
Assuming that you manage to locate a potentially exploitable vulnerability, how can IDA help with the exploit-development process? The answer to this question requires that you understand what type of help you need in order for you to make use of the appropriate features of IDA.
IDA is very good at several things that can save you a tremendous amount of trial and error when developing exploits:
IDA graphs can be useful in determining control flow paths as a means of understanding how a vulnerable function may be reached. Careful selection of graph-generation parameters may be required in large binaries in order to minimize the complexity of generated graphs. Refer to Chapter 9 for more information on IDA graphs.
IDA breaks down stack frames to a great level of detail. If you are overwriting information in the stack, IDA will help you understand exactly what is getting overwritten by which portions of your buffer. IDA stack displays are also invaluable in determining the memory layout of format string buffers.
IDA has excellent search facilities. If you need to search for a specific instruction (such as
jmp esp) or sequence of instructions (such aspop/pop/ret) within a binary, IDA can rapidly tell you whether the instruction(s) is present in the binary and, if so, the exact virtual address at which the instruction(s) is located.The fact that IDA maps binaries as if they are loaded in memory makes it easier for you to locate virtual addresses that you may require in order to land your exploit. IDA’s disassembly listings make it simple to determine the virtual address of any globally allocated buffers as well as useful addresses (such as
GOTentries) to target when you have a write4[195] capability.
We will discuss several of these capabilities and how you can leverage them in the following sections.
While stack-protection mechanisms are rapidly becoming standard features in modern operating systems, many computers continue to run operating systems that allow code to be executed in the stack, as is done in a plain-vanilla stack-based buffer-overflow attack. Even when stack protections are in place, overflows may be used to corrupt stack-based pointer variables, which can be further leveraged to complete an attack.
Regardless of what you intend to do when you discover a stack-based buffer overflow, it is vital to understand exactly what stack content will be overwritten as your data overflows the vulnerable stack buffer. You will probably also be interested in knowing exactly how many bytes you need to write into the buffer until you can control various variables within the function’s stack frame, including the function’s saved return address. IDA’s default stack frame displays can answer all of these questions if you are willing to do a little math. The distance between any two variables in the stack can be computed by subtracting the stack offsets of the two variables. The following stack frame includes a buffer that can be overflowed when input to the corresponding function is carefully controlled:
−0000009C result dd ? −00000098 buffer_132 db 132 dup(?) ; this can be overflowed −00000014 p_buf dd ? ; pointer into buffer_132 −00000010 num_bytes dd ? ; bytes read per loop −0000000C total_read dd ? ; total bytes read −00000008 db ? ; undefined −00000007 db ? ; undefined −00000006 db ? ; undefined −00000005 db ? ; undefined −00000004 db ? ; undefined −00000003 db ? ; undefined −00000002 db ? ; undefined −00000001 db ? ; undefined +00000000 s db 4 dup(?) +00000004 r db 4 dup(?) ; save return address +00000008 filedes dd ? ; socket descriptor
The distance from the beginning of the vulnerable buffer (buffer_132) to the saved return address is 156 bytes (4 - −98h, or 4 - −152). You can also see that after 132 bytes (−14h - −98h), the contents of p_buf will start to get overwritten, which may or may not cause problems. You must clearly understand the effect of overwriting variables that lie beyond the end of the buffer in order to prevent the target application from crashing before the exploit can be triggered. In this example, filedes (a socket descriptor) might be another problematic variable. If the vulnerable function expects to use the socket descriptor after you have finished overflowing the buffer, then you need to take care that any overwriting of filedes will not cause the function to error out unexpectedly. One strategy for dealing with variables that will be overwritten is to write values into these variables that make sense to the program so that the program continues to function normally until your exploit is triggered.
For a slightly more readable breakdown of a stack frame, we can modify the stack buffer–scanning code from Example 22-3 to enumerate all members of a stack frame, compute their apparent size, and display the distance from each member to the saved return address. Example 22-4 shows the resulting script.
Example 22-4. Enumerating a single stack frame using Python
func = ScreenEA() #process function at cursor location
frame = GetFrame(func)
if frame != −1:
Message("Enumerating stack for %s
" % GetFunctionName(func))
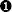 eip_loc = GetFrameLvarSize(func) + GetFrameRegsSize(func)
prev_idx = −1
idx = 0
while idx < GetStrucSize(frame):
member = GetMemberName(frame, idx)
if member is not None:
if prev_idx != −1:
#compute distance from previous field to current field
delta = idx - prev_idx
Message("%15s: %4d bytes (%4d bytes to eip)
" %
(prev, delta, eip_loc - prev_idx))
prev_idx = idx
prev = member
idx = idx + GetMemberSize(frame, idx)
else:
idx = idx + 1
if prev_idx != −1:
#make sure we print the last field in the frame
delta = GetStrucSize(frame) - prev_idx
Message("%15s: %4d bytes (%4d bytes to eip)
" %
(prev, delta, eip_loc - prev_idx))
eip_loc = GetFrameLvarSize(func) + GetFrameRegsSize(func)
prev_idx = −1
idx = 0
while idx < GetStrucSize(frame):
member = GetMemberName(frame, idx)
if member is not None:
if prev_idx != −1:
#compute distance from previous field to current field
delta = idx - prev_idx
Message("%15s: %4d bytes (%4d bytes to eip)
" %
(prev, delta, eip_loc - prev_idx))
prev_idx = idx
prev = member
idx = idx + GetMemberSize(frame, idx)
else:
idx = idx + 1
if prev_idx != −1:
#make sure we print the last field in the frame
delta = GetStrucSize(frame) - prev_idx
Message("%15s: %4d bytes (%4d bytes to eip)
" %
(prev, delta, eip_loc - prev_idx))This script introduces the GetFrameLvarSize and GetFrameRegsSize functions (also available in IDC). These functions are used to retrieve the size of a stack frame’s local variable and saved register areas, respectively. The saved return address lies directly beneath these two areas, and the offset to the saved return address is computed as the sum of these two values ![]() . When executed against our example function, the script produces the following output:
. When executed against our example function, the script produces the following output:
Enumerating stack for handleSocket
result: 4 bytes ( 160 bytes to eip)
buffer_132: 132 bytes ( 156 bytes to eip)
p_buf: 4 bytes ( 24 bytes to eip)
num_bytes: 4 bytes ( 20 bytes to eip)
total_read: 12 bytes ( 16 bytes to eip)
s: 4 bytes ( 4 bytes to eip)
r: 4 bytes ( 0 bytes to eip)
fildes: 4 bytes ( −4 bytes to eip)The results offer a concise summary of a function’s stack frame annotated with additional information of potential use to an exploit developer.
IDA’s stack frame displays also prove useful when developing exploits for format string vulnerabilities. As an example, consider the following short code fragment in which the fprintf function is invoked with a user-supplied buffer provided as the format string.
.text:080488CA lea eax, [ebp+format].text:080488D0 mov [esp+4], eax ; format .text:080488D4 mov eax, [ebp+stream]
In this example, only two arguments are passed to fprintf, a file pointer ![]() and the address of the user’s buffer as a format string
and the address of the user’s buffer as a format string ![]() . These arguments occupy the top two positions on the stack, memory that has already been allocated by the calling function as part of the function’s prologue. The stack frame for the vulnerable function is shown in Example 22-5.
. These arguments occupy the top two positions on the stack, memory that has already been allocated by the calling function as part of the function’s prologue. The stack frame for the vulnerable function is shown in Example 22-5.
Example 22-5. Stack frame for format string example
The 16 undefined bytes spanning frame offsets 128h through 119h represent the block of memory that the compiler (gcc in this case) has preallocated for the arguments passed in to the functions that will be called by the vulnerable function. The stream argument to fprintf will be placed at the top of the stack ![]() , while the format string pointer will be placed immediately below
, while the format string pointer will be placed immediately below ![]() the
the stream argument.
In format string exploits, an attacker is often interested in the distance from the format string pointer to the beginning of the buffer holding the attacker’s input. In the preceding stack frame, 16 bytes separate the format string argument from the actual format string buffer. To further the discussion, we will assume that an attacker has entered the following format string.
"%x %x %x %x %x"
Here, fprintf would expect five arguments immediately following the format string argument. The first four of these arguments would occupy the space between the format string argument and the format string buffer. The fifth, and final, of these arguments would overlap the first four bytes of the format string buffer itself. Readers familiar with format string exploits[196] will know that arguments within a format string may be named explicitly by index number. The following format string demonstrates accessing the fifth argument following the format string in order to format it as a hexadecimal value.
"%5$x"
Continuing with the preceding example, this format string would read the first 4 bytes of the format string buffer as an integer (which we previously noted would occupy the space of the fifth argument to the format string should one have been required), format that integer as a hexadecimal value, and then output the result to the specified file stream. Additional arguments to the format string (the sixth, seventh, and so on) would overlap successive 4-byte blocks within the format string buffer.
Crafting a format string that will work properly to exploit a vulnerable binary can be tricky and generally relies on precise specification of arguments within the format string. The preceding discussion demonstrates that, in many cases, IDA may be used to quickly and accurately compute required offsets into a format string buffer. By combining this information with information that IDA presents when disassembling various program sections, such as the global offset table (.got) or the destructor table (.dtor), a correct format string may be derived accurately with no trial and error as might be required when using only a debugger to develop an exploit.
In order to reliably land an exploit, it is often useful to employ a control-transfer mechanism that does not require you to know the exact memory address at which your shellcode resides. This is particularly true when your shellcode lies in the heap or the stack, which may make the address of your shellcode unpredictable. In such cases, it is desirable to find a register that happens to point at your shellcode at the time your exploit is triggered. For example, if the ESI register is known to point at your shellcode at the moment you take control of the instruction pointer, it would be very helpful if the instruction pointer happened to point to a jmp esi or call esi instruction, which would vector execution to your shellcode without requiring you to know the exact address of your shellcode. Similarly a jmp esp is often a very handy way to transfer control to shellcode that you have placed in the stack. This takes advantage of the fact that when a function containing a vulnerable buffer returns, the stack pointer will be left pointing just below the same saved return address that you just overwrote. If you continued to overwrite the stack beyond the saved return address, then the stack pointer is pointing at your data (which should be code!). The combination of a register pointing at your shellcode along with an instruction sequence that redirects execution by jumping to or calling the location pointed to by that register is called a trampoline.
The notion of searching for such instruction sequences is not a new one. In Appendix D of his paper “Variations in Exploit Methods between Linux and Windows,”[197] David Litchfield presents a program named getopcode.c designed to search for useful instructions in Linux ELF binaries. Along similar lines, the Metasploit[198] project offers its msfpescan tool, which is capable of scanning Windows PE binaries for useful instruction sequences. IDA is just as capable of locating interesting instruction sequences as either of these tools when given the chance.
For the sake of example, assume that you would like to locate a jmp esp instruction in a particular x86 binary. You could use IDA’s text-search features to look for the string jmp esp, which you would only find if you happened to have exactly the right number of spaces between jmp and esp and which you are unlikely to find in any case because a jump into the stack is seldom used by any compiler. So why bother searching in the first place? The answer lies in the fact that what you are actually interested in is not an occurrence of the disassembled text jmp esp but rather the byte sequence FF E4, regardless of its location. For example, the following instruction contains an embedded jmp esp:
.text:080486CD B8 FF FF E4 34 mov eax, 34E4FFFFh
Virtual address 080486CFh may be used if a jmp esp is desired. IDA’s binary search (Search ▸ Sequence of Bytes) capability is the correct way to rapidly locate byte sequences such as these. When performing a binary search for exact matches against a known byte sequence, remember to perform a case-sensitive search, or a byte sequence such as 50 C3 (push eax/ret) will be matched by the byte sequence 70 C3 (because 50h is an uppercase P, while 70h is a lowercase p), which is a jump on overflow with a relative offset of –61 bytes. Binary searches can be scripted using the FindBinary function, as shown here:
ea = FindBinary(MinEA(), SEARCH_DOWN | SEARCH_CASE, "FF E4");
This function call begins searching down (toward higher addresses) from the lowest virtual address in the database, in a case-sensitive manner, in search of a jmp esp (FF E4). If sequence is found, the return value is the virtual address of the start of the byte sequence. If the sequence is not found, the return value is BADADDR (−1). A script that automates searches for a wider variety of instructions is available on the book’s website. Using this script, we might request a search for instructions that transfer control to the location pointed to by the EDX register and receive results similar to the following:
Searching... Found jmp edx (FF E2) at 0x80816e6 Found call edx (FF D2) at 0x8048138 Found 2 occurrences
Convenience scripts such as these can save a substantial amount of time while ensuring that we don’t forget to cover all possible cases as we search for items in a database.
The last item we will mention briefly is IDA’s display of virtual addresses in its disassemblies. Situations in which we know that our shellcode is going to end up in a static buffer (in a .data or .bss section, for example) are almost always better than situations in which our shellcode lands in the heap or the stack, because we end up with a known, fixed address to which we can transfer control. This usually eliminates the need for NOP slides or the need to find special instruction sequences.
Some exploits take advantage of the fact that attackers are able to write any data they like to any location they choose. In many cases, this may be restricted to a 4-byte overwrite, but this amount often turns out to be sufficient. When a 4-byte overwrite is possible, one alternative is to overwrite a function pointer with the address of our shellcode. The dynamic linking process used in most ELF binaries utilizes a table of function pointers called the global offset table (GOT) to store addresses of dynamically linked library functions. When one of these table entries can be overwritten, it is possible to hijack a function call and redirect the call to a location of the attacker’s choosing. A typical sequence of events for an attacker in such cases is to stage shellcode in a known location and then overwrite the GOT entry for the next library function to be called by the exploited program. When the library function is called, control is instead transferred to the attacker’s shellcode.
The addresses of GOT entries are easily found in IDA by scrolling to the got section and browsing for the function whose entry you wish to overwrite. In the name of automating as much as possible, though, the following Python script quickly reports the address of the GOT entry that will be used by a given function call:
ea = ScreenEA() dref = ea for xref in XrefsFrom(ea, 0):
This script is executed by placing the cursor on any call to a library function, such as the following, and invoking the script.
.text:080513A8 call _memset
The script operates by walking forward through cross-references until the GOT is reached. The first cross-reference that is retrieved ![]() is tested to ensure that it is a call reference and that it references the ELF procedure linkage table (
is tested to ensure that it is a call reference and that it references the ELF procedure linkage table (.plt). PLT entries contain code that reads a GOT entry and transfers control to the address specified in the GOT entry. The second cross-reference retrieved ![]() obtains the address of the location being read from the PLT, and this is the address of the associated GOT entry. When executed on the preceding call to
obtains the address of the location being read from the PLT, and this is the address of the associated GOT entry. When executed on the preceding call to _memset, the output of the script on our example binary yields the following:
GOT entry for .memset is at 0x080618d8
This output provides us with exactly the information we require if our intention is to take control of the program by hijacking a call to memset, namely that we need to overwrite the contents of address 0x080618d8 with the address of our shellcode.
[195] A write4 capability presents an attacker with the opportunity to write 4 bytes of his choosing to a memory location of his choosing.
[196] Readers wishing to learn more about format string exploits might again refer to Jon Erickson’s Hacking: The Art of Exploitation, 2nd Edition.
[197] See http://www.nccgroup.com/Libraries/Document_Downloads/Variations_in_Exploit_methods_between_Linux_and_Windows.sflb.ashx.
[198] See http://www.metasploit.com/.