
Developing Your Organization’s Data Leveraging Capabilities
3.2 Engineering Leverage for your Data Advantage
3.3 Architecting Data Leverage
3.5 An Alternative Approach to IT Development
3.1 Chapter Overview
One of the primary tasks facing our chief organizational officers is providing appropriate tangible support for strategy implementation. For example, CFOs engineer financial assets to ensure resources are available when required. Similarly, your CDO should focus 100% on leveraging data assets or:
Successfully leveraging data-based1 assets in support of organizational strategy!
Currently, these capabilities are not easily available to 90% of organizations.
The data assets must be perceived holistically and more importantly, independently of technology, in the same manner a CFO “understands” the available range of financial assets and instruments. The concept “in support of organizational strategy” is foreign to those whose job it has become “to manage data.” Most data professionals refer to management as being a goal.2 Management is a necessary (but insufficient) prerequisite to successful data leveraging – leveraging is a higher order objective. Advantageous DM is a prerequisite to achieving organizational data leverage. Exploiting a data advantage is what brings recognized value to data assets. We examine seven related subtopics of exploiting a data advantage that are likely to be unfamiliar to your CIO/CDO.
• Engineering Leverage. Data is a mechanism for leveraging IT work products. Data enhances virtually all IT work products. (We like our colleague John Ladley’s concept: data as fuel.) Thus, data fuels all organizational operations that employ IT.
• Architecting Data Leverage. Leveraging data is accomplished through architecture/engineering methods/techniques. We illustrate the difference in problem-solving approaches and describe data leverage goals.
• Data Strategy Development. To truly serve as an asset, data must support strategy. Well-engineered data strategies are supported by a goal, plans, projected work product outcomes, cost estimates, and ROI – along with an engineered plan to measure accomplishment. Data architecture reinforces data strategy.
• An Alternative Approach to IT Development. Data assets do not exist in isolation. They are influenced by data-centric or process-centric development approaches. Data-centric approaches are generally better and more difficult to implement than process-centric approaches. When created through data-centric approaches, data’s leverage capabilities are extended.
• Data Centric Principles. Data leveraging needs to be guided by general design principles. These can be assessed for outcomes and contribution to goals.
• Assessing Data Leveraging. DM program execution needs to be regularly assessed. Without crisp mechanisms for measuring success, organizations lose focus on their mission.
• Application Software/COTS Packages. Data centric concepts apply specifically in largely package-based environments. They deliver specific concrete utility – several uses are described.
3.2 Engineering Leverage for your Data Advantage
Leverage is defined as: the mechanical advantage of a lever and as advantage gained by being in a position to use a lever. A lever then is defined as a rigid bar pivoted about a fulcrum, used to transfer a force to a load and usually to provide a mechanical advantage (dictionary.com 2012).
Figure 3.1 illustrates the leverage concept. Use of the term ‘leverage’ today means exploiting an advantage to gain a return on an asset such as staff, product, sales, or inventory. Equally important is that it derived from engineering, implying application and governance of engineering concepts,3 bringing with it rigor and motivation lacking from the term “management.” A critical leveraging characteristic is investments producing increasing returns. Points of diminishing returns can be calculated to guide decisions – ensuring that you don’t invest more than you will get back out of something. (Note: data leverage also requires synchronized application of architectural principles – these are addressed in the next chapter)
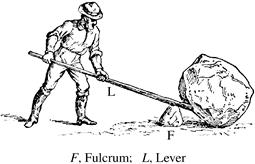
Without the engineering discipline, it is impossible to effectively leverage data within the organization and with partners. Leverage is obtained using data-centric technologies, processes, and human skill sets. Leverage is increased as redundant, obsolete, or trivial (ROT) data is eliminated from organizational data (Figure 3.2). Treating data more asset-like simultaneously 1) lowers IT costs and 2) increases knowledge worker productivity.
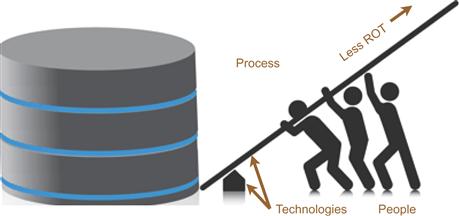
Data’s ‘define once – use many times’ nature permits it to be leveraged to great advantage. The natural consequence of this engineered leveraging is increased integration, interoperability, and non-redundancy. Leveraging through data architecture is an essential component that dramatically counters uncontrolled data growth and complexity.
Leveraging data requires specialized knowledge, dedicated resources, and sustained organizational commitment – components missing from data-unknowledgeable organizations. Quality results depend on leverage, and leverage requires an understanding of architecture/engineering concepts – missing from virtually all-education/training4 and not part of most IT conversations.
Leverage enables hard numbers to be associated with organizational data – such as:
These numbers are required before it is possible to develop measurable strategic objectives. As with physical levers, DM has a tipping point. It pays off according to a step function, requiring a specific, critical effectiveness to achieve not just ROI but any results. Successfully investing $90,000 in DM will result in nothing if the required investment was 100,000. As most IT projects exceed budget, failure in this area has caused organizations to shy away from these investments.
Engineering data leveraging affects the measures of success. It improves quality by reducing ambiguity and misunderstandings. It improves productivity by having the same collections of facts, concept structures, and database structures used over and over for as many purposes as possible. It reduces cost by eliminating the development of duplicate work products but whose sameness is obscured. It reduces the risk of reuse because the true nature, meaning and scope can be readily determined and thus their reuse can be trusted. One final data-leveraging characteristic – the bigger the data challenge, the more important data leveraging is to the organization based just on operational efficiencies.
Figure 3.3 illustrates application of engineering concepts. When determining the pictured machine’s purpose, some helpful characteristics include the fact that it:

The machine is clearly a mixer but the sort of mixer engineered to cook for the thousands of sailors on the carrier USS Midway and for those who still enjoy the great ship’s hospitality at events in the San Diego harbor. Clearly, a home grade mixer would been smaller and less expensive but could not have lasted through 65 years of continuous demanding service, much less provided the required instantaneous service levels.
3.3 Architecting Data Leverage
Architecture gives us the innovative leveraging component and the engineering gives us the effectiveness/efficiencies and the dimensions/considerations component. Architecture is also a discipline built on leverage. Consider how, office buildings are designed to include a certain number of male and female washrooms to accommodate the expected usage. How is the decision made to: provide one set of washrooms per office; one per floor; or one washroom facility for the building on the first floor? (Figure 3.4).

Figure 3.4 3D Graphics for Office Building Plan (from: http://www.michihito.com/14soft.html).
The easiest way to meet any instant demand would be to provide one washroom set per office. Although more convenient, it is not the best way to proceed. One set per office building floor is generally considered standard – providing the most flexible and adaptable means of satisfying current and future demand and it provides good leverage of the planned washroom facilities. Typically, architects do not overbuild infrastructure. Customers see it as both wasteful and potentially fraught with high future maintenance costs required to reconfigure to meet the demands of future tenants.
Similarly, decisions made about data should be informed with the same caliber of expertise and they simply cannot be as long as the outlined gaps remain. While almost all forms of IT work products are based on architectures, the focus here is on data architectures. These are what enable data engineering and leveraging. An organization’s data architecture is the physical means used to achieve data leveraging. All data work is architectural, as opposed to software development that can be architectural. This has a dramatic benefit, improving: development; maintenance; understanding; and reuse for process/systems/software engineering components.
Figure 3.5 specifies relationships between the terms DATA, INFORMATION, and INTELLIGENCE. Intelligence is derived from understanding both information and it associated use. Information, in turn is derived from data and requests. Data is based on facts and meaning. Part of the elegance of Appleton’s original model (extended here) is that it graphically depicts the importance of each architectural layer (depicted as building blocks) in organizational quests to leverage data. You cannot build a multi-story house on a marshmallow base. If the foundation is unable to support the higher levels, the entire effort will be crippled. The intelligence layers must be developed using the specification and common understanding of the contained information layer. The dependency repeats as the data layer enables the information layer – both layers serving as foundational to upper layers.

Foreshadowing Figure 6.1 in Chapter 6, good DM practices must precede effective, innovative organizational data use. Failure to focus foundationally ensures that results obtained at the intelligence level take longer, cost more, and deliver less. Poor data architectural foundations explain the still-high failure rates of data warehousing and other specialist data initiatives – representing a particular threat to the allure of big data techniques.
The process of building the data architecture must be done inductively – based on factual information that already exists. This can be effectively and efficiently extracted based on techniques reverse engineering techniques that have been refined over decades (Aiken, Muntz et al. 1994). When combined with some exciting automated reverse engineering technologies5 organizations can rapidly reclaim mastery over their data assets.
3.4 Data Strategy Development
Organizations maintain data-based assets in hopes of successfully employing them in support of strategy. In an attempt to provide valued products and/or services, a customer-relationship management (CRM) strategy might attempt to improve what is known about customer wants/needs. An organization may desire to transfer its inventory to its suppliers and to play only the role of transaction broker (Friedman 2005). A third strategy might be to use data to obtain significant efficiencies from productions/operations, ensuring a low cost advantage. “C” level positions are responsible for developing strategy. This sets direction, intensity, velocity, etc. as goal sets. Organizations maintain asset types to employ in support of goals. For example, receivables may be used as collateral for loans; real estate may be used to build literal store-fronts used to sell goods to customers, hiring many engineers and maintaining an engineering-supportive culture can build a literal brain trust of one or more types of expertise. In each instance, the asset is cultivated to further organizational strategic intentions.
As Figure 3.6 shows, basic confusion exists at the executive level concerning who is responsible for data strategy. The CDO is responsible for developing the organizational data strategy. Data asset-based strategies must be reliable, repeatable, and produce beneficial results that are clearly well beyond their costs. These range from tangibly, improved efficiencies to implementation of sustainable information-based strategies (Porter 1980).
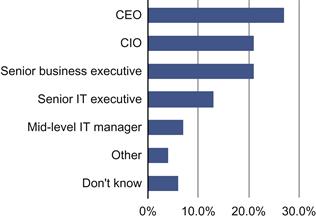
Figure 3.6 Who is responsible for data strategy? Source: Economist_Intelligence_Unit 2013.
For data, these can include tangibly improved operational efficiencies or sustainable data asset-based strategies. Studies indicate only 10% of organizations have board-approved data strategies (Eckerson 2011). Developing one jumps your organization ahead of the competition.
Developing a data strategy involves determining an organization’s relative positioning on Figure 3.7, and developing a plan with measureable objectives to get better within their current quadrant and be prepared to move to the next quadrant. Organizational DM practices mature through a progression from Q1 to Q4.

For organizations in Q1, DM is not seen as strategically important to the organization and little is attempted in DM beyond “keeping the doors open.” Data is not seen or managed as a strategic asset. Instead minimal efforts are expended as required to sustain operations (i.e., cash-balances instead of cash-forecasts).
In Q2, organizational needs dictate a DM strategy focused on increasing organizational effectiveness and/or efficiencies. These might be applicable supporting a lean-supply chain management or low cost provider model. Importantly, Q2 is achievable without the need for additional investments in technology – a significant advantage.
Q3 organizations have achieved the ability to use data to invent or dramatically reimagine various business models. CapitalOne is repeatedly mentioned as one such organization – innovating around the idea of providing products for underserved credit populations (CapitalOne 2013).
Q4 organizations have become good at both Q2 & Q3 practices.
Organizations should typically progress through four stages corresponding to (both) crawl, walk, run and tangibly, improved efficiencies to implementation of sustainable strategies. Most organizations overestimate their data knowledge and attempt to accomplish Q4 data initiatives with only a Q1 foundation. The beneficial results are fleeting because the Q1 foundations result in a dramatic increase of data and business information system stovepipes that makes the IT infrastructure unsustainable.
Unlike Q1, Q2 requires development of specific internal KSAs. Q3 requires different and not necessarily complimentary KSAs. Most organizations overestimate their data knowledge and attempt to accomplish Q4 data initiatives using a Q1 foundation and neither set of KSAs. Given these circumstances, anything accomplished will: take longer; deliver less; and cost more than Q4 efforts built both on solid Q2 and Q3 foundations.
3.5 An Alternative Approach to IT Development
Most IT organizations do not incorporate data-centric development practices. These are required to produce the building blocks required for a data advantage.
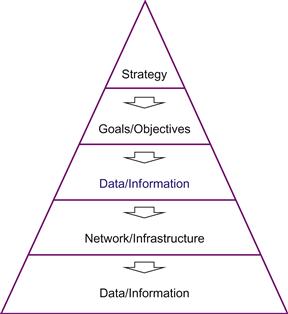
Figure 3.8 illustrates the application-centric development approach. From the top:
• Determining the organizational strategy;
• Specifying specific goals and objectives required to achieve the strategy;
• Using goals and objectives to drive the development of specific combinations of systems and applications;
• Implementation of these lead to network/infrastructure requirements to support the systems and applications.
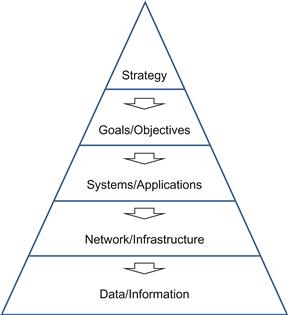
Data and information are identified, determined, and developed after other specifications have been articulated.
Many organizations still find this approach worth doing as the ROI remains high. Challenges identified with this approach include:
• Processes and data are tightly formed around applications – making it difficult to maintain, and risky to change either.
• Very little data reuse is possible with an application-centric focus. Data names, semantics and use rules are encapsulated within applications. This makes their applicability across functions, departments, and the organization difficult to discern.
• Data specifications are developed exclusively from the application domain.
• Data requirements are driven from application requirements and are not based on the organizational requirements.
Figure 3.96 illustrates data-centric development. The first two steps remain unchanged but the third level is now data-focused:
• Determine the data required to measure goal attainment, base parts of the strategy on these data being employed widely, governed by a data architecture;
These information requirements should be the only variable determining infrastructure requirements – all other network requirements would be associated with delivery platform implementation;
• Determine the network/infrastructure requirements to support the data collection, storage, updating, and retrieval for multiple functions across the organization;
• Identify, define, implement and deploy the specific systems/applications necessary to collect, store, process and report the data determined as needed to support the functions, organizations, and organization as articulated in the overall strategy.
Applications can be specified/delivered using smaller footprints focused on precisely articulated goals expressed by the data architecture. More importantly, through data and structure reuse, organizational system design is at least an order of magnitude less complex. Advantages of the data-centric approach include:
• Data assets are developed from integrated, organization-wide perspectives;
• Systems support organizational data needs and compliment organizational process flows;
• Elimination of application/system brittleness as data specification are separated, enabling it to be maintained independently;
• Data reuse is maximized – like a share buy-back this is pure mathematics it can only help organizations achieve agility;
• Enhanced data shareability and maintainability, particularly in cross-functional sharing;
• Significant reduction in the quality/complexity of applications/systems-wide perspective of their shared data – this leads to a reduction in systems creation; and
• Significant reduction in data interface quantities due to higher data reuse.
To be fair, there are some challenges identified with data-centric development:
• Perceiving and accommodating the application system needs for data (which may ultimately be unique to given applications) and to associate them effectively and efficiently within and across functions, organizations and/or organization-wide data requirements can be difficult; and
• Ensuring that as application needs evolve that the data architecture does not hinder the evolution;
• Engineering data structure generalization for maximum reuse.
3.6 Data Centric Principles
Organizations can prepare for future change by adopting our principals as a starting place to guide their data strategy goals. They are:
1. Focus data assets to efficiently and effectively support organizational strategy.
2. Increase the available resources by lowering the resources spent on maintenance activities.
3. Reduce organizational data ROT.
4. Remaining data will receive more ‘attention’ with respect to quality/security/reuse.
5. Reduce the amount and complexity of the organizational code-base.
6. Reduce the amount of time and effort and risk associated with IT projects.
7. Engineer flexibility and adaptability into data architectures instead of attempting to retrofit changes after they are in production.
8. Produce more, reusable data-focused work products.
9. When faced with a choice between chaos versus understanding, organizations will gravitate towards a cheaper, more understandable solution.
10. Same comment as point 9 when comparing complexity versus ease of implementation.
11. Decrease the time spend understanding versus time spent focused on data-centric strategy.
12. Reduce uncertain benefits and increase engineering-based benefit calculations.
When followed, these support data-centric development, helping to prepare for future change by implementing a flexible, adaptable, broadly useful data architecture.
3.7 Assessing Data Leveraging
Objective criteria need to be developed and used to assess whether your organization is objectively exploiting a data advantage. The assessment criterion consists of two parts: involvement and commitment. First there must be an organizational commitment to learn what it now doesn’t know. Second, it must commit to an ongoing program – results here must be measured across years not quarters.7 The first achievement is to demonstrate improving your ability to leverage data strategically.
An organization is objectively improving its data advantage if the organization is able to demonstrate that it has used objective data to improve its existing process. If it does this, then by definition, it must have an existing process that works.
This involves demonstrating: 1) that it is improving its people, processes, and technologies surrounding data management, and 2) it is using this knowledge to improve the effectiveness of “1”). Both are illustrated in Figure 3.10.

This sounds somewhat of a high standard but really just represents what should be best practices. If you have an important process incorporated into your organization, shouldn’t you periodically evaluate its continued use and effectiveness? In order to perform this analysis you need to understand the process well enough to get meaningful data from it. How otherwise would any process improvements be evaluated objectively?
3.8 Application Software/COTS Packages
Many readers who get to this point may say, “What of the commercial off the shelf (COTS) software packages?
Doesn’t our movement toward packages and ERP, etc. negate the effects of organizational data architecture?
If you are like most, your packages are driving your IT spend. Acquired under prior conditions (i.e. you inherited them), they are likely the focus of much IT management attention.
Your existing software application architecture is likely complex and was implemented in an application-centric manner. An immediate, useful role data architecture can play is a mapping function. Figure 3.11 illustrates this simplest, most-used form of mapping – the data architecture literally becomes the blueprint for the organizational integration activities.
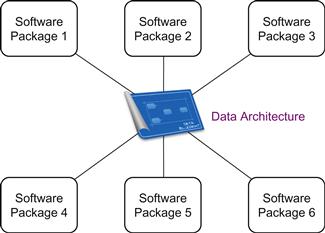
If your organization benefits from an ERP, SAAS or otherwise consolidated application solution you might be tempted to think that it plays the role of the data architecture. And it can – to the extent that your existing processes conform to the application’s internal picture of its processes. Unfortunately these are typically unknown. When known, they can provide portions of the architecture, usually transactionally focused. Application-centric architectures rarely offer direct data support of strategy. These components still need to be developed to understand your environment, holistically.
Data-centric practices can be most useful in these environments by guiding application package selection and evaluating proposed solution functionality. Ideally this should occur prior to any purchases but realistically must be implemented to impact subsequent implementations. Once you understand your existing data architecture, it is easy to identify processing gaps that can be filled by additional processing capabilities.
The first decision that data centrism can help you with is the build versus buy decision. The architecture will specify the data and provide information needed to contextualize and constrain the application requirements. Conventional wisdom dictates that packages are cheaper than evolving a legacy environment but now you will have information enabling you to make better informed build versus buy decisions. Armed with this information, many of our customers are choosing to build (at a lower cost) than acquiring packages. Either way the analysis has prevented over-investments in, mismatched software purchases.
When comparing among, and selecting from, potential applications, another data-centric practice requires offerors to present both physical and logical data models of their applications for comparison with the existing environment’s requirements. Failure to comply results in offerings being dropped from the ‘competition.’ Fact-based, data analysis of package compatibility can provide organizations with out-of-the-box matches with your existing environment, often speeding up implementation. In cases of imperfect requirements matches, the transformation costs required to either change organizational practices or modify the software can now be incorporated into existing selection criteria. Finally, architectural impacts can be formally evaluated and instances requiring software/architecture modification can be better-documented using data centrism techniques.
Software packages capture, manipulate, report, and update data. Metadata recovered from legacy software also often describes internal processes. While the percentage of ‘labels’ within a module attributable to fact-names versus process-names is not easily known, there can be an immediate improvement in the software understanding when the data facts are immediately available, contextually, and across the entire software module if supported by appropriate metadata practices.
Data leverage benefits extend beyond architecture engineering. Enhanced, too, are all forms of human understanding such as user-help processes, user guides, technical manuals, and other System Development Life Cycle work product/specifications.
Failure to use data centrism in a packages environment means that organizations are unable to benefit from specific, measureable integration characteristics – forcing decisions to be made on little or no available information about their data. Data centrism allows packaged environments to be evolved at a lower total cost of ownership than today’s application-centric environments.
3.9 Chapter Summary
This chapter covered: What data is; how leveraging data is a combined engineering/architectural discipline; how data leveraging is key to accomplishing data strategy; knowing when your organization reaches appropriate maturity; and that these concepts are particularly applicable in application-centric, package-heavy environments.
1“Data-based” refers to assets that are essentially information-based in nature. It is used in explicit contrast with the term “database,” which means all of the following: 1) the technology-based construct that contains data; 2) the Database Management System (DBMS) – software that stores, manages, updates, evolves, protects, and secures the database-contained data; and 3) the actual collection of data itself.
2It is an important goal – consider the question: How can you secure it, if you can’t manage it? and the associated implications for the information security industry.
3Consider how inappropriate “financial engineering” due to lack of governance contributed to the 2008 fiscal catastrophe – see (Lewis 2011).
4Some notable exceptions exist – DAMA International maintains an incomplete listing at http://www.dama.org/i4a/pages/index.cfm?pageid=3395
5See for example: http://globalids.com
6We are indebted to Douglas Bagley ([email protected]) for this conceptualization.
7Thanks to Lewis Broome for his advice; Don’t dabble in data management!