
Chapter 4. Practice 1: Automated Testing

Never do manually anything that can be automated.
Mistake-proofing is a fundamental Lean concept. It is a central part of producing a quality product and reducing waste (by eliminating rework). This is just as true in software development as it is in manufacturing. Automated testing is the primary means of mistake-proofing in software development.
Not coincidentally, automated testing is also a cornerstone of the Agile methodologies. Automated testing is so ubiquitous in the Agile world that it is just assumed that no one would even consider writing new code without automated tests. Although this is not quite as true with legacy code, even there the trend is toward increasing use of automated testing.
Automated testing is a pretty broad term. We are using it here as an umbrella term to refer to all kinds of testing: unit testing, integration testing, acceptance testing, executable specifications testing, performance testing, load testing, story testing, test-driven development, test-first development, behavior-driven development, etc.
Each of these different types of testing have a particular focus, but they all have the following in common:
The tests are created manually by developers
They can all be run automatically, without human intervention
They are run by some type of test harness
Test failures are detected automatically
The developer is notified when such failures occur
Automated testing supports three of the Lean software development principles described in Chapter 2:
Eliminate waste
Build quality in
Create knowledge
Automated testing helps eliminate the waste of rework that occurs when defects slip through to later phases of the software development lifecycle. Such escaped defects are particularly expensive (in time, money, and reputation) when they make it all the way to deployment.
Automated testing is a primary method for building in quality. A codebase with a full suite of automated tests is self-checking and self-validating. This helps reduce the likelihood that undetected errors will be introduced into the software.
Finally, automated tests serve as living documentation on how to actually use the APIs of the codebase. This creates firsthand knowledge that developers actually trust because it is guaranteed to be accurate every time the test suite successfully executes.
Why Test?
There are numerous benefits to automated testing, and we cover them throughout this chapter, but let’s start with the basics: productivity and quality. The quickest way to simultaneously increase your productivity and the quality of your software is by having a full suite of automated tests. This has been borne out through personal experience and independent studies, including a paper that Hakan Erdogmus presented at the Proceedings of the IEEE Transactions on Software Engineering (2005) titled, “On the Effectiveness of the Test-First Approach to Programming.”
When a project lacks a suite of automated tests, developers are very cautious about making changes or additions, especially if they are not very familiar with the code. This means that a lot of time is spent studying code that is going to be changed, and studying the use of that code throughout the entire codebase. Even then, developers may still feel like they’ve missed something important. This adds a lot of time to both the development of new features and the fixing of problems.
When your project has a suite of automated tests, it acts like a safety net for the developers. Rather than spending an inordinate amount of time studying and understanding the target code, the developer can simply implement the feature (or fix the problem) with a simpler understanding of just the immediate target code. She can safely do so because she knows that any unforeseen adverse consequences will be caught by the automated tests.
When you can confidently add to or modify the code without an excessive amount of research, you can save a substantial amount of time. In addition, since problems are immediately detected and corrected, you can eliminate expensive rework that would otherwise occur if the problems were detected at a much later phase in the project.
Finally, when a developer wants to know how a piece of code works, she will usually avoid any detailed documentation because experience has shown that such documentation is usually out-of-date and, therefore, wrong. This is why developers prefer to study the code itself. Tests effectively document how pieces of code should be used, and they can be proved to be correct and up-to-date simply by running them. Because of this, developers come to rely on tests as reliable, working documentation.
A typical excuse for not creating automated tests is that the deadlines are too tight and “we cannot spend extra time writing tests.” This is a myth and a classic example of shortsighted thinking. Yes, it does take time to write these tests, but this time is more than offset by the savings of eliminating rework, reducing the cost of debugging, and reducing the fear of changing the code. Automated tests actually help you meet your deadlines!
An unexpected benefit of automated testing is that it actually improves the design of the code being tested. There are two primary reasons for this. First, when you write tests against your API, any deficiencies in the design of that API become painfully obvious because you have just become a user of that API. If you are using test-first development, you write the tests even before writing the code. Since you are using your API before it is even implemented, it is very easy to simply change the API or design to address the deficiencies. If the tests are being written after the code, minor deficiencies are usually overlooked, but major deficiencies will still trigger a redesign.
Second, when you are creating automated tests as a part of your development process, you quickly learn to design the code in a manner that ensures that it is testable. Testable code encourages the same good attributes that design and architecture experts have been preaching for years: loose coupling, minimized dependencies, and encapsulation.
A recent trend in automated testing is to write requirements in the form of executable specification tests. New testing frameworks (RSpec, JBehave, NSpec, Spector, etc.) let you write tests that describe the desired system behavior in a manner that is readable by business stakeholders and by developers. The ability to execute these tests eliminates the disconnect between requirements and code. It also means that the verification of the code against the requirements is now trivial and completely automatic. The bottom line is another big jump in both productivity and first-time quality.
In summary, having a full set of automated tests is one of the most important things you can do, because tests:
Are bug-repellent
Help localize defects
Facilitate changes (act as a safety net)
Simplify integration
Improve code design (which also facilitates changes)
Document the actual behavior of the code
What Is Automated Testing?
First, let’s be absolutely clear about what automated testing is not: it is not running tests that are automatically created or generated by software that scans and analyzes your source code. We would call this automatic testing. While automatic testing may have its place (we have not yet been convinced that it offers any value), it is not the kind of testing we are talking about here. In automated testing, we are interested in checking the code’s correct behavior, something that a code analysis tool cannot do.
Automated testing provides you with the ability to execute a suite of tests at the push of a button (or via a single command). These tests are crafted manually, usually by the same developers who created the code being tested. Often the boilerplate code that represents the skeleton of a test (or set of tests) will be automatically generated, but never the actual test code itself.
The Test Harness and Test Suites
A test suite is a collection of related tests. The tests in a suite are executed, one at a time, by a piece of software known as a test harness. There are many freely available, open source test harnesses. The most widely used test harness is probably the xUnit series (JUnit, NUnit, cppUnit, httpUnit, etc.). A given test harness is usually specific to a particular programming language or environment.
As the test harness cycles through the tests it is running, it will typically do a number of other things as well. Before it runs each individual test, the test harness will call the test suite’s setup routine to initialize the environment in which the test will be run. Next, it runs the test, and the test harness stores information about the success or failure of the test (the test harness may also collect more information from the test describing the specifics of any failure). Finally, the test harness will call the suite’s teardown routine to clean up after the test.
The test harness will then report the results of all the tests back to the initiator of the test run. Sometimes this is simply a console log, but often the test harness is invoked by a GUI application that will display the results graphically.
In the GUI case, while the tests are running, you will usually see a green progress bar that grows toward 100% as each test is completed. This progress bar will stay green as long as all the tests are succeeding. However, as soon as a single test fails, the progress bar turns red and stays red as the remaining tests are run. Other parts of the display will tell the developer the details of the failures (how many, the names of the failed tests, etc.). When a GUI test runner is integrated with an IDE, failures are usually displayed as clickable links that will open the editor to the code line where the failure occurred.
Only very small codebases would have a single suite of tests. Typically, tests are organized into a collection of test suites where each suite contains a set of related tests. For example, for unit tests in an object-oriented language, you will usually create a separate test suite for every class (or group of closely related classes). Each test in a suite for a particular class would test a single method of that class.
Using behavior-driven development (BDD) as another example, each test suite would test a single feature of the application or system, with each individual test checking a single behavior of that feature.
Running Automated Tests
You can normally run automated tests in two different ways. First, developers can manually run a subset of the tests while coding. Second, the scripted build can run the full complement of tests automatically.
As developers write code, they will periodically run the subset of tests that check the part of the application in which they are working. This helps them ensure that they haven’t unexpectedly broken something. If a test fails, it is usually very easy to find the cause, since only a small amount of code has been changed since the same test ran successfully. Also, just before the developers check their changes into the source control repository, they usually run the full set of tests to make sure they haven’t broken something in other parts of the system.
If test-first development (TFD) is being used, the test for new or changed code is written before the implementing code. This means that, initially, the test will fail (because the change hasn’t yet been implemented), and the goal is to refine the application’s code until the test succeeds. There is more on TFD later in this chapter.
In any case, the script that builds the application will normally run the full set of tests automatically. This helps ensure that the application or system as a whole is relatively bug-free at all times.
When continuous integration is used (Chapter 5), the application is built on a regular basis—usually at least once a day, and often many times a day. For very large applications or systems, it can take a very long time to run the full set of automated tests. In this case, it is common to select a subset of tests to run as part of the daily or intraday builds, and to only run the full set of tests nightly or weekly.
Kinds of Tests
There are many different kinds of tests. In this section we present the common categories of tests. Keep in mind that the dividing line between these categories is not always sharp, and there can be overlap and gray areas.
Unit Tests
Unit tests are the most basic type of automated test. Unit tests are usually organized with an one-to-one correspondence to the physical organization of the code being tested. This is an easy-to-understand organization, so it’s not surprising that this is the most popular kind of automated testing. If you have never done any kind of automated testing, you should start with unit testing. Experienced testers, however, are starting to move to behavior testing instead of unit testing. So, if you are an adventurous novice tester, you might consider starting directly with behavior testing.
In an object-oriented language such as Java, C++, or C#, the units of code that are tested are the public methods within a class. Just as a class collects a group of related methods, a test suite for a given class will contain the unit tests for the methods within that class. There will usually be one test suite for every class.
Sometimes, when you have a small set of classes that work together intimately, you might instead have a single test suite for the group of classes. For example, if you had some kind of specialized collection class and a separate class for iterating over an instance of the collection, you would probably test both classes in a single test suite.
In functional languages such as C, Lisp, or Haskell, the units of code that are tested are the individual functions. The test suites would usually organize tests according to the natural organizational units of the target language (such as files or modules).
Examples 4-1, 4-2, and 4-3[1] show samples of unit tests in Java, C#, and C++, respectively.
//CalculatorTest.java
package test;
import static org.junit.Assert.*;
import org.junit.Test;
public class CalculatorTest {
private Calculator calc = new Calculator();
@Test
public void testAdd() {
assertSame(15, calc.add(10, 5));
}
@Test
public void testSubtract() {
assertSame(5, calc.subtract(10, 5));
}
@Test
public void testMultiply() {
assertSame(50, calc.multiply(10, 5));
}
@Test
public void testDivide() {
assertSame(2, calc.divide(10, 5));
}
}namespace account
{
using NUnit.Framework;
[TestFixture]
public class AccountTest
{
[Test]
public void TransferFunds()
{
Account source = new Account();
source.Deposit(200.00F);
Account destination = new Account();
destination.Deposit(150.00F);
source.TransferFunds(destination, 100.00F);
Assert.AreEqual(250.00F, destination.Balance);
Assert.AreEqual(100.00F, source.Balance);
}
}
}void
MoneyTest::testConstructor()
{
// Set up
const std::string currencyFF( "FF" );
const double longNumber = 1234.5678;
// Process
Money money( longNumber, currencyFF );
// Check
CPPUNIT_ASSERT_EQUAL( longNumber, money.getAmount() );
CPPUNIT_ASSERT_EQUAL( currencyFF, money.getCurrency() );
}
void
MoneyTest::testEqual()
{
// Set up
const Money money123FF( 123, "FF" );
const Money money123USD( 123, "USD" );
const Money money12FF( 12, "FF" );
const Money money12USD( 12, "USD" );
// Process & Check
CPPUNIT_ASSERT( money123FF == money123FF );
CPPUNIT_ASSERT( money12FF != money123FF );
CPPUNIT_ASSERT( money123USD != money123FF );
CPPUNIT_ASSERT( money12USD != money123FF );
}
void
MoneyTest::testAdd()
{
// Set up
const Money money12FF( 12, "FF" );
const Money expectedMoney( 135, "FF" );
// Process
Money money( 123, "FF" );
money += money12FF;
// Check
CPPUNIT_ASSERT( expectedMoney == money );
CPPUNIT_ASSERT( &money == &(money += money12FF) );
}Mocks and Stubs
Ideally, a unit test should test a single unit of code in isolation, not invoking any other code unit. In practice, this is one of the biggest challenges of automated testing. Code A calls code B, which, in turn, calls code C. So, how do you test only code A?
The primary techniques used are mocks and stubs. A stub is a piece of code that does nothing but substitute for another piece of code that you don’t want called. So, if code A calls code B, you can test code A in isolation by substituting a stub for code B. The stub will usually return a hardcoded value that is suitable for testing code A.
This implies that there is a way to perform this stub substitution at runtime (or at least at link time). Writing code in a way that makes this possible is what we mean when we say that you should create code that is testable. One technique is proving to be very versatile and is growing in popularity: Dependency Injection (DI), also known as Inversion of Control. DI is useful for much more than automated testing, but here we will restrict ourselves to the testing aspects.
In a traditionally written piece of code, say code A, other pieces of code that it calls (its dependencies) will be hardcoded. In other words, code A directly calls code B, code C, etc. With DI, these calls are not hardcoded. Instead, they are called through a variable or some other lookup mechanism, allowing you to switch the actual destination of the call at runtime—in our case, to a stub.
A mock is really just a more complicated set of stubs. A stub is really dumb, typically just containing a hardcoded return value. A mock is designed to substitute for a larger subsystem. As such, it pretends to be an instance of a subsystem, returning a coordinated set of values to emulate the subsystem it is replacing. A mock will usually consist of multiple stub-like functions that contain some minimal logic.
For example, you might have a mock that is designed to stand in place of a database. This mock database might read and return a set of canned responses from a text file.
There are also prewritten mocks ready to use. For example, the Java-based Spring framework includes several prewritten mocks, including one that stands in for the Java Naming and Directory Interface (JNDI) service.
Integration Tests
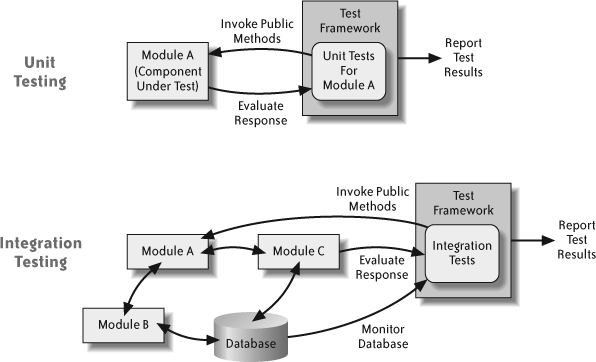
Where unit tests are designed to test individual units of code (in as much isolation as possible), integration tests allow you to determine how these code units work together. Sometimes this just means removing the mocks and stubs and letting the code call its real dependencies. It might also mean writing new tests that are specifically designed to test the interfaces between classes or modules. Figure 4-1 illustrates the basic differences between integration and unit testing.
Behavior Tests
Behavior testing is a recent development on the testing scene. Still, most of the leading advocates of automated testing are moving to behavior testing, lending it a great deal of advance credibility. Behavior testing is both a different perspective on testing and a new set of test harness tools to directly express this new perspective.
Behavior testing doesn’t take into account the physical organization of the code or things such as classes and modules. Instead, behavior testing focuses on the individual features of the application or system and the behaviors that the application must exhibit to implement the feature. It is these behaviors that are tested.
This is best illustrated by Examples 4-4 and 4-5, which contain sample behavior tests for Ruby and Java, respectively.
Story: transfer from savings to checking account
As a savings account holder
I want to transfer money from my savings account
to my checking account
So that I can get cash easily from an ATM
Scenario: savings account has sufficient funds
Given my savings account balance is $100
And my checking account balance is $10
When I transfer $20 from savings to checking
Then my savings account balance should be $80
And my checking account balance should be $30
Scenario: savings account has insufficient funds
Given my savings account balance is $50
And my checking account balance is $10
When I transfer $60 from savings to checking
Then my savings account balance should be $50
And my checking account balance should be $10/** set balance = 50 */
public class AccountIsInCredit extends GivenUsingMiniMock {
public void setUp(World world) {
Mock account = (Mock) world.get("account",
mock(Account.class));
account.stubs("getBalance")
.withNoArguments()
.will(returnValue(50));
}
}
. . .
public class HappyScenario extends MultiStepScenario {
public void specifySteps() {
given(new AccountIsInCredit());
when(new UserRequestsCash());
then(new ATMShouldDispenseCash());
then(new ATMShouldReturnBankCardToCustomer());
then(new AccountBalanceShouldBeReduced());
}
}
public class OverdrawnWithoutPermission extends MultiStepScenario {
public void specifySteps() {
given(new HappyScenarioWithOverdraft());
given(new AccountHasNegativeBalanceWithoutPermission());
when(new UserRequestsCash());
then(new ATMShouldRefuseCash());
then(new ATMShouldReturnBankCardToCustomer());
}
}Notice that the Ruby example reads like normal English. The Ruby programming language excels at creating domain-specific languages (DSLs) such as what you see in Example 4-4. Rest assured that this is really executable Ruby code.
Testing behaviors is closely related to the subject of the next section: executable specifications.
Executable Specifications
Another recent trend in automated tests has been the use of executable tests as specifications or requirements. These executable specifications often double as acceptance tests—when the project is completed, all of these tests should pass.
The idea of executable requirements has been developed from two separate camps. The first is Framework for Integrated Test (FIT), which uses tables on wiki pages to specify tests that are to be run by the FIT test harness. The second is a natural extension of behavior testing to a higher level of behavior that expresses the requirements of the system.
Both of these approaches to executable specifications share the same attributes: they are readable and understandable to both the business stakeholders and the software developers, and they are executable as tests by the computer.
Nonfunctional Testing
There are a number of areas in which an application or system must be tested that are not related to its functions. Here are a few of them:
Performance testing
Load testing
Security (vulnerability) testing
Compatibility testing
Usability testing
These types of testing are much more difficult to automate than the types of testing we have presented so far. In fact, it may be impossible to satisfactorily automate some of them (how would you automate usability testing?).
Because of this, these types of testing have remained largely manual. Tools are available to assist with performance and load testing, but it is rare for them to be fully automated.
User Interface Testing
Testing a user interface, whether it is a desktop UI or the browser interface in a web application, is another testing area that has been difficult to automate. Tools are available to help automate the testing of a user interface, but they tend to be specific to a particular environment and are difficult to create and maintain.
One potential bright spot is browser-based web applications. Since the environment and technologies that underlie web applications are based on standards, it should be possible to build fairly generic tools to automate testing of the user interface. One such tool, Selenium, is written in JavaScript and runs in the browser. Selenium lets you write automated tests that can simulate the actions of a user and check for the correct responses from the application. Over time you can expect to see more tools like this.
Since it is difficult to automate user interface testing, a traditional alternative strategy is to divide the user interface code into two parts. The bulk of the code implements the “business logic” of the user interface, with a thin GUI rendering layer on top. Automated tests are then directed at the business layer.
That traditional workaround has been rendered largely obsolete by the increasing use of the Model-View-Controller (MVC) architecture. The MVC architecture produces the same separation of business logic and GUI rendering by its very nature. In an MVC architecture, the automated tests are written to test the model and controller parts.
Approaches to Testing
No matter which approach you take to testing, the most important thing is to actually have a set of automated tests and to strive for a level of coverage that gives you benefits that will far outweigh the costs.
It is unrealistic, and probably not worth the cost, to achieve 100% test coverage of your source code. For new code and projects that are new to automated testing, 60 to 80% code coverage for your tests is a reasonable target, although seasoned testers will strive for 80 to 95% coverage. There are tools that will examine your source code and tests, and then tell you what your test coverage is (for example, Emma and Cobertura for Java, and NCover for .NET).
Legacy code is a different story. We have more to say about legacy code later in this chapter. For now, suffice it to say that legacy code will almost certainly start with 0% test coverage. The strategy with legacy code is to get a test harness in place, and then incrementally add tests over time—creating tests for any code that you change or enhance. This low-overhead approach will increase coverage over time and will also increase the quality and malleability of the legacy codebase.
Using Setup and Teardown
The cardinal rule of automated testing is that each individual test must be independent of any other test. Stated another way, no test can depend on the results of a previous test. If you adhere to these rules, tests can be run in any order, and any individual test can be run by itself.
Every test suite has its own setup and teardown function. The setup function’s job is to initialize the test environment for the suite’s tests. This includes preparing any data (data files, in-memory data, database tables, etc.) so that it is in a known, pristine state. The setup function also initializes any required libraries, subsystems, or services (for unit tests, this can be kept to a minimum by using mocks and stubs).
It is important to know that the test suite’s setup is called multiple times, once before each test in the suite. This ensures a pristine test environment at the start of each test. Correspondingly, the teardown function is called after each test in the suite to clean up and release any resources allocated or initialized by setup.
Testing with Databases
Unit testing a database-driven application is often a sticking point for novice testers, and the standard canned advice is not very helpful. The traditional answer is to create a mock for your database that lets you run your tests without a database. This only works for very simple schemas and very simple tests.
In the vast majority of cases, the database schema and application are too complicated to create a mock at a reasonable cost. This means that an alternative approach must be used. Keep in mind, however, that no matter what approach is taken, the data environment must be initialized to a known state before each test.
A common architectural approach is to design the application with a data abstraction layer (DAL) that isolates the application from the fact that a database is being used. The application calls the DAL for the logical data it wants, and the DAL queries the database to get the data. This makes it easy to create alternative DALs that go elsewhere for the data (like local files) or return a canned response (in the case of a mock).
If a DAL is not feasible, you might have to use a real database in your testing. This means that you need a test database and a test set of data that you can load into the database before each test. Of course, you’ll want to do this as efficiently as possible so that your tests run quickly. If your database supports nested transactions, you can load the test data into the database once, start a new transaction before each test, and then do a rollback after each test finishes.
There are tools that can help you test with a database (for example, the open source tool DbUnit).
Test-Driven Development
In TDD, you create the tests for each feature of an application before you develop the feature itself. Initially, the tests will fail because the code implementing the feature has not yet been written. You then proceed to implement the feature. You will know when you are done because the failing tests will pass.
Technically, you should always write the test first, before implementing the code. However, many projects are lenient on this rule, and the tests are often written after the feature has been implemented. This is particularly true when the implementation was the result of some exploratory programming.
Purists who want to make absolutely clear that they always write their tests first may say that they practice test-first development (TFD). That said, there are also some benefits to writing tests first that can make it worth striving for.
By writing tests first, you actually view the feature’s API through the eyes of the user of that API. More importantly, you do so before that API has been physically created. This means that you will discover problems with the usability of the API while it is easiest to change. The result is usually a significantly better internal design.
Red, Green, Refactor
The phrase “Red, Green, Refactor” is heard often in Agile and Lean development circles. It summarizes the endless repetition of the iterative work cycle of TDD until the project is finished:
- Red
This refers to the state where you have written the test for a new feature, but you haven’t yet written the implementing code. When you run the tests, they will fail, and a GUI test runner would show a “red” status.
- Green
You’ve written just enough code to get the tests to pass. At this point, a GUI test runner would show a “green” status.
- Refactor
You designed the code to get the feature working as quickly as possible, but it may not be the best code. In this step you refactor the code to improve its structure.
Refactoring is an essential step for maintaining a high-quality codebase. To refactor means to change the code’s internal structure and implementation without changing its external behavior. You can find entire books on the subject of refactoring. See Appendix A for a list of recommended resources.
Legacy Code
The traditional wisdom is that a legacy codebase slowly deteriorates over time. Changes and feature additions become increasingly costly and time-consuming to implement (you touch one thing, and 10 other things break!). Eventually, the codebase becomes so fragile that no one wants to touch it, so you consider only changes that are absolutely essential. The next time the code requires a major change, you tell management that it would be cheaper to throw it away and start over again from scratch.
It doesn’t have to be that way. Instead of slowly rotting away, a legacy codebase can instead be steadily and incrementally improved so that it gets better over time. Better means easier, safer, and less costly to change. The vehicle of this miracle is (drumroll, please...) automated tests!
Michael Feathers wrote the book (literally) on how to get a legacy codebase under test. His book, Working Effectively with Legacy Code (Prentice Hall, 2004), is a must-read for anyone who works with legacy code (at one time or another, this applies to all of us). Feathers has a very simple definition of legacy code: “Legacy code is any code for which automated tests do not exist.”
He goes to great lengths to justify this definition. If we accept it, then many of the developers reading this book probably wrote some legacy code just yesterday!
It is not easy to retrofit tests onto a legacy codebase. First, you can’t just stop all other work and undertake a massive effort to add tests across an entire codebase. (Even if you could convince management to fund it, this kind of boring drudge work would be doomed to failure.) However, you can take an incremental approach where you add tests to any area of the code that you change. Even so, you will likely encounter many other problems trying to test code that was not designed to be testable.
This is where Feathers’s book becomes essential reading. It is basically an encyclopedia of the problems you will run into while retrofitting tests onto legacy code, and it includes a series of techniques for dealing with each type of problem.
Behavior-Driven Development
BDD is at the current cutting edge of the automated testing field. As such, fewer tools, frameworks, and other resources are available. At the same time, BDD promises some of the greatest benefits of any automated testing technique. Even if you can’t currently practice BDD, it is a field worth keeping up with.
BDD takes the behavior testing that we presented earlier and makes it the driving force behind design and implementation. In BDD, you write the requirements for a feature as one or more behavior tests, before any detailed design or implementation.
Since behavior tests are readable by the business stakeholders, they can be considered to be the official product requirements. The business stakeholders can sign off on them (and approve subsequent changes). Because computers can run them, they become executable specifications. Finally, once the system has been implemented, they also become executable acceptance tests.
Summary
We believe that automated testing is the most important and beneficial practice that you can adopt. When you use automated testing conscientiously, the increase in your productivity and the quality of the resulting software cannot be matched by any other single practice.
[1] Most of the code examples in this chapter have been excerpted (with permission) from the documentation of each test framework.