
5 DML Insights
At some point you have to decide whether you’re going to be a politician or an engineer. You cannot be both. To be a politician is to champion perception over reality. To be an engineer is to make perception subservient to reality. They are opposites. You can’t do both simultaneously.—H. W. Kenton
As I said in the previous chapter, the goal of this book is not to rehash SQL Server’s online documentation. Instead, I assume you’ll refer frequently to the Books Online (BOL), as do most people who work regularly with the product.
With this in mind, this chapter doesn’t attempt to cover Transact-SQL DML (Data Manipulation Language) commands exhaustively. Instead, the goal here is to get beyond the obvious and provide DML tips, tricks, and techniques that go beyond the BOL. I would rather spend the limited pages in this book covering material with at least a modicum of originality—and hopefully even transcendence occasionally—than merely paraphrase what is only a couple of mouse clicks away for you anyway.
DML statements manipulate data—they delete it, update it, add to it, and list it. Transact-SQL DML syntax includes the INSERT, UPDATE, and DELETE commands. Technically, SELECT is also a DML command, but it’s so all-encompassing and so ubiquitous in mainstream Transact-SQL development that it’s been allotted its own chapter (see Chapter 6, “The Mighty SELECT Statement”).
There are four basic forms of the Transact-SQL INSERT statement; each has its own nuances. Here’s the first and simplest form:
INSERT [INTO] targettable [(targetcolumn1[,targetcolumn2])]
VALUES (value1[,value2...])
As with the other forms of the command, the INTO keyword is optional. Unless you’re only supplying values for specific columns, the target column list is also optional. Items in the VALUES clause can range from constant values to subqueries. Here’s a simple INSERT example:
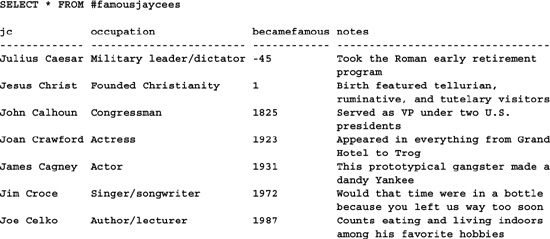
CREATE TABLE #famousjaycees
(jc varchar(15),
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL)
INSERT #famousjaycees VALUES (’Julius Caesar’,’Military leader/dictator’,
-0045,’Took the Roman early retirement program’)
INSERT #famousjaycees VALUES (’Jesus Christ’,’Founded Christianity’,
0001,’Birth featured tellurian, ruminative, and tutelary visitors’)
INSERT #famousjaycees VALUES (’John Calhoun’,’Congressman’,
1825,’Served as VP under two U.S. presidents’)
INSERT #famousjaycees VALUES (’Joan Crawford’,’Actress’,
1923,’Appeared in everything from Grand Hotel to Trog’)
INSERT #famousjaycees VALUES (’James Cagney’,’Actor’,
1931,’This prototypical gangster made a dandy Yankee’)
INSERT #famousjaycees VALUES (’Jim Croce’,’Singer/songwriter’,
1972,’Would that time were in a bottle because you left us way too soon’)
INSERT #famousjaycees VALUES (’Joe Celko’,’Author/lecturer’,
1987,’Counts eating and living indoors among his favorite hobbies’)
To insert a default value for columns with default constraints, attached default objects, those that allow NULL values, or timestamp columns, use the DEFAULT keyword in place of an actual value. DEFAULT causes columns with associated default constraints to receive their default values during the INSERT. When DEFAULT is specified with a NULLable column that doesn’t otherwise have a default value, the column is set to NULL. Timestamp columns get the database’s next timestamp value.
To specify explicitly a NULL value for a column that allows NULLs, use the NULL keyword. If you specify NULL for a column that doesn’t allow NULLs (or DEFAULT for a NOT NULL column without a default), your INSERT will fail. Here’s an example that illustrates DEFAULT and NULL:
INSERT #famousjaycees
VALUES (’Julius Caesar’,’Military leader/dictator’,DEFAULT,NULL)
SELECT * FROM #famousjaycees
(Results abridged)
jc occupation becamefamous notes
------------- ------------------------ ------------ ---------------------------
Julius Caesar Military leader/dictator 0 NULL
Note that, contrary to the Books Online, you’re not always required to supply a value for every column in the target column list (or every column in the table if the INSERT doesn’t have a column list). Identity columns may be safely omitted from any INSERT statement—even those with target column lists. This is true regardless of where the identity column appears in the table. Here’s an example:
CREATE TABLE #famousjaycees
(jcid int identity, -- Here, we’ve added an identity column
jc varchar(15),
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL
)
-- Notice that we omit it from list of values
INSERT #famousjaycees VALUES (’Julius Caesar’,’Military
leader/dictator’,DEFAULT,NULL)
SELECT * FROM #famousjaycees
(Results abridged)
jcid jc occupation becamefamous notes
----------- ------------- ------------------------ ------------ ----------------
1 Julius Caesar Military leader/dictator 0 NULL
Not only are identity columns optional, but you are not allowed to specify them unless the SET IDENTITY_INSERT option has been enabled for the table. SET IDENTITY_INSERT allows values to be specified for identity columns. It’s handiest when loading data into a table that has dependent foreign keys referencing its identity column.
Unlike timestamp columns and columns with defaults, you may not specify a default value for an identity column using the DEFAULT keyword. You can’t include a value of any type for an identity column unless SET IDENTITY_INSERT has been enabled. Here’s an example that features SET IDENTITY_INSERT:
SET IDENTITY_INSERT #famousjaycees ON
INSERT #famousjaycees (jcid,jc,occupation,becamefamous,notes)
VALUES (1,’Julius Caesar’,’Military leader/dictator’,DEFAULT,NULL)
SET IDENTITY_INSERT #famousjaycees OFF
SELECT * FROM #famousjaycees
jcid jc occupation becamefamous notes
----------- ------------- ------------------------ ------------ ----------------
1 Julius Caesar Military leader/dictator 0 NULL
Note the inclusion of a target column list—it’s required when you specify a value for an identity column.
The second form of the command allows default values to be specified for all columns at once. It looks like this:
INSERT [INTO] targettable DEFAULT VALUES
Here’s a simple example:
CREATE TABLE #famousjaycees
(jc varchar(15) DEFAULT ’’,
occupation varchar(25) DEFAULT ’Rock star’,
becamefamous int DEFAULT 0,
notes text NULL
)
INSERT #famousjaycees DEFAULT VALUES
SELECT * FROM #famousjaycees
jc occupation becamefamous notes
----------- ---------- ------------ --------------------------------------------
Rock star 0 NULL
Here, default values are specified for all the table’s columns at once. As with the first form, if you use DEFAULT VALUES with columns that do not have defaults of some type defined, your INSERT will fail. Note that a target column list is illegal with DEFAULT VALUES. If you supply one (even if it includes all the columns in the table), your INSERT will fail.
As with the DEFAULT value keyword, DEFAULT VALUES supplies NULLs for NULLable fields without defaults. And no special handling is required to use it with identity columns—it works as you would expect.
The third form of the INSERT command retrieves values for the table from a SELECT statement. Here’s the syntax:
INSERT [INTO] targettable [(targetcolumn1[,targetcolumn2])]
SELECT sourcecolumn1[,sourcecolumn2]
[FROM sourcetable...]
Since Transact-SQL’s SELECT statement doesn’t require that you include a FROM clause, the data may or may not come from another table. Here’s an example:

This example uses a UNION to add a row to those already in the source table.
The fourth form of the INSERT command allows the result set returned by a stored procedure or a SQL statement to be “trapped” in a table. Here’s its syntax:
INSERT [INTO] targettable [(targetcolumn1[,targetcolumn2])]
EXEC sourceprocedurename
--or--
EXEC(’SQL statement’)
And here’s an example of how to use it:

The ability to load the results of a SQL command into a table affords a tremendous amount of power and flexibility in terms of formatting the result set, scanning it for a particular row, or performing other tasks based on it.
This facility also supports loading the results of extended procedures into tables, though only output from the main thread of the extended procedure is inserted. Here’s an example using an extended procedure:
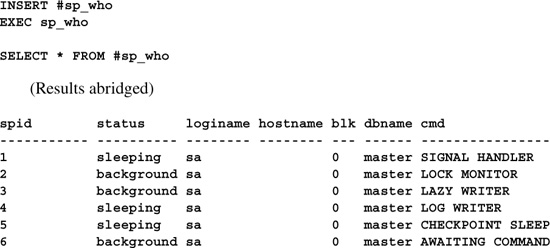
USE master
IF OBJECT_ID(’sp_listfile’) IS NOT NULL
DROP PROC sp_listfile
GO
CREATE PROCEDURE sp_listfile @filename sysname
AS
IF (@filename IS NULL) RETURN(-1)
DECLARE @execstr varchar(8000)
SET @execstr=’TYPE ’+@filename
CREATE TABLE #filecontents
(output varchar(8000))
INSERT #filecontents
EXEC master..xp_cmdshell @execstr
SELECT * FROM #filecontents
DROP TABLE #filecontents
GO
(Results abridged)
EXEC sp_listfile ’D:MSSQL7INSTALLREADME.TXT’
output
--------------------------------------------------------------------------------
****************************************************************
SQL SERVER 7.0 README.TXT
***************************************************************
This file contains important information that you should read
prior to installing Microsoft(R) SQL Server(TM) version 7.0.
It also contains information about the following SQL Server
topics that does not appear in SQL Server Books Online:
One interesting characteristic of the INSERT command is its imperviousness to fatal command batch errors. An INSERT that fails due to a constraint or invalid duplicate value will not cause the command batch to fail. If a group of INSERTs are executed within a command batch and one of them fails, the other INSERTs will not be affected. This is as it should be; otherwise, loading large amounts of data using INSERT statements would be greatly complicated.
If you want the whole command batch to fail when an INSERT fails, check the @@ERROR automatic variable after each INSERT and respond accordingly. Here’s an example:
CREATE TABLE #famousjaycees
(jc varchar(15) UNIQUE, -- Define a UNIQUE constraint
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL)
INSERT #famousjaycees VALUES (’Julius Caesar’,’Military leader/dictator’,
-0045,’Took the Roman early retirement program’)
IF (@@ERROR <>0) GOTO LIST
-- Now attempt to insert a duplicate value
INSERT #famousjaycees VALUES (’Julius Caesar’,’Military leader/dictator’,
-0045,’Took the Roman early retirement program’)
IF (@@ERROR <>0) GOTO LIST
INSERT #famousjaycees VALUES (’Jesus Christ’,’Founded Christianity’,
0001,’Birth featured tellurian, ruminative, and tutelary visitors’)
IF (@@ERROR <>0) GOTO LIST
INSERT #famousjaycees VALUES (’John Calhoun’,’Congressman’,
1825,’Served as VP under two U.S. presidents’)
IF (@@ERROR <>0) GOTO LIST
INSERT #famousjaycees VALUES (’Joan Crawford’,’Actress’,
1923,’Appeared in everything from Grand Hotel to Trog’)
IF (@@ERROR <>0) GOTO LIST
INSERT #famousjaycees VALUES (’James Cagney’,’Actor’,
1931,’This prototypical gangster made a dandy Yankee’)
IF (@@ERROR <>0) GOTO LIST
INSERT #famousjaycees VALUES (’Jim Croce’,’Singer/songwriter’,
1972,’Would that time were in a bottle because you left us way too soon’)
IF (@@ERROR <>0) GOTO LIST
INSERT #famousjaycees VALUES (’Joe Celko’,’Author/lecturer’,
1987,’Counts eating and living indoors among his favorite hobbies’)
LIST:
SELECT * FROM #famousjaycees
Server: Msg 2627, Level 14, State 2, Line 0
Violation of UNIQUE KEY constraint ’UQ__#famousjaycees__160F4887’. Cannot insert
duplicate key in object
’#famousjaycees_________________________________________________________________
_____________________________________00000000002E’.
The statement has been terminated.
jc occupation becamefamous notes
------------- ------------------------ ------------ --------------------
Julius Caesar Military leader/dictator -45 Took the Roman early
retirement program
On a related note, another interesting aspect of the INSERT command is its ability to remove duplicate rows by way of a unique index with the IGNORE_DUP_KEY option set. That is, if you insert a set of rows into a table with an IGNORE_DUP_KEY index, rows that violate the index’s unique constraint will be rejected without causing the other inserts to fail. So, in order to remove duplicate rows from a table, you can create a work table that’s identical in structure to it, then build an IGNORE_DUP_KEY index over the second table that includes all the first table’s candidate keys and insert the table’s rows into it. Here’s an example:
CREATE TABLE #famousjaycees
(jc varchar(15),
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL)
INSERT #famousjaycees VALUES (’Julius Caesar’,’Military leader/dictator’,
-0045,’Took the Roman early retirement program’)
-- Include a duplicate value for the sake of illustration
INSERT #famousjaycees VALUES (’Julius Caesar’,’Military leader/dictator’,
-0045,’Took the Roman early retirement program’)
INSERT #famousjaycees VALUES (’Jesus Christ’,’Founded Christianity’,
0001,’Birth featured tellurian, ruminative, and tutelary visitors’)
INSERT #famousjaycees VALUES (’John Calhoun’,’Congressman’,
1825,’Served as VP under two U.S. presidents’)
INSERT #famousjaycees VALUES (’Joan Crawford’,’Actress’,
1923,’Appeared in everything from Grand Hotel to Trog’)
INSERT #famousjaycees VALUES (’James Cagney’,’Actor’,
1931,’This prototypical gangster made a dandy Yankee’)
INSERT #famousjaycees VALUES (’Jim Croce’,’Singer/songwriter’,
1972,’Would that time were in a bottle because you left us way too soon’)
INSERT #famousjaycees VALUES (’Joe Celko’,’Author/lecturer’,
1987,’Counts eating and living indoors among his favorite hobbies’)
CREATE TABLE #famousjaycees2
(jc varchar(15),
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL)
CREATE UNIQUE INDEX removedups ON #famousjaycees2 (jc,occupation,becamefamous)
WITH IGNORE_DUP_KEY

Notice that we can’t include the notes column in the index because, as a text column, it’s not a valid index key candidate. This notwithstanding, the inclusion of the other columns still provides a reasonable assurance against duplicates.
A table without a clustered index is known as a heap table. Rows inserted into a heap table are inserted wherever there’s room in the table. If there’s no room on any of the table’s existing pages, a new page is created and the rows are inserted onto it. This can create a hotspot at the end of the table (meaning that users attempting simultaneous INSERTs on the table will vie for the same resources). To alleviate the possibility of this happening, you should always establish clustered indexes for the tables you build. Consider using a unique key that distributes new rows evenly across the table. Avoid automatic, sequential, clustered index keys as they can cause hotspots, too. Going from a heap table to a clustered index with a monotonically increasing key is not much of an improvement. Also avoid nonunique clustered index keys. Prior to SQL Server 7.0, they caused the creation of overflow pages as new rows with duplicate keys were inserted, slowing the operation and fragmenting the table. Beginning with version 7.0, a “uniqueifier” (a four-byte sequence number) is appended to each duplicate clustered index key in order to force it to be unique. Naturally, this takes some processing time and is unnecessary if you use unique keys in the first place. As with all indexing, try to use keys that balance your need to access the data with your need to modify it.
In addition to standard INSERTs, Transact-SQL supports bulk data loading via the BULK INSERT command. BULK INSERT uses the BCP (Bulk Copy Program) facility that’s been available in SQL Server for many years. Prior to its addition to Transact-SQL, developers called the external bcp utility using xp_cmdshell or accessed the Distributed Management Objects (DMO) API in order to bulk load data from within Transact-SQL. With the addition of the BULK INSERT command to the language itself, this is now largely unnecessary. Here’s an example:

BULK INSERT circumvents SQL Server’s trigger mechanism. When you insert rows via BULK INSERT, INSERT triggers do not fire. This is because SQL Server’s BCP facility avoids logging inserted rows in the transaction log if possible. This means that there’s simply no opportunity for triggers to fire. There is, however, a workaround that involves using a faux update to force them to fire. See the section “Using UPDATE to Check Constraints” later in the chapter for more information.
Declarative constraints, by contrast, can be enforced via the inclusion of BULK INSERT’s CHECK_CONSTRAINTS option. By default, except for UNIQUE constraints, the target table’s declarative constraints are ignored, so include this option if you want them enforced during the bulk load operation. Note that this can slow down the operation considerably.
Another salient point regarding BULK INSERT is the fact that, by default, it causes identity column values to be regenerated as data is loaded. Obviously, if you’re loading data into a table with dependent foreign key references, this could be catastrophic. To override this behavior, include BULK INSERT’s KEEPIDENTITY keyword.
UPDATE has two basic forms. One is used to update a table using static values, the other to update it using values from another table. Here’s an example of the first form:

And here’s one of the second:
CREATE TABLE #semifamousjaycees
(jc varchar(15),
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL)
INSERT #semifamousjaycees VALUES (’John Candy’,’Actor’,
1981,’Your melliferous life was all-too brief’)
INSERT #semifamousjaycees VALUES (’John Cusack’,’Actor’,
1984,’Uttered, "Go that way, very fast"’)
INSERT #semifamousjaycees VALUES (’Joan Cusack’,’Actress’,
1987,’Uncle Fester"s avaricious femme fatale’)
UPDATE f
SET jc=s.jc,
occupation=s.occupation,
becamefamous=s.becamefamous,
notes=s.notes
FROM #famousjaycees f
JOIN #semifamousjaycees s ON (f.becamefamous=s.becamefamous)
SELECT * FROM #famousjaycees

Notice the use of an alias to reference the target of the UPDATE. The actual table is named in the FROM clause. Also note the join between the two tables. It’s constructed using normal ANSI SQL-92 join syntax and allows values to be easily located in the UPDATE’s source table.
The situation where an updated row moves within the list of rows being updated during the update, and is therefore changed erroneously multiple times, is known as the Halloween Problem. In the early days of DBMSs, this was a common occurrence because vendors usually performed a group of updates one row at a time. If the update changed the key column on which the rows were sorted, it was likely that a row would move elsewhere in the group of rows, perhaps to a location further down in the group, where it would be changed yet again. For example, consider this code:
UPDATE sales
SET qty=qty*1.5
Provided that the server didn’t otherwise handle it and provided that the result set was sorted in descending order on the qty column, each update could cause the row to move further down in the result set, resulting in it being updated repeatedly as the UPDATE traversed the table—a classic case of the Halloween Problem. Fortunately, SQL Server recognizes situations where the Halloween Problem can occur and automatically handles them. The Row Operations Manager ascertains when encountering row movement problems and other types of transient errors such as the Halloween Problem is likely (updates to primary keys and foreign keys are examples) and takes steps to avoid them.

Note
Note that deferred updates, the approach SQL Server took to deal with row movement problems prior to version 7.0, are no longer used. In many cases, these were more trouble than they were worth, and many SQL Server practitioners are glad to see them go.
It might seem likely that the combination of a primary key update and an update trigger would increase the likelihood of the Halloween Problem occurring. After all, the trigger would see the data as it’s being changed, right? Wrong. SQL Server triggers fire once per statement, not per row, and have access only to the before and after picture of the data, not to any of the interim stages it might have gone through during the update.
This may seem counterintuitive since triggers appear to execute in conjunction with the DML statement that fires them, but that’s not the case. A trigger’s code is not compiled into the execution plan for the INSERT, UPDATE, or DELETE that fires it. Rather, it’s compiled and cached separately so that it’s available for reuse regardless of what causes it to fire. The execution plan for a DML statement branches to any triggers it fires just before it terminates, after its work is otherwise complete.
Note that this isn’t true of constraints. Steps are added directly to the DML execution plan for each of a table’s constraints.
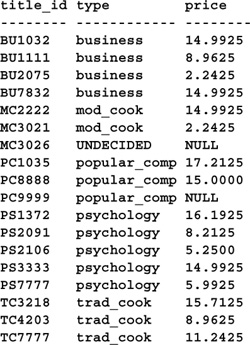
You can use a CASE expression to code some fairly sophisticated changes to a table via UPDATE. Using CASE allows you to embed program logic in the UPDATE statement that would otherwise require arcane function expressions or separate UPDATEs and flow-control syntax. Here’s an example:
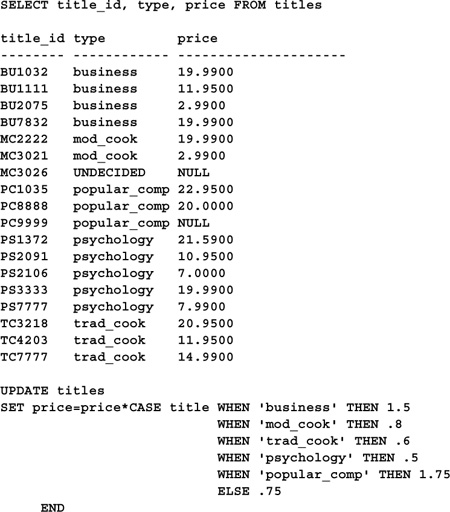
SELECT title_id, type, price FROM titles
If you use BULK INSERT or any of the other bulk load facilities that SQL Server provides to append data to a table that has an associated INSERT trigger, you’ll notice that the trigger does not fire. Also, even though BULK INSERT can be made to respect declarative constraints, you may find that this slows the operation down to a relative crawl. It will probably be significantly faster to ignore the table’s constraints during the load. One option here is to check constraints and triggers manually after the operation. This requires separate code for each constraint and trigger and a lot of effort not to make any mistakes. Another, and perhaps better, way is to issue a bogus update against the table in question once the operation completes. This fake update simply sets each column’s value to itself. This causes triggers to fire and constraints to be checked. If any of the rows contain bad data, the UPDATE will fail. Here’s an example:
CREATE TABLE famousjaycees
(jc varchar(15) CHECK (LEFT(jc,3)<>’Joe’), -- Establish a check constraint
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL)
-- Assume the file was previously created
BULK INSERT famousjaycees FROM ’D:GG_TSfamousjaycees.bcp’
-- Check that the miscreant is in place
SELECT * FROM famousjaycees
-- Now do the faux update
UPDATE famousjaycees
SET jc=jc, occupation=occupation, becamefamous=becamefamous, notes=notes

The statement has been terminated.
As you can see, the error message indicates the database, table, and column in which the bad data resides, so you have some basic information to begin locating the invalid data.
You can use the TOP n option of the SELECT command to limit the number of rows affected by an UPDATE. This SELECT is embedded as a derived table in the UPDATE’s FROM clause and joined with the target table, like so:
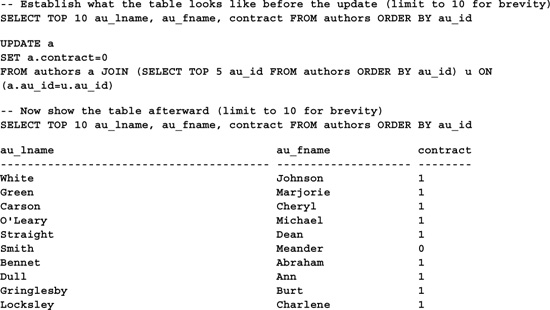

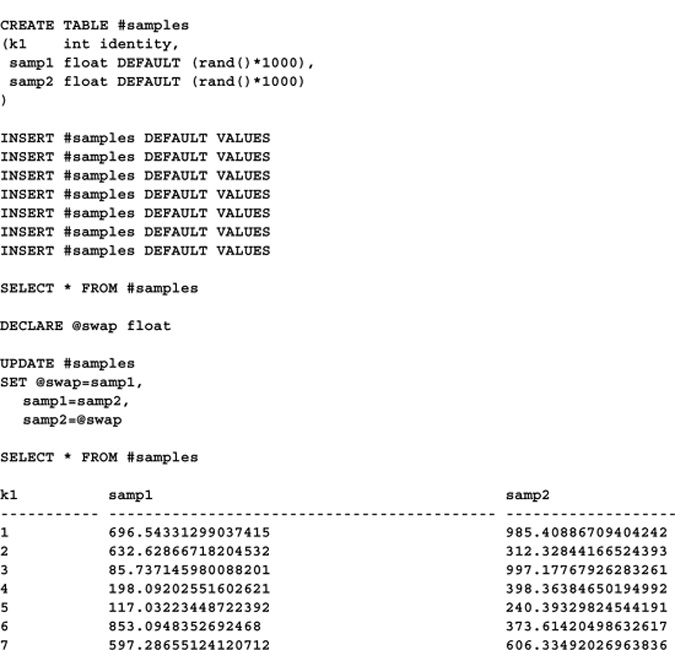
A nifty side effect of the fact that UPDATE can set local variables at the same time it sets column values is that you can use this variable in the update itself. Since Transact-SQL is processed left to right, you can set the variable early in the SET list, then reuse it later in the same update to supply a column value. For example, you could use it to swap the values of two columns, like so:

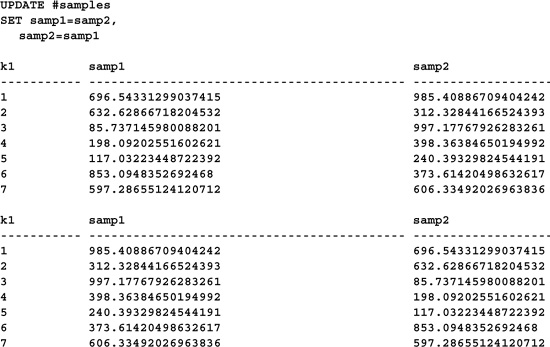
This trick is cool enough, but because column values referenced by an UPDATE statement always reflect their values before the operation, you don’t need an intermediate variable in order to swap them. You can just simply assign the columns to one another, like this:
You can use the UPDATE command to modify rows returned by updatable cursors. This is facilitated via UPDATE’s WHERE CURRENT OF clause. Here’s an example:
CREATE TABLE #famousjaycees
(jc varchar(15),
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL)
INSERT #famousjaycees VALUES (’Julius Caesar’,’Military leader/dictator’,
-0045,’Took the Roman early retirement program’)
INSERT #famousjaycees VALUES (’Jesus Christ’,’Founded Christianity’,0001,’Birth
featured tellurian, ruminative, and tutelary visitors’)
INSERT #famousjaycees VALUES (’John Calhoun’,’Congressman’,1825,’Served as VP
under two U.S. presidents’)
INSERT #famousjaycees VALUES (’Joan Crawford’,’Actress’,1923,’Appeared in
everything from Grand Hotel to Trog’)
INSERT #famousjaycees VALUES (’James Cagney’,’Actor’,1931,’This prototypical
gangster made a dandy Yankee’)
INSERT #famousjaycees VALUES (’Jim Croce’,’Singer/songwriter’,1972,’Would that
time were in a bottle because you left us way too soon’)
INSERT #famousjaycees VALUES (’Joe Celko’,’Author/lecturer’,1987,’Counts eating
and living indoors among his favorite hobbies’)
DECLARE jcs CURSOR DYNAMIC FOR SELECT * FROM #famousjaycees FOR UPDATE
OPEN jcs
FETCH RELATIVE 3 FROM jcs
UPDATE #famousjaycees
SET jc=’Johnny Cash’,
occupation=’Singer/songwriter’,
becamefamous=1955,
notes=’Began career selling appliances door-to-door’
WHERE CURRENT OF jcs
CLOSE jcs
DEALLOCATE jcs
SELECT * FROM #famousjaycees

Like its INSERT counterpart, the DELETE command has a number of forms. I won’t go into all of them here—they correspond closely enough with their INSERT and UPDATE siblings that their use should be obvious.
There are, however, a couple of aspects of the command that bear discussion. First, in addition to limiting the rows removed by a DELETE through the use of constants and variables in its WHERE clause, you can reference other tables. Below is a DELETE that’s based on a join to another table. It deletes customers in the Northwind Customers table that have no orders in the Orders table:
SET NOCOUNT ON
USE Northwind
GO
BEGIN TRAN
SELECT COUNT(*) AS TotalCustomersBefore FROM Customers
DELETE c
FROM Customers c LEFT OUTER JOIN Orders o ON (c.CustomerID=o.CustomerID)
WHERE o.OrderID IS NULL
SELECT COUNT(*) AS TotalCustomersAfter FROM Customers
GO
ROLLBACK TRAN
TotalCustomersBefore
--------------------
91
TotalCustomersAfter
-------------------
89
As with the UPDATE command, the number of rows affected by DELETE can be restricted via the SELECT TOP n extension. Here’s an example:
SELECT TOP 10 ord_num AS Before FROM sales ORDER BY ord_num
DELETE s
FROM sales s JOIN (SELECT TOP 5 ord_num FROM sales ORDER BY ord_num) a
ON (s.ord_num=a.ord_num)
SELECT TOP 10 ord_num AS After FROM sales ORDER BY ord_num
Before
--------------------
423LL922
423LL930
6871
722a
A2976
D4482
D4482
D4492
N914008
N914014
After
--------------------
D4482
D4482
D4492
N914008
N914014
P2121
P2121
P2121
P3087a
P3087a
You can use the DELETE command to delete rows returned by updatable cursors. Similarly to UPDATE, this is facilitated via the command’s WHERE CURRENT OF clause. Here’s an example:
CREATE TABLE #famousjaycees
(jc varchar(15),
occupation varchar(25),
becamefamous int DEFAULT 0,
notes text NULL)
INSERT #famousjaycees VALUES (’Julius Caesar’,’Military leader/dictator’,-0045,’Took the
Roman early retirement program’)
INSERT #famousjaycees VALUES (’Jesus Christ’,’Founded Christianity’,0001,’Birth featured
tellurian, ruminative, and tutelary visitors’)
INSERT #famousjaycees VALUES (’John Calhoun’,’Congressman’,1825,’Served as VP under two
U.S. presidents’)
INSERT #famousjaycees VALUES (’Joan Crawford’,’Actress’,1923,’Appeared in everything
from Grand Hotel to Trog’)
INSERT #famousjaycees VALUES (’James Cagney’,’Actor’,1931,’This prototypical gangster
made a dandy Yankee’)
INSERT #famousjaycees VALUES (’Jim Croce’,’Singer/songwriter’,1972,’Would that time were
in a bottle because you left us way too soon’)
INSERT #famousjaycees VALUES (’Joe Celko’,’Author/lecturer’,1987,’Counts eating and
living indoors among his favorite hobbies’)
DECLARE jcs CURSOR DYNAMIC FOR SELECT * FROM #famousjaycees FOR UPDATE
OPEN jcs
FETCH RELATIVE 3 FROM jcs
DELETE #famousjaycees
WHERE CURRENT OF jcs
CLOSE jcs
DEALLOCATE jcs
SELECT * FROM #famousjaycees

Analogous to BULK INSERT, the TRUNCATE TABLE command provides a way of deleting the rows in a table with a minimum of logging. That no logging occurs at all is a common misconception. The page deallocations are logged—they have to be. If they weren’t, you couldn’t execute the command from within a transaction and couldn’t reverse its effects on the database. Here’s an example:
USE pubs
BEGIN TRAN
SELECT COUNT(*) AS CountBefore FROM sales
TRUNCATE TABLE sales
SELECT COUNT(*) AS CountAfter FROM sales
GO
ROLLBACK TRAN
SELECT COUNT(*) AS CountAfterRollback FROM sales
CountBefore
-----------
25
CountAfter
------------------
0
CountAfterRollback
------------------
25
What’s not logged with TRUNCATE TABLE is the process of deleting individual rows. That’s because no row deletions actually occur—all that really happens is the deallocation of the pages that make up the table. Since row deletions don’t occur, they aren’t logged and can’t fire DELETE triggers.
You’ll find that TRUNCATE TABLE is many times faster than an unqualified DELETE tablename statement; in fact, it’s often instantaneous with small to medium-sized tables. There are a couple of limitations, though. You can’t use TRUNCATE TABLE on a table that’s referenced by a foreign key constraint, even if the truncation would not break any foreign key relationships (e.g., when the dependent table is empty). You also can’t use TRUNCATE TABLE on a table that’s been published for replication. This is because replication relies on the transaction log to synchronize publishers and subscribers, and TRUNCATE TABLE, as I’ve said, does not generate row deletion log records.
Normally, you can detect DML runtime errors by inspecting the @@ERROR automatic variable. However, if a DML statement doesn’t affect any rows, @@ERROR won’t be set because that’s technically not an error condition. You’ll have to check @@ROWCOUNT instead. In other words, if your code needs to consider the fact that a DML statement fails to affect (or find) any rows as an error, check @@ROWCOUNT after the statement and respond accordingly.