
If you’re passionate about what it is you do, then you’re going to be looking for everything you can to get better at it.
Software development is an industry whose landscape has given rise to several different project management processes and methodologies, ranging from the rigidity of waterfall to the iterative nature of Scrum. As previously discussed in Chapter 1, formal software engineering processes emerged in the industry in the 1960s to tame the project cost, time, and quality challenges that plagued the industry. Despite the different incarnations of software engineering processes and methodologies over the past four decades, the simplest goals of achieving a higher quality product and a more predictable time to market or deployment remains constant today. Achieving these goals requires the combination of great engineering practices and a repeatable project delivery rhythm that is well suited to your team’s needs. Successful project teams recognize this and, as the quote suggests, continuously look for opportunities to gain efficiencies or implement processes that improve the quality of their work.
As project participants, many of us do not always look favorably upon some aspects of the software development process. This could be based on suboptimal project experiences in the past or the idea that formal project processes merely get in the way of writing more code. The reality is that software development processes are implemented to control the flow of software construction, as a means to increase efficiency and control costs, resources, and quality. This is somewhat analogous to the way speed limits are leveraged on highways to control traffic and prevent accidents or congestion. Without some level of governance over application development projects, our chances for shipping a high-quality product are severely limited. The challenge is, of course, applying the appropriate amount of process so that the outcome of your software projects actually improves.
At Microsoft, teams often establish the processes that work best for their respective culture, objectives, and project size, which actually works quite well for them. Since development projects generally range from large, well established applications like Windows and Microsoft Office to small, cutting-edge niche services like Zune, it makes sense to encourage organizational autonomy with respect to development processes. Across the many teams at Microsoft, there is no clear one-size-fits-all approach to delivering software. However, there are several best practices and common techniques that are applied broadly across teams and are independent of a specific process or methodology. Throughout the remainder of this chapter, we will review several of these practices and discuss how your team’s existing processes could be augmented to include these techniques as a means to improve efficiency and product quality, regardless of the project’s current methodology. By improving existing software development processes with these tactics, development teams will ultimately improve their efficiency at bringing their applications to market, while simultaneously improving the quality of the software they deliver, thus closing the loop on how solid code can be achieved without introducing heavyweight development processes.
Releasing high-quality software products is no accident. It is the result of the combined, focused efforts of software development teams that are composed of people from multiple engineering disciplines, like development, program management, and test. Teams that achieve the successes associated with releasing great software in a timely manner are keenly aware of the importance of the engineering rigor and processes that guided them to the result. They recognize that, without this rubric, releasing high-quality software products within a reasonable project timeframe would not be possible. Furthermore, they understand that the processes and practices they incorporate in one release may not be applicable to future releases and thus periodically self-evaluate and make necessary adjustments to their processes. It is this process of project execution, self-evaluation, and continuous improvement that allows software development teams to continuously evolve their ability to deliver high-quality software applications to market in a timely manner.
In subsequent sections of this chapter, we will review and evaluate several tactics for augmenting your organization’s software development practices. Because there is such variation across organizations with respect to project processes, the focus of these recommendations will not align with a particular software development methodology. Instead, they will be presented in a way that assumes that a defined project management methodology exists and could be augmented to include some or all of these individual practices. Let us begin with some software project management basics.
If your organization is actively developing software, it is likely that a well-defined software project rhythm has been established. In many cases, this process may model more traditional waterfall processes, and in other cases it may mirror more agile processes. In either case, it is critically important that a well-defined software project rhythm be established first and foremost. This rhythm should balance the cultural and business needs of the organization while focusing on delivering high-quality software in a repeatable and predictable way. It is certainly not the focus of this book to recommend one specific development model over another, but rather to illustrate how any existing model could be augmented to add more quality-focused development practices. So, for the benefit of conversation, let us assume that your organization has an established milestone-based project rhythm that resembles that of the one illustrated in 11-1.

In 11-1, this typical software project rhythm is broken down into five major milestones that encompass the work required to ship any major or minor software release. These major milestones occur one after another, on a linear timeline, and each is defined as follows:
Planning. The milestone typically reserved for requirements gathering, feature specification development, and application design.
Coding. This is the milestone where the application code is developed and unit tested. This is also the time when testers write test cases in preparation for integration.
Integration. The first of two testing milestones where all major test cases are executed and major bugs are discovered and fixed.
Stabilization. The second of two testing milestones where deeper test analysis is completed and the build is further stabilized in preparation for release.
Release. The shipping milestone where code is released to the user community, either through typical client distribution mechanisms or through the Internet.
In Chapter 1, we discussed the importance of injecting quality-focused practices into the engineering process earlier in the project cycle. We referred to this principle as moving quality upstream, and we demonstrated the importance of integrating more quality-focused engineering practices into the daily development and integration rigor of the project process. This principle asserted that, by incorporating certain quality-focused practices throughout the project life cycle, the quality of the software being produced will increase as the team advances through each milestone. For example, by incorporating certain design practices such as class prototyping or metaprogramming within the planning milestone, and engineering practices like automated unit testing in the coding milestone, the quality of the software being produced will be markedly better as the team reaches subsequent milestones. By contrast, deferring many of these practices until late in the development cycle increases the risk of delivering the software late and with an undesirable number of bugs and a generally low degree of quality.
Throughout this book, we have built upon the quality upstream principle and have enumerated the many design, development, and coding tactics that can be applied within each of these major project milestones. Quite obviously, it is important that application development teams implement a quality-focused, milestone-based approach to developing software that incorporates the practices mentioned throughout this book. As we progress through this chapter, we will discuss process improvement tactics that can be applied to your organization’s milestone-based project rhythm. These tactics will focus on improving the day-to-day engineering processes that developers experience on almost every project and continue to build on the quality upstream principle. This will be accomplished by focusing on process changes and engineering protocols that will further help application development teams to achieve higher quality code. We will begin by discussing how to improve the quality of the code being stored in your team’s source control repository.
It is probably reasonable to assume that most organizations that are building software products use some form of source control in which they store and manage their source code. If your organization is not currently doing this, please stop reading this book now and return only after you have established a source control database and uploaded all of your precious source code into it! As you have probably figured out, source control is very important and should be taken seriously by every application development organization. Source control provides a number of benefits to development organizations, including, but not limited to, version management, change history, and change rollback. Many potential software development tragedies can be avoided by simply leveraging a source control system.
There are several source repository products that are commercially available today for managed code developers. The most obvious Microsoft source control product is Visual SourceSafe, which has been available for a number of years and integrated with Visual Studio 2005 as well as prior versions of Microsoft integrated development environments. The successor to Visual SourceSafe is part of Visual Studio Team Foundation Server, which belongs to the Visual Studio Team System suite of client and server products. Team Foundation Server (TFS) goes beyond simple source control and also incorporates a host of different features for reporting and project tracking. Within TFS, the source control repository itself is referred to as Team Foundation Version Control (TFVC) and stores all code, as well as change history within a SQL Server database. Generally speaking, TFVC is a dramatic improvement over Visual SourceSafe and, in conjunction with Visual Studio Team System, has really enhanced the collaborative managed code development ecosystem.
In addition to merely establishing a source control repository within your organization, application development project teams need to also consider the way they govern the use of source control and their repository. Without clearly defined procedures and processes for managing and updating source code, the repository can quickly become disorganized and it is nearly impossible to manage different versions of software effectively. It is therefore very important that the day-to-day software development process enforce good source management behaviors so that only high-quality code gets checked into source and previous versions of the software are preserved appropriately.
Establishing a process for managing software versions and the associative source control for the version specific code is a difficult job that will require tedious version management planning and meticulous documentation. It requires coordination across the organization and will not be successful without support from every application developer or tester who is responsible to check code into source. It is an important aspect of managing the software development process and should not be taken lightly. That said, let us briefly review the scenarios that require vigilant management of source control.
In most software development organizations, there is more than one developer participating on a software project. In some cases, there may be dozens of developers working together on a project. Chances are they will need to work on the same source code, perhaps even at the same time. Additionally, within those same development organizations, there are likely to be multiple versions of the software being managed. Depending on the life cycle of the software, some versions may actively be getting patched or fixed as bugs are discovered, even as new versions of the same software are being developed. Finally, some developers may be experimenting with portions of the software for potential future versions that may not be actively being developed. Each of these scenarios is a prime example of a software development problem for which source control procedures should provide support. Let’s consider some options for how to manage this.
At Microsoft, the scenarios illustrated above are fairly common problems. Without clear processes for handling these circumstances, there would most certainly be chaos in trying to manage different versions of the software. There would most certainly be an increase in the number of bugs getting introduced into the code. To address these challenges, many teams pursue a branching strategy for managing the different versions of source code. Branching allows files within version control to be forked, or branched away from the main trunk of the source tree so that multiple copies of the same file can be worked on at different speeds. These strategies usually involve multiple code branches with procedures for how the different branches are periodically merged with the main branch. 11-2 illustrates how multiple code branches could be established for a specific software application.
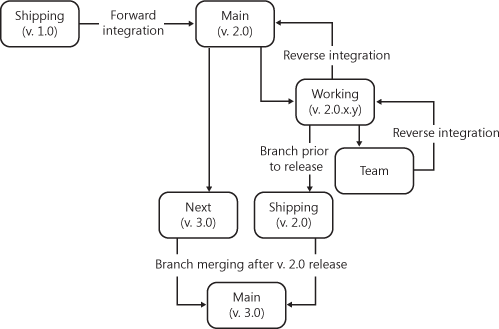
In 11-2, there are five main source code branches to consider, which are referred to as the main, working, next, team, and shipping branches. For the purposes of this example, we can define each of these branches as follows.
Main branch. This is the authority node, which contains the most current application source code that has achieved a certain quality bar. In other words, it represents the latest build that has passed a series of automated tests that have broadly examined the product for quality. Only code that has passed unit, functional, and integration tests would achieve the level of quality necessary to be reverse integrated into the main branch.
Working branch. The working branch is home to the application source code actively being developed across the team. Code living in the working branch has not yet passed the quality bar to be reverse integrated into main, but it maintains a quality bar that is indicative of daily application builds.
Next branch. This branch exists for the purposes of experimentation, prototyping, or for work being completed for a release that is further in the future than the current release. It is typically a fork of the main branch at a particular point in the current release cycle or a fork from the previous shipping branch.
Team branch. The team branch allows teams, or even individual developers, to fork code from the current working branch and work on their specific features. This allows teams to maintain individual branches for specific features or for broad feature sets and reverse integrate into working when complete. This may prove useful in circumstances where new code dependencies or integrations are evaluated prior to integrating into the working branch.
Shipping branch. This represents the version of the application that was actually shipped or released. Generally, as teams finalize their work in the working branch, the shipping branch for that release is created. This allows the code to be forked for the next release, while preserving a version of the application to which future bug fixes will be applied.
The diagram in 11-2 depicts how these various branch types participate in the development life cycle. For example, the main branch represents the authority source repository. At any given time, source taken from main should be robust enough to be built and deployed with a reasonable level of quality. The main branch is periodically updated from the working branch, which is where day-to-day feature check-in occurs. This happens through reverse integration from daily builds that surpass a predefined quality bar. This process ensures that the main branch be kept free of dysfunctional code. For teams or features that may not be getting checked in on a daily basis, the team branch offers a method for forking code out of the working branch and reverse integrating back in when the feature is complete. Upon completion of the project, and after the final quality sign off has been attained, the shipping branch can be created as a means to archive the shipping version of the code for future bug fixes. Finally, prior to beginning a new release, the shipping branch (or main branch, since they are theoretically identical) is merged with the next branch to establish the new releases main branch.
Note
TFVC allows development teams to maintain a source management process similar to the one mentioned above. This is accomplished through the branching and merging features within TFVC. A more detailed explanation of how to best accomplish this can be found in Working with Microsoft Visual Studio 2005 Team System by Richard Hundhausen (Microsoft Press, 2005), or online at http://msdn.microsoft.com/en-us/library/ms181423.aspx.
This is just one example of how tactics for managing source code and software versions could be applied. There are certainly many other potential solutions for achieving similar objectives that could be more beneficial to your organization. The important point is to illustrate why source code management is so critical to maintaining high-quality code across multiple versions of the product and among multiple developers within a project. It is less important how you manage specific source control processes within your organization and more important that the proper attention be given to this engineering practice. Not only will a formal source control management process provide a well-defined way of managing your company’s intellectual property, it will also provide teams the ability to enforce certain levels of quality within each branch and thus control the overall quality of the product across different versions. Subsequent sections of this chapter will build upon the concept of enforcing check-in quality criteria and recommend formal methods for governing code quality before the code is entered into the repository.
Once you establish the appropriate source control management process within your organization, it is important that you focus attention on how to manage the quality of the code being checked into the source repository. Oftentimes application development teams have no formal process for governing the quality of the code they check in. In some cases, simply getting the code to build on a developer’s workstation meets the quality bar of adding to source control. In other, even more extreme cases, source control is simply used as a backup to a file on the developer’s workstation. As we previously discussed, the source for your software application is critically important intellectual property, and development teams need to take the necessary strides to ensure that the code quality being checked into source will not accidentally degrade the overall quality of the application. The best way to prevent poor quality code or features from being introduced into the source repository is to establish check-in procedures and criteria.
Establishing a check-in process and associative quality criteria allows application development teams to enforce a certain level of quality in the code being checked into source control. This reduces the risk that certain classifications of bugs do not get introduced into the source repository, thus reducing the total volume of bugs likely to be found at the end of the development cycle. Additionally, these procedures also guarantee a certain level of product stability is always present within the repository, which is important for developers sharing the code. Accomplishing this, however, requires that engineering teams establish a process that all developers will adhere to, as well as certain criteria that define the quality bar for what features or bug fixes get checked into the repository. An example of what a hypothetical check-in process may look like is illustrated in 11-3.
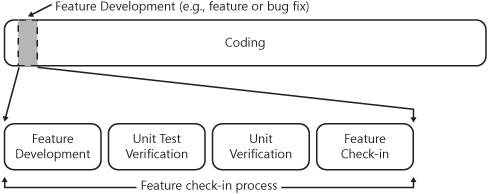
As depicted in 11-3, a feature check-in process incorporates a series of steps or quality gates that application development teams should apply to their existing development process to ensure that code being checked into source does not introduce bugs into the application. This process can be applied to either feature-level development or bug fixes, and it guarantees that certain steps are taken to control quality. For example, during feature development, application developers and their test counterparts partner to develop the feature or bug fix code, as well as the automated test code. Once both code and tests are complete, the entire unit of work is handed off to the tester for verification on a test workstation or a workstation that is independent from that of the developer. Upon verification by the tester, the feature can be cleared for check-in. Let us examine these steps in more detail.
During the feature development phase, application developers will work to complete feature-level coding or a specific bug fix within their product. As part of the code deliverables, developers should collaborate with their test counterpart and also deliver specific unit tests that exercise the code and business rules that they are developing or changing. This will ensure that, as each feature gets worked on, developers continue to expand the automated unit test corpus that can be run against the feature code to maintain code quality. In parallel to the application developer’s efforts, the tester should be also updating the suite of tests that get used to determine the quality of the build. This will ensure that any changes the developer makes that would be considered high risk or build-breaking changes would be caught in the build verification testing procedures. In addition to these steps, developers and testers should seek formal code reviews from their peers to be sure that the newly written code adheres to any previously established guidelines or best practices that the team requires. As previously established in Chapter 10, code reviews should be combined with code analysis tools like FxCop or the code analysis features within Visual Studio 2008. Once both feature code and test code are complete, the unit of work should move into the unit test verification phase.
In this step, the developer and tester begin running unit test passes against the newly developed code and review the code for overall quality. Application developers should physically hand off the unit of work to their testing partner so that the complete work can be built and executed on the tester’s workstation or within a lab environment that is independent of the developer’s workstation. This will ensure that the code can be independently built and deployed and all dependencies are accounted for within the unit of work. Visual Studio Team System can help facilitate this through the use of shelving, which allows a developer to temporarily set aside a set of pending changes for review by another developer or tester prior to check-in.
Note
Shelving is a feature within TFVC that allows application developers to set aside, or "shelve," their work on the version control server without actually checking the code in. This allows the code to be safely stored on a central server within a personal source branch, which ensures that the code is archived but not directly integrated with the working codebase. Once the work is shelved, it is preserved in source control for future use or can be shared immediately with other developers or testers.
Fortunately for application developers and testers, shelving opens up a number of different possible uses within the application development process. For example, it could be utilized for simple code storage or for sharing with another developer. It could also be leveraged for experimenting with alternative feature ideas and storing each separately, or supporting the process discussed above whereby developers shelve a unit of work and hand it off to a tester to be built and validated locally on a different workstation. In either case, shelving is a very useful feature within the TFVC toolset, and it is highly recommended for allowing flexibility with storing unfinished code in the source repository but still preserving the quality of code in the working branch.
For additional information about shelving, as well as some of the other features within Visual Studio Team System (VSTS) and Team Foundation Server, I recommend reading Working with Microsoft Visual Studio 2005 Team System (Microsoft Press, 2005) by Richard Hundhausen. In addition to covering shelving, the book also covers numerous other aspects of managing projects with VSTS.
During this time, application developers and testers are likely to find and fix a few bugs before getting the complete set of unit tests to pass completely. This is a critically important step because any bug found during this process is one less potentially build-breaking bug introduced into the source tree. This process may seem slightly more rigorous than most application developers may be used to, but in the long run it actually saves a lot of time that would otherwise be spent squashing bugs in the integration and stabilization testing phase of the project. Once all unit tests are passing, the unit of work should then move onto the next phase, which seeks to evaluate the code in the context of the broader application.
The next step in the feature check-in process is to validate the unit of work against the complete application build and broader feature set. This implies that any automated test cases that evaluate code for potentially build-breaking bugs should be executed against the full build of the application. This process ensures that any changes introduced with this feature code will not break the build, which is to say, break major functionality of the application and not literally the build process. During this process, testers should be executing the broader set of build verification tests against the version of the application containing the new code. If no issues result from this test pass, then the tester should authorize the developer to check in.
The final step in the feature check-in process is for the developer to check the code into the appropriate working branch within the source repository. This particular step assumes that the developer and tester have jointly met the previously established quality criteria for the feature. These criteria would have included passing all automated tests, performing a peer review of the application and test code, and any other specific rules that the team wishes to apply. Assuming that all appropriate quality gates have been passed, the developer would be authorized to check the code in by the tester.
Note
In addition to simply establishing a check-in process with specific quality criteria, application development teams can also enforce certain rules and policies during the check-in process within Team Foundation Server (TFS). This is a very powerful feature within TFS that gives application development teams quite a bit of control over the quality of the code being added to source.
TFS offers certain check-in policy rules out of the box as well as an extensibility model for adding more custom policies. These policies can be defined by a system administrator and provide warnings to developers if they attempt to check code in that violates those policies. In addition to the tools available out of the box with TFS, a check-in policy pack is included with the TFS Power Tools, which can be found at http://msdn.microsoft.com/en-us/tfs2008/bb980963.aspx#build. The following are examples of some typical TFS check-in policies.
The source intended for check-in must pass static code analysis rules.
The code being added to source control must pass x number of unit tests before being checked-in.
The source code must be reviewed by another developer prior to check-in.
The key point to remember is that TFS provides mechanisms to enforce the quality-focused policies that we have been discussing thus far. Additionally, it provides application development teams with flexibility for how they implement and enforce those policies. It represents precisely the toolset required to enforce the accountability for quality within the application development team.
If at any time during the development of this feature, other developers happened to check in newer versions of the same files being updated with this change, then the application developer of this new feature should perform the necessary code merging and re-execute the testing suites. This will ensure that the combination of these changes does not introduce quality issues with this new check in.
The previous example is just one possible solution to implementing a quality-focused check-in process for feature or bug fix development within your organization. As mentioned, establishing quality criteria for the source code being actively developed and checked in will help application developers and testers find and fix bugs earlier in the feature development process, rather than downstream during integration and stabilization testing phases. Discovering and fixing bugs early in the coding cycle not only increases the stability and quality of the code but ultimately saves time downstream during the integration and stabilization testing phases. It is important for application development teams to recognize the value in governing the quality of code at every step of the development cycle and establish the appropriate quality-control processes to ensure a successful project outcome. Creating these check-in processes and quality criteria is just one way to begin raising the bar on the quality of the code being produced on a daily or weekly basis. To build upon this process, application development teams should incorporate a daily build and release rhythm into their engineering rhythm as well. In addition to enforcing check-in criteria, this will further help them find and address bugs within the product earlier in the development cycle. We will explore this in more detail in the subsequent section.
In addition to establishing a feature check-in process and associated quality criteria, application development teams should also incorporate daily builds and daily release testing. Adding these steps to the feature check-in process will further help development teams find and fix product bugs early in the development cycle, thus continuing to build upon the quality upstream philosophy. This concept was originally introduced in Chapter 1, when we evaluated the quality upstream approach that the Windows Live Hotmail team follows. As you may recall, the Windows Live Hotmail team incorporates a process of building and deploying its application each day once it surpasses a certain build quality bar. This is a process that allows the team to see the effects of recent code changes on the broader application immediately and to control the quality of the application very tightly. This helps the team maintain a high degree of quality with the daily builds, even when its release schedule is aggressive. Augmenting your organization’s existing processes to incorporate these steps will also help your respective application development teams achieve the same result. Let us evaluate this process in greater detail.
In the previous section, we discussed a hypothetical feature development check-in process that included the establishment of quality criteria at each step. Within this process, we introduced the idea that application developers and testers collaborate on the development and testing of a unit of work prior to being checked into source control. The intent of this collaboration is to both parallelize the development of feature code and test code, while also encouraging joint ownership of the quality of the code being checked in. The result of this process assumes that units of feature work get introduced into the working branch of the source repository on a periodic basis. While this process works well at controlling the quality of code being produced by individual application developer and tester pairs, additional controls are needed to ensure that quality is also evaluated periodically across the larger team and the broader product. It is quite conceivable that developers across the team will write code that either interacts or overlaps with code being developed by other developers. Despite careful unit testing on the part of these individuals, there is a high likelihood that the testing will be somewhat isolated and not find broader product bugs. Therefore, it is important for application development teams to incorporate the use of Build Verification Testing (BVT) to ensure a certain level of quality across the product on a daily basis. In keeping with the spirit of previous examples, let us consider a hypothetical feature development and release process that defines a software development team’s daily project rhythm. 11-4 represents an example of this hypothetical build-and-release process.
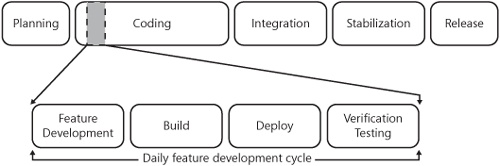
In this example, you will notice that feature development is encapsulated into one part of the process. This part of the process is inclusive of the aforementioned quality criteria and related processes illustrated in 11-3, shown previously. It assumes that the feature development portion ends once units of work are checked into the source repository. During the course of any day in the life of an application development team, several units of feature work or bug fixes are likely to be checked in as part of this process. After all work units are checked into source, a daily build should be executed against the latest code available in the source repository. This should happen on an independent workstation or build server that is managed within a test lab (we will discuss this process in greater detail in a subsequent section). Once a build has completed, it should be deployed to a test server for additional automated testing. The results of the daily testing should indicate whether the quality of the daily build is high enough to move forward with additional feature work or whether the development teams need to make immediate fixes so that the build can be declared successful. Let us evaluate this process at a deeper level and illustrate the importance both from a cultural and engineering perspective.
Note
At Microsoft, the daily build process is engrained into the engineering culture. If a build breaks or BVTs fail on a daily build, it is generally treated as an "all hands on deck" issue, and forward progress ceases until the issues with the build are addressed. Historically speaking, there have long been rumors about how some teams treat the individuals responsible for build breaks. By all accounts, this is a label that most developers would rather not be adorned with.
This process represents the period of time where individual units of development and test work, for a feature or bug fix, are being completed. As previously described in depth, feature development may take place over the course of hours, days, or weeks and culminates when all units of work have been unit tested and verified by a developer and tester. As a best practice, a single unit of work should not take weeks to complete. Incremental units of work that make up a large feature should be validated and checked in periodically. The quality of the code being developed during this process is first validated in isolation by the individuals working on the feature, and then more broadly using automated test cases that search for potentially build-breaking bugs. At this stage, code quality has been primarily analyzed at the feature level, rather than across the broader application.
The build is the complete, compiled application that represents the sum of all feature development units of work that have been checked in within the past day. Building the complete application should be an automated process whereby the most recent code is obtained from source control, copied to a build machine, and compiled. This process should be repeated at a specific time every day so that a build rhythm is maintained and build quality remains high. All team members should be keenly aware of the designated build time and be available to support any issues that arise from build failures.
Daily automated builds should be applied to a specific test server infrastructure that resembles that of the production environment. By installing builds on a daily basis, testers are able to validate deployment issues in parallel to application-specific issues as well. This will ensure continued high quality in application deployment processes, scripts, environmental dependencies, or configurations.
After the application completes the build and deployment steps, all core features of the product should be validated through the BVT procedures. These tests represent the highest priority automated test cases that adequately reflect the core functionality of the application. This suite of test cases should pass on a daily basis for all new features to ensure that no bugs have been introduced into the system that affects core functionality. Additionally, the BVT test cases should be updated with each check-in that occurs during the feature development process so that the corpus of high-priority test cases continues to evolve with the application.
As discussed, adding the additional steps of building, deploying, and verifying the quality of the application code on a daily basis will help promote a higher level of overall application quality, over and above that of the quality being verified at the feature level. With these steps, application and deployment bugs are discovered and fixed earlier in the release process, which provides a daily evaluation of end-to-end application quality. Additionally, this process also enables tighter control over daily application quality and project health, while also fostering a more rigorous engineering culture among the team members. By shining a light on the quality of an application development team’s daily activities, individual team members will take more pride in the feature work for which they are responsible, and overall team results will subsequently improve.
By incorporating these processes and monitoring the results of daily builds and release testing, application development teams will get a better sense for how they are trending toward their overall project goals or future version objectives. At the same time, they will also continue improving overall product quality. To effectively execute on these processes, it is important that teams automate as much of them as possible. Automation will both alleviate the resource overhead of managing the various tasks as well as encourage repeatability and reliability of the overall process. In the next section, we will review one of the many ways that automation can streamline the daily workings of the application development process, beginning with simply automating the build procedures.
Incorporating quality-focused processes into your organization’s day-to-day engineering rhythm is very important to the overall goals of delivering a functional and bug-free product. To that end, each process that gets added to your daily engineering rigor should be efficient, reliable, and repeatable so that quality objectives can be achieved without sacrificing unnecessary amounts of project time. One way to accomplish this is to automate as many of these processes as possible, which will help to maximize efficiency as well as reduce or eliminate human error. While some application development processes such as code reviews or project management will always require human intervention or coordination, many such as the application build process can be fully or partially automated using tools that are readily available to Microsoft .NET developers. Let’s consider a hypothetical application build example and explore the tools available to automate the build process.
In a typical application build scenario, multiple steps are often required to ensure that a successful build occurs. These steps might include such tasks as requesting files from source control, compiling the code locally, running code analysis or automated testing, copying the code to a shared server environment, and perhaps even sending an e-mail to the team advising that the process is complete. These steps are represented visually in 11-5.
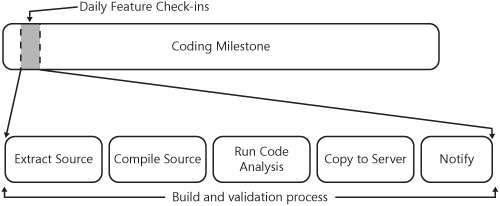
In many application development organizations, the build process happens at least once per day on any given project and often multiple times per day. This is not only a time-consuming effort but often very error prone if the steps are complex. Fortunately, it is an easily automatable process and one that pays repetitive efficiency and quality dividends after the initial engineering investment. Let’s consider the array of options that are available to automate application builds.
This is a free and open source build tool for Microsoft .NET applications. Originally released to the public in 2001, the tool was inspired by the freely available Java build tool called Apache Ant and was built to provide an extensible framework for automating complex build tasks. NAnt executes build tasks based on a set of instructions defined within an XML file, and because the framework is extensible, customized tasks can be developed and integrated directly into the build framework.
Officially known as the Microsoft Build Engine, MSBuild is the build environment for Visual Studio that can also be run as a stand-alone executable. Much like NAnt, MSBuild allows the build process to be described in an XML-based project that supports operations inclusive of build configuration, build tasks, inputs, and outputs. Because MSBuild is actually a build framework as well, it can also be extended to perform custom operations through the use of a managed code application programming interface (API). We will explore MSBuild in greater detail in a subsequent section of this chapter.
This product was introduced with the Team Foundation suite and is a flexible and extensible build automation system that layers additional functionality on top of the existing MSBuild capabilities. In addition to offering an easy-to-use wizard interface to create initial builds, Team Foundation Build tightly integrates with some of the team-focused features of the Visual Studio Team Suite and streamlines many of the tasks, such as generating reports or updating project work items, which require customization work when using MSBuild.
In summary, there are several automated build tools currently available for managed code applications, which provide application development teams with several options for incorporating automated builds into their daily engineering regimen. Even though open source software has been an incredibly beneficial movement from an innovation perspective, many corporations will likely prefer to utilize build tools that are backed by support agreements such as MSBuild or Team Foundation Build. Fortunately, these are both excellent tools that are full-featured, extensible, and improving with each release of the Microsoft Visual Studio suite of products. Although it is beyond the scope of this chapter and book to discuss each of these products in depth, we will review MSBuild in greater depth in the next section.
Note
Despite tackling a simple example of MSBuild in this chapter, this is a subject area that quite easily consumes an entire book. Constructing automated builds can be quite complex, and we definitely recognize that fact. That said, we simply could not provide a truly in-depth analysis in this chapter. For additional detailed information about MSBuild, we recommend reading Inside the Microsoft Build Engine: Using MSBuild and Team Foundation Build (Microsoft Press, 2008), by Sayed Ibrahim Hashimi and William Bartholomew.
MSBuild is a great command-line utility for automating your development team’s daily application builds. It does not require Visual Studio be installed and is therefore ideal to use in test lab environments. Basic tasks such as building projects, copying files, and running code analysis tests are easily accomplished through the build project file. Additionally, MSBuild provides an extensible framework for adding custom operations so developers can augment the build project to be customized to fit their respective needs. With a little ingenuity, MSBuild can be leveraged to provide a very rich build experience for just about any managed code development organization. Let us look at the basic anatomy of an MSBuild project, as well as a simple example.
All elements and attributes of an MSBuild project are contained within a project file. An example of a project file is the .csproj file associated with any Visual Studio C# application. Generally, the project file can contain any number of item collections, tasks, and properties and represents the complete set of build directives organized within a single file. The following illustrates the basic skeletal structure of an MSBuild project file.
<Project xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<PropertyGroup>
<!-- Properties -->
</PropertyGroup>
<ItemGroup>
<!–Item(s) -->
</ItemGroup>
<Target>
<!–Task(s) -->
</Target>
</Project>Items represent the inputs of the build process. They can be represented as either singular elements or as collections when they are of the same type, and they are created within the project file as children of the ItemGroup element. The following is an example of typical compile inputs.
<ItemGroup>
<Compile Include="class1.cs" />
<Compile Include="class2.cs" />
<Compile Include="PropertiesAssemblyInfo.cs" />
</ItemGroup>Within the MSBuild project, tasks are defined as the build operations of the project. Tasks are represented as children of the Target element. They are also capable of accepting parameters as well, which are represented as attributes of the Task element. MSBuild supports quite a few tasks by default, and custom tasks can be implemented by deriving the custom task the ITask interface that is supplied to developers. The following represents a WriteLinesToFile task, which is a default capability of MSBuild.
<Target name="AfterBuild">
<WriteLinesToFile File="c: emp" Lines="@(Items)" Overwrite="true" />
</Target>These are the basic configuration parameters of the MSBuild project. They are child elements of the PropertyGroup element and are used to describe such attributes of the project as the project name, version, root namespace, and many others. The following represents an example of an MSBuild property. A complete list of properties has been purposely omitted for brevity.
<PropertyGroup>
<AssemblyName>MyApplication</AssemblyName>
<StartupObject>MyApplication.Program</StartupObject>
</PropertyGroup>Although these elements represent the basic structure of the MSBuild file, there are several items and tasks available by default, as well as a number of default properties. Because it is out of scope for this chapter to list each one individually, it is recommended that application developers consult the definitive MSBuild Reference MSDN at http://msdn.microsoft.com/en-us/library/0k6kkbsd.aspx. The main point to remember is that Microsoft provides an initial set of functionality within MSBuild out of the box and allows application development teams to extend the framework to fulfill their specific needs. Now that we have reviewed the basic structure of an MSBuild project, let us look at a sample project file and the associative build process in greater depth.
In keeping with programming tradition, let us consider the bulid process of the simple yet well understood HelloApplication, which is a simple C# console application. For the purposes of this example, we will not focus valuable page space on the details of the application code but rather just discuss the basic structure so as to support the MSBuild example. In the HelloApplication, user input is received in the form of a first name and last name, and it is subsequently concatenated with a friendly message and output back to the screen. Within the application structure, there are three simple classes that provide the application functionality. Those classes include the following.
Program.cs. Contains the main entry point of the application, which performs the main read and write functionality on the console window.
Person.cs. Represents a simple person data structure that supports the Program.cs class.
AssemblyInfo.cs. Default class that manages information about the compiled assembly.
When writing the HelloApplication, Visual Studio automatically created the appropriate MSBuild .csproj file for us, but let’s assume we wish to add some functionality to the build process. We accomplish this by first unloading the project in Visual Studio and then editing the HelloApplication.csproj file directly. Next, we add some simple console messaging so that we can visually follow along with the build process. Finaly, we add an additional logging task where we will capture the list of files being compiled. Let us review an abridged version of the MSBuild file and review the changes.
<?xml version="1.0" encoding="utf-8"?>
<Project xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<!-- Property Groups and properties ommitted for brevity -- >
<!-- Add ItemGroup to define our log file -->
<ItemGroup>
<MyTextFile Include="logfile.txt"/>
<MyLogHeader Include="Hello Application Build Log"/>
<MyItems Include="*.cs"/>
</ItemGroup>
<!-- Compile Collection -->
<ItemGroup>
<Compile Include="Person.cs" />
<Compile Include="Program.cs" />
<Compile Include="PropertiesAssemblyInfo.cs" />
</ItemGroup>
<!-- Before build directive -->
<Target Name="BeforeBuild">
<!-- Log a console message -->
<Message Text="Begin Solid Code Chapter 11 HelloApplication Build." />
</Target>
<!-- After build directive -->
<Target Name="AfterBuild">
<!-- Log a console message -->
<Message Text="Finished Solid Code Chapter 11 HelloApplication Build." />
<Message Text="Writing simple log file." />
<!-- Output files to a log -->
<WriteLinesToFile File="@(MyTextFile)" Lines="@(MyLogHeader);@(MyItems)"
Overwrite="true" />
</Target>
</Project>Note
As with all code associated with this book, the complete set of source will be available on the companion Web site, but, for the sake of brevity, we have only included an abridged version here to illustrate the specific additions being applied.
As you will note from the preceding MSBuild project code sample, the log file and compile inputs were specificed within the ItemGroup elements. Both our console output messages and file writing tasks were specified within the Target elements. Whenever a build is initiated, a log file called logfile.txt with a list of the compiled resources will be generated, and several output messages will be written to the console. To actually initiate the build, we launch the Visual Studio 2008 command prompt and execute the build command using syntax similar to the following. The results are illustrated in 11-6.
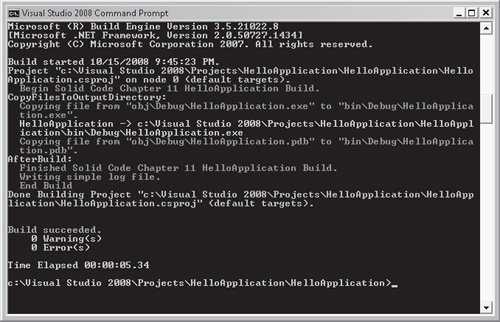
Msbuild switches projectfilenameSpecifically, the syntax required to execute the build is as follows.
Msbuild HelloApplication.csproj
Upon completion of the build, we note from the console output that the build was successful, and the messages specified in the build file were in fact output to the screen. Additionally, a physical log file called logfile.txt was written to the project’s root directory, which contained the following log information.
Hello Application Build Log Person.cs Program.cs
Although this example has only focused on basic capabilities of MSBuild, we should once again emphasize that there is an incredible degree of flexibility with this build tool. In addition to the simple log file and console example above, application developers could quite easily automate common tasks such as obtaining the latest code from source, generating code analysis results, or sending e-mail when the build has failed or completed. Regardless of the build process requirements, the extensibility available within MSBuild can help application development teams fulfill their automated build needs. Additionally, for development teams that are leveraging the capabilities of Team Foundation Server and Visual Studio Team Suite, similar flexibility and extensibility is available with those tools as well.
Thus far, we have focused many of our recommendations on quality- and efficiency-focused improvements that application development teams can implement within their respective organizations. For starters, we discussed how the appropriate source control processes and check-in procedures can help control the quality of code being applied to the source tree. Additionally, we reviewed how daily builds, releases, and testing can help teams find and fix product bugs early in the release cycle, which improves the quality of the application on a daily basis and decreases the number of bugs found during the testing phase of the project. As you have seen, each of these recommendations supports one central idea, which is to continuously increase the quality of the application code as early in the release process as possible, preferably before entering the integration and stabilization testing phase. Each of these engineering tactics will help application development teams to ratchet up the quality of the code during key points within the coding phase of the project. In addition to these tactics, it is also important to establish specific criteria across the application codebase, so that quality can also be improved within some of the key engineering focus areas previously discussed in this book, such as security, performance, and scalability.
In general, incorporating quality criteria into the feature development process helps teams to measure and maintain the health of their application code in specific engineering focus areas like security, performance, or scalability. Establishing and enforcing this criterion helps to ensure that focus is given to key areas of the application code, over and above that of basic functional code quality. For example, the code quality of a specific feature may be considered high when all functional test cases pass and the feature meets the necessary requirements. However, that feature may contain security vulnerabilities or be poorly performing, which ultimately affects the overall quality of the feature. To avoid this situation, application development teams must ensure that the quality bar they establish for their application code includes specific criteria for addressing issues within the following areas.
This is perhaps one of the most important, yet most frequently overlooked, engineering focus areas, where code quality issues can produce disastrous results for applications, as well as their users. It is critically important for application development teams to understand their application’s potential vulnerabilities, follow the security best practices outlined in this book, and continuously evaluate application code for security issues. It is not critical for security testing to be performed with the same frequency as functional testing. However, security testing should definitely be performed periodically throughout the development cycle. Security bugs are often quite challenging to find and sometimes very risky to fix once the application code reaches a certain completion state. Hence, discovering and fixing this style of bug early in the release process reduces potential code churn later in the development cycle. Establishing quality criteria for security within the team, which requires feature code to be free of security bugs prior to entering the testing phase of the project, is one way to ensure this class of bugs is caught early in the development process.
It is important for teams to embrace performance excellence and establish the appropriate performance goals for their applications. In Chapter 4, we specifically discussed the risk and cost associated with fixing Web performance bugs after they have crept into a product release. It is incumbent upon application development teams to focus a portion of their development and testing efforts on setting performance goals, incorporating the best practices, and proactively measuring performance indicators during the feature development cycle. Ideally, application development teams should establish quality criteria for performance and hold themselves accountable to making sure performance quality is high prior to exiting the development phase of the project.
Ensuring that your application is designed to scale appropriately should also be an area to focus specific attention on during the coding phase of the release cycle. Just like performance and security, quality issues in the area of scalability can be very costly and risky to fix late in the engineering release cycle. It is important that development teams make certain that their scalability designs are vetted with the appropriate testing during the coding period. This can be accomplished multiple ways, including leveraging such tactics as load testing daily builds, simulating hardware failure, or testing hardware load balancers. It is of course not critical that the testing be extensive, but it should evaluate key scale points of the application and ensure that major design flaws are not carried into the testing phase of the release cycle.
Although the three engineering focus areas we specifically mentioned will likely apply to a broad base of application development teams, there are other areas that deserve an increased quality focus also worth mentioning. For example, development teams that build international software should maintain a high degree of focus on globalization or localization quality. Alternatively, teams that develop software for government organizations should focus on ensuring a high degree of quality in the area of accessibility, which specifically improves the application usability experience for people with disabilities. In either case, it is important for development teams to identify the specific areas that are most relevant to their software applications and establish the appropriate criteria for maintaining a high degree of quality across the application during the coding phase of the development life cycle.
As you have seen, there are several key engineering focus areas that deserve special attention as applications are being constructed. Development teams should evaluate the set of focus areas that are most relevant to their applications and establish quality criteria to which they will hold themselves accountable to during the coding phase of the release cycle. Typically, this starts with setting simple goals for design reviews, test coverage, or bug counts in these specific areas. Once goals are established, application developers and their test counterparts should be held accountable to the established goals, prior to moving from the coding to the testing phase of the project. This implies, of course, that formal criteria and quality goals be broadly agreed to at the onset of the project to ensure that all stakeholders are bought into the process. Like the other tactics for improving quality that have been suggested in this chapter, this too will help to continue to focus on pulling quality upstream in the engineering process, which will ultimately lead to a much better product for your end users.