
Chapter 7 - How Joins Work Under the Covers
“The covers of this book are too far apart.”
Teradata Join Quiz
Which Statement is NOT true!
- Each Table in Teradata has a Primary Index, unless it is a NoPI table.
- The Primary Index is the mechanism that allows Teradata to physically distribute the rows of a table across the AMPs using a Hash Formula and the Hash Map.
- Each AMP Sorts its rows by the Row-ID unless it is a Partitioned table, and then it sorts first by the Partition and then by Row-ID which is actually the Row Key.
- For two rows to be Joined together, Teradata insists that both rows are physically on the same AMP.
- Teradata will either Redistribute one or both of the tables or Duplicate the smaller table across all AMPs to ensure that the matching rows are on the same AMP in FSG Cache. Once the matching rows are on the same AMP, the join can take place.
Do you know which statement above is False?
Teradata Join Quiz Answer
All statements below are true!
- Each Table in Teradata has a Primary Index, unless it is a NoPI table.
- The Primary Index is the mechanism that allows Teradata to physically distribute the rows of a table across the AMPs using a Hash Formula and the Hash Map.
- Each AMP Sorts its rows by the Row-ID unless it is a Partitioned table, and then it sorts first by the Partition, and then by Row-ID which is actually the Row Key.
- For two rows to be Joined together, Teradata insists that both rows are physically on the same AMP.

- Teradata will either Redistribute one or both of the tables or Duplicate the smaller table across all AMPs to ensure that the matching rows are on the same AMP in FSG Cache. Once the matching rows are on the same AMP, the join can take place.
All statements above are true. Teradata must have the matching rows on the same AMP in FSG cache for the join to take place. You don't see two people getting married in different locations, do you? For a join or marriage to take place, both must be together.
The Joining of Two Tables
SELECT C.CustNo,
,C.CustName
,O.Order_Total
FROM Customer_Table as C
INNER JOIN Order_Table as O
ON C.CustNo = O.CustNo ;
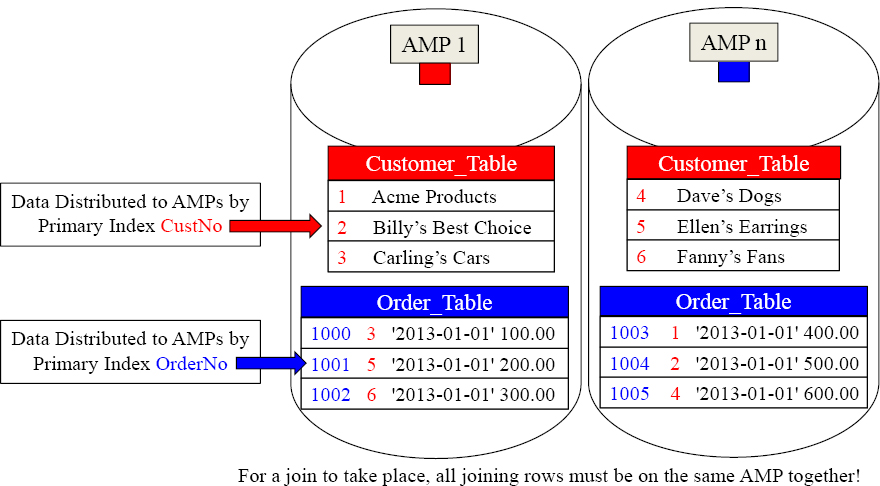
CustNo (1-6) (red) are the Join Condition (PK/FK). Each customer has placed one order. The matching join rows are on different AMPs because the tables were distributed by different Primary Indexes. How will Teradata get the joining rows on the same AMP? They will redistribute the Order_Table by Cust_No in FSG Cache memory.
Teradata Moves Joining Rows to the Same AMP
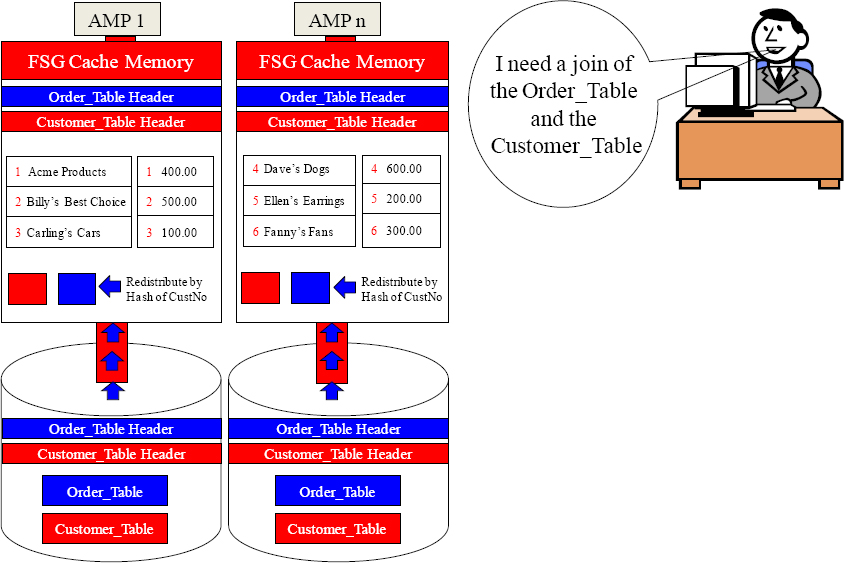
Parsing Engine
Move you Customer_Table and Order_Table blocks into FSG Cache.
Redistribute the Order_Table over the BYNET by the CustNo column.
Now Join the matching CustNo rows now that they're in the same FSG Cache.
On all joins, the matching rows must be on the same AMP so hashing is how it is done.
Imagine Joining Two NoPI Tables that have No Primary Index
SELECT C.CustNo,
,C.CustName
,O.Order_Total
FROM Customer_Table as C
INNER JOIN Order_Table as O
ON C.CustNo = O.CustNo ;
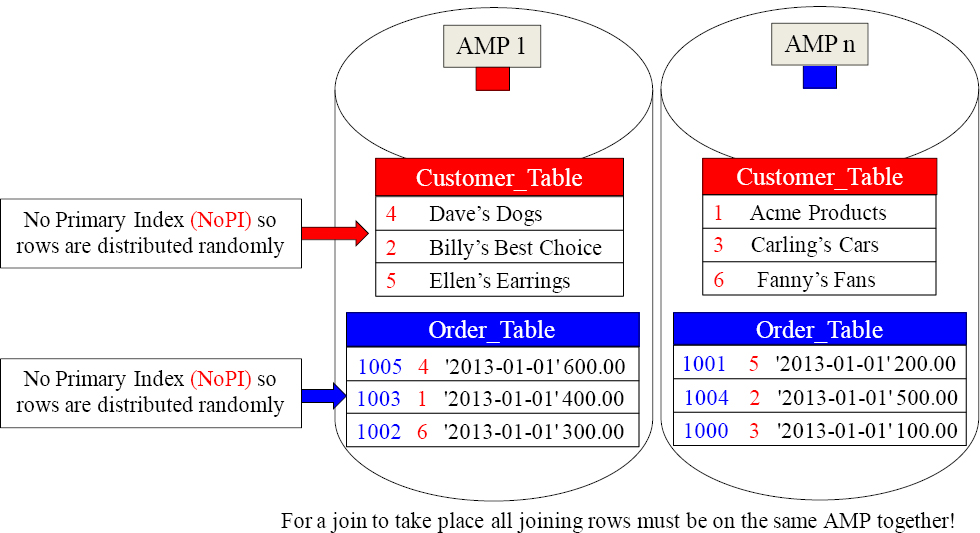
CustNo (1-6) (red) are the Join Condition (PK/FK). Each customer has placed one order. The matching join rows are on different AMPs because both tables are NoPI tables, so they are both distributed randomly but evenly. How will Teradata get the joining rows on the same AMP? They will redistribute both tables by Cust_No.
Both Tables are redistributed to Join Rows on the Same AMP
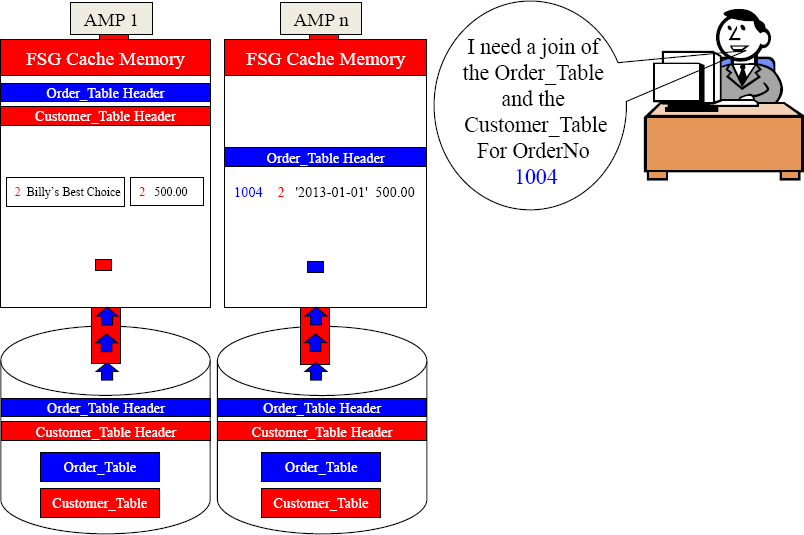
Parsing Engine
Only AMP n (Move you Order_Table block with OrderNo 1004 into FSG Cache).
Move that single row to the matching AMP by hashing the CustNo.
Now, Join the matching CustNo row now that they're in the same FSG Cache.
On all joins, the matching rows must be on the same AMP so hashing is how it is done.
How do you join if One Table is Big and One Table is small?
SELECT C.CustNo,
,C.CustName
,O.Order_Total
FROM Customer_Table as C
INNER JOIN Order_Table as O
ON C.CustNo = O.CustNo ;
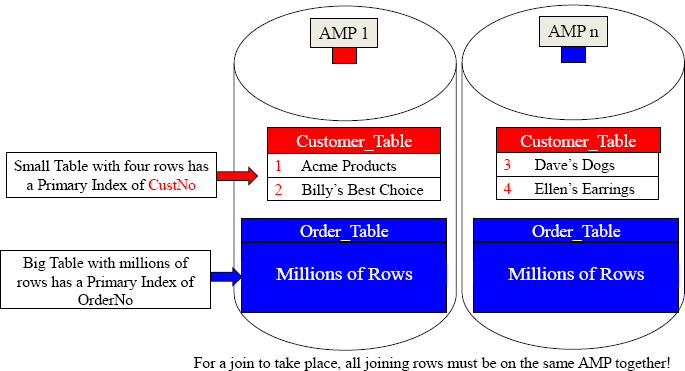
CustNo is the Join Condition (PK/FK) and the Customer_Table has CustNo as its Primary Index. The Order_Table has OrderNo as its Primary Index, but this table has millions of rows and the Customer_Table only has four rows. Teradata will NOT redistribute a big table, but instead duplicate the smaller table across all AMPs.
Duplicate the Small Table on Every AMP (like a mirror)
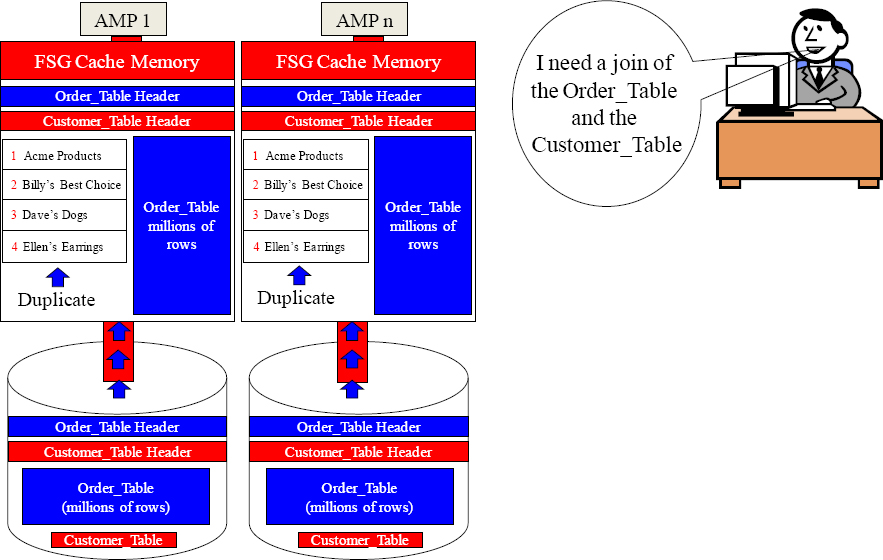
Parsing Engine
Move you Customer_Table and Order_Table blocks into FSG Cache.
Duplicate the smaller table in its entirety across every AMP in the system.
Now Join the matching CustNo rows now that they're in the same FSG Cache.
On a Big Table/Small Table join, the smaller table is duplicated on all AMPs.
What Could You Do If Two Tables Joined 1000 Times a Day?
CREATE Table Customer_Table
(
| CustNo | Integer |
| ,CustName | Char(20) |
)
Unique Primary Index (CustNo) ;
CREATE Table Order_Table
(
| OrderNo | Integer |
| ,CustNo | Integer |
| ,Order_Date | Date |
| ,Order_Total | Decimal (10,2) |
)
Primary Index (CustNo)
Give both tables the same Primary Index on the PK/FK join condition.
Each time these two tables are joined via the CustNo column, there will be no data movement because the matching CustNo rows will be on the same AMP. That is because CustNo is the Primary Index for both tables, so the matching rows are hashed and distributed to the same AMP. This is the beauty of the Hash Formula.
Joining Two Tables with the same PK/FK Primary Index
SELECT C.CustNo,
,C.CustName
,O.Order_Total
FROM Customer_Table as C
INNER JOIN Order_Table as O
ON C.CustNo = O.CustNo ;
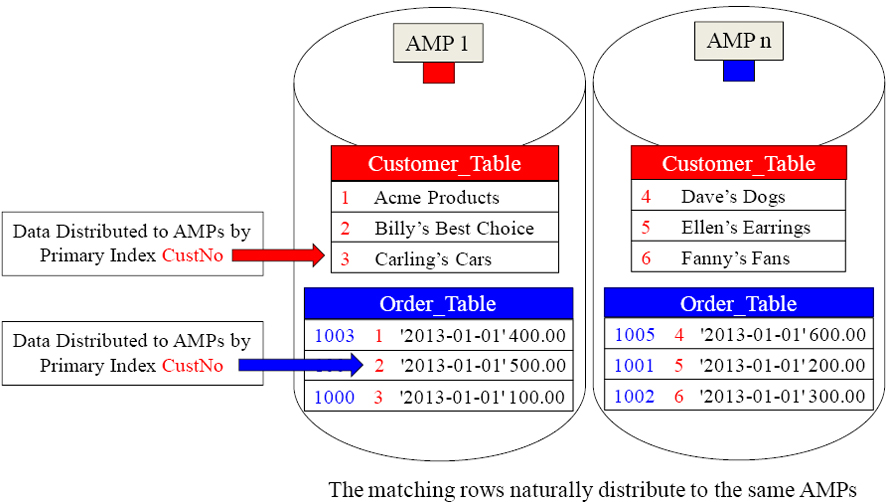
CustNo is the join condition (PK/FK), so the matching customer numbers are on the same AMP. They were hashed there originally. Each customer has placed one order. Teradata will have each AMP move their blocks into FSG Cache and perform a “Row Hash Match Scan”. Those key words in the Explain tell you the join is taking place.
A Join With No Redistribution or Duplication
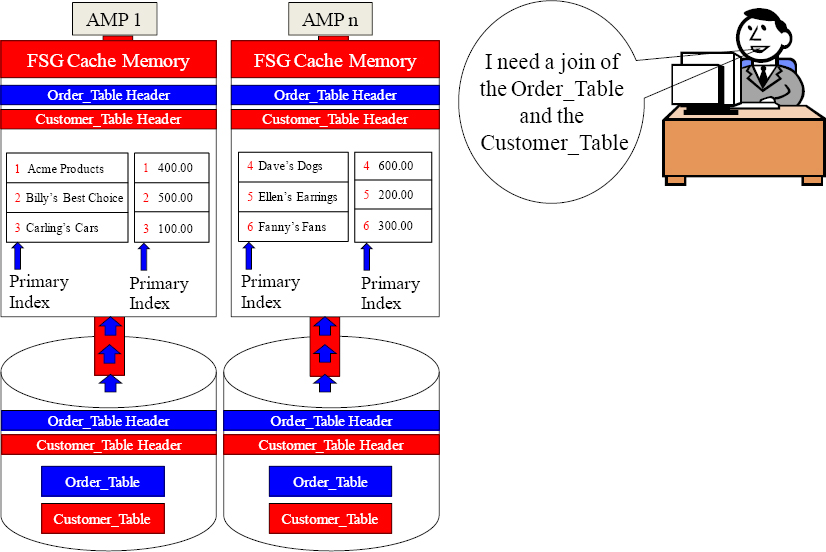
Parsing Engine
Move you Customer_Table and Order_Table blocks into FSG Cache.
Immediately perform a Row Hash Match Scan. The matches are lined up perfectly.
Both tables have the same Primary Index, and it is the join condition of CustNo. Perfect!
A Performance Tuning Technique for Large Joins
CREATE Table Customer_Table
(
| CustNo | Integer |
| ,CustName | Char(20) |
)
Unique Primary Index (CustNo) ;
CREATE Table Order_Table
(
| OrderNo | Integer |
| ,CustNo | Integer |
| ,Order_Date | Date |
| ,Order_Total | Decimal (10,2) |
)
Unique Primary Index (OrderNo)
The Primary Indexes are different and NOT both the PK/FK join condition.
SELECT C.CustNo,
,C.CustName
,O.Order_Total
FROM Customer_Table as C
INNER JOIN Order_Table as O
ON C.CustNo = O.CustNo
WHERE O.OrderNo = 1004 ;
SELECT C.CustNo,
,C.CustName
,O.Order_Total
FROM Customer_Table as C
Order_Table as O
WHERE C.CustNo = O.CustNo
AND O.OrderNo = 1004 ;
Add an additional WHERE or AND clause using the Primary Index (or a Unique Secondary Index) on one of the tables and Teradata will retrieve the row(s) first. Then, the join is done on only the matching row(s) thus saving enormous time and movement.
The Joining of Two Tables with an Additional WHERE Clause
SELECT C.CustNo,
,C.CustName
,O.Order_Total
FROM Customer_Table as C
INNER JOIN Order_Table as O
ON C.CustNo = O.CustNo
WHERE O.OrderNo = 1004 ;
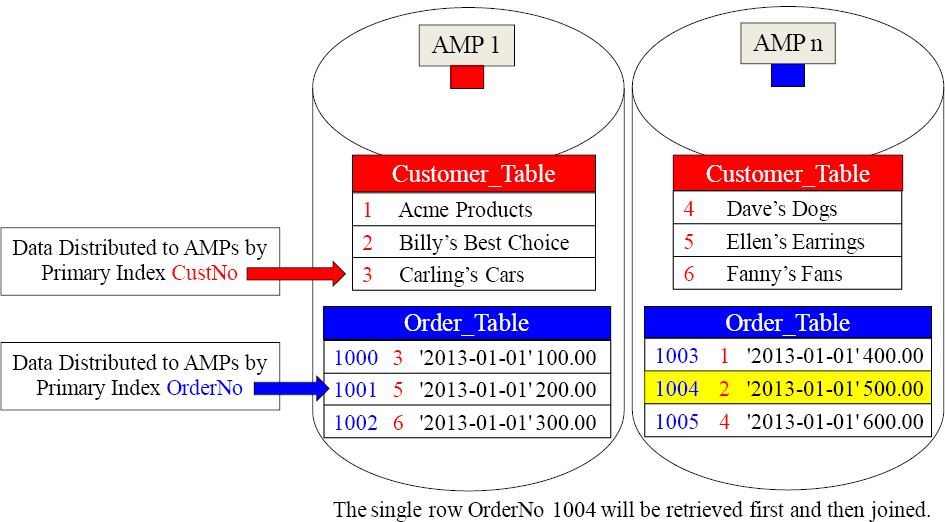
Notice the join SQL at the top left and notice the additional WHERE clause asking specifically for OrderNo 1004. Since OrderNo is the Primary Index of the Order_Table, Teradata will retrieve that row with a Single AMP retrieve. Then, it will join that single row with its matching row thus saving enormous time and energy.
An Example of the Fastest Join Possible
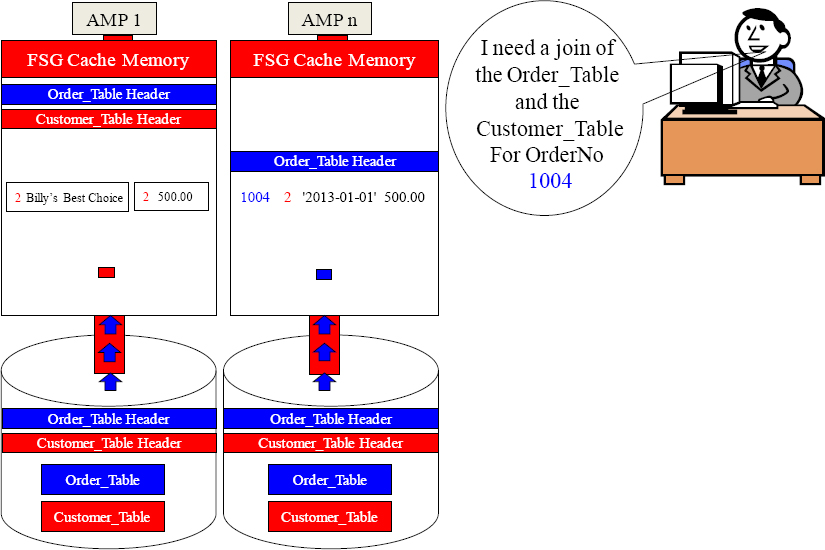
Parsing Engine
Only AMP n (Move you Order_Table block with OrderNo 1004 into FSG Cache).
Move that single row to the matching AMP by hashing the CustNo.
Now Join the matching CustNo row now that they're in the same FSG Cache.
On all joins, the matching rows must be on the same AMP so hashing is how it is done.
Using a Simple Volatile Table

CREATE Volatile TABLE Order_Volatile, NO LOG
| ( OrderNo | Integer NOT NULL |
| ,CustNo | Integer |
| ,Order_Date | Date |
| ,Order_Total | Decimal(10,2)) |
ON COMMIT PRESERVE ROWS ;

INSERT INTO Order_Volatile
SELECT OrderNo, CustNo,
Order_Date, Order_Total
FROM Order_Table
WHERE
extract(Month from Order_Date) = 9 ;
Many users (TEMP space required) can populate or materialize this table simultaneously with an Insert/Select statement, but a separate copy is made for each user for security purposes.

SELECT * FROM Order_Volatile
ORDER BY 1 ;
1) A USER Creates a Volatile Table and then 2) populates the Volatile Table with an INSERT/SELECT Statement, and then 3) Queries it until Logoff when all data is then automatically deleted. The next page will show you how to give it a Primary Index.
A Volatile Table with a Primary Index

INSERT INTO Order_Volatile
SELECT * FROM Order_Table
WHERE extract(Month from Order_Date) = 9;
SELECT C.*, Order_Date, Order_Total
FROM Customer_Table as C,
Order_Volatile as OV
Where C.CustNo = OV.CustNo ;
It is a great idea to give your Volatile Table a Primary Index so you can control how it is distributed and the best way you want to query it. In the above example, we knew we wanted to join this to another table so we made the Primary Index the join condition.
Using a Simple Global Temporary Table
CREATE Global Temporary TABLE Order_Global
| ( OrderNo | Integer NOT NULL |
| ,CustNo | Integer |
| ,Order_Date | Date |
| ,Order_Total | Decimal(10,2)) |
ON COMMIT PRESERVE ROWS ;
INSERT INTO Order_Global
SELECT OrderNo, CustNo,
Order_Date, Order_Total
FROM Order_Table
WHERE
extract(Month from Order_Date) = 9 ;
Many users (TEMP space required) can populate or materialize this table simultaneously with an Insert/Select statement, but a separate copy is made for each user for security purposes.
SELECT * FROM Order_Global
ORDER BY 1;
1) A USER Creates a Global Temporary Table and then 2) populates the Global Table with an INSERT/SELECT Statement, and then 3) Queries it until he/she logs off. All data is deleted when a user logs off, but the table definition stays forever unless dropped.
Two Brilliant Techniques for Global Temporary Tables

CREATE Global Temporary TABLE Order_Global
| ( OrderNo | Integer NOT NULL |
| ,CustNo | Integer |
| ,Order_Date | Date COMPRESS |
| ,Order_Total | Decimal(10,2)) COMPRESS |
| ) Primary Index (CustNo) | |
| ON COMMIT PRESERVE ROWS ; | |
Give your Global tables a Primary Index, and use the COMPRESS Keyword for any column that is Nullable and NOT the Primary Index.

INSERT INTO Order_Global
SELECT OrderNo, CustNo,
Order_Date, Order_Total
FROM Order_Table
WHERE
extract(Month from Order_Date) = 9 ;
Any user with Temp Space can materialize the table with an Insert/Select statement, and the data won't be deleted until they logoff.

SELECT * FROM Order_Global
ORDER BY 1;
The data is deleted when the user does logoff, but the table structure stays permanently.
Give your Global Temporary Tables a Primary Index and also compress any Nullable column. If a null is present, then Teradata will compress it and save space.
The Joining of Two Tables Using a Global Temporary Table
SELECT C.CustNo,
,C.CustName
,G.Order_Total
FROM Customer_Table as C
INNER JOIN Order_Global as G
ON C.CustNo = G.CustNo ;
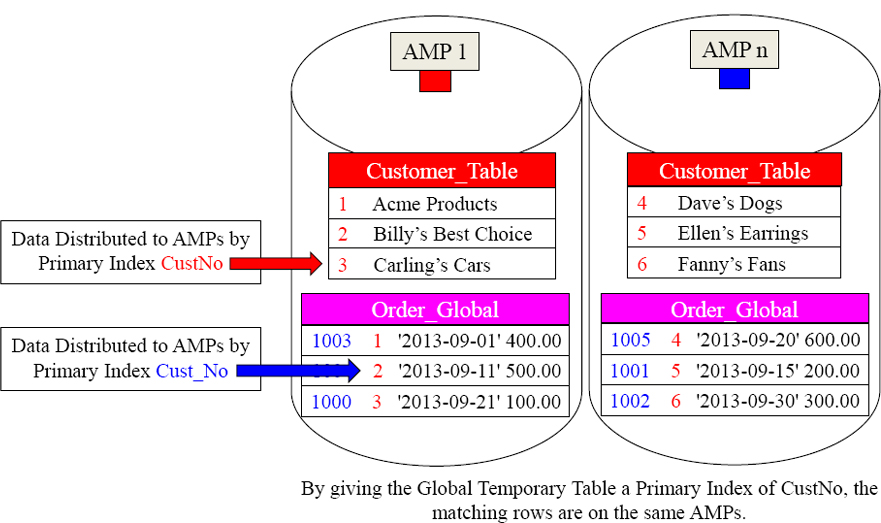
We gave our Global Temporary Table a great Primary Index fully knowing we were going to populate it with September orders, and then join it to the Customer_Table on the join condition of CustNo. Now, no data movement is required. Brilliant!
Quiz – How Much Data Moves Across the BYNET?
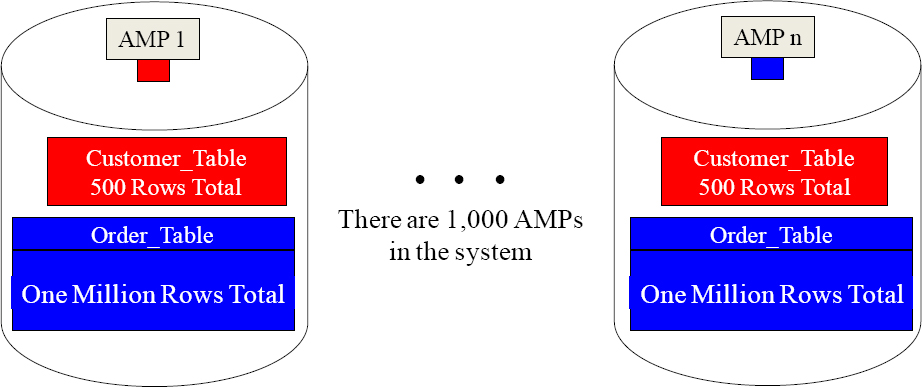
In a 1,000 AMP system, you are joining a large table with 1,000,000 rows to a smaller table that has 500 rows. The Parsing Engine must come up with a plan and it has two choices. It can either redistribute the larger table by hashing it by CustNo, or it can duplicate the smaller table across all AMPs. Here are your three questions:
How many rows will move if redistribution is done? ____________
How many rows will move if duplication is done? ____________
Which is the Parsing Engine most likely to do? _____________
Answer – How Much Data Moves Across the BYNET?
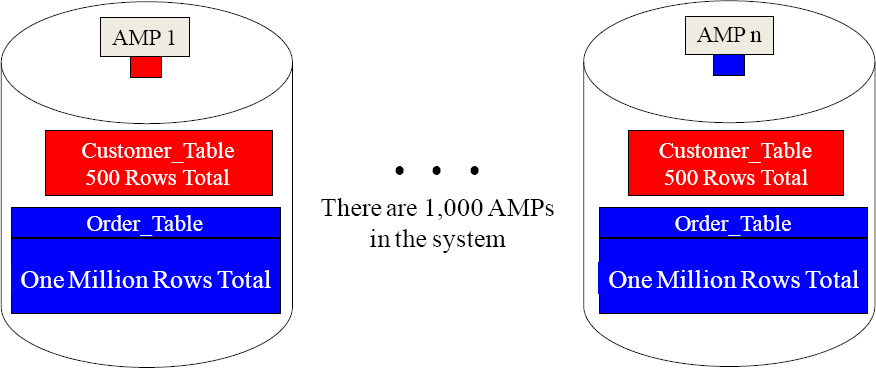
In a 1,000 AMP system, you are joining a large table with 1,000,000 rows to a smaller table that has 500 rows. The Parsing Engine must come up with a plan, and it has two choices. It can either redistribute the larger table by hashing it by CustNo, or it can duplicate the smaller table across all AMPs. Here are your three questions:
| How many rows will move if redistribution is done? | 1,000,000 rows |
| How many rows will move if duplication is done? | 500,000 rows |
| Which is the Parsing Engine most likely to do? | Duplication |