
Application Security
In this chapter, we consider the various ways in which we might secure our applications. We go over the vulnerabilities common to the software development process, including buffer overflows, race conditions, input validation attacks, authentication attacks, authorization attacks, and cryptographic attacks, and how we might mitigate these by following secure coding guidelines. We talk about Web security, the areas of concern on both the client and server sides of the technology. We introduce database security and cover protocol issues, unauthenticated access, arbitrary code execution, and privilege escalation and the measures we might take to mitigate them. Lastly, we examine security tools from an application perspective, including sniffers such as Wireshark, fuzzing tools including some developed by Microsoft, and Web application analysis tools such as Burp Suite in order to better secure our applications.
Keywords
Application security; authentication; authorization; buffer overflow; Burp Suite; cryptographic attack; database security; fuzzing; input validation; protocol; race condition; Web security; Wireshark
Information in This Chapter
Introduction
In Chapters 10 and 11, we discussed the need to keep our networks and operating systems secure from the variety of attacks and incidents that might befall them. Equally important to ensuring that we can keep attackers from interacting with our networks in an unauthorized manner and subverting our operating system security is ensuring that our applications are not misused.
As a good illustration of the importance of all three realms of security, we can look to any of the nearly constant streams of security breaches that take place in companies around the globe. One particular incident that was wide reaching in terms of the methods used in the attack was the TJX breach.
The TJX breach
The TJX Companies, a retailer operating more than 2000 stores under the brands T.J. Maxx, Marshalls, Winners, Homesense, T.K. Maxx, HomeGoods, A.J. Wright, and Bob’s Stores, reported a breach of financial data in January 2007. It was later announced that data regarding sales transactions for 2003, as well as May through December 2006, had been exposed, with an estimated total of 45 million to 200 million debit and credit card numbers having been stolen, as well as 455,000 records containing identification information, names, and addresses.
The very beginning of the breach was an attack on the wireless network used to communicate between handheld price-checking devices, cash registers, and the store’s computers, at a Marshalls retail store in Minnesota [1]. The system used the 802.11b wireless protocol to communicate and Wired Equivalent Privacy (WEP) encryption to secure the transmission media. WEP is an outdated encryption protocol with well-known weaknesses and was rendered obsolete in 2002 [2].
Once the attackers gained access to the system at a local store, they were able to access the central system at the parent company, TJX, in Massachusetts. After the system was compromised, the attackers were able to create their own accounts and access the stolen data directly from the Internet. This was possible due to the lack of firewalls and encryption on sensitive portions of the TJX network [3].
In the breach outlined in this case study, we can clearly see examples of network security issues and operating system security issues, both of which are relatively common when we look at security breaches. One of the things that makes the attack sting the most from a security perspective is that the attackers were able to turn TJX’s own systems against itself in order to gain access to sensitive data, by using the normal channels within the company in an unauthorized manner. These security issues are still relevant today, if we do not protect our applications, including the code that runs our operating systems, network infrastructure, and other vital pieces, we are potentially missing a critical portion of the attack surface that needs to be secured.
Software development vulnerabilities
A number of common software development vulnerabilities can lead to security issues in our applications. These issues are all well known as being problematic from a security perspective, and the reasons the development practices that lead to them should not be used are a frequent topic of discussion in both the information security and software engineering communities.
The main categories of software development vulnerabilities include buffer overflows, race conditions, input validation attacks, authentication attacks, authorization attacks, and cryptographic attacks, as shown in Figure 12.1. All these vulnerabilities can be minimized with relative ease when developing new software by simply using best practice programming techniques.

Additional resources
A great resource for secure software development standards is the set of documentation available from the Computer Emergency Response Team (CERT) at Carnegie Mellon University.1 This organization provides secure coding documentation for several programming languages and is a good overall resource for further investigation into secure coding in general.
Buffer overflows
Buffer overflows, also referred to as buffer overruns, occur when we do not properly account for the size of the data input into our applications. If we are taking data into an application, most programming languages will require that we specify the amount of data we expect to receive and set aside storage for that data. If we do not set a limit on the amount of data we take in, called bounds checking, we may receive 1000 characters of input where we had only allocated storage for 50 characters.
In this case, the excess 950 characters of data may be written over other areas in memory that are in use by other applications or by the operating system itself. An attacker might use this technique to allow him to tamper with other applications or to cause the operating system to execute his own commands.
Proper bounds checking can nullify this type of attack entirely. Depending on the language we choose for the development effort, bounds checking may be implemented automatically, as is the case with Java and C# [4].
Race conditions
Race conditions occur when multiple processes or multiple threads within a process control or share access to a particular resource, and the correct handling of that resource depends on the proper ordering or timing of transactions.
For example, if we are making a $20 withdrawal from our bank account via an ATM, the process might go as follows:
If someone else starts the same process at roughly the same time and tries to make a $30 withdrawal, we might end up with a bit of a problem:
1. User 1: Check the account balance ($100)
2. User 2: Check the account balance ($100)
3. User 1: Withdraw funds ($20)
4. User 2: Withdraw funds ($30)
Because access to the resource, our bank account, is shared, we end up with a balance of $70 being recorded, where we should see only $50. In reality, our bank will have implemented measures to keep this from happening, but this illustrates the idea of a race condition. Our two users “race” to access the resource, and undesirable conditions occur.
Race conditions can be very difficult to detect in existing software, as they are hard to reproduce. When we are developing new applications, careful handling of the way we access resources to avoid dependencies on timing can generally avoid such issues.
Input validation attacks
If we are not careful to validate the input to our applications, we may find ourselves on the bad side of a number of issues, depending on the particular environment and language being used. A good example of an input validation problem is the format string attack.
Format string attacks are an issue where certain print functions within a programming language can be used to manipulate or view the internal memory of an application. In some languages, C and C++ in particular, we can insert certain characters into our commands that will apply formatting to the data we are printing to the screen, such as %f, %n, %p. Although such parameters are indeed a legitimate part of the language, if we are not careful to filter the data input into our applications, they can also be used to attack us.
For example, if an attacker were to include the %n (write an integer into memory) parameter in an input field and had specifically crafted the rest of the input, he or she might be able to write a particular value into a location in memory that might not normally be accessible to him or her. The attacker could use this technique to crash an application or cause the operating system to run a command, potentially allowing him or her to compromise the system.
This type of attack is almost entirely one of input validation. If we are careful to check the input we are taking in, and filter it for unexpected or undesirable content, we can often halt any issues immediately. In the case of the format string attack, we may be able to remove the offending characters from the input or put error handling in place to ensure that they do not cause a problem.
Authentication attacks
When we plan the authentication mechanisms our applications will use, taking care to use strong mechanisms will help to ensure that we can react in a reasonable manner in the face of attacks. There are a number of common factors across the various mechanisms we might choose that will help make them stronger.
If we put a requirement for strong passwords into our applications when we are doing password authentication, this will go a long way toward helping to keep attackers out. If we use an eight-character, all-lowercase password, such as hellobob, a reasonably powerful machine may be able to break the password in a matter of seconds. If we use an eight-character, mixed-case password that also includes a number and a symbol, such as H3lloBob!, our time goes up to more than 2 years [5]. Furthermore, our applications should not use passwords that are built-in and are not changeable, often referred to as hard-coded passwords.
Additionally, performing any authentication steps on the client side is generally not a good idea, as we then place such measures where they may easily be attacked. As a good example of why we should not do client-side authentication, we can look to the incident involving certain hardware-encrypted flash drives from SanDisk, Kingston, and Verbatim that was reported in January 2010 [6]. In this case, it was found that an application running on the user’s computer was responsible for verifying that the decryption password entered was actually correct and sent a fixed code to the device to unlock it. Security researchers were able to build a tool to send the same unlock code without needing the password and were able to circumvent the security of the devices entirely [7].
Authorization attacks
Just as we discussed when we looked at authentication, placing authorization mechanisms on the client side is a bad idea as well. Any such process that is performed in a space where it might be subject to direct attack or manipulation by users is almost guaranteed to be a security issue at some point. We should instead authenticate against a remote server or on the hardware of the device, if we have a portable device, where we are considerably more in control.
When we are authorizing a user for some activity, we should do so using the principle of least privilege, as we discussed in Chapter 3. If we are not careful to allow the minimum permissions required, both for our users and for the internal activities of our software, we may leave ourselves open for attack and compromise.
Additionally, whenever a user or process attempts an activity that requires particular privileges, we should always check again to ensure that the user is indeed authorized for the activity in question, each time it is attempted. If we have a user who, whether by accident or by design, gains access to restricted portions of our application, we should have measures in place that will not allow the user to proceed.
Cryptographic attacks
We leave ourselves open to failure if we do not pay close enough attention to designing our security mechanisms while we implement cryptographic controls in our applications. Cryptography is easy to implement badly, and this can give us a false sense of security.
One of the big “gotchas” in implementing cryptography is to give in to the temptation to develop a cryptographic scheme of our own devising. The major cryptographic algorithms in use today, such as Advanced Encryption Standard (AES) and RSA, have been developed and tested by thousands of people who are very skilled and make their living developing such tools. Additionally, such algorithms are in general use because they have been able to stand the test of time without serious compromise. Although it is possible that our homegrown algorithm may have something to offer, software that stores or processes any sort of sensitive data is likely not a good place to test it out.
In addition to using known algorithms, we should also plan for the mechanisms we do select to become obsolete or compromised in the future. This means, in our software design, we should allow for the use of different algorithms, or at least design our applications in such a way that changing them is not a Herculean task. We should also plan for changing the encryption keys the software uses, in case our keys break or become exposed.
Web security
As the use of Web pages and applications has become prevalent in recent years, careful design and development of them is paramount. Attackers can use an enormous variety of techniques to compromise our machines, steal sensitive information, and trick us into carrying out activities without our knowledge. These types of attacks divide into two main categories: client-side attacks and server-side attacks.
Client-side attacks
Client-side attacks take advantage of weaknesses in the software loaded on our clients, or those attacks that use social engineering to trick us into going along with the attack. There are a large number of such attacks, but we will focus specifically on some that use the Web as an attack vehicle.
Cross-site scripting
Cross-site scripting (XSS) is an attack carried out by placing code in the form of a scripting language into a Web page, or other media, that is interpreted by a client browser, including Adobe Flash animation and some types of video files. When another person views the Web page or media, he or she executes the code automatically, and the attack is carried out. A good example of such an attack might be for the attacker to leave a comment containing the attack script in the comments section of an entry on a blog. Every person reading the command in her browser would execute the attack. This kind of attack is used on legitimate sites like banks or e-retailers to turn them into malicious sites.
Alert!
As we discussed, cross-site scripting is abbreviated as XSS, which may be a bit confusing to some. This was done because the acronym CSS was already used for Cascading Style Sheets, another Web-related technology.
Cross-site request forgery
A cross-site request forgery (XSRF) attack is similar to XSS, in a general sense. In this type of attack, the attacker places a link, or links, on a Web page in such a way that they will be automatically executed, in order to initiate a particular activity on another Web page or application where the user is currently authenticated. For instance, such a link might cause the browser to add items to our shopping cart on Amazon or transfer money from one bank account to another.
If we are browsing several pages and are still authenticated to the same page the attack is intended for, we might execute the attack in the background and never know it. For example, if we have several pages open in our browser, including one for MySpiffyBank.com, a common banking institution, and we are still logged in to that page when we visit BadGuyAttackSite.com, the links on the attack page may automatically execute in order to get us to transfer money to another account.
This type of attack takes somewhat of a shotgun approach in order to be carried out successfully. The attacker will most likely not know which Web sites the user is authenticated to but can guess at some of the more common choices, such as banks or shopping sites, and include components to target those specifically.
Clickjacking
Clickjacking is an attack that takes advantage of the graphical display capabilities of our browser to trick us into clicking on something we might not otherwise. Clickjacking attacks work by placing another layer over the page, or portions of the page, in order to obscure what we are actually clicking. For example, the attacker might hide a button that says “buy now” under another layer with a button that says “more information.”
More advanced
These types of attacks are, for the most part, thwarted by the newer versions of the common browsers, such as Internet Explorer, Firefox, Safari, and Chrome. The most common attacks we discussed in this section will be blocked by these automatically, but the landscape of attacks is constantly changing. In many cases, however, new attack vectors are simply variations of old attacks. Additionally, there are innumerable vulnerable clients running on outdated or unpatched software that are still vulnerable to attacks that are years old. Understanding how the common attacks work and protecting against them not only gives us an additional measure of security but also helps us understand how newer attacks might be developed.
It is very important to keep up with the most recent browser versions and updates, as the vendors that produce them regularly update their protections. Furthermore, for some browsers, we can apply additional tools in order to protect us from client-side attacks. One of the better known of these tools is NoScript2 and is presently only available for Firefox. NoScript blocks most Web page scripts by default and allows only those that we specifically enable. With careful use, script-blocking tools such as this can disable many of the Web-based threats we might encounter.
Server-side attacks
On the server side of the Web transaction, a number of vulnerabilities may cause us problems as well. Such threats and vulnerabilities can vary widely depending on our operating system, Web server software, various software versions, scripting languages, and many other factors. Across all of these, however, are several factors that are the cause of numerous security issues that are common across the various implementations we might encounter.
Lack of input validation
Lack of proper input validation is a large problem when we look at Web platforms. As we discussed earlier in the chapter, this is a general security issue when developing software, but some of the most common server-side Web attacks use this weakness to carry out their attacks.
Structured Query Language (SQL) injection gives us a strong example of what might happen if we do not properly validate the input of our Web applications. SQL is the language we use to communicate with many of the common databases on the market today. In the case of databases connected to Web applications, entering specially crafted data into the Web forms that interact with them can sometimes produce results not anticipated by the application developers. We will discuss the specifics of SQL injection in more depth later in this chapter.
If we are careful to validate the input we take into our Web applications and filter out characters that might be used to compromise our security, we can often fend off such an attack before it even begins. In many cases, filtering out special characters such as *, %, ‘,;, and / will defeat such attacks entirely.
Improper or inadequate permissions
Inadequate permissions can often cause us problems with Web applications, and Internet-facing applications of most any kind. Particularly with Web applications and pages, there are often sensitive files and directories that will cause security issues if they are exposed to general users. One area that might cause us trouble is the exposure of configuration files.
For example, in many Web applications that make use of a database (that is a vast majority of them), there are configuration files that hold the credentials the application uses to access the database. If these files and the directories that hold them are not properly secured, an attacker may simply read our credentials from the file and access the database as he or she pleases. For applications that hold sensitive data, this could be disastrous.
Likewise, for the directories on our Web servers, if we do not take care to secure them properly, this may be pointed out to us in a less than desirable way. We may find files changed in our applications, new files added, or the contents deleted entirely. Unsecure applications that are Internet facing do not tend to last very long before being compromised.
Extraneous files
When we move a Web server from development into production, one of the tasks often missed in the process is that of cleaning up any files not directly related to running the site or application, or that might be artifacts of the development or build process.
If we leave archives of the source code from which our applications are built, backup copies of our files, text files containing our notes or credentials, or any such related files, we may be handing an attacker exactly the materials he or she needs in order to compromise our system. One of the final steps when we are rolling out such a server should be to make sure all such files are cleaned up or moved elsewhere if they are still needed. This is also a good periodic check to ensure that, in the course of troubleshooting or upgrading, these items have not been left behind where they are visible to the general public.
Database security
As we discussed when we went over Web security issues, the vast majority of Web sites and applications in use today make use of databases in order to store the information they display and process. In some cases, such applications may hold very sensitive data, such as tax returns, medical data, or legal records; or they may contain only the contents of a discussion forum on knitting. In either case, the data such applications hold is important to the owners of the application and they would be inconvenienced, at the very least, if it were damaged or manipulated in an unauthorized manner.
A number of issues can cause trouble in ensuring the security of our databases. The canonical list includes the following [8]:
• Unauthenticated flaws in network protocols
• Authenticated flaws in network protocols
• Flaws in authentication protocols
• Unauthenticated access to functionality
• Arbitrary code execution in intrinsic SQL elements
• Arbitrary code execution in securable SQL elements
Although this may seem like a horribly complex set of issues for us to worry about, we can break them down into four major categories, as shown in Figure 12.2.
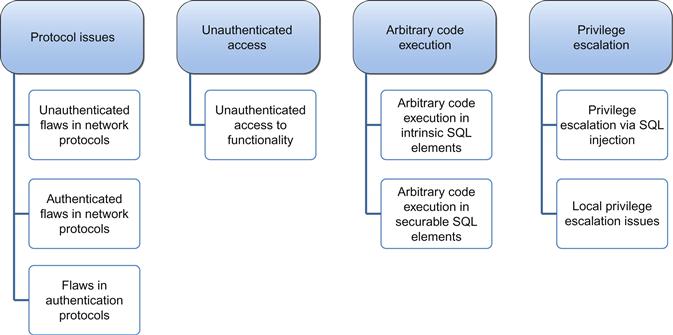
Protocol issues
We might find a number of issues in the protocols in use by any given database. We can look at the network protocols used to communicate with the database, some of which will need a set of credentials in order to use and some of which will not. In either case, there is often a steady stream of vulnerabilities for most any major database product and version we might care to examine. Such vulnerabilities often involve some of the more common software development issues, such as the buffer overflows we discussed at the beginning of this chapter.
When we are dealing with known protocol issues, the absolute best defense is to ensure that we are using the most current software version and patches for the database software in question, as we discussed in Chapter 11. Defending against presently unknown network protocol issues often revolves around limiting access to our databases, either in the sense of actually limiting access to who is able to connect to the database over the network, using some of the methods we discussed in Chapter 10, or, in the case of authenticated protocol problems, by limiting the privileges and accounts we make available for the database itself, following the principle of least privilege.
We may also have issues in the authentication protocols used by our database, depending on the specific software and version we have in use. In general, the older and more out-of-date our software becomes, the more likely it is that we are using an authentication protocol that is not robust. Many older applications will use authentication protocols we know to have been broken at some point, or to have obvious architectural flaws, such as sending login credentials over the network in plaintext (refer to Chapter 5), as Telnet does. Again, the best defense here is to ensure that we are on current versions of the software we are using.
Unauthenticated access
When we give a user or process the opportunity to interact with our database without supplying a set of credentials, we create the possibility for security issues. Such issues may be related to simple queries to the database through a Web interface, in which we might accidentally expose information contained in the database; or we might expose information on the database itself, such as a version number, giving an attacker additional material with which to compromise our application.
We might also experience a wide variety of issues related to the secure software development practices we discussed at the beginning of the chapter. If the user or process is forced to send us a set of credentials to begin a transaction, we can monitor, or place limits on, what the user or process is allowed to do, based on those credentials. If we allow access to part of our application or tool set without requiring these credentials, we may lose visibility and control over what actions are taking place.
Arbitrary code execution
We can find a number of areas for security flaws in the languages we use to talk to databases. Generally, these are concentrated on SQL, as it is the most common database language in use. In the default SQL language, a number of built-in elements are possible security risks, some of which we can control access to and some of which we cannot.
In these language elements, we may find a number of issues related to bugs in the software we are using, or issues spawned by not using secure coding practices, that might allow us to execute arbitrary code within the application. For example, a flaw allowing us to conduct a buffer overflow, as we discussed earlier in this chapter, might enable us to insert attack code into the memory space used by the database or the operating system, and compromise either or both of them.
Our best defenses against such attacks are twofold. From the consumer side, we should stay current on the version and patch levels for our software. From the vendor side, we should mandate secure coding practices, in all cases, in order to eliminate the vulnerabilities in the first place, as well as conducting internal reviews to ensure that such practices are actually being followed.
Privilege escalation
Our last category of major database security issues is that of privilege escalation. In essence, privilege escalation is a category of attack in which we make use of any of a number of methods to increase the level of access above what we are authorized to have or have managed to gain on the system or application through attack. Generally speaking, privilege escalation is aimed at gaining administrative access to the software in order to carry out other attacks without needing to worry about not having the access required.
As we mentioned earlier in the chapter, SQL injection is a very common attack against databases that are accessible through a Web interface and is largely an issue of not filtering or validating inputs properly. SQL injection can be used to gain information from the database in an unauthorized manner, modify data contained in the database, and perform many other similar activities. SQL injection can also be used to gain or escalate privileges in the database.
One of the more common SQL injection examples is to send the string “or” 1′=1′ as the input in a username field for an application. If the application has not filtered the input properly, this may cause it to automatically record that we have entered a legitimate username, which we have clearly not done, allowing us to potentially escalate the level of privilege to which we have access.
Additional resources
For those interested in more information regarding SQL injection and database security in general, two books available from Syngress are Securing SQL Server by Denny Cherry (ISBN: 9781597496254) and SQL Injection Attacks and Defense by Justin Clarke (ISBN: 9781597494243). Both are great resources from very knowledgeable folks.
An additional area of concern for privilege escalation is from an operating system perspective. Database applications are processes running on the operating system, using the credentials and privileges of an operating system user, just like a Web browser or any other application we might want to run. If we are not careful to protect our operating systems and the user accounts that run on them, as we talked about in Chapters 10 and 11, any database security measures we might put in place may be for naught. If an attacker gains access to the account under which the database software is running, he or she will likely have privileges to do anything he or she might care to do, including deleting the database itself, changing passwords for any of the database users, changing the settings for the way the database functions, manipulating data, and so on.
Our best defenses against operating system issues such as these are the set of hardening and mitigation steps we discussed in Chapter 11. If we can keep attackers from compromising our system in the first place, we can largely avoid this particular concern.
Application security tools
We can use a number of tools in an attempt to assess and improve the security of our applications. We discussed some of them, such as sniffers, in Chapters 10 and 11. Others are less familiar and more complex, such as fuzzers and reverse engineering tools. Some of these tools require a certain amount of experience in developing software and a higher level of familiarity with the technologies concerned in order to be able to use them effectively.
Sniffers
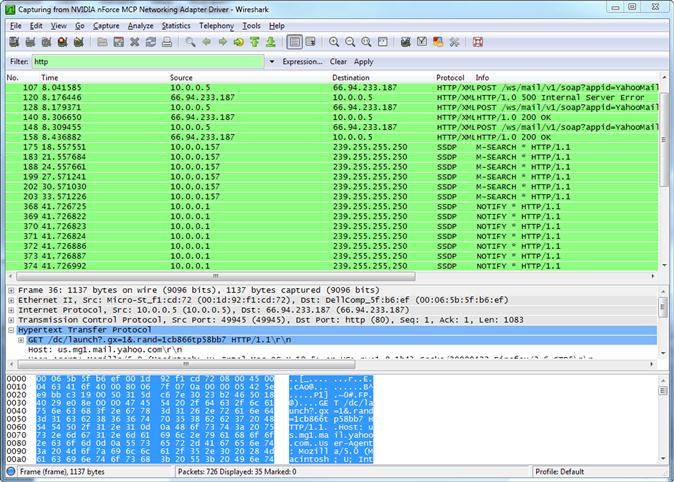
As we discussed in Chapters 10 and 11, sniffers can be of great use in a variety of security situations. We can use them at a very high level to examine all the traffic traveling over the portion of the network to which we are attached, presuming we can get our sniffer placed properly to see the traffic in question. We can also use such tools very specifically in order to watch the network traffic being exchanged with a particular application or protocol. In Figure 12.3, we are using Wireshark to examine Hypertext Transfer Protocol (HTTP) traffic specifically.
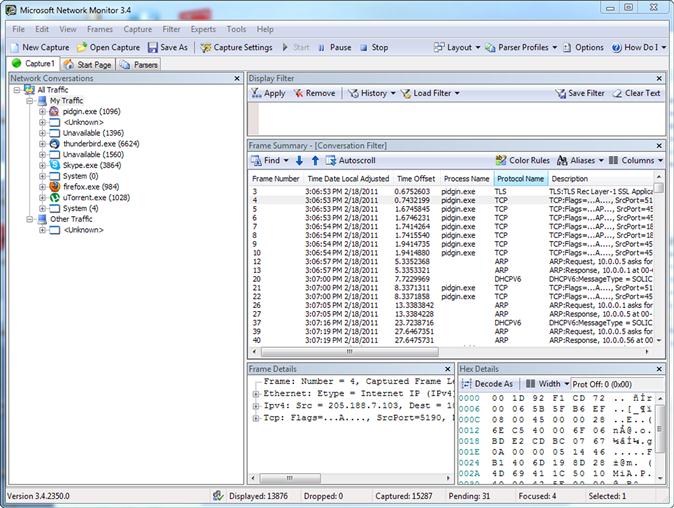
We can also, in some cases, use tools specific to certain operating systems in order to get additional information from sniffing tools. A good example of this is the Microsoft Network Monitor tool, which will enable us to not only sniff the network traffic but also easily associate the traffic we are seeing with a particular application or process running on the system. This allows us to very specifically track information we see on the network interface of the system back to a certain process, as shown in Figure 12.4.
Web application analysis tools
For purposes of analyzing Web pages or Web-based applications, a great number of tools exist, some of them commercial and some of them free. Most of these tools perform the same general set of tasks and will search for common flaws such as XSS or SQL injection flaws, as well as improperly set permissions, extraneous files, outdated software versions, and many more such items.
Nikto and Wikto
Nikto is a free and open source Web server analysis tool that will perform checks for many of the common vulnerabilities we mentioned at the beginning of this section and discussed earlier in the chapter when we went over server-side security issues. Nikto will index all the files and directories it can see on the target Web server, a process commonly referred to as spidering and will then locate and report on any potential issues it finds.
Alert!
It is important to note when using Web analysis tools that not everything the tool reports as a potential issue will actually be a security problem. Such tools almost universally give us back a certain number of false positives, indicating a problem that is not actually valid. It is important to manually verify that the issue really exists before taking action to mitigate it.
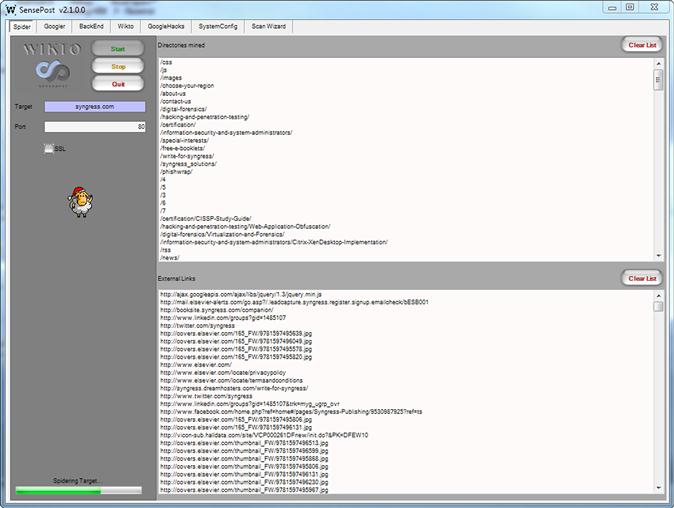
Nikto is a command-line interface tool that runs on Linux. For those of us who are in a Windows-centric environment, or prefer to use a graphical interface, SensePost has produced a Windows version of Nikto called Wikto, as shown in Figure 12.5. Wikto is very similar in functionality to Nikto and provides us with a GUI.
Burp Suite
Quite a few commercial Web analysis tools are also available, and they vary in price from several hundred dollars to many thousands of dollars. Burp Suite is one such tool, tending toward the lower end of the cost scale for the professional version ($299 per year at the time of this writing) but still presenting a solid set of features. Burp Suite runs in a GUI, as shown in Figure 12.6, and, in addition to the standard set of features we might find in any Web assessment product, includes several more advanced tools for conducting more in-depth attacks.
Burp Suite is also available in a free version that allows the use of the standard scanning and assessment tools but does not include access to the more advanced features.
Fuzzers
In addition to all the tools we can use to look over our software for various known vulnerabilities, there is another category of tools we can use to find completely unexpected problems, a process referred to as fuzz testing. The tools we use for this technique, referred to as fuzzers, work by bombarding our applications with all manner of data and inputs from a wide variety of sources, in the hope that we can cause the application to fail or to perform in unexpected ways.
More advanced
The concept of fuzzing was first developed by Barton Miller for a graduate-level university operating system class in the late 1980s [9], and it has enjoyed popular use by security researchers and those conducting security assessments on applications. A great resource for further reading on fuzzing, including the document that spawned this field of analysis, can be found on Miller’s fuzzing Web page at the University of Wisconsin, at http://pages.cs.wisc.edu/~bart/fuzz/.
A wide variety of fuzzing tools are available, some with a specific focus and some that are more general. Microsoft has released several very specific fuzzing tools to assist in discovering vulnerabilities in both existing software and software in development, including the MiniFuzz File Fuzzer, designed to find flaws in file-handling source code, the BinScope Binary Analyzer, for examining source code for general good practices, and the SDL Regex Fuzzer, for testing certain pattern-matching expressions for potential vulnerabilities. A great number of other tools exist for a variety of fuzzing purposes, many of them free and open source.
Application security in the real world
In today’s highly networked and application-based business world, securing our applications is an absolute necessity. We work online, shop online, go to school online, conduct business online, and generally lead heavily connected lives. We can see frequent examples of businesses that do not take the trouble to secure their assets, and the serious repercussions that are felt by both them and their customers when they experience failure in this area.
We talked about the need to build security into our applications through the use of secure coding practices, the need to secure our Web applications, and the need to secure our databases, but these measures all really work in concert when we apply them. When we are developing an application, whether it is for use internally or whether it is Internet facing, we need to take all these areas into account. When we are developing an application from scratch, developing to a set of secure coding standards is an absolute must. The National Institute of Standards and Technology (NIST) 800 Series of publications3 has numerous guides for both development and deployment of technologies and applications and is a great starting place for organizations that do not have internal development and deployment standards of their own.
Securing our Web applications and the databases they interface with is also a critical activity. When we look at any given breach that involved a lapse in security, whether corporate or governmental, we are almost guaranteed to find a failure in application security at some point. The TJX breach we discussed earlier in the chapter was not an application failure to begin with, but the lax application security the company had in place made the breach far worse than it might have been otherwise. Such security measures are not optional or just a “good idea” for technology-based companies, they are a foundational requirement. Depending on the industry in which we are operating and the data we are handling, such protections may be mandated by law.
Summary
A number of vulnerabilities are common to the software development process, across many of the platforms on which we might be developing or implementing our solution. We may encounter buffer overflows, race conditions, input validation attacks, authentication attacks, authorization attacks, and cryptographic attacks, just to name a few. Although such issues are very common, most of them can be resolved with relative ease by following secure coding guidelines, either those internal to our organizations, or from external sources such as NIST, CERT, or the Build Security in Software Assurance Initiative (BSI) from the US Department of Homeland Security.4
In terms of Web security, the areas of concern break out into client-side issues and server-side issues. Client-side issues involve attacks against the client software we are running, or the people using the software. We can help mitigate these by ensuring that we are on the most current version of the software and associated patches, and sometimes by adding extra security tools or plug-ins. On the other side, we have attacks that are directly against the Web server itself. Such attacks often take advantage of lack of strict permissions, lack of input validation, and leftover files from development or troubleshooting efforts. Fixing such issues requires careful scrutiny by both developers and security personnel.
Database security is a large concern for almost any Internet-facing application. The main categories of database security concerns are protocol issues, unauthenticated access, arbitrary code execution, and privilege escalation. Many of these problems can be mitigated by following secure coding practices, keeping up-to-date on our software versions and patches, and following the principle of least privilege.
There are a number of application security tools that we can use in our efforts to render our applications more able to resist attack. As with network and host security, we can put sniffers to use in examining what enters and exits our applications in terms of network data. We can also use reverse engineering tools to examine how existing applications operate and to determine what weaknesses we might have that a skilled reverse engineer could exploit. In addition, we can make use of fuzzing tools and Web application analysis tools in order to locate vulnerabilities, whether known or unknown.
Exercises
1. What does a fuzzing tool do?
2. Give an example of a race condition.
3. Why is it important to remove extraneous files from a Web server?
4. What does the tool Nikto do and in what situation might we use it?
5. Name the two main categories of Web security.
6. Is an SQL injection attack an attack on the database or an attack on the Web application?
7. Why is input validation important?
8. Explain an XSRF attack and what we might do to prevent it.
9. How might we use a sniffer to increase the security of our applications?
10. How can we prevent buffer overflows in our applications?