
Much like Spring, Hibernate changed the software development landscape when it first appeared on the scene. The timing was ideal. Developers were frustrated by the complexity of J2EE and the overhead associated with using EJB for persistence in particular. Hibernate solves the persistence problem through simplicity and clean, thoughtful design.
Also like Spring, Hibernate relies heavily on POJOs. Other ORM frameworks force developers to muddy their domain model with restrictive and rigid requirements, such as alternate and parent classes, as well as Data Transfer Objects (DTOs). Hibernate enables persistence with little reliance or coupling to Hibernate. Spring helps to decouple Hibernate further through several classes of its own, which serve to simplify and standardize integration and persistence operations. Additionally, Spring provides a framework-agnostic solution for implementing transactional behavior in a standardized, declarative fashion, without requiring Hibernate-specific code.
Looking back, it is easy to see how Spring and Hibernate were instrumental to each other's success. With philosophies that stressed lightweight methodologies, simplicity, and code cleanliness, the Hibernate-Spring duo ushered in a new age for enterprise Java applications and persistence. This mutual success had a dramatic impact on the Java community, and was the catalyst to numerous changes that embraced a lighter-weight approach to application development.
There is often a great deal of confusion about the various persistence options in the Java ecosystem. What's the difference between EJB 3, JPA, JDO, and Hibernate anyway? We'll attempt to demystify these things in this chapter by going over a bit of history and defining some terms. With that out of the way, we'll demonstrate how to integrate Hibernate into a Spring application.
JDBC was included by Sun Microsystems as part of JDK 1.1 in 1997. JDBC is a low-level API oriented toward relational databases. It provides methods for querying and updating a database. JDBC provides a great set of tools, but all of the heavy lifting is left entirely to the developer, who must write SQL, map query results to domain objects, manage connections and transactions, and so on. Most other persistence frameworks are built as abstractions on top of JDBC to ease this developer burden.
Beginning in 2000, version 3.0 of the JDBC specification was managed as a part of the Java Community Process (JCP). The JCP was created in 1998 as a mechanism for interested parties to participate in shaping the future directions of the Java platform. The JCP revolves around Java Specification Requests (JSRs), which are formal documents outlining proposed additions or changes to the Java platform. Each JSR has one or more individuals playing the role of specification lead and a team of members referred to as the expert group, who collaborate to hammer out the specification. A final JSR also includes a reference implementation.
This distinction between a specification and an implementation is one of the primary sources of confusion among developers when discussing the various persistence options available. For example, JPA is a specification, and Hibernate is just one of many projects that provide an implementation of the JPA specification. Other implementations of the JPA specification include OpenJPA, DataNucleus, and the reference implementation, EclipseLink. But we're getting ahead of ourselves. Let's walk through the origins of some of these specifications and implementations.
In the late 1990s and early 2000s, the leading technology for developing large-scale applications in Java was EJB. Originally conceived by IBM in 1997, the EJB 1.0 and 1.1 specifications were adopted by Sun in 1999. From there, EJB was enhanced through the JCP. JSR 19 served as the incubator for EJB 2.0, which was finalized in 2001. The EJB 2.0 specification became a major component in Sun's Java 2 Platform, Enterprise Edition (a.k.a J2EE) reference implementation.
There's no question that the problems that EJB set out to solve, including enabling transactional integrity over distributed applications, remote procedure calls (RPC), and ORM, are complex, but EJB quickly earned a reputation for being more trouble than it was worth. The EJB 1.0, 1.1, and 2.0 specifications were marred by the complexities of checked exceptions, required interfaces, and heavy use of abstract classes. Most applications just didn't require the heft associated with EJB 1 and 2. Against that backdrop, there was a huge opportunity for competition and innovation.
The first official attempt to create a lightweight abstraction layer on top of JDBC by the JCP was JSR 12: Java Data Objects (JDO). The expert group behind JDO set out in 1999 to define a standard way to store Java objects persistently in transactional datastores. In addition, it defined a means for translating data from a relational database into Java objects and a standard way to define the transactional semantics associated with those objects. By the time the specification was finalized in 2002, JDO had evolved into a POJO-based API that was datastore-agnostic. This meant that you could use JDO with many different datastores, ranging from a relational database management system (RDBMS) to a file system, or even with an object-oriented database (OODB). Interestingly, the major application server vendors did not embrace JDO 1.0, so it never took off.
Between JDO and EJB, there were now two competing standards for managing persistence, neither of which were able to break through and win over developers. That left the door open for commercial players and open source frameworks. Hibernate is usually the ORM framework that people think of as replacing EJB 2.0, but another major player actually came first.
An ORM by the name of TopLink was originally developed by The Object People for the Smalltalk programming language. It was ported to Java and added to the company's product line by 1998. TopLink was eventually acquired by Oracle in 2002. TopLink was an impressive framework, and its features played a major role in shaping the persistence specifications that have since emerged in the Java world. As a fringe commercial project, TopLink never saw the level of adoption enjoyed by EJB, which was heavily backed by the application server vendors like IBM and BEA; nor was it able to really compete with the lightweight open source frameworks that emerged, such as Hibernate.
Gavin King set out to build Hibernate in 2001 to provide an alternative to suffering through the well-known problems associated with EJB 2 entity beans. He felt that he was spending more time thinking about persistence than the business problems of his clients. Hibernate was intended to enhance productivity and enable developers to focus more on object modeling, and to simplify the implementation of persistence logic. Hibernate 1.0 was released in 2002, Hibernate 2.0 was released in 2003, and Hibernate 3.0 was released in 2005. Throughout that entire period, Hibernate gained a huge amount of momentum as a free, POJO-based ORM that was well documented and very approachable for developers. Hibernate was able to deliver a means to develop enterprise applications that was practical, simple, elegant, and open source.
Throughout the first five years of Hibernate's existence, it did not adhere to any specification, and it wasn't a part of any standards process. Hibernate was just an open source project that you could use to solve real problems and get things done. During this time, many key players, including Gavin King himself, came together to begin working on JSR 220: Enterprise JavaBeans 3.0. Their mission was to create a new standard that remedied the pain points associated with EJBs from a developer's point of view. As the expert group worked through the EJB 3.0 specification, it was determined that the persistence component for interacting with RDBMSs should be broken off into its own API. The Java Persistence API (JPA) was born, building on many of the core concepts that had already been implemented and proven in the field by ORMs like TopLink and Hibernate. As a part of the JSR 220 expert group, Oracle provided the reference implementation of JPA 1.0 with its TopLink product. JSR 220 was finalized in 2006, and EJB 3 played a central role in Sun's definition of Java Enterprise Edition 5, or JEE 5.
Note
Please pay attention to the change in notation from J2EE to JEE. J2EE is now a legacy designation for the Enterprise Edition of Java. It's time to fix your résumé! s/J2EE/JEE/
This evolution played out perfectly for JPA. JPA 1.0 was a huge milestone for persistence in Java. However, many features that were essential for developers already using tools like Hibernate didn't make the cut due to time constraints. JPA 2.0 added many important features, including the Criteria API, cache APIs, and enhancements to the Java Persistence Query Language (JPQL), JPA's object-oriented query language. The JPA 2.0 standard was finalized in December 2009 as a new, stand-alone JSR that was targeted for inclusion in the Java EE 6 specification. Oracle donated the source code and development resources for TopLink to Sun in order to create the EclipseLink project. EclipseLink went on to become the reference implementation for JPA 2.0. Hibernate 3.5 was released in the spring of 2010 with full support for JSR 317: JPA 2.0.
That's a long and sordid history, but things have worked out quite nicely. JPA now encompasses most of the functionality that you need for developing large-scale enterprise Java applications.
Now that we've talked about the standards, let's look at where Hibernate fits in and dispel a few common misconceptions.
First of all, Hibernate 3 is not EJB 3 and vice versa. EJB 3 is a specification to provide a distributed, container-managed, server-side component architecture. EJB 3 encapsulates several distinct specifications to facilitate many things, including distributed transaction management, concurrency control, messaging, web services, and security—just to name a few. The EJB 3 specification assumes persistence handling can be delegated to a JPA provider.
Secondly, Hibernate is not JPA. Rather, Hibernate is one of many frameworks that provide a standards-compliant implementation of JPA. The first release of Hibernate to support JPA 1.0 was Hibernate 3.2, which became generally available in the fall of 2006.
There are often specialized features provided by frameworks like Hibernate that fall outside the JPA specification. As such, Hibernate can be thought of as a superset of JPA. On one end of the spectrum, Hibernate's architecture allows you to use Hibernate Core without using any parts of the JPA specification at all. On the polar opposite end of the spectrum, you can strictly use only the pieces of Hibernate that adhere to the JPA specification. Strict adherence to the JPA specification ensures true frictionless portability to other JPA implementations like Apache's OpenJPA project.
When using Hibernate, we recommend that developers stick to the JPA specification as closely as possible, but don't drive yourself crazy. Because open source projects tend to evolve at a much more rapid pace than the JCP, frameworks like Hibernate will offer solutions to problems not addressed by the standards process. If these custom offerings ease developer pain, please, please be pragmatic and take advantage of them! This is part of the beauty of the standards process—implementers of the various specifications are free to innovate, and the best, most successful ideas are likely to be incorporated into future revisions of the specification.
The JPA specification defines a set of annotations that can be applied to domain classes in order to map objects to database tables and member variables to columns. JPA also features a SQL-like language called JPQL, which can query the database with an object-oriented flavor. To access your database-mapped domain model, or to execute JPQL queries, you use javax.persistence.EntityManager.
Prior to JPA, Hibernate applications revolved around using Hibernate's SessionFactory and Session interfaces. Simply speaking, Hibernate's SessionFactory is aware of global configuration details, while the Session scope is limited to the current transaction. The JPA EntityManager serves as a cross between Hibernate's SessionFactory and Session; therefore, it is aware of both your database connection configuration and the transaction context. In this chapter, you'll learn a bit about JPQL, EntityManager, and how they interact with Spring, but mostly, you'll learn how to go about setting up an application to use Hibernate's implementation of the JPA 2.0 specification.
Figure 4-1 outlines the four key interfaces in any JPA application. The EntityManagerFactory represents the configuration for a database in your application. You would typically define one EntityManagerFactory per datastore. The EntityManagerFactory is used to create multiple EntityManager instances.
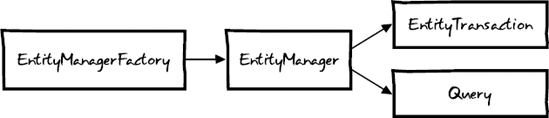
Each EntityManager instance is analogous to a database connection. In a multithreaded web application, each thread will have its own EntityManager.
Note
By default, all Spring objects are singletons. EntityManager is no different, but it is still thread-safe and knows about transactional boundaries. Spring passes in a shared proxy EntityManager, which delegates to a thread-bound instance of the EntityManager that knows all about the context of the request (including transaction boundaries).
Each EntityManager has a single EntityTransaction, which is required for persisting changes to the underlying database. Finally, the EntityManager serves as a factory for generating Query classes. Classes that implement the Query interface are needed for executing queries against the database.
The EntityManagerFactory is relevant only when starting up an application, and we'll show you how that is configured in a Spring application. Querying will be covered in more depth in Chapter 6, and transaction management will be discussed in Chapter 7. As you'll see in this chapter, the EntityManager interface is the interface that you tend to interact with the most.
Note
Since JPA is intended to be used in both heavyweight and lightweight containers, there are many configuration options. For example, you can use an EJB container to configure JPA, and then expose the container's EntityManager for Spring to access via JNDI. Alternatively, you can configure JPA directly within Spring using one of the many existing JPA implementations. One significant difference is the need (or lack thereof) of load-time weaving, which is the type of bytecode manipulation required for AOP. Load-time weaving is needed for creating transactionally aware JPA EntityManager and Entity objects that can perform lazy-loading. EJB servers have their own load-time weaving mechanism, and so does Spring. A single EntityManager can handle this type of functionality only through the support of the level of indirection that a proxy can provide. The Hibernate JPA implementation is one of the frameworks that doesn't require load-time weaving, so it allows you to get up and running in a JPA environment as quickly as possible.
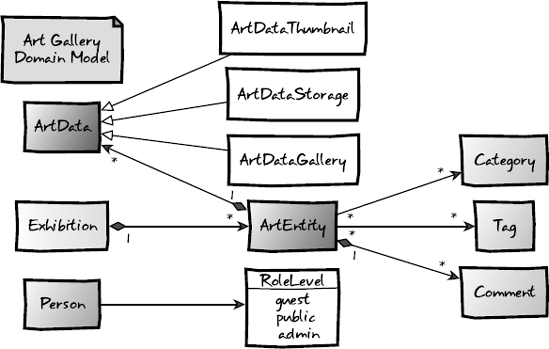
Now it's time to get back to building our art gallery application. The core thing that we must represent in an art gallery application is an entity for the works of art. In the Figure 4-2, you'll see that an ArtEntity class represents the artwork. In our gallery, we will allow gallery curators to associate ArtEntity entities to Category entities and allow the general public to apply Tag and Comment entities. These ArtEntity entities are organized into Exhibition entities for public display, and we're capturing all of the metadata for a given work of art in a polymorphic representation called ArtData. We also define a Person type to represent all users of the application. These Person entities are qualified by an enum representing the possible system roles they may take on.
JPA allows us to specify how a Java class is mapped to the database via annotations. The most important annotation is the @Entity annotation.
Adding a JPA @Entity annotation to a POJO makes it a persistable object! Well not quite—you still need to add an @Id somewhere and, ideally, a @Version field, but it's just that simple.
package com.prospringhibernate.gallery.domain;
import javax.persistence.Id;
import javax.persistence.Entity;
import javax.persistence.Version;
import javax.persistence.GeneratedValue;
@Entity
public class Person implements Serializable, DomainObject {
private Long id;
private Integer version;
@Id
@GeneratedValue
public final Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Version
public Integer getVersion() {
return version;
}
public void setVersion(Integer version) {
this.version = version;
}
// getters, setters and fields omitted
}Note
We've included all of the requisite import statements in the code listings here to help you see where the various annotations are coming from. Annotations are great for eliminating XML, but as the number of annotations on a given class or method grows, they can become a bit hard to read at times. Anything in the javax.persistence package is explicitly provided by JPA.
Unless told otherwise, the JPA implementation will employ convention over configuration and map this bean to a Person table. The @GeneratedValue JPA annotation tells Hibernate to use an autogenerated id column. Hibernate will choose the best ID-generation strategy for the specific database you're using. Hibernate is also smart enough to determine the right data type for each database column based on the Java primitive type or enumeration used for each member variable. You can customize these field mappings further through the use of the @Basic, @Enumerated, @Temporal, and @Lob annotations. Every member of the entity is assumed to be persistent unless it is static or annotated as @Transient. We'll talk more about the convention over configuration concept and Hibernate annotations in Chapter 5.
The implements Serializable that you see in the Person class isn't strictly necessary as far as the JPA specification is concerned. However, it is needed if you're going to use caching or EJB remoting, both of which require objects to be Serializable. Caching is a key component in achieving optimal performance in any JPA application, as you'll learn in Chapter 9, so implementing the Serializable interface is a good habit to adopt.
That's all you need to do from the POJO side, but an @Entity-annotated POJO doesn't do anything on its own. We need to, at the very least, provide code for basic CRUD operations. For now, we're going to embrace the DAO pattern. We'll explore coding in a more domain-centric style with the Active Record pattern when we cover Grails and Roo in Chapters 11 and 12, respectively.
Let's create a DAO that saves and finds a Person entity. We're going to get fancy with our class hierarchy using generics so that we can abstract away the boilerplate CRUD operations that would otherwise be repeated over and over again by each DAO in our application.
In the pseudo-UML in Figure 4-3, notice that our Person domain object implements an interface called DomainObject. That DomainObject interface is an empty interface that is used by our GenericDao interface as well as our GenericDaoJpa concrete class to bind our domain objects in a generic way. This structure enables us to push common methods into the GenericDaoJpa class, which in turn, allows us to keep our Hibernate DAOs succinct.
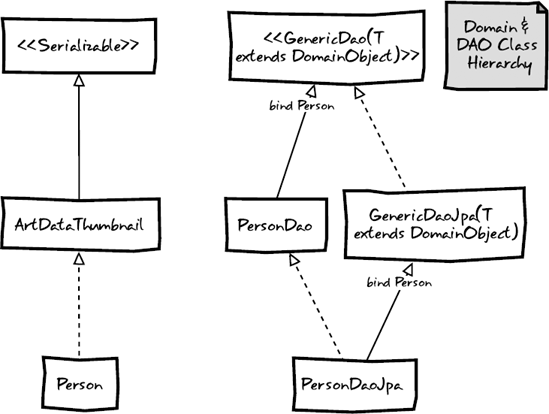
In the diagram in Figure 4-3, solid lines represent inheritance, and interface inheritance is depicted with dotted lines. The key usages of Java generics are highlighted by the "bind Person" annotations. Generics in Java allow a type or method to operate on objects of various types while providing compile-time type-safety.
Let's see how this plays out in actual code. The first class we'll tackle is GenericDao:
package com.prospringhibernate.gallery.dao;
import java.util.List;
import com.prospringhibernate.gallery.domain.DomainObject;
public interface GenericDao<T extends DomainObject> {
public T get(Long id);
public List<T> getAll();
public void save(T object);
public void delete(T object);
}Each generic type variable is represented as T. As you can see, we've defined four basic methods in this interface that are essential when managing persistent objects. The delete method will remove a given entity from the database. The save method allows us to insert a new row or update an existing row in the database based on the contents of the entity. The two basic getters provide a means for reading in any entity T, which uses our DomainObject interface.
In the code that follows, we implement those methods on our concrete GenericDaoJpa class using JPA's EntityManager.
package com.prospringhibernate.gallery.dao.hibernate;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import org.springframework.transaction.annotation.Transactional;
import com.prospringhibernate.gallery.dao.GenericDao;
import com.prospringhibernate.gallery.domain.DomainObject;
public class GenericDaoJpa<T extends DomainObject> implements GenericDao<T> {
private Class<T> type;
protected EntityManager entityManager;
@PersistenceContext
public void setEntityManager(EntityManager entityManager) {
this.entityManager = entityManager;
}
public GenericDaoJpa(Class<T> type) {
super();
this.type = type;
}
@Transactional(readOnly=true)
public T get(Long id) {
if (id == null) {
return null;
} else {
return entityManager.find(type, id);
}
}
@Transactional(readOnly=true)
public List<T> getAll() {
return entityManager.createQuery(
"select o from " + type.getName() + "o"
).getResultList();
}public void save(T object) {
entityManager.persist(object);
}
public void remove(T object) {
entityManager.remove(object);
}
}As we've discussed, EntityManager is the core mechanism for interacting with JPA. It performs data-access operations in a transaction-aware manner. With it, the GenericDaoJpa class can perform basic CRUD tasks: finding single or multiple instances of the class, as well as saving, updating, and deleting an instance.
You'll notice that the SELECT clause looks like it was written in SQL, but it wasn't. It's JPQL, which is specifically geared toward querying for JPA Entity objects, rather than tables.
This class uses the @Transactional and @PersistenceContext annotations. The @Transactional annotation is provided by Spring. It lets Spring know that this class requires transaction management, as well as the details of which types of operations are being performed within each method. You can add @Transactional at the class level to tell Spring that each and every method requires a transaction. You may also use the @Transactional annotation at the method level. If you annotate at both the class level and method level, the method level annotation will take precedence. We'll cover transaction semantics in depth in Chapter 7.
@PersistenceContext is a JPA annotation that tells Spring that it needs to inject the proxied EntityManager via autowiring. @PersistenceContext can be used on member variables, but the preferred approach is to use it on a setter as shown here.
The next interface is PersonDao. This interface extends GenericDao bound by the type Person and declares the methods that are specific to interacting with our Person entity in our DAO. Or class hierarchy has allowed us to simplify the following code to the point that we just need to define method signatures that are uniquely applicable to our Person entity.
package com.prospringhibernate.gallery.dao;
import com.prospringhibernate.gallery.domain.Person;
import com.prospringhibernate.gallery.exception.AuthenticationException;
import com.prospringhibernate.gallery.exception.EntityNotFoundException;
public interface PersonDao extends GenericDao<Person> {
public Person getPersonByUsername(String username) throws EntityNotFoundException;
public Person authenticatePerson(String username, String password)
throws AuthenticationException;
}And finally, here's the implementation for the PersonDaoJpa class, which implements PersonDao and extends GenericDaoJpa bound with our Person entity:
package com.prospringhibernate.gallery.dao.hibernate;
import java.util.List;
import javax.persistence.Query;
import javax.persistence.EntityManager;
import org.springframework.dao.DataAccessException;
import org.springframework.stereotype.Repository;
import com.prospringhibernate.gallery.domain.Person;
import com.prospringhibernate.gallery.dao.PersonDao;
import com.prospringhibernate.gallery.exception.AuthenticationException;
import com.prospringhibernate.gallery.exception.EntityNotFoundException;
public class PersonDaoJpa extends GenericDaoJpa<Person> implements PersonDao {
public PersonDaoJpa () {
super(Person.class);
}
public Person authenticatePerson(String username, String password)
throws DataAccessException, AuthenticationException {
List<Person> results = null;
Query query = entityManager.createQuery(
"from Person as p where p.username = :username and p.password = :password"
);
query.setParameter("username", username);
query.setParameter("password", password);
results = query.getResultList();
if (results == null || results.size() <= 0) {
throw new AuthenticationException("No users found");
} else {
return results.get(0);
}
}
public Person getPersonByUsername(String username)
throws DataAccessException, EntityNotFoundException {
List<Person> results = null;
Query query = entityManager.createQuery(
"from Person as p where p.username = :username"
);
query.setParameter("username", username);
results = query.getResultList();
if (results == null || results.size() <= 0) {throw new EntityNotFoundException(username + " not found");
} else {
return results.get(0);
}
}
}The Spring @Repository annotation has three primary purposes in this example:
It tells Spring that this class can be imported via classpath scanning.
It's a marker for Spring to know that this class requires DAO-specific
RuntimeExceptionhandling.We specify the name to be used in the Spring context to represent this class. By specifying that the DAO should be recognized as
personDao, via@Repository("personDao"), we can refer to this DAO elsewhere in our Spring configuration simply aspersonDao, rather thanpersonDaoJpa. This allows us to change the underlying DAO implementation to something else with far less friction.
Using the @Repository annotation allows us to quickly group all DAOs through IDE searching, and it also lets a reader know at a glance that this class is a DAO.
Because of our use of generics, the code that remains in the PersonDaoJpa implementation is nice and short, and relevant only to the Person domain class. Developers are often intimidated by generics, but they can help you avoid doing a lot of rote, repetitive work that adds no value.
Let's take a closer look at how JPA actually handles our Person entity internally. Figure 4-4 highlights the various states that an entity might be in, some of the key methods involved, and a handful of useful annotations for intercepting calls to modify behavior with cross-cutting aspects.
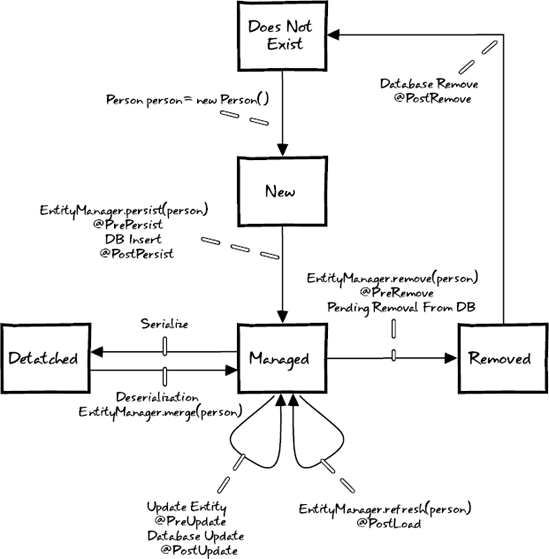
There are five key states: Does Not Exist, New, Managed, Removed, and Detached. In addition, there are seven life-cycle callback annotations. The callback annotations, when implemented within your entity class, are referred to as internal callback methods. Alternatively, they can be defined outside a given entity class as a listener class. These are referred to as external callback methods. You may implement any subset of the callback methods or none at all. You may apply only a specific life-cycle callback to a single method. You may use multiple callbacks on the same method by applying all of the annotations that apply. You can also use both internal callbacks and external callbacks on a single entity. The external callbacks fire first, and then the internal callbacks are executed. There are a ton of options for taking advantage of these callbacks.
Note
Callback methods should not interact with other entity objects or make calls to EntityManager or Query methods, to avoid conflicts with the original database operation that is still in progress.
Let's walk through a fictitious life cycle for a person through each of the five key states:
- Does Not Exist:
We start here.
- New:
A new person object is instantiated via
Person person = new Person(). At this stage, thepersonobject is in the New state. It is not associated with anEntityManager. and it has no representation in the database. Also, because we're using an autogenerated strategy for our primary key, the object is in memory but has no ID associated with it. Again, this is something to be wary of when managing objects in collections, as an entity has the potential to break theequals()andhashCode()contract if an object's equality is based off its identifier and this property suddenly changes from null to a real value upon being persisted via Hibernate. We will discuss this issue in more detail in Chapter 5.- Managed:
We persist the
personentity with a call toEntityManager.persist(). If we have a method annotated with@PrePersist, that method is executed followed by an insert into the database, optionally followed by the execution of any custom method we've annotated with@PostPersist. Now ourpersonentity is in the Managed state. In this state, there are many things that could happen to ourpersonentity. For instance, we could make a call toEntityManager.refresh(), which would discard the object in memory and retrieve a fresh copy from the database, optionally taking advantage of the@PostLoadcallback. Or we could delete the entity viaEntityManager.remove()resulting in a call to@PreRemove.- Remove:
Once the record is deleted from the database, the entity is in a Removed state, pending execution of a method annotated with
@PostRemovebefore returning to the Does Not Exist state.- Detached:
The Detached state comes into play when the object is no longer associated with an
EntityManageror persistence context. Detached objects are often returned from a persistence tier to the web layer where they can be displayed to the end-user in some form. Changes can be made to a detached object, but these changes won't be persisted to the database until the entity is reassociated with a persistence context.
A few pieces of the puzzle remain. Before we have a fully working system, we need to do the following:
Set up a JPA environment that knows about our
Persondomain object.Configure a database connection.
Manage the system's transactions.
Inject all of that into the DAO.
We'll first look at the setup from the JPA side, and then handle the Spring side of the configuration.
JPA requires you to create a META-INF/persistence.xml file. We're going to set up the easiest possible configuration:
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="galleryPersistenceUnit" transaction-type="RESOURCE_LOCAL"/>
</persistence>This creates a persistence unit called galleryPersistenceUnit. It's recommended that you name your persistence unit in a way that expresses the relationship to a given database so that you may easily incorporate more datastores later without your bean definitions getting too confusing. By default, all classes marked as @Entity will be added to this persistence unit.
Now that we have JPA up and running, the Spring configuration needs to be made aware of the persistence.xml. We'll set that up next.
We need a way to create a usable EntityManager in the Spring ApplicationContext. In typical Spring fashion, there is more than one way to configure JPA. The following are some of the options:
A
LocalEntityManagerFactoryBeanuses JPA's Java SE bootstrapping.LocalEntityManagerFactoryBeanrequires the JPA provider (for example, Hibernate or OpenJPA) to set up everything it needs, including database connections and a provider-specific load-time weaving setup. The bean would look something like this:<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalEntityManagerFactoryBean"> <property name="persistenceUnitName" value="galleryPersistenceUnit"/> </bean>If you have a Java EE container and you want to use EJB 3, you can use Spring's built-in JNDI lookup capabilities:
<jee:jndi-lookup id="entityManagerFactory" jndi-name="persistence/galleryPersistenceUnit"/>
The Spring JPA
LocalContainerEntityManagerFactoryBeanrequires a bit more Spring configuration than the other two options. However, it also gives you the most Spring capabilities. Setting up aLocalContainerEntityManagerFactoryBeanrequires you to configure a datasource and JPA vendor-specific adapters, so that the generic Spring JPA configuration can set up some of the extras required for each vendor. This is the approach we'll take in this chapter.
We're going to use some of the generic Spring configuration we've touched on earlier. We'll also use component scanning to tell Spring to automatically create DAOs found in specific packages.
Let's create a file called spring-jpa.xml under src/main/resources/META-INF/spring. This file will have the LocalContainerEntityManagerFactoryBean, our datasource, a JPA transaction manager, and annotation-based transactions. We'll start the spring-jpa.xml file with the namespace setup for the Spring file. There are a bunch of Spring namespaces that we'll use to configure JPA.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.0.xsd">
<!-- The rest of the config is covered below -->
</beans>This tells the XML parser that we want to use the following schemas as part of our configuration:
The default Spring
beansschemaThe
pschema, which reduces the verbosity of setting propertiesThe
txschema for transaction management
Because we're using the p namespace, we can configure Spring values more simply. For example, using p:url has the same effect as using the <property name="url" value="..."> XML fragment. You can also use the p namespace to create references.
Next, let's set up an in-memory H2 database datasource:
<bean id="dataSource"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close"
p:driverClassName="org.h2.Driver"
p:url="jdbc:h2:mem:gallery;DB_CLOSE_DELAY=-1"
p:username="sa"
p:password=""/>Obviously, you don't need to use an in-memory database. There are plenty of other ways of getting a datasource, including JNDI lookups and connection pooling.
We're using LocalContainerEntityManagerFactoryBean, which creates a JPA EntityManager according to JPA's stand-alone bootstrap contract. This is the way to set up a completely Spring-managed JPA EntityManagerFactory:
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"
p:dataSource-ref="dataSource"/>The LocalContainerEntityManagerFactoryBean can use a Spring-managed datasource and a few Hibernate-specific properties, such as showSql, generateDdl, and databasePlatform.
Our @Repository annotation gets picked up as a result of Spring's component scanning. Recall that we set up component scanning in our spring-master.xml file, like so:
<context:component-scan base-package="com.prospringhibernate"> <context:exclude-filter type="annotation"expression="org.springframework.stereotype.Repository"/> </context:component-scan>
This directive will ensure that Spring loads and manages all ofour application's DAO classes. As part of this process, Spring will inject the correct EntityManager instance into the respective DAOs, as expressed by the @PersistenceContext annotation.
The following settings allow our environment to perform JPA transactions. This very basic configuration is required for our JPA application to be able to update data.
<bean id="transactionManager"
class="org.springframework.orm.jpa.JpaTransactionManager"
p:entityManagerFactory-ref="entityManagerFactory"/>
<tx:annotation-driven mode="aspectj" transaction-manager="transactionManager"/>As you've seen, there is a fair amount involved for JPA configuration, but it's definitely worth the effort for the amount of functionality that is delivered!
Frameworks like Spring and Hibernate provided a means to solve some complex enterprise challenges. The critical difference between EJB 2.0 and frameworks like Spring and Hibernate is that this complexity is an option that you can elect to utilize, rather than an integral component of the framework architecture that you are forced to embrace.
In this chapter, you took a stroll down memory lane to see how persistence has evolved in the Java ecosystem, and now have a firmer understanding of the terminology as well as the distinctions between specifications and implementations. You've learned that you can have an application that uses many permutations of specifications and implementations. For instance, you can build a single application that uses EJB 3.0 for a distributed component-based architecture, with JPA for persistence powered by Hibernate as the JPA implementation. You also got a feel for the domain model and DAO structure that underpins our art gallery example application. Finally, you learned quite a lot about setting up a JPA application in a Spring environment. You are now armed with enough information to get a JPA application working.
In the next chapter, we'll continue building the domain model for our art gallery application.