
21 Potpourri
Intolerance is the root of all evil—or at least many kinds of it. That could have been my son or your son that was beaten to death and tied to a barbed-wire fence because of his sexual preference. Or it could have been your brother or my brother that was dragged behind a pickup truck until his head came off. Or it could have been you or me. If you want to rid the world of evil, start with intolerance.
—H. W. Kenton
This chapter is the catchall of this book. Here, you’ll find an assortment of odds and ends that didn’t seem to fit elsewhere. Banishment to this chapter doesn’t necessarily make a topic a second-class citizen. You may find some of the techniques presented here quite useful. Being a misfit doesn’t necessarily make one a miscreant.
Each new release of SQL Server has introduced new functions to the Transact-SQL language. There are now over fifty of them. With so many functions, it’s no surprise that the casual developer might miss a few. Though the goal of this book is not to supplant SQL Server’s Books Online, a few of these bear mentioning because they can save you real work if you know about them.
Status functions tell us something about the work environment. SQL Server has a number of these. You’re probably familiar with some of them; some of them you may not be. Here are a few that stand out from the rest in terms of rarity and usefulness:
GETANSINULL() allows you to determine default nullability for a database. Default nullability is controlled by the ANSI null default option of each database (set via sp_dboption), as well as the SET ANSI_NULL_DFLT_ON/SET ANSI_NULL_DFLT_OFF session-level commands. GETANSINULL() can optionally receive a single parameter—the database you’d like to check.
Here’s some code that uses GETANSINULL():
DECLARE @ansinull int
-- Save it off so that we can restore it later
SET @ansinull=GETANSINULL(’tempdb’)
IF (@ansinull=0)
SET ANSI_NULL_DFLT_ON ON
CREATE TABLE #nulltest (c1 int)
INSERT #nulltest (c1) VALUES (NULL)
SELECT * FROM #nulltest
IF (@ansinull=0) -- Reverse the setting above
SET ANSI_NULL_DFLT_ON OFF
This code uses GETANSINULL() to determine the status of ANSI null default before changing the setting. It then creates a temporary table consisting of a single column whose NULLability is unspecified and inserts a NULL value into it. Afterwards, it restores the setting to its original value.
HOST_NAME(), GETDATE(), and USER_NAME() are also handy environmental status functions. Frequently, you’ll see them used to establish column defaults, though they can also be featured in SELECT lists, as this code illustrates:
SELECT HOST_NAME()
--------------------------------------------------------------------------------
PUCK_FEET
Here, HOST_NAME() is used to return the current workstation name.
Another common use of these functions is as column default values. Here’s an example:
CREATE TABLE #REPORT_LOG
(ReportLogId int identity PRIMARY KEY,
ReportDate datetime DEFAULT GETDATE(),
ReportUser varchar(30) DEFAULT USER_NAME(),
ReportMachine varchar(30) DEFAULT HOST_NAME(),
ReportName varchar(30) DEFAULT ’UNKNOWN’)
INSERT #REPORT_LOG DEFAULT VALUES
SELECT * FROM #REPORT_LOG
(Results abridged)
ReportLogId ReportDate ReportUser ReportMachine
----------- ------------------------- --------------------- --------------------
1 1999-06-17 02:10:03.617 dbo PUCK_FEET
Note the use of INSERT...DEFAULT VALUES to add a row to the table using nothing but default values. Nullable columns without default values are inserted with NULL as their value; nonnullable columns without defaults cause an error to be generated.
Note that you could have used the ANSI SQL-92 CURRENT_TIMESTAMP and CURRENT_USER niladic functions in place of GETDATE() and USER_NAME(), respectively. USER and SESSION_USER are synonyms for CURRENT_USER. Interestingly, ANSI-92 niladic functions such as these may also be featured in SELECT lists, like so:
SELECT CURRENT_TIMESTAMP, CURRENT_USER
--------------------------- ----------------------------------------------------
1999-06-17 02:32:13.600 dbo
The SUSER_NAME() and SUSER_SNAME() functions come in handy if you prefer to default a column to the current user’s login name rather than his or her database user name (SYSTEM_USER is the ANSI SQL equivalent). If your app always logs in as ’sa’ and doesn’t use database user names, storing the current database user name in a table isn’t likely to be terribly useful. It will always be "dbo." Storing the user’s login name will permit you to track user activity without forcing you to set up separate database logins for each user.
SUSER_NAME() is included in the latest release of SQL Server for backward compatibility only—you should use SUSER_SNAME(), instead. SUSER_NAME() no longer maps directly to the SQL Server security model, so there’s a notable performance penalty for using it.
Property functions return information about objects in the database. Usually, this info is in the form of "meta-data"—data about data. There was a time when getting at even basic meta-data on SQL Server required spelunking through system tables. Fortunately, enough functions have been added that that’s no longer the case. Following are some of the more interesting ones.
COLUMNPROPERTY() returns useful info about table columns and stored procedure parameters. It takes three parameters—the object ID of the table or stored procedure (you can use OBJECT_ID() to get this), the name of the column or parameter, and a string expression indicating the exact info you’re after. You can refer to the Books Online for more information, but some of the more interesting uses of COLUMNPROPERTY() are illustrated below:
CREATE TABLE #testfunc
(k1 int identity PRIMARY KEY, c1 decimal(10,2), c3 AS k1*c1)
USE tempdb
SELECT COLUMNPROPERTY(OBJECT_ID(’#testfunc’),’k1’,’IsIdentity’),
COLUMNPROPERTY(OBJECT_ID(’#testfunc’),’c1’,’Scale’),
COLUMNPROPERTY(OBJECT_ID(’#testfunc’),’c3’,’IsComputed’),
COLUMNPROPERTY(OBJECT_ID(’#testfunc’),’k1’,’AllowsNull’)
---------- ---------- ---------- ----------
1 2 1 0
Note the USE tempdb immediately preceding the calls to COLUMNPROPERTY(). It’s necessary because the object in question resides in tempdb and COLUMNPROPERTY() can’t deal with cross-database references.
DATABASEPROPERTY() is similar to COLUMNPROPERTY() in that it returns property-level info about an object—in this case, a database. It takes two parameters—the name of the database and the property you’re after. Here are some examples that use DATABASEPROPERTY():
SELECT
DATABASEPROPERTY(’pubs’,’IsBulkCopy’),
DATABASEPROPERTY(’pubs’,’Version’),
DATABASEPROPERTY(’pubs’,’IsAnsiNullsEnabled’),
DATABASEPROPERTY(’pubs’,’IsSuspect’),
DATABASEPROPERTY(’pubs’,’IsTruncLog’)
-------- ---------- ---------- ---------- ----------
1 515 0 0 1
In the old days, you had to query master..sysdatabases and translate cryptic bit masks in order to get this information. Now, Transact-SQL makes the job much easier, completely insulating the developer from the underlying implementation details.
TYPEPROPERTY() returns property-level information about data types. It takes two parameters—the name of the data type you want to inspect and a string expression indicating the property in which you’re interested. The data type you supply can be either a system-supplied type or a user-defined data type. Here’s a query that uses TYPEPROPERTY():
SELECT TYPEPROPERTY(’id’,’AllowsNull’)
-----------
0
IDENT_SEED() and IDENT_INCR() return the seed and increment settings for identity columns. Each function takes a single parameter—a string expression that specifies the name of the table you want to inspect (you specify a table rather than a column because each table is limited to one identity column).
IDENTITYCOL is a niladic function that returns the value of a table’s identity column. You can use it in SELECT statements to return an identity column’s value without referencing the column by name, like so:
CREATE TABLE #testident (k1 int identity, c1 int DEFAULT 0)
INSERT #testident DEFAULT VALUES
INSERT #testident DEFAULT VALUES
INSERT #testident DEFAULT VALUES
SELECT IDENTITYCOL FROM #testident
This is handy for writing generic routines that copy data from table to table, for example. If you establish a convention of always keying your tables using an identity column, IDENTITYCOL provides a generic way of referencing each table’s primary key without having to know it in advance.
The IDENTITY() function allows you to create tables, using SELECT..INTO, that contain new identity columns. Previously, this required adding the identity column after the table was created using ALTER...TABLE. Here’s an example that features IDENTITY():
SELECT AuthorId=IDENTITY(int), au_lname, au_fname INTO #testident FROM authors
USE tempdb
SELECT COLUMNPROPERTY(OBJECT_ID(’#testident’),’AuthorId’,’IsIdentity’)
-----------
1
Though, technically speaking, it doesn’t have anything to do with identity columns, NEWID() is similar to IDENTITY() in that it generates unique identifiers. It returns a value of type uniqueidentifier and is most often used to supply a default value for a column. Here’s an example:
CREATE TABLE #testuid (k1 uniqueidentifier DEFAULT NEWID(), k2 int identity)
INSERT #testuid DEFAULT VALUES
INSERT #testuid DEFAULT VALUES
INSERT #testuid DEFAULT VALUES
INSERT #testuid DEFAULT VALUES
SELECT * FROM #testuid
k1 k2
------------------------------------ ---------
F4F407B5-244F-11D3-934F-005004044A19 1
F4F407B6-244F-11D3-934F-005004044A19 2
F4F407B7-244F-11D3-934F-005004044A19 3
F4F407B8-244F-11D3-934F-005004044A19 4
The uniqueidentifier data type corresponds to the Windows GUID type. It’s a unique value that is guaranteed to be unique across all networked computers in the world. You can use the ROWGUIDCOL keyword to designate a single uniqueidentifier column in each table as a global row identifier. Once you’ve done this, you can use ROWGUIDCOL analogously to IDENTITYCOL to return a table’s uniqueidentifier column without referencing it directly, like so:
CREATE TABLE #testguid
(k1 uniqueidentifier ROWGUIDCOL DEFAULT NEWID(), k2 int identity)
INSERT #testguid DEFAULT VALUES
INSERT #testguid DEFAULT VALUES
INSERT #testguid DEFAULT VALUES
INSERT #testguid DEFAULT VALUES
SELECT ROWGUIDCOL FROM #testguid
INDEX_COL() returns the column name of a particular index key column. You can use it to iterate through a table’s indexes, displaying each set of key columns as you go. Here’s a code sample that illustrates how to use INDEX_COL():
SELECT TableName=OBJECT_NAME(id), IndexName=name,
KeyName=INDEX_COL(OBJECT_NAME(id),indid,1) -- Just get the first key
FROM sysindexes
(Results abridged)
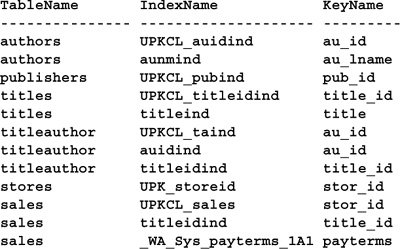
Note that the INFORMATION_SCHEMA.KEY_COLUMN_USAGE system schema view provides the same information. Querying KEY_COLUMN_USAGE is the ANSI SQL-compliant method of accessing index column schema information. It also has the advantage of being immune to changes in the underlying system tables between releases of SQL Server.
The INDEXPROPERTY() function, like the COLUMNPROPERTY() and DATABASEPROPERTY() functions, returns schema-level information. Like COLUMNPROPERTY(), it takes three arguments—the ID of the index’s host table, the name of the index, and a string expression indicating what info you’d like. Here’s a query that uses INDEXPROPERTY():
SELECT
TableName=CAST(OBJECT_NAME(id) AS varchar(15)),
IndexName=CAST(name AS VARCHAR(20)),
KeyName=CAST(INDEX_COL(OBJECT_NAME(id),indid,1) AS VARCHAR(30)),
"Clustered?"=CASE INDEXPROPERTY(id,name,’IsClustered’) WHEN 1 THEN ’Yes’ ELSE ’No’ END,
"Unique?"=CASE INDEXPROPERTY(id,name,’IsUnique’) WHEN 1 THEN ’Yes’ ELSE ’No’ END
FROM sysindexes
(Results abridged)

Again, it’s preferable to use the KEY_COLUMN_USAGE system view to get this type of information rather than querying sysindexes directly.
STATS_DATE() returns the date the index statistics were last updated for a particular index. This is handy for determining when to issue UPDATE STATISTICS for the indexes in a database. You could easily write a query that checks each index’s last statistics date and issues UPDATE STATISTICS commands for those considered out of date. Here’s a query that does just that:
DECLARE c CURSOR FOR
SELECT
TableName=OBJECT_NAME(id),
IndexName=name,
StatsUpdated=STATS_DATE(id, indid)
FROM sysindexes
WHERE
OBJECTPROPERTY(id,’IsSystemTable’)=0
AND indid>0
AND indid<255
DECLARE @tname varchar(30),
@iname varchar(30),
@dateupd datetime
OPEN c
FETCH c INTO @tname, @iname, @dateupd
WHILE (@@FETCH_STATUS=0) BEGIN
IF (SELECT DATEDIFF(dd,ISNULL(@dateupd,’19000101’),GETDATE()))>30 BEGIN
PRINT ’UPDATE STATISTICS ’+@tname+’ ’+@iname
EXEC(’UPDATE STATISTICS ’+@tname+’ ’+@iname)
END
FETCH c INTO @tname, @iname, @dateupd
END
CLOSE c
DEALLOCATE c
(Results abridged)
UPDATE STATISTICS authors UPKCL_auidind
UPDATE STATISTICS authors aunmind
UPDATE STATISTICS publishers UPKCL_pubind
UPDATE STATISTICS titles UPKCL_titleidind
UPDATE STATISTICS titles titleind
UPDATE STATISTICS titleauthor UPKCL_taind
UPDATE STATISTICS titleauthor auidind
UPDATE STATISTICS titleauthor titleidind
UPDATE STATISTICS stores UPK_storeid
UPDATE STATISTICS sales UPKCL_sales
UPDATE STATISTICS sales titleidind
Of course, you could get the same basic functionality with the sp_updatestats system procedure—it updates the statistics of every index on every table in a database, but you might not want to update all of them—you might want to be a bit more selective. Updating statistics can take a long time on large tables, so you’ll want to run it only against tables it actually benefits and when system utilization is low. Also, keep in mind that SQL Server can maintain index statistics information for you automatically, alleviating much of the need for UPDATE STATISTICS. You can turn automatic statistic generation on for a given table via sp_autostats or for the entire database via sp_dboption.
ISDATE() and ISNUMERIC() return 1 or 0 based on whether a given expression evaluates to a date or numeric value, respectively. These can be handy for data scrubbing operations where you need to convert a character column to a date or numeric but need to check it first for invalid entries. Here’s a query that searches for bad dates in a character field:
CREATE TABLE #testis (c1 char(8) NULL)
INSERT #testis VALUES (’19990131’)
INSERT #testis VALUES (’20000131’)
INSERT #testis VALUES (’19990229’)
INSERT #testis VALUES (’20000229’)
INSERT #testis VALUES (’19990331’)
INSERT #testis VALUES (’20000331’)
SELECT *
FROM #testis
WHERE ISDATE(c1)=0
c1
--------
19990229
This query returns 19990229 because 1999 wasn’t a leap year, making February 29 an invalid date.
DATALENGTH() returns the actual length of the data stored in a column rather than the length of the column itself. Though it can be used with any data type, it’s more commonly used with character, binary, and BLOB columns, since they can vary in length. The data length of a fixed data type (such as int) never varies, regardless of the value it contains. DATALENGTH() has more uses than you might think, most of them having to do with formatting result sets or data. Here’s some sample code from a previous chapter that makes novel use of DATALENGTH():
CREATE TABLE #array (k1 int identity, arraycol varchar(8000))
INSERT #array (arraycol) VALUES (’LES PAUL ’+
’BUDDY GUY ’+
’JEFF BECK ’+
’JOE SATRIANI ’)
INSERT #array (arraycol) VALUES (’STEVE MILLER ’+
’EDDIE VAN HALEN’+
’TOM SCHOLZ ’)
INSERT #array (arraycol) VALUES (’STEVE VAI ’+
’ERIC CLAPTON ’+
’SLASH ’+
’JIMI HENDRIX ’+
’JASON BECKER ’+
’MICHAEL HARTMAN’)
-- To set the fourth element
UPDATE #array
SET arraycol =
LEFT(arraycol,(3*15))+’MUDDY WATERS ’+
RIGHT(arraycol,CASE WHEN (DATALENGTH(arraycol)-(4*15))<0 THEN 0 ELSE
DATALENGTH(arraycol)-(4*15) END)
WHERE k1=2
SELECT
Element1=SUBSTRING(arraycol,(0*15)+1,15),
Element2=SUBSTRING(arraycol,(1*15)+1,15),
Element3=SUBSTRING(arraycol,(2*15)+1,15),
Element4=SUBSTRING(arraycol,(3*15)+1,15),
Element5=SUBSTRING(arraycol,(4*15)+1,15),
Element6=SUBSTRING(arraycol,(5*15)+1,15)
FROM #array a
(Results abridged)

Using FORMATMESSAGE(), you can format strings using a printf()-like syntax. It takes a parameter specifying the ID of the message from the master..sysmessages table that you want to use, as well as a list of arguments to insert into the message. FORMATMESSAGE() works similarly to RAISERROR(), except that it doesn’t return an error. Instead, it returns the resulting message as a string, which you may then do with as you please. Unfortunately, FORMATMESSAGE() is limited to messages that exist in sysmessages—you can’t use it to format a plain character string. Here’s a technique for working around that:
DECLARE @msg varchar(60), @msgid int, @pub_id varchar(10), @inprint int
SELECT @msgid=ISNULL(MAX(error)+1,999999) FROM master..sysmessages WHERE error > 50000
SELECT @pub_id=CAST(pub_id AS varchar), @inprint=COUNT(*) FROM titles GROUP BY pub_id
-- Get the last one
BEGIN TRAN
EXEC sp_addmessage @msgid,1,’Publisher: %s has %d titles in print’
SET @msg=FORMATMESSAGE(@msgid,@pub_id,@inprint)
ROLLBACK TRAN
SELECT @msg
New message added.
------------------------------------------------------------
Publisher: 1389 has 6 titles in print
This approach adds the string to sysmessages within a transaction for the express purpose of manipulating it with FORMATMESSAGE(). Once the string is formatted, it rolls the transaction back so that the message is removed from sysmessages. What you end up with is the ability to format a string without it having to be a permanent member of sysmessages first.
Admittedly, that’s a lot of code for a menial task like this. The logical thing to do here would be to generalize the technique by moving the code into a stored procedure. Unfortunately, this isn’t easily done because Transact-SQL doesn’t support variable stored procedure parameters—you can’t specify an unlimited number of variably typed parameters, which is what’s needed to exploit the capabilities of FORMATMESSAGE().
The system procedure xp_sscanf() provides a similar functionality and can handle a variable number of arguments but, unfortunately, supports only string parameters. It supports a variable number of parameters because it’s not a true stored procedure—it’s an extended procedure, and extended procedures are not written in Transact-SQL. They reside outside the server in a DLL and are usually written in C or C11. For the time being, it would probably be faster to cast nonstrings as strings and either call xp_sscanf() or use simple string concatenation to merge them with the message string.
PARSENAME() is handy for extracting the various parts of an object name. SQL Server object names have four parts:
[server.][database.][owner.]object
You can return any of these four parts using PARSENAME(), like so:
DECLARE @objname varchar(30)
SET @objname=’KHEN.master.dbo.sp_who’
SELECT ServerName=PARSENAME(@objname,4),
DatabaseName=PARSENAME(@objname,3),
OwnerName=PARSENAME(@objname,2),
ObjectName=PARSENAME(@objname,1)
ServerName DatabaseName OwnerName ObjectName
--------------- --------------- --------------- ---------------
KHEN master dbo sp_who
QUOTENAME() surrounds a string with either double quotation marks (""), single quotation marks (’’), or brackets ([]). It can be especially handy when building SQL to execute via EXEC(). Here’s a code sample from an earlier chapter that uses QUOTENAME() to create SQL code for execution by EXEC():
CREATE TABLE #array (k1 int identity, arraycol varchar(8000))
INSERT #array (arraycol) VALUES (’LES PAUL ’+
’BUDDY GUY ’+
’JEFF BECK ’+
’JOE SATRIANI ’)
INSERT #array (arraycol) VALUES (’STEVE MILLER ’+
’EDDIE VAN HALEN’+
’TOM SCHOLZ ’)
INSERT #array (arraycol) VALUES (’STEVE VAI ’+
’ERIC CLAPTON ’+
’SLASH ’+
’JIMI HENDRIX ’+
’JASON BECKER ’+
’MICHAEL HARTMAN’)
DECLARE @arrayvar varchar(8000), @select_stmnt varchar(8000)
DECLARE @k int, @i int, @l int, @c int
DECLARE c CURSOR FOR SELECT * FROM #array
SET @select_stmnt=’SELECT ’
SET @c=0
OPEN c
FETCH c INTO @k, @arrayvar
WHILE (@@FETCH_STATUS=0) BEGIN
SET @i=0
SET @l=DATALENGTH(@arrayvar)/15
WHILE (@i<@l) BEGIN
SELECT @select_stmnt=@select_stmnt+’Guitarist’+CAST(@c as
varchar)+’=’+QUOTENAME(RTRIM(SUBSTRING(@arrayvar,(@i*15)+1,15)),’"’)+’,’
SET @i=@i+1
SET @c=@c+1
END
FETCH c INTO @k, @arrayvar
END
CLOSE c
DEALLOCATE c
SELECT @select_stmnt=LEFT(@select_stmnt,DATALENGTH(@select_stmnt)-1)
EXEC(@select_stmnt)
(Results abridged)
Guitarist0 Guitarist1 Guitarist2 Guitarist3 Guitarist4
---------- ---------- ---------- ------------ ------------
LES PAUL BUDDY GUY JEFF BECK JOE SATRIANI STEVE MILLER
The task of cleaning up data received from sources outside SQL Server is a common one. Whether the data is migrated from a legacy system, generated by hardware, or produced by some other means, it’s fairly common to need to scan it for bad values.
The first step in removing bad data is to locate it. To that end, let’s consider the problem of finding duplicate values among the rows in a table. It’s not enough that we merely return those duplicate values—that would be trivial considering we have GROUP BY and SQL’s aggregate functions at our disposal. We need to return the actual rows that contain the duplicate values so that we can deal with them. We might want to delete them, move them to another table, fix them, and so on. Let’s assume we begin with the following table of employee IDs and in-case-of-emergency phone numbers. The folks who hired us believe they may have duplicate entries in this list and have determined that the best way to identify them is to locate duplicate ICE numbers. Here’s the table:
CREATE TABLE #datascrub
(EmpID int identity,
ICENumber1 varchar(14),
ICENumber2 varchar(14))
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(101)555-1212’,’(101)555-1213’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(201)555-1313’,’(201)555-1314’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(301)555-1414’,’(301)5551415’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(401)555-1515’,’(401)555-1516’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(501)555-1616’,’(501)555-1617’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(101)555-1211’,’(101)555-1213’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(201)555-1313’,’(201)555-1314’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(301)555-1414’,’(301)555-1415’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(401)555-1515’,’(401)555-1516’)
INSERT #datascrub (ICENumber1, ICENumber2)
VALUES (’(501)555-1616’,’(501)555-1617’)
The most obvious way to locate duplicates here is to perform a cross-join of the table with itself, like this:

This approach has a couple of problems—first and foremost is efficiency or, rather, the lack of it. Cross-joins are notoriously inefficient and even impractical for extremely large tables. A better way would be to use a correlated subquery, like this:
SELECT d.EmpId, d.ICENumber1, d.ICENumber2
FROM #datascrub d
WHERE EXISTS (SELECT a.ICENumber1, a.ICENumber2 FROM #datascrub a
WHERE a.ICENumber1=d.ICENumber1
AND a.ICENumber2=d.ICENumber2
This technique uses GROUP BY and COUNT() to identify duplicate values within the subquery and then correlates those values with the outer query to restrict the rows returned. It returns the same result set as the previous query but doesn’t require a cross-join. With small tables, the difference this makes won’t be noticeable. In fact, the self-join technique may actually be faster with really small tables like this one. However, the larger the table becomes, the more noticeably faster this technique becomes. The optimizer is able to use the EXISTS predicate to return from the inner query as soon as even one row satisfies the conditions imposed.
An even better way of doing this replaces the subquery with a derived table, like so:
SELECT d.EmpId, d.ICENumber1, d.ICENumber2
FROM #datascrub d, (SELECT t.ICENumber1, t.ICENumber2 FROM #datascrub t
GROUP BY t.ICENumber1, t.ICENumber2
HAVING COUNT(*) >=2) a
WHERE (d.ICENumber1=a.ICENumber1)
AND (d.ICENumber2=a.ICENumber2)
This technique embeds most of the previous example’s subquery in a derived table that it then performs an inner join against. This solution is plain, no-frills Transact-SQL, and it’s very efficient, regardless of table size.
I mentioned early on that the first approach to solving this problem had a couple of fundamental flaws. The first of those was inefficiency. We’ve solved that one. The second one is that neither the initial solution nor any of the code samples presented since finds all duplicate rows. Why? Because the duplicates are disguised a little more cleverly than they might have first appeared. Look closely at the INSERT statements. Notice anything peculiar about any of the ICE numbers? Exactly! Some of them are formatted incorrectly, hiding potential duplicates from our routines. To find all duplicates, we need to standardize the formatting of the columns we’re scanning. The best way to do this is simply to remove that formatting—to reduce the data to its bare essence. This is a common situation and, depending on the data, can be critical to a successful scrubbing. Here’s a revised query that takes the possibility of bad formatting into account. Check out the difference this makes in the result set.
SELECT d.EmpId, d.ICENumber1, d.ICENumber2
FROM #datascrub d, (SELECT ICENumber1=REPLACE(REPLACE(REPLACE(t.ICENumber1,’-’,’’),
’(’,’’),’)’,’’),
ICENumber2=REPLACE(REPLACE(REPLACE(t.ICENumber2,’-’,’’),
’(’,’’),’)’,’’)
FROM #datascrub t
GROUP BY REPLACE(REPLACE(REPLACE(t.ICENumber1,’-’,’’),
’(’,’’),’)’,’’),
REPLACE(REPLACE(REPLACE(t.ICENumber2,’-’,’’),
’(’,’’),’)’,’’)
HAVING COUNT(*) >=2) a
WHERE (REPLACE(REPLACE(REPLACE(d.ICENumber1,’-’,’’),’(’,’’),’)’,’’)
=REPLACE(REPLACE(REPLACE(a.ICENumber1,’-’,’’),’(’,’’),’)’,’’))
AND (REPLACE(REPLACE(REPLACE(d.ICENumber2,’-’,’’),’(’,’’),’)’,’’)
=REPLACE(REPLACE(REPLACE(a.ICENumber2,’-’,’’),’(’,’’),’)’,’’))

Of course, this could be extended to any number of delimiters, including spaces, commas, and so forth. This is one case where stored function support would really be nice. It would allow us to hide all the implementation details of the character stripping in a function that we could then call as needed.
Once the duplicate rows are identified, deleting or moving them to another table is fairly straightforward. You couldn’t simply translate the main SELECT into a DELETE statement as that would delete both the duplicate and the original. It’s easy enough to do but would probably get you fired. Instead, you could use a cursor defined with the same basic SELECT as the code above to cruise through the table. You could save each pair of phone numbers off as you traversed the cursor and then iterate through the duplicates, deleting them as you go.
This would work, but there may be a better way. You may be able to use SQL Server’s ability to toss duplicate keys when it builds an index to scrub your data. Here’s an example:
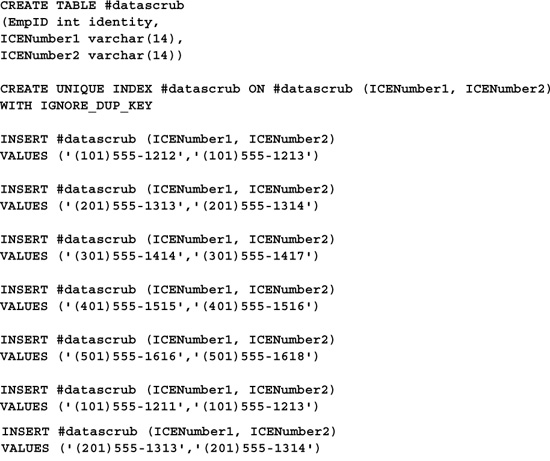
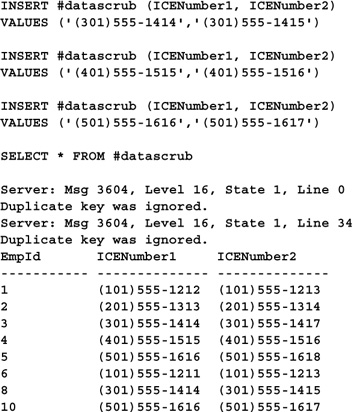
The key here is CREATE INDEX’s IGNORE_DUP_KEYS option. Note that you can’t build a UNIQUE index over a table with duplicate keys regardless of the IGNORE_DUP_KEYS option—that’s why the code above creates the index, then inserts the data. As you can see, attempting to insert a duplicate key value (in this case, we defined the key as the two columns we want to scan for duplicates) generates a warning but otherwise allows the query batch to proceed.
Note that this technique works only with "simple" duplicates—ones that don’t involve delimiters and extraneous character removal (i.e., noncharacter types, for the most part). If your needs are as complex as the above technique that made use of nested REPLACE() functions, CREATE INDEX...WITH IGNORE_DUP_KEYS won’t get the job done since SQL Server can’t detect these more cleverly hidden duplicates.
It’s common to need to loop through a set of values and perform some sort of computation on them. Normally, this is done in Transact-SQL using the WHILE looping construct, or, if you’re a glutton for punishment by your colleagues, an illicit GOTO may do the trick. But there’s a better way, if you’re willing to give up a tiny amount of disk space for a static iteration table. An iteration table is a simple table containing a sequence of numbers that you use for iterative types of computations rather than looping. It’s stored permanently in one of your databases (placing it in model will cause it to be copied to tempdb with each system restart) and can be filtered like any other table with a WHERE clause. To see how this works, consider the following example. Let’s say that we want to display a table of the squares of all numbers between one and one hundred. If this table already exists:
CREATE TABLE iterate (I int identity(-100,1))
DECLARE @loop int
SET @loop=-100
WHILE (@loop<101) BEGIN
INSERT iterate DEFAULT VALUES
SET @loop=@loop+1
END
SELECT * FROM iterate
I
------------
-100
-99
-98
(...)
0
1
(...)
99
100
writing the query is simple:
SELECT SQUARE=SQUARE(I) FROM iterate
WHERE I BETWEEN 1 AND 100
It’s fast and far more efficient than having to loop using WHILE every time we need a result set like this. Note the use of the negative seed for iterate’s identity column. This allows us to perform computations against negative as well as positive numbers. A nice future SQL Server enhancement would be an automatic table of some sort (along the lines of Oracle’s DUAL table) that you specify similarly to an identity column with a seed and an increment during a query. This would alleviate the requirement of a permanent iteration table in the example above.