
CHAPTER
11
A Sample Data Warehouse Data Model
Each enterprise has its own unique requirements regarding the types of information that are valuable for decision support. In general, though, the decision support environment provides information to illustrate trends, depict performance, and provide key business indicators in order to make informed strategic decisions.
There are a variety of decision support questions that many different departments across an enterprise may need to have answered, such as the following:
- How did sales representatives perform over different periods of time?
- What products are most popular to whom and when?
- What types of customers are buying what types of products?
- How much are the various internal organizations spending on what products?
- What were the variances between the amounts budgeted and the amounts spent?
- What positions are being filled by people with what types of backgrounds?
- What is the average pay for people within different age brackets or Equal Employment Opportunity Commission (EEOC) categories?
This chapter provides a sample data warehouse data model that answers these types of questions. The model was developed using the logical data models from Chapters 2 through 9 as a basis, then utilizing the principles outlined in Chapter 10 to perform the appropriate transformations. The model in this chapter will serve as the source for the data in the departmental models in Chapters 12, 13, and 14.
This data warehouse data model serves as the enterprise-wide source of decision support information. It is an integral piece for an architecture, as described in Chapter 10, that allows a central process for the extraction, cleansing, and transformation of data from the operational environment into the data warehouse environment. Using this approach, various departments with differing needs can use an integrated, consistent source of information to build departmental data warehouses or data marts.
Transformation to Customer Invoice
Two key factors are needed in describing the transformation of data from the operational environment to the data warehouse environment: the selection (or non-selection) of data and the transformation rules describing how the data is moved into the data warehouse.
This section gives an example of the transformation process used to develop the CUSTOMER_INVOICES subject data area of an enterprise-wide data warehouse data model in order to move toward the data warehouse design in Figure 11.1, which is a portion of the data warehouse design. Selection criteria and algorithms for extracting the data are provided solely for the purpose of illustrating the process. Remember, these selection criteria and algorithms may vary across enterprises based on business requirements.
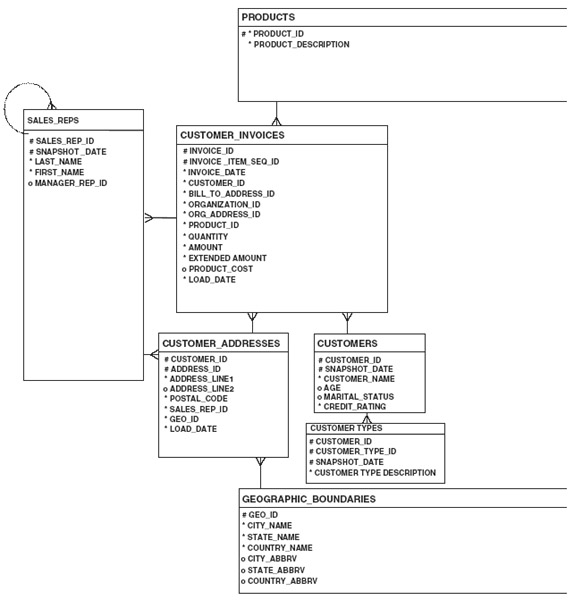
Figure 11.1 Beginning of data warehouse design.

The information in the CUSTOMER_INVOICES table is the result of transforming INVOICE and INVOICE_ITEM (see Chapter 7, Figure 7.1), according to the principles described in Chapter 10. Details of this process are outlined in the following sections.
First, any operational information, such as messages, descriptions, status, and invoice terms, was removed from INVOICE. This left invoice_id and invoice_date as part of the CUSTOMER_INVOICES data warehouse table. The column invoice_id was left to allow the user to do analysis on a specific transaction. Looking at the invoice items, taxable_flag was removed in this model because it was deemed not important for strategic sales management decisions (although some organizations may deem this as valid decision support information—again, these decisions are dependent on the enterprise involved). Therefore, product_id, quantity, and amount were left.
In order to make sure that the element of time is present, the invoice_date was left from the INVOICE entity. Because the table CUSTOMER_INVOICES represents particular invoice item transactions, it is not necessary to include the invoice_date as part of the key. The transaction itself is identified uniquely by the invoice_id and the invoice_item_seq_id and is not time-variant; in other words, the transaction information will not change over time. (This model assumes that the enterprise has a business rule that prevents invoice items from being updated once they are sent out. Any adjustments must be made as separate invoice items that may adjust the original invoice.)
The CUSTOMERS table includes demographics about a customer that can change over time. This table includes a snapshot_date as part of the key to provide for the storage of historical data and is discussed later in this chapter.
Figure 11.2 is a more complete data warehouse design and is discussed later in this chapter. The POSITIONS table in Figure 11.2 illustrates the use of another common technique to represent changes to data over time. It includes an effective date range as part of the key by using the columns from_date and thru_date. This is an appropriate technique when the data changes less frequently and changes over time need to be recorded. (The snapshot method gives information only at specific points in time, not for time intervals.)
Figure 11.2 Sample data warehouse design.

The extended amount column in the CUSTOMER_INVOICES table is included as a derived value. It was added because it can be calculated once and will be commonly accessed. The formula for calculating this field is amount∗ quantity.
Creating Relationship Artifacts
Where did the billed to_customer_id and billed_to_contact_mechanism in CUSTOMER_INVOICES come from? They were derived through the resolution of the billed to relationships described in the logical model (see Figure 7.2, 7.3a and 7.3b). Those relationships ultimately point a party ID either directly to a PARTY or through a BILLING ACCOUNT that has a BILLING ACCOUNT ROLE of role type “bill to customer” that is related to a PARTY (Figure 7.3a). In any case, for the purposes of this decision support model, the information required is the who and where portion of these relationships. In order to make the design more understandable for the DSS analyst or other end users, the column is called billed to_customer_id rather than party_id. The billed_to_customer_id is a foreign key to the customer_id columns in CUSTOMERS as well as CUSTOMER_ADDRESSES.
The billed_to_customer_id and billed_to_contact_mechanism identify the customer who was responsible for the bill and the contact mechanism of where the invoice was sent. For this model it was decided that billed to customer information was important to capture within the data warehouse. Other fields could be added if deemed valuable for decision support, such as using the party to whom the order was shipped as the customer or the party placing the order. This model could have included additional artifact information about the customer and their contact mechanisms in this entity; however, another design decision was made to store additional customer information in the CUSTOMER ADDRESSES and CUSTOMERS tables because this would reduce the overall storage space required (by reducing the amount of redundantly stored data). The customer address being stored is the primary work address for the customer.
Another question the DSS analyst may need to answer is this: Who were the sales representatives involved in the transaction? To answer this, there is a relationship to the SALES_REPS table from the CUSTOMER_INVOICES table. The salespersons can again be derived from the Invoice Role model of Figure 7.2, which shows that each INVOICE has INVOICE ROLE, of which one may be an INVOICE ROLE TYPE of “sales representative”. In this case, a relationship similar to customer/sales rep between an external organization (i.e., customer) and internal persons (i.e., sales reps or employees) needs to be traced.
The sales_rep_last_name and sales_rep_first_name columns could be included in CUSTOMER_INVOICES as data artifacts to allow for the occasions when the sales rep perhaps has left the enterprise. This model, however, includes the sales rep names in the SALES REPs table with snapshot dates to store what the name was and who the manager was at various points in time. This allows maintaining multiple sales reps for each invoice with a snapshot date that will probably correspond to the invoice date.
Additionally, if user requirements indicated that the names of the sales reps would be used frequently, then it would make the analysis simpler and more efficient by including these columns with the details and eliminating the need for a join to SALES_REPS to find the rep's name. In this way, the DSS analyst could more easily access the sales information by the sales rep's name. It would require more disk space for storage, however, and also require a design decision to maintain a preestablished number of names.
Who was the manager of the sales rep at the time of the transaction? The column manager_rep_id in the SALES REPS table provides this data through a recursive relationship. This column indicates the party id for the sales rep's manager at the current time. Because this relationship can change over time, the snapshot date on the SALES REPS table allows capturing who the manager was at various points in time. To make analysis easier, a manager_last_name and manager_first_name could have also been stored as artifacts in the CUSTOMER_INVOICE, if user requirements so indicated. These fields were stored in the SALES REPS table to reduce storage requirements (instead of storing them redundantly for every CUSTOMER INVOICE record) and to allow for the possibility of multiple sales reps and managers.
Assuming the models from this book have been implemented, the manager ID can be obtained from the operational data by examining the POSITION REPORTING STRUCTURE (see Figure 9.6). This data can be derived by determining the party ID of the person holding the position that is “reported to” by the position that the sales rep is currently filling. The recursive foreign key shown on the SALES_REP table is meant to indicate that the manager_rep_id will exist as a sales_rep_id in the SALES_REP table. This model assumes then that all sales rep managers are also sales reps themselves. In addition, this recursive relationship could be used for a higher-level grouping by which sales data could be summarized (i.e., a salesperson may report to a local manager who may report to a regional manager). Because the only information stored by this model is first_name and last_name, this relationship also saves the overhead of having an additional table for the manager information (this may or may not be a benefit, depending on the DBMS being used).
The internal_organization_id and internal_organization_name columns in CUSTOMER_INVOICES provide a mechanism for tracking which internal organization is responsible for the sale. The party is derived from tracing the billed from relationship from INVOICE to INTERNAL ORGANIZATION in Figure 7.3b. If internal organizational information changes quickly, the designer may also consider storing artifacts of additional internal organization information in the CUSTOMER_INVOICES table.
The product_cost is a derived field based on relationship artifacts. It represents what the actual product cost was at the time of the sale. Some of the information for item costs can be selected by traversing the relationships from INVOICE ITEM to the associated costs of the item that is being invoiced. This can be a complex field to derive because the costs may be stored in various parts of the model, such as the PURCHASE ORDER ITEM amount (see Chapter 4), the actual ship cost in the SHIPMENT (see Chapter 5), or the cost maintained as a rate in that are applied through TIME ENTRYs in WORK EFFORTs (see Chapter 6). This is further complicated by the applications of various costing methods [i.e., First In First Out (FIFO), Last In First Out (LIFO), or average cost] to determine the product cost. The INVOICE ITEM entity stores the quantity and amount as well as any INVOICE ADJUSTMENTS (see Figure 7.1b) that provide some of the information necessary to determine the costs of purchased items. While this example provides some of the selection criteria involved, the algorithms involved in determining product costs can be quite complex and are highly dependent on the business rules of the enterprise in terms of how they calculate costs.
Accommodating Levels of Granularity
By storing sales information at an invoice item level in the CUSTOMER_INVOICES table, the enterprise has chosen to maintain the lowest level of granularity in its enterprise data warehouse. In other words, the data is stored at the transaction level and cannot be further subdivided. This allows departmental data warehouses the ability to summarize the sales information at whatever level of detail is required because the most detailed level of data (sometimes referred to as atomic level) is present in the data warehouse data model.
In some cases, it may be prudent to store multiple levels of granularity in an enterprise warehouse. This should be done only if there are good business reasons and requirements available to define the additional levels. If real requirements are not known, then the space required to store these extra levels, and the resources to build them, may be wasted. When it is known that the warehouse will be used to feed departmental warehouses, it is best to defer the definition of higher levels of granularity to the designers of these data marts. Then the specific requirements of the department can be used in producing meaningful summaries.
As implied from the previous sections, the basis for CUSTOMER_INVOICES was the merging of the INVOICE and INVOICE ITEM entities. This was done on the basis that the two tables shared a common key (i.e., invoice_id), the data from the different tables is used together frequently, and the pattern for insertion is the same for both tables.
In the CUSTOMERS table, the snapshot_date column, which is part of the primary key, provides the ability to maintain a history of some of the more volatile demographics associated with each customer. If some of this data was more volatile, such as age and credit rating, it could have been separated into a CUSTOMER_DEMOGRAPHICS table to save space. This would have illustrated the concept of separation of data attributes according to its stability.
The customer information can be directly extracted from the operational systems of the enterprise. In terms of the models presented in this book, this data comes from the PARTY entity as described in Chapter 2. The data could be extracted by gathering all the parties that had a PARTY ROLE TYPE of “bill to customer”. In the case of a customer that is an organization or company, the column customer_name is derived from ORGANIZATION name of the PARTY and, more specifically, the ORGANIZATION that was billed for the INVOICE. If the customer is a person, then the current first name and current last name from the PERSON entity would be combined into the name column (in which order will need to be determined by detailed enterprise-specific transformation rules).
The load_date in CUSTOMER_INVOICES identifies the date that data was loaded into the data warehouse. This provides the ability to replace some records in the data warehouse with more up-to-date information if there are changes in the operational environment that affect history.
As may be obvious by the discussion so far, even though the design of the tables for the warehouse may be simple, getting the data into the proposed format could be quite an ominous task. Considering that the data may be coming from many separate source systems, there could be a need to scrub (or clean) the data and integrate it, as well as transform it into the warehouse model. For example, customer data may exist in two operational systems running on different platforms. Getting this information into one warehouse table will require careful examination of the data to see where the two systems match and where they do not. Then processes must be developed to convert that data into a common format that fits in the warehouse.
This point is precisely why a properly designed data warehouse can be of such incredible benefit to executives and analysts in an enterprise. It can allow them to view data and trends in ways that were not possible before without a substantial amount of time and effort on the part of the IS staff. With the data prearranged as described, the amount of time and system resources needed to process the various reports is also reduced.
The Sample Data Warehouse Data Model
Figure 11.2 illustrates an example of a data warehouse data model to support the information needs across an enterprise. This model illustrates the idea that while a data warehouse data model may start with a single subject data area, other subject areas may be integrated as time moves forward.
This sample data warehouse model builds on the previous section's customer invoicing model and integrates other subject data areas into the model. In particular, human resources, budget, and purchasing information has been added to the model.
Notice that while this model may contain a large part of the information that an enterprise may find useful for decision support, it is not all-inclusive. For instance, it doesn't cover all financial information, work efforts, or ordering and shipment information. This model illustrates the principle that the data warehouse is developed iteratively and other subject areas may be integrated, one at a time, into this model over time. Three subject data areas are integrated and included in this model:
- Sales analysis. This decision support information is primarily provided via the PRODUCTS, CUSTOMER_INVOICES, SALES_REPS, CUSTOMER_ADDRESSES, CUSTOMERS, and GEOGRAPHIC_BOUNDARIES tables.
- Budgeting and purchasing. This decision support information is provided via the PRODUCTS, PRODUCT_SNAPSHOTS, PURCHASE_INVOICES, SUPPLIER_ADDRESSES, BUDGET_DETAILS, INTERNAL_ORG_ADDRESSES, and GEOGRAPHIC_BOUNDARIES tables.
- Human resources. This decision support information is provided through the INTERNAL_ORG_ADDRESSES, POSITIONS, and EMPLOYEES tables.
Notice in Figure 11.2 that certain tables span subject data areas and are useful for several departmental views of data. The GEOGRAPHIC_BOUNDARIES table is useful to identify the types of boundaries included in different types of analysis. Notice that geo_id is present in several tables such as the CUSTOMER_ADDRESSES, SUPPLIER_ADDRESSES, and INTERNAL_ORG_ADDRESSES. The GEOGRAPHIC_BOUNDARIES table provides the look-up information linked to geo_id. This table can be used for extracting data based on city, state, or country (this will be discussed in future chapters). Because this information is maintained in a central prescrubbed decision support environment, it can be easily extracted into various departmental data marts (thus ensuring consistency across the data marts).
The PRODUCTS table is another example of standard information that may be used in purchasing, sales, and budgeting departmental data marts. The products sold are very often the products purchased, especially in retail and distribution organizations. For instance, a distributor may purchase a certain type of pencil in order to resell it. The fact that this information is being transformed only once from the operational environment to the data warehouse can save a great deal of development time in the long run and can lead to better quality decision support information.
This chapter has discussed details of the design of a sample data warehouse built to support the enterprise's needs. The methods discussed in Chapter 10 for transforming a corporate data model to a data warehouse model were applied specifically to the logical data models related to invoicing as presented in this book. The resulting data warehouse design contains some denormalization and various levels of granularity to assist in answering questions posed by the enterprise. The data warehouse data model as presented could be used as a starting point for developing departmental models for use in DSS, online analytical processing (OLAP), and multidimensional analysis. Some examples of these models are presented in the next three chapters.
It should be noted that what has been presented is one of many possible warehouse designs that could result from transforming the logical data models. The structure of a data warehouse will be influenced greatly by the questions it is designed to answer. If the corporate end users are asked enough questions during analysis, then the resulting design should provide the enterprise with the information it needs. If this does not occur, then more questions must be asked and another design developed. This is why it has been said that building a data warehouse is an iterative process.
Please refer to Appendix B for a listing of tables and columns for this data warehouse design. SQL scripts to build tables and columns derived from this data warehouse design can be found on the full-blown CD-ROM, which is licensed separately.