
A slipping gear could let your M203 grenade launcher fire when you least expect it. That would make you quite unpopular in what's left of your unit. | ||
| --The U.S. Army's PS magazine, August 1993 | ||
During execution, applications can run into many kinds of errors of varying degrees of severity. When methods are invoked on an object, the object can discover internal state problems (inconsistent values of variables), detect errors with objects or data it manipulates (such as a file or network address), determine that it is violating its basic contract (such as reading data from an already closed stream), and so on.
Many programmers do not test for all possible error conditions, and for good reason: Code becomes unintelligible if each method invocation checks for all possible errors before the next statement is executed. This trade-off creates a tension between correctness (checking for all errors) and clarity (not cluttering the basic flow of code with many error checks).
Exceptions provide a clean way to check for errors without cluttering code. Exceptions also provide a mechanism to signal errors directly rather than indirectly with flags or side effects such as fields that must be checked. Exceptions make the error conditions that a method can signal an explicit part of the method's contract. The list of exceptions can be seen by the programmer, checked by the compiler, and preserved (if needed) by extended classes that override the method.
An exception is thrown when an unexpected error condition is encountered. The exception is then caught by an encompassing clause further up the method invocation stack. Uncaught exceptions result in the termination of the thread of execution, but before it terminates, the thread's UncaughtExceptionHandler is given the opportunity to handle the exception as best it can, usually printing useful information (such as a call stack) about where the exception was thrown—see “Threads and Exceptions” on page 379.
Exceptions are objects. All exception types—that is, any class designed for throwable objects—must extend the class Throwable or one of its subclasses. The Throwable class contains a string that can be used to describe the exception—it is set via a constructor parameter and may be retrieved with the getMessage method. By convention, most new exception types extend Exception, a subclass of Throwable. Exception types are not allowed to be generic types.
Exceptions are primarily checked exceptions, meaning that the compiler checks that your methods throw only the exceptions they have declared themselves to throw. The standard runtime exceptions and errors extend one of the classes RuntimeException and Error, making them unchecked exceptions. Here is the top of the exception type hierarchy:
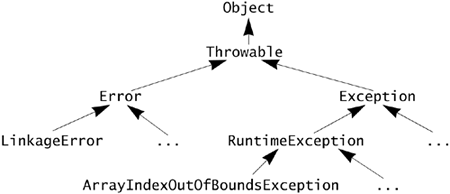
Checked exceptions represent conditions that, although exceptional, can reasonably be expected to occur, and if they do occur must be dealt with in some way. Making these exceptions checked documents the existence of the exception and ensures that the caller of a method deals with the exception in some way—or at least consciously chooses to ignore it.
Unchecked runtime exceptions represent conditions that, generally speaking, reflect errors in your program's logic and cannot be reasonably recovered from at run time. For example, the ArrayIndexOutOfBoundsException thrown when you access outside the bounds of an array tells you that your program calculated an index incorrectly, or failed to verify a value to be used as an index. These are errors that should be corrected in the program code. Given that you can make errors writing any statement it would be totally impractical to have to declare or catch all the exceptions that could arise from those errors—hence they are unchecked.
The Error class, through its subclasses, defines a range of errors that indicate something has failed in the virtual machine itself (VirtualMachineError), or in the virtual machine's attempt to execute your application (LinkageError). These are also unchecked because they are beyond the applications ability to control, or handle. Application code should rarely, if ever, throw these error exceptions directly.
Nearly all exceptions you create should extend Exception, making them checked exceptions. These new checked exceptions represent the exceptional conditions that can arise in your library or application. You can usually handle any runtime problems that arise in your code by throwing one of the existing runtime exception classes—there are sufficient of these that one of them is usually a good match to the kind of error that has occurred, or else the error is sufficiently general that throwing an instance of RuntimeException itself is sufficient. Occasionally, you may want to extend an existing runtime exception class to provide additional information about the error that occurred. Even more rarely, you might define a new class of runtime exception that is specific to your application domain. Just remember that when it comes to unchecked exceptions, proper usage relies on good documentation because the compiler will not be able to assist you.
Sometimes it is useful to have more data to describe the exceptional condition than what is in the Exception class. In such cases, you can extend Exception to create a class that contains the added data (usually set in the constructor).
For example, suppose a replaceValue method is added to the Attributed interface discussed in Chapter 4. This method replaces the current value of a named attribute with a new value. If the named attribute doesn't exist, an exception should be thrown, because it is reasonable to assume that one should replace only existing attributes. That exception should contain the name of the attribute. To represent the exception, we create the NoSuchAttributeException class:
public class NoSuchAttributeException extends Exception {
public final String attrName;
public NoSuchAttributeException(String name) {
super("No attribute named "" + name + "" found");
attrName = name;
}
}
NoSuchAttributeException extends Exception to add a constructor that takes the name of the attribute; it also adds a public final field to store the data. The constructor invokes the superclass's constructor with a string description of what happened. This custom exception type helps when writing code that catches the exception because it holds both a human-usable description of the error and the data that created the error. Adding useful data is one reason to create a new exception type.
Another reason to create a new exception type is that the type of the exception is an important part of the exception data, because exceptions are caught according to their type. For this reason, you would invent NoSuchAttributeException even if you did not want to add data. In this way, a programmer who cared only about such an exception could catch it exclusive of other exceptions that might be generated either by the methods of the Attributed interface, or by other methods used on other objects in the same area of code.
In general, new exception types should be created when programmers will want to handle one kind of error differently from another kind. Programmers can then use the exception type to execute the correct code rather than examine the contents of the exception to determine whether they really care about the exception or they have caught an irrelevant exception by accident.
You throw exceptions using the throw statement:
throw expression;
where expression must evaluate to a value or variable that is assignable to Throwable—or in simple terms, a reference to a Throwable object. For example, here is an addition to AttributedImpl from Chapter 4 that implements replaceValue:
public void replaceValue(String name, Object newValue)
throws NoSuchAttributeException
{
Attr attr = find(name); // look up the attr
if (attr == null) // it isn't found
throw new NoSuchAttributeException(name);
attr.setValue(newValue);
}
The replaceValue method first looks up the current Attr object for the name. If there isn't one, it throws a new object of type NoSuchAttributeException, providing the constructor with the attribute name. Exceptions are objects, so they must be created before being thrown. If the attribute does exist, its value is replaced with the new value. You can also generate an exception by invoking a method that itself throws an exception.
When an exception is thrown, the statement or expression that caused the exception is said to complete abruptly. This abrupt completion of statements causes the call chain to gradually unwind as each block or method invocation completes abruptly until the exception is caught. If the exception is not caught, the thread of execution terminates, after giving the thread's UncaughtExceptionHandler a chance to handle the exception—see “Threads and Exceptions” on page 379.
Once an exception occurs, actions after the point at which the exception occurred do not take place. If evaluation of a left-operand causes an exception then no part of the right-operand is evaluated; if evaluation of a left argument expression results in an exception, then no argument to the right is evaluated. The next action to occur will be in either a finally block, or a catch block that catches the exception.
A throw statement results in a synchronous exception, as does, say, a divide-by-zero arithmetic exception—the exception occurs directly as a result of executing a particular instruction; either the throw or dividing by zero. In contrast an asynchronous exception is one that can occur at any time, regardless of the instructions being executed.
Asynchronous exceptions can occur in only two specific ways. The first is an internal error in the Java virtual machine—such exceptions are considered asynchronous because they are caused by the execution of instructions in the virtual machine, not the instructions of the program. Needless to say, there is little that you can do about an internal error.
The second mechanism is the use of the deprecated Thread.stop methods, or the related, and not deprecated, stopThread methods of the JVM™ Tool Interface (JVMTI)—a native code interface to the virtual machine that allows for the inspection, and control of, a running application. These methods allow an asynchronous exception of any kind (checked or unchecked) to be thrown at any point during the execution of the target thread. Such a mechanism is inherently dangerous, which is why it has been deprecated in the Thread class—we discuss this further in Chapter 14.
The definition of the replaceValue method declares which checked exceptions it throws. The language requires such a declaration because programmers invoking a method need to know the exceptions it can throw just as much as they need to know its normal behavior. The checked exceptions that a method throws are as important as the type of value it returns. Both must be declared.
The checked exceptions a method can throw are declared with a throws clause, which declares a comma-separated list of exception types. Only those exceptions that are not caught within the method must be listed.
You can throw checked exceptions that are extensions of any type of exception in the throws clause because you can use a class polymorphically anywhere its superclass is expected. A method can throw many classes of checked exceptions—all of them extensions of a particular exception class—and declare only the superclass in the throws clause. By doing so, however, you hide potentially useful information from programmers invoking the method: They won't know which of the possible extended exception types could be thrown. For documentation purposes, the throws clause should be as complete and specific as possible.
The contract defined by the throws clause is strictly enforced—you can throw only a type of checked exception that has been declared in the throws clause. Throwing any other type of checked exception is invalid, whether you use throw directly or use it indirectly by invoking another method. If a method has no throws clause, that does not mean that any exceptions can be thrown: It means that no checked exceptions can be thrown.
All the standard runtime exceptions (such as ClassCastException and ArithmeticException) are extensions of the RuntimeException class. The more serious errors are signaled by exceptions that are extensions of Error, and these exceptions can occur at any time in any code. RuntimeException and Error are the only exceptions you do not need to list in your throws clauses. They are ubiquitous, and every method can potentially throw them. This is why they are unchecked by the compiler. Those runtime exceptions—such as IllegalArgumentException—thrown under specific conditions should always be documented, even though they do not appear in the throws clause; see Chapter 19 for details on how to document exceptions thrown by your methods.
Because checked exceptions must be declared in a throws clause, it follows that any code fragment outside a method, or constructor, with a throws clause cannot throw a checked exception. This means that static initializers and static initialization blocks cannot throw checked exceptions, either directly or by invoking a method that throws such an exception. Non-static initializers and non-static initialization blocks are considered to be part of the constructor for a class, and so they are allowed to throw checked exceptions only if all the constructors of the class declare those checked exceptions.
Checked exception handling is strictly enforced because doing so helps avoid bugs that come from not dealing with errors. Experience has shown that programmers forget to handle errors or defer writing code to handle them until some future time that never arrives. The throws clause states clearly which exceptions are being thrown by methods and makes sure they are dealt with in some way by the invoker.
If you invoke a method that lists a checked exception in its throws clause, you have three choices:
Catch the exception and handle it.
Catch the exception and map it into one of your exceptions by throwing an exception of a type declared in your own
throwsclause.Declare the exception in your
throwsclause and let the exception pass through your method (although you might have afinallyclause that cleans up first; see “finally” on page 288 for details).
The first two choices require that you catch exceptions thrown by other methods—something you will learn about soon.
You should be explicit in your throws clause, listing all the exceptions you know that you throw, even when you could encompass several exceptions under some superclass they all share. This is good self-documentation. Deciding how explicit you should be requires some thought. If you are designing a general interface or superclass you have to think about how restrictive you want to be to the implementing classes. It may be quite reasonable to define a general exception you use in the interface's throws clause, and to expect that the implementing classes will be more specific where possible. This tactic is used by the java.io package, which defines a general IOException type for its methods to throw. This lets implementing classes throw exceptions specific to whatever kind of I/O is being done. For example, the classes that do I/O across network channels can throw various network-related subclasses of IOException, and those dealing with files throw file-related subclasses.
When you override an inherited method, or implement an inherited abstract method, the throws clause of the overriding method must be compatible with the throws clause of the inherited method (whether abstract or not).
The simple rule is that an overriding or implementing method is not allowed to declare more checked exceptions in the throws clause than the inherited method does. The reason for this rule is quite simple: Code written to deal with the original method declaration won't be prepared to catch any additional checked exceptions and so no such exceptions are allowed to be thrown. Subtypes of the declared exceptions can be thrown because they will be caught in a catch block for their supertype. If the overriding or implementing method does not throw a checked exception then it need not redeclare that exception. For example, as you saw in “Strategies for Cloning” on page 101, a class that implements Cloneable need not declare that clone may throw a CloneNotSupportedException. Whether to declare it or not is a matter of design—if you declare it in the overriding method then subclasses of your class will be allowed to throw the exception in that method, otherwise they will not.
If a method declaration is multiply inherited—that is, it exists in more than one inherited interface, or in both an inherited interface and a superclass—then the throws clause of that method must satisfy all the inherited throws clauses. As we discussed in “Inheriting, Overriding, and Overloading Methods” on page 125, the real issue in such multiple inheritance situations, is whether a single implementation of a method can honor all the inherited contracts.
A native method declaration (see page 74) can provide a throws clause that forces all users of that method to catch or redeclare the specified checked exceptions. However, the implementation of native methods is beyond the control of the Java compiler and so they cannot be checked to ensure that only the declared exceptions are thrown. Well-written native methods, however, will throw only those checked exceptions that they declare.
Exercise 12.1: Create an ObjectNotFoundException class for the LinkedList class you built in previous exercises. Add a find method that looks for an object in the list and either returns the LinkedList object that contains the desired object or throws the exception if the object isn't found in the list. Why is this preferable to returning null if the object isn't found? What additional data if any should ObjectNotFoundException contain?
You catch exceptions by enclosing code in try blocks. The basic syntax for a try block is:
try {
statements
} catch (exception_type1 identifier1) {
statements
} catch (exception_type2 identifier2) {
statements
...
} finally {
statements
}
where either at least one catch clause, or the finally clause, must be present. The body of the try statement is executed until either an exception is thrown or the body finishes successfully. If an exception is thrown, each catch clause is examined in turn, from first to last, to see whether the type of the exception object is assignable to the type declared in the catch. When an assignable catch clause is found, its block is executed with its identifier set to reference the exception object. No other catch clause will be executed. Any number of catch clauses, including zero, can be associated with a particular try as long as each clause catches a different type of exception. If no appropriate catch is found, the exception percolates out of the try statement into any outer try that might have a catch clause to handle it.
If a finally clause is present with a try, its code is executed after all other processing in the try is complete. This happens no matter how completion was achieved, whether normally, through an exception, or through a control flow statement such as return or break.
This example code is prepared to handle one of the exceptions replaceValue throws:
Object value = new Integer(8);
try {
attributedObj.replaceValue("Age", value);
} catch (NoSuchAttributeException e) {
// shouldn't happen, but recover if it does
Attr attr = new Attr(e.attrName, value);
attributedObj.add(attr);
}
The try sets up a statement (which must be a block) that does something that is normally expected to succeed. If everything succeeds, the block is finished. If any exception is thrown during execution of the code in the try block, either directly via a throw or indirectly by a method invoked inside it, execution of the code inside the try stops, and the attached catch clause is examined to see whether it wants to catch the exception that was thrown.
A catch clause is somewhat like an embedded method that has one parameter — namely, the exception to be caught. As with method parameters, the exception “parameter” can be declared final, or can have annotations applied. Inside a catch clause, you can attempt to recover from the exception, or you can clean up and rethrow the exception so that any code calling yours also has a chance to catch it. Or a catch can do what it needs to and then fall out the bottom, in which case control flows to the statement after the try statement (after executing the finally clause, if there is one).
A general catch clause—one that catches exceptions of type Exception, for example—is usually a poor implementation choice since it will catch any exception, not just the specific one you are interested in. Had we used such a clause in our code, it could have ended up handling, for example, a ClassCastException as if it were a missing attribute problem.
You cannot put a superclass catch clause before a catch of one of its subclasses. The catch clauses are examined in order, so a catch that picked up one exception type before a catch for an extended type of exception would be a mistake. The first clause would always catch the exception, and the second clause would never be reached. The compiler will not accept the following code:
class SuperException extends Exception { }
class SubException extends SuperException { }
class BadCatch {
public void goodTry() {
/* This is an INVALID catch ordering */
try {
throw new SubException();
} catch (SuperException superRef) {
// Catches both SuperException and SubException
} catch (SubException subRef) {
// This would never be reached
}
}
}
Only one exception is handled by any single encounter with a try clause. If a catch or finally clause throws another exception, the catch clauses of the try are not reexamined. The catch and finally clauses are outside the protection of the try clause itself. Such exceptions can, of course, be handled by any encompassing try block in which the inner catch or finally clauses were nested.
The finally clause of a try statement provides a mechanism for executing a section of code whether or not an exception is thrown. Usually, the finally clause is used to clean up internal state or to release non-object resources, such as open files stored in local variables. Here is a method that closes a file when its work is done, even if an error occurs:
public boolean searchFor(String file, String word)
throws StreamException
{
Stream input = null;
try {
input = new Stream(file);
while (!input.eof())
if (input.next().equals(word))
return true;
return false; // not found
} finally {
if (input != null)
input.close();
}
}
If the new fails, input will never be changed from its initial null value. If the new succeeds, input will reference the object that represents the open file. When the finally clause is executed, the input stream is closed only if it has been open. Whether or not the operations on the stream generate an exception, the contents of the finally clause ensure that the file is closed, thereby conserving the limited resource of simultaneous open files. The searchFor method declares that it throws StreamException so that any exceptions generated are passed through to the invoking code after cleanup, including any StreamException thrown by the invocation of close.
There are two main coding idioms for correctly using finally. The general situation is that we have two actions, call them pre and post, such that if pre occurs then post must occur—regardless of what other actions occur between pre and post and regardless of whether those actions complete successfully or throw exceptions. One idiom for ensuring this is:
pre();
try {
// other actions
} finally {
post();
}
If pre succeeds then we enter the try block and no matter what occurs we are guaranteed that post gets executed. Conversely, if pre itself fails for some reason and throws an exception, then post does not get executed—it is important that pre occur outside the try block in this situation because post must not execute if pre fails.
You saw the second form of the idiom in the stream searching example. In that case pre returns a value that can be used to determine whether or not it completed successfully. Only if pre completed successfully is post invoked in the finally clause:
Object val = null;
try {
val = pre();
// other actions
} finally {
if (val != null)
post();
}
In this case, we could still invoke pre outside the try block, and then we would not need the if statement in the finally clause. The advantage of placing pre inside the try block comes when we want to catch both the exceptions that may be thrown by pre and those that may be thrown by the other actions—with pre inside the try block we can have one set of catch blocks, but if pre were outside the try block we would need to use an outer try-catch block to catch the exceptions from pre. Having nested try blocks can be further complicated if both pre and the other actions can throw the same exceptions—quite common with I/O operations—and we wish to propagate the exception after using it in some way; an exception thrown by the other actions would get caught twice and we would have to code our catch blocks to watch for and deal with that situation.
A finally clause can also be used to clean up for break, continue, and return, which is one reason you will sometimes see a try clause with no catch clauses. When any control transfer statement is executed, all relevant finally clauses are executed. There is no way to leave a try block without executing its finally clause.
The preceding example relies on finally in this way to clean up even with a normal return. One of the most common reasons goto is used in other languages is to ensure that certain things are cleaned up when a block of code is complete, whether or not it was successful. In our example, the finally clause ensures that the file is closed when either the return statement is executed or the stream throws an exception.
A finally clause is always entered with a reason. That reason may be that the try code finished normally, that it executed a control flow statement such as return, or that an exception was thrown in code executed in the try block. The reason is remembered when the finally clause exits by falling out the bottom. However, if the finally block creates its own reason to leave by executing a control flow statement (such as break or return) or by throwing an exception, that reason supersedes the original one, and the original reason is forgotten. For example, consider the following code:
try {
// ... do something ...
return 1;
} finally {
return 2;
}
When the try block executes its return, the finally block is entered with the “reason” of returning the value 1. However, inside the finally block the value 2 is returned, so the initial intention is forgotten. In fact, if any of the other code in the try block had thrown an exception, the result would still be to return 2. If the finally block did not return a value but simply fell out the bottom, the “return the value 1” reason would be remembered and carried out.
Exceptions sometimes are caused by other exceptions. In “A Quick Tour”, Section 1.14 on page 32, you saw an example where this was true:
public double[] getDataSet(String setName)
throws BadDataSetException
{
String file = setName + ".dset";
FileInputStream in = null;
try {
in = new FileInputStream(file);
return readDataSet(in);
} catch (IOException e) {
throw new BadDataSetException();
} finally {
try {
if (in != null)
in.close();
} catch (IOException e) {
; // ignore: we either read the data OK
// or we're throwing BadDataSetException
}
}
}
// ... definition of readDataSet ...
This method throws a BadDataSetException on any I/O exception or data format error. The problem is that any information about the original exception is lost, and it might be a needed clue to fixing the problem.
Replacing exceptions with other ones is an important way to raise the level of abstraction. To any code invoking the above method, all failures can be recovered from in the same way. The particulars of the failure probably don't much matter to what the program will do, which is to handle the failure of the data file. But humans fixing the problem can require knowledge of the exact failure, so they will want to have that information available—see “Stack Traces” on page 294.
Situations like this are common enough that the exception mechanism includes the notion of one exception being caused by another exception. The initCause method, defined in Throwable, sets one exception's cause to be the exception object passed as a parameter. For example, the previous example can have its IOException catch clause rewritten as:
} catch (IOException e) {
BadDataSetException bdse = new BadDataSetException();
bdse.initCause(e);
throw bdse;
} finally {
// ...
}
Here initCause is used to remember the exception that made the data bad. This means that the invoking code can handle all bad data simply with one exception handler but still know the kind of exception that caused the underlying problem. The invoking code can use the getCause method to retrieve the exception.
The example can be simplified further by writing BadDataSetException to expect to have a cause, at least some of the time, and so provide a constructor to accept that cause if it is known. The idiomatic way to define a new exception class is to provide at least the following four constructor forms—or variants thereof that deal with exception specific data:
class BadDataSetException extends Exception {
public BadDataSetException() {}
public BadDataSetException(String details) {
super(details);
}
public BadDataSetException(Throwable cause) {
super(cause);
}
public BadDataSetException(String details,
Throwable cause) {
super(details, cause);
}
}
Now the catch clause in the example simply becomes:
} catch (IOException e) {
throw new BadDataSetException(e);
} finally {
// ...
}
Not all exception classes provide cause-taking constructors, but all support the initCause method. To make it easier to use initCause with such exception classes, it returns the exception instance that it is invoked on. The idea is that you can use it like this:
throw new BadDataSetException().initCause(e); // Error?
The only problem is that this will nearly always result in a compile-time error: initCause returns a Throwable instance, and you can only throw a Throwable if your method's throw clause lists Throwable—which it rarely, if ever, should! Consequently, you have to modify the above, to cast the Throwable back to the actual exception type you are creating:
throw (BadDataSetException)
new BadDataSetException().initCause(e);
Note that an exception can only have it's cause set once—either via a constructor, or by a single call to initCause—any attempt to set it again will cause an IllegalStateException to be thrown.
When an exception is created, a stack trace of the call is saved in the exception object. This is done by the Throwable constructor invoking its own fillInStacktrace method. You can print this stack trace by using printStackTrace, and you can replace it with the current stack information by invoking fillInStackTrace again. If an exception has a cause, then typically printStackTrace will print the current exceptions stack trace, followed by the stack trace of its cause—however, the details of stack trace printing depend on the virtual-machine implementation.
A stack trace is represented by an array of StackTraceElement objects that you can get from getStackTrace. You can use this array to examine the stack or to create your own display of the information. Each StackTraceElement object represents one method invocation on the call stack. You can query these with the methods getFileName, getClassName, getMethodName, getLineNumber, and isNativeMethod.
You can also set the stack trace with setStackTrace, but you would have to be writing a very unusual program for this to be a good idea. The real information contained in a stack trace is quite valuable. Do not discard it without compelling need. Proper reasons for changing a stack trace are vital, but very rare.
We used the phrase “unexpected error condition” at the beginning of this chapter when describing when to throw exceptions. Exceptions are not meant for simple, expected situations. For example, reaching the end of a stream of input is expected, so the method that returns the next input from the stream has “hitting the end” as part of its expected behavior. A return flag that signals the end of input is reasonable because it is easy for callers to check the return value, and such a convention is also easier to understand. Consider the following typical loop that uses a return flag:
while ((token = stream.next()) != Stream.END)
process(token);
stream.close();
Compare that to this loop, which relies on an exception to signal the end of input:
try {
for (;;) {
process(stream.next());
}
} catch (StreamEndException e) {
stream.close();
}
In the first case, the flow of control is direct and clear. The code loops until it reaches the end of the stream, and then it closes the stream. In the second case, the code seems to loop forever. Unless you know that end of input is signaled with a StreamEndException, you don't know the loop's natural range. Even when you know about StreamEndException, this construction can be confusing since it moves the loop termination from inside the for loop into the surrounding try block.
In some situations no reasonable flag value exists. For example, a class for a stream of double values can contain any valid double, and there is no possible end-of-stream marker. The most reasonable design is to add an explicit eof test method that should be called before any read from the stream:
while (!stream.eof())
process(stream.nextDouble());
stream.close();
On the other hand, continuing to read past the end of input is not expected. It means that the program didn't notice the end and is trying to do something it should never attempt. This is an excellent case for a ReadPastEndException. Such behavior is outside the expected use of your stream class, and throwing an exception is the right way to handle it.
Deciding which situations are expected and which are not is a fuzzy area. The point is not to abuse exceptions as a way to report expected situations.
Exercise 12.2: Decide which way the following conditions should be communicated to the programmer:
Someone tries to set the capacity of a
PassengerVehicleobject to a negative value.A syntax error is found in a configuration file that an object uses to set its initial state.
A method that searches for a programmer-specified word in a string array cannot find any occurrence of the word.
A file provided to an “open” method does not exist.
A file provided to an “open” method exists, but security prevents the user from using it.
During an attempt to open a network connection to a remote server process, the remote machine cannot be contacted.
In the middle of a conversation with a remote server process, the network connection stops operating.
An assertion is used to check an invariant, a condition that should always be true. If the assertion is found to be false then an exception is thrown. If your code assumes that something is true, adding an assertion to test it gives you a way to catch mistakes before they cause odd effects. For example, in a linked list the last element in the list usually has a null reference to the next element:
public void append(Object value) {
ListNode node = new ListNode(value);
if (tail != null)
tail.next = node;
tail = node;
assert tail.next == null;
}
When the append method has done its work, the assert double-checks that the last node is properly formed. If it is not, then an AssertionError is thrown.
By default, assertions are not evaluated. It is possible to turn assertion evaluation on and off for packages, classes, and entire class loaders, as you will soon see. When assertions are turned off, the assertions are not evaluated at all. This means that you must be careful about side effects that affect non-assertion code. For example, the following code is very dangerous:
assert ++i < max;
When assertions are being evaluated, the value of i will be incremented to the next value. But when someone turns off assertions the entire expression will logically vanish from the code leaving i perpetually unchanged. Don't ever do anything like this. Split it up:
i++; assert i < max;
The syntax for an assertion is:
assert eval-expr [: detail-expr];
where eval-expr is either a boolean or Boolean expression and detail-expr is an optional expression that will be passed to the AssertionError constructor to help describe the problem. The detail expression is optional; if present, it provides information to a person who looks at the statement or thrown exception. If the detail is a Throwable it will become the cause of the AssertionError; that is, it will be the value returned by the error's getCause method. Otherwise, the detail will be converted to a string and become the detail message for the error.
When an assert is encountered in the code, the first expression is evaluated. If the resulting value is true, the assertion passes. If it is false, the assertion fails, and an AssertionError will be constructed and thrown.
Assertions are typically used to make sure those things that “can't happen” are noticed if they do happen. This is why a failed assertion throws a kind of Error instead of an Exception. A failed assertion means that the current state is basically insane.
You should not use assertions to test for things that you know will actually happen sometimes (IOException) or for which other means are common (IllegalArgumentException, NullPointerException, …). You want to deal with these problems whether or not assertions are being evaluated. Assertions are for testing for things that should never happen—in a properly functioning program no assertion should ever fail. The next few sections show some good examples of when to use assertions.
Some assertions are used to test that the current state is always as it should be.
public void setEnds(Point p1, Point p2) {
this.p1 = p1;
this.p2 = p2;
distance = calculateDistance(p1, p2);
assert (distance >= 0) : "Negative distance";
}
In the above code, setting the endpoints causes the distance field to be recalculated. The distance calculation should always result in a positive value. Any bug that gives distance a negative value would produce odd effects when the value is used in the future. The assertion shown will catch such a bug right at the source. Simple assertions of this form can be used in many places to ensure the sanity of your state and algorithms.
The terms precondition and postcondition refer to particular kinds of state assertion. A precondition is something that must be true before a particular chunk of code (usually a method) is executed; a postcondition must be true after. You can use assert to check pre- and postconditions, such as:
public boolean remove(Object value) {
assert count >= 0;
if (value == null)
throw new NullPointerException("value");
int orig = count;
boolean foundIt = false;
try {
// remove element from list (if it's there)
return foundIt;
} finally {
assert ((!foundIt && count == orig) ||
count == orig - 1);
}
}
Here the method enforces the precondition that the list size must be non-negative before the operation, and the postcondition that the list size should be reduced by one after removal of an element, unless the element was not in the list.
Note that the check for whether the element to remove is null is not an assert, but instead throws a NullPointerException. In general you should expect that users of your class will make mistakes, and so, where possible, you should always check for them and have defined what happens for when they make them, such as returning a flag value or throwing an exception. In effect an assertion is a way of checking that there are no bugs or unexpected usage in the code, not that the code that calls it is bug free—so do not use assertions to validate arguments passed to your non-private methods.
Assert statements may or may not be executed, so the compiler will not always consider them reachable. A variable that is initialized only in an assert statement will be considered potentially uninitialized because if asserts are disabled it will be uninitialized. This will be true even if all uses of the variable are in other assert statements.
You can also use assertions to verify that the control flow of some code is always what you want it to be:
// value must always be present
private void replace(int val, int nval) {
for (int i = 0; i < values.length; i++) {
if (values[i] == val) {
values[i] = nval;
return;
}
}
assert false : "replace: can't find " + val;
}
This loop should never reach the end, because some index in the loop ought to cause a return. If this doesn't happen, the loop will unexpectedly fall out the bottom and the program will continue silently on its unexpected way. The assertfalse after the loop means that if the control flow ever gets there you will be told.
In this kind of case you can reasonably avoid the assertion mechanism entirely and go straight to throwing the error yourself, replacing the assert with a throw:
throw new AssertionError("replace: can't find " + val);
Using a throw is especially valuable for methods that return values. Without a throw the compiler would not know that the method cannot get to the bottom, so it insists that you return a value at the end. That code typically looks like this:
return -1; // never happens
The comment “never happens” asserts something to be true but doesn't check or enforce it. Only a human reading the code knows the invariant. And an assertfalse could be turned off, so the compiler would still require the code to have a bogus return. The throw enforces what you already know.
The compiler will not let you have an assert statement it believes to be unreachable, just like it won't let you have any other unreachable statement. When the compiler can determine that a line is unreachable, not only do you need no assert, you may not put one there.
By default, assertion evaluation is turned off. You can turn on all assertion evaluation in a virtual machine, or on a package, class, or class loader basis. Because they can be on or off, you must be careful to avoid side effects that affect non-assertion code.
You control assertion evaluation either by passing command-line options to the virtual machine—described shortly—or by using methods provided by the class loader—see “Controlling Assertions at Runtime” on page 444.
The first question to answer is why you would want to be able to switch assertion evaluation on and off. The usual example is to turn assertions on during development, but turn them off when your system is shipping. The argument is that you will have caught any insanities during the development cycle so the overhead of doing all the checks is not worth the effort.
This is tempting logic, but you can open yourself up to serious problems. The point of assertions is to catch bugs early before they corrupt things and cause bizarre side effects. When someone else is running your code, tracking down causes for problems is much more difficult, so catching them early and reporting them clearly is much more important, even if it should happen a lot less often. You should only turn off assertions in code where they have very noticeable performance effects. In those critical sections of code, though, you will want to turn them off.
Assertion evaluation is off by default. To change this, you can use standard command line options if you are using a command-line-driven virtual machine:
-enableassertions/-ea[descriptor]Enables (turns on) assertion evaluation as defined by the
descriptor. If there is no descriptor, assertions are enabled for all classes except those loaded by the system class loader—see “Loading Classes” on page 435.
-disableassertions/-da[descriptor]Disables (turns off) assertion evaluation for all classes as defined by the
descriptor. If there is no descriptor, assertions are disabled for all classes.
The descriptor allows you to specify particular packages or classes that will be affected by the option. An absent descriptor means the option applies to all non-system classes (that is, classes loaded by any class loader but the system class loader). Packages are defined by name, followed by ... which means to apply the option to all subpackages. For example, the option
-enableassertions:com.acme...
would turn on assertions in all classes in com.acme and all its subpackages. If the descriptor consists only of ... it represents the unnamed package in the current working directory. Without the ... the descriptor is assumed to be the full name of a class.
-enableassertions:com.acme.Plotter
turns on assertions for the class com.acme.Plotter. So if you want to turn on all assertions in com.acme, but the class com.acme.Evalutor is not relevant, you could say
-enableassertions:com.acme... -da:com.acme.Evaluator
This applies the option to the Evaluator class and any of its nested types.
If you are using assertions in your code, the obvious thing you should do is always use –ea with enough specificity to get all your relevant code.
Multiple options are evaluated in order from the command line. Class-specific options take precedence over package ones, and a more specific package option takes precedence over a less specific one. For example, given
-da:com.acme.Plotter -ea:com.acme... -da:com.acme.products -ea:com.acme.products.Rocket
assertions will be enabled for all classes and subpackages of com.acme, except the class com.acme.Plotter, and disabled for all classes and subpackages of com.acme.products, except for the class com.acme.products.Rocket.
The system classes are controlled separately because you are more likely to be searching for bugs in your code than in the system code. To affect system classes, use the “system” variants of the options: -enablesystemassertions/-esa and -disablesystemassertions/-dsa (the latter option is primarily for symmetry).
The assertion status of a class is determined when that class is initialized—see “Preparing a Class for Use” on page 441—and never changes. This determination is made before any static initializers for the class are executed, but after the initialization of the superclass. If a superclass static initializer causes a static method of its own subclass to be executed, it is possible for that static method to execute before its own class is initialized, and before the assertion status of that class has been determined. In such circumstances, the execution of any assert statements must be dealt with as if assertions were enabled for the class.
Even though assertions may never get executed at runtime, the code associated with them still exists, and they can still consume virtual machine resources and add overhead to the performance of an application. For most applications this isn't something you should worry about—and a good just-in-time compiler will take care of the overhead—but sometimes, in resource constrained environments, you do have to worry about it. The only way to guarantee the complete removal of assertion related code is to edit the code and remove the assertions. But there is a standard Java programming idiom that gives the source code compiler a hint that you don't want certain sections of code present under some circumstances:
private static final boolean doAssert = true;
if (doAssert)
assert (cleared || size == origSize);
In the above code fragment, asserts will be checked only if the doAssert variable is true. The doAssert variable is a compile-time constant—it is static, final, and initialized with a constant value—and references to compile-time constants are replaced, at compile time, with the value of that constant. If doAssert is false nothing will ever cause the assert to get executed, so the if statement can be completely removed by the compiler, if it chooses. You can also use this technique to elide debugging print statements, for example.
Sometimes (rarely) you may need to ensure that some class never has its assertions turned off. You can do this with code like the following
static {
boolean assertsEnabled = false;
assert assertsEnabled = true;
if (!assertsEnabled)
throw new IllegalStateException("Asserts required");
}
In this code we purposefully use a side effect of the assert statement so that the code can determine whether asserts have been turned off—if they have then the class will not load. This is a nearly unique case in which side effects are a good thing.
Requiring assertions to be on complicates the running environment of the code since it must always turn on assertions for this class even if they are off elsewhere. You should do this almost, if not actually, never.
The greatest of all faults is to be conscious of none. | ||
| --Thomas Carlyle | ||