
4 DDL Insights
If the auto industry had done what the computer industry has done in the last thirty years, a Rolls Royce would cost $2.50 and get two million miles per gallon.—Herb Grosch
But it would be the size of a Dinky toy and crash every three days. Beware of false analogy.—Joe Celko
The chapter is not intended to cover Transact-SQL DDL (Data Definition Language) comprehensively—the Books Online (BOL) do that well enough already. It is not a syntax guide and makes no attempt to cover every T-SQL DDL command thoroughly, or even to cover every command.
Instead, it’s a loose collection of tips, pointers, and advice regarding a variety of DDL-related topics. It’s intended to supplement the Books Online, not replace them. The goal of this chapter is to fill in some of the gaps left by the BOL and to highlight DDL topics that could use further emphasis.
One of the challenges of writing a book like this is in trying to avoid replicating what’s already covered in the vendor documentation while remaining thorough enough to be truly useful to readers and to assure them that their money was well spent. SQL Server’s online documentation has long been one of its strong points. I prefer it hands-down to the online documentation of the other DBMS vendors I regularly work with. That said, the exhaustiveness of its coverage makes writing about relatively mundane topics such as DDL challenging for the author who would aspire to fresh, original work. In short, many subjects are already covered quite well by the Books Online, and rather than rehash what comes in the box with the product, I’d rather spend the limited number of pages in this book covering those that aren’t.
As opposed to querying database objects, DDL commands are concerned with creating and managing them. They include Transact-SQL commands such as CREATE TABLE, CREATE INDEX, ALTER TABLE, and CREATE PROCEDURE. These commands have a number of nuances and idiosyncrasies that one has to explore to appreciate fully.
Aside from the obvious function of constructing tables, CREATE TABLE is used to establish declarative referential integrity between tables. It’s also used to set up default column values and to establish primary and unique key constraints.
Generally speaking, declarative RI (referential integrity) is preferable to triggers, and triggers are preferable to stored procedures, but there’s a place for each. Declarative RI usually gets the nod over triggers and stored procedures because it’s easy to use and because it alleviates the possibility of a bug in a trigger or stored procedure compromising data integrity. Declarative “RI is also typically faster than a comparable trigger because it is enforced before the pending change is made. Triggers, by contrast, execute just after a change has been recorded in the transaction log but before it’s been written to the database. This is what permits them to work with the before and after images of the changed data. This notwithstanding, sometimes triggers are a better choice due to their increased power and flexibility.
And there’s nothing wrong with stored procedures that pull double duty and carry out DML (Data Management Language) requests as well as ensure data integrity. In fact, some shops work exclusively in this mode, creating INSERT, UPDATE, and DELETE procedures for every table in a database. This isn’t taboo and has its place in the complex world that is database application development.
One way in which stored procedures are better than triggers for ensuring RI is in their ability to enforce data integrity even when constraints are present. If you use a stored procedure, say, to perform deletes on a given table, that stored procedure can ensure that no foreign key references will be broken prior to the delete and display the appropriate error message if necessary. All the while, a declarative foreign key constraint on the table can serve as a safety net by providing airtight protection against inappropriate deletions. That’s not possible with a delete trigger. Since declarative constraints have precedence over triggers, a deletion that would violate referential integrity will be nabbed first by the constraint, and your app may have no control over what message, if any, is displayed for the user. In the case of deletes that violate foreign key references, the delete trigger will never even get to process the delete because it will be rolled back by the constraint before the trigger ever sees it.
It’s not as though you can use only one of these methods to ensure referential integrity in the database apps you build—most shops have a mix. It’s not unusual to see declarative RI make up the lion’s share of an RI scheme, with triggers and stored procedures supplementing where necessary.
A foreign key constraint establishes a relationship between two tables. It ensures that a key value inserted or updated in the referencing table exists in the referenced table and that a key value in the referenced table cannot be deleted as long as rows in the referencing table depend on it.
The ANSI SQL-92 specification defines four possible actions that can occur when a data modification is attempted: NO ACTION, SET NULL, SET DEFAULT, and CASCADE. Of these, only the first one, NO ACTION, is supported directly by SQL Server. For example, if you attempt an update or deletion that would break a foreign key reference, SQL Server rejects the change and aborts the command—the end result of your modification is NO ACTION.
Though SQL Server doesn’t directly support the other three referential actions, you can still implement them in stored procedures and triggers. Triggers, for example, are quite handy for implementing cascading deletes and updates. Stored procedures are the tool of choice for implementing the SET NULL and SET DEFAULT actions since a trigger cannot directly modify a row about to be modified.
SQL Server strictly enforces foreign key relationships with one notable exception. If the column in the referencing table allows NULL values, NULLs are allowed regardless of whether the referenced table contains a NULL entry. In this sense, NULLs circumvent SQL Server’s declarative RI mechanism. This makes more sense if you think of NULL as a value that’s missing rather than an actual column value.
The target of the foreign key reference must have a unique index on the columns referenced by the dependent table. This index can exist in the form of a primary or unique key constraint or a garden-variety unique key index. Regardless of how it’s constructed, SQL Server’s declarative RI mechanism requires the presence of a unique index on the appropriate columns in the referenced table.
The presence of foreign key constraints on a table precludes the use of TRUNCATE TABLE. This is true regardless of whether deleting the rows would break a foreign key relationship. Rows deleted by TRUNCATE TABLE aren’t recorded in the transaction log, so no row-oriented operations (such as checking foreign key constraints) are possible. It’s precisely because TRUNCATE TABLE deals with whole pages rather than individual rows that it’s so much faster than DELETE.
Default constraints establish default column values. These can be more than mere constant values—they can consist of CASE expressions, functions, and other types of scalar expressions (but not subqueries). Here’s an example:
CREATE TABLE #testdc (c1 int DEFAULT CASE WHEN SUSER_SNAME()=’JOE’ THEN 1 ELSE 0 END)
INSERT #testdc DEFAULT VALUES
SELECT * FROM #testdc
Even though they can’t contain subqueries, default constraints can be quite complex. Here’s an example that defines a default constraint that supplies a random number default value:
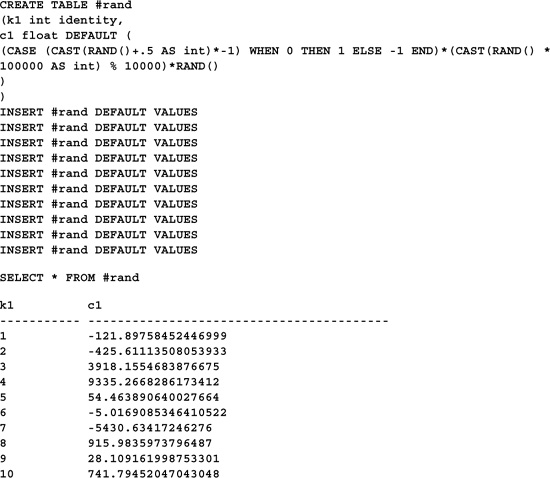
The (CASE (CAST(RAND()+.5 AS int)*-1) WHEN 0 THEN 1 ELSE -1 END) expression randomizes the sign of the generated number, allowing for both positive and negative numbers, while the (CAST(RAND() * 100000 AS int) % 10000)*RAND() expression generates an integer between 0 and 9999.
These exotic expressions aren’t limited to numeric columns. You can specify intricate default expressions for other types of columns as well. Here’s an example that supplies a random number for a numeric column and a random character string for a varchar column:
CREATE TABLE #rand
(k1 int identity,
c1 float DEFAULT (
(CASE (CAST(RAND()+.5 AS int)*-1) WHEN 0 THEN 1 ELSE -1 END)*(CAST(RAND() *
100000 AS int) % 10000)*RAND()
),
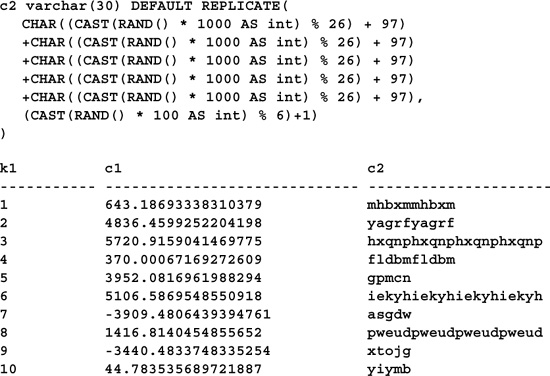
The technique used to build the varchar default is worth discussing. It begins by creating a string of five random lowercase characters (the %26 operation returns a number between 0 and 25; since 97 is the ASCII value of a, incrementing the number by 97 and converting it to a character value produces a character between a and z). It then replicates that five-character string between 1 and 6 times (the %6 operation returns a number between 0 and 5, which we then increment by 1) to create a string with a maximum length of 30 characters—the defined width of the column.
Though it’s not documented, you can drop multiple objects of a given type simultaneously using the appropriate DROP command. For example, to drop multiple tables, you can issue a single DROP TABLE followed by a comma-separated list of the tables to drop. This also applies to stored procedures, views, and other types of objects. Here’s an example:
There are a number of restrictions related to SQL Server indexes that bear mentioning. These are sensible limitations, but they’re ones of which you should be aware as you design databases.
First, you can’t create indexes on bit, text, ntext, or image columns. With the exception of bit, these are all BLOB data types, so it’s logical that you can’t create standard indexes on them. (For information on creating BLOB indexes, see Chapter 18, “Full-Text Search.”) The reasoning behind not allowing bit indexes is also pretty sound. The purpose of an index is to locate a row within a table. SQL Server builds balanced trees (B-trees) using the distinct values in the index’s underlying data. If a column has only two distinct values, it’s virtually useless as an aid in locating a row. A tree representing it would have exactly two branches, though there could be millions of rows in the table. SQL Server would always choose to read the data sequentially rather than deal with an index branch with only two distinct values, so creating such an index would be a waste of time. That’s why the server doesn’t allow it—there would be no point in building a bit index—it would never be used.
To grasp why a column with just two distinct values is so useless as an index key, imagine being a private investigator with the task of locating a missing person and having no information to go on other than the person’s sex. Half the world’s population would match your description. That’s a lot of missing people!
Another limitation of SQL Server indexing is the inability to create indexes on computed columns. SQL Server doesn’t allow indexes on computed columns because computed columns do not actually exist in the database—they don’t store any real data. A computed column in a table is just like one in a view—they’re both rendered when queried, but they do not otherwise exist. Since there’s no permanent data to index, indexes on computed columns simply aren’t allowed.
When used in conjunction with FILLFACTOR, CREATE INDEX’s PAD_INDEX option causes the intermediate pages in an index to assume the same fill percentage as that specified by FILLFACTOR for the leaf nodes. Here’s an example:
IF INDEXPROPERTY(OBJECT_ID(’titles’),’typeind’,’IsClustered’) IS NOT NULL
DROP INDEX titles.typeind
GO
CREATE INDEX typeind ON titles (type) WITH PAD_INDEX, FILLFACTOR = 10
PAD_INDEX is useful when you know in advance that you’re about to load a sizable portion of new data that will cause page splits and row relocation in an index’s intermediate pages if sufficient space isn’t set aside up front for the new data.
As of SQL Server 7.0, CREATE INDEX’s SORTED_DATA and SORTED_DATA_REORG options are no longer supported. In their place is the new DROP_EXISTING option. DROP_EXISTING allows you to drop and recreate an index in one step. DROP_EXISTING offers special performance enhancements for clustered indexes in that it rebuilds dependent nonclustered indexes only once and only when the clustered key values change. If the data is already sorted in the correct order, DROP_EXISTING doesn’t resort the data but does compact it using the current FILLFACTOR value (providing the same basic functionality as the old SORTED_DATA_REORG option).
Because the recreation of a clustered index and its dependent nonclustered indexes using DROP_EXISTING is carried out in one step, it’s inherently atomic—either all the indexes will be created, or none of them will be. For a comparable set of DROP INDEX/CREATE INDEX statements to have this same atomicity, the whole operation would have to be encapsulated in a transaction.
SQL Server supports two types of temporary objects—local temporary objects and global temporary objects. Locals are prefixed with one pound sign (#); globals are prefixed with two (##).
As of SQL Server 7.0, the CREATE VIEW, CREATE DEFAULT, and CREATE RULE commands no longer support creating temporary objects. Prior to version 7.0, you could create these objects, but you couldn’t do anything with them—not terribly useful. That behavior has now been rectified, so in order to create a view, default, or rule that resides in tempdb, you must first change the current database context to tempdb, then issue the appropriate CREATE command.
On a related note, these three CREATE statements don’t permit you to use qualified object names—the name you specify must be an unqualified, one-part object identifier. If you want to create an object in tempdb, you must first switch the database context. Of course, changing to tempdb to create an object means that you must fully qualify objects it references that reside elsewhere. This limitation does not apply to CREATE TABLE, which directly supports creating objects in other databases.
As with tables, you can create temporary stored procedures by prefixing the procedure name with a pound sign (#). You can create global temporary procedures by prefixing the name with a double pound sign (##). These stored procedures can then be executed just like any other stored procedure. In the case of global temporary procedures, they can even be executed by other connections.
Prior to 7.0, SQL Server reported an error if you attempted to specify a local temporary table name that was longer than 20 characters. This has been fixed, and local temporary table names may now be up to 116 characters long.
Global temporary tables (those prefixed with ##) are visible to all users and, as such, are not uniquely named for each connection. That’s what distinguishes them from local temporary tables. This global visibility makes them ideal for status tables for long running reports and jobs. Since the table is globally accessible, the report or job can place in it status messages that can be viewed from other connections. Here’s an example:
SET NOCOUNT ON
DECLARE @statusid int
CREATE TABLE ##jobstatus
(statusid int identity,
start datetime,
finish datetime NULL,
description varchar(50),
complete bit DEFAULT 0)
INSERT ##jobstatus VALUES (GETDATE(),NULL,’Updating index stats for pubs’,0)
SET @statusid=@@IDENTITY
PRINT ’’
SELECT description AS ’JOB CURRENTLY EXECUTING’ FROM ##jobstatus WHERE
statusid=@statusid
EXEC pubs..sp_updatestats
UPDATE ##jobstatus SET finish=GETDATE(), complete=1
WHERE statusid=@statusid
INSERT ##jobstatus VALUES (GETDATE(),NULL,’Updating index stats for northwind’,0)
SET @statusid=@@IDENTITY
PRINT ’’
SELECT description AS ’JOB CURRENTLY EXECUTING’ FROM ##jobstatus WHERE
statusid=@statusid
EXEC northwind..sp_updatestats
UPDATE ##jobstatus SET finish=GETDATE(), complete=1
WHERE statusid=@statusid
SELECT * FROM ##jobstatus
GO
DROP TABLE ##jobstatus
JOB CURRENTLY EXECUTING
--------------------------------------------
Updating index stats for pubs
Updating dbo.authors
Updating dbo.publishers
Updating dbo.titles
Updating dbo.employee
Statistics for all tables have been updated.
JOB CURRENTLY EXECUTING
--------------------------------------------
Updating index stats for northwind
Updating dbo.employees
Updating dbo.categories
Updating dbo.customers
Statistics for all tables have been updated.
sid start finish description complete
--- ------------------- ------------------- ---------------------------------- --------
1 1999-07-24 16:26:40 1999-07-24 16:26:49 Updating index stats for pubs 1
2 1999-07-24 16:26:41 1999-07-24 16:26:49 Updating index stats for northwind 1
Unqualified object names are resolved using the following process:
1. SQL Server checks to see whether you own an object with the specified name in the current database.
2. It then checks to see whether the DBO owns a table with the specified name in the current database.
3. If the object name you specified is prefixed with a pound sign (#), the server checks to see whether you own a local temporary table or procedure with that name.
4. If the object name you specified is prefixed with two pound signs (##), the server checks to see whether a global temporary table or procedure with that name exists.
5. If the object name is prefixed with “sp_” and you are using it in a valid context for a stored procedure, the server first checks the current database and then the master database to see whether you or the DBO owns an object with the specified name.
6. If not one of these conditions is met, the object is not found, and an error condition results.
You can temporarily change the database context in which a system stored procedure will run by prefixing it with the name of the database in which you want it to execute. That is, even though the procedure resides in the master database, you can treat it as though it resides in a different database, like so:
EXEC pubs..sp_spaceused
Regardless of your current database at the time of execution, the stored procedure will run as though you were in the specified database when you ran it.
Thanks to SQL Server 7.0’s deferred name resolution, you can now refer to a temporary table’s indexes by name within the stored procedure that creates it. In version 6.5 and earlier, you were forced to reference them by number. Since object names aren’t translated into their underlying identifiers in SQL Server 7.0 until the procedure runs, you’re now able to reference temporary table indexes by name in the same manner as indexes on permanent tables.
There’s a bit of a quirk in SQL Server’s CREATE VIEW command that allows you to create views on tables to which you have no access. No message is generated and the CREATE VIEW operation appears to work fine. However, an error is returned if you attempt to access the view, making it basically useless. Since no compile-time message is generated, it pays to verify that proper rights have been granted on the objects referenced by a view before putting it into production.
SQL Server’s object dependency mechanism (which uses the sp_depends stored procedure) is inherently deficient and you shouldn’t rely on it to provide accurate dependency information. The original idea behind sp_depends was for object dependency relationships to be stored in the sysdepends table in every database to ensure that dependency info was complete and readily accessible. Unfortunately, it didn’t quite work out that way. The mechanism has a bevy of fundamental flaws. Among them:
1. Objects outside the current database are not reported.
2. If an object with dependents is dropped, its dependency information is dropped with it.
3. Recreating an object that has dependents doesn’t restore or recreate its dependency information.
4. Thanks to SQL Server’s deferred name resolution, you will see dependency information only for those objects that actually exist when an object is created.
5. By design, the only way the information contained in sysdepends can be kept up to date is to drop and recreate all the objects in the database periodically in order of dependence.
Personally, the facility has always felt rather perfunctory—like it was an afterthought that someone squeezed into production right before shipping without thinking it through very well. The best thing you can do with sp_depends is to avoid using it. That goes for the object dependency report in Enterprise Manager, as well. It’s just as unreliable as sp_depends.