
ANDREA: Unhappy the land that has no heroes. GALILEO: No, unhappy the land that needs heroes. | ||
| --Bertolt Brecht, Life of Galileo | ||
The java.util package contains many useful interfaces, classes, and a range of subpackages. The classes and interfaces can be roughly divided into two categories: collections and everything else. This chapter describes the collection types. You will learn about the other general utilities in the next chapter.
Collections (sometimes called containers) are holders that let you store and organize objects in useful ways for efficient access. What will be efficient depends on how you need to use the collection, so collections come in many flavors. Most programming environments provide some collection types, ranging from impoverished up through gargantuan.
In the package java.util you will find interfaces and classes that provide a generic collection framework. This framework gives you a consistent and flexible set of collection interfaces and several useful implementations of these interfaces. You've already been briefly introduced to some of these, such as the interfaces List, Set, Map, and Iterator, and implementations ArrayList and HashMap.
The collection framework is designed to be concise. The principle is to have a core set of valuable collection abstractions and implementations that are broadly useful, rather than an exhaustive set that is complete but conceptually complex and unwieldy.
One way to keep the size down is to represent broad abstractions in the interfaces rather than fine-grained differences. Notions such as immutability and resizability are not represented by different interface types. The core collection interfaces provide methods that allow all common operations, leaving it to specific implementations to refuse to execute particular improper operations by throwing the unchecked java.lang.UnsupportedOperationException.
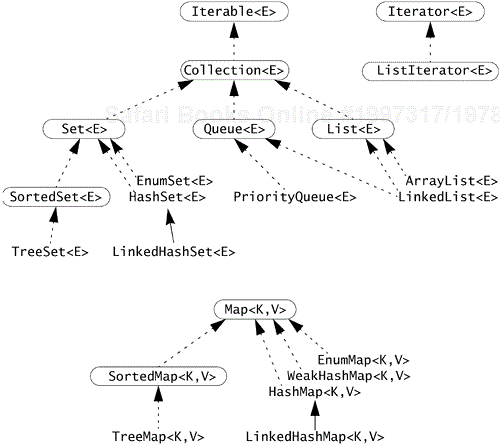
Figure 21-1 shows the collections interfaces and the concrete implementations provided directly in java.util.[1] The collections interfaces are
Collection<E>—. The root interface for collections. Provides such methods asadd,remove,size, andtoArray.Set<E>—. A collection in which no duplicate elements can be present, and whose elements are not necessarily stored in any particular order (extendsCollection<E>).SortedSet<E>—. A set whose elements are sorted (extendsSet<E>).List<E>—. A collection whose elements stay in a particular order unless the list is modified (extendsCollection<E>). This is a general use of the word “list” and does not necessarily mean “linked list,” although that is one possible implementation.Queue<E>—. A collection with an implied ordering in its elements (extendsCollection<E>). Every queue has a head element that is the target of specific operations likepeekandpoll.Map<K,V>—. A mapping from keys to at most one value each. (Mapdoes not extendCollection, although the concepts meaningful to both maps and collections are represented by methods of the same names, and maps can be viewed as collections.)SortedMap<K,V>—. A map whose keys are sorted (extendsMap<K,V>).Iterator<E>—. An interface for objects that return elements from a collection one at a time. This is the type of object returned by the methodIterable.iterator.ListIterator<E>—. An iterator forListobjects that adds usefulList-related methods. This is the type of object returned byList.listIterator.Iterable<E>—. An object that provides anIteratorand so can be used in an enhancedforstatement. Although defined in thejava.langpackage, this is considered part of the collection framework because the vast majority of standard iterable types are collections.
The interfaces SortedSet and SortedMap guarantee that iteration through the elements is done in sorted order. You will learn how to define an order for objects later in this chapter.
The java.util package also provides several useful concrete implementations of these interfaces that will suffice for most of your needs. For example:
HashSet<E>—. ASetimplemented as a hashtable. A good, general-purpose implementation for which searching, adding, and removing are mostly insensitive to the size of the contents.TreeSet<E>—. ASortedSetimplemented as a balanced binary tree. Slower to search or modify than aHashSet, but keeps the elements sorted.ArrayList<E>—. AListimplemented using a resizable array. It is expensive to add or delete an element near the beginning if the list is large, but relatively cheap to create and fast for random access.LinkedList<E>—. A doubly linkedListandQueueimplementation. Modification is cheap at any size, but random access is slow.HashMap<K,V>—. A hashtable implementation ofMap. A very generally useful collection with relatively cheap lookup and insertion times.TreeMap<K,V>—. An implementation ofSortedMapas a balanced binary tree to keep its elements ordered by key. Useful for ordered data sets that require moderately quick lookup by key.WeakHashMap<K,V>—. An hashtable implementation ofMapthat references its keys with weak reference objects (see page 454). This is useful only in limited situations.
Nearly all the implementation classes in java.util are both Cloneable and Serializable. The exceptions are PriorityQueue which is not Cloneable, and WeakHashMap which is neither.
In this chapter you first learn about iteration because it is useful with all the collection classes. We then cover ordering since it is used by many of the collection types. We then present the details of the Collection-based types, followed by the Map-based types. After that we look at the various utilities available, and we show you how to make unmodifiable and type-safe versions of your collections. Next we show you the synchronized and concurrent collections. You will then learn how to write your own iteration and collection types in case you have a need that the provided classes do not fill. Finally, we cover the “legacy collections” in java.util that predate the overall collection system, but which you will find in some existing code. One of these legacy collection types—Properties—continues in common use.
For simplicity, we usually refer to the various interfaces without mentioning their type parameters—for example, Iterator or Collection—except where it is necessary to show that the same type parameter is being used—for example, that iterator has a return type Iterator<E> for a Collection<E>.
A few conventions related to exceptions are used throughout the collections classes and interfaces, and we do not wish to document them for every constructor and method where they may occur:
Methods that are optional in an implementation of an interface throw
UnsupportedOperationExceptionwhen not implemented. We indicate which methods are optional as we go through—using “(Optional)” at the end of the method description.Methods or constructors that accept elements (either individually or as part of other collections) to be added to the current collection can throw
ClassCastExceptionif the element is not of an appropriate type for the collection, or for sorted collections, if the element cannot be compared with other elements. Methods that check for the existence of elements or try to remove them may also throwClassCastException.Methods or constructors that accept elements (either individually or as part of other collections) to be added to the current collection throw
IllegalArgumentExceptionif the element's value is not appropriate for the collection—for example, some collections, such as subsets, define restricted ranges on the values of elements allowed in the collection.Methods that return individual elements of a collection will give you a
NoSuchElementExceptionif the collection is empty.Methods or constructors that take parameters of reference type usually throw
NullPointerExceptionif passed anullreference. The exceptions to this are collections that acceptnullelements, with whichnullcan be used when adding, removing, or searching.
Any variations to the above, or other exceptions generated, are documented on a case-by-case basis.
You've encountered iteration several times already during the course of this book—particularly in the discussion of the enhanced for loop in Chapter 10. This section reviews the basic operation of an iterator and covers its additional capabilities and the additional iterator types.
Collection<E> extends Iterable<E>, which defines an iterator method that returns an object that implements the Iterator<E> interface:
public booleanhasNext()Returns
trueif the iteration has more elements.
public Enext()Returns the next element in the iteration. If there is no next element a
NoSuchElementExceptionis thrown.
public voidremove()Removes the element returned most recently by the iteration from the underlying collection.
removecan be called only once per call ofnext. Ifnexthas not yet been called, or ifremovehas already been called since the last call tonext, anIllegalStateExceptionis thrown. (Optional)
The following code uses all three methods of Iterator to remove all long strings from a collection:
public void removeLongStrings
(Collection<? extends String> coll, int maxLen) {
Iterator<? extends String> it = coll.iterator();
while (it.hasNext()) {
String str = it.next();
if (str.length() > maxLen)
it.remove();
}
}
First we use iterator to get an Iterator object that steps through the contents of the collection one element at a time (recall that the enhanced for loop can't be used when you want to remove elements using the iterator). Then we loop as long as hasNext returns true to indicate that there is at least one more element left in the iteration. Each time through the loop we get the next element of the list using next. If any string is longer than the maximum allowed length, we use the iterator's remove method to remove the most recent element returned by next. When you use an iterator's remove method you modify the underlying collection safely for that iterator—the iterator will properly move through the subsequent elements of the collection. Removing elements from the collection any other way (using operations on the collection or through a different iterator on the same collection) is unsafe.
The ListIterator<E> interface extends Iterator<E>, adding methods you can use to manipulate an ordered List object during iteration. You can iterate forward using hasNext and next, backward using hasPrevious and previous, or back and forth by intermixing the calls as you please. The following code loops backward through a list of strings:
ListIterator<String> it = list.listIterator(list.size());
while (it.hasPrevious()) {
String obj = it.previous();
System.out.println(obj);
// ... use obj ...
}
This gets a ListIterator positioned one beyond the end of the list, and then backs up through the list one element at a time, printing each element. List elements are indexed by position, just like array elements, from 0 to list.size()-1. The methods nextIndex or previousIndex get the index of the element that a subsequent invocation of next or previous will return. The next index when the iterator is at the end of the list is returned as list.size(). The previous index when the iterator is at the first element in the list (index 0) is returned as –1.
The remove method on a ListIterator removes the last value returned by either next or previous. In addition to remove, you can use two additional methods to modify the list's contents:
public voidset(E elem)Replaces the last element returned by
nextorpreviouswithelem. If you have calledremoveoraddon the iterator since the last call tonextorprevious, callingsetthrowsIllegalStateException. (Optional)
public voidadd(E elem)Inserts
eleminto the list in front of the next element that would be returned, or at the end ifhasNextreturnsfalse. The iterator is moved forward; if you invokepreviousafter anaddyou will get the added element. (Optional)
The contract of remove is extended such that an IllegalStateException is thrown if remove is invoked and either set or add has been invoked since the last call to next or previous.
The contracts for Iterator and ListIterator do not include a snapshot guarantee. In other words, changing the contents of the collection while the iterator is in use can affect the values returned by the methods. For example, if the implementation of next uses the contents of the original collection for its list, it is dangerous to remove elements from the list as you step through it except through the iterator's own methods. A snapshot would return the elements as they were when the Iterator or ListIterator object was created, immune from future changes. You can rely on having a snapshot of the contents only if the method that returns an iterator object explicitly makes a snapshot guarantee. If you need a snapshot but don't have such a guarantee, you can create a snapshot by making a simple copy of the collection, such as with an ArrayList:
public <T> Iterator<T>
snapshotIterator(Collection<? extends T> coll) {
return new ArrayList<T>(coll).iterator();
}
Any utility method that returns a collection will invariably be a generic method. We introduce the type variable T to represent the unknown type of the collection being passed in. The snapshotIterator method can accept any collection of T or a subtype of T, but only guarantees that it returns an Iterator<T>.[2]
Many of the iterators defined in the java.util package are what is known as fail-fast iterators. Such iterators detect when a collection has been modified other than through the iterator itself, and fail quickly and cleanly by throwing an exception—a ConcurrentModificationException—rather than risk performing an action whose behavior may be unsafe.
The interface java.lang.Comparable<T> can be implemented by any class whose objects can be sorted. The interface has a single method:
public intcompareTo(T other)Returns a value that is less than, equal to, or greater than zero as this object is less than, equal to, or greater than the
otherobject. This method should return zero only ifequalswith the same object would returntrue. If the objects are not mutually comparable (such as anIntegerwith aString), aClassCastExceptionis thrown.
The ordering defined by compareTo is a class's natural ordering, that is, the ordering that is most natural to objects of the class. It is also a total ordering, meaning that any two objects of the same type must be mutually comparable—that is, you must be able to compare them in either order and always get the same result as to which is the larger. Similarly, the equals method defines a natural equivalence.
Many existing classes are Comparable, including String, java.io.File, java.util.Date, and all the primitive wrapper class types.
If a given class does not implement Comparable or if its natural ordering is wrong for some purpose, you can often provide a java.util.Comparator object instead. The Comparator<T> interface has the method
public intcompare(T o1, T o2)Provides an ordering in the same manner as
Comparable.compareTofor the two provided objects.
You can use Comparable and Comparator objects to sort and search List objects with the Collections class's static methods sort and binarySearch. The Collections class (see page 594) also provides static methods min and max to return the smallest and largest element in a Collection.
Comparing strings ignoring case is a common requirement, so the String class defines a Comparator object for this purpose, available from the field String.CASE_INSENSITIVE_ORDER.
As you have seen, most collection types are subtypes of the Collection interface. The only exceptions are those that are subtypes of Map. In this section we cover the Collection interface. The following sections describe the interfaces that extend Collection and the specific collection implementations provided in java.util. We leave Map and its related types for later. We also defer talking about implementing your own collection types.
The basis of much of the collection system is the Collection interface. As you saw in Figure 21-1, most of the actual collection types implement this interface, usually by implementing an extended interface such as Set or List. So Collection is a good place to start understanding collections. It has the following primary methods for working with an individual collection:
public intsize()Returns the size of this collection, that is, the number of elements it currently holds. The value returned is limited to
Integer.MAX_VALUEeven if the collection holds more elements.
public booleanisEmpty()Returns
trueif this collection currently holds no elements.
public booleancontains(Object elem)Returns
trueif the collection contains the objectelem; that is, if this collection has an element on which invokingequalswithelemreturnstrue. Ifelemisnull, returnstrueif there is anullelement in the collection.
public Iterator<E>iterator()Returns an iterator that steps through the elements of this collection.
public Object[]toArray()Returns a new array that contains all the elements of this collection.
public <T> T[]toArray(T[] dest)Returns an array that contains all the elements of this collection. If the elements will fit in
dest, then they are placed indestand it isdestthat is returned. Ifdesthas more elements than this collection, the first element indestthat follows the contents of the collection is set tonullto mark the end of the collection. If the elements do not fit indest, a new, larger array is created of the same type asdest, filled in, and returned. If the type ofdestis not compatible all the elements in the collection, anArrayStoreExceptionis thrown.
public booleanadd(E elem)Makes sure that this collection contains the object
elem, returningtrueif this required changing the collection. If this collection allows duplicates,addwill always returntrue. If duplicates are not allowed and an equivalent element is already in the collection,addwill returnfalse. (Optional)
public booleanremove(Object elem)Removes a single instance of
elemfrom the collection, returningtrueif this required changing the collection (that is, if the element existed in this collection). Ifelemisnull, returnstrueif there was anullelement in the collection. (Optional)
All methods that need the notion of equivalence (such as contains and remove) use the equals method on the relevant objects.
The toArray method that has no parameters returns an array of Object. You can use toArray(T[]) to create arrays of other types. For example, if your collection contains String objects, you may want to create a String array. The following code will do that:
String[] strings = new String[collection.size()]; strings = collection.toArray(strings);
Notice that strings is assigned the return value of toArray. This is to be safe in case the size of the collection has increased since the array was allocated, in which case the returned array will not be the one originally allocated. You can also use an empty String array to pass in the desired type and let toArray allocate an array of exactly the right size:
String[] strings = collection.toArray(new String[0]);
Several methods of Collection operate in bulk from another collection. The methods are provided for convenience; also, a collection can often operate more efficiently in bulk.
public booleancontainsAll(Collection<?> coll)Returns
trueif this collection contains each of the elements incoll.
public booleanaddAll(Collection<? extends E> coll)Adds each element of
collto this collection, returningtrueif any addition required changing the collection. (Optional)
public booleanremoveAll(Collection<?> coll)Removes each element of
collfrom this collection, returningtrueif any removal required changing the collection. (Optional)
public booleanretainAll(Collection<?> coll)Removes from this collection all elements that are not elements of
coll, returningtrueif any removal required changing the collection. (Optional)
public voidclear()Removes all elements from this collection. (Optional)
This Collection interface is purposely very general. Each specific collection type can define restrictions on its parameters or other related behavior. A collection may or may not accept null elements, may be restricted to certain types of elements, may retain elements in a sorted order, and so on. Each collection that makes a restriction should state those restrictions in its documentation so that users can understand the contract for that collection.
The Set<E> interface extends Collection<E>, providing a more specific contract for its methods, but adds no new methods of its own. A collection that is a Set contains no duplicate elements. If you add the same element twice to a set (in other words, if you add two objects that are equal), the first invocation will return true, while the second will return false. If after this, remove is similarly invoked twice, the first remove of the element will return true since the set was changed by removing the element, while the second will return false since the element was no longer present. A set may also contain at most one null element.
The SortedSet<E> interface extends Set<E> to specify an additional contract—iterators on such a set will always return the elements in a specified order. By default this will be the element's natural order. In the implementations of SortedSet provided in java.util you can also specify a Comparator object that will be used to order the elements instead of the natural order.
SortedSet adds some methods that make sense in an ordered set:
public Comparator<? super E>comparator()Returns the
Comparatorbeing used by this sorted set, ornullif the elements' natural order is being used. Note the use of the lower bounded wildcard in the return type; any implementation of this interface should accept a comparator that is typed the same way.
public Efirst()Returns the first (lowest) object in this set.
public Elast()Returns the last (highest) object in this set.
public SortedSet<E>subSet(E min, E max)Returns a view of the set that contains all the elements of this set whose values are greater than or equal to
minand less thanmax. The view is backed by the collection; that is, changes to the collection that fall within the range will be visible through the returned subset and vice versa. Ifminis greater thanmax, or if this set is itself a view of another set andminormaxfall outside the range of that view, anIllegalArgumentExceptionis thrown. You will also get anIllegalArgumentExceptionif you attempt to modify the returned set to contain an element that is outside the specified range.
public SortedSet<E>headSet(E max)Returns a view of the set that contains all the elements of this set whose values are less than the value of
max. This view is backed by the collection as withsubSet. The exceptions thrown by this method or the returned set are the same as those ofsubSet.
public SortedSet<E>tailSet(E min)Similar to
headSet, but the returned set contains all the elements of this set whose values are greater than or equal to the value ofmin.
The notion of being backed by a collection is important in many methods. The sets returned by the subsetting methods are not snapshots of the matching contents. Rather, they are views onto the underlying collection that filter out certain elements, returning an empty collection if all elements are filtered out. Because the subsets are backed by the original collection, the views remain current no matter which set you use—the subset or the original set. You can create snapshots by making copies of the view, as in
public <T> SortedSet<T> copyHead(SortedSet<T> set, T max) {
SortedSet<T> head = set.headSet(max);
return new TreeSet<T>(head); // contents from head
}
This utilizes the copy constructor provided by most of the concrete collection implementations to create a new collection whose initial members are the same as the collection passed to the constructor.
The java.util package gives you two general-purpose Set implementations—HashSet and LinkedHashSet—and one SortedSet implementation, TreeSet.
HashSet<E> is a Set<E> implemented with a hashtable. Modifying the contents of a HashSet or testing for containment are 0(1) constant-time operations[3]—that is, they do not get larger as the size of the set increases (assuming that the hashCode methods of the contents are well written to distribute the hash codes widely across the full range of int values). HashSet has four constructors:
publicHashSet(int initialCapacity, float loadFactor)Creates a new
HashSetwithinitialCapacityhash buckets and the givenloadFactor, which must be a positive number. When the ratio of the number of elements in the set to the number of hash buckets is greater than or equal to the load factor, the number of buckets is increased.
publicHashSet(int initialCapacity)Creates a new
HashSetwithinitialCapacityand a default load factor.
publicHashSet()Creates a new
HashSetwith a default initial capacity and load factor.
publicHashSet(Collection<? extends E> coll)Creates a new
HashSetwhose initial contents are the elements incoll. The initial capacity is based on the size ofcoll, and the default load factor is used.
The initial capacity and load factor are used to construct the HashMap that underlies a HashSet. The meaning of these values is discussed in “HashMap” on page 590. Iteration of a HashSet requires a time proportional to the sum of the size and capacity.
LinkedHashSet<E> extends HashSet<E> and refines the contract of HashSet by defining an order to the elements in the set. Iterating through the contents of a LinkedHashset will return the elements in insertion order—the order in which they were added. Aside from this, LinkedHashSet behaves the same as HashSet and defines constructors with the same form. The performance of a LinkedHashSet is likely to be a little slower than a HashSet because of the overhead of maintaining the linked list structure; however, iteration only requires a time propertional to the size, regardless of capacity.
If you need a SortedSet, you can use TreeSet, which stores its contents in a tree structure that is kept balanced. This means that the time required to modify or search the tree is . TreeSet has four constructors:
publicTreeSet()Creates a new
TreeSetthat is sorted according to the natural order of the element types. All elements added to this set must implement theComparableinterface and be mutually comparable.
publicTreeSet(Collection<? extends E> coll)Equivalent to using
TreeSet()and then adding the elements ofcoll.
publicTreeSet(Comparator<? super E> comp)Creates a new
TreeSetthat is sorted according to the order imposed bycomp.
publicTreeSet(SortedSet<E> set)Creates a new
TreeSetwhose initial contents will be the same as those insetand that is sorted in the same way asset.
The List<E> interface extends Collection<E> to define a collection whose elements have a defined order—each element exists in a particular position in the collection, indexed from 0 to list.size()-1. Or, in other words, a List defines a sequence of elements. This requires a refinement of the contracts of several methods inherited from Collection: when you add an element, it is placed at the end of the list; When you remove the nth element from the list, the element that was after it is shifted over, becoming the new nth element; and the toArray methods fill in the array in the list's order.
List also adds several methods that make sense in an ordered collection:
public Eget(int index)Returns the
indexth entry in the list.
public Eset(int index, E elem)Sets the indexth entry in the list to
elem, replacing the previous element and returning it. (Optional)
public voidadd(int index, E elem)Adds the entry
elemto the list at theindexth position, shifting every element farther in the list down one position. (Optional)
public Eremove(int index)Removes and returns the
indexth entry in the list, shifting every element farther in the list up one position. (Optional)
public intindexOf(Object elem)Returns the index of the first object in the list that is
equaltoelem, or that isnullifelemisnull. Returns –1 if no match is found.
public intlastIndexOf(Object elem)Returns the index of the last object in the list that is
equaltoelem, or that isnullifelemisnull. Returns –1 if no match is found.
public List<E>subList(int min, int max)Returns a
Listthat is a view on this list over the range, starting withminup to, but not including,max. For example,subList(1,5)would return a list containing elements number 1, 2, 3, and 4 from this list. The returned list is backed by this list, so changes made to the returned list are reflected in this list. Changes made directly to the backing list are not guaranteed to be visible to a sublist and can cause undefined results (so don't do it). Sublists allow you to do anything to part of a list that you could to do an entire list, so they can be a powerful tool. For example, you can remove part of a list usinglist.subList(min,max).clear().
public ListIterator<E>listIterator(int index)Returns a
ListIteratorobject that will iterate through the elements of the list starting at theindexth entry.
public ListIterator<E>listIterator()Returns a
ListIteratorobject that will iterate through the elements of the list starting at the beginning.
All the methods that take an index will throw IndexOutOfBoundsException if index is less than zero or greater than or equal to the list's size.
The java.util package provides two implementations of List—ArrayList and LinkedList.
ArrayList is a good basic list implementation that stores its elements in an underlying array. Adding and removing elements at the end is very simple—0(1). Getting the element at a specific position is also 0(1). Adding and removing elements from the middle is more expensive—0(n-i) where n is the size of the list and i is the position of the element being removed. Adding or removing the element requires copying the remainder of the array one position up or down.
An ArrayList has a capacity, which is the number of elements it can hold without allocating new memory for a larger array. As you add elements they are stored in the array, but when room runs out, a replacement array must be allocated. Setting your initial capacity correctly can improve performance. If the initial size of the data is significantly smaller than its final size, setting the initial capacity to a larger value reduces the number of times the underlying array must be replaced with a larger copy. Setting the size too large can waste space.
ArrayList has three constructors:
publicArrayList()Creates a new
ArrayListwith a default capacity.
publicArrayList(int initialCapacity)Creates a new
ArrayListthat initially can storeinitialCapacityelements without resizing.
publicArrayList(Collection<? extends E> coll)Creates a new
ArrayListwhose initial contents are the contents ofcoll. The capacity of the array is initially 110% of the size ofcollto allow for some growth without resizing. The order is that returned by the collections iterator.
ArrayList also provides some methods to manage capacity:
public voidtrimToSize()Sets the capacity to be exactly the current size of the list. If the capacity is currently larger than the size, a new, smaller underlying array will be allocated and the current values copied in. You can thus reduce the amount of memory necessary to hold the list, although at some cost.
public voidensureCapacity(int minCapacity)Sets the capacity to
minCapacityif the capacity is currently smaller. You can use this if you are about to add a large number of elements to the list, and so ensure the array will be reallocated at most once (whenensureCapacityis invoked) rather than possibly multiple times while the elements are added.
ALinkedList is a doubly linked list whose performance characteristics are virtually the reverse of ArrayList: Adding an element at the end is 0(1), but everything else is swapped. Adding or removing an element in the middle is 0(1) because it requires no copying, while getting the element at a specific position i is 0(i) since it requires starting at one end and walking through the list to the ith element.
LinkedList provides two constructors and adds methods that are useful and efficient for doubly linked lists:
publicLinkedList()Creates a new empty
LinkedList.
publicLinkedList(Collection<? extends E> coll)Creates a new
LinkedListwhose initial contents are those ofcoll. The order is that returned by the collection's iterator.
public EgetFirst()Returns the first object in this list.
public EgetLast()Returns the last object in this list.
public EremoveFirst()Removes the first object in this list.
public EremoveLast()Removes the last object in this list.
public voidaddFirst(E elem)Adds
eleminto this list as the first element.
public voidaddLast(E elem)Adds
eleminto this list as the last element.
A LinkedList is a good base for a queue—and indeed it implements the Queue interface discussed next—or any other list in which most of the action is not at the end. For a stack, or for building up a list of elements as you find them, an ArrayList is more efficient because it requires fewer objects: the one array instead of one object for each element in the list. You can also efficiently scan an ArrayList without creating an Iterator object, by simply using an int as an index. This can be a good reason to use an ArrayList for a list that will be scanned frequently.
Here is a Polygon class that stores a list of Point objects that are the polygon's vertices:
import java.util.List;
import java.util.ArrayList;
public class Polygon {
private List<Point> vertices =
new ArrayList<Point>();
public void add(Point p) {
vertices.add(p);
}
public void remove(Point p) {
vertices.remove(p);
}
public int numVertices() {
return vertices.size();
}
// ... other methods ...
}
Notice that vertices is a List reference that is assigned an ArrayList object. You should declare a variable to be as abstract a type as possible, preferring the abstract List type to the implementation class ArrayList. As written, you could change Polygon to use a LinkedList if that would be more efficient by changing only one line of code—the line that creates the list. All the other code can remain unchanged.
Exercise 21.1: Write a program that opens a file and reads its lines one at a time, storing each line in a List sorted by String.compareTo. The line-reading class you created for Exercise 20.4 should prove helpful.
The marker interface RandomAccess marks list implementations that support fast random access. Random access means that any element of the list can be accessed directly. For example, ArrayList implements RandomAccess because any element can easily be accessed by its index. In contrast, a LinkedList does not implement RandomAccess because accessing an element by index requires traversing from one end of the list. Some algorithms for manipulating random access lists perform poorly when applied to sequential lists, so the purpose of the RandomAccess interface is to allow an algorithm to adapt depending on the kind of list it is given. As a rule of thumb, if code such as
for (int i = 0; i < list.size(); i++)
process(list.get(i));
will typically be faster than using
Iterator it = list.iterator();
while (it.hasNext())
process(it.next());
then your list should implement RandomAccess.
The Queue<E> interface extends Collection<E> to add some structure to the internal organization of the collection. A queue defines a head position, which is the next element that would be removed. Queues often operate on a first-in-first-out ordering, but it is also possible to have last-in-first-out ordering (commonly known as a stack) or to have a specific ordering defined by a comparator or by comparable elements. Each implementation must specify its ordering properties. The Queue interface adds several methods that work specifically with the head:
public Eelement()Returns, but does not remove, the head of the queue. If the queue is empty a
NoSuchElementExceptionis thrown.
public Epeek()Returns, but does not remove, the head of the queue. If the queue is empty,
nullis returned. This differs fromelementonly in its handling of an empty queue.
public Eremove()Returns and removes the head of the queue. If the queue is empty a
NoSuchElementExceptionis thrown.
public Epoll()Returns and removes the head of the queue. If the queue is empty,
nullis returned. This differs fromremoveonly in its handling of an empty queue.
There is also a method for inserting into a queue:
public booleanoffer(E elem)Attempts to insert the given element into this queue. If the attempt is successful,
trueis returned, otherwisefalse. For queues that have genuine reason to reject a request—such as a queue with finite capacity—this method is preferable to theCollectionaddmethod which can only indicate failure by throwing an exception.
Queues in general should not accept null elements because null is used as a sentinel value for poll and peek to indicate an empty queue.
The LinkedList class provides the simplest implementation of Queue. For historical reasons the LinkedList class accepts null elements, but you should avoid inserting null elements when using a LinkedList instance as a queue.
The other Queue implementation is PriorityQueue, an unbounded queue, based on a priority heap. The head of the queue is the smallest element in it, where smallest is determined either by the elements' natural order or by a supplied comparator. A PriorityQueue is not a sorted queue in the general sense—you can't pass it to a method expecting a sorted collection—because the iterator returned by iterator is not guaranteed to traverse the elements in priority order; rather it guarantees that removing elements from the queue occurs in a given order. The iterator can traverse the elements in any order. If you need ordered traversal you could extract the elements to an array and then sort the array (see “The Arrays Utility Class” on page 607).
Whether the smallest element represents the element with the highest or lowest “priority” depends on how the natural order or the comparator is defined. For example, if queuing Thread objects according to their execution priority, then the smallest element represents a Thread with the lowest execution priority.
The performance characteristics of a PriorityQueue are unspecified. A good implementation based on a priority heap would provide 0(1)operations on the head, with 0(logn) for general insertion. Anything that requires traversing, such as removing a specific element or searching for one, would be 0(n)
There are six constructors:
publicPriorityQueue(int initialCapacity)Creates a new
PriorityQueuethat can storeinitialCapacityelements without resizing and that orders the elements according to their natural order.
publicPriorityQueue()Creates a new
PriorityQueuewith the default initial capacity, and that orders the elements according to their natural order.
publicPriorityQueue(int initialCapacity, Comparator<? super E> comp)Creates a new
PriorityQueuethat can initially storeinitialCapacityelements without resizing, and that orders the elements according to the supplied comparator.
publicPriorityQueue(Collection<? extends E> coll)Creates a new
PriorityQueuewhose initial contents are the contents ofcoll. The capacity of the queue is initially 110% of the size ofcollto allow for some growth without resizing. Ifcollis aSortedSetor anotherPriorityQueue, then this queue will be ordered the same way; otherwise, the elements will be sorted according to their natural order. If any element incollcan't be compared, aClassCastExceptionis thrown.
publicPriorityQueue(SortedSet<? extends E> coll)Creates a new
PriorityQueuewhose initial contents are the contents ofcoll. The capacity of the queue is initially 110% of the size ofcollto allow for some growth without resizing. This queue will be ordered the same way ascoll.
publicPriorityQueue(PriorityQueue<? extends E> coll)Creates a new
PriorityQueuewhose initial contents are the contents ofcoll. The capacity of the queue is initially 110% of the size ofcollto allow for some growth without resizing. This queue will be ordered the same way ascoll.
Since PriorityQueue does not accept null elements, all constructors that take collections throw NullPointerException if a null element is encountered.
The comparator used to construct the priority queue can be retrieved with the comparator method. This has the same contract as the comparator method in SortedSet, returning null if the elements' natural ordering is being used.
The interface Map<K,V> does not extend Collection because it has a contract that is different in important ways. The primary difference is that you do not add an element to a Map—you add a key/value pair. A Map allows you to look up the value stored under a key. A given key (as defined by the equals method of the key) maps to one value or no values. A value can be mapped to by as many keys as you like. For example, you might use a map to store a mapping of a person's name to their address. If you have an address listed under a name, there will be exactly one in the map. If you have no mapping, there will be no address value for that name. Multiple people might share a single address, so the map might return the same value for two or more names.
The basic methods of the Map interface are
public intsize()Returns the size of this map, that is, the number of key/value mappings it currently holds. The return value is limited to
Integer.MAX_VALUEeven if the map contains more elements.
public booleanisEmpty()Returns
trueif this collection currently holds no mappings.
public booleancontainsKey(Object key)Returns
trueif the collection contains a mapping for the givenkey.
public booleancontainsValue(Object value)Returns
trueif the collection contains at least one mapping to the givenvalue.
public Vget(Object key)Returns the object to which
keyis mapped, ornullif it is not mapped. Also returnsnullifkeyhas been mapped tonullin a map that allowsnullvalues. You can usecontainsKeyto distinguish between the cases, although this adds overhead. It can be more efficient to put marker objects instead ofnullinto the map to avoid the need for the second test.
public Vput(K key, V value)Associates
keywith the given value in the map. If a map already exists forkey, its value is changed and the original value is returned. If no mapping exists,putreturnsnull, which may also mean thatkeywas originally mapped tonull. (Optional)
public Vremove(Object key)Removes any mapping for the
key. The return value has the same semantics as that ofput. (Optional)
public voidputAll(Map< ? extends K, ? extends V> otherMap)Puts all the mappings in
otherMapinto this map. (Optional)
public voidclear()Removes all mappings. (Optional)
Methods that take keys as parameters may throw ClassCastException if the key is not of the appropriate type for this map, or NullPointerException if the key is null and this map does not accept null keys.
You can see that, though Map does not extend Collection, methods with the same meaning have the same names, and analogous methods have analogous names. This helps you remember the methods and what they do.
Generally, you can expect a Map to be optimized for finding values listed under keys. For example, the method containsKey will usually be much more efficient than containsValue on larger maps. In a HashMap, for example, containsKey is 0(1), whereas containsValue is 0(n) —the key is found by hashing, but the value must be found by searching through each element until a match is found.
Map is not a collection, but there are methods that let you view the map using collections:
public Set<K>keySet()Returns a
Setwhose elements are the keys of this map.
public Collection<V>values()Returns a
Collectionwhose elements are the values of this map.
public Set<Map.Entry<K,V>>entrySet()Returns a
Setwhose elements areMap.Entryobjects that represent single mappings in the map. As you will see soon,Map.Entryis a nested interface with methods to manipulate the entry.
The collections returned by these methods are backed by the Map, so removing an element from one of these collections removes the corresponding key/value pair from the map. You cannot add elements to these collections—they do not support the optional methods for adding to a collection. If you iterate through the key and value sets in parallel you cannot rely on getting key/value pairs—they may return values from their respective sets in any order. If you need such pairing, you should use entrySet.
The interface Map.Entry<K,V> defines methods for manipulating the entries in the map, as returned from the Map interface's entrySet method:
public KgetKey()Returns the key for this entry.
public VgetValue()Returns the value for this entry.
public VsetValue(V value)Sets the value for this entry and returns the old value.
Note that there is no setKey method—you change the key by removing the existing mapping for the original key and adding another mapping under the new key.
The SortedMap interface extends Map refining the contract to require that the keys be sorted. This ordering requirement affects the collections returned by keySet, values, and entrySet. SortedMap also adds methods that make sense in an ordered map:
public Comparator<? super K>comparator()Returns the comparator being used for sorting this map. Returns
nullif none is being used, which means that the map is sorted using the keys' natural order.
public KfirstKey()Returns the first (lowest value) key in this map.
public KlastKey()Returns the last (highest value) key in this map.
public SortedMap<K,V>subMap(K minKey, K maxKey)Returns a view of the portion of the map whose keys are greater than or equal to
minKeyand less thanmaxKey.
public SortedMap<K,V>headMap(K maxKey)Returns a view of the portion of the map whose keys are less than
maxKey.
public SortedMap<K,V>tailMap(K minKey)Returns a view of the portion of the map whose keys are greater than or equal to
minKey.
Any returned map is backed by the original map so changes made to either are visible to the other.
A SortedMap is to Map what SortedSet is to Set and provides almost identical functionality except that SortedMap works with keys. The exceptions thrown by the SortedMap methods mirror those thrown by its SortedSet counterparts.
The java.util package gives you four general-purpose Map implementations—HashMap, LinkedHashMap, IdentityHashMap, and WeakHashMap—and one SortedMap implementation, TreeMap.
HashMap implements Map with a hashtable, where each key's hashCode method is used to pick a place in the table. With a well-written hashCode method, adding, removing, or finding a key/value pair is 0(1). This makes a HashMap a very efficient way to associate a key with a value—HashMap is one of the most commonly used collections. You already have seen a HashMap in “Implementing Interfaces” on page 127. The constructors for HashMap are
publicHashMap(int initialCapacity, float loadFactor)Creates a new
HashMapwithinitialCapacityhash buckets and the givenloadFactor, which must be a positive number.
publicHashMap(int initialCapacity)Creates a new
HashMapwith the giveninitialCapacityand a default load factor.
publicHashMap()Creates a new
HashMapwith default initial capacity and load factor.
publicHashMap(Map<? extends K, ? extends V> map)Creates a new
HashMapwhose initial mappings are copied frommap. The initial capacity is based on the size ofmap; the default load factor is used.
The internal table used by a hash map consists of a number of buckets, initially determined by the initial capacity of the hash map. The hash code of an object (or a special hashing function used by the hash map implementation) determines which bucket an object should be stored in. The fewer the number of buckets, the more likely that different objects will get stored in the same bucket, so looking up the object will take longer because the bucket has to be examined in detail. The more buckets there are, the less likely it is that this will occur, and the lookup performance will improve—but the space occupied by the hash map will increase. Further, the more buckets there are, the longer iteration will take, so if iteration is important you may want to reduce the number of buckets—the cost of iteration is proportional to the sum of the hash map's size and capacity. The load factor determines when the hash map will automatically have its capacity increased. When the number of entries in the hash map exceeds the product of the load factor and the current capacity, the capacity will be doubled. Increasing the capacity requires that all the elements be rehashed and stored in the correct new bucket—a costly operation.
You need to consider the load factor and the initial capacity when creating the hash map, be aware of the expected number of elements the map will hold, and be aware of the expected usage patterns of the map. If the initial capacity is too small and the load factor too low, then numerous rehash operations will occur. In contrast, with a large enough initial capacity and load factor, a rehash might never be needed. You need to balance the cost of normal operations against the costs of iteration and rehashing. The default load factor of 0.75 provides a good general trade-off.
LinkedHashMap<K,V> extends HashMap<K,V> and refines the contract of HashMap by defining an order to the entries in the map. Iterating through the contents of a LinkedHashMap (either the entry set or the key set) will, by default, return the entries in insertion order—the order in which they were added. Aside from this, LinkedHashMap behaves like HashMap and defines constructors of the same forms. The performance of a LinkedHashMap is likely to be a little slower than a HashMap due to the overhead of maintaining the linked list structure; however, iteration only requires a time proportional to the size, regardless of capacity.
Additionally, LinkedHashMap provides a constructor that takes the initial capacity, the load factor and a boolean flag accessOrder. If accessOrder is false, then the map behaves as previously described with respect to ordering. If accessOrder is true, then the map is sorted from the most recently accessed entry to the least recently accessed entry, making it suitable for implementing a Least Recently Used (LRU) cache. The only methods to count as an access of an entry are direct use of put, get, and putAll—however, if invoked on a different view of the map (see Section 21.10 on page 597), even these methods do not count as an access.
The general contract of Map requires that equality for keys be based on equivalence (that is, using the equals method). But there are times when you really want a map that stores information about specific objects instead of treating all equivalent objects as a single key to information. Consider the serialization mechanism discussed in Chapter 20. When determining if an object in the serialization graph has already been seen, you need to check that it is the actual object, not just one that is equivalent. To support such requirements the IdentityHashMap class uses object identity (comparison using ==) to determine if a given key is already present in the map. This is useful, but it does break the general contract of Map.
There are three constructors:
publicIdentityHashMap(int expectedSize)Creates a new
IdentityHashMapwith the given expected maximum size.
publicIdentityHashMap()Creates a new
IdentityHashMapwith the default expected maximum size.
publicIdentityHashMap(Map<? extends K, ? extends V> map)Creates a new
IdentityHashMapcontaining the entries from the given map.
The expected maximum size is a hint for the initial capacity of the map, but its exact effects are not specified.
The collection implementations all use strong references for elements, values, and keys. As with strong references elsewhere, this is usually what you want. Just as you occasionally need reference objects to provide weaker references, you also occasionally need a collection that holds the objects it contains less strongly. You can use WeakHashMap in such cases.
WeakHashMap behaves like HashMap but with one difference—WeakHashMap refers to keys by using WeakReference objects instead of strong references. As you learned in Section 17.5 on page 454, weak references let the objects be collected as garbage, so you can put an object in a WeakHashMap without the map's reference forcing the object to stay in memory. When a key is only weakly reachable, its mapping may be removed from the map, which also drops the map's strong reference to the key's value object. If the value object is otherwise not strongly reachable, this could result in the value also being collected.
A WeakHashMap checks to find unreferenced keys when you invoke a method that can modify the contents (put, remove, or clear), but not before get. This makes the performance of such methods dependent on the number of keys that have become unreferenced since the last check. If you want to force removal you can invoke one of the modifying methods in a way that will have no effect, such as by removing a key for which there is no mapping (null, for example, if you do not use null as a key). Because entries in the map can disappear at any time, the behavior of some methods can be surprising—for example, successive calls to size can return smaller and smaller values; or an iterator for one of the set views can throw NoSuchElementException after hasNext returns true.
The WeakHashMap class exports the same constructors as HashMap: a no-arg constructor; a constructor that takes an initial capacity; a constructor that takes an initial capacity and a load factor; and a constructor that takes a Map whose contents will be the initial contents of the WeakHashMap.
Exercise 21.2: Rewrite the DataHandler class on page 457 to use a WeakHashMap to store the returned data instead of a single WeakReference.
Exercise 21.3: A WeakHashMap has weak keys and strong values. A WeakValueMap would have strong keys and weak values. Design a WeakValueMap. Be cautioned that this is not as simple as it might seem, in fact it is extremely complicated and requires a number of design choices to be made. For example, should iteration of values be allowed to yield null after hasNext has returned true, or should iteration keep the values alive while they are being iterated? Hint: Don't try to extend AbstractMap, delegate to a HashMap instead.
The TreeMap class implements SortedMap, keeping its keys sorted in the same way as TreeSet. This makes adding, removing, or finding a key/value pair 0(logn) . So you generally use a TreeMap only if you need the sorting or if the hashCode method of your keys is poorly written, thereby destroying the 0(1) behavior of HashMap.
TreeMap has the following constructors:
publicTreeMap()Creates a new
TreeMapthat is sorted according to the natural order of the keys. All elements added to this map must implement theComparableinterface and be mutually comparable.
publicTreeMap(Map<? extends K, ? extends V> map)Equivalent to using
TreeMap()and then adding all the key/value pairs ofmapto this map.
publicTreeMap(Comparator<? super K> comp)Creates a new
TreeMapthat is sorted according to the order imposed bycomp.
publicTreeMap(SortedMap<K, ? extends V> map)Creates a new
TreeMapwhose initial contents will be the same as those inmapand that is sorted the same way asmap.
Two collections, EnumSet and EnumMap, are specifically designed for working efficiently with enum constants.
The abstract class EnumSet<Eextends Enum<E>> represents a set of elements that are all enum constants from a specific enum type. Suppose you were writing a reflection related API, you could define an enum of the different field modifiers, and then have your Field class return the set of modifiers applicable to that field:
enum FieldModifiers { STATIC, FINAL, VOLATILE, TRANSIENT }
public class Field {
public EnumSet<FieldModifiers> getModifiers() {
// ...
}
// ... rest of Field methods ...
}
In general, whenever an enum represents a set of flags or “status bits,” then you will probably want to group the set of flags applicable to a given element in an enum set.
EnumSet objects are not created directly but are obtained from a number of static factory methods in EnumSet.
public static <E extends Enum<E>> EnumSet<E>allOf(Class<E> enumType)Creates an
EnumSetcontaining all the elements of the given enum type.
public static <E extends Enum<E>> EnumSet<E>noneOf(Class<E> enumType)Creates an empty
EnumSetthat can contain elements of the given enum type.
public static <E extends Enum<E>> EnumSet<E>copyOf(EnumSet<E> set)Creates an
EnumSetof the same enum type assetand containing all the elements ofset.
public static <E extends Enum<E>> EnumSet<E>complementOf(EnumSet<E> set)Creates an
EnumSetof the same enum type assetand containing all the enum constants that are not contained inset.
public static <E extends Enum<E>> EnumSet<E>copyOf(Collection<E> coll)Creates an
EnumSetfrom the given collection. If the collection is anEnumSet, a copy is returned. Any other collection must contain one or more elements, all of which are constants from the same enum; this enum will be the enum type of the returnedEnumSet. Ifcollis empty and is not anEnumSetthenIllegalArgumentExceptionis thrown because there is no specified enum type for this set.
The of method creates an enum set containing the given enum constant. It has five overloaded forms that take one through five elements as arguments. For example, here is the form that takes three elements:
public static <E extends Enum<E>> EnumSet<E>of(E e1, E e2, E e3)Creates an
EnumSetcontaininge1,e2, ande3.
A sixth overload takes an arbitrary number of elements:
public static <E extends Enum<E>> EnumSet<E>of(E first, E... rest)Creates an
EnumSetcontaining all the specified enum values.
Finally, the range method takes two enum constants that define the first and last elements that the enum set will contain. If first and last are in the wrong order then IllegalArgumentException is thrown.
Once you have obtained an enum set you can freely modify it in whatever way you need.
EnumSet uses a bit-vector internally so it is both compact and efficient. The iterator returned by iterator is not the usual fail-fast iterator of other collections. It is a weakly consistent iterator that returns the enum values in their natural order—the order in which the enum constants were declared. A weakly consistent iterator never throws ConcurrentModificationException, but it also may not reflect any changes that occur while the iteration is in progress.
The EnumMap<Kextends Enum<K>,V> is a special map that uses enum values as keys. All values in the map must come from the same enum type. Just like EnumSet the enum values are ordered by their natural order, and the iterator is weakly consistent.
Suppose you were writing an application that dynamically builds and displays an on-line form, based on a description written in a structured format such as XML. Given the set of expected form elements as an enum
enum FormElements { NAME, STREET, CITY, ZIP }
you could create an enum map to represent a filled in form, where the keys are the form elements and the values are whatever the user entered.
EnumMap has three constructors:
publicEnumMap(Class<K> keyType)Creates an empty
EnumMapthat can hold keys of the given enum type.
publicEnumMap(EnumMap<K, ? extends V> map)Creates an
EnumMapof the same enum type asmapand containing all the elements ofmap.
publicEnumMap(Map<K, ? extends V> map)Creates an
EnumMapfrom the given map. If the map is anEnumMap, a copy is returned. Any other map must contain one or more keys, all of which are constants from the same enum; this enum will be the enum type of the returnedEnumMap. Ifmapis empty and is not anEnumMapthenIllegalArgumentExceptionis thrown because there is no specified enum type for this map.
EnumMap is implemented using arrays internally, so it is compact and efficient.
The Collections class defines a range of static utility methods that operate on collections. The utility methods can be broadly classified into two groups: those that provide wrapped collections and those that don't. The wrapped collections allow you to present a different view of an underlying collection. There are three different views: a read-only view, a type-safe view, and a synchronized view. The first two are discussed in this section, synchronized wrappers are discussed later with the concurrent collections. First we discuss the general utility methods.
The Collections class defines many useful utility methods. You can find the minimum and maximum valued elements in a collection:
public static <T extends Object & Comparable<? super T>> Tmin(Collection<? extends T> coll)Returns the smallest valued element of the collection based on the elements' natural order.
public static <T> Tmin(Collection<? extends T> coll, Comparator<? super T> comp)Returns the smallest valued element of the collection according to
comp.
public static <T extends Object & Comparable<? super T>> Tmax(Collection<? extends T> coll)Returns the largest valued element of the collection based on the elements' natural order.
public static <T> Tmax(Collection<? extends T> coll, Comparator<? super T> comp)Returns the largest valued element of the collection according to the comparator
comp.
The declarations of the type variables for two of these methods seem rather complex. Basically, they just declare that T is a Comparable type. The inclusion of “extendsObject ” might seem redundant, but it changes the erasure of T to be Object rather than Comparable.
You can obtain a Comparator that will reverse the natural ordering of the objects it compares, or that of a given comparator:
public static <T> Comparator<T>reverseOrder()Returns a
Comparatorthat reverses the natural ordering of the objects it compares.
public static <T> Comparator<T>reverseOrder(Comparator<T> comp)Returns a
Comparatorthe reverses the order of the given comparator.
Then there are some general convenience methods for collections:
public static <T> booleanaddAll(Collection<? super T> coll, T... elems)Adds all of the specified elements to the given collection, returning
trueif the collection was changed. Naturally, if the collection does not support theaddmethod thenUnsupportedOperationExceptionis thrown.
public static booleandisjoint(Collection<?> coll1, Collection<?> coll2)Returns
trueif the two given collections have no elements in common.
There are numerous methods for working with lists:
public static <T> booleanreplaceAll(List<T> list, T oldVal, T newVal)Replaces all occurrences of
oldValin the list withnewVal. Returnstrueif any replacements were made.
public static voidreverse(List<?> list)Reverses the order of the elements of the list.
public static voidrotate(List<?> list, int distance)Rotates all of the elements in the list by the specified distance. A positive distance moves elements toward the end of the list, wrapping around to the beginning. A negative distance moves elements toward the head of the list, wrapping around to the end. For example, given a list v, w, x, y, z, a rotate with distance 1 will change the list to be z, v, w, x, y (as will a rotation of 6, 11, … or –4, –9, …).
public static voidshuffle(List<?> list)Randomly shuffles the list.
public static voidshuffle(List<?> list, Random randomSource)public static voidswap(List<?> list, int i, int j)Swaps the
ith andjth elements of the given list. This can be done efficiently inside the collection.
public static <T> voidfill(List<? super T> list, T elem)Replaces each element of
listwithelem.
public static <T> voidcopy(List<? super T> dest, List<? extends T> src)Copies each element to
dstfromsrc. Ifdstis too small to contain all the elements, throwsIndexOutOfBoundsException. You can use a sublist for eitherdstorsrcto copy only to or from parts of a list.
public static <T> List<T>nCopies(int n, T elem)Returns an immutable list that contains
nelements, each of which iselem. This only requires storing one reference toelem, soncan be 100 and the returned list will take the same amount of space it would ifnwere one.
public static intindexOfSubList(List<?> source, List<?> target)Returns the index of the start of the first sublist of
sourcethat is equal totarget.
public static intlastIndexOfSubList(List<?> source, List<?> target)Returns the index of the start of the last sublist of
sourcethat is equal totarget.
There are also methods for sorting and searching lists:
public static <T extends Comparable<? super T>> voidsort(List<T> list)Sorts
listin ascending order, according to its elements' natural ordering.
public static <T> voidsort(List<T> list, Comparator<? super T> comp)Sorts
listaccording tocomp.
public static <T> intbinarySearch(List<? extends Comparable<? super T>> list,T key)Uses a binary search algorithm to find a
keyobject in thelist, returning its index. The list must be in its elements' natural order. If the object is not found, the index returned is a negative value encoding a safe insertion point.
public static <T> intbinarySearch(List<? extends T> list, T key, Comparator<? super T> comp)Uses a binary search algorithm to find a
keyobject in thelist, returning its index. The list must be in the order defined bycomp. If the object is not found, the index returned is a negative value encoding a safe insertion point.
The phrase “a negative value encoding a safe insertion point” requires some explanation. If you use a binarySearch method to search for a key that is not found, you will always get a negative value. Specifically, if i is the index at which the key could be inserted and maintain the order, the value returned will be –(i+1). (The return value algorithm ensures that the value will be negative when the key is not found, since zero is a valid index in a list.) So using the binarySearch methods you can maintain a list in sorted order: Search the list to see if the key is already present. If not, insert it according to the return value of binarySearch:
public static <T extends Comparable<? super T>>
void ensureKnown(List<T> known, T value)
{
int indexAt = Collections.binarySearch(known, value);
if (indexAt < 0) // not in the list -- insert it
known.add(-(indexAt + 1), value);
}
If the list of known elements does not include the given value, this method will insert the value in its place in the list based on its natural ordering.
If you invoke one of the sorting or searching methods that relies on ordering on a list that contains objects that are not mutually comparable, or are not comparable by the relevant Comparator, you will get a ClassCastException.
You can ask how many times an element appears in a collection:
public static intfrequency(Collection<?> coll, Object elem)Returns the number of times that the given element appears in the given collection.
There are also methods to create singleton collections—collections containing only a single element:
public static <T> Set<T>singleton(T elem)Returns an immutable set containing only
elem.
public static <T> List<T>singletonList(T elem)Returns an immutable list containing only
elem.
public static <K,V> Map<K,V>singletonMap(K key, V value)Returns an immutable map containing only one entry: a mapping from
keytovalue.
And finally, there are methods that return empty collections:
public static <T> List<T>emptyList()Returns an empty, immutable list of the desired type.
public static <T> Set<T>emptySet()Returns an empty, immutable set of the desired type.
public static <K,V> Map<K,V>emptyMap()Returns an empty, immutable map of the desired type.
There are also legacy static final fields, EMPTY_LIST, EMPTY_SET, and EMPTY_MAP, of the raw types List, Set, and Map, initialized to refer to empty immutable collection objects. The use of these fields is not type-safe and is discouraged, as is all use of raw types.
The Collections class has static methods that return unmodifiable wrappers for all of the collection types: unmodifiableCollection, unmodifiableSet, unmodifiableSortedSet, unmodifiableList, unmodifiableMap, and unmodifiableSortedMap. The collections returned by these methods pass non-modifying methods through to the underlying collection. Modifying methods throw UnsupportedOperationException. The unmodifiable wrapper is backed by the original collection, so any changes you make to the collection will be visible through the wrapped collection. In other words, the contents of an unmodifiable wrapper can change, but not through the wrapper itself.
Unmodifiable wrappers are a reasonable way to expose information that may be changing but that shouldn't be changed by the observer. For example, consider the Attributed interface and the AttributedImpl class from Chapter 4. The attributes are exposed by having the attrs method return an Iterator—a reasonable design. An alternative, however, would be to return the attributes as an unmodifiable collection. Here's how AttributedImpl could implement this:
public Collection<Attr> attrs() {
return Collections.
unmodifiableCollection(attrTable.values());
}
Generally, iterators must be used immediately after they are obtained from the iterator method, with no intervening changes to the collection—otherwise, use of the iterator will encounter a ConcurrentModificationException. In contrast, you can ask for an unmodifiable collection, and then use it at some later time when the original collection has undergone arbitrary changes. Exposing information via a collection also allows the users of your class to utilize all the Collection utility methods. For example, if you expose your information as an unmodifiable list, it can be searched and sorted without your having to define search and sort methods.
A List<String> is guaranteed at compile time to only ever hold String objects—unless you have to pass it to legacy code as a raw type, in which case all guarantees are off (and you will get an “unchecked” warning). Dealing with legacy code that is unaware of generic types is a practical necessity. However, tracking down problems can be difficult. If you pass a List<String> to a legacy method that erroneously inserts a Number, you won't discover the problem until another part of your code tries to force the Number to be a String. The type-safe checked wrappers have been provided to help you with this problem. A checked wrapper will make a runtime check to enforce the type safety lost when the collection is used as a raw type. This allows errors to be detected as soon as they occur—when that erroneous Number is inserted.
public static <E> Collection<E>checkedCollection(Collection<E> coll, Class<E> type)Returns a dynamically typeset view of the given collection. Any attempt to insert an element that is not of the specified type will result in a
ClassCastException.
The other type checked wrappers are obtained from checkedList, checkedSet, checkedSortedSet, checkedMap, and checkedSortedMap.
All the collection implementations provided in java.util are unsynchronized (except the legacy collections you will soon see). You must ensure any necessary synchronization for concurrent access from multiple threads. You can do this explicitly with synchronized methods or statements, or algorithmically by designing your code to use a given collection from only one thread. These techniques are how collections are often naturally used—as local variables in methods or as private fields of classes with synchronized code.
Thread-safety for collection classes themselves takes two main forms: lock-based synchronization to ensure that concurrent access is precluded, and the use of sophisticated data structures that allow (to varying degrees) truly concurrent use of a collection. The former is provided through the synchronized wrappers, while the latter are provided in the java.util.concurrent subpackage.
A synchronized wrapper passes through all method calls to the wrapped collection after adding any necessary synchronization. You can get a synchronized wrapper for a collection from one of the following static methods of Collections: synchronizedCollection, synchronizedSet, synchronizedSortedSet, synchronizedList, synchronizedMap, or synchronizedSortedMap. These factory methods return wrappers whose methods are fully synchronized and so are safe to use from multiple threads. For example, the following code creates a new HashMap that can be safely modified concurrently:
Map<String, String> unsyncMap =
new HashMap<String, String>();
Map<String, String> syncMap =
Collections.synchronizedMap(unsyncMap);
The map referred to by unsyncMap is a full, but unsynchronized, implementation of the Map interface. The Map returned by synchronizedMap has all relevant methods synchronized, passing all calls through to the wrapped map (that is, to unsyncMap). Modifications made through either map are visible to the other—there is really only one map with two different views: the unwrapped, unsynchronized view referenced by unsyncMap, and the wrapping, synchronized view referenced by syncMap:
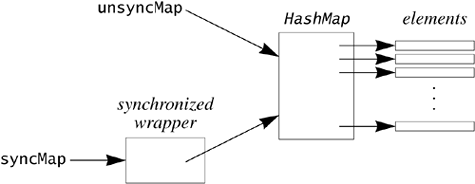
Because the underlying collection is unsynchronized, you must be very careful what you do with unsyncMap. The safest alternative is to drop the reference and do all work through syncMap. If you do not, you must be sure that you carefully control concurrency. The wrapper synchronizes on itself, so you could use syncMap to synchronize access on the collection and then use unsyncMap safely inside such code:
// add a lot of elements but grab the lock only once
synchronized (syncMap) {
for (int i = 0; i < keys.length; i++)
unsyncMap.put(keys[i], values[i]);
}
Iterators returned by synchronized wrappers are not synchronized but must be manually synchronized in a similar manner when needed:
synchronized (syncMap) {
System.out.println("--- map contents:");
for (String key : syncMap.keySet())
System.out.println(key + ": " + syncMap.get(key));
}
If you use an unsynchronized collection concurrently the result is undefined—if you are lucky the error will be detected by the collection and you will get a ConcurrentModificationException. If you are unlucky the collection will quietly become corrupt.
The java.util.concurrent subpackage provides collection implementations that are not only safe for concurrent use but are specially designed to support such use.
When using a collection concurrently, you can't be sure when a collection might be empty, or, for a capacity constrained collection, when it might be full. In such circumstances it is useful to be able to wait until an element appears or until space for an element appears. The BlockingQueue<E> interface that extends Queue<E> defines such a capability:
public voidput(E elem)throws InterruptedExceptionAdds the specified element to this queue, waiting if necessary for space to become available.
public booleanoffer(E elem, long time, TimeUnit unit)throws InterruptedExceptionAdds the specified element to this queue, waiting if necessary up to the specified waiting time for space to become available. Returns
trueif the element was added, andfalseif the specified waiting time elapsed before space became available.
public Etake()throws InterruptedExceptionReturns and removes the head of this queue, waiting if necessary for the queue to be non-empty.
public Epoll(long time, TimeUnit unit)throws InterruptedExceptionReturns and removes the head of this queue, waiting if necessary up to the specified waiting time for the queue to be non-empty. Returns the head of the queue, or
nullif the specified waiting time elapsed before an element became available.
As these are all potentially blocking operations. They support cancellation by throwing an InterruptedException in response to the current thread being interrupted.
You specify the waiting times with a long to indicate the time, and a value of the enum java.util.concurrent.TimeUnit to indicate the units. The enum TimeUnit has the constants NANOSECONDS, MICROSECONDS, MILLISECONDS, and SECONDS.
A BlockingQueue may be capacity constrained. The remainingCapacity method returns the number of elements that can be put in the queue without causing blocking—but note that if multiple threads are using the queue it doesn't guarantee how many elements an individual thread may be able to add without blocking. If there is no inherent limit Integer.MAX_VALUE is returned. If there is a capacity limit then Collection.add will throw IllegalStateException if the element cannot be added.
The drainTo method takes a collection and attempts to transfer all the elements of this queue into the given collection. The number of elements transferred is returned. An overloaded form of drainTo takes an additional int parameter that limits the maximum number of elements to transfer. This operation is provided as an alternative to repeated polling of the queue because some implementations will be able to implement it very efficiently—even atomically. However, the guarantees of this method are somewhat loose: It is possible that if an error occurs when an element is added to the target collection, the element may end up in one, neither, or both collections!
All BlockingQueue implementations must be thread-safe, but it is not required (unless explicitly documented by an implementation) that the bulk collection operations (addAll, containsAll, retainAll) are executed atomically.
The following blocking queue implementations are provided:
ArrayBlockingQueue—. A bounded blocking queue backed by an array. You construct one with a capacity and an optional fairness setting. If the queue is fair then blocked threads are processed in first-in-first-out order; otherwise, blocked threads can be unblocked in arbitrary order. The queue itself is ordered first-in-first-out. It provides a weakly consistent iterator.LinkedBlockingQueue—. An optionally bounded queue based on a linked node implementation. The queue elements are ordered first-in-first-out. It provides a weakly consistent iterator.A linked queue implementation will typically provide greater throughput than an array-based implementation when used concurrently. This is due to the use of algorithms that allow the head and tail to be locked independently. However, a linked queue implementation may require allocation for each insertion and produce garbage on each removal, which can add significant overhead. When the queue is used as a fixed size buffer that is constantly filled by one set of threads and then drained by another, this overhead is at its worst, and an array-based implementation may perform better than a bounded linked queue. Moreover, in the usage pattern described, the additional concurrency support of the linked queue isn't used because each thread within a set operates on the same end of the queue.
PriorityBlockingQueue—. An unbounded queue ordered the same way as aPriorityQueue. This implementation adds thread safety and the blocking retrieval operations. It provides an iterator that is thread-safe but fail-fast.SynchronousQueue—. A specialized blocking queue where eachtakemust wait for aput, and vice versa. A synchronous queue has no capacity, not even a capacity of one, so you cannot peek into a synchronous queue, nor can you iterate through it. From the perspective of most of the collection methods a synchronous queue acts like an empty collection.DelayQueue—. A specialized unbounded blocking queue ofDelayedelements. TheDelayedinterface has a single method,getDelay, which takes aTimeUnitconstant and returns the delay in that time unit. ADelayedelement cannot be removed from aDelayQueueuntil its delay has expired. The head of a delay queue is that element whose delay expired furthest in the past. If no elements have a delay that has passed then the head isnull. It provides an iterator that is thread-safe but fail-fast.
In addition to the thread-safe blocking queues, java.util.concurrent provides a number of other concurrent collections.
ConcurrentHashMap provides a hash map implementation that allows for fully concurrent retrievals and up to a set number of concurrent insertions. Although all operations are thread-safe, they do not involve locking, and there is no way to externally synchronize the map to provide atomic sequences of operations. Because of this, some extra support is needed to do things like inserting a value in the map only if it is not present. The ConcurrentMap<K,V> interface, implemented by ConcurrentHashMap, defines a number of such methods:
public VputIfAbsent(K key, V value)Atomically stores the given value in the map only if a mapping for
keydoes not currently exist. The old value mapped tokeyis returned, ornullif the key was not present—but be aware thatnullmay be a legitimate value for some maps. (Optional if the map does not supportput)
public booleanremove(Object key, Object value)Atomically remove the entry for
keyif it currently maps tovalue. Returnstrueif the entry was removed. (Optional if the map does not supportremove)
public booleanreplace(K key, V oldValue, V newValue)Atomically replaces the entry for
keyonly if it currently maps tooldValue. Returnstrueif the entry was replaced. (Optional if the map does not supportput)
public Vreplace(K key, V value)Atomically replaces the mapping for
keyif and only if a mapping currently exists. The old value mapped tokeyis returned, ornullif thekeywas not present—but be aware thatnullmay be a legitimate value for some maps. (Optional if the map does not supportput)
The ConcurrentLinkedQueue<E> class provides an unbounded thread-safe queue based on a linked node representation. Operations on the queue are highly concurrent and do not utilize locks. Because of the concurrent nature an operation like size requires a complete traversal of the queue and so is quite expensive—however, knowing the size that a concurrently changing queue used to be is seldom, if ever, useful. The iterator provided by ConcurrentLinkedQueue is weakly consistent, it guarantees to traverse the elements that existed when the iterator was created, but may not reflect subsequent additions.
The CopyOnWriteArrayList<E> is a thread-safe variant of ArrayList. It allows iteration to be done over a snapshot of the contents without actually making a copy of the original list. Copies are made only when someone modifies the list—hence the name “copy on write.” This makes a very efficient structure for lists that are read much more frequently than they are changed. Because the iterator sees a snapshot of the elements, it can never fail; but it does not support the remove operation.
The CopyOnWriteArraySet<E> class is an implementation of Set that uses a CopyOnWriteArrayList.
The class Arrays provides useful static methods for dealing with arrays. Most of these methods have a full complement of overloads: one for arrays of each primitive type (except boolean for searching and sorting) and one for Object arrays. There are also two variants of some methods: one acting on the whole array and one acting on the subarray specified by two supplied indices. The methods are
sort—. Sorts an array into ascending order. The exact algorithm is not specified other than it must be stable for objects (that is, equal objects don't get reordered because of the sort). A good implementation would use a technique that is not worse than O(nlogn)binarySearch—. Searches a sorted array for a given key. Returns the key's index, or a negative value encoding a safe insertion point (as for the methodCollections.binarySearchdescribed previously). There are no subarray versions of these methods.fill—. Fills in the array with a specified value.equalsanddeepEquals—. Returntrueif the two arrays they are passed are the same object, are bothnull, or have the same size and equivalent contents. There are no subarray versions. Theequalsmethod forObject[]usesObject.equalson each non-nullelement of the array;nullelements in the first array must be matched bynullelements of the second. This does not treat nested arrays specially, so it cannot generally be used to compare arrays of arrays. ThedeepEqualsmethod checks for equivalance of twoObject[]recursively taking into account the equivalence of nested arrays.hashCodeanddeepHashCode—. Return a hash code based on the contents of the given array. There are no subarray versions. ThedeepHashCodemethod computes a hash code for anObject[]recursively taking into account the contents of nested arrays.toStringanddeepToString—. Return a string representation of the contents of the array. There are no subarray versions. The string consists of a comma seperated list of the array's contents, enclosed by '[' and ']'. The array contents are converted to strings withString.valueof. ThetoStringmethod forObject[]converts any nested arrays to strings usingObject.toString. ThedeepToStringmethod returns a string representation of anObject[]recursively converting nested arrays to strings as defined by this method.
The methods sort and binarySearch have two overloads for Object arrays. One assumes that its elements are comparable (implement the Comparable interface). The second uses a provided Comparator object instead, so you can manipulate arrays of objects that are not comparable or for which you do not want to use the natural ordering.
You can view an array of objects as a List by using the object returned by the asList method.
public static <T> List<T> asList(T... elems)
This can take an actual array reference, or it can conveniently create an array from the given sequence of elements. The list is backed by the underlying array, so changes made to the array are visible to the list and vice versa. The returned list allows you to set elements, but not to add or remove them—it is a modifiable list, but not a resizable list. Using a List for access to an underlying array can give you useful features of List, such as using synchronized wrappers to synchronize access to the underlying array.
Iterators are generally useful, and you may want to write your own, even if you are not implementing a collection type. The following code demonstrates the basics of writing your own Iterator implementation, in this case for an iterator that will filter out strings longer than a given length:
public class ShortStrings implements Iterator<String> {
private Iterator<String> strings; // source for strings
private String nextShort; // null if next not known
private final int maxLen; // only return strings <=
public ShortStrings(Iterator<String> strings,
int maxLen) {
this.strings = strings;
this.maxLen = maxLen;
nextShort = null;
}
public boolean hasNext() {
if (nextShort != null) // found it already
return true;
while (strings.hasNext()) {
nextShort = strings.next();
if (nextShort.length() <= maxLen)
return true;
}
nextShort = null; // didn't find one
return false;
}
public String next() {
if (nextShort == null && !hasNext())
throw new NoSuchElementException();
String n = nextShort; // remember nextShort
nextShort = null; // consume nextShort
return n; // return nextShort
}
public void remove() {
throw new UnsupportedOperationException();
}
}
The class ShortStrings is a type of iterator that will read String objects from another iterator, returning only those that are no longer than a specified length. The constructor takes the iterator that will provide the strings and the maximum length, storing those in the object's fields. The field nextShort will hold the next short string, or null when there isn't one. If nextShort is null, the hasNext method searches for the next short string, remembering it in nextShort. If hasNext reaches the end of its source iteration without finding a short string it returns false.
The method next checks to see if there is a next short string, either returning it if there is one or throwing NoSuchElementException if there are none to return. Notice that hasNext does all the real work of finding the short strings, and next just returns the results, setting nextShort to null to indicate that the next short string, if any, is as yet undiscovered.
Finally, remove is not supported by this iterator implementation, so remove throws UnsupportedOperationException.
A few things to notice. First, hasNext is carefully written so that it will work if invoked multiple times before a next. This is required—the calling code may invoke hasNext as many times as it wants between invocations of next. Second, next is carefully written so that it works even if programmer using it has never invoked hasNext. Although generally a poor practice, you could never invoke hasNext and simply loop invoking next until an exception is generated.
Third, remove is not allowed because it cannot work correctly. Imagine, for example, if remove invoked remove on the underlying iterator. The following legal (although odd) code can cause incorrect behavior:
it.next(); it.hasNext(); it.remove();
Imagine that this were to happen when there was one more short string left in the iteration followed by some long ones. The invocation of next would return the last short string. Then hasNext would iterate through the list of strings, and finding no more short ones, return false. When remove was invoked, it would invoke remove on the underlying iterator, thereby removing the last (long) string that hasNext rejected. That would be incorrect. Since the above code is valid, you cannot fix the problem by forbidding the sequence of methods. You are effectively stuck. Because of this, you cannot build a filtering iterator on top of another Iterator object. You can build one on top of a ListIterator though, since it allows you to back up to the previously returned short string.
The methods of ListIterator have contracts similar to those of Iterator, as you have learned earlier in this chapter. You can provide ListIterator objects in some circumstances where you might otherwise write an Iterator. If you are writing a general utility class for others to use, you should implement ListIterator instead of Iterator if possible.
Exercise 21.4: Write a version of ShortStrings that implements ListIterator to filter a ListIterator object. Should your class extend ShortStrings?
You will usually find that at least one of the collection implementations will satisfy your needs. If not, you can implement relevant collection interfaces yourself to provide collections that satisfy your particular needs. You will find skeletal implementations in the abstract classes AbstractCollection, AbstractSet, AbstractList, AbstractSequentialList, AbstractQueue, and AbstractMap. You can extend these classes to create your own collections, often with less work than starting from the interfaces directly. The concrete collections shown in Figure 21-1 on page 568 each extend the appropriate abstract collection type, as shown in the concrete type tree in Figure 21-1.
These abstract collection classes are designed to be helpful superclasses for your own collection implementations. They are not required—in some cases you will find it easier or more efficient to directly implement the interfaces.
Each abstract collection class declares a few abstract methods and uses them in default implementations of other methods of the collection type. For example, AbstractList has two abstract methods: size and get. All other querying methods of AbstractList, including its iterators, are implemented by using these methods. You need only write your own implementation of the other methods if you want to, typically to either increase efficiency or to allow something disallowed by default. For example, if your list is modifiable, your subclass of AbstractList will have to provide an overriding implementation of the set method, which by default throws UnsupportedOperationException.
The root of the abstract collection types is AbstractCollection. If you need a collection that isn't a set, list, or map you can subclass this directly. Otherwise, you will probably find it more useful to subclass one of the more specific abstract collections classes.
If the Collection class you are creating is unmodifiable (if the modification methods of your collection should throw UnsupportedOperationException), your subclass of AbstractCollection need only provide an implementation of the size and iterator methods. This means you must at least write an implementation of Iterator for your collection. If your collection is modifiable, you must also override the default implementation of the add method (which throws UnsupportedOperationException) and your iterator must support remove.
AbstractSet extends AbstractCollection, and the methods you must implement and can override are the same, with the additional constraint that a subclass of AbstractSet must conform to the contract of the Set interface. It also overrides the implemention of equals and hashCode from Object.
AbstractQueue has the same requirements as AbstractCollection, with the additional requirements that you must implement offer, poll, and peek.
AbstractList requires you to implement only size and get(int) to define an unmodifiable list class. If you also override set(int,Object) you will get a modifiable list, but one whose size cannot change. Your list can change size if you also override the methods add(int,Object) and remove(int).
For example, suppose you need to view a bunch of arrays as a single list. You could use one of the existing List implementations, but at the cost of copying the information each time from the arrays into a new collection. You could instead subclass AbstractList to create an ArrayBunchList type that lets you do this without copying:
public class ArrayBunchList<E> extends AbstractList<E> {
private final E[][] arrays;
private final int size;
public ArrayBunchList(E[][] arrays) {
this.arrays = arrays.clone();
int s = 0;
for (E[] array : arrays)
s += array.length;
size = s;
}
public int size() {
return size;
}
public E get(int index) {
int off = 0; // offset from start of collection
for (int i = 0; i < arrays.length; i++) {
if (index < off + arrays[i].length)
return arrays[i][index - off];
off += arrays[i].length;
}
throw new ArrayIndexOutOfBoundsException(index);
}
public E set(int index, E value) {
int off = 0; // offset from start of collection
for (int i = 0; i < arrays.length; i++) {
if (index < off + arrays[i].length) {
E ret = arrays[i][index - off];
arrays[i][index - off] = value;
return ret;
}
off += arrays[i].length;
}
throw new ArrayIndexOutOfBoundsException(index);
}
}
When an ArrayBunchList is created, all the constituent arrays are remembered internally in the arrays field, and the total size of the collection in size. ArrayBunchList implements size, get, and set, but not add or remove. This means that the class provides a modifiable list, but one whose size cannot be changed. Any call that needs values from the underlying arrays will go through get. Any action that modifies the value of the ArrayBunchList will go through set, which modifies the appropriate underlying array.
AbstractList provides Iterator and ListIterator implementations on top of the other methods of the class. Because the iteration implementations use the methods of your underlying subclass of AbstractList, the modifying methods of the iteration will properly reflect the modifiability of your class.
The Iterator implementations of AbstractList use get to read values. As you will note, ArrayBunchList has a get that can do some significant work if the value is stored in one of the later arrays. We can make get smarter than shown here to help with this work, but we can be even more efficient for iteration because it accesses the data sequentially. Here is an optimized Iterator:
private class ABLIterator implements Iterator<E> {
private int off; // offset from start of list
private int array; // array we are currently in
private int pos; // position in current array
ABLIterator() {
off = 0;
array = 0;
pos = 0;
// skip any initial empty arrays (or to end)
for (array = 0; array < arrays.length; array++)
if (arrays[array].length > 0)
break;
}
public boolean hasNext() {
return off + pos < size();
}
public E next() {
if (!hasNext())
throw new NoSuchElementException();
E ret = arrays[array][pos++];
// advance to the next element (or to end)
while (pos >= arrays[array].length) {
off += arrays[array++].length;
pos = 0;
if (array >= arrays.length)
break;
}
return ret;
}
public void remove() {
throw new UnsupportedOperationException();
}
}
This implementation uses our knowledge of the underlying data structures to know exactly where the next element is coming from. This is more efficient than invoking get to implement the iterator's next. (It is also written to handle empty arrays and an empty ArrayBunchList.)
You can often substantially increase the performance of a resizable list by overriding the protected removeRange method, which takes two int parameters, min and max, and removes the elements starting at min, up to but not including max. The clear method uses remove Range to remove elements from lists and sublists. The default implementation is to invoke remove on each element one at a time. Many data structures can do bulk removes much more efficiently.
AbstractSequentialList extends AbstractList to make it easier to implement lists that are backed by a sequential access data store where moving from one element of the data to another requires examining each element of the data. In such a store, random access requires work since you must traverse each element to get to the next. A linked list is a sequential access data store. By contrast, an array can be randomly accessed directly. This is why ArrayList extends AbstractList, while LinkedList extends AbstractSequentialList.
Where AbstractList implements its iterators via the random access method get, AbstractSequentialList implements the random access methods via an iterator you provide by implementing the listIterator method. You must also implement size. Your class will be modifiable in whatever ways your list iterator's methods allow. For example, if your iterator allows set but not add or remove, you will have a modifiable but non-resizable list.
To use the AbstractMap class you must implement the entrySet method to return an unmodifiable set of entries that contains the mappings of the map. This will implement an unmodifiable map. To make a modifiable map, you must override put, and the iterator your entrySet object returns must allow remove.
The abstract implementations provided in these classes are designed to be easy to extend, but efficiency is not always a consequence. You can often make your subclass of an abstract collection type much faster by judicious overriding of other methods, as shown for the ArrayBunchList iterator. As another example, the implementation of get in AbstractMap, having only a set of entries, must search through that set one at a time until it finds an appropriate entry. This is an O(n)implementation. To get its O(1) performance, HashMap overrides get and all other key-based methods to use its own hash buckets. However, HashMap does not override the implementation of equals because that requires iteration anyway and the implementation in AbstractMap is reasonably efficient.
Exercise 21.5: Implement a more efficient ListIterator for ArrayBunchList. Be careful of the specific contracts of ListIterator methods, such as set not being valid until either next or previous is invoked.
The collection framework—the interfaces and classes described in this chapter, and shown in Figure 21-1 on page 568—has not always been a part of the package java.util, but that package has always contained some other collections. Most are superseded by the new collection types. Even so, they are not deprecated because they are in widespread use in existing code and will continue to be used until programs shift over to the new types. You are therefore likely to encounter these legacy collections so you should learn about them, including their relationship to the newer collection types. The legacy collections consist of the following types:
Enumeration—. Analogous toIterator.Vector—. Analogous toArrayList, maintains an ordered list of elements that are stored in an underlying array.Stack—. A subclass ofVectorthat adds methods to push and pop elements so that you can treat the vector by using the terms normal to a stack.Dictionary—. Analogous to theMapinterface, althoughDictionaryis an abstract class, not an interface.[4]Hashtable—. Analogous toHashMap.Properties—. A subclass ofHashtable. Maintains a map of key/value pairs where the keys and values are strings. If a key is not found in a properties object a “default” properties object can be searched.
Of these types, only Properties is in active use—it is used to contain system properties, as described in “System Properties” on page 663 and by some applications to store configuration data. We describe the other legacy collections by contrasting them with their analogous types. We then describe Properties in more detail since you are more likely to actually need to write code that uses it.
Enumeration<E> is analogous to Iterator, but has just two methods: hasMoreElements which behaves like hasNext, and nextElement which behaves like next. You can get an Enumeration that iterates through a non-legacy collection from the static method Collections.enumeration.
You can convert an Enumeration to a List via the static Collections.list method, which returns an ArrayList containing all the elements accessible by the enumeration, in the order the enumeration returned them.
Exercise 21.6: Rewrite the example program Concat on page 528 so that it uses an implementation of Enumeration that has only one FileInputStream object open at a time.
The Vector<E> class is analogous to ArrayList<E>. Although Vector is a legacy class, it has been made to implement List, so it works as a Collection. All methods that access the contents of a Vector are synchronized. As a legacy collection, Vector contains many methods and constructors that are analogous to those of ArrayList, in addition to those it inherits from List. The legacy constructors and methods of Vector and their analogues in ArrayList are
publicVector(int initialCapacity, int capacityIncrement)No analogue. Creates a new
Vectorwith the giveninitialCapacitythat will grow bycapacityIncrementelements at a time.
publicVector(int initialCapacity)Analogous to
ArrayList(initialCapacity).
publicVector()Analogous to
ArrayList().
publicVector(Collection<? extends E> coll)Analogous to
ArrayList(coll).
public final voidaddElement(E elem)Analogous to
add(elem).
public final voidinsertElementAt(E elem, int index)Analogous to
add(index,elem).
public final voidsetElementAt(E elem, int index)Analogous to
set(index,elem).
public final voidremoveElementAt(int index)Analogous to
remove(index).
public final booleanremoveElement(Object elem)Analogous to
remove(elem).
public final voidremoveAllElements()Analogous to
clear().
public final EelementAt(int index)Analogous to
get(index).
public final voidcopyInto(Object[] anArray)No direct analogue; the closest is
toArray(Object[]), althoughtoArrayallocates a new array if the array is too small, wherecopyIntowill throw anIndexOutOfBoundsException.
public final intindexOf(Object elem, int index)Searches for the first occurrence of
elem, beginning the search atindex, and testing for equality usingequals. The closest analogue would be to create a sublist covering the range and useindexOfon the sublist.
public final intlastIndexOf(Object elem, int index)Searches backward for the last occurrence of
elem, beginning the search atindex, and testing for equality usingequals. The closest analogue would be to create a sublist covering the range and uselastIndexOfon the sublist.
public final Enumeration<E>elements()Analogous to
iterator(). Equivalent toCollections.enumeration.
public final EfirstElement()Analogous to
get(0).
public final ElastElement()Analogous to
get(size()-1).
public final voidsetSize(int newSize)No analogue. If
newSizeis less than the current size, extra data is dropped. IfnewSizeis larger than the current size, any added elements arenull.
public final intcapacity()No analogue. Returns the current capacity of the vector.
In addition to these public methods, protected fields are available to classes that subclass the Vector class. Be careful what you do (if anything) with these fields because, for example, methods in Vector rely on elementCount being less than or equal to the length of the elementData array.
protected Object[]elementDataThe buffer where elements are stored.
protected intelementCountThe number of elements currently used in the buffer.
protected intcapacityIncrementThe number of elements to add to the capacity when
elementDataruns out of space. If zero, the size of the buffer is doubled every time it needs to grow.
The Stack<E> class extends Vector<E> to add methods for a simple last-in-first-out stack of objects. Use push to push an object onto the stack and use pop to remove the top element from the stack. The peek method returns the top item on the stack without removing it. The empty method returns true if the stack is empty. Trying to pop or peek in an empty Stack object will throw an EmptyStackException.
You can use search to find an object's distance from the top of the stack, with 1 being the top of the stack. If the object isn't found, –1 is returned. The search method uses Object.equals to test whether an object in the stack is the same as the one it is searching for.
These methods are trivial uses of the Vector methods, so using an ArrayList to implement a Stack would be simple: using add to implement push, and so on. There is no analogue to Stack in the collections.
Exercise 21.7: Implement a stack using ArrayList. Should your stack class be a subclass of ArrayList or use an ArrayList internally, providing different stack-specific methods?
The Dictionary<K,V> abstract class is essentially an interface. It is analogous to the Map interface but uses the terms key and element instead of key and value. With two exceptions, each method in Dictionary has the same name as its analogous method in Map: get, put, remove, size, and isEmpty. The two exceptions are keys and elements. In Map, you get a Set of keys or values that you can iterate over or otherwise manipulate. In Dictionary, you can only get an Enumeration (iterator) for the keys and elements, using the keys and elements methods, respectively. The legacy collections did not contain a Set type, and so Dictionary could not be expressed in those terms.
The Hashtable<K,V> class is similar to the HashMap class, but implements the methods of Dictionary as well as (more recently) implementing the Map interface. All methods of Hashtable are synchronized, unlike HashMap. Beyond the methods inherited from Dictionary and Map, Hashtable adds the following methods and constructors:
publicHashtable()Analogous to
HashMap().
publicHashtable(int initialCapacity)Analogous to
HashMap(initalCapacity).
publicHashtable(int initialCapacity, float loadFactor)Analogous to
HashMap(initialCapacity,loadFactor).
publicHashtable(Map<? extends K,? extends V> t)Analogous to
HashMap(map).
public booleancontains(Object elem)Analogous to
containsValue(elem).
A Properties object is used to store string keys and associated string elements. This kind of hashtable often has a default Properties object in which to look for properties that are not specified in the table itself. The Properties class extends Hashtable<Object,Object>. Standard Hashtable methods are used for almost all manipulation of a Properties object, but to get and set properties, you can use string-based methods. In addition to inherited methods, the following methods and constructors are provided:
publicProperties()Creates an empty property map.
publicProperties(Properties defaults)Creates an empty property map with the specified default
Propertiesobject. If a property lookup fails, the defaultPropertiesobject is queried. The defaultPropertiesobject can have its own defaultPropertiesobject, and so on. The chain of default objects can be arbitrarily deep.
public StringgetProperty(String key)Gets the property element for
key. If the key is not found in this object, the defaultPropertiesobject (if any) is searched. Returnsnullif the property is not found.
public StringgetProperty(String key, String defaultElement)Gets the property element for
key. If the key is not found in this object, the defaultPropertiesobject (if any) is searched. ReturnsdefaultElementif the property is not found.
public ObjectsetProperty(String key, String value)Adds the property
keyto the map with the givenvalue. This only affects thePropertiesobject on which it is invoked—the defaultPropertiesobject (if any) is unaffected. Returns the previous value that was mapped to this key, ornullif there was none.
public voidstore(OutputStream out, String header)throws IOExceptionSaves properties to an
OutputStream. This only works if thisPropertiesobject contains only string keys and values (as the specification says it must); otherwise you get aClassCastException. If notnull, theheaderstring is written to the output stream as a single-line comment. Do not use a multiline header string, or else the saved properties will not be loadable. Only properties in this object are saved to the file; the defaultPropertiesobject (if any) is not saved.
public voidload(InputStream in)throws IOExceptionLoads properties from an
InputStream. The property list is presumed to have been created previously bystore. This method puts values into thisPropertiesobject; it does not set values in the defaultPropertiesobject.
public Enumeration<?>propertyNames()Enumerates the keys, including those of any default
Propertiesobject. This method provides a snapshot, and hence can be expensive. The inheritedkeysmethod, by contrast, returns only those properties defined in this object itself.
public voidlist(PrintWriter out)Lists (prints) properties on the given
PrintWriter. Useful for debugging.
public voidlist(PrintStream out)Lists (prints) properties on the given
PrintStream. Also useful for debugging.
The default Properties object cannot be changed after the object is created. To change the default Properties object, you can subclass the Properties class and modify the protected field named defaults that contains the default Properties object.
Science is facts; just as houses are made of stones, so is science made of facts; but a pile of stones is not a house and a collection of facts is not necessarily science. | ||
| --Henri Poincaré | ||
[1] The full list of collections includes abstract collections that help you write your own implementations. These are presented in Section 21.14 on page 611. Other specialized implementations are also elided for clarity, but are discussed later in the chapter.
[2] It is possible to return Iterator<? super T>, which is slightly more general than Iterator<T>, but to do so would mean you wouldn't be able to assign the result to a variable of type Iterator<T>. That would be a very annoying restriction.
[3] The notation 0(f) is used in computer science to mean that the order of time for the execution of an algorithm increases in the manner of f. In this notation, n is traditionally the magnitude of the data under consideration. An algorithm that is 0(logn) takes longer as a function of the log of n—the number of elements—multiplied by some constant C. Generally speaking, the constant is irrelevant when algorithms are compared because as n gets large, the difference between an algorithm that is 0(logn) compared to one that is, say, 0(n2) is governed by n, not the constant—when n is 1000, for example, logn is 6.9, whereas n2 is 1,000,000. The multiplying constant for the 0(logn) algorithm would have to be extremely large to make it worse than the 0(n2) algorithm. Of course, when two 0(logn) algorithms are compared, the constant does matter, so in such a case it would be written. A similar argument means that for algorithms whose overhead has multiple terms, such as 0(C2+n), the smaller term is not relevant and so would be typically described as 0(n). An algorithm that is not sensitive to the size of n is written as 0(1) or sometimes 0(C). You will see “big O” notation in this chapter because it is an effective way of comparing different collection implementations.
[4] Dictionary is not an interface because it predates the addition of interfaces to the language, which gives you some idea of how old these legacy collections are.