
Chapter 17. Multi-Party Coordination Patterns
The two-party coordination patterns of the previous chapter generalize to situations involving three or more parties. This chapter explores four of these generalizations and offers some thoughts on data validation and breakdown detection in multi-party situations. The patterns discussed in this chapter include:
• Multi-Party Delegation with Confirmation
The three other coordination patterns from the previous chapter, Delegation, Distributed Transactions, and Third-Party Process Coordinator, also extend to multiple parties. However, the discussion of these patterns in the previous chapter, augmented with the additional discussion in this chapter, is sufficient to cover their multi-party extensions. Therefore, these patterns will not be discussed further in this chapter.
Multi-Party Fire-and-Forget
The Multi-Party Fire-and-Forget pattern (Figure 17-1) is pretty much what you would expect. The pattern generally arises when the service provider sends its service result to a third party. Commonly, the arrival of the service result also serves as a trigger (an implicit request) for the third party to perform some work.
Figure 17-1. Multi-Party Fire-and-Forget
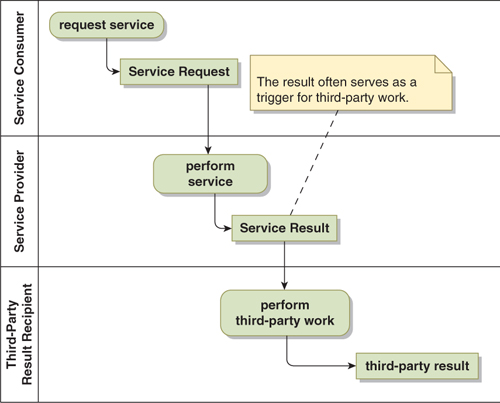
As with its two-party cousin, the Multi-Party Fire-and-Forget pattern is simple (and therefore inexpensive) to implement, but it offers no breakdown detection anywhere in the process.
Multi-Party Request-Reply
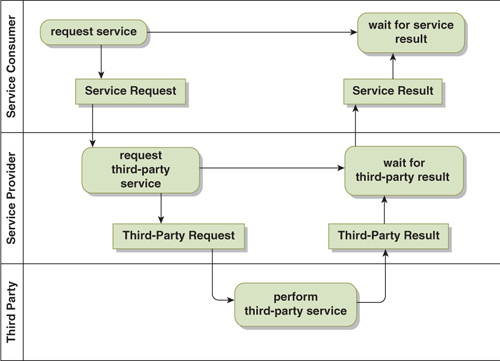
The multi-party extension to synchronous request-reply is shown in Figure 17-2. This extension, like its two-party cousin, is very robust with respect to breakdown detection—again, with the caveat concerning the need for response-time service-level agreements. The pattern also tends to extend the length of time that the service consumer waits for the reply since latency is added in each layer of the exchange. Furthermore, resources are tied up for every participant waiting for the reply. When the request volume is high, and/or the nesting is deep, the resulting resource consumption can be a significant factor in the design and should be carefully considered.
Figure 17-2. Synchronous Multi-Party Request Reply
Multi-Party Delegation with Confirmation
Just as the two-party delegation with confirmation pattern had several variants, so does the multi-party pattern. Figure 17-3 shows a variation in which the hand-off to the third party is treated as part of providing the service, and the eventual hand-off of the third-party result is accomplished via fire-and-forget.
Figure 17-3. Multi-Party Delegation with Confirmation
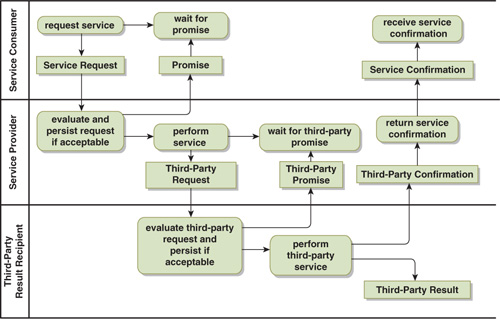
With the exception of the delivery of the third-party result, this pattern can detect any breakdown in the process. Breakdown detection could be further strengthened by delivering the third-party result via request reply or some other breakdown-detecting pattern.
The major advantage of this pattern over the multi-party request-reply is that the resources of the service consumer and intermediate parties are not tied up during the time it takes to perform the work. The disadvantage is that the eventual confirmations are delivered asynchronously, resulting in a more complex design (see the discussion of the two-party request-reply pattern in the previous chapter).
Data Validation
A common requirement in a distributed solution is that the validity of information must be checked at some point in the process. Such requirements give rise to two questions: What kind of validation is required? And where should this validation occur?
Types of Validation
Validation can run the gamut from simple syntactic checks through complex analysis of the data. Some of the most common techniques are the following:
• Syntactic validation: Checking the format of the supplied information. With XML the process involves validating the XML against its defining schema.
• Self-consistency checks: Comparing data elements against one another for logical consistency. For example, is the requested delivery date on an order on or after the order placement date?
• External reference checks: Determining whether the data correspond to information saved in some system. Does the supplied customerID match one in the customer database?
Where to Validate Impacts Coordination Pattern Selection
Looking at the example in Figure 17-4, there are multiple points within this process at which the information in the initial service request might be validated. The design question is: Where is the optimal place for validation?
Figure 17-4. Possible Points of Validation in a Front-to-Back Dialog
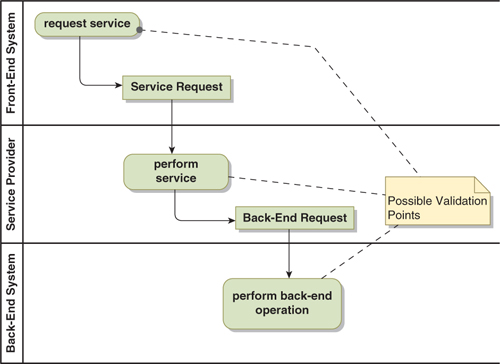
A good rule of thumb is to perform validation as close to the origin of the information as possible. This is because correcting the information is generally easier the closer you are to the source. Based on this guideline, the ideal place to validate in the Figure 17-4 example would be in the front-end system itself, which is likely a user interface. There, errors can be detected and the user immediately prompted to correct the error.
Second best would be to have the service provider validate the information in the incoming service request. However, a problem immediately arises: Since this is a fire-and-forget interaction, there is no mechanism available to correct invalid inputs. If you want to fix a problem here, you need to design a secondary process by which the invalid input is identified, corrected, and resubmitted. This recovery process can be as complicated as the mainstream process!
Another alternative would be to replace the Fire-and-Forget interaction with a Request-Reply or Delegation pattern. This would afford the opportunity for the front-end system to prompt the user to correct the invalid information. Although not as simple as catching the error initially, it is simpler than designing a secondary process.
An aside regarding the use of SOAP faults is in order here. Rule of thumb: If you are designing for the exception, don’t use a SOAP fault to return it. Instead, design the return data structure to represent both the normally expected data and the alternative results that can arise. The reason is that handling SOAP faults generally breaks the process flow in the component receiving the faults. This makes it very complicated for that component to recover by taking some action and then resuming the process.
Similar considerations apply to placing the validation in the back-end system. Fire-and-forget would again require a secondary process for recovery, while replacing it with a Multi-Party Request-Reply or Multi-Party Delegation pattern makes it possible for the front-end system to correct the original inputs.
The decision about where to validate also depends somewhat on the nature of the validation being performed. Syntactic validation and self-consistency checks can typically be performed anywhere. It is good practice, for example, to always validate an XML structure—whether the component is creating it or receiving it.
External reference checks, on the other hand, require access to the external data. In the example, if the back-end system is the owner of the data, then this validation can be readily performed in the back-end system. If you wanted to perform that check in either the service or the front-end system, the back-end system would have to provide another interface to access the data (or, alternatively, perform the actual validation).
For this reason, when the business process calls for external reference checks, it is good practice to explicitly model them both in the process model and, most importantly, in the mapping of that model onto the architecture pattern.
Multi-Party Breakdown Detection
The choice of coordination patterns has a direct impact on the solution’s ability to detect breakdowns in the business process. Bottom line: If it can’t be detected, you can’t do anything about it!
The Fire-and-Forget pattern provides no opportunity to detect breakdowns. Request-Reply provides two forms of breakdown detection: a reply that explicitly indicates the existence of a problem and the absence of a reply after the response time SLA has expired. Delegation can detect breakdowns in the work hand-off, but not in the subsequent execution of the service. Adding Confirmation enables the detection of work performance breakdowns. Depending upon the coordination patterns used, it may also be able to detect problems in the delivery of the work result.
Distributed transactions can detect breakdowns in the execution of the transaction, but nothing else. A Process Coordinator can detect problems anywhere in the process provided that it, in turn, uses appropriate coordination patterns when interacting with the process participants.
Adding Feedback to Improve Breakdown Detection
The addition of feedback in a process can greatly improve breakdown detection. Consider the process shown in Figure 17-5. This is essentially a Multi-Party Fire-and-Forget pattern with one addition: The last participant in the process is sending a confirmation back to the first participant confirming that the work was performed. This immediately places the first participant in a position to detect a breakdown anywhere in the process (with the possible exception of the third-party work result delivery, depending upon the coordination used for that).
Figure 17-5. Adding Feedback to Improve Breakdown Detection
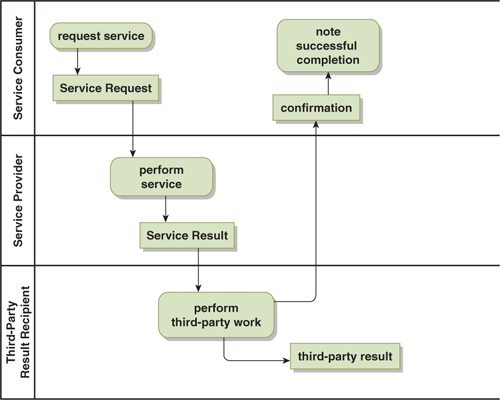
The implication here is that you can greatly improve the breakdown detection of any process with the selective addition of feedback.
Third-Party Process Monitoring
Another approach to detecting breakdowns is to add a process monitor (Figure 17-6). The monitor captures events that are generated at various points in the process and uses them to determine whether or not the process is executing properly. TIBCO BusinessEvents is ideally suited to play this monitoring role.
Figure 17-6. Third-Party Process Monitoring
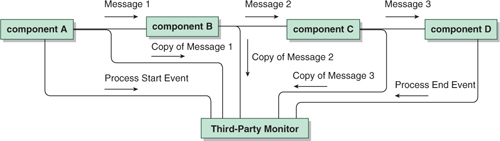
Evaluating an Architecture for Breakdown Detection
If you have mapped the business process onto the architecture pattern in the manner described, evaluating the architecture for breakdown detection is a straightforward process. For each participant (swimlane), ask yourself: What would the impact be if that participant failed? Which other participant (if any) would notice, and what would the symptoms be? Then ask the same question for each interaction: What would the impact be? Which participants (if any) would notice and what would the symptoms be?
When you perform this analysis, you will observe an interesting phenomenon: Many different failures typically result in a small number of symptoms. Looking at Figure 17-5, the loss of the Service Provider, Third-Party Recipient, Service Request, Service Result, or Confirmation will all result in the same symptom—the Confirmation will not be received by the Service Consumer. This puts the Service Consumer in a position to detect breakdowns anywhere in the process, although it does not provide sufficient information to determine the nature of the problem.
Finally, you should consider what the component detecting the breakdown should do with the information. You most likely will want this information in a log file, but nobody will know that the error has occurred. It is good practice to annunciate the existence of the breakdown so that at least someone is aware that there is a problem. Doing this requires an understanding of your organization’s operations group and the mechanisms available to inform it of problems.
Summary
The two-party coordination patterns extend in consistent ways to multi-party interactions. The Multi-Party Fire-and-Forget pattern is simple, but again affords no opportunity for breakdown detection. Multi-Party Request-Reply can detect all breakdowns, but long response times and high request volumes can tie up many resources. Multi-Party Delegation with Confirmation does not tie up resources while work is being performed but still provides the same level of breakdown detection as Multi-Party Request-Reply.
Data validation is an important consideration in distributed design. There are different types of validation that may be required, including syntactic checks, self-consistency checks, and external reference checks. The location of the data validation impacts the ease with which the process can be recovered from a failed validation. The choice of coordination patterns impacts the ease of recovery.
Breakdown detection is another important consideration that is also impacted by the selection of coordination patterns. Adding feedback to a process can greatly improve breakdown detection. Architectures are readily evaluated for breakdown detection by considering the loss of individual process participants and communications and then determining which remaining participants (if any) are in a position to detect that the process has failed.