
3 Useful anti-patterns
- Known bad practices that can be put to good use
- Anti-patterns that are, in fact, useful
- Identifying when to use a best practice versus its evil twin
Programming literature is full of best practices and design patterns. Some of them even seem indisputable and provoke people to give you the side-eye if you argue about them. They eventually turn into dogmas and are rarely questioned. Once in a while, someone writes a blog post about one, and if their article gets the approval of the Hacker News1 community, it can be accepted as valid criticism and can open a door for new ideas. Otherwise, you can’t even discuss them. If I had to send a single message to the world of programming, it would be to question all the things that are taught to you—their usefulness, their reason, their gain, and their cost.
Dogmas, immutable laws, create blind spots for us, and their size grows the longer we stick to them. Those blind spots can obscure some useful techniques that can even be more useful for certain use cases.
Anti-patterns, or bad practices, if you will, get a bad rap, and deservedly so, but that doesn’t mean we should avoid them like radioactive material. I’ll be going over some of those patterns that can help you more than their best practice counterparts. This way, you’ll also be using the best practices and great design patterns with better understanding of how they help and when they aren’t helpful. You’ll see what you’re missing in your blind spot and what kind of gems are there.
3.1 If it ain’t broke, break it
One of the first things I learned at the companies where I worked—after where the restrooms were—was to avoid changing the code, aka code churn, at all costs. Every change you make carries the risk of creating a regression, which is a bug that breaks an already working scenario. Bugs are already costly, and fixing them takes time when they are part of a new feature. When it’s a regression, that’s worse than releasing a new feature with bugs—it’s a step backward. Missing a shot in basketball is a bug. Scoring a goal on your own hoop, effectively scoring for your opponent, is a regression. Time is the most critical resource in software development, and losing time has the most severe penalty. Regressions lose the most time. It makes sense to avoid regressions and avoid breaking the code.
Avoiding changes can lead to a conundrum eventually, though, because if a new feature requires that something be broken and made again, it might cause resistance to its development. You can become accustomed to tiptoeing around existing code and trying to add everything in new code without touching existing code. Your effort to leave the code untouched can force you to create more code, which just increases the amount of code to maintain.
If you have to change existing code, that’s a bigger problem. There is no tiptoeing around this time. It can be awfully hard to modify existing code because it is tightly coupled to a certain way of doing things, and changing it will oblige you to change many other places. This resistance of existing code to change is called code rigidity. That means the more rigid the code gets, the more of the code you have to break to manipulate it.
3.1.1 Facing code rigidity
Code rigidity is based on multiple factors, and one of them is too many dependencies in the code. Dependency can relate to multiple things: it can refer to a framework assembly, to an external library, or to another entity in your own code. All types of dependency can create problems if your code gets tangled up in them. Dependency can be both a blessing and a curse. Figure 3.1 depicts a piece of software with a terrible dependency graph. It violates the concern boundaries, and any break in one of the components would require changes in almost all of the code.

Figure 3.1 The occult symbol for dependency hell
Why do dependencies cause problems? When you consider adding dependencies, consider also every component as a different customer or every layer as a different market segment with different needs. Serving multiple segments of customers is a greater responsibility than serving only a single type of customer. Customers have different needs, which might force you to cater to different needs unnecessarily. Think about these relationships when you are deciding on dependency chains. Ideally, try to serve as few types of customers as possible. This is the key to keeping your component or your entire layer as simple as possible.
We can’t avoid dependencies. They are essential for reusing code. Code reuse is a two-clause contract. If component A depends on component B, the first clause is, “B will provide services to A.” There is also a second clause that is often overlooked: “A will go through maintenance whenever B introduces a breaking change.” Dependencies caused by code reuse are okay as long as you can keep the dependency chain organized and compartmentalized.
3.1.2 Move fast, break things
Why do you need to break that code, as in making it not even compile or fail the tests? Because intertwined dependencies cause rigidity in the code that makes it resistant to change. It’s a steep hill that will make you slower over time, eventually bringing you to a halt. It’s easier to handle breaks at the beginning, so you need to identify these issues and break your code, even when it’s working. You can see how dependencies force your hand in figure 3.2.
A component with zero dependencies is the easiest to change. It’s impossible to break anything else. If your component depends on one of your other components, that creates some rigidity because dependency implies a contract.
If you change the interface on B, that means you need to change A too. If you change the implementation of B without changing the interface, you can still break A because you break B. That becomes a bigger issue when you have multiple components that depend on a single component.
Changing A becomes harder because it needs a change in the dependent component and incurs a risk of breaking any of them. Programmers tend to assume that the more they reuse code, the more time they save. But at what cost? You need to consider this.
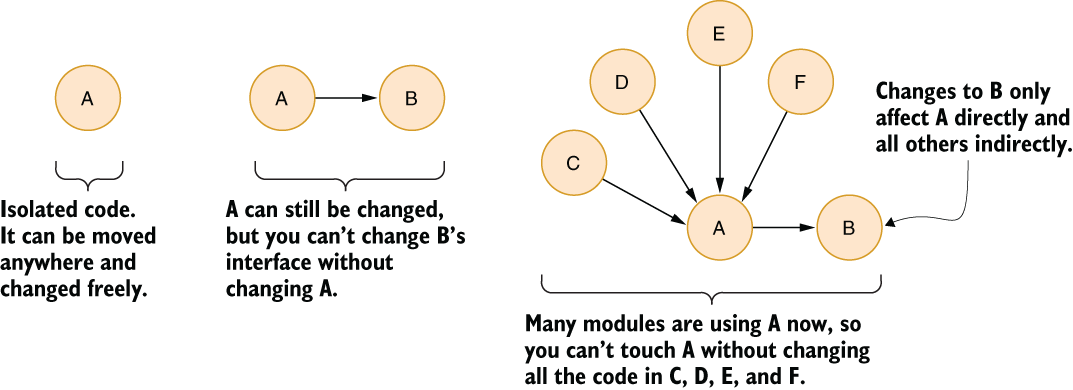
Figure 3.2 Resistance to change is proportional to dependencies.
3.1.3 Respecting boundaries
The first habit you must adopt is to avoid violating abstraction boundaries for dependencies. An abstraction boundary is the logical borders you draw around layers of your code, a set of the concerns of a given layer. For example, you can have web, business, and database layers in your code as abstractions. When you layer code like that, the database layer shouldn’t know about the web layer or the business layer, and the web layer shouldn’t know about the database, as figure 3.3 shows.
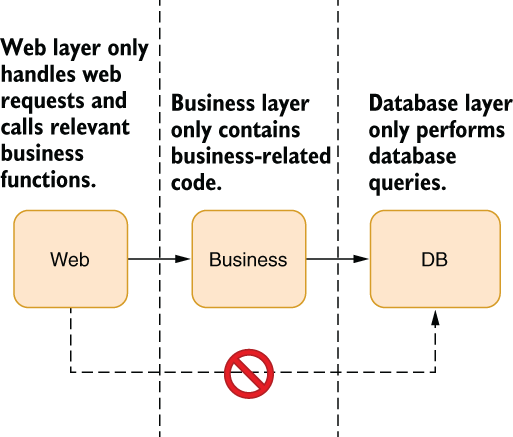
Figure 3.3 Violation of abstraction boundaries that you need to avoid
Why is stepping over boundaries a bad idea? Because it eliminates the benefits of an abstraction. When you pull the complexity of lower layers into higher layers, you become responsible for maintaining the impact of the changes everywhere on the lower layers. Think about a team whose members are responsible for their own layers. Suddenly, the developer of the web layer needs to learn SQL. Not only that, but the changes in the DB layer also need to be communicated now with more people than is necessary. It burdens the developer with unnecessary responsibilities. The time to reach a consensus among the people who need to be convinced increases exponentially. You lose time, and you lose the value of abstractions.
If you bump into such boundary issues, break the code, as in deconstruct it so it might stop working, remove the violation, refactor the code, and deal with the fallout. Fix other parts of the code that depend on it. You have to be vigilant about such issues and immediately cut them off, even at the risk of breaking the code. If the code makes you afraid to break it, it’s badly designed code. That doesn’t mean good code doesn’t break, but when it does, it’s much easier to glue the pieces back together.
3.1.4 Isolating common functionality
Does this all mean the web layer in figure 3.3 can’t ever have common functionality with the DB? It can, of course. But such cases indicate a need for a separate component. For instance, both layers can rely on the common model classes. In that case, you’d have a relationship diagram like that shown in figure 3.4.
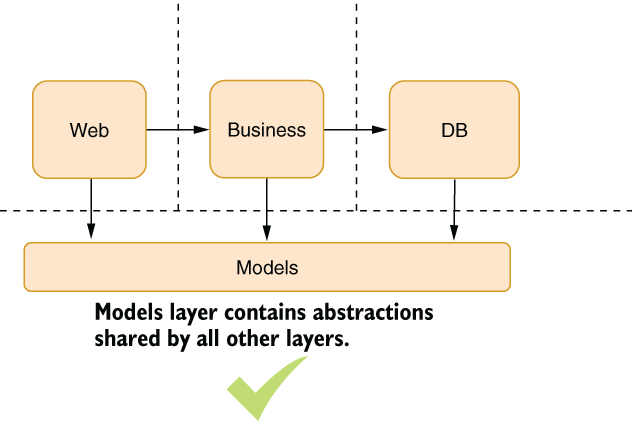
Figure 3.4 Extracting common functionality without violating abstractions
Refactoring code can break your build process or make your tests fail, and theoretically, it’s something you should never do. But I regard such violations as hidden breaks. They need immediate attention, and if they cause more breakage and more bugs in the process, that doesn’t mean you caused the code to stop working: it means the bug that was already there has now manifested itself in a way that is easier to reason about.
Let’s look at an example. Consider that you’re writing an API for a chat app in which you can communicate only in emojis. Yes, it sounds horrible, but there was once a chat app in which you could send only “Yo” as a message.2 Ours is an improvement over that, if nothing else.
We design the app with a web layer that accepts requests from mobile devices and calls the business layer (aka logic layer) that performs the actual operations. This kind of separation allows us to test the business layer without a web layer. We can also later use the same business logic in other platforms, such as a mobile website. Therefore, separating business logic makes sense.
NOTE Business in business logic or a business layer doesn’t necessarily mean something related to a business, but is more like the core logic of the application with abstract models. Arguably, reading business-layer code should give you an idea about how the application works in higher-level terms.
A business layer doesn’t know anything about databases or storage techniques. It calls on the database layer for that. The database layer encapsulates the database functionality in a DB-agnostic fashion. This kind of separation of concerns can make the testability of business logic easier because we can easily plug a mocked implementation of the storage layer into the business layer. More importantly, that architecture allows us to change a DB behind the scenes without changing a single line of code in the business layer, or in the web layer, for that matter. You can see how that kind of layering looks in figure 3.5.
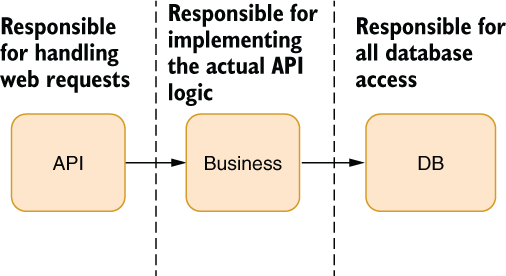
Figure 3.5 The basic architecture of our mobile app API
The downside is that every time you add a new feature to the API, you need to create a new business-layer class or method and a relevant database-layer class and methods. This seems like a lot of work, especially when the deadlines are tight and the feature is somewhat simple. “Why do I need to go through all this hassle for a simple SQL query?” you might think. Let’s go ahead and fulfill the fantasy of many developers and violate the existing abstractions.
3.1.5 Example web page
Suppose you receive a request from your manager to implement a new feature, a new statistics tab that shows how many messages the user sent and received in total. It’s just two simple SQL queries on the backend:
SELECT COUNT(*) as Sent FROM Messages WHERE FromId=@userId SELECT COUNT(*) as Received FROM Messages WHERE ToId=@userId
You can run these queries in your API layer. Even if you’re not familiar with ASP.NET Core, web development, or SQL, for that matter, you should have no problem understanding the gist of the code in listing 3.1, which defines a model to return to the mobile app. The model is then automatically serialized into JSON. We retrieve a connection string to our SQL server database. We use that string to open a connection, run our queries against the database, and return the results.
The StatsController class in listing 3.1 is an abstraction over web handling wherein received query parameters are in function arguments, the URL is defined by the name of the controller, and the result is returned as an object. So, you would reach the code in listing 3.1 with a URL like https://yourwebdomain/Stats/Get?userId=123, and the MVC infrastructure maps the query parameters into function parameters and the returned object to a JSON result automatically. It makes writing web-handling code simpler because you don’t really have to deal with URLs, query strings, HTTP headers, and JSON serialization.
Listing 3.1 Implementing a feature by violating abstractions
public class UserStats { ❶
public int Received { get; set; }
public int Sent { get; set; }
}
public class StatsController: ControllerBase { ❷
public UserStats Get(int userId) { ❸
var result = new UserStats();
string connectionString = config.GetConnectionString("DB");
using (var conn = new SqlConnection(connectionString)) {
conn.Open();
var cmd = conn.CreateCommand();
cmd.CommandText =
"SELECT COUNT(*) FROM Messages WHERE FromId={0}";
cmd.Parameters.Add(userId);
result.Sent = (int)cmd.ExecuteScalar();
cmd.CommandText =
"SELECT COUNT(*) FROM Messages WHERE ToId={0}";
result.Received = (int)cmd.ExecuteScalar();
}
return result;
}
}I probably spent five minutes writing this implementation. It looks straightforward. Why do we bother with abstractions? Just put everything in an API layer, right?
Such solutions can be okay when you’re working on prototypes, which don’t require a perfect design. But in a production system, you need to be careful about making such decisions. Are you allowed to break production? Is it okay if the site goes down for a couple of minutes? If these are okay, then feel free to use this. How about your team? Is the maintainer of the API layer okay with having these SQL queries all around the place? How about testing? How do you test this code and make sure that it runs correctly? How about new fields being added to this? Try to imagine the office the next day. How do you see people treating you? Do they hug you? Cheer you? Or do you find your desk and your chair decorated with tacks?
You added a dependency to the physical DB structure. If you need to change the layout of the Messages table or the DB technology you used, you’ll have to go around all the code and make sure that everything works with the new DB or the new table layout.
3.1.6 Leave no debt behind
We programmers are not good at predicting future events and their costs. When we make certain unfavorable decisions just for the sake of meeting a deadline, we make it even harder to meet the next one because of the mess we’ve created. Programmers commonly call this technical debt.
Technical debts are conscious decisions. The unconscious ones are called technical ineptitude. The reason they are called debts is because either you pay them back later, or the code will come looking for you in an unforeseen future and break your legs with a tire iron.
There are many ways technical debt can accumulate. It might look easier just to pass an arbitrary value instead of taking the trouble to create a constant for it. “A string seems to work fine there,” “No harm will come from shortening a name,” “Let me just copy everything and change some of its parts,” “I know, I’ll just use regular expressions.” Every small bad decision will add seconds to your and your team’s performance. Your throughput will degrade cumulatively over time. You will get slower and slower, getting less satisfaction from your work and less positive feedback from management. By being the wrong kind of lazy, you are dooming yourself to failure. Be the right kind of lazy: serve your future laziness.
The best way to deal with technical debt is to procrastinate with it. You have a larger job ahead of you? Use this as an opportunity to get yourself warmed up. It might break the code. That’s good—use it as an opportunity to identify rigid parts of the code, get them granular, flexible. Try to tackle it, change it, and then if you think it doesn’t work well enough, undo all your changes.
3.2 Write it from scratch
If changing code is risky, writing it from scratch must be orders of magnitude riskier. It essentially means any untested scenario might be broken. Not only does it mean writing everything from scratch, but fixing all the bugs from scratch, too. It’s regarded as a seriously cost-inefficient method for fixing design deficiencies.
However, that’s only true for code that already works. For code that you already have been working on, starting anew can be a blessing. How, you might ask? It’s all related to the spiral of desperation when writing new code. It goes like this:
-
Then you notice that the current design doesn’t work for the requirements.
-
You start tweaking the design again, but you avoid redoing it because it would cause too many changes. Every line adds to your shame.
-
Your design is now a Frankenstein’s monster of ideas and code mashed together. Elegance is lost, simplicity is lost, and all hope is lost.
At that point, you’ve entered a loop of sunk-cost fallacy. The time you spent already with your existing code makes you averse to redoing it. But because it can’t solve the main issues, you spend days trying to convince yourself that the design might work. Maybe you do fix it at some point, but it might lose you weeks, just because you dug yourself into a hole.
3.2.1 Erase and rewrite
I say, start from scratch: rewrite it. Toss away everything you already did and write every bit from scratch. You can’t imagine how refreshing and fast that will be. You might think writing it from scratch would be hugely inefficient and you’d be spending double the time, but that’s not the case because you’ve already done it once. You already know your way around the problem. The gains in redoing a task resembles something like those shown in figure 3.6.
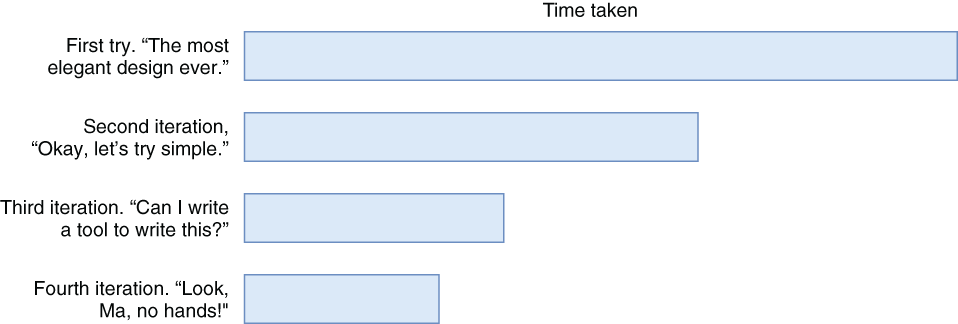
Figure 3.6 The brilliance of doing something over and over and expecting the same results
It’s hard to overstate the gains in speed when you’re doing something the second time. Unlike the hackers depicted in movies, most of your time is spent looking at the screen: not writing stuff, but thinking about things, considering the right way of doing things. Programming isn’t about crafting things as much as it’s about navigating the maze of a complex decision tree. When you restart the maze from the beginning, you already know possible mishaps, familiar pitfalls, and certain designs you’ve reached in your previous attempt.
If you feel stuck developing something new, write it from scratch. I’d say don’t even save the previous copy of your work, but you might want to in case you’re not really sure if you can do it again really quickly. Okay, then save a copy somewhere, but I assure you, most of the time, you won’t even need to look at your previous work. It’s already in your mind, guiding you much faster, and without going into the same spiral of desperation this time.
More importantly, when you start from scratch, you’ll know if you’re following the wrong path much earlier in your process than you previously did. Your pitfall radar will come installed this time. You’ll have gained an innate sense of developing that certain feature the right way. Programming this way is a lot like playing console games like Marvel’s Spider-Man or The Last of Us. You die constantly and start that sequence again. You die, you respawn. You become better with this repetition, and the more you repeat, the better you become at programming. Doing it from scratch improves how you develop that single feature, yes, but it also improves your development skills in general for all the future code you will be writing.
Don’t hesitate to throw your work away and write it from scratch. Don’t fall for the sunk-cost fallacy.
3.3 Fix it, even if it ain’t broke
There are ways to deal with code rigidity, and one of them is to keep the code churning so it doesn’t solidify—as far as the analogy goes. Good code should be easy to change, and it shouldn’t give you a list of a thousand places that you need to change to make the change you need. Certain changes can be performed on code that aren’t necessary but can help you in the long term. You can make it a regular habit to keep your dependencies up to date, keeping your app fluid, and identify the most rigid parts that are hard to change. You can also improve the code as a gardening activity, taking care of the small issues in the code regularly.
3.3.1 Race toward the future
You’ll inevitably be using one or more packages from the package ecosystem, and you’ll leave them as is because they keep working for you. The problem with this is that when you need to use another package and it requires a later version of your package, the upgrade process can be much more painful than gradually upgrading your packages and staying current. You can see such a conflict in figure 3.7.
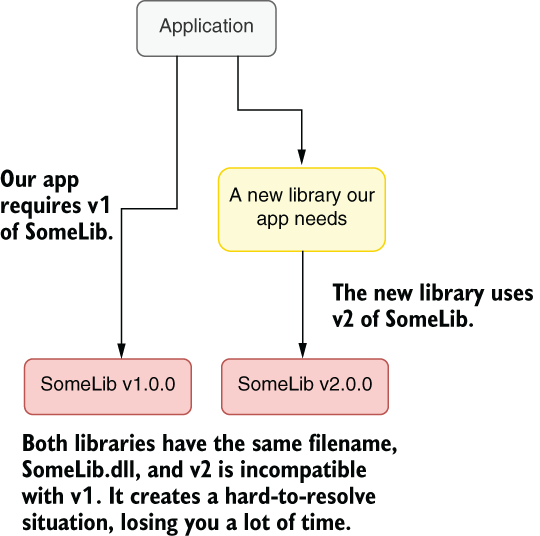
Figure 3.7 Unfixable version conflicts
Most of the time, package maintainers only think about the upgrade scenarios between two major versions, rather than multiple in-between versions. For example, the popular Elasticsearch search library requires major version upgrades to be performed one by one; it doesn’t support upgrading from one version to another directly.
.NET supports binding redirects to avoid the problem of multiple versions of the same package, to a certain degree. A binding redirect is a directive in application configuration that causes .NET to forward calls to an older version of an assembly to its newer version, or vice versa. Of course, this only works when both packages are compatible. You don’t normally need to deal with binding redirects yourself because Visual Studio can do that for you if you have already selected Automatically Generate Binding Redirects in the project properties screen.
Keeping your packages up to date periodically will have two important benefits. First, you’ll have spread the effort of upgrading to the current version out over the maintenance period. Every step will be less painful. Second, and more importantly, every minor upgrade might break your code or your design in small or subtle ways that you will need to fix to move to the future. This may sound undesirable, but it will make you improve the code and design in small steps as long as you have tests in place.
You might have a web application that uses Elasticsearch for search operations and Newtonsoft.Json for parsing and producing JSON. They are among the most common libraries out there. The problem starts when you need to upgrade the Newtonsoft.Json package to use a new feature, but Elasticsearch uses the old one. But to upgrade Elasticsearch, you need to change the code that handles Elasticsearch, too. What do you do?
Most packages only support single-version upgrades. Elasticsearch, for example, expects you to upgrade from 5 to 6, and it has guidelines on how to do that. It doesn’t have guidelines for upgrading from 5 to 7. You’ll have to apply each individual upgrade step separately. Some upgrades also require you to change code significantly. Elasticsearch 7 almost makes you write the code from scratch.
You might as well stay in the older versions under the safety of unchanged code, but not only does the support for older versions end at some point, but the documentation and code examples don’t stay around forever, either. Stack Overflow gets filled with the answers about the newer versions because people use the latest version when they start a new project. Your support network for the older version fades over time. That makes it even harder to upgrade with every passing year, which pushes you into a downward spiral of desperation.
My solution to this problem is to join the race toward the future. Keep the libraries up to date. Make it a regular habit to upgrade libraries. This will break your code occasionally, and thanks to that, you’ll find out which part of your code is more fragile, and you can add more test coverage.
The key idea is that upgrades may cause your code to break, but letting them have microbreaks will prevent huge roadblocks that become really hard to tackle. You are not only investing in a fictional future gain, but you are also investing in the flexing of dependencies of your app, letting it break and mending it so it doesn’t break as easily with the next change, regardless of package upgrades. The less resistant your app is to change, the better it is in terms of design and ease of maintenance.
3.3.2 Cleanliness is next to codeliness
What I liked first about computers was their determinism. What you wrote would happen the same way all the time, guaranteed. Code that’s working would always work. I found comfort in that. How naive of me. In my career, I’ve seen many instances of bugs that could only be observed occasionally based on the speed of your CPU or the time of the day. The first truth of the streets is, “Everything changes.” Your code will change. Requirements will change. Documentation will change. The environment will change. It’s impossible for you to keep running code stable just by not touching it.
Since we’ve gotten that out of the way, we can relax and say that it’s okay to touch code. We shouldn’t be afraid of change because it will happen anyway. That means that you shouldn’t hesitate to improve working code. Improvements can be small: adding some necessary comments, removing some unnecessary ones, naming things better. Keep the code alive. The more changes you make on some code, the less resistant it becomes to future change. That’s because changes will cause breaks and breaks will let you identify weak parts and make them more manageable. You should develop an understanding of how and where your code breaks. Eventually, you’ll have an innate sense of what kind of change would be the least risky.
You can call this kind of code-improvement activity gardening. You are not necessarily adding features or fixing bugs, but the code should be slightly improved when you’re done with it. Such a change can let the next developer who visits the code understand it better or improve the test coverage on the code, as if Santa left some gifts overnight or the bonsai at the office was mysteriously alive.
Why should you bother doing a chore that will never be recognized by anyone in your career? Ideally, it should be recognized and rewarded, but that may not be always the case. You can even get some backlash from your peers because they may not like the change you made. You can even break their workflow without breaking the code. You can turn it into a worse design than what the original developer intended while you’re trying to improve it.
Yes, and that’s expected. The only way to become mature about how to handle code is to change lots of it. Make sure that your changes are easily reversible so in case you upset someone, you can take your changes back. You will also learn how to communicate with your peers about changes that might impact them. Good communication is the greatest skill you can improve in software development.
The greatest benefit of trivial code improvements is that it puts you into the programming state of mind very quickly. Large work items are the heaviest mental dumbbells. You usually don’t know where to start and how to handle such a large change. The pessimism of “Oh, that will be so hard to do that I’ll just suffer through this” makes you postpone starting the project. The more you postpone it, the more you will dread coding it.
Making minor improvements to code is a trick to get your mental wheels turning so you can warm up enough to tackle a larger problem. Because you’re already coding, your brain resists switching gears less than if you try to switch from browsing social media to coding. Relevant cognitive parts will have already been fired and are ready for a larger project.
If you can’t find anything to improve, you can get help from code analyzers. They are great tools for finding minor issues in the code. Make sure you customize the options of the code analyzer you use to avoid offending people as much as possible. Talk to your peers about what they think about it. If they think that they can’t be bothered to fix the issues, promise them to fix the first batch yourself and use that as an opportunity to warm up. Otherwise, you can use a command-line alternative or Visual Studio’s own code analysis features to run code analysis without violating your team’s coding guidelines.
You don’t even have to apply the changes you make because they are only for warming you up to coding. For example, you may not be sure if you can apply a certain fix, it might look risky, but you have already done so much. But as you have learned, throw it away. You can always start from scratch and do it again. Don’t worry much about throwing away your work. If you are keen on it, keep a backup, but I wouldn’t really worry about it.
If you know that your team will be okay with the changes you made, then publish them. The satisfaction of improvement, however small, can motivate you to make larger changes.
3.4 Do repeat yourself
Repetition and copy-paste programming are concepts that are looked down on in the circles of software development. Like every sane recommendation, they’ve eventually turned into a religion, causing people to suffer.
The theory goes like this: you write a piece of code. You need the same piece of code somewhere else in the code. A beginner’s inclination would be to just copy and paste the same code and use it. It’s all good so far. Then you find a bug in the copy-pasted code. Now, you need to change the code in two separate places. You need to keep them in sync. That will create more work and cause you to miss deadlines.
It makes sense, right? The solution to the problem is usually to put the code in a shared class or module and use it in both parts of the code instead. So, when you change the shared code, you would be changing it magically everywhere it’s referenced, saving you a great deal of time.
It’s all good so far, but it doesn’t last forever. The problems begin to appear when you apply this principle to everything imaginable, and blindly, at that. One minor detail you miss when you try to refactor code into reusable classes is that you are inherently creating new dependencies, and dependencies influence your design. Sometimes they can even force your hand.
The biggest problem with shared dependencies is that the parts of the software that use the shared code can diverge in their requirements. When this happens, a developer’s reflex is to cater to different needs while using the same code. That means adding optional parameters, conditional logic to make sure that the shared code can serve two different requirements. This makes the actual code more complicated, eventually causing more problems than it solves. At some point, you start thinking about a more complicated design than copy-pasted code.
Consider an example in which you are tasked to write an API for an online shopping website. The client needs to change the shipping address for the customer, which is represented by a class called PostalAddress like this:
public class PostalAddress {
public string FirstName { get; set; }
public string LastName { get; set; }
public string Address1 { get; set; }
public string Address2 { get; set; }
public string City { get; set; }
public string ZipCode { get; set; }
public string Notes { get; set; }
}You need to apply some normalization to the fields, such as capitalization, so they look decent even when the user doesn’t provide the correct input. An update function might look like a sequence of normalization operations and the update on the database:
public void SetShippingAddress(Guid customerId,
PostalAddress newAddress) {
normalizeFields(newAddress);
db.UpdateShippingAddress(customerId, newAddress);
}
private void normalizeFields(PostalAddress address) {
address.FirstName = TextHelper.Capitalize(address.FirstName);
address.LastName = TextHelper.Capitalize(address.LastName);
address.Notes = TextHelper.Capitalize(address.Notes);
}Our capitalize method would work by making the first character uppercase and the rest of the string lowercase:
public static string Capitalize(string text) {
if (text.Length < 2) {
return text.ToUpper();
}
return Char.ToUpper(text[0]) + text.Substring(1).ToLower();
}Now, this seems to work for shipping notes and names: “gunyuz” becomes “Gunyuz” and “PLEASE LEAVE IT AT THE DOOR” becomes “Please leave it at the door,” saving the delivery person some anxiety. After you run your application for a while, you want to normalize city names, too. You add it to the normalizeFields function:
address.City = TextHelper.Capitalize(address.City);
It’s all good so far, but when you start to receive orders from San Francisco, you notice that they are normalized to “San francisco.” Now you have to change the logic of your capitalization function so that it capitalizes every word, so the city name becomes “San Francisco.” It will also help with the names of Elon Musk’s kids. But then you notice the delivery note becomes, “Please Leave It At The Door.” It’s better than all uppercase, but the boss wants it perfect. What do you do?
The easiest change that touches the least code might seem to be to change the Capitalize function so that it receives an additional parameter about behavior. The code in listing 3.2 receives an additional parameter called everyWord that specifies if it’s supposed to capitalize every word or only the first word. Please note that you didn’t name the parameter isCity or something like that because what you’re using it for isn’t the problem of the Capitalize function. Names should explain things in the terms of the context they are in, not the caller’s. Anyway, you split the text into words if everyWord is true and capitalize each word individually by calling yourself for each word and then join the words back into a new string.
Listing 3.2 Initial implementation of the Capitalize function
public static string Capitalize(string text,
bool everyWord = false) { ❶
if (text.Length < 2) {
return text;
}
if (!everyWord) { ❷
return Char.ToUpper(text[0]) + text.Substring(1).ToLower();
}
string[] words = text.Split(' '); ❸
for (int i = 0; i < words.Length; i++) { ❸
words[i] = Capitalize(words[i]); ❸
} ❸
return String.Join(" ", words); ❸
}❷ The case that handles only the first letter
❸ Capitalizes every word by calling the same function
It has already started to look complicated, but bear with me—I really want you to be convinced about this. Changing the behavior of the function seems like the simplest solution. You just add a parameter and if statements here and there, and there you go. This creates a bad habit, almost a reflex, to handle every small change this way and can create an enormous amount of complexity.
Let’s say you also need capitalization for filenames to download in your app, and you already have a function that corrects letter cases, so you just need the filenames capitalized and separated with an underscore. For example, if the API received invoice report, it should turn into Invoice_Report. Because you already have a capitalize function, your first instinct will be to modify its behavior slightly again. You add a new parameter called filename because the behavior you are adding doesn’t have a more generic name, and you check the parameter at the places where it matters. When converting to upper- and lowercase, you must use culture invariant versions of ToUpper and ToLower functions so the filenames on Turkish computers don’t suddenly become İnvoice_Report instead. Notice the dotted “I” in İnvoice_Report? Our implementation would now look like that shown in the following listing.
Listing 3.3 A Swiss army knife function that can do anything
public static string Capitalize(string text,
bool everyWord = false, bool filename = false) { ❶
if (text.Length < 2) {
return text;
}
if (!everyWord) {
if (filename) { ❷
return Char.ToUpperInvariant(text[0])
+ text.Substring(1).ToLowerInvariant();
}
return Char.ToUpper(text[0]) + text.Substring(1).ToLower();
}
string[] words = text.Split(' ');
for (int i = 0; i < words.Length; i++) {
words[i] = Capitalize(words[i]);
}
string separator = " ";
if (filename) {
separator = "_"; ❸
}
return String.Join(separator, words);
}Look what a monster you’ve created. You violated your principle of crosscutting concerns and made your Capitalize function aware of your file-naming conventions. It suddenly became part of a specific business logic, rather than staying generic. Yes, you are reusing code as much as possible, but you are making your job in the future really hard.
Notice that you also created a new case that isn’t even in your design: a new filename format where not all words are capitalized. It’s exposed through the condition where everyWord is false and filename is true. You didn’t intend this, but now you have it. Another developer might rely on the behavior, and that’s how your code becomes spaghetti over time.
I propose a cleaner approach: repeat yourself. Instead of trying to merge every single bit of logic into the same code, try to have separate functions with perhaps slightly repetitive code. You can have separate functions for each use case. You can have one that capitalizes only the first letter, you can have another one that capitalizes every word, and you can have another one that actually formats a filename. They don’t even have to reside next to each other—the code about the filename can stay closer to the business logic it’s required for. You instead have these three functions that convey their intent much better. The first one is named CapitalizeFirstLetter so its function is clearer. The second one is CapitalizeEveryWord, which also explains what it does better. It calls CapitalizeFirstLetter for every word, which is much easier to understand than trying to reason about recursion. Finally, you have FormatFilename, which has an entirely different name because capitalization isn’t the only thing it does. It has all the capitalization logic implemented from scratch. This lets you freely modify the function when your filename formatting conventions change without needing to think about how it would impact your capitalization work, as shown in the next listing.
Listing 3.4 Repeated work with much better readability and flexibility
public static string CapitalizeFirstLetter(string text) {
if (text.Length < 2) {
return text.ToUpper();
}
return Char.ToUpper(text[0]) + text.Substring(1).ToLower();
}
public static string CapitalizeEveryWord(string text) {
var words = text.Split(' ');
for (int n = 0; n < words.Length; n++) {
words[n] = CapitalizeFirstLetter(words[n]);
}
return String.Join(" ", words);
}
public static string FormatFilename(string filename) {
var words = filename.Split(' ');
for (int n = 0; n < words.Length; n++) {
string word = words[n];
if (word.Length < 2) {
words[n] = word.ToUpperInvariant();
} else {
words[n] = Char.ToUpperInvariant(word[0]) +
word.Substring(1).ToLowerInvariant();
}
}
return String.Join("_", words);
}This way, you won’t have to cram every possible bit of logic into a single function. This gets especially important when requirements diverge between callers.
3.4.1 Reuse or copy?
How do you decide between reusing the code and replicating it somewhere else? The greatest factor would be how you frame the caller’s concerns, that is, describing the caller’s requirements for what they actually are. When you describe the requirements of the function where a filename needs to be formatted, you become biased by the existence of a function that is quite close to what you want to do (capitalization) and that immediately signals to your brain to use that existing function. If the filename would be capitalized exactly the same way, it might still make sense, but the difference in requirements should be a red flag.
Three things are hard in computer science: cache invalidation, naming things, and off-by-one errors.3 Naming things correctly is one of the most important factors when understanding conflicting concerns in code reuse. The name Capitalize frames the function in a correct way. We could have called it NormalizeName when we first created it, but it would have prevented us from reusing it in other fields. What we did was to name things as closely as possible to their actual functionality. This way, our function can serve all the different purposes without creating confusion, and more importantly, it explains its job better wherever it’s used. You can see how different naming approaches affect describing the actual behavior in figure 3.8.
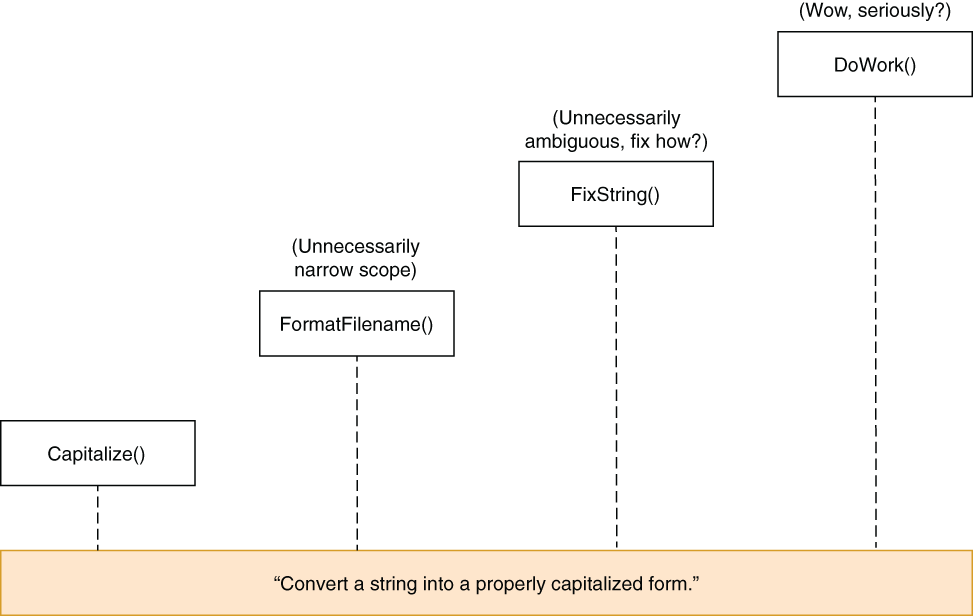
Figure 3.8 Pick a name as close as possible to the actual functionality.
We could go deeper with the actual functionality, like, “This function converts first letters of each word in a string to uppercase and converts all the remaining letters to lowercase,” but that’s hard to fit into a name. Names should be as short and as unambiguous as possible. Capitalize works in that sense.
Awareness of concerns for a piece of code is an important skill to have. I usually assign personalities to functions and classes to categorize their concerns. I’d say, “This function doesn’t care about this,” as if it were a person. You can similarly get an understanding of the concerns of a piece of code. That’s why we named the parameter to capitalize every word everyWord instead of isCity because the function just doesn’t care if it’s a city or not. It isn’t the function’s concern.
When you name things closer to their circle of concern, their usage patterns become more apparent. Then why did we end up naming the filename-formatting function FormatFilename? Shouldn’t we have called it CapitalizeInvariantAndSeparateWithUnderscores? No. Functions can do multiple things, but they only perform a single task, and they should be named after that task. If you feel the need to use the conjunctions “and” or “or” in your function’s name, either you’re naming it wrong or you are putting too much responsibility on your function.
Name is just one aspect of the concerns of code. Where the code resides, its module, its class, can also be an indication of how to decide whether to reuse it.
3.5 Invent it here
There is a common Turkish expression that literally translates to “Don’t come up with an invention now.” It means, “Don’t cause us trouble by trying a novel thing now, we don’t have time for that.” Reinventing the wheel is problematic. That pathology even has its own name in computer science circles: Not Invented Here Syndrome. It specifically addresses a type of person who cannot sleep at night if they don’t invent an already invented product themselves.
It’s certainly a lot of work to go to great lengths to create something from scratch when there is a known and working alternative. It’s prone to errors, too. The problem arises when reusing existing stuff becomes the norm and creating something becomes unreachable. The calcification of this perspective eventually turns into the motto “never invent anything.” You shouldn’t let yourself be afraid of inventing things.
First, an inventor has a questioning mindset. If you keep questioning things, you will inevitably become an inventor. When you explicitly prevent yourself from asking questions, you start to become dull and you turn yourself into a menial worker. You should avoid that attitude because it’s impossible for someone without a questioning mindset to optimize their work.
Secondly, not all inventions have alternatives. Your own abstractions are also inventions—your classes, your design, the helper functions you come up with. They are all productivity enhancements, yet they require invention.
I always wanted to write a website that provides Twitter statistics reports about my followers and people I follow. The problem is that I don’t want to learn how the Twitter API works. I know there are libraries out there that handle this, but I also don’t want to learn how they work, or more importantly, I don’t want their implementation to influence my design. If I use a certain library, it will bind me to the API of that library, and if I want to change the library, I will need to rewrite code everywhere.
The way to deal with these issues involves invention. We come up with our dream interface and put it as an abstraction in front of the library we use. This way, we avoid binding ourselves to a certain API design. If we want to change the library we use, we just change our abstraction, not everything in our code. I currently have no idea how the Twitter web API works, but I imagine that it is a regular web request with something to identify the authorization to access the Twitter API. That means getting an item from Twitter.
A programmer’s first reflex is to find a package and check out the documentation on how it works to integrate it into their code. Instead of doing that, invent a new API yourself and use it, which eventually calls the library that you’re using behind the scenes. Your API should be the simplest possible for your requirements. Become your own customer.
First, go over the requirements of an API. A web-based API provides a user interface on the web to give permissions to an application. It opens up a page on Twitter that asks for permissions and redirects back to the app if the user confirms. That means we need to know which URL to open for authorization and which URL to redirect back to. We can then use the data in the redirected page to make additional API calls later.
We shouldn’t need anything else after we authorize. So, I imagine an API for this purpose like that shown next.
Listing 3.5 Our imaginary Twitter API
public class Twitter {
public static Uri GetAuthorizationUrl(Uri callbackUrl) { ❶
string redirectUrl = "";
// ... do something here to build the redirect url
return new Uri(redirectUrl);
}
public static TwitterAccessToken GetAccessToken( ❶
TwitterCallbackInfo callbackData) {
// we should be getting something like this
return new TwitterAccessToken();
}
public Twitter(TwitterAccessToken accessToken) {
// we should store this somewhere
}
public IEnumerable<TwitterUserId> GetListOfFollowers( ❷
TwitterUserId userId) {
// no idea how this will work
}
}
public class TwitterUserId { ❸
// who knows how twitter defines user ids
}
public class TwitterAccessToken { ❸
// no idea what this will be
}
public class TwitterCallbackInfo { ❸
// this neither
} ❶ Static functions that handle the authorization flow
❷ The actual functionality we want
❸ Classes to define Twitter’s concepts
We invented something from scratch, a new Twitter API, even though we know little about how the Twitter API actually works. It might not be the best API for general use, but our customers are ourselves, so we have the luxury of designing it to fit our needs. For instance, I don’t think I’ll need to handle how the data is transferred in chunks from the original API, and I don’t care if it makes me wait and blocks the running code, which may not be desirable in a more generic API.
NOTE This approach to having your own convenient interfaces that act as an adapter is, unsurprisingly, called adapter pattern in the streets. I avoid emphasizing names over actual utility, but in case somebody asks you, now you know it.
We can later extract an interface from the classes we defined, so we don’t have to depend on concrete implementations, which makes testing easier. We don’t even know if the Twitter library we’re going to use supports replacing their implementation easily. You may occasionally encounter cases where your dream design doesn’t really fit with the design of the actual product. In that case, you need to tweak your design, but that’s a good sign—it means your design also represents your understanding of the underlying technology.
So, I might have lied a little. Don’t write a Twitter library from scratch. But don’t stray from the inventor’s mindset, either. Those go hand in hand, and you should stick with both.
3.6 Don’t use inheritance
Object-oriented programming (OOP) fell on the programming world like an anvil in the 1990s, causing a paradigm shift from structured programming. It was considered revolutionary. The decades-old problem of how to reuse code had finally been resolved.
The most emphasized feature of OOP was inheritance. You could define code reuse as a set of inherited dependencies. Not only did this allow simpler code reuse, but also simpler code modification. To create new code that has a slightly different behavior, you didn’t need to think about changing the original code. You just derived from it and overrode the relevant member to have modified behavior.
Inheritance caused more problems than it solved in the long run. Multiple inheritance was one of the first issues. What if you had to reuse the code from multiple classes and they all had the method with the same name, and perhaps with the same signature? How would it work? What about the diamond dependency problem shown in figure 3.9? It would be really complicated, so very few programming languages went ahead and implemented it.
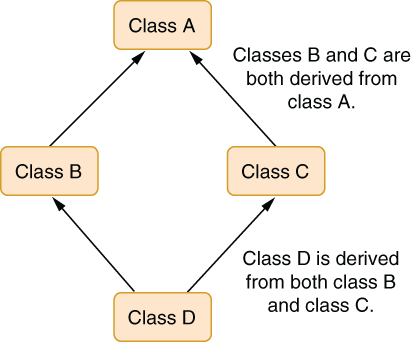
Figure 3.9 Diamond dependency problem—how should class D behave?
Aside from multiple inheritance, a greater problem with inheritance is that of strong dependency, also known as tight coupling. As I have already discussed, dependencies are the root of all evil. Because of its nature, inheritance binds you to a concrete implementation, which is considered a violation of one of the well-regarded principles of object-oriented programming, the dependency inversion principle, which states that code should never depend on the concrete implementation, but on an abstraction.
Why is there such a principle? Because when you are bound to a concrete implementation, your code becomes rigid and immovable. As we have seen, rigid code is very hard to test or modify.
Then how do you reuse code? How do you inherit your class from an abstraction? It’s simple—it’s called composition. Instead of inheriting from a class, you receive its abstraction as a parameter in your constructor. Think of your components as lego pieces that support each other rather than as a hierarchy of objects.
With regular inheritance, the relationship between common code and its variations is expressed with an ancestor/descendant model. In contrast, composition thinks of the common function as a separate component.
Composition is more like a client-server relationship than a parent-child one. You call reused code by its reference instead of inheriting its methods in your scope. You can construct the class you’re depending on in your constructor, or even better, you can receive it as a parameter, which would let you use it as an external dependency. That allows you to make that relationship more configurable and flexible.
Receiving it as a parameter has the extra advantage of making it easier to unit test the object by injecting mock versions of the concrete implementations. I’ll discuss dependency injection more in chapter 5.
Using composition over inheritance can require writing substantially more code because you might need to define dependencies with interfaces instead of concrete references, but it would also free the code from dependencies. You still need to weigh the pros and cons of composition before you use it.
3.7 Don’t use classes
Make no mistake—classes are great. They do their job and then get out of the way. But as I discussed in chapter 2, they incur a small reference indirection overhead and occupy slightly more indirection compared to value types. These issues won’t matter most of the time, but it’s important for you to know their pros and cons to understand the code and how you can impact it by making wrong decisions.
Value types can be, well, valuable. The primitive types that come with C# such as int, long, and double are already value types. You can also compose your own value types with constructs like enum and struct.
3.7.1 Enum is yum!
Enums are great for holding discrete ordinal values. Classes can also be used to define discrete values, but they lack certain affordances that enums have. A class is still, of course, better than hardcoding values.
If you’re writing code that handles the response of a web request that you make in your app, you may need to deal with different numerical response codes. Say that you’re querying weather information from the National Weather Service for a user’s given location, and you write a function to retrieve the required information. In listing 3.6, we’re using RestSharp for API requests and Newtonsoft.JSON to parse the response if the request is successful by checking whether the HTTP status code is successful. Notice that we’re using a hardcoded value (200) on the if line to check for the status code. We then use the Json.NET library to parse the response into a dynamic object to extract the information we need.
Listing 3.6 Function that returns NWS temperature forecast for a given coordinate
static double? getTemperature(double latitude,
double longitude) {
const string apiUrl = "https://api.weather.gov";
string coordinates = $"{latitude},{longitude}";
string requestPath = $"/points/{coordinates}/forecast/hourly";
var client = new RestClient(apiUrl);
var request = new RestRequest(requestPath);
var response = client.Get(request); ❶
if (response.StatusCode == 200) { ❷
dynamic obj = JObject.Parse(response.Content); ❸
var period = obj.properties.periods[0];
return (double)period.temperature; ❹
}
return null;
}❷ Check for successful HTTP status code.
The greatest problem with hardcoded values is humans’ inability to memorize numbers. We’re not good at it. We don’t understand them at first sight with the exception of the number of zeros on our paychecks. They are harder to type than simple names because it’s hard to associate numbers with mnemonics, and yet they are easier to make a typo in. The second problem with hardcoded values is that values can change. If you use the same value everywhere else, that means changing everything else just to change a value.
The second problem with numbers is that they lack intent. A numeric value like 200 can be anything. We don’t know what it is. So don’t hardcode values.
Classes are one way to encapsulate values. You can encapsulate HTTP status codes in a class like this:
class HttpStatusCode {
public const int OK = 200;
public const int NotFound = 404;
public const int ServerError = 500;
// ... and so on
}This way, you can change the line that checks for a successful HTTP request with some code like this:
if (response.StatusCode == HttpStatusCode.OK) {
...
}That version looks way more descriptive. We immediately understand the context, what the value means, and what it means in which context. It’s perfectly descriptive.
Then, what are enums for? Can’t we use classes for this? Consider that we have another class for holding values:
class ImageWidths {
public const int Small = 50;
public const int Medium = 100;
public const int Large = 200;
}Now this code would compile, and more importantly, it would return true:
return HttpStatusCode.OK == ImageWidths.Large;
That’s something you probably don’t want. Suppose we wrote it with an enum instead:
enum HttpStatusCode {
OK = 200,
NotFound = 404,
ServerError = 500,
}That’s way easier to write, right? Its usage would be the same in our example. More importantly, every enum type you define is distinct, which makes the values type-safe, unlike our example with classes with consts. An enum is a blessing in our case. If we tried the same comparison with two different enum types, the compiler would throw an error:
error CS0019: Operator '==' cannot be applied to operands of type
➥ 'HttpStatusCode' and 'ImageWidths'Awesome! Enums save us time by not allowing us to compare apples to oranges during compilation. They convey intent as well as classes that contain values. Enums are also value types, which means they are as fast as passing around an integer value.
3.7.2 Structs rock!
As chapter 2 points out, classes have a little storage overhead. Every class needs to keep an object header and virtual method table when instantiated. Additionally, classes are allocated on the heap, and they are garbage collected.
That means .NET needs to keep track of every class instantiated and get them out of memory when not needed. That’s a very efficient process—most of the time, you don’t even notice it’s there. It’s magical. It requires no manual memory management. So, no, you don’t have to be scared of using classes.
But as we’ve seen, it’s good to know when you can take advantage of a free benefit when it’s available. Structs are like classes. You can define properties, fields, and methods in them. Structs can also implement interfaces. However, a struct cannot be inherited and also cannot inherit from another struct or class. That’s because structs don’t have a virtual method table or an object header. They are not garbage collected because they are allocated on the call stack.
As I discussed in chapter 2, a call stack is just a contiguous block of memory with only its top pointer moving around. That makes a stack a very efficient storage mechanism because cleanup is fast and automatic. There is no possibility of fragmentation because it’s always LIFO (Last In First Out).
If a stack is that fast, why don’t we use it for everything? Why is there heap or garbage collection? That’s because a stack can only live for the lifetime of the function. When your function returns, anything on the function’s stack frame is gone, so other functions can use the same stack space. We need the heap for the objects that outlive functions.
Also, a stack is limited in size. That’s why there is a whole website named Stack Overflow: because your application will crash if you overflow the stack. Respect the stack—know its limits.
Structs are lightweight classes. They are allocated on stacks because they are value types. That means that assigning a struct value to a variable means copying its contents since no single reference represents it. You need to keep this in mind because copying is slower than passing around references for any data larger than the size of a pointer.
Although structs are value types themselves, they can still contain reference types. If, say, a struct contains a string, it’s still a reference type inside a value type, similar to how you can have value types inside a reference type. I will illustrate this in the figures throughout this section.
If you have a struct that contains only an integer value, it occupies less space in general than a reference to a class that contains an integer value, as figure 3.10 shows. Consider that our struct and class variants are about holding identifiers, as I discussed in chapter 2. Two flavors of the same structure would look like those in the following listing.
Listing 3.7 Similarity of class and struct declarations
public class Id {
public int Value { get; private set; }
public Id (int value) {
this.Value = value;
}
}
public struct Id {
public int Value { get; private set; }
public Id (int value) {
this.Value = value;
}
}The only difference in the code is struct versus class keywords, but observe how they differ in how they are stored when you create them in a function like this:
var a = new Id(123);
Figure 3.10 shows how they are laid out.
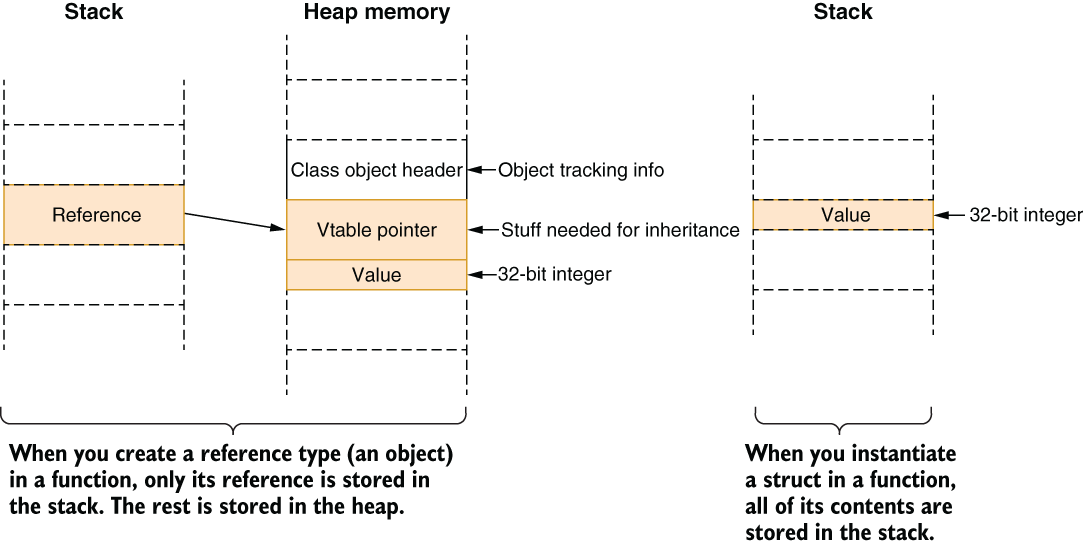
Figure 3.10 The difference between how classes and structs are laid out in memory
Because structs are value types, assigning one to another also creates another copy of the whole content of the struct instead of just creating another copy of the reference:
var a = new Id(123); var b = a;
In this case, figure 3.11 shows how structs can be efficient for storage of small types.
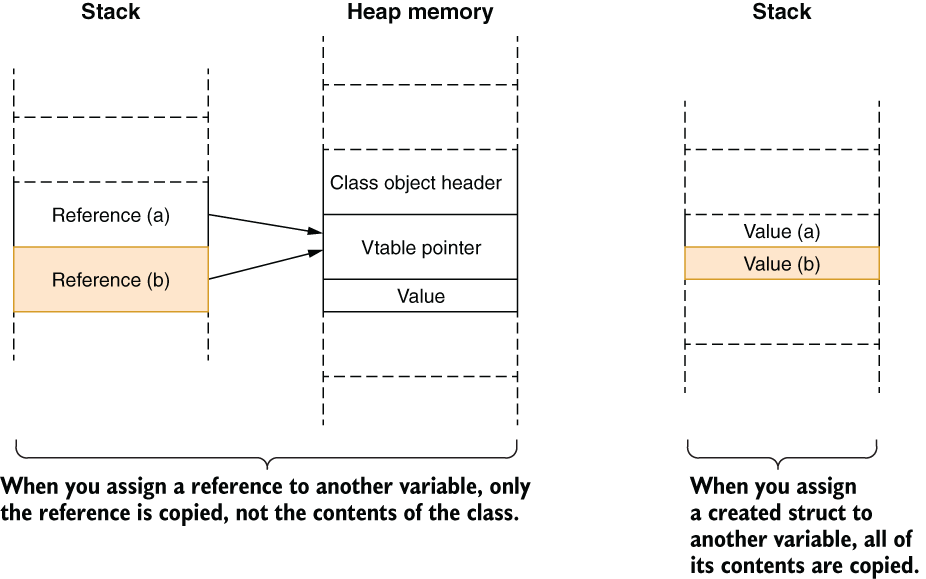
Figure 3.11 Efficiency of small structs in memory storage
Although stack storage is temporary during the execution of the function, it’s minuscule compared to the heap. A stack is 1 megabyte in size in .NET, while a heap can contain terabytes of data. A stack is fast, but if you fill it with large structs, it can fill up easily. Furthermore, copying large structs is also slower than only copying a reference. Consider that we’d like to keep some user information along with our identifiers. Our implementation would look like the next listing.
Listing 3.8 Defining a larger class or a struct
public class Person { ❶
public int Id { get; private set; }
public string FirstName { get; private set; }
public string LastName { get; private set; }
public string City { get; private set; }
public Person(int id, string firstName, string lastName,
string city) {
Id = id;
FirstName = firstName;
LastName = lastName;
City = city;
}
}❶ We can make a class a struct by changing the “class” word here to “struct.”
The only difference between the two definitions is the struct and class keywords. Yet creating and assigning one from another has a profound impact on how things work behind the scenes. Consider this simple code where Person can be either a struct or a class:
var a = new Person(42, "Sedat", "Kapanoglu", "San Francisco"); var b = a;
After you assign a to b, the difference in resulting memory layouts is shown in figure 3.12.
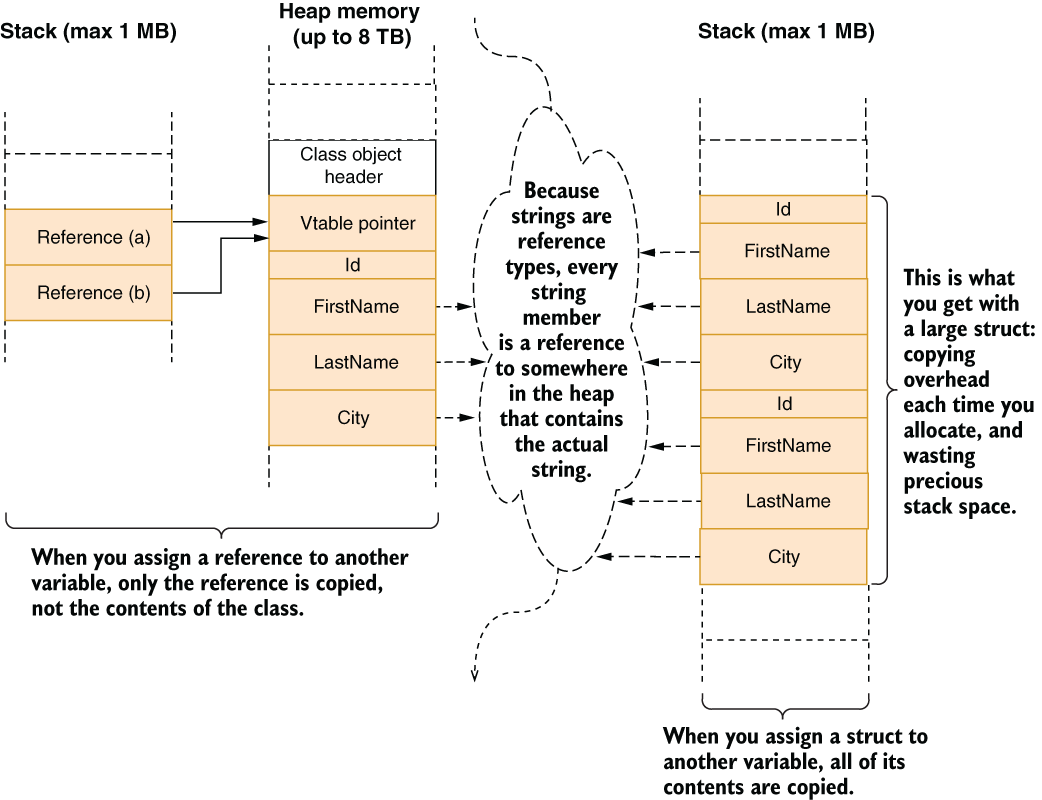
Figure 3.12 Impact difference between value types and reference types in larger types
A call stack can be extremely fast and efficient for storing things. They are great for working with small values with less overhead because they are not subject to garbage collection. Because they are not reference types, they cannot be null, either, which makes null reference exceptions impossible with structs.
You can’t use structs for everything, as is apparent by how they are stored: you can’t share a common reference to them, which means you can’t change a common instance from different references. That’s something we do a lot unconsciously and never think about. Consider if we wanted the struct to be mutable and used get; set; modifiers instead of get; private set;. That means we could modify the struct on the fly. Look at the example shown next.
public struct Person {
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string City { get; set; }
public Person(int id, string firstName, string lastName,
string city) {
Id = id;
FirstName = firstName;
LastName = lastName;
City = city;
}
}Consider this piece of code with a mutable struct:
var a = new Person(42, "Sedat", "Kapanoglu", "San Francisco"); var b = a; b.City = "Eskisehir"; Console.WriteLine(a.City); Console.WriteLine(b.City);
What do you think the output would be? If it were a class, both lines would show “Eskisehir” as the new city. But since we have two separate copies, it would print “San Francisco” and “Eskisehir.” Because of this, it’s always a great idea to make structs almost immutable so they can’t be accidentally changed later and cause bugs.
Although you should prefer composition over inheritance for code reuse, inheritance can also be useful when the given dependency is contained. Classes can provide you better flexibility than structs in those cases.
Classes can provide more efficient storage when they are larger in size because only their references will be copied in an assignment. In light of all this, feel free to use structs for small, immutable value types that have no need for inheritance.
3.8 Write bad code
Best practices come from bad code, and yet bad code can also emerge from the blind application of best practices. Structured, object-oriented, and even functional programming are all developed to make developers write better code. When best practices are taught, some bad practices are also singled out as “evil” and are completely banished. Let’s visit some of them.
3.8.1 Don’t use If/Else
If/Else is one of the first constructs you learn about programming. It is the expression of one of the fundamental parts of computers: logic. We love If/Else. It lets us express the logic of our program in a flowchart-like way. But that kind of expression can also make code less readable.
Like many programming constructs, If/Else blocks make the code in the conditionals indented. Suppose that we want to add some functionality to our Person class from the last section to process a record in the DB. We want to see if the City property of the Person class was changed and to change it in the DB too if the Person class points to a valid record. This is quite a stretched implementation. There are better ways to do these things, but I want to show you how the code can turn out, rather than its actual functionality. I draw a shape for you in the following listing.
Listing 3.10 An example of an If/Else festival in the code
public UpdateResult UpdateCityIfChanged() {
if (Id > 0) {
bool isActive = db.IsPersonActive(Id);
if (isActive) {
if (FirstName != null && LastName != null) {
string normalizedFirstName = FirstName.ToUpper();
string normalizedLastName = LastName.ToUpper();
string currentCity = db.GetCurrentCityByName(
normalizedFirstName, normalizedLastName);
if (currentCity != City) {
bool success = db.UpdateCurrentCity(Id, City);
if (success) {
return UpdateResult.Success;
} else {
return UpdateResult.UpdateFailed;
}
} else {
return UpdateResult.CityDidNotChange;
}
} else {
return UpdateResult.InvalidName;
}
} else {
return UpdateResult.PersonInactive;
}
} else {
return UpdateResult.InvalidId;
}
}Even if I explained what the function did step by step, it’s impossible to come back to this function five minutes later and not be confused again. One reason for the confusion is too much indentation. People are not accustomed to reading things in indented format, with the small exception of Reddit users. It’s hard to determine which block a line belongs to, what the context is. It’s hard to follow the logic.
The general principle to avoid unnecessary indentation is exiting the function as early as possible and avoiding using else when the flow already implies an else. Listing 3.11 shows how return statements already imply the end of the code flow, eliminating the need for else.
Listing 3.11 Look, Ma, no elses!
public UpdateResult UpdateCityIfChanged() {
if (Id <= 0) {
return UpdateResult.InvalidId; ❶
}
bool isActive = db.IsPersonActive(Id);
if (!isActive) {
return UpdateResult.PersonInactive; ❶
}
if (FirstName is null || LastName is null) {
return UpdateResult.InvalidName; ❶
}
string normalizedFirstName = FirstName.ToUpper();
string normalizedLastName = LastName.ToUpper();
string currentCity = db.GetCurrentCityByName(
normalizedFirstName, normalizedLastName);
if (currentCity == City) {
return UpdateResult.CityDidNotChange; ❶
}
bool success = db.UpdateCurrentCity(Id, City);
if (!success) {
return UpdateResult.UpdateFailed; ❶
}
return UpdateResult.Success; ❶
}❶ No code runs after a return.
The technique used here is called following the happy path. The happy path in code is the part of the code that runs if nothing else goes wrong. It’s what ideally happens during execution. Since the happy path summarizes a function’s main work, it must be the easiest part to read. By converting the code in else statements into early return statements, we allow the reader to identify the happy path much more easily than having matryoshka dolls of if statements.
Validate early, and return as early as possible. Put the exceptional cases inside if statements, and try to put your happy path outside of the blocks. Familiarize yourself with these two shapes to make your code more readable and maintainable.
3.8.2 Use goto
The entire theory of programming can be summarized with memory, basic arithmetic, and if and goto statements. A goto statement transfers the execution of the program directly to an arbitrary destination point. They are hard to follow, and using them has been discouraged since Edsger Dijkstra wrote a paper titled “Go to statement is considered harmful” (https://dl.acm.org/doi/10.1145/362929.362947). There are many misconceptions about Dijkstra’s paper, first and foremost its title. Dijkstra titled his paper “A case against the GO TO statement,” but his editor, also the inventor of the Pascal language, Niklaus Wirth, changed the title, which made Dijkstra’s stance more aggressive and turned the war against goto into a witch hunt.
This all happened before the 1980s. Programming languages had ample time to create new constructs to address the functions of the goto statement. The for/while loops, return/break/continue statements, and even exceptions were created to address specific scenarios that were previously only possible with goto. Former BASIC programmers will remember the famous error-handling statement ON ERROR GOTO, which was a primitive exception-handling mechanism.
Although many modern languages don’t have a goto equivalent anymore, C# does, and it works great for a single scenario: eliminating redundant exit points in a function. It’s possible to use a goto statement in an easy-to-understand fashion and make your code less prone to bugs while saving you time. It’s like a three-combo hit on Mortal Kombat.
An exit point is each statement in a function that causes it to return to its caller. Every return statement is an exit point in C#. Eliminating exit points in the older era of programming languages was more important than it is now because manual cleanup was a more prominent part of a programmer’s daily life. You had to remember what you allocated and what you needed to clean up before you returned.
C# provides great tools for structured cleanup such as try/finally blocks and using statements. There may be cases where neither works for your scenario and you can use goto for cleanup too, but it actually shines more in eliminating redundancy. Let’s say we’re developing the shipment address entry form for an online shopping web page. Web forms are great for demonstrating the multilevel validation that happens with them. Assume that we’d like to use ASP.NET Core for that. That means we need to have a submit action for our form. Its code might look like that in listing 3.12. We have model validation that happens in the client, but at the same time, we need some server validation with our form so we can check whether the address is really correct using USPS API. After the check, we can try to save the information to the database, and if that succeeds, we redirect the user to the billing information page. Otherwise, we need to display the shipping address form again.
Listing 3.12 A shipping address form handling code with ASP.NET Core
[HttpPost]
public IActionResult Submit(ShipmentAddress form) {
if (!ModelState.IsValid) {
return RedirectToAction("Index", "ShippingForm", form); ❶
}
var validationResult = service.ValidateShippingForm(form);
if (validationResult != ShippingFormValidationResult.Valid) {
return RedirectToAction("Index", "ShippingForm", form); ❶
}
bool success = service.SaveShippingInfo(form);
if (!success) {
ModelState.AddModelError("", "Problem occurred while " +
"saving your information, please try again");
return RedirectToAction("Index", "ShipingForm", form); ❶
}
return RedirectToAction("Index", "BillingForm"); ❷
}I have already discussed some of the issues with copy-paste, but the multiple exit points in listing 3.12 pose another problem. Did you notice the typo in the third return statement? We accidentally deleted a character without noticing, and since it’s in a string, that bug is impossible to detect unless we encounter a problem when saving the form in the production or we build elaborate tests for our controllers. Duplication can cause problems in these cases. The goto statement can help you merge the return statements under a single goto label, as listing 3.13 shows. We create a new label for our error case under our happy path and reuse it at multiple places in our function using goto.
Listing 3.13 Merging common exit points into a single return statement
[HttpPost]
public IActionResult Submit2(ShipmentAddress form) {
if (!ModelState.IsValid) {
goto Error; ❶
}
var validationResult = service.ValidateShippingForm(form);
if (validationResult != ShippingFormValidationResult.Valid) {
goto Error; ❶
}
bool success = service.SaveShippingInfo(form);
if (!success) {
ModelState.AddModelError("", "Problem occurred while " +
"saving your shipment information, please try again");
goto Error; ❶
}
return RedirectToAction("Index", "BillingForm");
Error: ❷
return RedirectToAction("Index", "ShippingForm", form); ❸
}The great thing about this kind of consolidation is that if you ever want to add more in your common exit code, you only need to add it to a single place. Let’s say you want to save a cookie to the client when there is an error. All you need to do is to add it after the Error label, as shown next.
Listing 3.14 Ease of adding extra code to common exit code
[HttpPost]
public IActionResult Submit3(ShipmentAddress form) {
if (!ModelState.IsValid) {
goto Error;
}
var validationResult = service.ValidateShippingForm(form);
if (validationResult != ShippingFormValidationResult.Valid) {
goto Error;
}
bool success = service.SaveShippingInfo(form);
if (!success) {
ModelState.AddModelError("", "Problem occurred while " +
"saving your information, please try again");
goto Error;
}
return RedirectToAction("Index", "BillingForm");
Error:
Response.Cookies.Append("shipping_error", "1"); ❶
return RedirectToAction("Index", "ShippingForm", form);
}❶ The code that saves the cookie
By using goto, we actually kept our code style more readable with fewer indents, saved ourselves time, and made it easier to make changes in the future because we only have to change it once.
A statement like goto can still perplex a colleague who is not used to the syntax. Luckily, C# 7.0 introduced local functions that can be used to perform the same work, perhaps in a way that’s easier to understand. We declare a local function called error that performs the common error return operation and returns its result instead of using goto. You can see it in action in the next listing.
Listing 3.15 Using local functions instead of goto
[HttpPost]
public IActionResult Submit4(ShipmentAddress form) {
IActionResult error() { ❶
Response.Cookies.Append("shipping_error", "1");
return RedirectToAction("Index", "ShippingForm", form);
}
if (!ModelState.IsValid) {
return error(); ❷
}
var validationResult = service.ValidateShippingForm(form);
if (validationResult != ShippingFormValidationResult.Valid) {
return error(); ❷
}
bool success = service.SaveShippingInfo(form);
if (!success) {
ModelState.AddModelError("", "Problem occurred while " +
"saving your information, please try again");
return error(); ❷
}
return RedirectToAction("Index", "BillingForm");
}Using local functions also allows us to declare error handling at the top of the function, which is the norm with modern programming languages like Go, with statements like defer, although in our case, we have to explicitly call the error() function to execute it.
3.9 Don’t write code comments
A Turkish architect called Sinan lived in the sixteenth century. He built the famous Suleymaniye Mosque in Istanbul and countless other buildings. There is a story about his prowess in architecture. As the story goes, hundreds of years after Sinan passed, a group of architects started restoration work on one of his buildings. There was a keystone in one of the archways that they needed to replace. They carefully removed the stone block and found a small glass vial wedged between blocks that contained a note. The note said, “This keystone would last only three hundred years. If you’re reading this note, it must have broken down or you are trying to repair it. There is only one right way to put a new keystone back in correctly.” The note continued with the technical details of how to replace the keystone properly.
Sinan the architect could be the first person in history who used code comments correctly. Consider the opposite case where the building had writings everywhere on it. Doors would have the text, “This is a door.” Windows would have “Window” written over them. Between every brick there would be a glass vial with a note in it saying, “These are bricks.”
You don’t need to write code comments if your code is sufficiently self-explanatory. Conversely, you can hurt the readability of code with extraneous comments. Don’t write code comments just for the sake of writing comments. Use them wisely and only when necessary.
Consider the example in the next listing. If we had gone overboard with code comments, it could have looked like this.
Listing 3.16 Code comments everywhere!
/// <summary> /// Receive a shipment address model and update it in the /// database and then redirect the user to billing page if /// it's successful. ❶ /// </summary> /// <param name="form">The model to receive.</param> ❷ /// <returns>Redirect result to the entry form if /// there is an error, or redirect result to the /// billing form page if successful.</returns> [HttpPost] public IActionResult Submit(ShipmentAddress form) { ❷ // Our common error handling code that saves the cookie // and redirects back to the entry form for // shipping information. ❸ IActionResult error() { ❸ Response.Cookies.Append("shipping_error", "1"); ❸ return RedirectToAction("Index", "ShippingForm", form); ❸ } // check if the model state is valid ❹ if (!ModelState.IsValid) { ❹ return error(); } // validate the form with server side validation logic. ❺ var validationResult = service.ValidateShippingForm(form); ❺ // is the validation successful? ❻ if (validationResult != ShippingFormValidationResult.Valid) { ❻ return error(); } // save shipping information ❼ bool success = service.SaveShippingInfo(form); ❼ if (!success) { // failed to save. report the error to the user. ❽ ModelState.AddModelError("", "Problem occurred while " + ❽ "saving your information, please try again"); return error(); } // go to the billing form ❾ return RedirectToAction("Index", "BillingForm"); ❾ }
❶ These are already explained by the function’s context and declaration.
❷ These are already explained by the function’s context and declaration.
❸ Literally a repetition of the following code
❹ Again, completely unnecessary
❼ Really? We’ve come to this now?
The code we’re reading tells us a story even without the comments. Let’s go over the same code without comments and find the hidden hints in it (figure 3.13).

Figure 3.13 Reading hints in code
This might look like a lot of work. You’re trying to bring the pieces together just to understand what the code does. It does get better over time. You will spend less effort the better you get at it. There are things that you can do to improve the life of the poor soul who reads your code, and even yourself six months later, because after six months, it might as well be somebody else’s code.
3.9.1 Choose great names
I touched on the importance of good names at the beginning of this chapter, about how our names should represent or summarize the functionality as closely as possible. Functions shouldn’t have ambiguous names like Process, DoWork, Make, and so forth unless the context is absolutely clear. That might sometimes require you to type longer names than usual, but it’s usually possible to create good names and still keep them concise.
The same applies for variable names. Reserve single-letter variable names only for loop variables (i, j, and n) and coordinates like x, y, and z where they are obvious. Otherwise, always pick a descriptive name, and avoid abbreviations. It’s still okay to use well-known initialisms like HTTP and JSON or well-known abbreviations like ID and DB, but don’t shorten words. You only type the variable name once anyway. Code completion can take care of the rest later. The benefits of descriptive names are tremendous. Most importantly, they save you time. When you pick a descriptive name, you don’t have to write a full-sentence comment to explain it wherever it’s used. Consult the convention documentation of the programming language you’re using. Microsoft’s guideline for .NET naming conventions, for example, is a great starting point for C#: https:// docs.microsoft.com/en-us/dotnet/standard/design-guidelines/naming-guidelines.
3.9.2 Leverage functions
Small functions are easier to understand. Try to keep a function small enough to fit in a developer’s screen. Scrolling back and forth is terrible for understanding what a code does. You should be able to see everything the function does right in front of you.
How do you shorten a function? Beginners might be inclined to put as much as possible on a single line to make the function more compressed. No! Never put multiple statements on a single line. Always have at least one line per statement. You can even have blank lines in a function to group relevant statements together. In light of this, let’s look at our function in the next listing.
Listing 3.17 Using blank lines to separate logical parts of a function
[HttpPost]
public IActionResult Submit(ShipmentAddress form) {
IActionResult error() { ❶
Response.Cookies.Append("shipping_error", "1"); ❶
return RedirectToAction("Index", "ShippingForm", form); ❶
} ❶
if (!ModelState.IsValid) { ❷
return error(); ❷
} ❷
var validationResult = service.ValidateShippingForm(form); ❸
if (validationResult != ShippingFormValidationResult.Valid) { ❸
return error(); ❸
} ❸
bool success = service.SaveShippingInfo(form); ❹
if (!success) { ❹
ModelState.AddModelError("", "Problem occurred while " + ❹
"saving your information, please try again"); ❹
return error(); ❹
} ❹
return RedirectToAction("Index", "BillingForm"); ❹
}❸ Server-side model validation part
❹ Saving part and the successful case
You may ask how this helps make the function smaller. Yes, in fact, it makes the function bigger. But identifying logical parts of a function lets you refactor those parts into meaningful functions, which is the key to having small functions and descriptive code at the same time. You can refactor the same code into even more digestible chunks if the logic isn’t straightforward enough to understand. In listing 3.18, we extract parts of the logic in our Submit function by using what we identified as logical parts. We basically have a validation part, an actual saving part, a save-error-handling part, and a successful response. We only leave those four parts in the body of the function.
Listing 3.18 Keeping only the descriptive functionality in the function
[HttpPost]
public IActionResult Submit(ShipmentAddress form) {
if (!validate(form)) { ❶
return shippingFormError();
}
bool success = service.SaveShippingInfo(form); ❷
if (!success) { ❸
reportSaveError();
return shippingFormError();
}
return RedirectToAction("Index", "BillingForm"); ❹
}
private bool validate(ShipmentAddress form) {
if (!ModelState.IsValid) {
return false;
}
var validationResult = service.ValidateShippingForm(form);
return validationResult == ShippingFormValidationResult.Valid;
}
private IActionResult shippingFormError() {
Response.Cookies.Append("shipping_error", "1");
return RedirectToAction("Index", "ShippingForm", form);
}
private void reportSaveError() {
ModelState.AddModelError("", "Problem occurred while " +
"saving your information, please try again");
}The actual function is so simple that it almost reads like an English sentence—well, maybe a hybrid of English and Turkish, but still very readable. We achieved greatly descriptive code without writing a single line of comment, and that’s the key you need to keep in mind if you ever ask if it’s too much work. It’s less work than writing paragraphs of comments. You’ll also thank yourself by shaking your left hand with your right hand when you learn that you don’t need to keep comments and the actual code in sync for the comments to remain useful over the lifetime of the project. This is way better.
Extracting functions may look like a chore, but it’s in fact a breeze with development environments like Visual Studio. You just select the part of the code that you want to extract and press Ctrl-. (the period key) or choose the light bulb icon appearing next to the code and select Extract Method. All you need to do is to give it a name.
When you extract those pieces, you also open a door to reusing those pieces of code in the same file, which can save you time when you’re writing a billing form if the error-handling semantics aren’t any different.
This all may sound like I’m against code comments. It’s exactly the opposite. Avoiding unnecessary comments makes useful comments shine like jewels. It’s the only way to make comments useful. Think like Sinan when you’re writing comments: “Will someone need an explanation for this?” If it needs an explanation, be as clear as possible, be elaborate, even draw ASCII diagrams if necessary. Write as many paragraphs as you need, just so the developers working on the same code don’t have to come to your desk and ask you what that piece of code does or fix it incorrectly because you forgot to explain yourself. It comes down to you to fix the code correctly when the production goes down. You owe this to yourself as much as to everybody else.
There are cases where you must write comments whether they are useful or not, such as public APIs, because users may not have access to the code. But that also doesn’t mean that having written comments makes your code easy to understand. You still need to write clean code with small, easy-to-digest pieces.
Summary
-
Avoid creating rigid code by avoiding violating logical dependency boundaries.
-
Don’t be afraid of doing a job from scratch because the next time you do it, it’ll go much faster.
-
Break the code when there are dependencies that might tie your shoelaces together in the future, and fix it.
-
Avoid digging yourself a legacy hole by keeping the code up to date and fixing the problems it causes regularly.
-
Repeat the code instead of reusing it to avoid violating logical responsibilities.
-
Invent smart abstractions so the future code you write takes less time. Use abstractions as investments.
-
Don’t let the external libraries you use dictate your design.
-
Prefer composition over inheritance to avoid binding your code to a specific hierarchy.
-
Try to keep a code style that is easy to read from the top down.
-
Use
gotoor, even better, a local function to keep common code in one place. -
Avoid frivolous, redundant code comments that make it impossible to distinguish the tree from the forest.
-
Write self-descriptive code by leveraging good naming for variables and functions.
-
Divide functions into easy-to-digest sub-functions to keep the code as descriptive as possible.
1. Hacker News is a tech news-sharing platform where everyone is an expert about everything: https:// news.ycombinator.com.
2. The chat app called Yo in which you could only send a text containing “Yo” was once valued at $10 million. The company got shut down in 2016: https://en.wikipedia.org/wiki/Yo_(app).
3. This is Leon Bambrick’s excellent variation (https://twitter.com/secretGeek/status/7269997868) of the famous quote by Phil Karlton, who said it without the “off-by-one errors” part.