
CHAPTER
10
Creating the Data Warehouse Data Model from the Enterprise Data Model
Each of the previous chapters focused on the data model for a specific subject data area, namely parties, products, orders, shipments, work efforts, accounting, and human resources. These data models are essential for building not only a data warehouse but also any type of system because it is critical to understand the nature of the data and their relationships.
What is the process for using these data models to build a data warehouse? This chapter not only describes the transformation process, but also provides examples of each type of transformation by using the logical data models from the previous chapters as a basis.
The Data Warehouse Architecture
Before discussing how to convert the logical data models into a data warehouse, it is important to understand the three types of models involved in the transformation process from the operational environment to a decision support system:
- The enterprise data model
- The data warehouse design
- The departmental data warehouse design or data mart
The enterprise data model is an enterprise-wide view of the data and its relationships. It normally includes a high-level model that is an overview of each subject data area and the relationships between them, as well as logical data models for each subject data area. These models are the basis for developing both the enterprise's online transaction processing (OLTP) systems and its data warehouses. The models presented in the previous chapters could serve as a starting point for an enterprise's enterprise data model.
The data warehouse design is sometimes referred to as a data warehouse data model. It represents an integrated, subject-oriented, and very granular base of strategic information that serves as a single source for the decision support environment. This allows an architecture where information is extracted from the operational environment, cleansed, and transformed into a central, integrated enterprise-wide data warehouse environment. The data warehouse data model maintains this integrated, detailed level of information so that all the departments and other internal organizations of the enterprise can benefit from a consistent, integrated source of decision support information.
The Departmental Data Warehouse Design or Data Mart
The departmental data warehouse design is used to maintain departmental information that is extracted from the enterprise data warehouse. This is sometimes referred to as lightly and highly summarized data or as data marts. An example of a departmental data warehouse is the maintaining of a particular department's sales analysis information such as its product sales by customer, by date, and by sales representative. This department can create a departmental data warehouse and pull the information into its own data warehouse (or data mart) from the enterprise data warehouse.
Another department of the corporation, for example, the marketing department, may be interested in higher-level sales information across the enterprise such as sales by month, by product, and by geographic area. This department can create a departmental data warehouse design for its own purposes. Rather than building its own extraction, transformation, and cleansing routines against the operational systems to gather this information, it can rely on the enterprise data warehouse.
An Architected Data Warehouse Environment
By using this architected approach, as illustrated in Figure 10.1, the enterprise will avoid the pitfall of having each department extracting different views of the enterprise's information. These inconsistent extractions lead to more uninte-grated and inconsistent data. After all, the primary goal of decision support is to provide strategic, meaningful management information. The most ideal method of doing this is by focusing on developing integrated data; then, once this is done, passing it on to different departments that have various information needs.
Figure 10.1 Data warehouse architecture.

It is important to note that as the enterprise moves from the enterprise data model to the data warehouse data model to the departmental data warehouse, the models become more dependent on the particular enterprise. For instance, many parts of the logical data models in the prior chapters can be used by many different enterprises. The data warehouse data model is more specific to an enterprise because it is based on numerous assumptions concerning the type of decision support information that is considered useful to the enterprise. The departmental data warehouse is even more dependent on the specific needs of a department. Therefore, the data warehouse models presented later in this chapter and in subsequent chapters serve only as examples because each enterprise's data warehouse designs will be highly dependent on its own specific business needs.
This chapter will focus specifically on the transformation of the enterprise data model to the data warehouse data models. Chapter 11 provides an example of a data warehouse data model containing several subject areas. Chapters 12, 13, and 14 provide examples of departmental data models and illustrate various designs for structuring the departmental warehouse using the star schema representation for multidimensional analysis.
The point of departure for the design and construction of the data warehouse is the enterprise data model. Without a data model it is very difficult to organize the structure and content of data in the data warehouse.
The enterprise data model may cover a very wide scope; when it does, it is often called an enterprise data model (corporate data model is a synonym). On the other hand, a data model within an enterprise may cover a restricted scope; for instance, it may cover the information within a particular department or division. In either case—that of the enterprise data model or the data model for a part of the enterprise—the data model is the starting point for creating the data warehouse data model.
Many organizations have recognized the importance of the data model over the years and have invested the time and effort to build such a model. One of the problems with classical data modeling techniques is that there is no distinction between modeling for the operational and decision support environments. Classical data modeling techniques gather and synthesize the informational needs of the entire enterprise without consideration for the context of the information. The result of such a model is the enterprise data model, which tends to be very normalized.
The enterprise data model is a very good place to start the process of building a data warehouse. It provides a foundation for integration and unification at an intellectual level. Because the enterprise data model is not built specifically for the data warehouse, some amount of transformation is necessary to adapt it to the design to build the data warehouse data model.
To do the transformation from the enterprise data model to the data warehouse data model, the enterprise data model must have identified and structured, at least, the following:
- Major subjects of the enterprise
- Relationships between the subjects
- Definitions of the subject areas
- Logical data models for each subject data area (sometimes referred to as entity relationship diagrams)
Also, for each major logical data model, the following must be identified and structured:
- Entities
- Key(s) of the entity
- Attributes of the entity
- Subtypes of the entity
- Relationships between entities
Figure 10.2 identifies the minimum components of the enterprise data model.
Figure 10.2 The components of a data model.

The logical models in the previous chapters can be used as a starting point toward the development of an enterprise data model. The models presented represent many of the major subject data areas within enterprises. Each of the previous chapters of this book, Chapters 2-9, correspond roughly to a possible subject data area for an enterprise. For instance, there is often a PARTY subject data area, PRODUCT subject data area, and so on. Each enterprise needs to select the appropriate subject data areas for its specific business and add any other subject data areas needed.
Many more design and modeling components may be used in conjunction with an enterprise data model. For example, the enterprise may model the design and synthesis of processes as well. Process analysis typically consists of the following:
- Functional decomposition
- Data and process matrices
- Data flow diagrams
- State transition diagrams
- HIPO charts
- Pseudocode
These are generally included in an enterprise process model, as opposed to being part of the enterprise data model. This book addresses “universal data models,” but there is also a great need for “universal process models”—or templates to help develop these enterprise process models.
While these corporate process models are interesting to some, the process model usually is not of much interest to the data warehouse designer because the process analysis applies directly to the operational environment, not the data warehouse or the decision support system (DSS) environment. It is the enterprise data model that forms the backbone of design for the data warehouse, not the process models.
High-Level and Logical Data Models
As stated previously, the enterprise data model is usually divided into multiple levels—a high-level model and logical data models for each subject area. The high level of the enterprise data model contains the major subject areas and the relationship between the subject areas. Figure 10.3 shows a simple example of a high-level enterprise data model.
Figure 10.3 A simple example of a high-level model.

In Figure 10.3 there are five subject areas: party, order, product, shipment, and work effort. A direct relationship exists between party and order, order and work effort, order and shipment, and order and product. Of course, many indirect relationships are inferred from the highlevel data model, but only the direct relationships are shown. Note that the high-level enterprise data model does not contain any amount of detail at all; at this level, detail only clutters up the model unnecessarily.
The next level of modeling found in the enterprise data model is logical data modeling. Here is where much of the detail of the model is found. These models contain entities, keys, attributes, subtypes, and relationships, and they are fully normalized. Each of the previous chapters generally corresponds to a subject data area and includes a normalized logical data model for that area. There is a relationship between each subject area identified in the high-level model and the logical data models. For each subject area identified, there is a single logical data model, as shown in Figure 10.4
Figure 10.4 Each major subject area has its own mid-level model.

Note that in many organizations the logical data model is not fleshed out to the same level of detail. Some logical data models are completely designed and fully attributed, while other models are only sketched out, with little or no detail.
The degree of completion of the larger enterprise data model is of little concern to the data warehouse developer because the data warehouse will be developed iteratively, one stage at a time. In other words, it is very unusual to develop the data warehouse on a massive frontal assault, where all logical data models are developed at once. Therefore, the fact that the enterprise data model is in a state of differing degrees of readiness is not a concern to the data warehouse developer. Figure 10.5 shows that the data warehouse will be built one step at a time. First, one part of the data model (perhaps a particular subject data area such as “product”) is transformed and readied for data warehouse design, then another part of the data model is transformed, and so forth.
Figure 10.5 Each major subject area will be integrated one step at a time.

Once the enterprise has an enterprise data model, the transformation process into the data warehouse data model can begin. Following are a set of procedures for how to transform the enterprise data model to a data warehouse data model:
- Removal of purely operational data
- Addition of an element of time to the key structure of the data warehouse if one is not already present
- Addition of appropriate derived data
- Transformation of data relationships into data artifacts
- Accommodation for the different levels of granularity found in the data warehouse
- Merging of like data from different tables together
- Creation of arrays of data
- Separation of data attributes according to their stability characteristics
These activities serve as guidelines in creating the data warehouse data model. Transformation decisions should be based largely on the enterprise's specific decision support requirements. The following sections will discuss each of these aspects in detail.
The first task is to examine the enterprise data model and remove all data that is purely operational, as illustrated in Figure 10.6. The figure shows that some data found in the enterprise data model finds its way into the data model for the data warehouse. Some data, such as message, description, terms and status, usually apply to the operational environment. These should be removed as a first step in building the data warehouse data model. They are not removed from the logical data models; they are simply not useful in the data warehouse. Note that the box represents information about the INVOICE within the corporate data model and may be either an attribute such as message or description, or related information such as INVOICE TERM or INVOICE STATUS.
Figure 10.6 Removing data that will not be used for DSS processing.

The removal of operational data is seldom a straightforward decision. It always centers around the question, “What is the chance the data will be used for DSS?” Unfortunately, circumstances can be contrived such that almost any data can be used for DSS. A more rational approach is to ask, “What is the reasonable chance that the data will be used for DSS?”
The argument that can always be raised is that one never knows what is to be used for DSS because it always involves the unknown. On that basis, any and all data should be kept. The cost of managing volumes of data in the data warehouse environment, however, is such that it is patently a mistake not to weed out data that will be used for DSS only in farfetched or contrived circumstances.
Adding an Element of Time to the Warehouse Key
The second necessary modification to the enterprise data model is the addition of an element of time to the data warehouse key if one does not already exist, as shown in Figure 10.7.
Figure 10.7 Adding an element of time to the data warehouse data model.

In the figure, snapshot_date has been added as a key to the customer record. The enterprise data model has specified party information with only a party ID as the key. But in the warehouse, snapshots of customer-related party data are made because customer demographics may change over time. The effective date of those snapshots is added to the key structure. Note that there are many different ways to take these snapshots and a few common ways to add an element of time to the data warehouse key. The technique shown in the example is a common one.
Another common technique is the addition of a from and thru date to the key structure. This technique has the advantage of representing continuous data rather than snapshots at a specified point in time. An example of this technique is illustrated in the sample data warehouse data model in Figure 11.2
If data identified in the logical data model already has an element of time, such as a from datetime orthru datetime attribute, then there is no need to add another element of time to the data warehouse key structure.
The next transformation to the logical data models is the addition of derived data to the data warehouse data model where it is appropriate, as shown in Figure 10.8. The total_amount field is derived by multiplying the quantity times the amount field of the INVOICE.
Figure 10.8 Adding appropriate derived data.

As a rule, data modelers do not include derived data as part of the data modeling process. Logical models show only the data requirements of an enterprise. The reason for the omission of derived data in logical data models is that when derived data is included, certain processes are inferred regarding the derivation or calculation of that data. Derived data is added only to the physical database design for performance or ease of access reasons.
It is appropriate to add derived data to the data warehouse data model where the derived data is popularly accessed and calculated once. The addition of derived data makes sense because it reduces the amount of processing required on accessing the data in the warehouse. In addition, once properly calculated, there is little fear in the integrity of the calculation. Said another way, once the derived data is properly calculated, there is no chance that someone will come along and use an incorrect algorithm to calculate the data, thus enhancing the credibility of the data in the data warehouse.
Of course, any time that data is added to the data warehouse, the following question must be asked: “Is the addition of the data worth it?” The issue of volume of data in a data warehouse is such that every byte of data needs to be questioned. Otherwise, the data warehouse will quickly grow to unmanageable proportions.
Creating Relationship Artifacts
The data relationships found in classical data modeling assume that there is one and only one business value underlying the relationship (i.e., there is only one primary supplier for a product). For the assumption that data is accurate as of the moment of access (i.e., operational data), the classical representation of a relationship is correct. A data warehouse usually has many relationship values between tables of data because data in a warehouse represents data over a long spectrum of time; therefore, there will naturally be many relationship values over time (i.e., there are many product suppliers for a product over time). Thus, the classical representation of relationships between tables as found in classical data modeling is inadequate for the data warehouse. Relationships between tables in the data warehouse are achieved by means of the creation of artifacts.
One means of describing a relationship artifact is that it is the existence of a relationship that existed at one point in time and no longer exists. If one is married and gets a divorce, an alimony payment is an indication of a relationship artifact. It is the reminder of a relationship that used to exist and that no longer exists. For sales analysis purposes within businesses, old customer relationships are important to record in the data warehouse even though they may no longer exist in the operational system.
An artifact of a relationship that is maintained in the warehouse is merely that part of a relationship that is obvious and tangible at the moment the snapshot of data is made for the data warehouse. In other words, when the snapshot is made the data associated with the relationship that is useful and obvious will be pulled into the warehouse table.
The artifact may include foreign keys and other relevant data, such as columns from the associated table, or the snapshot may include only relevant data and no foreign keys. This is one of the most complex subjects facing the data warehouse designer. Consider the simple data relationship shown in Figure 10.9.
Figure 10.9 An operational relationship between product and supplier.

Figure 10.9 shows that there is a relationship between a PRODUCT and a SUPPLIER. This information is shown in Chapter 3, Figure 3.5, in the entities PRODUCT, SUPPLIER PRODUCT, and PREFERENCE TYPE. In the example, each PRODUCT has a primary SUPPLIER (a PREFERENCE TYPE of primary). Integrity constraints dictate that if a SUPPLIER (or organization) is deleted, a SUPPLIER PRODUCT record may not exist that has that SUPPLIER as the primary source. In other words, the information about who was the primary supplier is lost because the supplier record was deleted. The relationship represents an ongoing relationship of data that is active and accurate as of the moment of access.
Now consider how snapshots of data might be made and how the relationship information might be captured. Figure 10.10 shows a snapshot of PRODUCT and SUPPLIER data that might appear in the data warehouse.
Figure 10.10 Artifacts of the operational data relationship.

The PRODUCT snapshot table is one that is created periodically-at the end of the week, the end of the month, and so on. Much detailed information about a PRODUCT is captured at this time. One of the pieces of information that is captured is primary supplier name as of the moment of snapshot. Another artifact is the supplier location that is extracted from the supplier information found in the operational system at that point in time. Even if the enterprise stops doing business with a supplier and the supplier record is deleted, the data warehouse still maintains a history of the primary suppliers for the product. This, then, is an example of an artifact of a relationship being captured. Note that the relationship is accurate as of the moment of capture. No other implications are intended or implied.
The snapshot previously discussed has one major drawback: It is incomplete. It shows only the relationship as it exists as of some moment in time. Major events may have occurred that the snapshots never capture. For example, suppose the PRODUCT SNAPSHOT is made every week. A product may have had three primary suppliers during the week, yet the snapshot would never reflect this fact.
Snapshots are easy to make and are an essential part of the data warehouse, but they do have their drawbacks. To capture a complete record of data, an historical record rather than a snapshot is required for data in the data warehouse. Figure 10.11 shows an example of historical data in a data warehouse.
Figure 10.11 Another form of warehouse data is discrete historical data in which all activities are captured.

In the PRODUCT HISTORY table, a shipment has been received at the loading dock and relevant information is recorded. Among other things, the SUPPLIER of the PRODUCT is recorded. This is another form of artifact relationship information being recorded inside a data warehouse. Assuming that all deliveries have an historical record created for them, the record of the relationship between the two tables, over time, is complete.
One of the features of a data warehouse is the different levels of granularity. In some cases, the level of granularity does not change as data passes from the operational environment to the data warehouse environment. In other cases, the level of granularity does change as data is passed into the data warehouse. When there is a change in the level of granularity, the data warehouse data model needs to reflect those changes, as shown in Figure 10.12
Figure 10.12 Accommodating the different changes in granularity in going from the operations environment to the data warehouse environment.
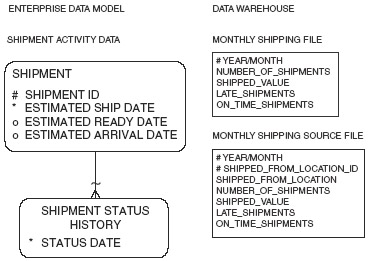
In the figure, the enterprise data model shows shipment activity data that is gathered each time a shipment is made. Due to the requirements specified by end users, data granularity is changed as the data passes into the data warehouse. Two summarizations of shipment data are made-the monthly summarization of total shipments and the summarization of shipments made by the shipped from location.
The issues in the changing of granularity (insofar as the data warehouse data modeler is concerned) revolve around the following questions:
- What period of time should be used to summarize the data (i.e., summarized by day, by week, by month, etc.)?
- What elements of data should be in the summarized table?
- Will the operational environment support the summarized data elements (i.e., has the data warehouse designer specified data in the warehouse that cannot be calculated from the operational data source)?
- What is the trade-off between keeping lower levels of granularity for detailed analysis versus the cost of storing those details? The costs include disk space, performance, and database management overhead, especially for very large databases (VLDB).
The next transformation consideration involves merging corporate tables into one data warehouse table, as illustrated in Figure 10.13.
Figure 10.13 Merging corporate data tables into a warehouse data model.

The figure shows two tables, INVOICEs and INVOICE_ ITEMs (the top two boxes), from an operational environment (see Chapter 7). The tables are normalized. As they are placed in the data warehouse environment, they are merged together. The merge can greatly improve query performance and can simplify the data structure by eliminating a commonly required join.
The conditions under which a merge makes sense are when the following situations occur:
- The tables share a common key (or partial key).
- The data from the different tables is used together frequently.
- The pattern of insertion is roughly the same.
If any one of these conditions is not met, it may not make sense to merge the tables together.
In the example given, the common portion of the key is invoice_id. In many situations the information in the two tables is used together and the pattern of insertion is exactly the same (i.e., there would be no need for an invoice without invoice items).
The next transformation activity is the consideration of the creation of arrays of data in the data warehouse data model. Data in the enterprise data model is usually normalized. This means that repeating groups are not shown as part of the data model. But, under the proper conditions, the data warehouse can and should contain repeating groups. Figure 10.14 shows an example creating a data warehouse data model containing arrays of data.
Figure 10.14 Under the right conditions, creating an array of data in the data warehouse data model is the correct design choice.

The enterprise data model has shown that the budget record (from BUDGET and BUDGET_ ITEMs in Chapter 8) is created on a month-by-month basis. However, as data goes into the data warehouse, it is organized into an array so that each month of the year is an occurrence of the array.
There are several benefits to this structuring of data. One is that by not having individual records of data for each month, a certain amount of space is saved. In the data warehouse case, the values budget_id and year appear in only one row for each year, while in the case of the enterprise data model, the values appear in 12 rows for each year (assuming that the budget period is monthly). The savings of this space may not be trivial at all. In some cases, it amounts to as much as 25 percent of the total space required for the table. In addition, the data warehouse structuring of data requires one twelfth the index entries as the enterprise data model structuring of data.
The other advantage is the possibility of organizing all yearly occurrences of data in a single physical location, creating the possibility of performance enhancement. This is due to a reduction in the number of physical inputs/outputs (I/Os) needed to retrieve the same data because many logical records are stored in one physical record. Whether this turns out to be a significant factor depends on many considerations, such as the use of data, which database management system (DBMS) is being used, the physical organization of the records within the DBMS, and so forth.
The creation of arrays of data is not a general-purpose option. Only under the correct circumstances does it pay off to create arrays of data in the data warehouse data model. Those conditions are as follows:
- When the number of occurrences of data are predictable
- When the occurrence of data is relatively small (in terms of physical size)
- When the occurrences of data are frequently used together
- When the pattern of insertion and deletion is stable
One of the interesting aspects of the data warehouse is that because the key structure of the data in the warehouse often contains an element of time and because the units of time occur predictably, then the techniques of arrays of data in a data warehouse table are peculiarly appropriate. In other words, there is a strong affinity between the technique of creating arrays of data in a single table and the data warehouse.
Organizing Data According to Its Stability
The final transformation technique is organizing data in the data warehouse according to its propensity for change. The enterprise data model makes little or no distinction in the rate of change of the variables contained inside a table. But a data warehouse is very sensitive to the rate of change of data within the warehouse. The optimal organization of data inside a data warehouse is where data in one table changes slowly and data in another changes rapidly. The reason for this is that if all the data for an entity is stored in only table with a snapshot, then a change to any of the values will necessitate making a copy of all the values. Rapidly changing values should be stored in a separate table to avoid many instances of the stable data.
An illustration of how this transformation works is shown in Figure 10.15. The figure shows that the enterprise data model has gathered some data for customers. That data is then divided into three categories-data that rarely changes, data that sometimes changes, and data that often changes. The data warehouse data structure finally ends up with structures that are compatible, in terms of volatility. This provides a mechanism to minimize the data within the warehouse, so that stable information such as date-of-birth doesn't have to be rerecorded each time a more rapidly changing attribute such as customer_status changes.
Figure 10.15 Data in the enterprise data model may be further divided according to its propensity for change.

THE ORDER OF APPLYING THE TRANSFORMATION CRITERIA
The order in which the transformation criteria are applied is as previously presented, with the removal of purely operational data first and the grouping of data according to stability last. Of course, as with every design process, a certain amount of iteration occurs. The order in which the transformation criteria is applied is not set in concrete. As a general guideline, though, the criteria should be applied as presented.
The enterprise data model is the basis for building the data warehouse. However the enterprise data model needs a fair amount of design activity as it is turned into a design for the data warehouse. The data warehouse data model is created from the enterprise data model by going through the following design activities, as they relate to user requirements:
- Removing all purely operational data
- Adding an element of time to the warehouse key if one isn't already there
- Adding appropriate derived data
- Creating relationship artifacts
- Accommodating the granularity changes in warehouse data
- Merging tables where appropriate
- Specifying arrays of data where appropriate
- Organizing data according to its stability
The next chapter will illustrate the design of a sample data warehouse data model using these principles.