
Chapter 5. Practice 2: Continuous Integration

Integration isn’t easy. It can be painful, aggravating, and even depressing. It’s the hill you have to climb at the end of the race to reach the finish line. Why would you want to do it continuously? Isn’t one thrashing enough?
Integration is where the whole development effort comes together. Individual components, databases, user interfaces, and system resources are all tied together and tested via the underlying architecture. Integration involves verifying that components communicate properly via public interfaces, ensuring that data formats and message contents are compatible and complete, and making sure that timing and resource constraints are obeyed. Traditional development processes treat integration as a separate phase occurring after all the pieces have been implemented, and it is typically a laborious, time-consuming process involving a lot of debugging and rework. Continuous integration, or CI, turns the traditional integration phase into an ongoing activity that occurs during the implementation of the system.
CI is not simply an integration phase spread out over the entire development cycle—at least, not the traditional integration phase you’re probably used to. Continuous integration is the process of integrating small changes on a continual basis in order to eliminate a separate integration phase prior to product release. By integrating small changes at short intervals, developers can grow the product a little bit at a time while ensuring that each new piece works with the rest of the system.
Essentially, CI is a practice wherein developers integrate small changes by checking in updates to a source code management (SCM) system and building the system to ensure that nothing has been broken. A CI implementation can be as simple as building and testing all the source code or as complex as creating a fully tested, inspected, and deployable release.
CI is closely associated with the idea of completely automated builds, which create deployable products from source code in an SCM repository. CI extends the idea by performing an automated build (including testing and reporting of results) each time the codebase changes. What separates CI from automated builds is how the process is initiated. Automated builds are typically started on command by a developer or at a specific time of day; in a CI implementation, the build process starts automatically anytime a developer checks in changes to the SCM repository.
Continuous integration has several prerequisites:
- Source code management
We covered SCM in Practice 0, so you should backtrack to Chapter 3 if you don’t already have it in place.
- Unit testing framework
Automated unit testing is an integral part of any useful CI implementation, so a unit testing framework and a robust set of unit tests is necessary to fully implement CI. Unit testing was covered in Practice 1, so backtrack to Chapter 4 to see how unit testing is implemented.
- An end-to-end automated build
An end-to-end automated build uses a script to control the building of the product from source code to releasable software.
- A dedicated build server
You can perform CI without a machine dedicated to building software, but it is most effective with a dedicated build server. A dedicated build server helps eliminate problems arising from configuration changes caused by other activities.
- Continuous integration software
Continuous integration software must do three things: detect changes in the SCM repository, invoke the scripts that build the product, and report the results of the build. The development team can write custom CI software, but it is more common to use a third-party application.
In the following sections, we’ll look at the prerequisites for implementing CI and then discuss how to approach an initial implementation.
End-to-End Automated Builds
An end-to-end automated build creates a complete software product from the raw source code by invoking all required actions automatically and without intervention on the part of a developer. Implemented via build scripts (see Chapter 3), end-to-end automated builds used within a CI process (called CI builds) are characterized by three features:
CI builds start from scratch
CI builds are end-to-end processes
CI builds report results automatically
Building from Scratch
CI builds start by retrieving a fresh copy of the latest source code from the SCM repository. Scripted builds used for other purposes may build only those modules that have changed, but CI builds always start from scratch. Rebuilding everything eliminates the possibility of dependency changes sneaking in undetected.
Having used the word “always,” we now have to point out the exceptions to the rule. When using CI in large, complex systems, you may have to break the build into smaller pieces to reduce the amount of time required. Breaking down the build based on module relationships and dependencies ensures that your team builds and tests all code affected by a change.
For example, consider a financial system that contains modules for managing user account information and tracking the stock market, as in Figure 5-1. The two modules interact with a database that drives the system’s user interface. A system this small probably doesn’t warrant breaking the build into pieces, but it is useful for demonstrating how to apply CI to large, complex systems effectively.
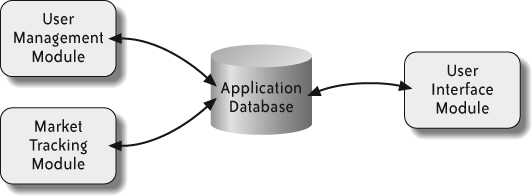
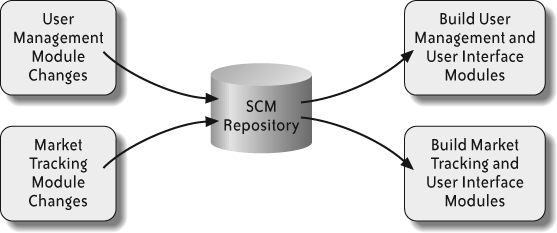
To break the build into smaller pieces, start by looking for independent modules. The user management and market tracking modules are completely decoupled, so they are candidates for separate builds. Changes to the user management module don’t affect the market tracking module. Likewise, changes to the market tracking module don’t affect the user management module. The decoupled modules may be built separately; however, both modules may indirectly affect the user interface via the database, so you should build (and test) the user interface module as part of both builds, as in Figure 5-2.
End-to-End Builds
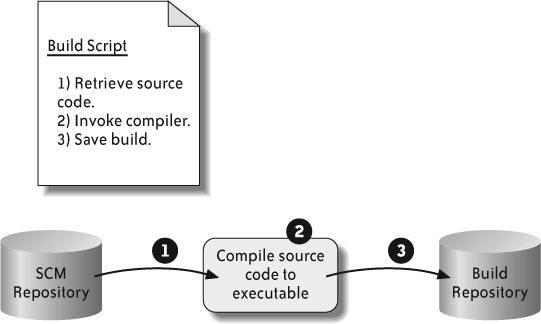
CI builds are end-to-end processes. End-to-end builds start from source code and include all the actions necessary to create the final software product. The definitions of “all the actions necessary” and “final software product” are arbitrary, and different development teams may apply different meanings to each. For example, the simplest end-to-end build consists of nothing more than compiling source code into an executable file, as shown in Figure 5-3.
While a simple end-to-end build implements a repeatable process for creating executables, it doesn’t incorporate all the steps typically performed prior to releasing a software product. CI builds are often more complex and may include:
Unit and integration testing
Database initialization
Code coverage analysis
Coding standards inspections
Performance and load testing
Documentation generation
Packaging of executables into deployable products
Automatic deployment of products
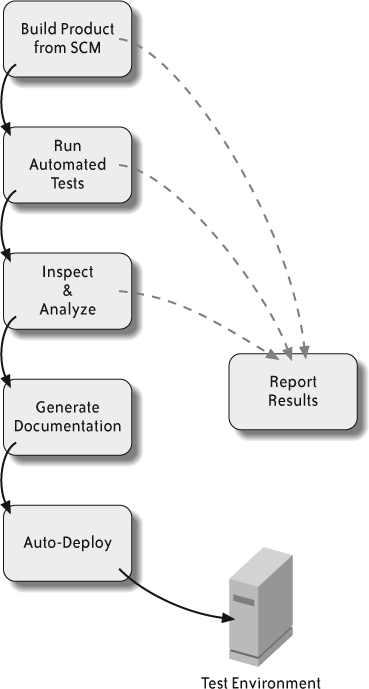
Figure 5-4 shows a typical end-to-end build used in a CI process, including automatic deployment of the product. Be aware that automatic deployment is a tricky proposition. Updating a product while it is being tested or used can cause confusion and can result in decreased productivity, lost data, and a lack of confidence in the product.
Builds resulting in deployable software packages are sometimes referred to as push button builds because a single command creates the entire product from scratch. Builds that are started automatically at preset times are called scheduled builds.
Reporting Results
CI builds employ automated reporting mechanisms to ensure that developers, managers, and possibly even customers always know the state of the build. Report content depends on the complexity of the build; simple builds may report compiler errors, whereas more complex builds may include error messages, unit and integration test results, code coverage statistics, adherence to standards, and statistics generated by performance testing.
An important part of the process is getting reports to developers quickly. Broken builds disrupt the normal flow of development because developers working on other parts of the system can’t use the latest version of source code from SCM. The sooner the developers who are responsible for the bad code know the build is broken, the sooner they can fix it and restore the flow.
Results can be reported in a number of different ways. Some of the more common methods are:
- Email notifications
Build failures generate email notifications to the development team, alerting everyone that the build is broken and needs attention. The first build to pass after a failure also generates an email notification, giving the “all clear” signal.
- RSS feeds
Really Simple Syndication (RSS) feeds are handy ways to display the build status continually. Feeds can be viewed via a generic RSS reader or a custom application, allowing developers to see the current build status at a glance.
- Web pages
Web pages are another handy way to continually display build status. Many of the software packages used to implement CI include a web application that tracks and displays the status automatically, allowing anyone to see the status simply by viewing a web page.
- Physical indicators
Physical indicators, such as red and green lights, can be used to indicate build status. Although they don’t provide details, physical indicators do display the current status in an easily interpreted way.
Dedicated Build Servers
Many CI gurus insist on using a dedicated machine for performing builds. Often referred to as build servers, these machines provide a number of benefits, but they also have some drawbacks. Whether you implement CI with or without a dedicated build server depends on your situation.
Dedicated Build Servers Isolate Build Activities
Using a dedicated build server prevents interference from other activities. Other activities may slow down or even halt a build due to limited resources or access issues.
The primary function of a build server is to build and test the project. Build servers doing double duty, such as hosting the test database for a web application or hosting the web server itself, will require more time to build the software. Small projects with few developers may be able to utilize a less powerful machine or allow the machine to perform other tasks without sacrificing build speed. However, large projects with many developers and frequent code check-ins will benefit from having a powerful, dedicated build server.
Dedicated Build Servers Provide a Well-Known Build Environment Configuration
Dedicated build servers allow you to build and test the product in a well-known environment. Users performing other tasks on a shared build server may load different versions of libraries and supporting software or make changes to the runtime or test environment resulting in build failures.
Build servers should not be used for prototyping, experimenting with new technologies, or evaluating new software packages. Each of these activities can introduce new versions of libraries and make system-level configuration changes that are incompatible with the build environment.
Dedicated Build Servers Require Extra Hardware
One drawback of using a dedicated build server is the expense of obtaining an additional computer, one that will not be used by developers for writing code. In addition, you may require a fairly powerful machine to deal with large, complex builds.
Setting up a dedicated build server requires an initial investment, but the payoff is well worth the expense. One of the main drivers behind CI is immediate feedback, so the more powerful the machine, the better. Faster builds mean faster feedback to developers. If at all possible, consider using a powerful, dedicated build server to implement CI.
Continuous Integration Software
CI software applications, also known as CI servers, must do three things to control the CI process: detect changes in the SCM repository, invoke build scripts, and report results.
CI Servers Detect Changes in the SCM Repository
Because CI is based on rebuilding the system whenever the codebase changes, it requires the capability to detect such changes automatically. CI servers typically include the capability to interface with a wide variety of SCM systems, allowing them to monitor the repository and take action when the codebase changes, or to defer action when no changes are detected.
CI Servers Invoke Build Scripts
Once a CI server has detected a change in the codebase, it starts an automated build process by invoking a build script. Typically, CI servers incorporate a mechanism to ensure that all pending changes to the SCM repository are completed before invoking the build script. Once it has started the build script, the CI server monitors the process and waits for it to finish.
CI Servers Report Build Results
The final responsibility of a CI server is to report the build results to the development team and anyone else who needs to know the build status. CI servers commonly provide error notification via email and web-based access to the latest build results.
CI Servers Can Schedule Builds
A strict interpretation of CI does not include scheduled builds, but such builds can be useful in managing large, complex products. Using a combination of builds triggered by code changes and scheduled builds, developers can create a system that performs fast-running unit and integration tests for all code changes and longer tests in the background. Most CI servers allow you to schedule builds for a particular time of day—a nightly build, for example—or on a periodic basis.
Implementing Continuous Integration
As we mentioned at the beginning of the chapter, CI is the process of continually integrating small code changes into a software product. Each time the codebase changes (i.e., changes are checked into the SCM repository), the system is built and tested. Developers are notified immediately of any errors caused by the changes, allowing them to make corrections quickly. CI can be thought of as an extension of automated builds in that it performs an automated build (including testing, reporting, and other actions) each time the codebase changes.
So, you’ve decided to implement CI on your project. What do you do first? Start with the first three prerequisites noted at the beginning of the chapter. If you’ve been following this book’s recommendations about the order in which to implement practices, you should already have two of the three completed (SCM and automated testing). If not, refer to the appropriate practices in the preceding chapters. These prerequisites are:
Establish an SCM repository for all source code, scripts, test data, etc. Just about any modern SCM system will do, although several have gained wide acceptance in the industry.
Identify a build server. Ensure that the server has access to the SCM repository.
Identify the unit testing framework(s) necessary to support unit testing the project. Load the framework software onto the build server.
If you’ve already implemented automated builds using a build scripting language, you’re done with the next step. If not, work through the following list to establish an automated build script for your project:
Choose a build scripting language that supports the SCM software and unit testing framework you’ll be using.
Load the scripting software onto the build server.
Create a simple build script that retrieves all source code from the SCM repository.
Add a compile task to the build script for each module in the project.
Add the build script to the SCM repository!
One way to create the compile task for each module is to copy the script that has been created for the module by an integrated development environment (IDE), such as Eclipse or Microsoft Visual Studio. A parent script can pull the individual scripts together and invoke them in order to perform the complete build. In many cases, you can use IDEs in a command-line mode, allowing the CI process to invoke the IDE to perform the build directly.
With a build script for each module in place, it’s time to create the CI process itself. Here we assume you’ll be using one of the available CI servers:
Select a CI server with the features and compatibilities you need (SCM, build scripting language, and unit test framework).
Load the CI server software onto the build machine.
Configure the CI server to monitor the project’s SCM repository and to execute the master build script when changes are detected.
Start the CI server.
Virtually all CI servers have the ability to monitor the repository for changes, so once started, the CI server should initiate a build whenever any changes are made to the SCM repository.
Now that the CI server is building the project, we need to report the results. The next step is to add a reporting mechanism to the CI process. Results are typically reported by adding tasks to the build script. The tasks may generate XML data in a particular format for display in a web application, generate emails to developers when something fails, set the state of a visual indicator, or update an RSS feed. Select the desired reporting mechanism and add it as appropriate for the CI server in use.
The CI process is now on the verge of doing something useful. All that’s left is to add unit testing and report the results. As with reporting mechanisms, unit testing is typically invoked from within the build script. Modifying the build script to invoke all existing unit tests makes it easier to add modules (as well as unit tests for legacy code) later. New unit tests will be picked up automatically as they are added to the SCM repository.
At this point, the project has a working, useful CI process that will build the project when changes are detected in the repository and will notify developers if the build or unit tests fail. You can enhance the CI process to include other tasks such as code analysis, load testing, documentation, and deployment by adding the appropriate task to the build script.
Developers and the CI Process
An effective CI process requires more than a collection of tools and scripts; it requires acceptance by the development team members. CI works by integrating small pieces of functionality at regular intervals. Developers must adhere to a few rules to make the CI process effective:
- Frequent check-ins
Developers should check code into the SCM repository at least once a day, preferably several times a day. The longer modified code remains checked out, the more likely it is to get out of sync with the rest of the project, leading to problems integrating the code when it is finally checked in.
- Only check in functional code
Although code should be checked in often, it should not be checked in if it is not yet functional, doesn’t compile, or fails unit tests. Developers must build the updated project locally and run the applicable unit tests before checking code into the repository.
- The highest priority task is fixing build failures
When a failure is detected in the build, fixing the failure becomes the highest priority. Allowing a build failure to persist adds the risk of integration problems to ongoing development, so developers need to focus on fixing the problem before moving forward.
Continuous Integration Builds Quality in
CI benefits a software development organization in a number of ways. All of the descriptions that follow assume the CI implementation includes a robust set of unit and integration tests that are run each time the source code is rebuilt.
Aid Debugging by Limiting the Scope of Errors
An effective CI implementation requires users to check changes into SCM frequently. Frequent check-ins tend to limit both the size and scope of changes, which in turn limit the possible sources of error when a test fails. CI helps speed debugging by limiting the source of a test failure to recent changes.
Provide Immediate Feedback for Changes
Feedback for changes is not limited to test failures; it includes successful integrations as well. CI provides both positive and negative feedback about recent changes, allowing developers to see the effects of those changes quickly. The negative or positive quality of those effects can then drive additional changes or a determination that no more work is required.
Minimize Integration Effort
Traditional software development life cycles include an integration phase sandwiched between the end of development and the release of the product. CI minimizes—and sometimes eliminates completely—the integration phase. By spreading the integration effort out over the entire development cycle, CI allows developers to integrate smaller changes. Integrating smaller changes frequently doesn’t simply spread the same effort out over a longer period; it actually reduces the integration effort. Because the changes are small and limited to specific sections of the source code, isolation of errors is quicker and debugging is easier.
Minimize Propagation of Defects
An undetected defect in one module can propagate through the software system via dependencies with other modules. When the defect is finally discovered, the fix affects not only the defective module, but also all modules dependent on it. First, the defect propagates through the system, and then the fix propagates through the system.
Continuous integration minimizes the propagation of defects through the system by detecting the problem early (via thorough automated unit and integration testing), before it has a chance to propagate.
Create a Safety Net for Developers
A significant part of any development effort involves modifying existing code to account for changing requirements and refactoring modules to improve the overall software implementation. Developers can modify and refactor code with confidence because CI is providing a safety net. The unit and integration tests that run as part of the build give immediate feedback to developers, who can roll back changes if something causes the build to break.
Ensure the Latest and Greatest Software Is Always Available
Because CI builds the project whenever the code changes, it keeps the latest build in sync with the code repository. A CI implementation that reads from an SCM repository and deploys the build to a test environment ensures that developers, testers, and users are all working with the latest version of software.
Provide a Snapshot of the Current State of the Project
Because CI reports the state of every build, it provides up-to-date visibility into the current state of the project. The snapshot may include:
Results of the latest build, which tells developers what needs to be fixed before moving forward.
Metrics resulting from unit testing, code coverage, and coding standards analysis, which allows team leaders to gauge the team’s adherence to processes.
Number of passing tests, which indicates how many requirements are actually completed and can provide managers with insight into the progress of the project.
Resistance to Implementing CI
Much of the resistance to implementing CI has to do with increased cost in terms of time, money, or both. Some has to do with retrofitting CI onto a system not designed to support it. In most cases, the benefits outweigh the costs; however, being aware of the arguments against CI will help prepare you to convince management it’s a good idea.
CI Requires Extra Hardware
As discussed earlier in the section Dedicated Build Servers,” CI works best with a powerful computer dedicated to performing builds and all the associated tasks. Although CI can be implemented without a dedicated build server, the benefits generally outweigh the costs of extra hardware, even when the machine is a very powerful (i.e., expensive) one. Even so, there are at least two ways to get started with CI on something less than the biggest, fastest machine on the market: piggyback on an existing server or use a less powerful machine that no one wants.
Piggybacking on an existing server or shared computer, such as a test machine or an underutilized web server, is a quick way to implement CI. Such machines are often already running the typical deployment environment, so you only have to load the CI-related software. When following this approach, the more stable the environment, the better. A server whose configuration is changed often will lead to inconsistent build results.
Implementing CI on a less powerful machine—perhaps one left over from the last time the development machines were upgraded—provides the benefits of a dedicated machine at the cost of fast builds. Whether a less powerful machine is adequate for a particular project will depend on a number of factors, such as the number of developers and the frequency of check-ins (both directly affect the frequency of builds), the size of the build, and the number and type of automated tests. Less powerful machines may be enough for small development efforts. Larger, more complex projects can use this approach to demonstrate the benefits of CI in an effort to lobby management for the funds to obtain a more powerful machine.
Both of these approaches can provide a starting point for implementing CI, but there is no substitute for a powerful, dedicated build server. In the end, the justification is simply that the time saved during integration far outweighs the upfront costs of adequate hardware.
CI Requires New Software
Though it is possible to implement CI from scratch with custom scripts and applications, the easiest approach is to use a third-party CI server application, many of which are available as open source software. Implementing CI with open source packages can reduce the initial cost to almost nothing, although there are maintenance and training costs to consider. Other software packages required for implementing CI—such as an SCM system, a build scripting language, and a unit test framework—are also available as open source software.
As with most software, there is a learning curve associated with CI software; however, CI software packages are usually independent of the project software, so experience gained on one project transfers easily to new projects. In addition, you can implement CI in a stepwise fashion, starting simply and enhancing the process as developers learn more about the package.
CI Adds Maintenance Tasks
In addition to the initial setup tasks, CI requires ongoing maintenance of the build scripts, although the amount of ongoing maintenance is fairly small. This type of maintenance typically involves creating build scripts for new modules and adding tasks to the build process.
Creating the build script for a new module can be time-consuming, since you must take care to ensure that all dependencies are accounted for and all required libraries are available. As noted earlier, one way to simplify the task is to use an IDE to create a build script that can be invoked by the CI process.
Spending time upfront to organize the project structure (in conjunction with the SCM repository structure) and create extensible build scripts often reduces work necessary for both the addition of tasks and the addition of modules. You can add tasks to the build script such that they apply to all modules or a specific subset of them. And good build scripts will automatically incorporate repository changes, so adding and deleting modules is as simple as adding or removing the module from the SCM repository.
CI for Legacy Code Is Expensive
Continuous integration is most effective when used with a robust set of unit tests; after all, without testing, CI degrades to simply compilation of the source code. Legacy code often lacks unit tests (at least automated unit tests), so retrofitting CI onto an existing project can be a daunting task.
The best approach to implementing CI in a legacy system is to begin by creating build scripts for the existing modules, including any unit tests that exist. Unit tests are then added to legacy modules as the modules are modified or refactored, expanding unit test coverage to the entire legacy codebase over time. New modules are required to have unit tests before being allowed into the build. Chapter 4 covers the implementation of unit tests for legacy code in detail.
Summary
CI is the process of integrating small changes at short intervals. The process reduces, and sometimes eliminates, the need for an integration phase at the end of development. CI involves building the entire software product, testing it, and reporting the results whenever changes are made, which provides immediate feedback to the developers responsible for the changes.
The CI process has several prerequisites, though these prerequisites are themselves valid practices for implementing Lean and Agile methodologies. You can implement CI gradually, starting with a basic build and unit test sequence and expanding to include automated integration and acceptance testing, code analysis, and even deployment.
The benefits of a well-implemented CI process include detecting defects as soon as possible, minimizing the propagation of defects, simplifying the debug process by limiting the scope of errors, minimizing the integration phase, providing immediate feedback to developers, and raising the visibility of the project’s status. These benefits are gained at the expense of an initial setup process, additional hardware and software, and, possibly, a change in the way developers handle source code and automated testing.