

EXHIBIT 9.5 Instance and object segmentation
Identification is the computer vision task involving identifying specific instances of an object, usually over time. One example of a common identification task is facial recognition. Object identification could be used to track a product and keep a record of which workstations it passed through. This might allow better tracing of products that fail quality control as well as insight into bottlenecks in the production process.
Although there are many more computer vision tasks with differing state-of-the-art models, a few other notable mentions include optical character recognition, pose estimation, depth mapping, and 3D reconstruction. Optical character recognition (OCR) could digitize paper workflows and allow seamless transitioning between digital and physical tracking systems. Pose estimation may be used for predicting and preventing human–robot collision by determining 3D orientation and the position of the robot, human, or both. Depth mapping is more prevalent in the world of self-driving, but it can provide a uniform replacement or augmentation for radar or lidar data. 3D reconstruction is fairly new but could allow the creation of 3D models, automatically speeding up prototyping and design stages.
Building a Model
Once you know what you want to build, the next step is creating a data set and model. This section addresses the process of building a supervised learning model for object detection, but the same process will apply elsewhere. The basic process involves selecting data, cleaning and annotating data, training or fine-tuning a model, evaluating the trained model, and continual improvement.
While not glamorous, selecting and cleaning the data are the most time-consuming and important steps in machine learning. Biases or faulty data can easily poison a model, reducing accuracy by a noticeable margin. At this stage, you should consider how much you are going to spend on data collection and annotation on a weekly, monthly, or yearly basis. Unfortunately, models often require regular retraining to handle issues like concept drift, where the statistical properties of a target change as the environment in which the model works changes. For example, if you build a model to detect safety vests, but the company changes the color of all safety vests, your model likely will perform worse because it hasn't seen the new color before. When selecting data, you want to make sure you get a representative set from all the different camera angles and conditions you expect the model to see when deployed. Ideally, there should also be a balance of classes that you expect to see, without any one class being over- or underrepresented. You should also make sure to be aware of any biases or shortcomings in the data set, preferably documenting them alongside the model. The siloed nature of data at larger companies can interfere with the ability to get widespread and useful data selected. Where possible, long-term investment in a single data lake can make this process faster, cheaper, and more agile.
After data selection and some analysis, cleaning and annotation of the data pose a number of unique challenges. Before starting annotations, you should write up a guide for how to annotate the data. This minimizes communication errors and allows more uniform results, which in turn leads to better model performance. While you may need to annotate the data internally, external annotation services likely offer better guarantees for annotation accuracy. Internally, you will likely have to train team members and double-check annotations, since everyone will have a different idea about annotating initially.
Once you have your annotated data, you should split it into three sets: training, validation, and testing. At least 10% of your data should be set aside for testing and around 20% should be set aside for validation. This leaves the remaining 70% for training. These data sets are kept separate to ensure that you have adequate data to estimate accuracy of your model. If there is overlap between these data sets, you will have no way of performing unbiased evaluation of your model or ensuring that no overfitting occurred. Overfitting is when the model performs better on the training data than on the test/validation data. This is usually because it conforms too closely to the data, effectively memorizing it rather than generalizing. You want to stop training before you overfit the data. The purpose of a separate validation set is to allow you to experiment with parameters of different models without selecting a model that best fits the test set. This becomes more important if you are testing a large range of models or parameters but is good practice either way.
Now that you have data, you can start experimenting with models. While state-of-the-art models may offer higher accuracy, they often are more expensive to train and deploy because they are more complex. One good way to evaluate model complexity is to look at inference time. The longer it takes to perform inference on one or many images, the more complex it is and the longer it will take to train. If you can, start with simple initial models such as MobileNet or an SSD-based model and scale up if you need better performance. You can fine-tune (train only the last few layers of a model) or train the entire model, although the latter requires significantly more data to do without overfitting. In general, fine-tuning will be enough for most purposes. Like model complexity, start simple and see whether you need more.
Once you have a trained model, you should check its performance on the validation set. This will allow you to see how well it performs on data it hasn't seen before. From here, repeating the training step with different models or different parameters can produce better results. When you are happy with the results, evaluating on the test data set should give an indication of the performance you will see for the model when deployed.
From here, the model can be updated with whatever frequency is necessary to obtain good performance. One of the greatest benefits of machine learning is that more data and computation tend to produce better results so there is a straightforward improvement process. Over time, you can build up a data set allowing a better model to be made. This data set can also be a valuable asset to any company, providing a benefit over your competitors.
Machine Learning Pipelines
Given the continuous nature of machine learning, it may make sense to have a pipeline, much like you would for data science. Pipelines may also offer cost-saving techniques such as active learning, which are beyond the scope of this chapter. Machine learning pipelines can easily become a greater time and maintenance sink than the models they were used to build.8 If your needs are met by one of the many existing free or paid pipelines, these will almost always offer more features than a pipeline you build yourself.
Having a pipeline can also be beneficial by allowing integration of automated tests to check whether the model is performing well. Organizing and tracking model performance can help diagnose issues and regressions before they cause major issues.
Issues with Artificial Intelligence
While artificial intelligence can be extremely powerful, it is important to understand the ethical implications of it. Ethical issues with artificial intelligence are not limited to some far-off reality with superhuman artificial intelligence or complete societal automation; plenty of existing machine learning–based systems cause real harm every day. It is your job to consider the implications of your use of artificial intelligence and avoid creating more harm through your application of artificial intelligence to manufacturing.
At their core, most machine learning systems look to optimize an objective; these algorithms will often replicate any systemic bias they are trained on. These biases can lead to critical failures of systems incorporating the compromised model. In a now-famous example, Amazon set out to build an automated hiring algorithm, hoping to mitigate sexism in the hiring process; despite not being fed data on the gender of candidates, it learned to discriminate against women.9 One potential cause of such behavior is a proxy, where seemingly unrelated data can infer protected attributes such as race, age, or gender. This can have potential legal ramifications, especially as laws evolve to manage artificial intelligence.
Beyond biases, artificial intelligence systems often introduce a level of opacity into their design. While it may be amusing the first time your object detection model misses detecting a person because they wore an unexpected color of T-shirt, a Tesla crashing into a parked car or a robotic arm hitting an assembly line worker show us that the stakes can be deadly serious. What is worse is that in many of these cases, there is no way to be sure the problem is fixed. Sure, you can improve the training data, rerun training, and validate that the original scenario no longer occurs, but you can't verify that the model won't fail under another novel circumstance. This is one of the major downsides to machine learning; even if you achieve over 99% accuracy, there is no predicting what kind of failure you may experience in the remaining cases.
These hidden failures can also lead to real-world attacks on AI systems. Adversarial attacks rely on modifying input to models to intentionally disrupt the output. This may be as simple as placing tape on the right parts of a stop sign to prevent it from being recognized.10 As artificial intelligence becomes more widespread, businesses will need similar cybersecurity practices for adversarial activities to what they now have for physical security.
It is also important to recognize that most artificial intelligence systems will work alongside humans. Artificial intelligence will drive robots and cobots. It may even optimize manufacturing floor layouts and worker scheduling. While automation can reduce the dangerous and repetitive tasks done by humans, it also runs the risk of harming humans, especially where AI and humans interact. Done improperly, artificial intelligence can optimize warehouses and manufacturing in ways that are harmful to workers.11
This isn't to discourage artificial intelligence, but it is important to be aware of the ethical issues when implementing these systems. Especially when thinking about integrating machine learning, applying different ethical decision-making frameworks can be useful. Potential ethical decisions can be assessed by recognizing, researching, evaluating, testing, and reflecting.12 In this process, you want to recognize decisions that may cause harm to individuals or groups of people. Then you should research the relevant information, including your options for action. This should include consultation with possible stakeholders who may be impacted or harmed by the decision. While some concerns may be more or less important in the decision making, missing concerns may result in poor decision making. Next, you should evaluate the different options, preferably under different ethical frameworks. The easiest approach to conceptualize is usually a utilitarian approach of maximizing good and minimizing harm. After arriving at a decision, you should test that the decision addresses the issue and concerns raised in the research phase. Then, after implementing the decision, you should return to the issue to reflect on the implementation and ensure that it was implemented in an appropriate way for all stakeholders. Following this process should help ensure that you have a positive impact with your artificial intelligence application.
At the time of this writing, regulation of artificial intelligence is limited, but it is likely to increase in the next 10 years, with multiple agencies signaling interest in regulatory oversight. Currently, the National Artificial Intelligence Initiative Act of 2020 and General Data Protection Regulation (GDPR) are most influential when it comes to artificial intelligence uses, but neither has significant restrictions on artificial intelligence use. It is likely that the European Union will pass some form of the Artificial Intelligence Act in 2022, which may be much more restrictive. Recent industry initiatives have pushed for fairness, accountability, and transparency in machine learning; algorithms and machine learning should not be an excuse for companies causing harm.
Like much of machine learning, AI ethics is an extraordinarily fast-moving field. I would highly recommend checking out additional information on the topic, including researchers such as:
- Kate Crawford
- Timnit Gebru
- Guillaume Chaslot
and websites like:
Conclusion
Artificial intelligence, machine learning, and computer vision are a gold mine to Smart Manufacturing, driven by the proliferation of Big Data and the low cost of computing. Innovation in these areas can drive process improvements by automating tasks and reducing human error as well as assisting workers with dangerous or repetitive tasks. While knowledge of code is useful, it isn't required to build machine learning systems. Advances in no-code systems enable anyone to build machine learning models, reducing the barrier to entry and enabling experts to apply their domain knowledge to building useful artificial intelligence systems. While there are potential issues with artificial intelligence, careful decision making prevents future harm and avoids costly mistakes. As seen in the case studies, computer vision is already revolutionizing Smart Manufacturing.
Sample Questions
- What is the relationship between artificial intelligence, machine learning, and deep learning?
- There is no relationship.
- Machine learning and deep learning are subsets of artificial intelligence, but completely separate from each other.
- Deep learning and artificial intelligence are subsets of machine learning.
- Artificial intelligence contains machine learning. Deep learning is a subset of machine learning.
- Artificial intelligence experienced how many winters?
- Zero
- One
- Two
- Three
- Which of the following have enabled the rise of machine learning?
- Big Data
- Moore's law
- Specialized hardware
- All of the above
- Which model architecture revolutionized computer vision by outperforming other techniques?
- Faster R-CNN
- Convolutional Neural Networks
- AlexNet
- Reinforcement learning
- What is the difference between supervised and unsupervised learning?
- Supervised learning requires constant human interaction; unsupervised learning solves more problems.
- Unsupervised learning works on data without labels, while supervised learning requires labels.
- Unsupervised learning requires an interactive environment which an agent explores, while supervised learning requires labeled data.
- All of the above
- Which of the following is not an example of image classification?
- Finding a person in an image
- Checking whether an image is a cat or a dog
- Determining whether a machine in an image is on or off
- Classifying whether the image is taken on the East or West Coast.
- What should you ensure that you do with training, validation, and testing data?
- Mix the data to ensure that you have an even distribution of each when training and evaluating your model.
- Keep the data separate and don't use testing data to evaluate different models.
- Train until the model performs significantly better on training data than validation or test data.
- Set aside at least 50% of your data for validation and testing.
- When building an artificial intelligence system, you should always:
- Consult with stakeholders to determine potential consequences of the system.
- Develop and deploy systems quickly to determine whether they can accelerate your process.
- Test systems by implementing them in your manufacturing facility.
- Avoid artificial intelligence and machine learning at all costs.
- Which of the following is an example of an adversarial attack?
- A sticker is placed on a machine to prevent it from properly detecting the machine state.
- A model fails to recognize a person in an image because of a change to safety vest color.
- A model learns to detect machine state by image brightness because the training data features machines in their “off” state at night.
- A cobweb obscures the camera's view and causes poor model performance.
- Who is responsible for a machine learning algorithm that causes harm?
- Nobody; the algorithm works in obscure ways.
- It is difficult to say because there is little legal precedent, but the company or anyone involved in the deployment of the system may be liable.
- The person harmed by the algorithm.
- The company.
Notes
- 1. Karpathy, A. (November 11, 2017). Software 2.0. Medium. https://karpathy.medium.com/software-2-0-a64152b37c35.
- 2. IBM Cloud Education. (May 1, 2020). What is deep learning? IBM. https://www.ibm.com/cloud/learn/deep-learning.
- 3. Shreyas, S. (March 7, 2019). Relationship between artificial intelligence, machine learning and data science. Medium. https://medium.com/@shreyasb494/relationship-between-artificial-intelligence-machine-learning-and-data-science-15a87e2cc758.
- 4. Anyoha, R. (August 28, 2017). The history of artificial intelligence. Science in the News, Harvard University. https://sitn.hms.harvard.edu/flash/2017/history-artificial-intelligence/.
- 5. Houlsby, N., and Weissenborn, D. (December 3, 2020). Transformers for image recognition at scale. Google AI Blog. https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html.
- 6. Cat. Pixabay. https://pixabay.com/photos/cat-kitten-pet-striped-young-1192026/. Dog. Pixabay. https://pixabay.com/photos/bulldog-dog-puppy-pet-black-dog-1047518/
- 7. Chafik, A. Unsplash. https://unsplash.com/photos/2_3c4dIFYFU.
- 8. Sculley, D., Holt, G., Golovin, D., et al. (2014). Machine learning: The high-interest credit card of technical debt. SE4ML: Software Engineering for Machine Learning (NIPS 2014 Workshop).
- 9. Goodman, R. (October 12, 2018). Why Amazon's automated hiring tool discriminated against Women. ACLU. https://www.aclu.org/blog/womens-rights/womens-rights-workplace/why-amazons-automated-hiring-tool-discriminated-against.
- 10. Eykholt, K., Evtimov, I., Fernandes, E., et al. (June 2018). Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1625–1634).
- 11. Ghaffary, S. (October 22, 2019). Robots aren't taking warehouse employees’ jobs, they're making their work harder. Vox. https://www.vox.com/recode/2019/10/22/20925894/robots-warehouse-jobs-automation-replace-workers-amazon-report-university-illinois.
- 12. Markkula Center for Applied Ethics. (2015). A framework for ethical decision making. https://www.scu.edu/ethics/ethics-resources/ethical-decision-making/a-framework-for-ethical-decision-making/.