
Chapter 1 – The Teradata Fundamentals
“The man who doesn't read good books has no advantage over the man who can't read them.”
What is Parallel Processing?
“After enlightenment, the laundry”
Tera-Tom's Parallel Processing Wash and Dry
“After parallel processing the laundry, enlightenment!”
Two guys were having fun on a Saturday night when one said, “I've got to go and do my laundry.” The other said, “What?!” The man explained that if he went to the laundry mat the next morning, he would be lucky to get one machine and be there all day. But, if he went on Saturday night, he could get all the machines. Then, he could do all his wash and dry in two hours. Now that's parallel processing mixed in with a little dry humor!
The Basics of a Single Computer

How are we doing on orders today?
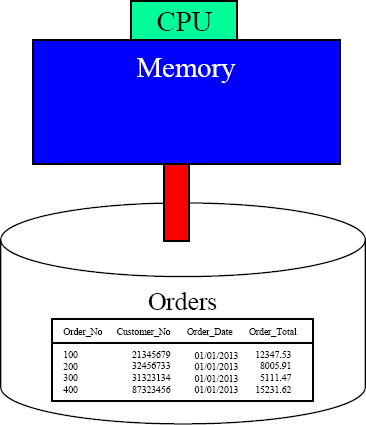
How would I know? I'm just a disk. I need to transfer the block of data to the memory, and that is a slow process.
Data on disk does absolutely nothing. When data is requested, the computer moves the data one block at a time from disk into memory. Once the data is in memory, it is processed by the CPU at lightning speed. All computers work this way. The “Achilles Heel” of every computer is the slow process of moving data from disk to memory. That is all you need to know to be a computer expert!
Teradata Parallel Processes Data
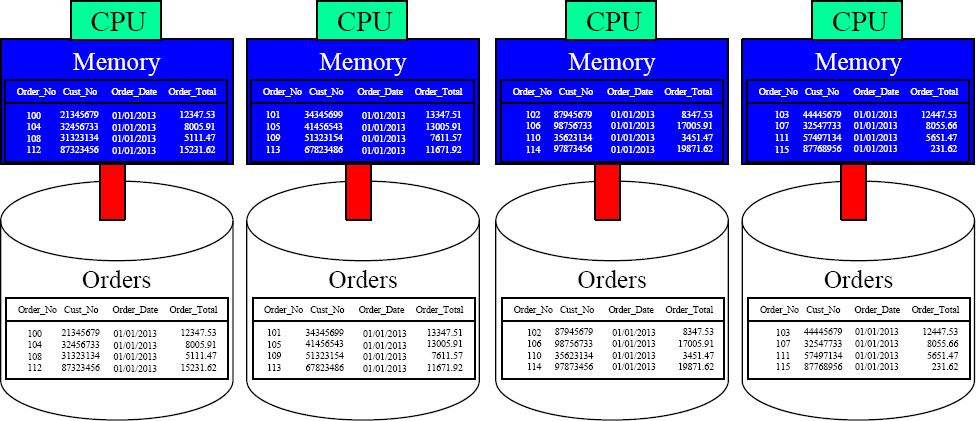
Teradata has been the pioneer in parallel processing since 1988 when Wells Fargo bought the first Teradata system. In the picture above, you see that we have 16 orders with four orders placed on each disk. It appears to be four separate computers, but this is one system. Teradata systems work just like a basic computer as they still need to move data from disk into memory, but Teradata divides and conquers.
The Teradata Architecture
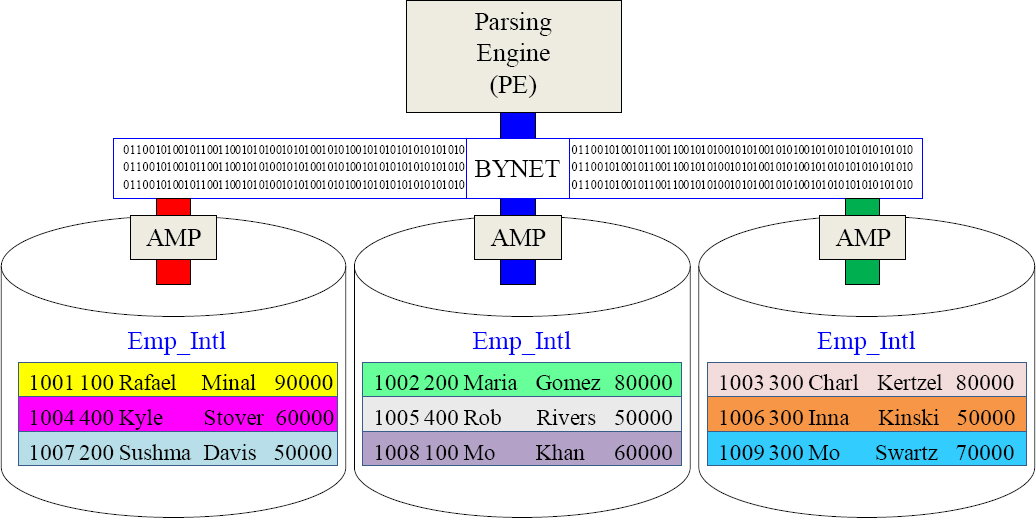
The Parsing Engine (PE) takes the User's SQL and builds a Plan for each AMP to follow to retrieve the data. Parallel Processing is all about each AMP doing an equal amount of the work. If they start at the same time and end the same time, they are performing true Parallel Processing. All communication is done over the BYNET.
Parallel Architecture
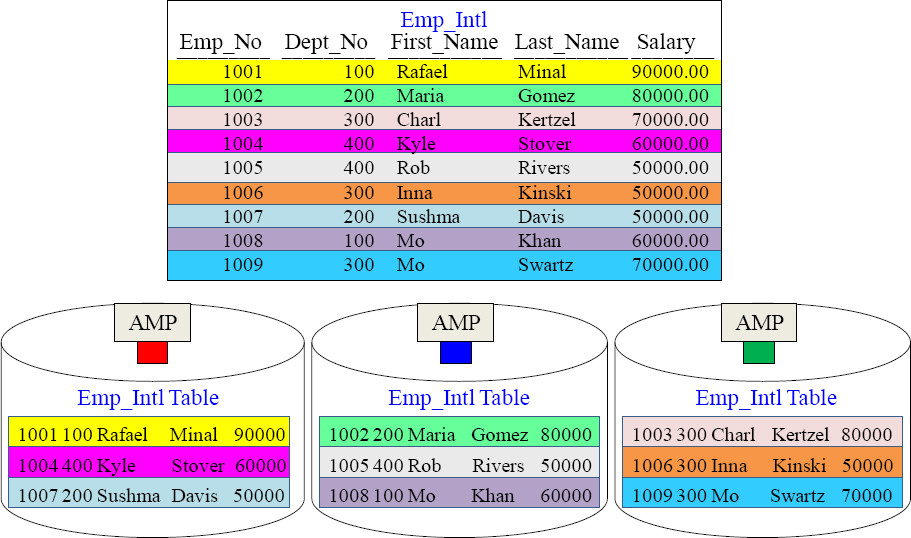
The rows of a Teradata table are spread across all the AMPs, so each AMP can then process an equal amount of the rows when a USER queries the table. Every table is spread across every AMP as evenly as possible.
All Teradata Tables are spread across ALL AMPS
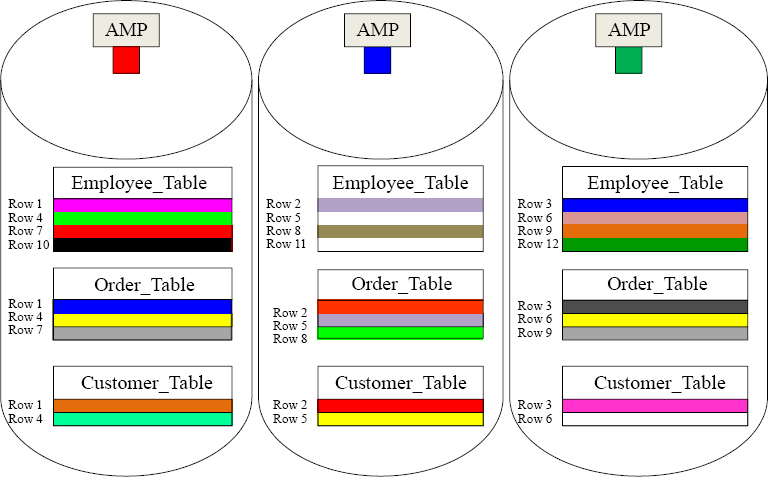
Each table dreams of spreading their rows equally across the AMPs. Notice in the picture above, that we have three tables, and each table spreads their rows across all AMPs. If there were 500 tables in the system, then all 500 tables would be spread across the AMPs. Every AMP is responsible for a portion of the rows on every table.
Teradata Systems can Add AMPs for Linear Scalability
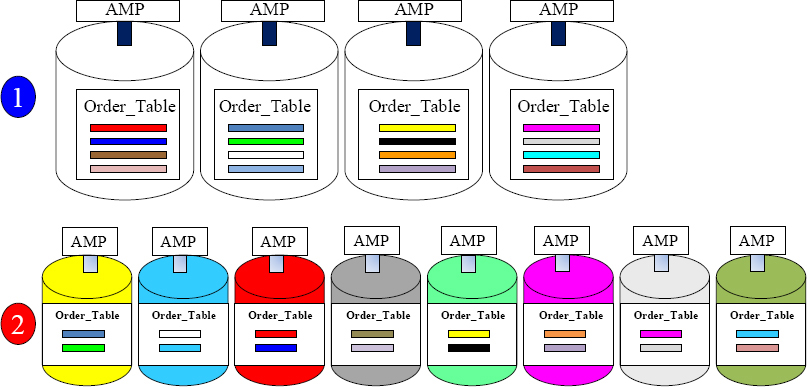
4-AMP Test System.
Order_Table has 16 rows.
8-AMP Production System – with the same 16 rows
Teradata systems often start small, but as more data is added or more power is needed, more AMPs are added. Above, you can see that our system at first had four AMPs. The Order_Table has 16 rows and each AMP is responsible for four Order_Table rows. Our second system has upgraded to eight AMPs. The Order_Table still has 16 rows, but now each AMP is responsible for one two Order_Table rows. Teradata systems will often continue to grow, and some systems have thousands of AMPs.
Teradata Parallel Processing
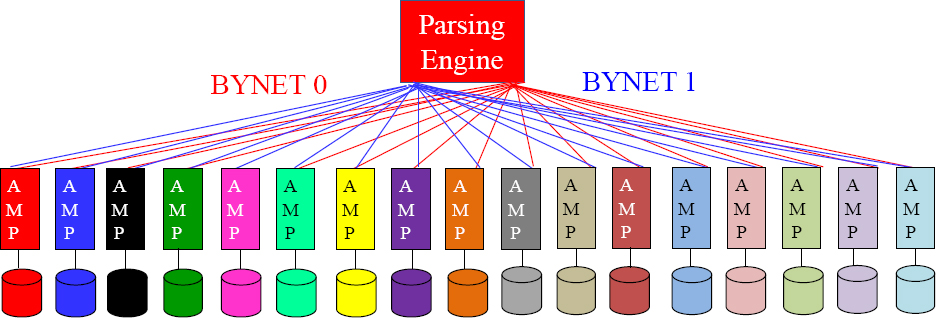
Each AMP holds a portion of the rows for every table in the system.
This is a great picture to put in your mind of how Teradata works. The most important concept is that every table is created on every AMP, and each AMP is responsible for a portion of the rows on each table. Each AMP does what the Parsing Engine tells them to do, and each AMP is only concerned about the rows of a table they own. The system is designed so each AMP reads and writes the rows they own simultaneously.
Teradata Systems can continue to grow to thousands of AMPs
“If you do what you've always done, you'll get what you've always got.”
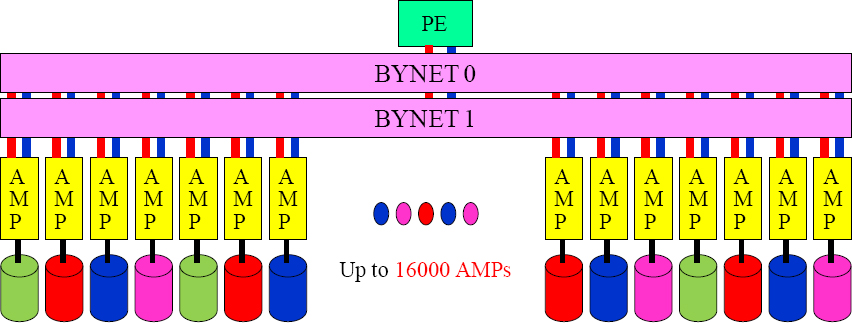
The largest systems in the world have used Teradata for market dominance for the past 20 years. Its Massively Parallel Processing (MPP) technology analyzes data so large that companies can run queries they have never been able to run before. Recognize that you now have something very powerful, and that is the ability to analyze every aspect of your business. So do what you've never done, and get something that you've never got.
How Teradata Creates Tables
CREATE TABLE Sales_Table
( Product_ID INTEGER
,Sale_Date DATE
,Daily_Sales DECIMAL (10,2)
) PRIMARY INDEX (Product_ID) ;
When a table is created a Table Header is created on every AMP.
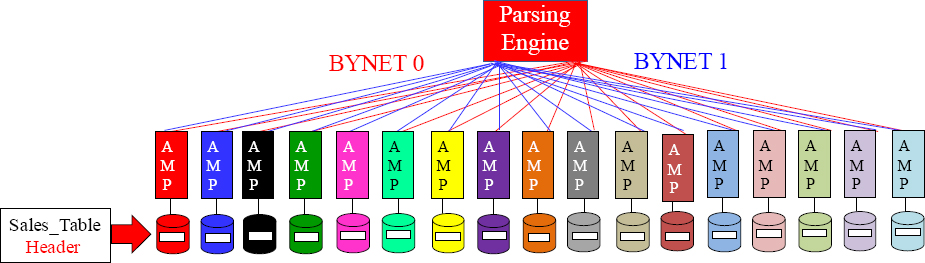
When a table is created, a Table Header is automatically created on every AMP. Each AMP thus has the exact same amount of tables. From a table perspective, each AMP looks exactly the same as if they were looking at each other in a mirror.
Every AMP has the Exact Same Tables
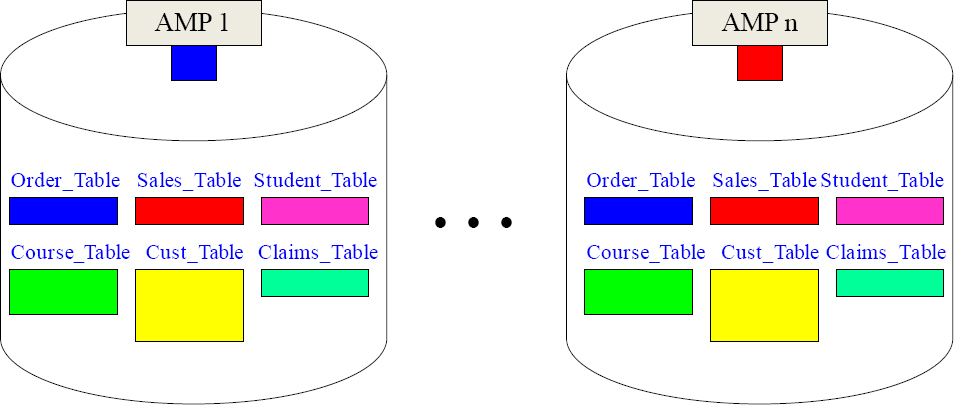
The first thing that happens when a table is created is that a Table Header is created on every AMP. So now, each AMP has the table and they know the table's columns. So, each AMP has the exact same tables and the exact same number of tables. It is just like looking into a mirror. Each AMP will hold a portion of the rows on every table.
All Teradata Tables are spread across All AMPs
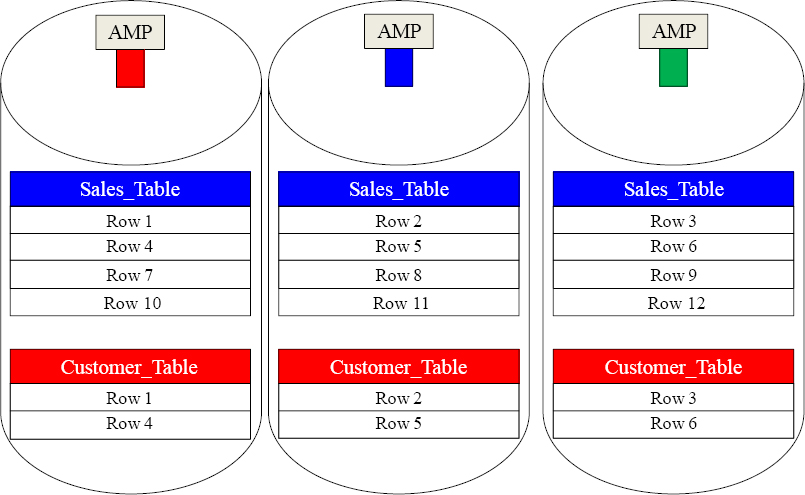
When data is loaded, each AMP holds a portion of the rows for every table. When queries are run, each AMP simultaneously retrieves the rows they are responsible for.
Understand the Extremes of Teradata for Tactical Queries
“It's kind of fun to do the impossible.”
-Walt Disney

Mastering the extremes allows Teradata to do the impossible. When I was 21 years old, I decided that my career would consist of mastering the extremes. My goal was to become the best and most knowledgeable speaker in the world, and to also become one of the most technical computer experts in the business. This made the early years of my career very difficult, but as time went on, I soon realized this was the best decision of my life.
Teradata has brilliantly mastered the extremes as they can analyze massive amounts of data. But, did you know that Teradata can find a single record in under a second, no matter how much data is stored?
This extreme capability is made possible because every table in Teradata has one column designated as the Primary Index. When users want to find a single record quickly, they merely query and ask for the value in the Primary Index column. The query will come back in under a second every time. Understanding this extreme is one of the most important concepts that business users can understand. These lightning fast queries are called Tactical Queries.
Each Table has a Primary Index that is Unique or Non-Unique
| UPI |
CREATE TABLE Department_Table
| ( Dept_No | INTEGER, |
| ,Dept_Name | CHAR (20), |
| , Budget | DECIMAL (10,2)) |
UNIQUE PRIMARY INDEX ( Dept_No ) ;
| NUPI |
CREATE TABLE Department_Table
| ( Dept_No | INTEGER, |
| ,Dept_Name | CHAR (20), |
| , Budget | DECIMAL (10,2)) |
PRIMARY INDEX ( Budget ) ;
| Multi-Column NUPI |
CREATE TABLE Department_Table
| ( Dept_No | INTEGER, |
| ,Dept_Name | CHAR (20), |
| , Budget | DECIMAL (10,2)) |
PRIMARY INDEX ( Dept_Name, Budget ) ;
| If no Primary Index is defined then the 1st column is selected as a NUPI |
CREATE TABLE Department_Table
| ( Dept_No | INTEGER, |
| ,Dept_Name | CHAR (20), |
| , Budget | DECIMAL (10,2)) ; |
Each Teradata table has only one Primary Index and it is either a Unique Primary Index (UPI) or a Non-Unique Primary Index (NUPI). The Primary Index is established when the table is created inside the CREATE Table statement.
The Hash Map Determines which AMP will own the Row
Every row is run through a math formula, and the result is the “Row Hash”. This alone, in conjunction with the Hash Map, determines which AMP will hold the row.
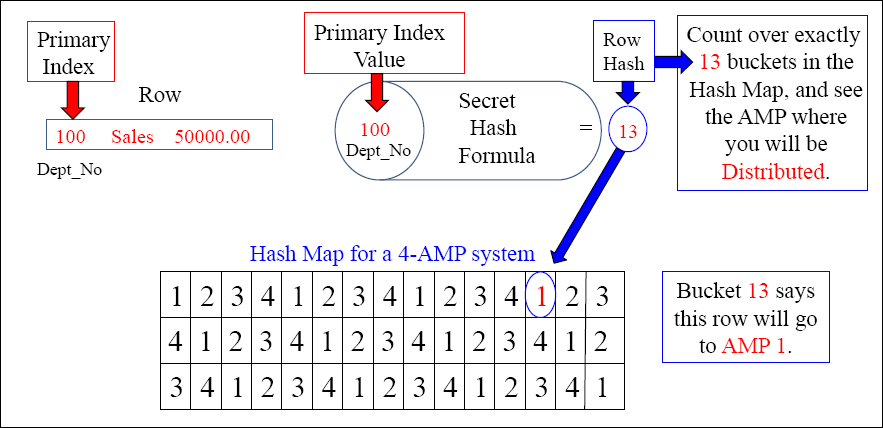
Teradata uses one secret “Hash Formula” that runs a math formula on the Primary Index value of each row. The hashing of the row results in an answer called the “Row Hash”. This alone, in conjunction with the system's hash map, determines which AMP holds the row. The Parsing Engine can rerun the Hash Formula again to quickly find the row.
A Unique Primary Index Spreads the Data Evenly
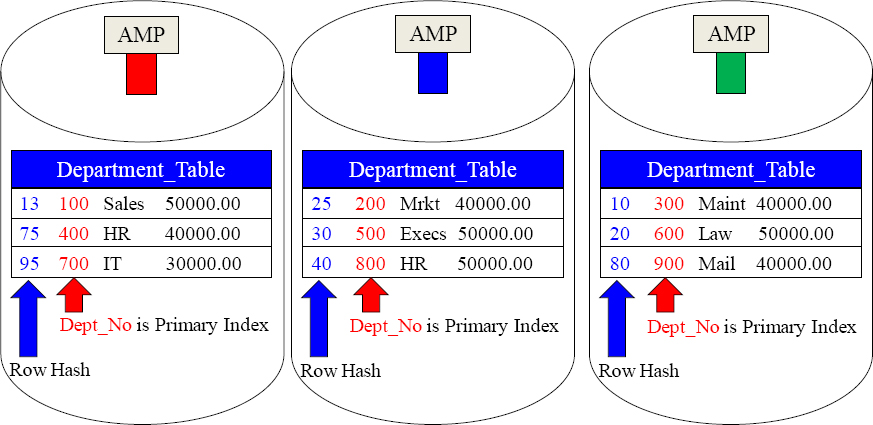
The Row Hash is the result of the Primary Index value going through the Hash Formula. It will stay with the row forever.
The Department_Table has a Unique Primary Index (UPI) on Dept_No. The rows are spread evenly across the AMPs. Take notice of the Row Hash in front of each row. When the row is hashed, the resulting Row Hash sticks with the row like glue forever.
A Non-Unique Primary Index Skews the Data
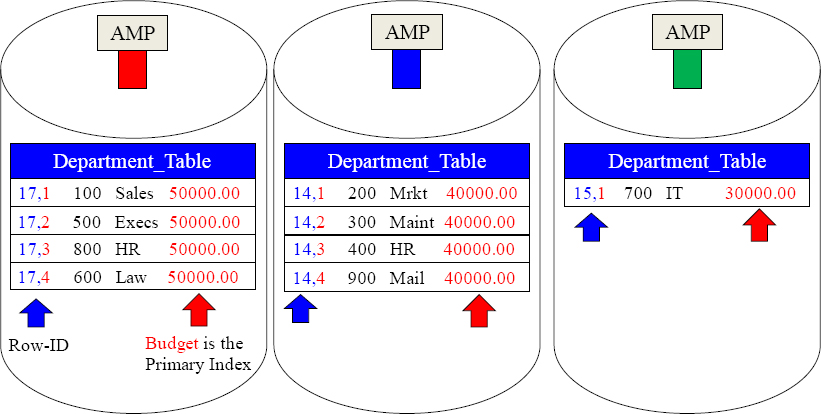
Because Budget was chosen as the Primary Index, and the Teradata hash formula is consistent, all like values go to the same AMP. Notice that all of the budgets of 50,000.00 went to AMP 1. The 40,000.00 budgets all went to AMP 2, and the only row with a 30,000.00 budget went to AMP 3. The data is skewed. Also notice the Row Hash values and the increasing Uniqueness ID for budgets with the same value.
Comparing the Same Table with Different Primary Indexes
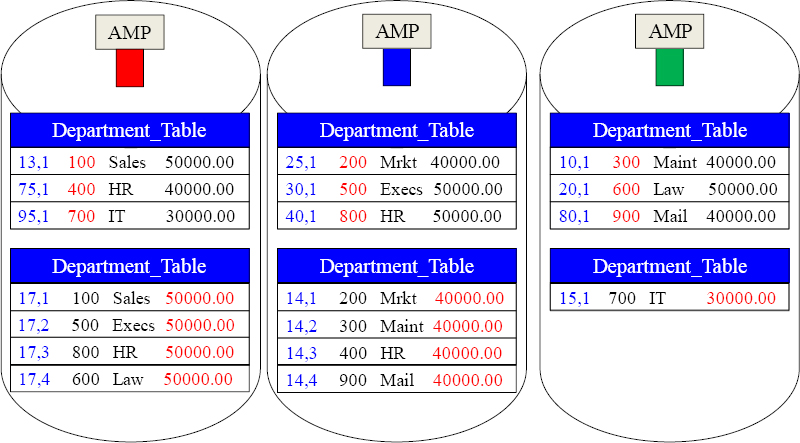
The Department_Table is laid out twice, but with a different Primary Index. The red colors denote the table's Primary Index, and the blue colors denote the Row-ID. The top example uses a Unique Primary Index (UPI) to distribute data evenly, but the bottom example uses Budget as a Non-Unique Primary Index (NUPI) and the data is skewed.
Unique Primary Index Queries are a Single AMP Retrieve
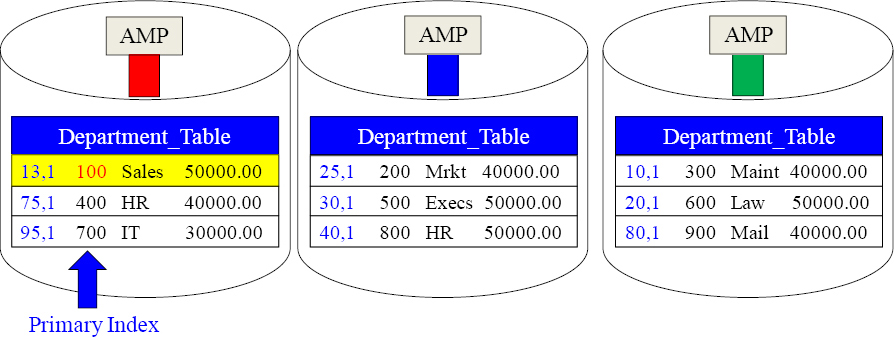
SELECT *
FROM Department_Table
WHERE Dept_No = 100 ;
The above query uses the Unique Primary Index (UPI) on Dept_No in the WHERE clause of the SQL. This results in a “Single AMP retrieve”. Only AMP 1 is contacted to retrieve the row. The Parsing Engine distributes the data by hashing the Primary Index value with a “Hash Formula”, so the Parsing Engine's plan is to reengineer that process, and the BYNET only contacts AMP 1. Give Teradata any Primary Index value for a table, and it knows which AMP has that row by rerunning the “Hash Formula”.
Using EXPLAIN
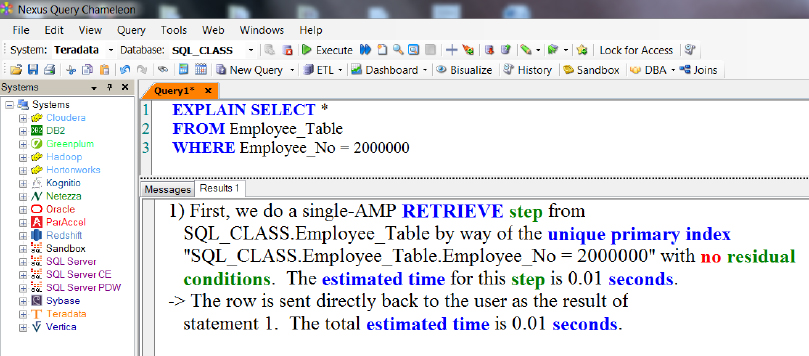
If you want to see the Parsing Engine's plan, all you have to do is type EXPLAIN in front of your SQL. You can also hit the Function Key F6 or click on the magnifying glass on Nexus. Above, you can see that we are doing a single-AMP RETRIEVE step by way of a Unique Primary Index (UPI).
A Non-Unique Primary Index is also a Single AMP Retrieve
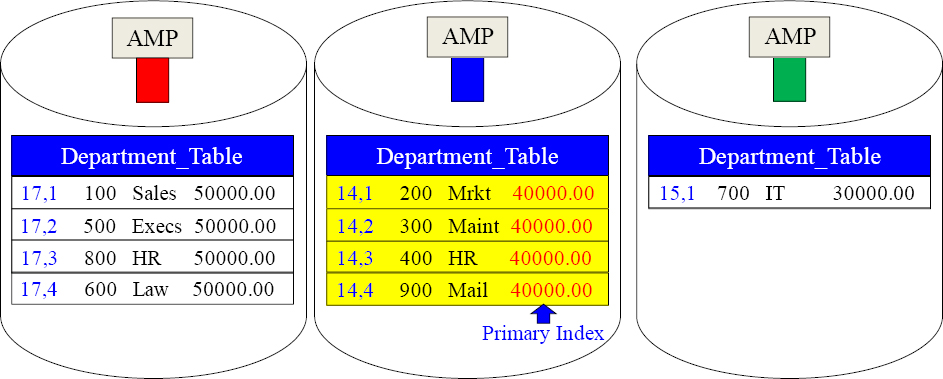
SELECT * FROM Department_Table
WHERE Budget = 40000.00 ;
The above query uses a Non-Unique Primary Index (NUPI) on the column Budget in the WHERE clause of the SQL. This also results in a Single AMP retrieve. Only AMP two is contacted to retrieve the rows. The Parsing Engine distributes the data by hashing the Primary Index value, so the Parsing Engine's plan is to reengineer this process and contact only the proper AMP. AMP two brings back all qualifying rows.
Using EXPLAIN in a NUPI Query
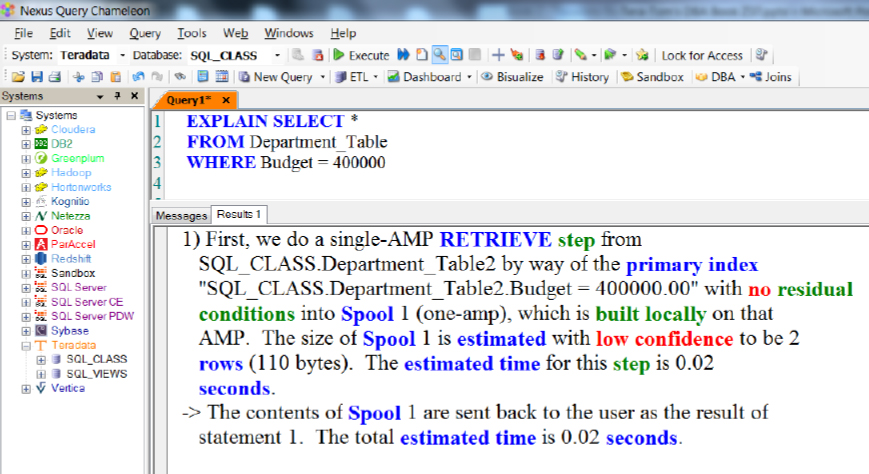
If you want to see the Parsing Engine's plan, all you have to do is type EXPLAIN in front of your SQL. You can also hit the Function Key F6 or click on the magnifying glass on Nexus. Above, you can see that we are doing a single-AMP RETRIEVE step by way of a Primary Index (NUPI).
Teradata has a No Primary Index Table called a NoPI Table
CREATE TABLE Department_Table
(Dept_No INTEGER,
Dept_Name CHAR(20),
Budget DECIMAL(10,2))
NO PRIMARY INDEX ;
NoPI
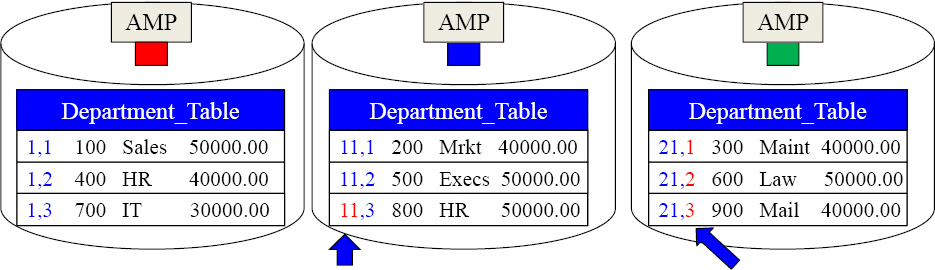
Each AMP is assigned a Row Hash, and then it merely increments its Uniqueness Value.
A NoPI Table has no primary index. A NoPI table guarantees even distribution. It still has a Row-ID. How? Each AMP is assigned a Row Hash and then for every row the AMP receives it increments the Uniqueness Value. A NoPI table is most often used as a loading staging table or with a columnar designed table. Each row is appended quickly. Distribution is always random, but even, so as a staging table it is quicker to load.
A conceptual example of a Table with NO PRIMARY INDEX
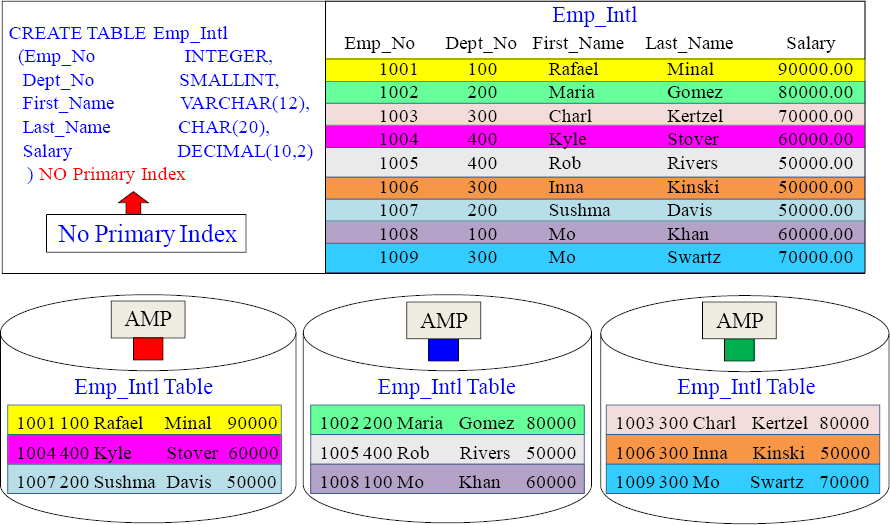
A Table that specifically states NO PRIMARY INDEX will receive no primary index. It will distribute the data evenly but randomly, and this is often used as a staging table.
A Full Table Scan is likely on a table with NO Primary Index
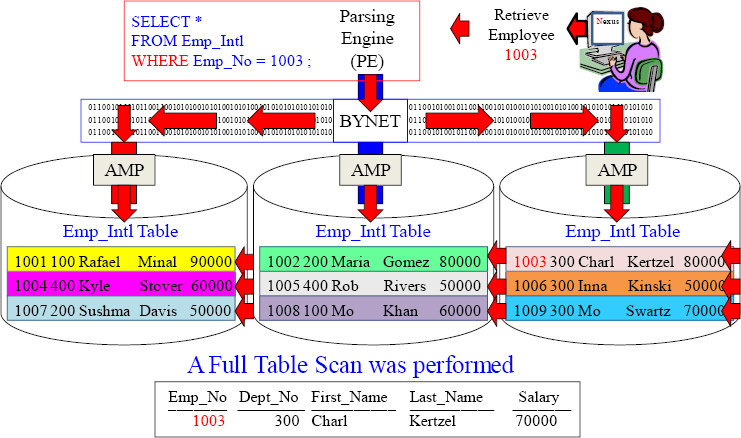
Since a NO Primary Index (NoPI) table has no primary index, the system retrieves by performing a Full Table Scan which means All-AMPs read All-Rows they own once.
Table CREATE Examples with four different Primary Indexes
![]() CREATE TABLE Emp_Intl
CREATE TABLE Emp_Intl
| (Emp_No | INTEGER, |
| Dept_No | SMALLINT, |
| First_Name | VARCHAR(12), |
| Last_Name | CHAR(20), |
| Salary | DECIMAL(10,2)) |
UNIQUE PRIMARY INDEX ( Emp_No ) ;
UPI
![]() CREATE TABLE Emp_Intl
CREATE TABLE Emp_Intl
| (Emp_No | INTEGER, |
| Dept_No | SMALLINT, |
| First_Name | VARCHAR(12), |
| Last_Name | CHAR(20), |
| Salary | DECIMAL(10,2)) |
PRIMARY INDEX ( Dept_No ) ;
NUPI
![]() CREATE TABLE Emp_Intl
CREATE TABLE Emp_Intl
| (Emp_No | INTEGER, |
| Dept_No | SMALLINT, |
| First_Name | VARCHAR(12), |
| Last_Name | CHAR(20), |
| Salary | DECIMAL(10,2)) |
PRIMARY INDEX ( First_Name , Last_Name );
Multi-Column NUPI
![]() CREATE TABLE Emp_Intl
CREATE TABLE Emp_Intl
| (Emp_No | INTEGER, |
| Dept_No | SMALLINT, |
| First_Name | VARCHAR(12), |
| Last_Name | CHAR(20), |
| Salary | DECIMAL(10,2)) |
No Primary Index
No Primary Index
A table can have only one Primary Index, so picking the right one is essential. Above are four different examples for your consideration.
What happens when you forget the Primary Index?
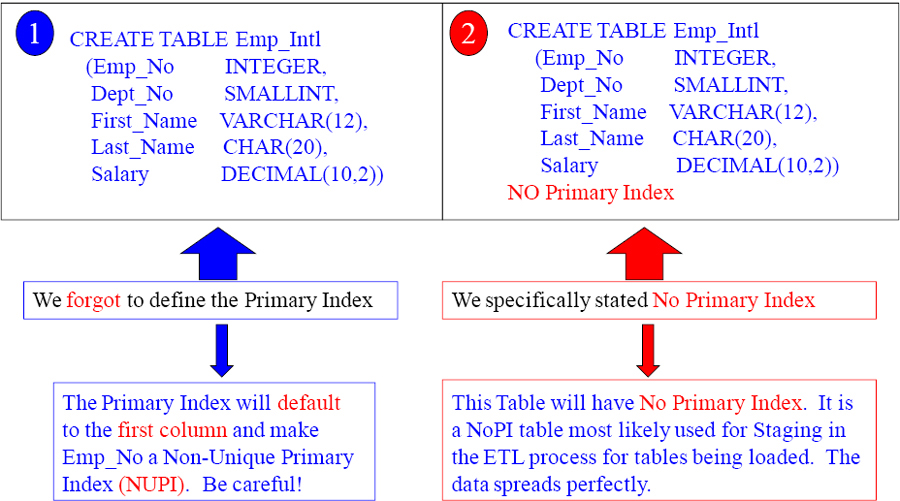
When you forget to define the Primary Index, Teradata will default to the first column in the table and it will be defined as Non-Unique. Clearly define what you want!