
I'm gonna wrap myself in paper, I'm gonna dab myself with glue, Stick some stamps on top of my head! I'm gonna mail myself to you. | ||
| --Woody Guthrie, Mail Myself to You | ||
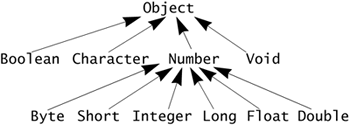
The separation of primitive types (byte, float, and so on) and reference types (classes and interfaces) is a trade-off between efficiency and familiarity versus expressiveness and consistency. An object may incur too much overhead where a plain int will do, while an int may be fast and convenient until you need to store it into a hashtable. To smooth this separation, the Java programming language provides a wrapper class corresponding to each of the primitive types. Instances of a given wrapper class contain a value of the corresponding primitive type. The type hierarchy for these classes looks like this:
The language provides automatic conversion between primitives and their wrappers in many contexts, specifically when assigning values or passing arguments. For example, you can write:
Integer val = 3;
And val will be assigned a reference to an instance of the Integer class that holds the value 3.
Converting a primitive value to a wrapper object is known as a boxing conversion; unsurprisingly, extracting a primitive value from a wrapper object is known as an unboxing conversion.[1] The details of these conversions are discussed in “Boxing Conversions” on page 198. These automated conversions make it easy to write general purposes classes that are written in terms of Object references, but that can handle either reference types or primitive types. The HashMap class, for example, stores only references, not primitive types—see “HashMap” on page 590—but an int can be passed as a key because it will be converted to an Integer instance:
The efficiency and convenience of using an int can be maintained, while an object can still be obtained when necessary—the best of both worlds.
A second purpose of the wrapper classes is to provide a home for methods and variables related to the type (such as string conversions and value range constants). Here, for example, is how you might check whether you could use a faster float calculation on a particular value or whether the value requires a larger range than a float provides and so must be performed as a double calculation:
double aval = Math.abs(value); if (Float.MAX_VALUE >= aval && aval >= Float.MIN_VALUE) return fasterFloatCalc((float) value); else return slowerDoubleCalc(value);
The following sections cover methods and constants specific to each particular wrapper class, but first let's look at some things that are common to most of the wrapper classes.
Except where individually noted, the following sections define constructors, constants, and methods that are defined for each of the wrapper classes. The general exception is the Void class which supports almost nothing—see page 187.
For the constructors and methods that convert strings into values, each class defines the valid form that the string can take, and these are described in the section for each class. For the numeric types, an invalid string format results in NumberFormatException being thrown.
The term radix, used in several places in the wrapper classes, is another word for numeric base. For example, decoding a long in radix 8 means the same as decoding it in base 8. The allowable range for a radix is 2 through 36.
In the following, Type refers to the wrapper class, and type is the corresponding primitive type.
Each wrapper class defines an immutable object for the primitive value that it is wrapping. This means that once a wrapper object has been created, the value represented by that object can never be changed. So, for example, the object created by newInteger(1) will always have the value 1, and no methods of class Integer allow you to modify this value.
Each wrapper class has the following constructors:
A constructor that takes a value of the primitive type and creates an object of the corresponding wrapper class. The constructors
Character(char)andInteger(int)are examples.A constructor that converts a single
Stringparameter into the object's initial value (exceptCharacter, which has no such constructor)—for example,newFloat("6.02e23").
Each wrapper class, Type, also has the following methods:
public staticTypevalueOf(typet)Returns an object of the specified
Typewith the valuet.
public staticTypevalueOf(String str)Returns an object of the specified
Typewith the value parsed fromstr.Float.valueOf("6.02e23")andInteger.valueOf("16")are examples.Characterdoes not have this method just as it does not have the string-converting constructor.
These methods may return a newly constructed instance or a cached instance. For efficiency, you should always use one of the valueOf methods, in preference to direct construction, unless you really need distinct instances that have the same value.
Each of the wrapper classes, with the exception of Boolean define the following three fields:
public static finaltypeMIN_VALUEThe minimum value representable by this data type. For example, for
Integerthis is –231.
public static finaltypeMAX_VALUEThe maximum value representable by this data type. For example, for
Integerthis is 231–1.
public static final intSIZEThe number of bits used to represent a value of this type. For example, for
Integerthis is 32.
All the wrapper classes define the following field:
public static final Class<Type>TYPEA reference to the
Classobject that represents primitives of this type. These fields are equivalent to theClassobjects you can obtain from.classclass literal expressions as described in “Class Literals” on page 169. For example,Integer.TYPEis the sameClassobject you will get from the expressionint.class. Note thatint.classandInteger.classyield two differentClassinstances, both of typeClass<Integer>.
Each of the wrapper classes implements the Comparable<T> interface and so defines:
public intcompareTo(Typeother)Returns a value less than, equal to, or greater than zero as the object on which it is invoked is less than, equal to, or greater than the object (of the same type
Type) passed as a parameter.
For the numeric types, comparison follows the normal arithmetic rules; however, the Float and Double classes have specific ordering properties that differ from float and double—see page 191. For Boolean, the value true is considered greater than false—in contrast to boolean for which the relational operators < and > are not defined. For Character, the comparison is strictly numerical, with no consideration of alphabetic, or locale specific ordering.
Each class provides a method to extract the wrapped value:
publictypetypeValue()Returns the primitive value corresponding to the current wrapper object. For example,
Integer.valueOf(6).intValue()returns 6.
And each class overrides the following members of Object:
public StringtoString()Provides a string representation of the wrapper object's value. For the numeric classes base 10 is always used.
public booleanequals(Object obj)Returns
trueif the two objects are the same type and wrap the same value. For example, for twoIntegerobjectsxandy,x.equals(y)is true if and only if,x.intValue()==y.intValue(). Ifobjis not of the same type as the current object, or isnull,falseis returned.
public inthashCode()Returns a value-based hash code for use in hashtables.
The following additional methods convert primitive values to and from strings:
public statictypeparseType(String str)Converts the string
strto a value of the specified primitivetype. For example,Integer.parseInt("10")returns the value 10. This is equivalent to invoking the string-converting constructor, and extracting the resulting value withtypeValue(), but without constructing an object.Characterdoes not have this method just as it does not have the string-converting constructor.
public static StringtoString(typeval)Returns a string representation of the given primitive value of type
type. For example,Double.toString(0.3e2)returns the string"30.0".
All wrapper classes have these methods so we do not list them in each class's description. The wrapper class's system property fetch-and-decode methods, described in “System Properties” on page 663, are not discussed in this chapter.
The Void class is the exception to all the preceding rules because it has no values to wrap, provides no methods, and cannot be instantiated. It has only a static TYPE field containing a reference to the Class object void.class. The language has no void type—void is a placeholder indicating no return type. The Void class represents that lack of an actual return type and is only used in reflection (see “The Method Class” on page 420).
The Boolean class represents the boolean type as a class. Both the constructor that decodes a string, the valueOf method and the parseBoolean method understand "true", with any mixture of uppercase and lowercase characters, to be true. Any other string is interpreted as false.
The Boolean class has two static references to objects corresponding to each of the primitive boolean values: Boolean.TRUE and Boolean.FALSE.
The Number class is an abstract class extended by all wrapper classes that represent primitive numeric types: Byte, Short, Integer, Long, Float, and Double.
The abstract methods of Number return the value of the object converted to any of the numeric types:
public byte byteValue() public short shortValue() public int intValue() public long longValue() public float floatValue() public double doubleValue()
Each extended Number class overrides these methods to convert its own type to any of the others under the same rules used for an explicit cast. For example, given a Float object with the value 32.87, the return value of intValue on the object would be 32, just as “(int)32.87 ” would be 32.
The classes Byte, Short, Integer, and Long extend Number to represent the corresponding integer types as classes. In addition to the standard Number methods, each of the integer wrapper classes supports the following methods:
public statictypeparseType(String str, int radix)Converts the string
strinto a numeric value of the specifiedtype, using the given radix. For example,Integer.parseInt("1010",2)returns 10, andInteger.parseInt("-1010",2)returns –10. The characters in the string must all be valid digits for the given radix, except that the first character may be a minus sign to indicate a negative value. ANumberFormatExceptionis thrown ifstrcontains any other characters (including leading or trailing whitespace), the value is out of range for this type, orradixis out of range.
public staticTypevalueOf(String str, int radix)Returns a wrapper object of class
Typewith the value obtained by decodingstrusing the specified radix. Note that there are no equivalent constructors with this form. This is equivalent to the two-step process of parsing the string and using that value to construct a new wrapper object. For example,Integer.valueOf("1010",2)is equivalent to the more verbose expressionnewInteger(Integer.parseInt("1010",2)).
public staticTypedecode(String str)Returns a wrapper object of class
Typewith the value obtained by decodingstr. A leading – character indicates a negative value. The base of the number is encoded instr: Hexadecimal numbers start with#,0x, or0X, while octal numbers are indicated by a leading0; otherwise, the number is presumed to be decimal. This is in contrast to theparseTypeandvalueOfmethods, to which you pass the radix as an argument. For example,Long.decode("0xABCD")returns aLongwith the value 43981, whileLong.decode("ABCD")throws aNumberFormatException. Conversely,Long.parseLong("0xABCD", 16)throws aNumberFormatException, whileLong.parseLong("ABCD", 16)returns aLongwith the value 43981. (The character#is used in many external data formats for hexadecimal numbers, so it is convenient thatdecodeunderstands it.)
For each class, the string-based constructor, parseType(String str) method, and valueOf methods work like parseType(String str, intradix) , with a radix of 10 if none is specified
In addition, the Integer and Long classes each have the following methods, where type is either int or long, respectively:
public static StringtoString(typeval, int radix)Returns a string representation of the given value in the given radix. If radix is out of range then a radix of 10 is used.
public static StringtoBinaryString(typeval)Returns a string representation of the two's complement bit pattern of the given value. For positive values this is the same as
toString(value,2). For negative values the sign of the value is encoded in the bit pattern, not as a leading minus character. For example,Integer.toBinaryString(-10)returns"11111111111111111111111111110110". These string representations for negative values cannot be used with correspondingparseTypemethods because the magnitude represented by the string will always be greater thanMAX_VALUEfor the given type.
public static StringtoOctalString(typeval)Returns a string representation of the given value in an unsigned base 8 format. For example,
Integer.toOctalString(10)returns"12". Negative values are treated as described intoBinaryString. For example,Integer.toOctalString(-10)returns"37777777766".
public static StringtoHexString(typeval)Returns a string representation of the given value in an unsigned base 16 format. For example,
Integer.toHexString(10)returns"a". Negative values are treated as described intoBinaryString. For example,Integer.toHexString(-10)returns"fffffff6".
Note that none of the string formats include information regarding the radix in that format—there is no leading 0 for octal, or 0x for hexadecimal. If radix information is needed then you must construct it yourself.
The Short, Integer, and Long classes have a method reverseBytes that returns a value with its constituent bytes in the reverse order to the value passed in. For example, Integer.reverseBytes(0x0000ABCD) returns an int value with the hexadecimal representation of 0xCDAB0000. The Integer and Long classes also provide a family of bit-querying methods:
public static intbitCount(typeval)Returns the number of one-bits in the two's complement binary representations of
val.
public statictypehighestOneBit(typeval)Returns a value consisting of all zero-bits, except for a single one-bit, in the same position as the highest-order (left-most) one-bit in
val.
public statictypelowestOneBit(typeval)Returns a value consisting of all zero-bits, except for a single one-bit, in the same position as the lowest-order (right-most) one-bit in
val.
public static intnumberOfLeadingZeros(typeval)Returns the number of zero-bits preceding the highest-order one-bit in
val.
public static intnumberOfTrailingZeros(typeval)Returns the number of zero-bits following the lowest-order one-bit in
val.
public statictypereverse(typeval)Returns the value obtained by reversing the order of the bits in
val.
public statictyperotateLeft(typeval, int distance)Returns the value obtained by rotating the bits in
valto the left. In a left rotation the high-order bit moved out on the left becomes the lowest-order bit on the right. Rotating to the left by a negative distance is the same as rotating to the right by a positive distance.
public statictyperotateRight(typeval, int distance)Returns the value obtained by rotating the bits in
valto the right. In a right rotation the low-order bit moved out on the right becomes the highest-order bit on the left. Rotating to the right by a negative distance is the same as rotating to the left by a positive distance.
Finally, the Integer and Long classes also define the mathematical signum function. This function takes a value and returns –1, 0, or +1 as the value is negative, zero, or positive, respectively.
The Float and Double classes extend Number to represent the float and double types as classes. With only a few exceptions, the names of the methods and constants are the same for both types. In the following list, the types for the Float class are shown, but Float and float can be changed to Double and double, respectively, to get equivalent fields and methods for the Double class. In addition to the standard Number methods, Float and Double have the following constants and methods:
public final static floatPOSITIVE_INFINITYThe value for +∞.
public final static floatNEGATIVE_INFINITYThe value for −∞.
public final static floatNaNNot-a-Number. This constant gives you a way to get a NaN value, not to test one. Surprising as it may be,
NaN==NaNis always false because a NaN value, not being a number, is equal to no value, not even itself. To test whether a number is NaN, you must use theisNaNmethod.
public static booleanisNaN(float val)Returns
trueifvalis a Not-a-Number (NaN) value.
public static booleanisInfinite(float val)Returns
trueifvalis either positive or negative infinity.
public booleanisNaN()Returns
trueif this object's value is a Not-a-Number (NaN) value.
public booleanisInfinite()Returns
trueif this object's value is either positive or negative infinity.
In addition to the usual constructor forms, Float has a constructor that takes a double argument to use as its initial value after conversion to float.
Comparison of Float and Double objects behaves differently than float and double values. Each wrapper class defines a sorting order that treats –0 less than +0, NaNs greater than all values (including +∞), and all NaNs equal to each other.
When converting to a string, NaN values return the string "NaN", +∞ returns "Infinity" and −∞ returns "-Infinity". The string-taking constructor, and the parseType method are defined in terms of the valueOf method, which accepts strings in the following form:
The values
"NaN"or"Infinity"with an optional leading+or-characterA floating-point literal
A hexadecimal floating-point literal
In contrast to the integer wrapper classes, the string is first stripped of leading and trailing whitespace. If the literal forms contain a trailing float or double specifier, such as "1.0f", the specifier is ignored and the string is converted directly to a value of the requested type.
To let you manipulate the bits inside a floating-point value's representation, Float provides methods to get the bit pattern as an int, as well as a way to convert a bit pattern in an int to a float value (according to the appropriate IEEE 754 floating-point bit layout). The Double class provides equivalent methods to turn a double value into a long bit pattern and vice versa:
public static intfloatToIntBits(float val)Returns the bit representation of the
floatvalue as anint. All NaN values are always represented by the same bit pattern.
public static intfloatToRawIntBits(float val)Equivalent to
floatToIntBitsexcept that the actual bit pattern for a NaN is returned, rather than all NaNs being mapped to a single value.
public static floatintBitsToFloat(int bits)Returns the
floatcorresponding to the given bit pattern.
The Character class represents the char type as a class. It provides methods for determining the type of a character (letter, digit, uppercase, and so forth) and for converting between uppercase and lowercase.
Since a char is a 16-bit value, and Unicode allows for 21-bit characters, known as code points, many of the methods of Character are overloaded to take either a char or an int that represents an arbitrary code point. Such methods are described in combination below and the pseudo-type codePoint is used to represent either a char or an int code point value.
In addition to MIN_VALUE and MAX_VALUE constants, Character provides the constants MIN_RADIX and MAX_RADIX, which are the minimum and maximum radices understood by methods that translate between digit characters and integer values or vice versa,. The radix must be in the range 2–36; digits for values greater than 9 are the letters A through Z or their lowercase equivalents. Three methods convert between characters and integer values:
public static intdigit(codePointch, int radix)Returns the numeric value of
chconsidered as a digit in the given radix. If the radix is not valid or ifchis not a digit in the radix, –1 is returned. For example,digit('A',16)returns 10 anddigit('9',10)returns 9, whiledigit('a',10)returns –1.
public static intgetNumericValue(codePointch)Returns the numeric value of the digit
ch. For example, the characteru217Fis the Roman numeral digit M, sogetNumericValue('u217F')returns the value 1000. These numeric values are non-negative. Ifchhas no numeric value, –1 is returned; if it has a value but is not a non-negative integer, such as the fractional value¼('u00bc'),getNumericValuereturns –2.
public static charforDigit(int digit, int radix)Returns the character value for the specified digit in the specified radix. If the digit is not valid in the radix, the character
'u0000'is returned. For example,forDigit(10,16)returns'a'whileforDigit(16,16)returns'u0000'.
There are three character cases in Unicode: upper, lower, and title. Uppercase and lowercase are familiar to most people. Titlecase distinguishes characters that are made up of multiple components and are written differently when used in titles, where the first letter in a word is traditionally capitalized. For example, in the string "ljepotica",[2] the first letter is the lowercase letter lj(u01C9 , a letter in the Extended Latin character set that is used in writing Croatian digraphs). If the word appeared in a book title, and you wanted the first letter of each word to be in uppercase, the correct process would be to use toTitleCase on the first letter of each word, giving you "Ljepotica" (using Lj, which is u01C8). If you incorrectly used toUpperCase, you would get the erroneous string "LJepotica" (using LJ, which is u01C7).
All case issues are handled as defined in Unicode. For example, in Georgian, uppercase letters are considered archaic, and translation into uppercase is usually avoided. Therefore, toUpperCase will not change lowercase Georgian letters to their uppercase equivalents, although toLowerCase will translate uppercase Georgian letters to lowercase. Because of such complexities, you cannot assume that converting characters to either lower or upper case and then comparing the results will give you a proper case-ignoring comparison. However, the expression
leaves you with a character that you can compare with another similarly constructed character to test for equality ignoring case distinctions. If the two resulting characters are the same, then the original characters were the same except for possible differences in case. The case conversion methods are:
public staticcodePointtoLowerCase(codePointch)Returns the lowercase character equivalent of
ch. If there is no lowercase equivalent,chis returned.
public staticcodePointtoUpperCase(codePointch)Returns the uppercase character equivalent of
ch. If there is no uppercase equivalent,chis returned.
public staticcodePointtoTitleCase(codePointch)Returns the titlecase character equivalent of
ch.If there is no titlecase equivalent, the result oftoUpperCase(ch)is returned.
The Character class has many methods to test whether a given character is of a particular type in any Unicode character set (for example, isDigit recognizes digits in Ethiopic and Khmer). The methods are passed a char or int code point and return a boolean that answers a question. These methods are:
Method | Is the Character… |
|---|---|
| a defined Unicode character? |
| a digit? |
| ignorable in any identifier (such as a direction control directive)? |
| an |
| valid to start a source code identifier? |
| valid after the first character of a source code identifier? |
| a letter? |
| a letter or digit? |
| a lowercase letter? |
| a space? |
| a titlecase letter? |
| valid to start a Unicode identifier? |
| valid after the first character of a Unicode identifier? |
| an uppercase letter? |
| a source code whitespace character? |
You can also ask whether a char value isLowSurrogate or isHighSurrogate, a specific int code point isSupplementaryCodePoint or isValidCodePoint, or if a pair of char values isSurrogatePair.
Unicode identifiers are defined by the Unicode standard. Unicode identifiers must start with a letter (connecting punctuation such as _ and currency symbols such as ¥ are not letters in Unicode, although they are in the Java programming language) and must contain only letters, connecting punctuation (such as _), digits, numeric letters (such as Roman numerals), combining marks, nonspacing marks, or ignorable control characters (such as text direction markers).
All these types of characters, and several others, are defined by the Unicode standard. The static method getType returns an int that defines a character's Unicode type. The return value is one of the following constants:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Unicode is divided into blocks of related characters. The static nested class Character.Subset is used to define subsets of the Unicode character set. The static nested class Character.UnicodeBlock extends Subset to define a set of standard Unicode character blocks, which are available as static fields of UnicodeBlock. The static method UnicodeBlock.of returns the UnicodeBlock object representing the Unicode character block for a particular character. The UnicodeBlock class also defines constants for all the blocks, such as GREEK, KATAKANA, TELUGU, and COMBINING_MARKS_FOR_SYMBOLS. The of method will return one of these values, or null if the character is not in any block. For example, the code
tests to see if a character is in the GEOMETRIC_SHAPES block.
Two Subset objects define the same Unicode subset if they are the same object, a semantic enforced in Subset by declaring equals and hashCode to be final, and defining them to have the default Object behavior for these methods. If you define your own subsets for some reason, you should give people a way analogous to of to get a single Subset object for each different kind of Subset you define.
Working with sequences of characters, whether arrays of char, strings, or other types that implement CharSequence (see Chapter 13), is complicated by the fact that supplementary characters need to be encoded as a pair of char values. To assist with this, the Character class defines a range of methods that help with the encoding and decoding of surrogate pairs, and accounting for their existence in a sequence of character values:
public static intcharCount(int codePoint)Returns the number of
charvalues needed to encode the given code point. This returns 2 for supplementary characters, otherwise 1.
public static intcodePointAt(char[] seq, int index)Returns the code point defined at the given index in
seq, taking into account that it may be a supplementary character represented by the pairseq[index]andseq[index+1]. There is a variant that takes an additionallimitargument that restricts the use ofindex+1to be less than a specified value.
public static intcodePointAt(CharSequence seq, int index)Returns the code point defined at the given index in
seq, taking into account that it may be a supplementary character represented by the pairseq.charAt(index)andseq.charAt(index+1).
public static intcodePointBefore(char[] seq, int index)Returns the code point defined preceding the given index in
seq, taking into account that it may be a supplementary character represented by the pairseq[index-2]andseq[index-1]. There is a variant that takes an additionalstartargument, that restricts the use ofindex-1andindex-2to be greater than or equal to the specified start position.
public static intcodePointBefore(CharSequence seq, int index)Returns the code point defined at the given index in
seq, taking into account that it may be a supplementary character represented by the pairseq.charAt(index-2)andseq.charAt(index-1).
public static intcodePointCount(char[] seq, int start, int count)Returns the number of code points defined in
seq[start]toseq[start+length], taking into account surrogate pairs. Any unpaired surrogate values count as one code point each.
public static intcodePointCount(CharSequence seq, int start, int end)Returns the number of code points defined in
seq.charAt(start)toseq.charAt(end), taking into account surrogate pairs. Any unpaired surrogate values count as one code point each.
public static intoffsetByCodePoints(char[] seq, int start, int count, int index, int numberOfCodePoints)Returns the index into the array, that is
numberOfCodePointsaway fromindex, considering only the subarray fromseq[start]toseq[start+length], taking into account surrogate pairs. This allows you to skip a given number of code points, without having to manually loop through the array, keeping track of surrogate pairs. If any unpaired surrogates are found, they count as one code point.
public static intoffsetByCodePoints(CharSequence seq, int index, int numberOfCodePoints)Returns the index into the
CharSequence, that isnumberOfCodePointsaway fromindex, taking into account surrogate pairs.
public static char[]toChars(int codePoint)Converts a code point to its
UTF-16 representation as a one- or two-chararray. IfcodePointis not valid,IllegalArgumentExceptionis thrown.
public static inttoChars(int codePoint, char[] dst, int dstBegin)Converts a code point to its
UTF-16 representation, storing it indststarting atdst[dstBegin]and returning the number of characters written (either 1 or 2). IfcodePointis not valid,IllegalArgumentExceptionis thrown.
public static inttoCodePoint(char high, char low)Converts the given surrogate pair of
charvalues to their supplementary code point value. This method does not check thathighandlowform a valid surrogate pair, so you must check that yourself by usingisSurrogatePair.
All of these methods that use indices can throw IndexOutOfBoundsException, if you cause them to try to index outside the given array, or CharSequence, accounting for any imposed limits on the valid range of indices.
The automatic conversion of a variable of primitive type into an instance of its wrapper class, is termed a boxing conversion—the wrapper object acts like a “box” in which the primitive value is held. The opposite conversion, from an instance of a wrapper class to a primitive value, is termed an unboxing conversion.
A boxing conversion replaces any primitive value v with a wrapper object of the same value. The wrapper object's type corresponds to the type of v. For example, given
Integer val = 3;
val will refer to an Integer object because 3 is an int value; val.intValue() will return the value 3.
An unboxing conversion takes a reference to a wrapper object and extracts its primitive value. Building on the previous example,
int x = val;
is equivalent to the explicit
int x = val.intValue();
and the value of x is 3. If val was a Short reference, the unboxing of val would invoke val.shortValue(), and so forth. If a wrapper reference is null, an unboxing conversion will throw a NullPointerException.
The boxing and unboxing conversions are applied automatically in many contexts, such as assignment and argument passing, so primitives and reference types can be used almost interchangeably. However, the conversions do not apply everywhere, and in particular you cannot directly dereference a primitive variable, or value, as if it were an object. For example, given the int variable x, as above, the expression x.toString() will not compile. You can, however, apply a cast to the primitive first, such as:
((Object) x).toString()
The exact contexts in which boxing and unboxing automatically occur are discussed in “Type Conversions” on page 216.
Ideally, you would rely on boxing conversions wherever necessary, without giving it a second thought. In practice, you need to be aware that a boxing conversion may need to allocate an instance of a wrapper class, which consumes memory and which may fail if insufficient memory is available. Given that the wrapper classes are immutable, two objects with the same value can be used interchangeably, and there is no need to actually create two distinct objects. This fact is exploited by requiring that boxing conversions for certain value ranges of certain types always yield the same object. Those types and value ranges are:
Type | Range |
|---|---|
|
|
| all values |
|
|
|
|
|
|
So given the method
static boolean sameArgs(Integer a, Integer b) {
return a == b;
}
the following invocation returns true:
sameArgs(3, 3)
while this invocation returns false:
sameArgs(3, new Integer(3))
An implementation of the virtual machine may choose to expand on these types and ranges, and is free to determine when instances of the wrapper classes are first created: They could be created eagerly and all stored in a lookup table, or they could be created as needed.
Dare to be naïve. | ||
| --R. Buckminster Fuller | ||