
Rare will be the case in which an application will require Spring and Hibernate alone. Depending on your situation, you will likely need to integrate with multiple frameworks in order to meet your application's requirements. Sometimes these integration details will be a trivial matter. Other times, integration with another framework can present its own unique set of challenges.
Two very common requirements faced by engineers today are implementing free-text search and exposing web-based APIs. In this chapter, we'll show you how you can leverage several frameworks to attain these goals. To expose an API for our art gallery application, we'll take advantage of the RESTful web service enhancements added to Spring 3.0, as well as Dozer, Spring's Object/XML Mapping support, and the Data Transfer Object pattern for data marshaling. To implement free-text search, we'll leverage Hibernate Search, a subproject of Hibernate that provides a seamless way to integrate Lucene into a Hibernate-based application.
These days, the requirements for web applications have become increasingly complex. As processing power and bandwidth increase, users' expectations follow along, leading to more complex architectures and more interactive and responsive features. Template-driven HTML web pages powered by controllers and JSPs are rarely adequate anymore. Instead, today's typical applications require asynchronous messaging between the client and the server—often leveraging Ajax or Flash. This shift away from pure server-side processing means that rendering the user interface is only part of the battle. A large proportion of the work in many of today's rich Internet applications (RIAs) often revolves around communicating with a web service or serializing data as part of a remoting strategy.
REST, which stands for Representational State Transfer, has become increasingly popular for implementing web services. REST is best described as an architectural style, rather than a standard or protocol. REST leverages HTTP to provide a consistent, resource-oriented approach for representing data. As opposed to a remote procedure call (RPC) style of communication, in which the metaphor is more akin to a method call, REST focuses on the representation of a particular resource, which is typically embodied as a URL. RESTful APIs leverage many of the built-in features of the Web, such as caching, proxying, and HTTP-based authentication strategies.
Note
Roy Fielding originally coined the term REST in 2000 as a part of his doctoral dissertation. Fielding was one of the primary authors of the HTTP specification, and REST was defined in parallel with the HTTP 1.1 specification.
RESTful APIs are usually expressed in terms of nouns, verbs and content-types:
Nouns are the names of resources. These names are normally expressed as URLs.
Verbs are the operations that can be performed on a resource. The verbs are the common HTTP verbs:
GET, POST, PUT, andDELETE.Content-type representations refer to the data format used to enable machine-to-machine communication. Popular representations are XML, JSON, HTML, binary data such as images, or even RDF ontologies.
Nouns, verbs, and representations can be visualized as depicted in Figure 10-1.
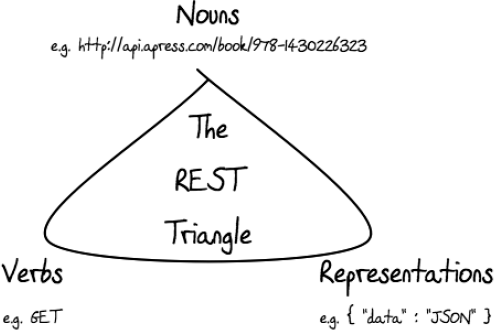
To further illustrate the relationship between nouns, verbs, and content-type representations, let's assume that Apress has an API that is used for managing its books. To create the book you're reading, we might issue an HTTP POST on a URL like http://api.apress.com/book/. The body of that POST, as well as the format for the data returned, is completely up to the API designer. REST doesn't prescribe a particular data format, so API designers must make the right choice for their situation. The API might accept XML, JSON, or any number of data formats that can be transmitted over HTTP. The Apress API might even support multiple representations of the data, allowing consumers of the API to issue requests to a single resource URL as either XML or JSON. You would typically handle this content negotiation by specifying a content-type header (for example, json/text).
A well-designed API may also allow you to indicate which data representation you expect to receive in return by supplying an Accept header. Adhering to the semantics of HTTP, the successful addition of our book would return HTTP status code 201, created. The API would likely also provide a link to the resource representing the newly created entity by its name, http://api.apress.com/book/prospringhibernate, or perhaps better yet, via the ISBN-13 number, http://api.apress.com/book/978-1430226323.
With a resource defined, a RESTful web service can use the verbs provided by HTTP to access or manipulate the data these resources represent. For example, if you wanted to retrieve the current representation of our book, you would issue an HTTP GET on the resource http://api.apress.com/book/978-1430226323, specifying a content-type header as json/text. The JSON response might look like this:
{
"book" : {
"ISBN-13" : "978-1430226321",
"title" : "Code Generation in Action",
"authors" : {
"author" : [ {
"first" : "Paul", "last" : "Fisher"
}, {
"first" : "Brian", "last" : "Murphy"
}
] },
"publisher" : "Apress"
}
}Similarly, if you wanted to update the properties of this resource (to update some content related to this book), you could issue an HTTP PUT request targeting the URL http://api.apress.com/book/978-1430226323, passing in the updated state of the resource.
Here, we'll focus on the features provided by Spring that simplify developing RESTful APIs. Before we can tackle our Spring implementation though, we need to settle on a serialization strategy. In order to transmit a rich domain model over the wire, we need to be able to flatten our object graph so that it can be serialized and represented as XML or JSON.
Despite the simplicity inherent in RESTful architectures, a challenge remains in the way in which your domain model is serialized into whatever format your web service chooses to provide. For instance, if you choose to represent your data as XML, there are numerous frameworks and techniques for converting an object-oriented domain model into XML. No matter which you choose to marshal your domain object, you will likely run into the problem of serializing too much of your object graph. This is a side effect of another type of impedance mismatch between the object-oriented Java realm and the flat, text-based realm of XML and JSON.
In Chapter 9, you learned about the benefits and drawbacks of lazy loading. When it comes to marshaling your data, lazy loading can flare up again, if you're not careful and attempt to marshal your domain entities after your EntityManager has already been closed. However, even if the EntityManager remains open, you are bound to initialize your object graph as the marshaling process attempts to serialize your data to the specified payload format.
Unfortunately, this is a difficult problem to solve. One solution is to plug in a specialized framework, designed to prevent the LazyInitializationException from popping up or too much data being inadvertently marshaled. One such solution is a framework called Gilead. Gilead attempts to clone your domain entities into a new instance in which Hibernate proxies have been filtered out. This prevents the potential for LazyInitializationException occurrences, as well as the likelihood of loading your entire object graph, which causes serious database overhead and performance implications.
The problem with "nulling out" all of an entity's associations so that it can be serialized into a more compact and efficient format is that if this data is read back into the application and reattached to an EntityManager, these nulled-out associations will cause Hibernate to remove important data, such as dropping collections on a particular entity. Gilead provides several strategies for what it calls the merging process, in which data returned to the Hibernate application is reassembled back into the original structure. One solution attempts to keep these details in the HttpSession, which requires the least intrusion into your application code, but can also come with performance and scalability penalties. Another strategy requires that your domain model extend from a base class provided by Gilead. Gilead then uses this base class as a means to stash the information required to merge the lightweight marshaled data back into the Hibernate application. You can learn more about Gilead at http://noon.gilead.free.fr/gilead/.
The Data Transfer Object (DTO) pattern is considered by many to be a "bad idea." This is because it has the potential to add significant code redundancy and complexity, leading to a higher potential for bugs and maintenance overhead down the road. However, there are times when the DTO pattern can serve as a viable solution, and dealing with marshaling your domain model is arguably one of those times.
The DTO pattern typically requires the creation of specialized classes intended solely for transferring your domain objects' data. Usually, you will create a separate package structure to help avoid confusion. Your DTO classes will likely be smaller and more compact than your domain objects, often replacing object references with a simple identifier, and possibly removing associations altogether. Obviously, the specifics of your DTO layer depend on your application's unique requirements. However, because your DTO classes have no dependency on Hibernate, are more compact, and have far less potential for circular references, they can help simplify the effort required by a marshaling strategy.
The primary concern raised when using DTOs is that you need to write a lot of custom code to translate from one class hierarchy to another (from your domain model to your DTOs and back). Not only does this translation effort require a lot of up-front development time, but it can also lead to bugs, especially if your domain classes are changed but your DTO translation code isn't updated accordingly.
One solution to this problem is Dozer. Dozer is a different type of mapping framework. Unlike Hibernate, Dozer doesn't attempt to map Java classes to a relational database. Dozer maps Java classes to other Java classes, and it is designed especially for the domain model-to-DTO translation requirements.
The chief advantage of a framework like Dozer is that it offloads the complex implementation details of converting one class to another. Dozer is able to make some intelligent determinations regarding how two classes relate. For instance, if two classes that are intended to be mapped to one another share properties with the same name, Dozer will attempt to automatically map these properties, unless it is told otherwise. Dozer is also able to handle conversion between types, so even if mapped properties are not of the same type, Dozer will attempt to convert from one type to another using one of its built-in converters. It is also possible to create your own converters, if you can't find an applicable converter. However, Dozer supports nested mapping behavior, so if you define the mapping behavior between two classes, these rules will be applied at any level of conversion. In other words, even if you are attempting to map two different top-level classes, Dozer will apply the mapping rules for any other defined classes as necessary. This holds true even for nested properties and collections. When Dozer is confronted with a mappable scenario, it will apply these rules automatically. These details are much clearer when examining a few examples, so let's begin integrating Dozer into our art gallery application.
To begin using Dozer, we first need to add the necessary dependencies to our Maven pom.xml file:
<!--Dozer -->
<dependency>
<groupId>net.sf.dozer</groupId>
<artifactId>dozer</artifactId>
<version>5.2.2</version>
</dependency>This will provide all the necessary JARs required for Dozer integration. Once this snippet is added to your pom.xml, you will likely need to run mvn install in order to download the necessary dependencies into your local Maven repository.
Before we can go any further, we need to define our DTO classes. Typically, DTOs are similar to their corresponding domain classes, but are simpler in nature. By removing bidirectional associations, circular references, and unnecessary properties, a DTO class can reduce the complexity in a marshaling strategy or a remoting implementation.
Let's define our ArtEntityDTO class:
package com.prospringhibernate.gallery.dto;
import java.net.URL;
import java.util.Date;
import java.util.HashSet;
import java.util.Set;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
@XmlRootElement(name = "artEntity")
public class ArtEntityDTO {
private Long id;
private String title;
private String subTitle;
private Date uploadedDate;
private String displayDate;
private Integer width;
private Integer height;
private String media;
private String description;private String caption;
private String galleryURL;
private String storageURL;
private String thumbnailURL;
private Boolean isGeneralViewable;
private Boolean isPrivilegeViewable;
private Set<CommentDTO> comments = new HashSet<CommentDTO>();
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getSubTitle() {
return subTitle;
}
public void setSubTitle(String subTitle) {
this.subTitle = subTitle;
}
public Date getUploadedDate() {
return uploadedDate;
}
public void setUploadedDate(Date uploadedDate) {
this.uploadedDate = uploadedDate;
}
public String getDisplayDate() {
return displayDate;
}
public void setDisplayDate(String displayDate) {
this.displayDate = displayDate;
}
public Integer getWidth() {
return width;
}public void setWidth(Integer width) {
this.width = width;
}
public Integer getHeight() {
return height;
}
public void setHeight(Integer height) {
this.height = height;
}
public String getMedia() {
return media;
}
public void setMedia(String media) {
this.media = media;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public String getCaption() {
return caption;
}
public void setCaption(String caption) {
this.caption = caption;
}
public String getGalleryURL() {
return galleryURL;
}
public void setGalleryURL(String galleryURL) {
this.galleryURL = galleryURL;
}
public String getStorageURL() {
return storageURL;
}
public void setStorageURL(String storageURL) {
this.storageURL = storageURL;
}public String getThumbnailURL() {
return thumbnailURL;
}
public void setThumbnailURL(String thumbnailURL) {
this.thumbnailURL = thumbnailURL;
}
public Boolean getGeneralViewable() {
return isGeneralViewable;
}
public void setGeneralViewable(Boolean generalViewable) {
isGeneralViewable = generalViewable;
}
public Boolean getPrivilegeViewable() {
return isPrivilegeViewable;
}
public void setPrivilegeViewable(Boolean privilegeViewable) {
isPrivilegeViewable = privilegeViewable;
}
public Set<CommentDTO> getComments() {
return comments;
}
public void setComments(Set<CommentDTO> comments) {
this.comments = comments;
}
}At first glance, the ArtEntityDTO looks very similar to the ArtEntity domain class. On closer inspection, however, you will notice that we've removed a few references. We no longer have a dependency on any of the classes in the ArtData hierarchy. Instead, we have replaced references to a particular ArtData subclass with a String that will contain a URL to the relevant image (instead of a wrapper class that contains image metadata and the binary image data itself).
The ArtEntityDTO also omits the many-to-many association to the Category domain class. This means we won't be able to directly access the associated categories of a particular ArtEntity instance. In our application, this isn't a critical requirement. We will be able to access the ArtEntity instances associated with a particular Category by accessing a Category instance directly and navigating to its child ArtEntity instances.
Notice that our ArtEntityDTO still includes a comments property. This property is represented by a java.util.Set, but rather than containing Comment domain class instances, it holds CommentDTO instances. We haven't defined our CommentDTO class yet, but like the ArtEntityDTO, this class will serve as a simplified representation of a Comment entity.
One additional detail we added to the ArtEntityDTO is the @XmlRootElement(name = "artEntity") annotation. One use case for a DTO class is to simplify the marshaling process to XML or JSON. @XMLRootElement is a Java Architecture for XML Binding (JAXB) annotation—a standard for object-to-XML marshaling. Later in this chapter, we will leverage JAXB for rendering an XML representation of our domain classes, as part of a REST web service.
Although the differences between the ArtEntity domain class and the ArtEntityDTO are not significant, the discrepancies are intricate enough to require a fairly complex mapping strategy. For instance, consider what would be required to map a collection of Comment instances to a collection of CommentDTO instances. Luckily, Dozer is able to handle the task of mapping and converting between these classes without requiring much work.
Next, let's take a look at the CommentDTO class:
@XmlRootElement(name = "comment")
public class CommentDTO {
private Long id;
private String comment;
private Date commentDate;
private String firstName;
private String lastName;
private String emailAddress;
private String telephone;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getComment() {
return comment;
}
public void setComment(String comment) {
this.comment = comment;
}
public Date getCommentDate() {
return commentDate;
}
public void setCommentDate(Date commentDate) {
this.commentDate = commentDate;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getEmailAddress() {
return emailAddress;
}
public void setEmailAddress(String emailAddress) {
this.emailAddress = emailAddress;
}
public String getTelephone() {
return telephone;
}
public void setTelephone(String telephone) {
this.telephone = telephone;
}
}The differences between the Comment domain class and the CommentDTO class are fairly trivial. We have removed the commentedArt property, which would create a circular reference between the ArtEntityDTO and the CommentDTO (provided that we changed the property type from ArtEntity to ArtEntityDTO).
Now that we have defined our DTO classes, let's create the mapping configuration that instructs Dozer how to map one class to another. Dozer provides a DozerBeanMapperFactoryBean abstraction for Spring, which is a factory bean that will help to create the Dozer mapper. The Dozer mapper relies on an XML configuration file to learn the rules that define how the properties of one class are mapped to the properties of another class.
First, let's add the appropriate configuration to our spring-master.xml file:
<bean class="org.dozer.spring.DozerBeanMapperFactoryBean">
<property name="mappingFiles" value="classpath*:/dozer-mapping.xml"/>
</bean>This bean is actually quite flexible, and supports additional properties for defining custom converters, event listeners, and other Dozer extension points. You can learn more about the capabilities of the DozerBeanMapperFactoryBean on the Dozer website.
In the preceding configuration, we have specified that the Dozer mapping files should be located on the classpath, under the name dozer-mapping.xml. This XML file defines the default behavior for Dozer as well as the rules for mapping between one class and another. Let's take a look at our Dozer mapping configuration:
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozer.sourceforge.net"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozer.sourceforge.net
http://dozer.sourceforge.net/schema/beanmapping.xsd">
<configuration>
<stop-on-errors>true</stop-on-errors>
<date-format>MM/dd/yyyy HH:mm</date-format>
<wildcard>true</wildcard>
</configuration>
<mapping>
<class-a>com.prospringhibernate.gallery.domain.ArtEntity</class-a>
<class-b>com.prospringhibernate.gallery.dto.ArtEntityDTO</class-b>
<field>
<a>galleryPicture.url</a>
<b>galleryURL</b>
</field>
<field>
<a>storagePicture.url</a>
<b>storageURL</b>
</field>
<field>
<a>thumbnailPicture.url</a>
<b>thumbnailURL</b>
</field>
</mapping>
<mapping>
<class-a>com.prospringhibernate.gallery.domain.Category</class-a>
<class-b>com.prospringhibernate.gallery.dto.CategoryDTO</class-b>
</mapping>
<mapping>
<class-a>com.prospringhibernate.gallery.domain.Comment</class-a>
<class-b>com.prospringhibernate.gallery.dto.CommentDTO</class-b>
</mapping>
<mapping>
<class-a>com.prospringhibernate.gallery.domain.Exhibition</class-a>
<class-b>com.prospringhibernate.gallery.dto.ExhibitionDTO</class-b>
</mapping>
</mappings>Let's step through the important components of this configuration. First is a configuration block toward the top of the file. This section specifies the default global mapping behavior for Dozer. We define a default date-format and also set the wildcard behavior to true. The wildcard behavior determines whether Dozer will attempt to automatically map all obvious properties by default. For instance, if wildcard is set to true and both mapped classes share properties with the same name, Dozer will attempt to map these properties automatically. This feature can be overridden within specific mapping rules. If wildcard is left active, you can still omit certain properties from being mapped by using the field-exclude element. For instance, if we wanted to prevent our subTitle property from being mapped, we could add the following snippet to the ArtEntity mapping configuration:
<field-exclude>
<a>subTitle</a>
<b>subTitle</b>
</field-exclude>The mapping configuration for a pair of classes is straightforward. Each mapping definition is encapsulated in a mapping XML block. Within each block, we include a class-a element and a class-b element, specifying the respective classes to be mapped. Although the configuration is sequential in nature, keep in mind that Dozer is bidirectional by default. This means that rules defining how we map from an ArtEntity class to an ArtEntityDTO class can also be applied in reverse to map from a DTO class back to a domain class. You can require that mapping rules be applied in only a single direction by adding the attribute type="one-way" to a mapping element.
In the case of our ArtEntity to ArtEntityDTO mapping, most of the details will be implicit since the property names are fairly consistent between the two classes. Although the comments collection property on the ArtEntityDTO contains elements of a different type, Dozer will automatically convert each Comment element within the ArtEntity.comments collection to an instance of CommentDTO by applying the mapping rules specified.
The only exception we need to explicitly define in our ArtEntity mapping rules is the conversion between the three ArtData references into String properties. In this example, the names of the properties are not in sync between the two classes, so we need to define a field element for each ArtData reference. Notice that we are not only mapping properties with different names, but we are also extracting the value of a subproperty and using this value for the converted DTO property. For instance, in defining the mapping rule to convert the ArtEntity.galleryPicture property of type ArtData_Gallery to the ArtEntityDTO.galleryURL property, we attempt to extract the url property from the galleryPicture property to use as the value for the galleryURL. This is accomplished by specifying a nested expression in the Dozer configuration:
<field>
<a>galleryPicture.url</a>
<b>galleryURL</b>
</field>The value of element a specifies a nested property, and the value of element b simply defines the property directly. Dozer is very flexible in this regard and supports nested properties as well as indexed properties when using arrays or collections.
With the configuration details out of the way, let's try to do some mapping! The easiest way to verify that everything is working properly is to start with a test. As discussed in Chapter 8, let's create an integration test. It would actually be fairly trivial to define a unit test, as our dependencies are fairly minimal. However, since we have specified some of our Dozer setup using Spring configuration, it's a little easier to let Spring take care of the details.
Here is a simple test that will help ascertain whether our Dozer mapping process is working as it should:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = {"classpath:/META-INF/spring/spring-master.xml"})
public class DozerMappingTest {
private Mapper dozerMapper;
private ArtEntity artEntity;
public Mapper getDozerMapper() {
return dozerMapper;
}
@Autowired
public void setDozerMapper(Mapper dozerMapper) {
this.dozerMapper = dozerMapper;
}
@Before
public void preMethodSetup() {
Comment comment = new Comment();
comment.setComment("This is a test comment. What a cool picture!");
comment.setCommentDate(new Date());
comment.setEmailAddress("[email protected]");
comment.setFirstName("John");
comment.setLastName("Doe");
comment.setTelephone("212-555-1212");
ArtData_Thumbnail thumbnail = new ArtData_Thumbnail();
thumbnail.setId(1L);
artEntity = new ArtEntity();
artEntity.setCaption("caption test");
artEntity.addCommentToArt(comment);
artEntity.setDescription("A very cool picture of trees.");
artEntity.setDisplayDate("October 10th");
artEntity.setHeight(500);
artEntity.setWidth(300);
artEntity.setSubTitle("This is a subtitle for a picture");
artEntity.setTitle("This is a title of a picture");artEntity.setThumbnailPicture(thumbnail);
}
@Test
public void testMappingArtEntity() {
ArtEntityDTO artEntityDTO = this.getDozerMapper().map(artEntity, ArtEntityDTO.class);
Assert.assertEquals(artEntity.getTitle(), artEntityDTO.getTitle());
Assert.assertTrue(artEntityDTO.getComments().size() > 0);
Assert.assertTrue("artData_thumbnail should be a string value",
artEntityDTO.getThumbnailURL().length() > 0);
}
}You should recognize much of the boilerplate detail from earlier testing examples. Notice that we specify our top-level Spring configuration file using the @ContextConfiguration annotation. Most of the code in this class is included in the preMethodSetup() method, which is annotated with the @Before annotation to ensure it is called before our test method (which is annotated with @Test). In preMethodSetup(), we instantiate an ArtEntity domain class, setting basic properties and associations. Once we have configured our ArtEntity instances, the testMappingArtEntity() method is called, which contains the code for our actual test. In this method, we call the map method on our Mapper instance, which was injected by Spring via autowiring into the dozerMapper private property. The Dozer mapper does all the real heavy lifting for us. We pass in our artEntity instance, which was set up in the previous step, along with the class type to which we want to map the instance, and Dozer converts our ArtEntity class into an ArtEntityDTO.
To ensure that all went according to plan, we assert a few properties on the mapped ArtEntityDTO instance, verifying that the correct values are present. Although the mapping process is deceptively simple, there is quite a bit going on behind the scenes. We now have an effective and reliable approach for converting Hibernate domain classes into simpler DTO classes.
Spring 3 offers numerous enhancements to MVC development. When Spring first appeared on the scene, it was praised for its elegant, interface-driven MVC approach. Things have improved significantly since then, helping to reduce configuration and simplify development effort.
By taking advantage of annotations, Spring now provides a much more intuitive approach for implementing controllers. It is no longer necessary to explicitly extract request parameters and other details from the request. Additionally, controllers are far less constrained. You have more flexibility in defining method signatures, without needing to obey a contract for parameter types. Instead, Spring lets you map method parameters to various aspects of the incoming request, such as query parameters, session attributes, and even sections of the URL. This newfound flexibility is powered by annotations—arguably a much cleaner and intuitive solution. Let's take a look at an example:
@Controller
public class ArtEntityRestController {
@Autowired
private ArtworkFacade artworkFacade;@Autowired
private Mapper dozerMapper;
public static final String JAXB_VIEW = "jaxbView";
@RequestMapping(method=RequestMethod.GET, value="/api/artEntities/{id}")
public ModelAndView getArtEntity(@PathVariable Long id) {
ArtEntity artEntity = this.artworkFacade.getArtEntity(id);
ArtEntityDTO artEntityDTO = null;
if (artEntity != null) {
artEntityDTO = this.getDozerMapper().map(artEntity, ArtEntityDTO.class);
}
ModelAndView modelAndView = new ModelAndView(JAXB_VIEW);
modelAndView.addObject("artEntity", artEntityDTO);
return modelAndView;
}
@RequestMapping(method=RequestMethod.GET, value="/api/category/{category}/artEntities")
@ResponseBody()
public List<ArtEntity> getArtEntities(@PathVariable Long categoryId) {
List<ArtEntity> artEntities = this.artworkFacade.getArtworkInCategory(categoryId);
return artEntities;
}
public ArtworkFacade getArtworkFacade() {
return artworkFacade;
}
public void setArtworkFacade(ArtworkFacade artworkFacade) {
this.artworkFacade = artworkFacade;
}
public Mapper getDozerMapper() {
return dozerMapper;
}
public void setDozerMapper(Mapper dozerMapper) {
this.dozerMapper = dozerMapper;
}
}In this example, we have annotated our class with the @Controller annotation. As you'll recall, @Controller is a stereotype annotation that extends from @Component. Just as with @Service and @Repository, @Controller helps to indicate the purpose of this class and can be managed by Spring automatically through its component-scanning capability.
You will also notice that we have autowired our ArtworkFacade implementation and the Dozer mapper. The real magic happens in each of the two methods defined. Both of these methods are annotated with @RequestMapping, which tells Spring the URL mapping rules for this controller method. In both methods, we have defined the URL with which the controller will be associated. More important, however, is the use of the {} characters. Portions of the URL embedded within curly braces can be referenced in the method using the @PathVariable annotation. In this way, we have implicitly extracted portions of the URL to be injected into method parameters.
In addition to the @PathVariable annotation, Spring also offers several other options for extracting aspects of the incoming request and mapping these values to method parameters. For example, query parameters and session attributes can also be mapped to parameters through the appropriate annotation. Check out the Spring documentation to learn more about implementing MVC controllers.
One important detail that we can't leave out is how we are rendering our DTOs as XML. To make this happen, we are leveraging Spring 3's Object/XML Mapping (OXM) support. Spring's OXM abstraction helps to decouple the marshaling implementation details from your application. This makes your code more portable and also simplifies the integration of multiple marshaling strategies.
Let's take a look at the Spring MVC configuration powering our REST service. The following is an abridged version of our spring-web-gallery.xml file.
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util-3.0.xsd">
<bean class="org.springframework.web.servlet.view.ContentNegotiatingViewResolver">
<property name="mediaTypes">
<map>
<entry key="xml" value="application/xml"/>
<entry key="html" value="text/html"/>
</map>
</property>
<property name="viewResolvers">
<list>
<bean class="org.springframework.web.servlet.view.BeanNameViewResolver"/>
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="viewClass" value="org.springframework.web.servlet.view.JstlView"/>
<property name="prefix">
<value>/WEB-INF/JSP/</value>
</property><property name="suffix">
<value>.jsp</value>
</property>
</bean>
</list>
</property>
</bean>
. . .
<context:component-scan base-package="com.prospringhibernate.gallery.restapi"/>
<bean class="org.springframework.web.servlet.mvc.annotation.DefaultAnnotationHandlerMapping"/>
<bean class="org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter"/>
<bean id="jaxbView" class="org.springframework.web.servlet.view.xml.MarshallingView">
<constructor-arg ref="jaxbMarshaller"/>
</bean>
<!-- JAXB2 marshaller. Automagically turns beans into xml -->
<bean id="jaxbMarshaller" class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound">
<list>
<value>com.prospringhibernate.gallery.dto.ArtEntityDTO</value>
<value>com.prospringhibernate.gallery.dto.CategoryDTO</value>
<value>com.prospringhibernate.gallery.dto.CommentDTO</value>
<value>com.prospringhibernate.gallery.dto.ExhibitionDTO</value>
</list>
</property>
</bean>
. . .
</beans>Let's step through a few of the integral components. First, we have included a ContentNegotiatingViewResolver. This bean allows us to plug in multiple ViewResolvers (which power a particular rendering strategy), specifying which ViewResolver to use based on the content-type of the request. There are two important properties for this bean: mediaTypes and viewResolvers. The mediaTypes property configures the contentTypes. The viewResolvers property specifies the ViewResolver. The order of the items within the respective properties is key, as that is how one is associated with the other.
We've also integrated component-scanning, specifying the package of our REST controllers. Additionally, we have included the necessary beans for performing request mapping via annotations.
Finally, we have specified a bean for our JAXB view, using Spring's org.springframework.web.servlet.view.xml.MarshallingView class. This bean requires a marshaller as a constructor argument, which we inject using a reference to the jaxbMarshaller bean defined next. The jaxbMarshaller bean also requires a list of classes to be bound, to which we pass all of our DTO classes (which have been properly annotated with JAXB annotations).
That's all there is to it! We recommend that you take a look at the source code to get a clearer sense of how the REST service and Spring's OXM support operate.
One of the issues we would typically run into when developing a REST web service is reliably handling concurrent attempts to modify a particular domain entity. In our earlier REST example, we examined an HTTP GET scenario, in which our web service only returned static representations of a particular entity (or entities) within our database. When dealing with HTTP PUT operations (which typically implies that a resource should be updated), things are not as simple.
Properly handling simultaneous attempts to update a particular domain entity is not always straightforward. Depending on the approach used, there can be consequences in terms of scalability risks, database deadlock potential, and data loss or conflict.
For applications in which the likelihood that two simultaneous transactions should conflict is fairly remote, Hibernate and JPA offer support for Optimistic Locking. Optimistic Locking does not pose any constraints on accessing or writing data. Instead, the version field of the relevant domain entity is verified before the current transaction is committed. If the value of the version field does not match the value of the row (representing this particular domain entity) in the database, this implies that a concurrent transaction has modified the domain entity.
When a version field is added to a domain class (by annotating a field with @Version), Hibernate will automatically increment the value of this field on a particular domain entity whenever it is updated. We can then leverage this feature to help prevent entities that were modified in a concurrent transaction from having their state reverted. In other words, a typical update operation is enhanced with a SQL condition to check the version field, such that updating the name property of an ArtEntity domain entity would become:
UPDATE artentity SET name = 'foo', version = 8 where id = 4 and version = 7;
Optimistic Locking is beneficial in that it does not pose any significant constraints that could limit scalability, such as database locks. However, this strategy will throw an exception if a version mismatch is detected, which means that application developers must re-attempt the transaction, while trying to reconcile the conflicting data.
When the potential for simultaneous modifications are more likely, you may want to consider leveraging Pessimistic Locking instead. Pessimistic Locking uses database locks, and therefore poses greater risk for scalability and database deadlock. The chief advantage of Pessimistic Locking is that it limits concurrent access or modification of domain entities, which can help maintain data consistency without complicating application code. Keep in mind, however, that the longer a pessimistic lock is held, the greater the impact to scalability.
Locking an entity is relatively simple in JPA 2.0. You can acquire a pessimistic lock when loading a particular entity. You can also explicitly lock an entity after it has already been loaded, by calling lock or refresh on the entityManager instance.
For example, to acquire a pessimistic write lock (which is an exclusive lock) while loading a particular ArtEntity instance, we could do the following:
ArtEntity artEntity = entityManager.find(ArtEntity.class, 7, LockModeType.PESSIMISTIC_WRITE)
If we had previously loaded an ArtEntity instance, and now wanted to acquire a pessimistic read lock (which represents a shared lock), we could use the following approach:
entityManager.lock(artEntity, LockModeType.PESSIMISTIC_READ)
While it is possible to obtain multiple, concurrent read locks, there can only be a single pessimistic write lock.
As amazing as it may sound, there are some solutions that aren't in Hibernate's repertoire. It's important to recognize those situations in which a requirement might be better solved by using a different strategy altogether. These scenarios aren't always that obvious, so having a solid understanding of what other options are available can be useful.
Consider providing search-like functionality in an application. A relational database is able to handle this functionality, but only to a point. If your application is required to provide search functionality that extends far beyond what a simple "SQL-like query" will accommodate, it is time to consider an alternate solution.
Users expect search features to be intelligent. For example, if you were attempting to search for "Spring Framework" and you inadvertently typed "Sprong Framework," you would probably expect the application to work around your error and return your intended results anyway. This type of feature is often referred to as fuzzy search, as it reduces the strictness of the match, allowing similarly spelled terms to be included. This concept can also be extended to allow for synonyms. For example, a search for "car" can also match entries containing "automobile."
Relational databases don't typically excel at finding groups of words within blocks of text, a feature often referred to as free-text search. Providing this kind of search functionality within a relational database would likely incur significant performance overhead as well as additional development time.
Finding text content that begins or ends with a particular word can be implemented using a like condition, such as the following:
List<ArtEntity> blueEntities = entityManager.createQuery( "select artEntities from ArtEntity artEntities where artEntities.description like 'blue%'" ).list();
Obviously, this query is a bit contrived, as we wouldn't likely have a hard-coded query, specifically one that filters items with a description field that starts with "blue," but it serves for demonstration purposes. While this query might be reasonably performant (since we can rely on the database index to quickly find a description that starts with an exact match of a particular word), we will begin to incur more significant performance penalties if we attempt to find those ArtEntities with a description containing a particular word or phrase. This sort of search operation will typically require an index scan or table scan, which can be taxing on the database.
Furthermore, we still don't have a strategy for determining the relevance of a particular match. If five description fields contain the word blue, how do we determine which match is more relevant? We could make the assumption that the more times the word blue appears within a particular description, the more relevant it is. However, implementing this solution with Hibernate alone will likely require a lot of extra coding, and we still have barely met the base expectations for a user's search requirements. What if we wanted to support fuzzy matching or handle synonyms?
The fundamental problem with using Hibernate alone to tackle search requirements is that a relational database is not designed to provide this type of functionality. However, this is exactly the sort of thing Apache Lucene—a powerful open source Java search framework—was intended to do.
Lucene is a performant and full-featured information retrieval (IR) library, providing a comprehensive API for indexing and searching operations. Indexing is a strategy used by both search engines and databases to allow content to be found as efficiently as possible. A Lucene index is not all that different from the index for this book. It provides a logical and systematic way to locate and access a particular piece of data.
At the center of Lucene's indexing API is the Document class. Similar to the concept of a database table, a Document is composed of Fields, each of which contains text data extracted from the original content intended to be indexed. Unlike a database, Lucene documents are denormalized. There is no concept of joining, as data relationships are not indicative of IR. Instead, you can think of documents as containers—a means for organizing content so that it can be effectively searched against later.
Each Field in a Lucene Document typically represents a particular component of the content you wish to search. For example, if you wanted to index your personal music library, you would likely define a document with fields for an audio track, the track's album, the track's artist, the file name for the track, your notes about the track, the album's release date, and so on. To assist with the indexing process, Lucene provides a set of Analyzers. An Analyzer helps to break down and filter the content for each particular field, extracting a stream of tokens. For instance, since it's reasonable that your notes on a particular album could contain several paragraphs of text, you would need to break down this content into words. You might then want to break down these words into their roots, allowing you to be able to find notes by using the word listen, even if a particular note actually contained the word listens or listening. This process is called stemming, and helps to break down words into their root forms. An analyzer might also filter out superfluous content, such as removing stop words, such as the and a.
The individual tokens that an analyzer extracts are known as terms. Terms are the foundational elements that comprise an Index, and therefore are also the primary component of a search query. Lucene uses an inverted index to optimize the manner in which content is found. An inverted index uses the tokens extracted in the analyzer step of the indexing process as the lookup keys for a particular piece of content. This sort of approach is more conducive to searching, as the emphasis for lookup is placed on the individual terms or words a user might want to search for, rather than the content itself. Additionally, Lucene is able to track the frequency of a particular token, its position in relation to other tokens, and its offset within the original content from which it was extracted. This metadata is extremely valuable for a host of search features.
Lucene provides a series of options to customize how a particular field is indexed. For instance, it might be more ideal for some fields to be tokenized, while others should have their content preserved in its original form. In the music library example, you would probably want to tokenize the notes field, since you would want to be able to search for a particular word or phrase contained in your notes. However, you would not want to tokenize the track's file name, as this data makes sense only as a complete, unmodified unit.
Lucene also allows you to specify whether the original content for a particular field is stored. For instance, while you might not want to tokenize a track's file name, you would definitely want to store this data. Then when a particular document is returned as part of a search result list, you could access the file name directly so that the application could work with this data (for instance, to play the track or locate it on your file system).
Lucene includes a powerful querying API, providing a flexible way to specify the fields and terms for which to search, along with the ability to define Boolean and grouping expressions.
The simplest Lucene query might look like the following:
cupcake
This would search for the term cupcake on the default field. The default field is typically specified in the QueryParser, a Lucene class used to parse a user-defined query expression into a Query instance.
More often, a Lucene query will target one or more fields, such as in the following example:
notes:cupcake AND album:Pepper
This will return all documents in which the word cupcake is contained in the notes field and the word Pepper is contained in the album field. It is also possible to define this query as follows:
+notes:cupcake +album:Pepper
As you can see, you can define Boolean AND expressions by using the + prefix or by using the AND keyword. In Lucene, a Boolean OR is the default, so you can simply specify multiple expressions together:
notes:cupcake album:Pepper
Or you can explicitly include the OR keyword:
notes:cupcake OR album:Pepper
If you want to insist that a search should not include a particular term, you can prefix it with a minus (-) character. For example, if you wanted to ensure that your search results did not contain any tracks played by the Beatles, you could use the following query:
notes:cupcake AND album:Pepper -artist:"The Beatles"
This query will look for a note containing the word cupcake and an album containing the word Pepper, but the track artist can't be The Beatles. Notice the quotes around "The Beatles" to indicate that the artist field must match the entire phrase. So, if the artist name was specified as just Beatles, you could still end up with a Beatles track in your search results. To prevent this scenario, you could just use Beatles, without the quotation marks.
But what if you wanted to ensure that a misspelled artist attribution on a track in your library wouldn't affect the intention of your searches? To address this problem, you can use a tilde (˜) character, which lets Lucene know that you want to allow a fuzzy match:
(track:"Fixing a Hole" OR track:"Hey Jude") AND artist:Beatles˜
This query expresses your intention for a fuzzy search on the artist field. Now, even if the artist attribution in your library is spelled as "Beetles," it will likely be included in your search results. Notice also the use of parentheses to group the first part of the query. This grouping specifies that the query should return tracks that match either title, provided they both are by the artist Beatles.
If you wanted to ensure that your results contain only tracks released within a particular date range, you could take advantage of Lucene's date-range querying capability:
artist:Rol* AND releaseDate:[5/18/1975 TO 5/18/2010]
This query will find any track with a release date between May 18, 1975, and May 18, 2010, as long as the artist name starts with Rol. The wildcard modifier (*) indicates that you want to match an artist given the specified prefix.
The preceding query examples should give you a sense of some of the things possible with Lucene query expressions. You will learn shortly how to parse these expressions into a Lucene Query. Of course, it's also possible to define queries programmatically, and doing so can often provide you with more flexibility. However, defining an expression using some of the conventions shown in these examples can give your design more clarity.
Hibernate Search is a framework that extends Hibernate in order to provide seamless integration with Apache Lucene. It is possible for developers to integrate Lucene into their applications directly. However, if your goal is to index the data within your domain classes, then it is a nontrivial problem to make this integration work reliably such that changes made to your domain model are automatically reflected in your index. Additionally, it is important that updates to the Lucene index occur within the context of a Hibernate operation.
For example, imagine if a domain class was updated as part of a DAO method, and within this method, a call was made to Lucene to trigger an update to the Lucene index. While this setup may work, what would happen if the domain class update was made within the context of a transaction, and suddenly the transaction was rolled back? Most likely, the database and the Lucene index would fall out of sync.
Hibernate Search attempts to solve these sort of problems, offering an implementation that integrates Lucene into the Hibernate life cycle and that respects the transactional boundaries to ensure the respective resources stay in sync.
Let's consider the search requirements of our image gallery application. Users will likely want to be able to find images by caption, author, title, or description, and possibly filter results by category or tag. We also want to display results in terms of relevance, not just sorted alphabetically or by date. What constitutes relevance is an important concern for search features, as ultimately, the success of search is based on how expediently users are able to find what they are looking for.
To begin integrating Hibernate Search into our art gallery application, we must first update our Maven pom.xml to include the necessary dependencies. This is easily accomplished by adding the following snippet to our pom.xml:
<!--Hibernate Search-->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search</artifactId>
<version>3.2.1.Final</version>
</dependency>Hibernate Search expects a few key configuration properties in order to define some of the basic defaults, such as the location of the Lucene index. These properties can be specified within the persistence.xml file. The following represents the key properties to set in order to bootstrap our Hibernate Search integration. The important new attributes are in bold.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="persistenceUnit" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
<property name="hibernate.cache.use_second_level_cache" value="true"/>
<property name="hibernate.cache.provider_class"
value="net.sf.ehcache.hibernate.SingletonEhCacheProvider"/>
<property name="hibernate.search.default.directory_provider"
value="org.hibernate.search.store.FSDirectoryProvider"/>
<property name="hibernate.search.default.indexBase" value="./lucene/indexes"/>
<property name="hibernate.search.default.batch.merge_factor" value="10"/>
<property name="hibernate.search.default.batch.max_buffered_docs" value="10"/>
</properties>
</persistence-unit>
</persistence>This configuration provides Hibernate Search with some of the key details required to get things rolling, such as which directory provider to use (a Lucene configuration that delineates the strategy for managing and storing the index) and where the index is located.
With the configuration out of the way, we need to design our Lucene index, specifying the fields within the Lucene document and defining how these fields map to the properties within each of our domain classes. Hibernate Search is flexible in this regard, and allows you to fine-tune the requirements for every field. However, following convention over configuration, the framework includes sensible defaults, so you need to deal with only special requirements.
By default, each domain class that is indexed will be mapped to its own index. Each domain class property will map to a Lucene field of the same name, unless you choose to override this default. It is also possible to define more than one field for a particular domain class property, which is useful if you need to use multiple indexing strategies for the same domain class property. For example, you might want to have one field that is not tokenized but stores the content in its original form, while another field tokenizes the content.
To map your domain class properties to a Lucene index, Hibernate Search offers a set of specialized annotations that complement the JPA annotations we used to define our Hibernate mappings. Let's take a look at the ArtEntity domain class and add Hibernate Search annotations to establish our Lucene mappings:
@Entity
@Indexed
@Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public class ArtEntity implements DomainObject {
private Long id;
private String title;
private String subTitle;
private String uploadedDate;
private String displayDate;
private Integer width;
private Integer height;
private String media;
private String description;
private String caption;
private ArtData_Gallery galleryPicture;
private ArtData_Storage storagePicture;
private ArtData_Thumbnail thumbnailPicture;
private Boolean isGeneralViewable;
private Boolean isPrivilegeViewable; // can be seen by logged-in non-administrators (special visitors)
private Set<Category> categories = new HashSet<Category>();
private Set<Comment> comments = new HashSet<Comment>();
private Integer version;
public ArtEntity() {
}@Id
@GeneratedValue
@DocumentId
public final Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn()
public ArtData_Gallery getGalleryPicture() {
return galleryPicture;
}
public void setGalleryPicture(ArtData_Gallery galleryPicture) {
this.galleryPicture = galleryPicture;
}
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn()
public ArtData_Storage getStoragePicture() {
return storagePicture;
}
public void setStoragePicture(ArtData_Storage storagePicture) {
this.storagePicture = storagePicture;
}
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn()
public ArtData_Thumbnail getThumbnailPicture() {
return thumbnailPicture;
}
public void setThumbnailPicture(ArtData_Thumbnail thumbnailPicture) {
this.thumbnailPicture = thumbnailPicture;
}
@Field(index = Index.TOKENIZED, store=Store.YES)
@Boost(2.0f)
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}@Field(index = Index.TOKENIZED, store=Store.YES)
public String getSubTitle() {
return subTitle;
}
public void setSubTitle(String subTitle) {
this.subTitle = subTitle;
}
@Field(index = Index.TOKENIZED, store=Store.NO)
public String getMedia() {
return media;
}
public void setMedia(String media) {
this.media = media;
}
@Field(index = Index.UN_TOKENIZED, store=Store.YES)
@DateBridge(resolution = Resolution.MINUTE)
public String getUploadedDate() {
return uploadedDate;
}
public void setUploadedDate(String uploadedDate) {
this.uploadedDate = uploadedDate;
}
public String getDisplayDate() {
return displayDate;
}
public void setDisplayDate(String displayDate) {
this.displayDate = displayDate;
}
@Field(index = Index.UN_TOKENIZED, store=Store.YES)
public Integer getWidth() {
return width;
}
public void setWidth(Integer width) {
this.width = width;
}
@Field(index = Index.UN_TOKENIZED, store=Store.YES)
public Integer getHeight() {
return height;
}public void setHeight(Integer height) {
this.height = height;
}
@Field(index = Index.TOKENIZED, store=Store.NO)
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
@Field(index = Index.TOKENIZED, store=Store.NO)
public String getCaption() {
return caption;
}
public void setCaption(String caption) {
this.caption = caption;
}
public Boolean getGeneralViewable() {
return isGeneralViewable;
}
public void setGeneralViewable(Boolean generalViewable) {
isGeneralViewable = generalViewable;
}
public Boolean getPrivilegeViewable() {
return isPrivilegeViewable;
}
public void setPrivilegeViewable(Boolean privilegeViewable) {
isPrivilegeViewable = privilegeViewable;
}
@ContainedIn
@ManyToMany(mappedBy = "artEntities")
public Set<Category> getCategories() {
return categories;
}
public void setCategories(Set<Category> categories) {
this.categories = categories;
}
@ContainedIn
@OneToMany(orphanRemoval = true, cascade = { javax.persistence.CascadeType.ALL })
@Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)public Set<Comment> getComments() {
return comments;
}
public void setComments(Set<Comment> comments) {
this.comments = comments;
}
}The Hibernate Search annotations are fairly intuitive, given the Lucene concepts introduced earlier. Let's examine the additions to this class, one at a time.
First, we need to annotate a class with the @Indexed annotation in order for it to be considered for indexing. Next, Hibernate Search requires that the identifier of a domain class be annotated with @DocumentId. The document ID is used by Hibernate Search to bridge the Lucene and Hibernate worlds. In each index, Lucene stores a Hibernate entity's full class name as well as its identifier. Together, they form the basis for querying in Hibernate Search, and allow a list of documents returned by a Lucene query to be exchanged for a list of active Hibernate entities.
Unless a domain class property is annotated with the @Field annotation, it will not be indexed. The @Field annotation specifies that a particular domain class property be included in the Lucene index. The annotation takes a few parameters, including the ability to override the name of the field. Of most importance, however, are the index and store attributes. These parameters tell Lucene how to configure the field.
As noted earlier, a field can be tokenized, which will extract the contents of a particular property into a stream of tokens, leveraging a particular analyzer to filter out superfluous words, perform stemming, insert synonyms, and possibly perform a range of other options, depending on the analyzer used. A field can also be stored, which means that the original content will be inserted into the Lucene index. Storing a field can increase the size of the index, so it is rarely a good idea for large blocks of text. However, fields containing data that may need to be displayed by the application—such as a title, file name, or a business identifier—should be marked as stored. Let's look at a few examples:
In our
ArtEntitydomain class, we have specified that thetitleproperty be stored and tokenized:@Field(index = Index.TOKENIZED, store=Store.YES) @Boost(2.0f) public String getTitle() { return title; }We have specified that the
widthproperty be left untokenized, but still stored:@Field(index = Index.UN_TOKENIZED, store=Store.YES) public Integer getWidth() { return width; }We have set the
descriptionproperty to be tokenized but not stored:@Field(index = Index.TOKENIZED, store=Store.NO) public String getDescription() { return description; }
You probably also noticed the use of the @DateBridge annotation. Since Lucene typically only manages text within its index, Hibernate Search includes a bridge strategy as way to convert nontext data into a String (and possibly back again). Hibernate Search will use the appropriate built-in bridges for mapping fields such as integers and longs, but for more complex data types, you can leverage a custom bridge or use one of the bridges provided by the framework. For example, we can map our uploadedDate property in the following way:
@Field(index = Index.UN_TOKENIZED, store=Store.YES)
@DateBridge(resolution = Resolution.MINUTE)
public Date getUploadedDate() {
return uploadedDate;
}This mapping parameterizes the @DateBridge so that the date value is converted to text that can be lexicographically sorted. The date is stored within the Lucene index has a resolution of a minute. For performance reasons, you generally want to use the largest resolution setting your application can support (for instance, prefer a resolution of Minute over Second, or better yet, Day rather than Minute or Hour).
The @Boost annotation can be used to boost the weighting of a particular field within the Lucene index. For instance, to have the title field be twice as relevant as the description field, we can specify a boost factor of 2.0:
@Field(index = Index.TOKENIZED, store=Store.YES)
@Boost(2.0f)
public String getTitle() {
return title;
}It is also possible to specify boost factors within a query, but in cases where you want a consistent boost weighting, the @Boost annotation can come in handy.
As we mentioned earlier, a Lucene index is denormalized, offering no concept of implicit relationships as found in typical relational databases. To translate some of the Hibernate association mappings into the world of Lucene, Hibernate Search offers the @IndexEmbedded annotation. @IndexEmbedded tells Hibernate Search to embed a particular association into the owning class. However, because Lucene is inherently denormalized, Hibernate Search must be made aware any time the embedded entity changes. To help track these changes, Hibernate Search provides the @ContainedIn annotation, to mark the other side of an embedded association.
Now that you have a clearer understanding of how to annotate a domain class for indexing, let's examine the indexing and search processes.
One of the primary advantages of Hibernate Search is the seamlessness of the integration between Hibernate and Lucene. Hibernate Search relies on Hibernate events to trigger the appropriate changes to the Lucene index as persistent state changes are made to your domain model.
In Chapter 4, we covered the JPA life cycle. In adhering to the JPA life cycle, Hibernate offers a fine-grained event model, broadcasting specific events based on persistent state changes to a domain object. For example, when a domain class instance is persisted, Hibernate will propagate the appropriate event. Similarly, Hibernate will broadcast numerous other events, such as delete and update notifications, providing a means to listen and respond to changes to your domain model. Event listeners are an effective design pattern for defining application behavior in a decoupled way, and Hibernate Search is able to plug in to domain life-cycle events through this powerful mechanism.
If you are building an application from scratch and are starting with an empty database, then the process of populating the Lucene index is straightforward. When your domain object is first persisted to the database, such as through entityManager.save(artEntity), Hibernate Search will catch the life-cycle event and add the specified artEntity to the Lucene index. By default, each domain class will have its own index, and all the appropriate properties will be added to the index according to the rules specified through the Hibernate Search annotations. Because Hibernate Search takes care of keeping your database and your Lucene index in sync, the integration between the two frameworks is intuitive and simple.
However, there are circumstances under which you may need to index your domain objects more explicitly. For instance, if you are integrating Hibernate Search into an existing application or working with a legacy database, you will need to find a way to retrofit your existing data into the Lucene index. Hibernate Search provides a more direct means of indexing your domain model as well.
Hibernate Search provides an extended version of Hibernate's EntityManager, enhancing these core framework classes with search-specific functionality. The enhanced version of the JPA EntityManager is the FullTextEntityManager. Accessing this search-capable EntityManager is fairly seamless:
import org.hibernate.search.jpa.Search; FullTextEntityManager fullTextEntityManager = Search.getFullTextEntityManager(entityManager);
The next step is to perform the indexing. Here is how to explicitly index a single entity:
public void indexEntity(T object) {
FullTextEntityManager fullTextEntityManager = Search.getFullTextEntityManager(entityManager);
fullTextEntityManager.index(object);
}This method is intended to be added to your GenericDaoJpa class, in order to provide a generic means to index a domain class. If you want to implement a way to index all the entities of a particular type currently stored in the database, you could define the following method on your GenericDaoJpa implementation:
public void indexAllItems() {
FullTextEntityManager fullTextEntityManager = Search.getFullTextEntityManager(entityManager);
List results = fullTextEntityManager.createQuery("from " +
type.getCanonicalName()).getResultList();int counter = 0, numItemsInGroup = 10;
Iterator resultsIt = results.iterator();
while (resultsIt.hasNext()) {
fullTextEntityManager.index(resultsIt.next());
if (counter++ % numItemsInGroup == 0) {
fullTextEntityManager.flushToIndexes();
fullTextEntityManager.clear();
}
}
}In this method, we use the FullTextEntityManager to perform a standard JPA query, which simply lists all of the entities of the parameterized type. We then iterate through the results, indexing each entity. However, every ten index invocations, we call fullTextEntityManager.flushToIndexes(). This flushes the queued changes to the Lucene index, without waiting for the Hibernate Search batch threshold to be reached. Next, we call fullTextEntityManager.clear(), which clears out the JPA persistenceContext. This may not always be necessary, but if you are iterating through a large dataset, you want to reduce your memory footprint as much as possible.
Now let's put together all the concepts we've covered in this chapter to offer a basic search feature that allows end users to search across several of the ArtEntity fields using the specified search terms. Here is an example of how this can be implemented:
public List<ArtEntity> searchForArtEntitiesByTerms(String searchTerms,
Integer startIndex,
Integer maxResults) {
FullTextEntityManager fullTextEntityManager =
Search.getFullTextEntityManager(entityManager);
String[] fieldsToMatch = new String[] {"title", "subTitle", "media", "description", "caption"};
QueryParser parser = new MultiFieldQueryParser(Version.LUCENE_29, fieldsToMatch,
new StandardAnalyzer(Version.LUCENE_29));
org.apache.lucene.search.Query luceneQuery = null;
try {
luceneQuery = parser.parse(searchTerms);
} catch (ParseException e) {
log.error("Error parsing lucene query: " + searchTerms);
}
Query jpaQuery = fullTextEntityManager.createFullTextQuery(luceneQuery, ArtEntity.class);
if (startIndex != null && maxResults != null) {
jpaQuery.setFirstResult(startIndex);jpaQuery.setMaxResults(maxResults);
}
List<ArtEntity> artEntities = jpaQuery.getResultList();
return artEntities;
}In order to search across the ArtEntity title, subtitle, media, description, and caption fields, we use a special Lucene query parser called the MultiFieldQueryParser. This query parser takes an array of field names, so that all the user-specified search terms can be equally applied to each of the fields. In other words, using the MultiFieldQueryParser in this way is equivalent to the following Lucene query, assuming the user searched for "test":
title: test OR subtitle: test OR media: test OR description:test OR caption:test
After parsing the Lucene query using our MultiFieldQueryParser and the specified searchTerms, we invoke the createFullTextQuery method on our fullTextEntityManager reference. This method returns a standard javax.persistence.Query instance, which we can use in the same manner as any JPA query. We limit our result set using setFirstResult and setMaxResults (if these parameters are specified), and then call getResultList() to return a List of ArtEntity instances.
One of the really interesting details here is that even though we are invoking a Lucene query, we are working with entities at the JPA level. This means that we don't need to worry about correlating the results of a Lucene query to load a series of JPA entities. Hibernate Search takes care of these details for us, providing a very powerful abstraction over Lucene to simulate a completely Hibernate or JPA-centric world.
In this chapter, we've demonstrated how to integrate and extend Hibernate in order to implement more advanced application features. We discussed some of the challenges with exposing RESTful web services on Hibernate-powered applications, and how to simplify a serialization or marshaling strategy. We examined Spring 3's new MVC capabilities, as well as its OXM abstraction for providing object-to-XML marshaling.
We also discussed the DTO pattern, and how this strategy can reduce the complexities of serializing your domain model. However, translating a domain class to a DTO class (and back again) can be a source of defects and maintenance problems. One solution is to use a framework like Dozer. Dozer handles the mapping between two different classes, using convention over configuration and mapping configuration files. By abstracting these translation details to a specialized framework, the complexities inherent in a DTO mapping layer are significantly reduced.
Providing full-text search capability is a very important and common requirement for many applications. Lucene is an open source Java framework that offers powerful indexing and search capability, but can be difficult to integrate into an application without requiring significant glue code to sync changes to the domain model with the Lucene index. Hibernate Search is a framework that bridges the gap between these two excellent frameworks, enhancing key Hibernate framework classes to offer Lucene querying and indexing capabilities. Hibernate Search allows developers to execute Lucene queries within the realm of Hibernate, so that search results return standard Hibernate entities.
Spring and Hibernate are amazing open source frameworks. However, building upon the foundations of these tools is the key to successful application development. Learning best practices for integrating your persistence tier with other frameworks is as important as learning the persistence framework itself.