
9 Living with bugs
- Error handling best practices
- Living with bugs
- Intentional error handling
- Avoiding debugging
- Advanced rubber-duck debugging
The most profound work of literature on bugs is Metamorphosis by Franz Kafka. It tells the story of Gregor Samsa, a software developer, who wakes up one day to find out that he is actually the only bug. Well, he isn’t actually a software developer in the story because the entire practice of programming in 1915 only consisted of a couple of pages of code Ada Lovelace wrote 70 years before Kafka wrote his book. But Gregor Samsa’s profession was the next best thing to a software developer: he was a traveling salesperson.
Bugs are basic units of metrics for determining software quality. Because software developers consider every bug a stain on the quality of their craftsmanship, they usually either aim for zero bugs or actively deny their existence by claiming that it works on their computer or that it’s a feature, not a bug.
Software development is immensely complex because of the inherent unpredictability of a program. That’s the nature of a Turing machine, a theoretical construct that all computers and most programming languages are based on, thanks to the works of Alan Turing. A programming language based on a Turing machine is called Turing complete. Turing machines allow the infinite levels of creativity we have with software, but it’s just impossible to verify their correctness without executing them. Some languages depend on a non-Turing complete machine, such as HTML, XML, or regular expressions that are way less capable than Turing complete languages. Because of the nature of a Turing machine, bugs are inevitable. It’s impossible to have a bug-free program. Accepting this fact before you set out to develop software will make your job easier.
9.1 Don’t fix bugs
A development team must have a triaging process for deciding which bugs to fix for any sizable project. The term triaging originated during World War I, when medics had to decide which patients to treat and which to leave unattended to allocate their limited resources for those who still had a chance of surviving. It’s the only way to effectively utilize a scarce resource. Triaging helps you decide what you need to fix first or whether you should fix it at all.
How do you prioritize a bug? Unless you’re just a single person driving all the business decisions, your team needs to have shared criteria to determine the priority of a given bug. On the Windows team at Microsoft, we had a complicated set of criteria to decide which bugs to fix as assessed by multiple engineering authorities. Consequently, we had daily meetings to prioritize bugs and debated, in a place called the War Room, whether a bug was worth fixing. That’s understandable for a product with such an immense scale like Windows, but it may be unnecessary for most software projects. I had to ask for prioritization of a bug because an automated system at an official marriage center in Istanbul was broken after an update and all marriage ceremonies had to stop. I had to make my case by breaking down being unable to marry into tangible metrics like applicability, impact, and severity. “How many couples get married in a day in Istanbul?” suddenly sounded like a meaningful interview question.
A simpler way to assess priority could be by using a tangential second dimension called severity. Although the goal is essentially to have a single priority, having a secondary dimension can make assessment easier when two different issues seemingly have the same priority. I find priority/severity dimensions handy and a good balance between business-oriented and technology-oriented. Priority is the business impact of a bug, while severity is the impact on the customer. For example, if a web page on your platform isn’t working, it’s a high severity issue because the customer can’t use it. But its priority might be entirely different depending on whether it’s on the home page or an obscure page only a few customers visit. Similarly, if your business logo on your home page goes missing, it might have no severity at all, yet it can have the topmost business priority. The severity dimension takes some load off business prioritization because it’s impossible to come up with accurate metrics to prioritize bugs.
Couldn’t we achieve the same level of granularity with a single priority dimension? For example, instead of having three priority and severity levels, wouldn’t just six priority levels do the same job? The problem is that the more levels you have, the more difficult it becomes to differentiate between them. Usually, a secondary dimension helps you come up with a more accurate assessment of the importance of an issue.
You should have a threshold for priority and severity so that any bugs that rank below it are categorized as won’t fix. For example, any bug that has both low priority and low severity can be considered a won’t fix and can be taken off your radar. Table 9.1 shows the actual meanings of priority and severity levels.
Table 9.1 Actual meanings of priority and severity
|
Won’t fix. Never fix these unless there’s nothing else to do at the office. In that case, let the intern fix it. |
Tracking bugs incurs costs, too. At Microsoft, it took our team at least an hour a day just to assess the priority of bugs. It’s imperative for your team to avoid revisiting bugs that aren’t ever likely to be fixed. Try to decide on that earlier in the process. It gains you time, and it still ensures you maintain decent product quality.
9.2 The error terror
Not every bug is caused by an error in your code, and not every error implies the existence of a bug in your code. This relationship between bugs and errors is most evident when you see a pop-up dialogue that says, unknown error. If it’s an unknown error, how can you be so sure that it’s an error in the first place? Maybe it’s an unknown success!
Such situations are rooted in the primitive association between errors and bugs. Developers instinctively treat all errors as bugs and try to eliminate them consistently and insistently. That kind of reasoning usually leads to an unknown error situation because something has gone wrong, and the developer just doesn’t care to understand whether it’s an error. This understanding makes developers treat all kinds of errors the same way, usually either by reporting every error regardless of whether the user needs to see them or by hiding them all and burying them inside a log file on a server that no one will ever bother to read.
The solution to that kind of obsession with treating all errors the same way is to consider them part of your state. Perhaps it was a mistake to call them errors. We should have just called them uncommon and unexpected state changes or exceptions. Oh wait, we already have those!
9.2.1 The bare truth of exceptions
Exceptions may be the most misunderstood construct in the history of programming. I can’t even count the times I’ve seen someone simply put their failing code inside a try block followed with an empty catch block and call it good. It’s like closing the door to a room that’s on fire and assuming the problem will sort itself out eventually. It’s not a wrong assumption, but it can be quite costly.
Listing 9.1 The solution to all of life’s problems
try {
doSomethingMysterious();
}
catch {
// this is fine
}I don’t blame programmers for that, either. As Abraham Maslow said in 1966, “If the only tool you have is a hammer, you tend to see every problem as a nail.” I’m sure when the hammer was first invented, it was the next big thing, and everybody tried to adopt it in their solution process. Neolithic people probably published blog posts using hand markings on cave walls about how revolutionary the hammer was and how it could make problems go away, without knowing that better tools would emerge in the future for spreading butter on bread.
I’ve seen instances where the developer added a generic exception handler for the whole application that actually ignores all exceptions, preventing all crashes. Then why do we keep getting bugs? We would have solved the bug problem a long time ago if adding an empty handler was the cure.
Exceptions are a novel solution to the undefined state problem. In the days when error handling was only done with return values, it was possible to omit handling the error, assume success, and continue running. That would put the application in a state the programmer never anticipated. The problem with an unknown state is that it’s impossible to know the effects of that state or how serious they can be. That’s pretty much the sole reason behind operating system fatal error screens, like the kernel panic on UNIX systems or the infamous Blue Screen of Death on Windows. They halt the system to prevent potential further damage. Unknown state means that you can’t predict what will happen next anymore. Yes, the CPU might just freak out and enter an infinite loop, or the hard disk drive might decide to write zeros on every sector, or your Twitter account might decide to publish random political opinions in all caps.
Error codes are different from exceptions in that it’s possible to detect if exceptions aren’t handled during runtime—not so with error codes. The usual recourse for unhandled exceptions is to terminate the application because the given state isn’t anticipated. Operating systems do the same thing: they terminate the application if it fails to handle an exception. They can’t do the same for device drivers or kernel-level components because they don’t run in isolated memory spaces, unlike user mode processes. That’s why they must halt the system completely. That’s less of a problem with microkernel-based operating systems because the number of kernel-level components is minimal and even device drivers run in user space, but that has a slight performance penalty that we haven’t come to terms with yet.
The greatest nuance we’re missing about exceptions is the fact that they’re exceptional. They’re not for generic flow control; you have result values and flow control constructs for that. Exceptions are for cases when something happens outside a function’s contract and it can’t fulfill its contract anymore. A function like (a,b) => a/b guarantees performing a division operation, but it can’t do that when b’s value is 0. It’s an unexpected and undefined case.
Suppose you download software updates for your desktop app, store the downloaded copy on disk, and switch your app with the newly downloaded one when the user starts your app the next time. That’s a common technique for self-updating apps outside a package management ecosystem. An update operation would look like figure 9.1. This is a bit naive because it doesn’t take half-finished updates into account, but that’s the whole point.
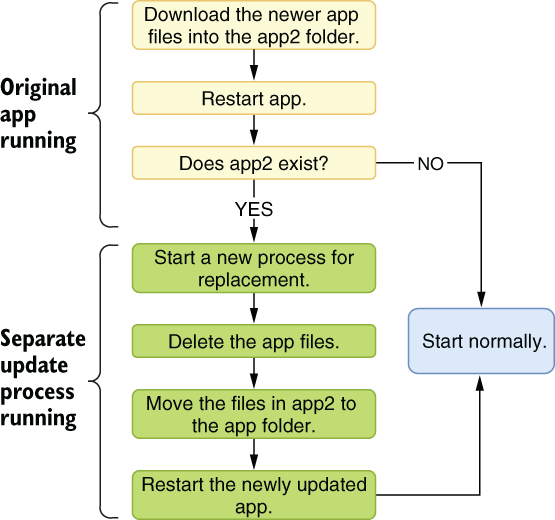
Figure 9.1 Some primitive logic for a self-updating app
If any exception is raised at any point during the self-update, you’d get an incomplete app2 folder that would cause the app files to be replaced with a broken version, causing a catastrophic state that’s impossible to recover from.
At every step, you can encounter an exception, and that might cause everything to fall apart if it’s not handled, or if it’s handled incorrectly. The figure also shows the importance of how your process design should be resilient against exceptions. Any failure at any step could leave your app in a corrupt state, never to be recovered. You shouldn’t leave the app in a dirty state even when an exception occurs.
9.2.2 Don’t catch exceptions
Try/catch blocks are considered quick and easy patches for code that crashes because of an exception. Ignoring an exception makes the crash disappear, but it doesn’t make the root cause go away.
Exceptions are supposed to cause crashes because that’s the easiest way to identify the problem without causing further problems. Don’t be afraid of crashes. Be afraid of bugs that don’t cause clean crashes along with a convenient stack trace that helps you pinpoint the exact place where it happened. Be afraid of problems that are hidden by empty catch statements, lurking in the code and disguised as a mostly correct-looking state, slightly accumulating a bad state over a long time, and finally causing either a noticeable slowdown or a completely irrelevant-looking crash, like an OutOfMemoryException. Unnecessary catch blocks can prevent some crashes, but they might cost you hours in reading logs. Exceptions are great because they let you catch a problem before it becomes a hard-to-catch issue.
The first rule of exception handling is, you don’t catch an exception. The second rule of exception handling is IndexOutOfRangeException at Street Coder chapter 9.
See what happens when you have only one rule? Don’t catch an exception because it causes a crash. If it’s caused by an incorrect behavior, fix the bug that causes it. If it’s caused by a known possibility, put explicit handling statements in the code for that specific case.
Whenever there is a possibility of getting an exception at some point in the code, ask yourself, “Do I have a specific recourse planned for this exception, or do I just want to prevent a crash?” If it’s the latter, handling that exception may not be necessary and may be even harmful because blindly handling an exception can hide a deeper, more serious problem with your code.
Consider the self-updating application I mentioned in section 9. 2.1. It could have a function that downloads a series of application files into a folder, as shown in listing 9.2. We need to download two files from our update server, assuming they are the latest versions. Obviously, there are many problematic issues with that approach, like not using a central registry to identify the latest version and downloading that specific version. What happens if I start downloading an update while the developers are in the middle of updating remote files? I’d get half of the files from the previous version and half from the next version, causing a corrupt installation. For the sake of our example, let’s assume the developers shut down the web server before an update, update the files, and turn it back on after it’s complete, preventing such a screw-up.
Listing 9.2 Code for downloading multiple files
private const string updateServerUriPrefix =
"https://streetcoder.org/selfupdate/";
private static readonly string[] updateFiles =
new[] { "Exceptions.exe", "Exceptions.app.config" }; ❶
private static bool downloadFiles(string directory,
IEnumerable<string> files) {
foreach (var filename in updateFiles) {
string path = Path.Combine(directory, filename);
var uri = new Uri(updateServerUriPrefix + filename);
if (!downloadFile(uri, path)) {
return false; ❷
}
}
return true;
}
private static bool downloadFile(Uri uri, string path) {
using var client = new WebClient();
client.DownloadFile(uri, path); ❸
return true;
}❶ The list of files to be downloaded
❷ We detect a problem with download and signal cleanup.
❸ Download an individual file.
We know that DownloadFile can throw exceptions for various reasons. Actually, Microsoft has great documentation for the behavior of .NET functions, including which exceptions they can throw. There are three exceptions that WebClient’s DownloadFile method can throw:
-
WebExceptionwhen something unexpected happens during a download, like a loss of internet connection -
NotSupportedExceptionwhen the sameWebClientinstance is called from multiple threads to signify that the class itself isn’t thread-safe
To prevent an unpleasant crash, a developer might choose to wrap the call to DownloadFile in a try / catch, so the downloads would continue. Because many developers wouldn’t care about which types of exceptions to catch, they just do it with an untyped catch block. We introduce a result code so we can detect whether an error has occurred.
Listing 9.3 Preventing crashes by creating more bugs
private static bool downloadFile(Uri uri, string path) {
using var client = new WebClient();
try {
client.DownloadFile(uri, path);
return true;
}
catch {
return false;
}
}The problem with that approach is that you catch all three possible exceptions, two of which actually point to a definite programmer error. ArgumentNullException only happens when you pass an invalid argument and the caller is responsible for it, meaning there’s either bad data or bad input validation somewhere in the call stack. Similarly, NotSupportedException is only raised when you misuse the client. That means you’re hiding many potentially easy-to-fix bugs that might lead to even more serious consequences by catching all exceptions. No, despite what some magic animal slavery ring might dictate, you don’t gotta catch ’em all. If we didn’t have a return value, a simple argument error would cause files to be skipped, and we wouldn’t even know if they were there. You should instead catch a specific exception that’s probably not a programmer error, as listing 9.4 shows. We only catch WebException, which is, in fact, expected because you know a download can fail any time for any reason, so you want to make it part of your state. Catch an exception only when it’s expected. We let other types of exceptions cause a crash because it means we were stupid and we deserve to live with its consequences before it causes a more serious problem.
Listing 9.4 Precise exception handling
private static bool downloadFile(Uri uri, string path) {
using var client = new WebClient();
try {
client.DownloadFile(uri, path);
return true;
}
catch (WebException) { ❶
return false;
}
}❶ You don’t gotta catch ’em all.
That’s why code analyzers suggest that you avoid using untyped catch blocks, because they are too broad, causing irrelevant exceptions to be caught. Catchall blocks should only be used when you really mean catching all the exceptions in the world, probably for a generic purpose like logging.
9.2.3 Exception resiliency
Your code should work correctly even without handling exceptions, even when it’s crashed. You should design a flow that works fine even when you constantly get exceptions, and you shouldn’t enter a dirty state. Your design should tolerate exceptions. The main reason is that exceptions are inevitable. You can put a catchall try/catch in your Main method, and your app would still be terminated unexpectedly when new updates cause a restart. You shouldn’t let exceptions break your application’s state.
When Visual Studio crashes, the file you were changing at that moment doesn’t go missing. You get reminded about the missing file when you start the application again, and you’re offered an option to recover the missing file. Visual Studio manages that by constantly keeping a copy of unsaved files at a temporary location and deleting one when the file is actually saved. At startup, it checks for the existence of those temporary files and asks if you want to recover them. You should design your code to anticipate similar problems.
In our self-updating app example, your process should allow exceptions to happen, and recover from them when the app’s restarted. An exception-resilient design for our self-updater would look like figure 9.2, in which instead of downloading individual files, we download a single atomic package, which prevents us from getting an inconsistent set of files. Similarly, we back up original files before replacing them with new ones so we can recover in case something goes wrong.
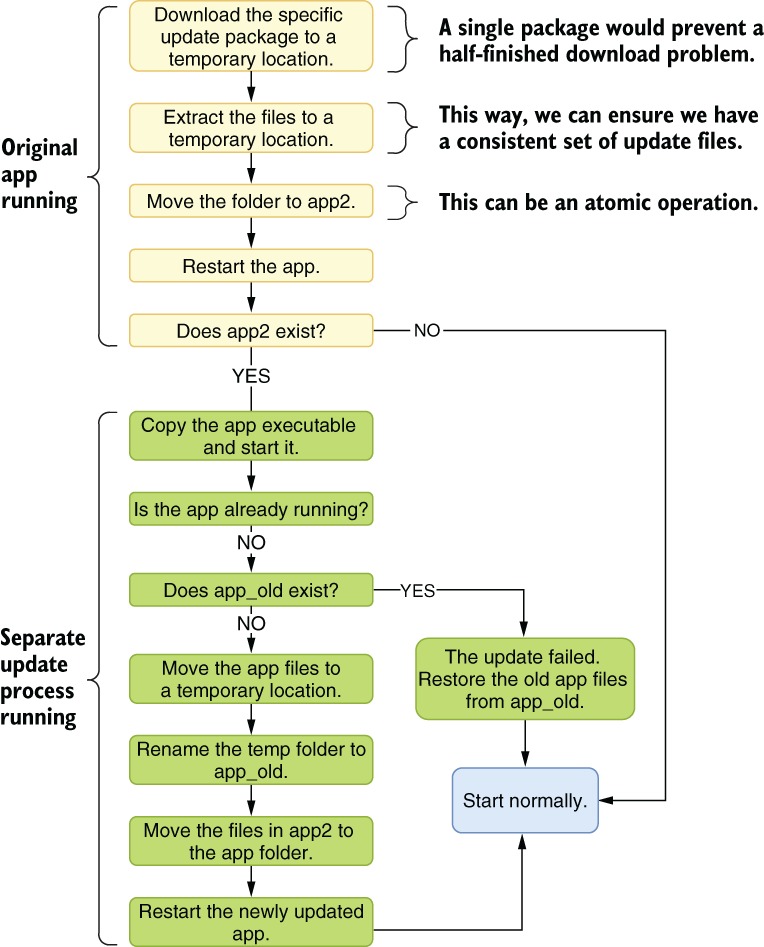
Figure 9.2 A more exception-resilient version of our self-updating app
How much time it takes to install updates on our devices hints that the software update is complicated, and I’m sure I’ve missed many cases where this design can fail. However, you can apply similar techniques to prevent a bad state in your app.
Achieving exception-resilient design starts with idempotency. A function, or a URL, is idempotent if it returns the same result regardless of how many times it’s called. That might sound trivial for a pure function like Sum(), but it gets more complicated with functions that modify external state. An example is the checkout process of online shopping platforms. If you accidentally click the Submit Order button twice, does your credit card get charged twice? It shouldn’t. I know that some websites try to fix this by putting up a warning like “Don’t click the button twice!” but as you know, most cats walking on the keyboard are illiterate.
Idempotency is usually thought of in a simplified manner for web requests like “HTTP GET requests should be idempotent and anything non-idempotent should be a POST request.” But GET requests may not be idempotent, say, for content with dynamically changing parts; or a POST request can be idempotent, like an upvote operation: multiple upvotes for the same content shouldn’t change the number of times the users have upvoted for the same content.
How does this help us become exception resilient? When we design our function to have consistent side effects regardless of how many times it’s called, we also gain some consistency benefits for when it gets interrupted unexpectedly. Our code becomes safely callable multiple times without causing any problems.
How do you achieve idempotency? In our example, you can have a unique order-processing number, and you can create a record on the DB as soon as you start processing the order and check its existence at the start of your processing function, as figure 9.3 shows. The code needs to be thread-safe, because some cats can walk really fast. DB transactions can help you avoid a bad state because they’re rolled back if they somehow cut off because of an exception, but they may not be necessary for many scenarios.
In figure 9.3, we define an order status change operation, but how do we ensure that we do it atomically? What if somebody else changes it before we read the result? The secret is to use a conditional update operation for the database that makes sure the status is the same as the expected one. It might look like this:
UPDATE orders SET status=@NewState WHERE id=@OrderID status=@CurrentState
UPDATE returns the number of rows affected, so if the state changed during the UPDATE operation, the operation itself would fail and it would return 0 as the number of rows affected. If the state change is successful, it would return 1. You can use this to atomically update the record state changes, as shown in figure 9.3.
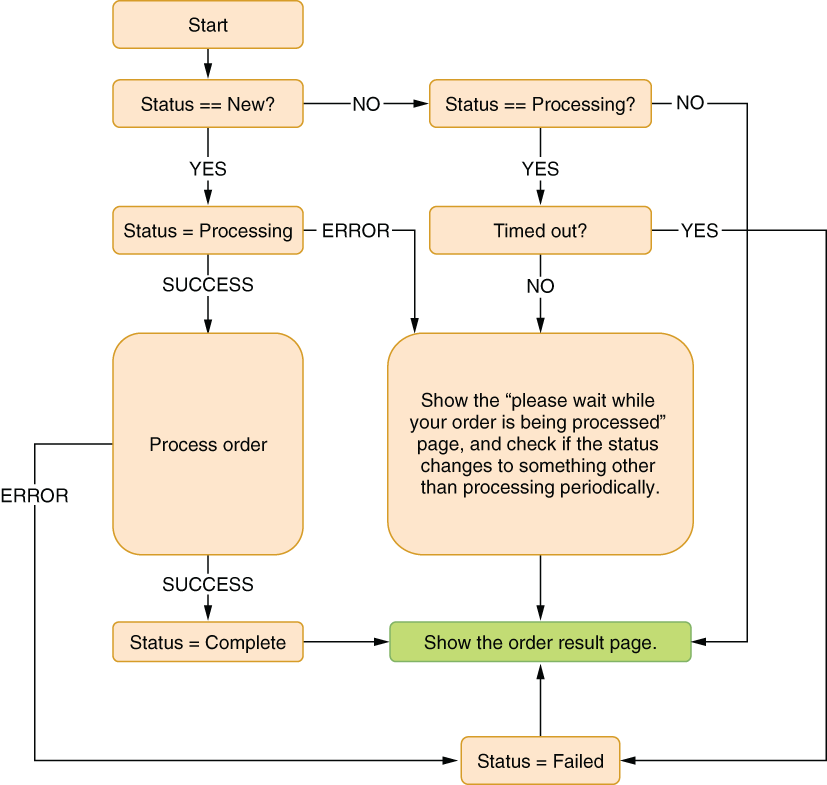
Figure 9.3 An idempotent example of order submission
An implementation example would look like listing 9.5. We define every individual state the order can be in throughout order processing and enable our processing to handle the situation at different levels of processing. If it’s already being processed, we just show the still-processing page and expire the order if it times out.
Listing 9.5 Idempotent order processing
public enum OrderStatus {
New,
Processing,
Complete,
Failed,
}
[HttpPost]
public IActionResult Submit(Guid orderId) {
Order order = db.GetOrder(orderId);
if (!db.TryChangeOrderStatus(order, from: OrderStatus.New, ❶
to: OrderStatus.Processing)) {
if (order.Status != OrderStatus.Processing) {
return redirectToResultPage(order);
}
if (DateTimeOffset.Now - order.LastUpdate > orderTimeout) { ❷
db.ChangeOrderStatus(order, OrderStatus.Failed);
return redirectToResultPage(order);
}
return orderStatusView(order); ❸
}
if (!processOrder(order)) {
db.ChangeOrderStatus(order, OrderStatus.Failed);
} else {
db.TryChangeOrderStatus(order, ❹
from: OrderStatus.Processing, ❹
to: OrderStatus.Complete); ❹
}
return redirectToResultPage(order);
}❶ Try changing status atomically.
❹ If it fails, the result page will show the correct outcome.
Despite that being an HTTP POST request, the order submission is perfectly okay to be called multiple times without causing any unwanted side effects, and therefore, it’s idempotent. If your web app crashes and you restart your application, it can still recover from many invalid states, such as a processing state. Order processing can be more complicated than this, and it might require external periodic cleanup work for certain cases, but you can still have great resiliency against exceptions, even with no catch statements whatsoever.
9.2.4 Resiliency without transactions
Idempotency may not be enough for exception resiliency, but it provides a great foundation because it encourages us to think about how our function would behave at different states. In our example, the process-order step may cause exceptions and leave a dirty state around for a given order, preventing the same step from being called again. Normally, transactions protect against that because they roll back all the changes without leaving any dirty data behind. But not every storage has transaction support—file systems, for example.
You still have options even when transactions aren’t available. Suppose you created an image-sharing app where people can upload albums and share them with their friends. Your content delivery network (CDN, a nifty name for file servers) could have a folder for each album with image files underneath, and you’d have album records in a database. It’s quite impractical to wrap the operation of building these in a transaction because it spans multiple technologies.
The traditional approach to creating an album is to create the album record first, create the folder, and finally upload the images to the folder based on this information. But if an exception is raised anywhere in the process, you would get an album record with some of the pictures missing. This problem applies to pretty much all kinds of interdependent data.
You have multiple options to avoid this problem. In our album example, you can create the folder for images first at a temporary location, move the folder to a UUID created for the album, and finally create the album record as the last operation in the process. This way, users would never browse albums that are half complete.
Another option would be to create the album record first with a status value that specifies that the record is inactive and then add the rest of the data. You can finally change the status of the album record to active when the insertion operation is complete. This way, you wouldn’t get duplicate album records when exceptions interrupt the upload process.
In both cases, you can have periodic cleanup routines that can sweep records that are abandoned and remove them from the DB. With a traditional approach, it’s hard to know whether a resource is valid or a remnant from an interrupted operation.
9.2.5 Exceptions vs. errors
It can be argued that exceptions signify errors, and that may be true, but not all errors are qualified to be exceptions. Don’t use exceptions for cases where you expect the caller to handle it most of the time. That’s not an exceptional situation. A very familiar example is Parse versus TryParse in .NET, where the former throws an exception on invalid input, while the latter just returns false.
There was only Parse once. Then came TryParse in .NET Framework 2.0 because invalid input turned out to be common and expected in most scenarios. Exceptions are an overhead in those cases because they’re slow. That’s because they need to carry the stack trace with them, which requires walking the stack in the first place to gather stack trace information. That can be very expensive compared to simply returning a Boolean value. Exceptions are also harder to handle because you need all the try/catch ceremony, while a simple result value only needs to be checked with an if, as shown in the following listing. You can see that an implementation with try/catch involves more typing, it’s harder to implement correctly because the developer can easily forget to keep its exception handler specific to FormatException, and the code is harder to follow.
Listing 9.6 A tale of two parses
public static int ParseDefault(string input, ❶ int defaultValue) { try { return int.Parse(input); } catch (FormatException) { ❷ return defaultValue; } } public static int ParseDefault(string input, ❸ int defaultValue) { if (!int.TryParse(input, out int result)) { return defaultValue; } return result; }
❷ It’s tempting to omit the exception type here.
❸ Implementation with TryParse
Parse still has its place when you expect the input to always be correct. If you’re sure that the input value is always correctly formatted, and any invalid value is actually a bug, you do want an exception to be thrown. It’s a dare in a way, because then you’re sure that an invalid input value is a bug. “Crash if you can!”
Regular error values are good enough to return responses most of the time. It’s even okay not to return anything if you have no use for the return value. For example, if you expect an upvote operation to always be successful, don’t have a return value. The function’s return already signifies success.
You can have different types of error results based on how much you expect the caller needs the information. If the caller only cares about success or failure and not the details, returning a bool is perfectly fine, with true signifying success; false, on the other hand, is failure. If you have a third state or you’re using bool already to specify something else, then you might need a different approach.
For example, Reddit has voting functionality, but only if the content’s recent enough. You can’t vote on comments or posts that are older than six months. You also can’t vote on deleted posts. That means voting can fail in multiple ways, and that difference might need to be communicated to the user. You can’t just say “voting failed: unknown error ” because the user might think it’s a temporary problem and keep trying. You have to say, “This post is too old ” or “This post is deleted,” so the user learns about that specific platform dynamic and stops trying to vote. A better user experience would be to hide the voting buttons so the user would immediately know they can’t vote on that post, but Reddit insists on showing them.
In Reddit’s case, you can simply use an enum to differentiate between different failure modes. A possible enum for a Reddit voting result could look like listing 9.7. That may not be comprehensive, but we don’t need additional values for other possibilities because we don’t have any plans for them. For example, if voting fails because of a DB error, that must be an exception, not a result value. It points to either an infrastructure failure or a bug. You want your call stack; you want it to be logged somewhere.
Listing 9.7 Voting result for Reddit
public enum VotingResult {
Success,
ContentTooOld,
ContentDeleted,
}The great thing about enums is that the compiler can warn you about unhandled cases when you use switch expressions. You get a warning for cases you didn’t handle because they’re not exhaustive enough. The C# compiler can’t do the same for switch statements, only for switch expressions because they’re newly added to the language and can be designed for these scenarios. A sample exhaustive enum handling for an upvote operation might look like the following listing. You might still get a separate warning for the switch statement not being exhaustive enough because, in theory, you can assign invalid values to enums due to initial design decisions made for the C# language.
Listing 9.8 Exhaustive enum handling
[HttpPost]
public IActionResult Upvote(Guid contentId) {
var result = db.Upvote(contentId);
return result switch {
VotingResult.Success => success(),
VotingResult.ContentTooOld
=> warning("Content is too old. It can't be voted"),
VotingResult.ContentDeleted
=> warning("Content is deleted. It can't be voted"),
};
}9.3 Don’t debug
Debugging is an ancient term; it even predates programming, before Grace Hopper made it popular in the 1940s by finding an actual moth in the relays of a Mark II computer. It was originally used in aeronautics for processes that identified aircraft faults. It is now being replaced by Silicon Valley’s more advanced practice of firing the CEO whenever a problem is discovered after the fact.
The modern understanding of debugging mostly implies running the program under a debugger, putting breakpoints, tracing the code step by step, and examining the state of the program. Debuggers are very handy, but they’re not always the best tools. It can be very time consuming to identify the root cause of a problem. It may not be even possible to debug a program in all circumstances. You may not even have access to the environment the code is running.
9.3.1 printf() debugging
Inserting console output lines inside your program to find a problem is an ancient practice. We developers have since gotten fancy debuggers with step-by-step debugging features, but they aren’t always the most efficient tools for identifying the root cause of a problem. Sometimes, a more primitive approach can work better to identify an issue. printf() debugging gets its name from the printf() function in the C programming language. Its name stands for print formatted. It’s quite similar to Console.WriteLine(), albeit with a different formatting syntax.
Checking the state of the application continuously is probably the oldest way to debug programs. It even predates computer monitors. Older computers were equipped with lights on their front panels that actually showed the bit states of the registers of the CPU, so programmers could understand why something didn’t work. Luckily for me, computer monitors were invented before I was born.
printf() debugging is a similar way to show the state of the running program periodically, so the programmer can understand where the issue happens. It’s usually frowned on as a newbie technique, but it can be superior to step-by-step debugging for several reasons. For example, the programmer can pick a better granularity for how frequently the state should be reported. With step-by-step debugging, you can only set breakpoints at certain places, but you can’t really skip more than a single line. You either need a complicated breakpoint setup, or you just need to press the Step Over key tediously. It can get quite time consuming and boring.
More importantly, printf() or Console.WriteLine() writes the state to the console terminal that has history. That’s significant since you can build a chain of reasoning between different states by looking at your terminal output, which is something you can’t do with a step-by-step debugger.
Not all programs have visible console output, web applications, or services. .NET has alternatives for those environments, primarily Debug.WriteLine() and Trace.WriteLine(). Debug.WriteLine() writes the output to the debugger output console, which is shown in the debugger output window on Visual Studio instead of the application’s own console output. The greatest benefit of Debug.WriteLine is that calls to it get stripped completely from optimized (release) binaries, so they don’t affect the performance of the released code.
That, however, is a problem for debugging production code. Even if the debug output statements had been kept in the code, you’d have no practical way to read them. Trace.WriteLine() is a better tool in that sense because .NET tracing can have runtime configurable listeners apart from the usual output. You can have trace output written to a text file, an event log, an XML file, and anything you can imagine with the right component installed. You can even reconfigure tracing while the application is running, thanks to .NET’s magic.
It’s easy to set up tracing, so you can enable it while your code is running. Let’s consider an example, a live, running web application where we might need to enable tracing while it’s running to identify a problem.
9.3.2 Dump diving
Another alternative to step-by-step debugging is to examine crash dumps. While they’re not necessarily created after a crash, crash dumps are files that contain the contents of the snapshot of the memory space of a program. They’re also called core dumps on UNIX systems. You can manually create crash dumps with a right-click on a process name on Windows Task Manager and then clicking on Create Dump File, as shown in figure 9.4. That’s a non-invasive operation that would only pause the process until the operation is complete, but would keep the process running after.
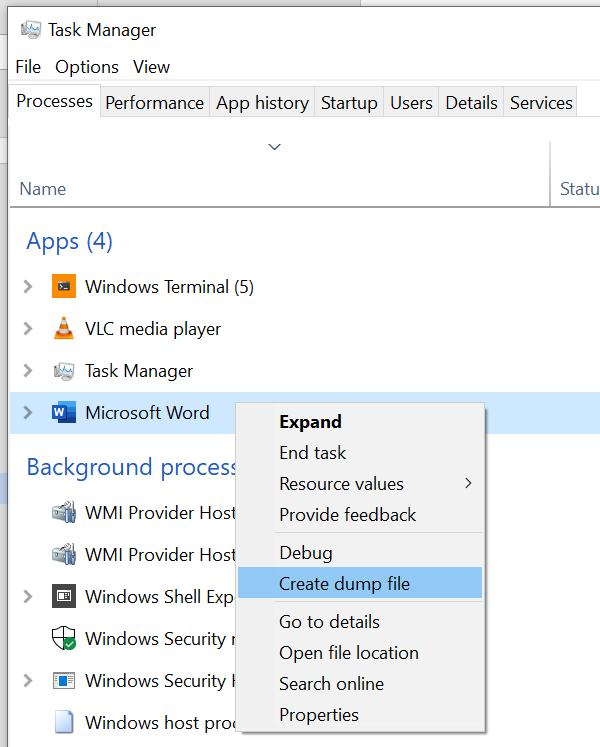
Figure 9.4 Manually generate a crash dump on a running application.
You can perform the same kind of smooth core dumping on UNIX variants without killing the app, but it’s slightly more involved. It requires you to have the dotnet dump tool installed:
dotnet tool install --global dotnet-dump
The tool’s great for analyzing crash dumps, so it’s a good idea to have it installed even on Windows. The installation command is the same for Windows.
There is a project on GitHub, under the examples for this chapter, called InfiniteLoop that consumes CPU continuously. That could be our web application or our service running on a production server, and it’s a good exercise to try to identify a problem on such a process. It’s pretty much like honing your lock-picking skills on a dummy lock. You might not think you need lock-picking skills, but wait until you hear about a locksmith’s fees. The whole code of the application is shown in listing 9.9. We basically run a multiplication operation in a loop continuously without any benefit to world peace. It probably still wastes way less energy than Bitcoin. We’re using random values determined in the runtime to prevent the compiler from accidentally optimizing away our loop.
Listing 9.9 InfiniteLoop application with unreasonable CPU consumption
using System;
namespace InfiniteLoop {
class Program {
public static void Main(string[] args) {
Console.WriteLine("This app runs in an infinite loop");
Console.WriteLine("It consumes a lot of CPU too!");
Console.WriteLine("Press Ctrl-C to quit");
var rnd = new Random();
infiniteLoopAggressive(rnd.NextDouble());
}
private static void infiniteLoopAggressive(double x) {
while (true) {
x *= 13;
}
}
}
}Compile the InfiniteLoop application and leave it running in a separate window. Let’s assume this is our service in production and we need to find out where it’s stuck or where it consumes so much CPU. Finding the call stack would help us a lot, and we can do that with crash dumps without crashing anything.
Every process has a process identifier (PID), a numeric value that is unique among other running processes. Find the PID of the process after you run the application. You can either use Task Manager on Windows or just run this command on a PowerShell prompt:
Get-Process InfiniteLoop | Select -ExpandProperty Id
Or, on a UNIX system, you can just type
pgrep InfiniteLoop
The PID of the process would be shown. You can create a dump file using that PID by writing out the dotnet dump command:
dotnet dump collect -p PID
If your PID is, say, 26190, type
dotnet dump collect -p 26190
The command would show where the crash dump is saved:
Writing full to C:UsersssgDownloadsdump_20210613_223334.dmp Complete
You can later analyze the command of dotnet-dump on that generated dump file:
dotnet dump analyze .dump_20210613_223334.dmp Loading core dump: .dump_20210613_223334.dmp ... Ready to process analysis commands. Type 'help' to list available commands or 'help [command]' to get detailed help on a command. Type 'quit' or 'exit' to exit the session. > _
You’d use forward slashes for UNIX pathnames instead of the backslashes of Windows. This distinction has an interesting story that comes down to Microsoft adding directories to MS-DOS in its v2.0 instead of v1.0.
The analyze prompt accepts many commands that can be seen with help, but you only need to know a few of them to identify what the process is doing. One is the threads command that shows all the threads running under that process:
> threads *0 0x2118 (8472) 1 0x7348 (29512) 2 0x5FF4 (24564) 3 0x40F4 (16628) 4 0x5DC4 (24004)
The current thread is marked with an asterisk, and you can change the current thread with the setthread command, like this:
> setthread 1 > threads 0 0x2118 (8472) *1 0x7348 (29512) 2 0x5FF4 (24564) 3 0x40F4 (16628) 4 0x5DC4 (24004)
As you can see, the active thread changed. But the dotnet dump command can only analyze managed threads, not native threads. If you try to see the call stack of an unmanaged thread, you get an error:
> clrstack OS Thread Id: 0x7348 (1) Unable to walk the managed stack. The current thread is likely not a managed thread. You can run !threads to get a list of managed threads in the process Failed to start stack walk: 80070057
You need a native debugger like WinDbg, LLDB, or GDB to do that kind of analysis, and they work similarly in principle to analyzing crash dumps. But we’re not interested in the unmanaged stack currently, and usually, the thread 0 belongs to our app. You can switch back to thread 0 and run command clrstack again:
> setthread 0
> clrstack
OS Thread Id: 0x2118 (0)
Child SP IP Call Site
000000D850D7E678 00007FFB7E05B2EB InfiniteLoop.Program.infiniteLoopAggressive(Double) [C:UsersssgsrcookCH09InfiniteLoopProgram.cs @ 15]
000000D850D7E680 00007FFB7E055F49 InfiniteLoop.Program.Main(System.String[]) [C:UsersssgsrcookCH09InfiniteLoopProgram.cs @ 10]Apart from a couple of uncomfortably long memory addresses, the call stack makes complete sense. It shows what that thread has been doing when we got the dump down to the line number (the number after @) that it corresponds to, without even breaking the running process! It gets that information from debugging information files with the extension .pdb on .NET and matches memory addresses with symbols and line numbers. That’s why it’s important for you to deploy debugging symbols to the production server in case you need to pinpoint errors.
Debugging crash dumps is a deep subject and covers many other scenarios like identifying memory leaks and race conditions. The logic is pretty much universal among all operating systems, programming languages, and debugging tools. You have a memory snapshot in a file where you can examine the file’s contents, the call stack, and the data. Consider this a starting point and an alternative to traditional step-by-step debugging.
9.3.3 Advanced rubber-duck debugging
As I discussed briefly at the beginning of the book, rubber duck debugging is a way to solve problems by telling them to a rubber duck sitting on your desk. The idea is that when you put your problem into words, you reframe it in a clearer way so you can magically find a solution to it.
I use Stack Overflow drafts for that. Instead of asking a question on Stack Overflow and wasting everybody’s time with my perhaps silly question, I just write my question on the website without posting it. Why Stack Overflow, then? Because being aware of the peer pressure on the platform forces you to iterate over one aspect that’s crucial when constructing your question: “What have you tried?”
Asking yourself that question has multiple benefits, but the most important one is that it helps you realize that you haven’t tried all the possible solutions yet. Solely thinking about that question has helped me think of numerous other possibilities that I haven’t considered.
Similarly, Stack Overflow mods ask you to be specific. Too-broad questions are considered off topic. That pushes you to narrow your problem down to a single specific issue, helping you deconstruct your problem in an analytical way. When you practice this on the website, you’ll make this a habit, and you’ll be able to do it mentally later.
Summary
-
Prioritize bugs to avoid wasting your resources on fixing bugs that don’t matter.
-
Catch exceptions only when you have a planned, intentional action in place for that case. Otherwise, don’t catch them.
-
Write exception-resilient code that can withstand crashes first instead of trying to avoid crashes as an afterthought.
-
Use result codes, or
enums, instead of exceptions for cases where errors are common or highly expected. -
Use framework-provided tracing affordances to identify problems faster than clunky step-by-step debugging.
-
Use crash dump analysis to identify problems on running code in production if other methods are unavailable.
-
Use your drafts folder as a rubber duck debugging tool, and ask yourself what you’ve tried.