
5 Rewarding refactoring
- Getting comfortable with refactoring
- Incremental refactoring on large changes
- Using tests to make code changes faster
- Dependency injection
In chapter 3, I discussed how resistance to change caused the downfall of the French royal family and software developers. Refactoring is the art of changing the structure of the code. According to Martin Fowler,1 Leo Brodie coined the term in his book Thinking Forth back in 1984. That makes the term as old as Back to the Future and Karate Kid, my favorite movies when I was a kid.
Writing great code is usually only half of being an efficient developer. The other half is being agile in transforming code. In an ideal world, we should be writing and changing code at the speed of thought. Hitting keys, nailing the syntax, memorizing keywords, and changing the coffee filter are all obstacles between your ideas and the product. Since it’ll probably take a while before we get AI to do programming work for us, it’s a good idea to polish our refactoring skills.
IDEs are instrumental in refactoring. You can rename a class with a single keystroke (F2 on Visual Studio for Windows) and rename all the references to it instantly. You can even access most of the refactoring options with a single keystroke. I strongly recommend familiarizing yourself with keyboard shortcuts for the features that you frequently use on your favorite editor. The time savings will accumulate, and you’ll look cool to your colleagues.
5.1 Why do we refactor?
Change is inevitable, and code change is doubly so. Refactoring serves purposes other than simply changing the code. It lets you
-
Reduce repetition and increase code reuse. You can move a class that can be reused by other components to a common location so those other components can start using it. Similarly, you can extract methods from the code and make them available for reuse.
-
Bring your mental model and the code closer. Names are important. Some names may not be as easily understandable as others. Renaming things is part of the refactoring process and can help you achieve a better design that more closely matches your mental model.
-
Make the code easier to understand and maintain. You can reduce code complexity by splitting long functions into smaller, more maintainable ones. Similarly, a model can be easier to understand if complex data types are grouped in smaller, atomic parts.
-
Prevent certain classes of bugs from appearing. Certain refactoring operations, like changing a class to a
struct, can prevent bugs related to nullability, as I discussed in chapter 2. Similarly, enabling nullable references on a project and changing data types to non-nullable ones can prevent bugs that are basically refactoring operations. -
Prepare for a significant architectural change. Big changes can be performed faster if you prepare the code for the change beforehand. You will see how that can happen in the next section.
-
Get rid of the rigid parts of the code. Through dependency injection, you can remove dependencies and have a loosely coupled design.
Most of the time, we developers see refactoring as a mundane task that is part of our programming work. Refactoring is also separate external work that you do even if you’re not writing a single line of code. You can even do it for the purpose of reading the code because it’s hard to grasp. Richard Feynman once said, “If you want to truly learn a subject, write a book about it.” In a similar vein, you can truly learn about a piece of code by refactoring it.
Simple refactoring operations need no guidance at all. You want to rename a class? Go ahead. Extract methods or interfaces? These are no-brainers. They are even on the right-click menu for Visual Studio, which can also be brought up with Ctrl-. on Windows. Most of the time, refactoring operations don’t affect code reliability at all. However, when it comes to a significant architectural change in the code base, you might need some advice.
5.2 Architectural changes
It’s almost never a good idea to perform a large architectural change in one shot. That’s not because it’s technically hard, but mostly because large changes generate a large number of bugs and integration problems due to the long and broad nature of the work. By integration problems, I mean that if you’re working on a large change, you need to work on it for a long time without being able to integrate changes from other developers (see figure 5.1). That puts you in a bind. Do you wait until you’re done with your work and manually apply every change that’s been made on the code in that timeframe and fix all the conflicts yourself, or do you tell your team members to stop working until you finish your changes? This is mostly a problem when you’re refactoring. You don’t have the same problem when you’re developing a new feature because the possibility of conflicting with other developers is far less: the feature itself does not exist in the first place. That’s why an incremental approach is better.
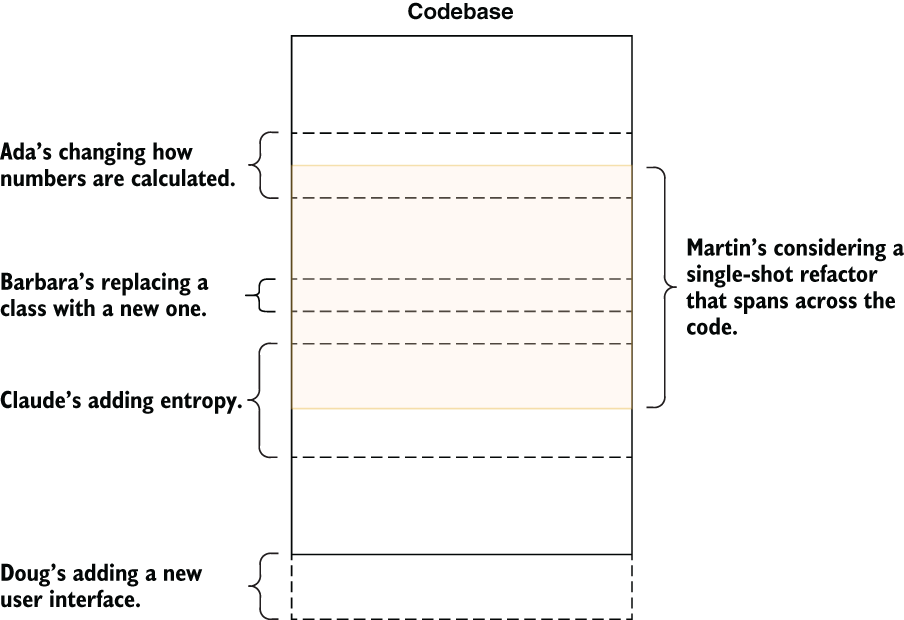
Figure 5.1 Why one-shot large refactors are a bad idea
To create a road map, you need to have a destination and to know where you are. What do you want the end result to look like? It may not be possible to imagine everything at once because large software is really hard to wrap your head around. Instead, you can have a certain list of requirements.
Let’s work on a migration example. Microsoft has two flavors of .NET in the wild. The first one is the .NET Framework, which is decades old, and the second one is just called .NET (previously known as .NET Core), which was released in 2016. Both are still supported by Microsoft as of the writing of this book, but it’s obvious that Microsoft wants to move forward with .NET and drop the .NET Framework at some point. It’s very likely that you’ll encounter work that needs migration from .NET Framework to .NET.
In addition to your destination, you need to know where you are. This reminds me of the story about a CEO who was getting a ride in a helicopter, and they got lost in the fog. They noticed the silhouette of a building and saw someone on the balcony. The CEO said, “I’ve got an idea. Get us closer to that person.” They got closer to the person, and the CEO shouted, “Hey! Do you know where we are?” The person replied, “Yes, you’re in a helicopter!” The CEO said, “Okay, then we must be at the college campus and that must be the engineering building!” The person on the balcony was surprised and asked, “How did you figure it out?” The CEO replied, “The answer you gave us was technically correct, but completely useless!” The person shouted, “Then you must be a CEO!” Now the CEO was surprised and asked, “How did you know that?” The person answered, “You got lost, have no idea where you are or where you’re going, and it’s still my fault!”
I can’t help imagining the CEO jumping to the balcony from the helicopter and a Matrix-like fight sequence breaking out between the runaway engineer and the CEO, both wielding katanas, simply because the pilot didn’t know how to read a GPS instead of practicing a precision approach maneuver to balconies.
Consider that we have our anonymous microblogging website called Blabber written in .NET Framework and ASP.NET and we’d like to move it to the new .NET platform and ASP.NET Core. Unfortunately, ASP.NET Core and ASP.NET are not binary compatible and are only slightly source compatible. The code for the platform is included in the source code of the book. I won’t be listing the full code here because the ASP.NET template comes with quite a lot of boilerplate, but I’ll sketch out the architectural details that will guide us in creating a refactoring road map. You don’t need to know about the architecture of ASP.NET or how web apps work in general to understand our refactoring process because that’s not directly relevant to refactoring work.
5.2.1 Identify the components
The best way to work with a large refactor is to split your code into semantically distinct components. Let’s split our code into several parts for the sole purpose of a refactor. Our project is an ASP.NET MVC application with some model classes and controllers we added. We can have an approximate list of components, as in figure 5.2. It doesn’t need to be accurate; it can be what you come up with initially because it will change.
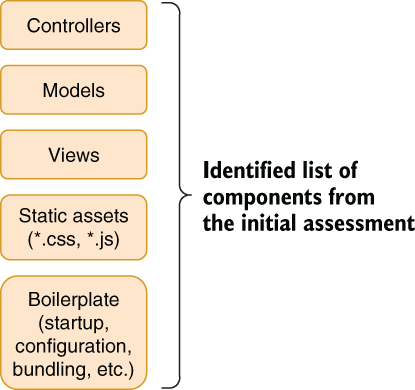
Figure 5.2 Our initial assessment of components
After you have the list of components down, start assessing how many of them you can transfer directly to your destination, as in our example .NET 5. Note that destination means the destination state that symbolizes the end result. Can the components be manipulated into the destination state without breaking anything? Do you think they will need some work? Assess this per component, and we will use this guesswork to prioritize. You don’t really need to accurately know this because guesswork is adequate at this moment. You can have a work estimation table like the one in table 5.1.
Table 5.1 Assessing relative cost and risks of manipulating components
5.2.2 Estimate the work and the risk
How will you know how much work will be needed? You must have a vague idea about how both frameworks work to determine that. It’s important that you know your destination before you start walking toward it. You can be wrong about some of these guesses, and that’s okay, but the primary reason to follow this practice is to prioritize work to reduce your workload without breaking anything for as long as possible.
For example, I know controllers and views require minimal effort because I know their syntax hasn’t changed much between frameworks. I anticipate a little work with the syntax of some HTML helpers or controller constructs, but there is a great chance that I should be moving them without any issues. Similarly, I know static assets are moved under the wwwroot/ folder in ASP.NET Core, which requires only a little work, but they definitely are not directly transferable. I also know that startup and configuration code has completely been overhauled in ASP.NET Core, which means I’ll have to write them from scratch.
I assume all the other developers will be working on features, so I expect their work will involve work under controllers, views, and models. I don’t expect existing models to change as frequently as the business logic or how the features look, so I assign models a medium risk while controllers and views merit a higher risk probability. Remember, other developers are working on the code while you’re working on your refactoring, so you must find a way to integrate your work to their workflow as early as possible without breaking their flow. The most feasible component for that looks like models in table 5.1. Despite the possibility of high conflict, it requires minimal change, so resolving any conflicts should be straightforward.
It needs no change to be refactored. How do you make the existing code and the new code with the same component at the same time? You move it into a separate project. I discussed this in chapter 3 when I talked about breaking dependencies to make a project structure more open to change.
5.2.3 The prestige
Refactoring without disrupting your colleagues is pretty much like changing the tire of a car while driving on the highway. It resembles an illusion act that makes the old architecture disappear and replaces it with the new one without anyone noticing. Your greatest tool when you’re doing that would be extracting code into shareable parts, as shown in figure 5.3.
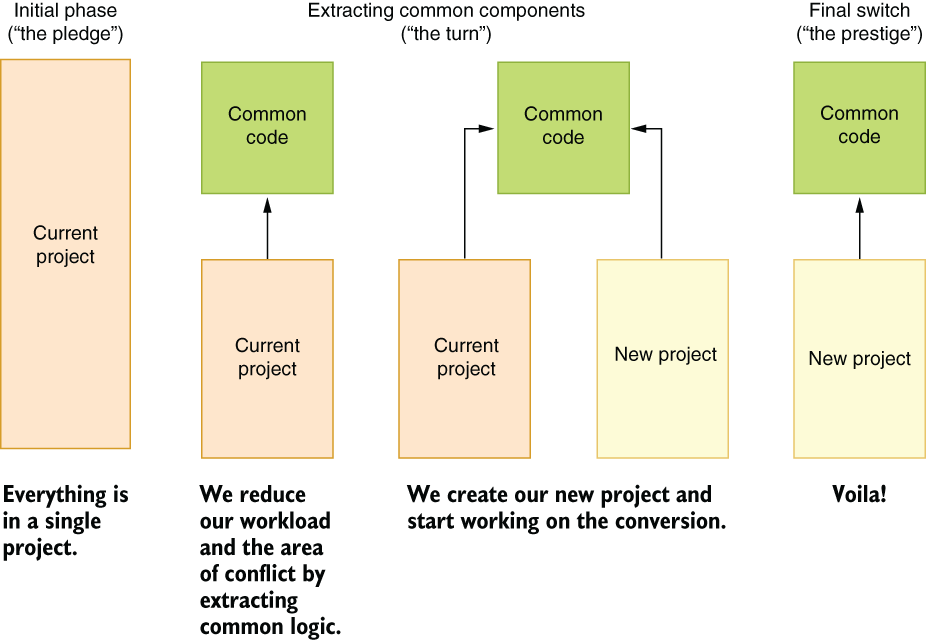
Figure 5.3 The illusion of refactoring without any developer noticing
Of course, it’s impossible for developers not to notice the new project in the repository, but as long as you communicate the changes you’re trying to implement with them beforehand and it’s straightforward for them to adapt, you should have no problems implementing your changes as the project goes forward.
You create a separate project, as in our example, Blabber.Models, move your models classes to that project, and then add a reference to that project from the web project. Your code will keep running as it did before, but the new code will need to be added in the Blabber.Models project rather than Blabber, and your colleagues need to be aware of this change. You can then create your new project and reference Blabber.Models from that too. Our road map resembles that in figure 5.4.
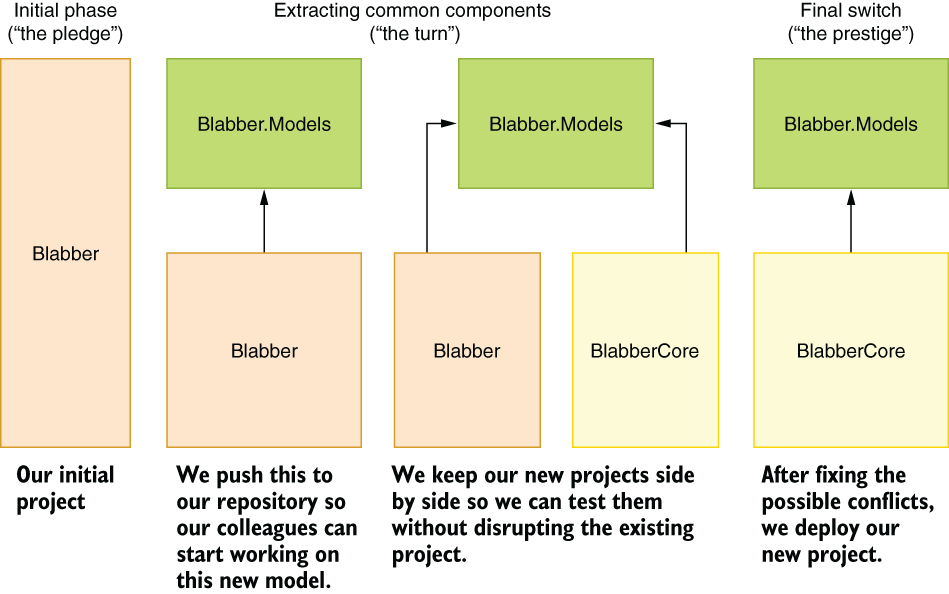
Figure 5.4 Our project’s refactoring road map
The reason we are going through this is to reduce our work while staying as current as possible with the main branch. This method also lets you perform your refactoring work over a longer timeline while squeezing other, more urgent work into your schedule. It pretty much resembles checkpoint systems in video games where you can start at the same Valkyrie fight for the hundredth time in God of War instead of going back to the beginning of the entire game all over again. Whatever you can integrate into the main branch without breaking the build becomes a last-known good spot that you don’t have to repeat. Planning your work with multiple integration steps is the most feasible way to perform a large refactor.
5.2.4 Refactor to make refactoring easier
When moving code across projects, you’ll encounter strong dependencies that cannot be easily moved out. In our example, some of the code might depend on web components, and moving them to our shared project would be meaningless because our new project, BlabberCore, wouldn’t work with the old web components.
In such cases, composition comes to our rescue. We can extract an interface that our main project can provide and pass it to the implementation instead of the actual dependency.
Our current implementation of Blabber uses an in-memory storage for the content posted on the website. That means that whenever you restart the website, all the platform content is lost. That makes sense for a post-modern art project, but users expect at least a level of persistence. Let’s assume we’d like to use either Entity Framework or Entity Framework Core, based on the framework we’re using, but we still would like to share the common DB access code among two projects while our migration is ongoing, so the actual work needed for the final stretch for migration will be far less.
You can abstract away a dependency that you don’t want to deal with by creating an interface for it and receiving its implementation in a constructor. That technique is called dependency injection. Do not confuse it with dependency inversion, which is an overhyped principle that basically states “depend on abstractions,” but sounds less profound when it’s put like that.
Dependency injection (DI) is also a slightly misleading term. It implies interference or disturbance, but nothing like that is going on. Perhaps it should have been called dependency reception because that’s what it’s about: receiving your dependencies during initialization such as in your constructor. DI is also called IoC (inversion of control), which sometimes is even more confusing. A typical dependency injection is a design change like that shown in figure 5.5. Without dependency injection, you instantiate your dependent classes in your code. With dependency injection, you receive the classes you depend on in a constructor.
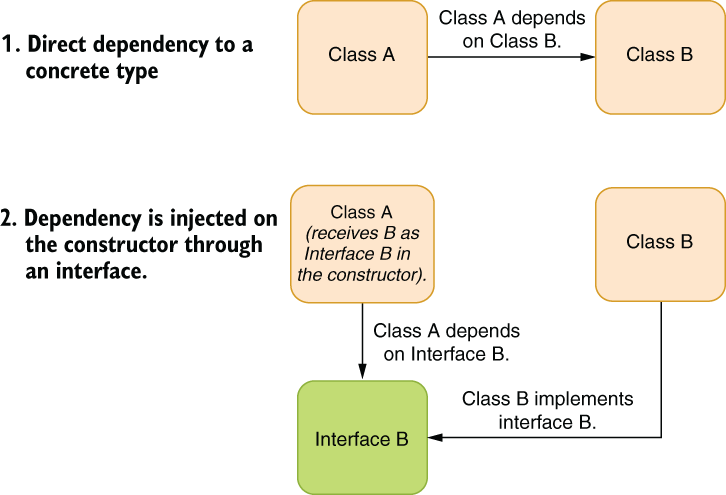
Figure 5.5 How dependency injection changes the design of a class
Let’s go over how it’s performed in some simple and abstract code so you can focus on the actual changes that are happening. In this example, you can see how C# 9.0 top-level program code looks, without a main method or a program class per se. You can actually type the code in the following listing in a .cs file under a project folder and run it right away, without any extra code. Note how class A initializes an instance of a class B every time the method X is called.
Listing 5.1 Code that uses direct dependency
using System; var a = new A(); ❶ a.X(); public class A { public void X() { Console.WriteLine("X got called"); var b = new B(); ❷ b.Y(); } } public class B { public void Y() { Console.WriteLine("Y got called"); } }
❶ The main code creates an instance of A here.
❷ Class A creates the instance of class B.
When you apply dependency injection, your code gets its instance of class B in its constructor and through an interface, so you have zero coupling between classes A and B. You can see how it shapes up in listing 5.2. However, there is a difference in conventions. Because we moved the initialization code of class B to a constructor, it always uses the same instance of B instead of creating a new one, which is how it used to work in listing 5.1. That’s actually good because it reduces the load on the garbage collector, but it can create unexpected behavior if the state of the class changes over time. You might be breaking behavior. That’s why having test coverage is a good idea in the first place.
What we’ve accomplished with the code in listing 5.2 is that we now can completely remove the code for B and move it to an entirely different project without breaking the code in A, as long as we keep the interface we’ve created (IB). More importantly, we can move everything B needs along with it. It gives us quite a lot of freedom to move the code around.
Listing 5.2 Code with dependency injection
using System; var b = new B(); ❶ var a = new A(b); ❷ a.X(); public interface IB { void Y(); } public class A { private readonly IB b; ❸ public A(IB b) { this.b = b; } public void X() { Console.WriteLine("X got called"); b.Y(); ❹ } } public class B : IB { public void Y() { Console.WriteLine("Y got called"); } }
❶ The caller initializes class B
❷ It passes it to class A as a parameter.
❸ The instance of B is kept here.
❹ The common instance of B is called.
Now let’s apply this technique to our example in Blabber and change the code to use database storage instead of memory so our content will survive restarts. In our example, instead of depending on a specific implementation of a DB engine, in this case Entity Framework and EF Core, we can receive an interface we devise that provides required functionality to our component. This lets two projects with different technologies use the same code base, even though the common code depends on the specific DB functionality. To achieve that, we create a common interface, IBlabDb, which points to the database functionality, and use it in our common code. Our two different implementations share the same code; they let the common code use different DB access technologies. Our implementation will look like that in figure 5.6.
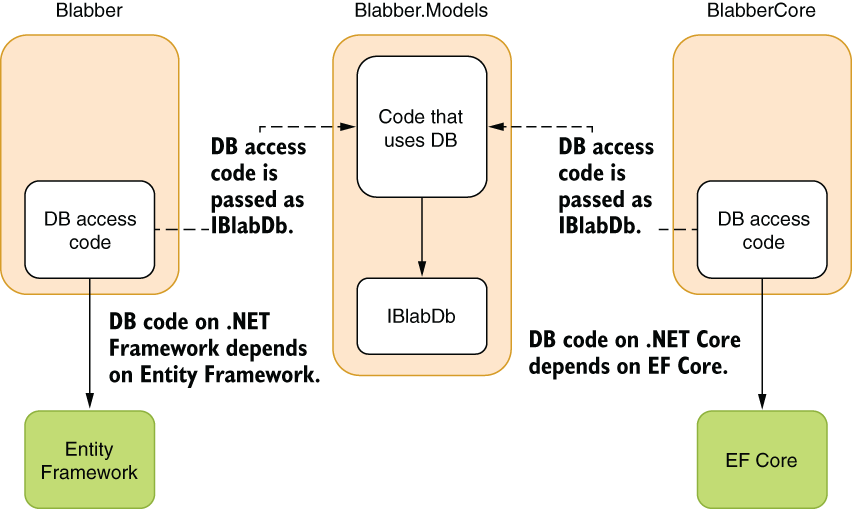
Figure 5.6 Using different technologies in common code with dependency injection
To implement that, we first change our implementation of BlabStorage in the Blabber .Models that we refactored, so it will defer work to an interface instead. The in-memory implementation of the BlabStorage class looks like that in listing 5.3. It keeps a static instance of a list that is shared between all requests, so it uses locking to ensure that things don’t become inconsistent. We don’t care about the consistency of our Items property because we only add items to this list, never remove them. Otherwise, it would have been a problem. Note that we use Insert instead of Add in the Add() method because it lets us keep posts in descending order by their creation date without resorting to any sorting.
Listing 5.3 Initial in-memory version of BlabStorage
using System.Collections.Generic;
namespace Blabber.Models {
public class BlabStorage {
public IList<Blab> items = new List<Blab>(); ❶
public IEnumerable<Blab> Items => items;
public object lockObject = new object(); ❷
public static readonly BlabStorage Default =
new BlabStorage(); ❸
public BlabStorage() {
}
public void Add(Blab blab) {
lock (lockObject) {
items.Insert(0, blab); ❹
}
}
}
}❶ Creating an empty list by default
❷ We’re using lock object to allow concurrency.
❸ A default singleton instance that’s used everywhere
❹ The most recent item goes to the top.
When we implement dependency injection, we remove everything related to in-memory lists and use an abstract interface for anything related to the database instead. The new version looks like listing 5.4. You can see how we remove anything related to the logic of data storage, and our BlabStorage class actually became an abstraction itself. It looks like BlabStorage doesn’t do anything extra, but as we add more complicated tasks, we’re able to share some logic between our two projects. For the sake of the example, this is okay.
We keep the dependency in a private and read-only field called db. It’s a good habit to mark fields with the readonly keyword if they won’t change after the object is created, so the compiler can catch whether you or one of your colleagues accidentally tries to modify it outside the constructor.
Listing 5.4 BlabStorage with dependency injection
using System.Collections.Generic;
namespace Blabber.Models {
public interface IBlabDb { ❶
IEnumerable<Blab> GetAllBlabs();
void AddBlab(Blab blab);
}
public class BlabStorage {
private readonly IBlabDb db;
public BlabStorage(IBlabDb db) { ❷
this.db = db;
}
public IEnumerable<Blab> GetAllBlabs() {
return db.GetAllBlabs(); ❸
}
public void Add(Blab blab) {
db.AddBlab(blab); ❸
}
}
}❶ The interface that abstracts away the dependency
❷ Receiving the dependency in the constructor
❸ Deferring work to the component that does the actual work
Our actual implementation is called BlabDb, which implements the interface IBlabDb and resides in the project BlabberCore, rather than Blabber.Models. It uses an SQLite (pronounced sequel-light) database for practical purposes because it requires no setup of third-party software, so you can start running it right away. SQLite is God’s last gift to the world before he gave up on humankind. Just kidding—Richard Kipp created it before he gave up on humankind. Our BlabberCore project implements it in EF Core, as in listing 5.5.
You may not be familiar with EF Core, Entity Framework, or ORM (object- relational mapping) in general, but that’s okay—you don’t have to be. It’s pretty straightforward, as you can see. The AddBlab method just creates a new database record in memory, creates a pending insertion to the Blabs table, and calls SaveChanges to write changes to the database. Similarly, the GetAllBlabs method simply gets all the records from the database, ordered by date in descending order. Notice how we need to convert our dates to UTC to make sure time zone information isn’t lost because SQLite doesn’t support DateTimeOffset types. Regardless of how many best practices you learn, you’ll always encounter cases in which they just won’t work. Then you’ll have to improvise, adapt, and overcome.
Listing 5.5 EF Core version of BlabDb
using Blabber.Models;
using System;
using System.Collections.Generic;
using System.Linq;
namespace Blabber.DB {
public class BlabDb : IBlabDb {
private readonly BlabberContext db; ❶
public BlabDb(BlabberContext db) { ❷
this.db = db;
}
public void AddBlab(Blab blab) {
db.Blabs.Add(new BlabEntity() {
Content = blab.Content,
CreatedOn = blab.CreatedOn.UtcDateTime, ❸
});
db.SaveChanges();
}
public IEnumerable<Blab> GetAllBlabs() {
return db.Blabs
.OrderByDescending(b => b.CreatedOn)
.Select(b => new Blab(b.Content,
new DateTimeOffset(b.CreatedOn, TimeSpan.Zero))) ❹
.ToList();
}
}
}❷ Receiving context through dependency injection
❸ Converting our DateTimeOffset to a DB-compatible type
❹ Converting DB-time to DateTimeOffset
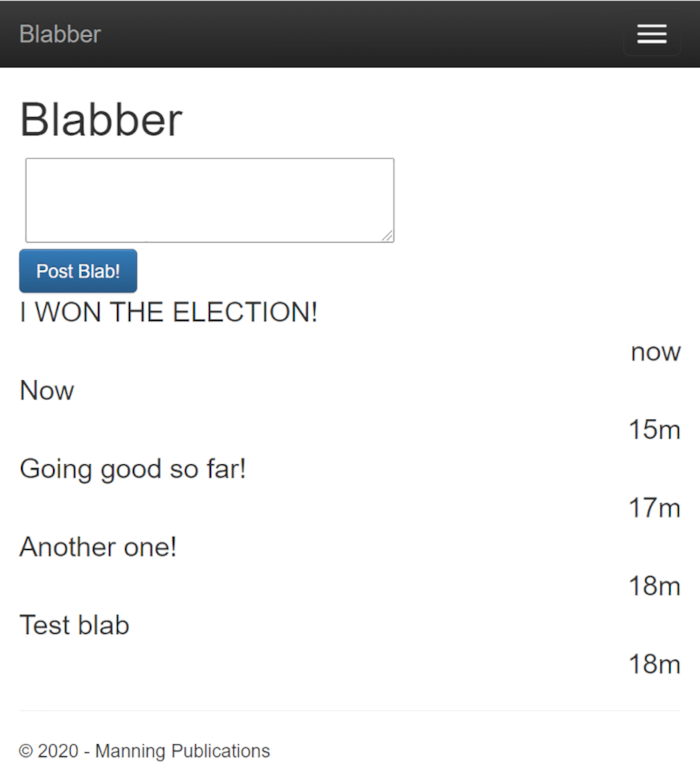
Figure 5.7 Screenshot of Blabber running on a SQLite database
We managed to introduce a database storage backend to our project during our refactoring without disrupting the development workflow. We used dependency injection to avoid direct dependencies. More importantly, our content is now persisted across sessions and restarts, as figure 5.7 shows.
5.2.5 The final stretch
You can extract as many components as can be shared between the old and the new project, but eventually, you’ll hit a chunk of code that can’t be shared between two web projects. For example, our controller code doesn’t need to change between ASP.NET and ASP.NET Core because the syntax is the same, but it’s impossible to share that piece of code between the two because they use entirely different types. ASP.NET MVC controllers are derived from System.Web.Mvc.Controller, while ASP.NET Core controllers are derived from Microsoft.AspNetCore.Mvc.Controller. There are theoretical solutions to this, like abstracting away the controller implementation behind an interface and writing custom classes that use that interface instead of being direct descendants of the controller class, but that’s just too much work. When you come up with a supposedly elegant solution to a problem, you should always ask yourself, “Is it worth it?” Elegance in engineering must always take cost into account.
That means that at some point, you’ll have to risk conflicting with other developers and transfer the code to the new code base. I call that the final stretch, which will take a shorter time thanks to your previous preparatory work on refactoring. Because of your work, the future refactor operations will take less time because you’ll end up with a compartmentalized design at the end of the process. It’s a good investment.
In our example, the models component is an unusually small part of our project, therefore makes our savings negligible. However, it’s expected that large projects have a significant amount of shareable code, which might reduce your work factor considerably.
In the final stretch, you need to transfer all the code and assets to your new project and then make everything work. I added a separate project to the code examples called BlabberCore, which contains the new .NET code so you can see how some constructs translate to .NET Core.
5.3 Reliable refactoring
Your IDE tries really hard so you don’t break the code simply by randomly choosing menu options. If you manually edit a name, any other code that references the name will break. If you use the rename function of your IDE, all references to the name will be renamed as well. That still is not always a guarantee. There are many ways you can refer to a name without the compiler knowing. For example, it’s possible to instantiate a class using a string. In our example microblogging code, Blabber, we refer to every piece of content as blabs, and we have a class that defines a content called Blab.
Listing 5.6 Class representing a content
using System;
namespace Blabber
{
public class Blab
{
public string Content { get; private set; } ❶
public DateTimeOffset CreatedOn { get; private set; }
public Blab(string content, DateTimeOffset createdOn) {
if (string.IsNullOrWhiteSpace(content)) {
throw new ArgumentException(nameof(content));
}
Content = content;
CreatedOn = createdOn;
}
}❶ The constructor ensures there are no invalid blabs.
We normally instantiate classes using the new operator, but it’s also possible to instantiate the Blab class using reflection for certain purposes, such as when you don’t know what class you’re creating during compile time:
var blab = Activator.CreateInstance("Blabber.Models",
"Blabber", "test content", DateTimeOffset.Now);Whenever we refer to a name in a string, we risk breaking the code after a rename because the IDE cannot track the contents of strings. Hopefully, that’ll stop being a problem when we start doing code reviews with our AI overlords. I don’t know why in that fictional future it’s still us who are doing the work and AI just grades our work. Weren’t they supposed to take over our jobs? It turns out they are much more intelligent than we give them credit for.
Until the AI takeover of the world, your IDE can’t guarantee a perfectly reliable refactoring. Yes, you have some wiggle room, like using constructs like nameof() to reference types instead of hardcoding them into strings, as I discussed in chapter 4, but that helps you only marginally.
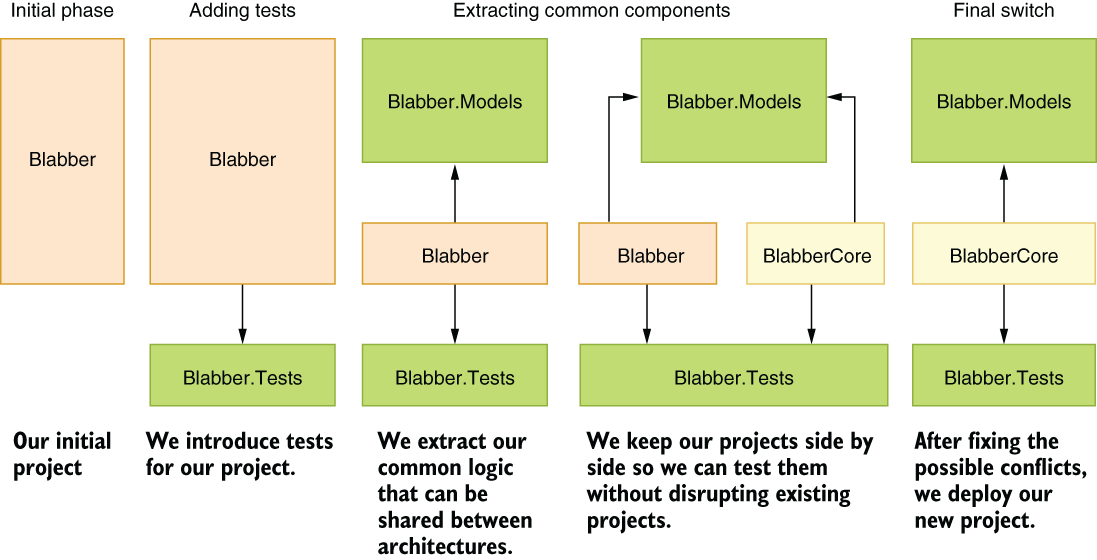
Figure 5.8 Reliable refactoring with tests
The secret to reliable refactoring is testing. If you can make sure your code has good test coverage, you can have much more freedom in changing it. Therefore, it’s usually a wise idea to start a long-term refactoring project by creating missing tests for the relevant piece of code first. If we take our architecture change example in chapter 3 as an example, a more realistic road map would involve adding missing tests to the whole architecture. We skipped that step in our example because our code base was extremely small and trivial to test manually (e.g., run the app, post a blab, and see if it appears). Figure 5.8 shows a modified version of our road map that includes the phase of adding tests to our project so it can be refactored reliably.
5.4 When not to refactor
The good thing about refactoring is that it makes you think about ways to improve code. The bad thing about refactoring is that at some point, it might become an end rather than a means, pretty much like Emacs. For the uninformed, Emacs is a text editor, a development environment, a web browser, an operating system, and a post-apocalyptic role-playing game because someone just couldn’t hold their horses. The same can happen with refactoring. You start seeing every piece of code as a place for a potential improvement. It becomes such an addiction that you create excuses to make a change for the sake of making the change, but you don’t consider its benefits. Not only does this waste your time, but it also wastes your team’s because they need to adapt to every change you introduce.
You should essentially develop an understanding of good-enough code and worthiness when you’re working in the streets. Yes, code can rust away when it’s left untouched, but good-enough code can bear that burden easily. The criteria you need for good-enough code are
-
Is your only reason for refactoring “This is more elegant?” That’s a huge red flag because elegance is not only subjective, but also vague and therefore meaningless. Try to come up with solid arguments and solid benefits, like “This will make this component easier to use by reducing the amount of boilerplate we need to write every time we use it,” “This will prepare us for migrating to the new library,” “This will remove our dependency to the component X,” and so forth.
-
Does your target component depend on a minimal set of components? That indicates that it can be moved or refactored easily in the future. Our refactoring exercises may not benefit us for identifying rigid parts of the code. You can postpone it until you come up with a more solid improvement plan.
-
Does it lack test coverage? That is an immediate red flag to avoid refactoring, especially if the component also has too many dependencies. Lack of testing for a component means you don’t know what you’re doing, so stop doing it.
-
Is it a common dependency? That means that even with a good amount of test coverage and good justification, you might be impacting the ergonomics of your team by disrupting their workflow. You should consider postponing a refactor operation if the gains you seek aren’t sufficient to compensate the cost.
If any of those criteria is met, you should consider avoiding refactoring, or at least postponing it. Prioritization work is always relative, and there are always more fish in the sea.
Summary
-
Embrace refactoring because it provides more benefits than what’s on the surface.
-
You can perform large architectural changes in incremental steps.
-
Use testing to reduce the potential problems ahead in large refactoring work.
-
Always have either a mental or a written road map for incremental work when you’re working on large architectural changes.
-
Use dependency injection to remove roadblocks like tightly coupled dependencies when refactoring. Reduce code rigidity with the same technique.
-
Consider not doing a refactor when it costs more than it yields.
1. Etymology of Refactoring, Martin Fowler, https://martinfowler.com/bliki/EtymologyOfRefactoring.html.