
Chapter 5. Working with Active Record
An object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data.
—Martin Fowler, Patterns of Enterprise Architecture
The Active Record pattern, identified by Martin Fowler in his seminal work, Patterns of Enterprise Architecture, maps one domain class to one database table, and one instance of that class to each row of that database. It is a simple approach that, while not perfectly applicable in all cases, provides a powerful framework for database access and object persistence in your application.
The Rails Active Record framework includes mechanisms for representing models and their relationships, CRUD (Create, Read, Update, and Delete) operations, complex searches, validation, callbacks, and many more features. It relies heavily on convention over configuration, so it’s easy to use when you’re creating a new database schema that can follow those conventions. However, Active Record also provides configuration settings that let you adapt it to work well with legacy database schemas that don’t necessarily conform to Rails conventions.
According to Martin Fowler, delivering the keynote address at the inaugural Rails conference in 2006, Ruby on Rails has successfully taken the Active Record pattern much further than anyone imagined it could go. It shows you what you can achieve when you have a single-minded focus on a set of ideals, which in the case of Rails is simplicity.
5.1 The Basics
For the sake of completeness, let’s briefly review the basics of how Active Record works. In order to create a new model class, the first thing you do is to declare it as a subclass of ActiveRecord::Base, using Ruby’s class extension syntax:
class Client < ActiveRecord::Base
end
By convention, an Active Record class named Client will be mapped to the clients table. Rails understands pluralization, as covered in the section “Pluralization” in this chapter. Also by convention, Active Record will expect an id column to use as primary key. It should be an integer and incrementing of the key should be managed automatically by the database server when creating new records. Note how the class itself makes no mention of the table name, columns, or their datatypes.
Each instance of an Active Record class provides access to the data from one row of the backing database table, in an object-oriented manner. The columns of that row are represented as attributes of the object, using straightforward type conversions (i.e. Ruby strings for varchars, Ruby dates for dates, and so on), and with no default data validation. Attributes are inferred from the column definition pertaining to the tables with which they’re linked. Adding, removing, and changing attributes and their types are done by changing the columns of the table in the database.
When you’re running a Rails server in development mode, changes to the database schema are reflected in the Active Record objects immediately, via the web browser. However, if you make changes to the schema while you have your Rails console running, the changes will not be reflected automatically, although it is possible to pick up changes manually by typing reload! at the console.
Courtenay says ...
Active Record is a great example of the Rails “Golden Path.” If you keep within its limitations, you can go far, fast. Stray from the path, and you might get stuck in the mud. This Golden Path involves many conventions, like naming your tables in the plural form (“users”). It’s common for new developers to Rails and rival web-framework evangelists to complain about how tables must be named in a particular manner, how there are no constraints in the database layer, that foreign keys are handled all wrong, enterprise systems must have composite primary keys, and more. Get the complaining out of your system now, because all these defaults are simply defaults, and in most cases can be overridden with a single line of code or a plugin.
5.2 Macro-Style Methods
Most of the important classes you write while coding a Rails application are configured using what I call macro-style method invocations (also known in some circles as a domain-specific language or DSL). Basically, the idea is to have a highly readable block of code at the top of your class that makes it immediately clear how it is configured.
Macro-style invocations are usually placed at the top of the file, and for good reason. Those methods declaratively tell Rails how to manage instances, perform data validation and callbacks, and relate with other models. Many of them do some amount of metaprogramming, meaning that they participate in adding behavior to your class at runtime, in the form of additional instance variables and methods.
5.2.1 Relationship Declarations
For example, look at the Client class with some relationships declared. We’ll talk about associations extensively in Chapter 7, Active Record Associations, but all I want to do right now is to illustrate what I’m talking about when I say macro-style:

As a result of those three has_many declarations, the Client class gains at least three new attributes, proxy objects that let you manipulate the associated collections interactively.
I still remember the first time I sat with an experienced Java programmer friend of mine to teach him some Ruby and Rails. After minutes of profound confusion, an almost visible light bulb appeared over his head as he proclaimed, “Oh! They’re methods!”
Indeed, they’re regular old method calls, in the context of the class object. We leave the parentheses off to emphasize the declarative intention. That’s a style issue, but it just doesn’t feel right to me with the parentheses in place, as in the following code snippet:

When the Ruby interpreter loads client.rb, it executes those has_many methods, which, again, are defined as class methods of Active Record’s Base class. They are executed in the context of the Client class, adding attributes that are subsequently available to Client instances. It’s a programming model that is potentially strange to newcomers, but quickly becomes second nature to the Rails programmer.
5.2.2 Convention over Configuration
Convention over configuration is one of the guiding principles of Ruby on Rails. If we follow Rails conventions, very little explicit configuration is needed, which stands in stark contrast to the reams of configuration that are required to get even a simple application running in other technologies.
It’s not that a newly bootstrapped Rails application comes with default configuration in place already, reflecting the conventions that will be used. It’s that the conventions are baked into the framework, actually hard-coded into its behavior, and you need to override the default behavior with explicit configuration when applicable.
It’s also worth mentioning that most configuration happens in close proximity to what you’re configuring. You will see associations, validations, and callback declarations at the top of most Active Record models.
I suspect that the first explicit configuration (over convention) that many of us deal with in Active Record is the mapping between class name and database table, since by default Rails assumes that our database name is simply the pluralized form of our class name.
5.2.3 Setting Names Manually
The set_table_name and set_primary_key methods let you use any table and primary names youd like, but youll have to specify them explicitly in your model class. It’s only a couple of extra lines per model, but on a large application it adds unnecessary complexity, so don’t do it if you don’t absolutely have to.
When you’re not at liberty to dictate the naming guidelines for your database schema, such as when a separate DBA group controls all database schemas, then you probably don’t have a choice. But if you have flexibility, you should really just follow Rails conventions. They might not be what you’re used to, but following them will save you time and unnecessary headaches.
5.2.4 Legacy Naming Schemes
If you are working with legacy schemas, you may be tempted to automatically set_table_name everywhere, whether you need it or not. Before you get accustomed to doing that, learn the additional options available that might just be more DRY and make your life easier.
Let’s assume you need to turn off table pluralization altogether; you would set the following attribute to your config/application.rb:
config.active_record.pluralize_table_names = false
There are various other useful attributes of ActiveRecord::Base, provided for configuring Rails to work with legacy naming schemes.
primary_key_prefix_type
Accessor for the prefix type that will be prepended to every primary key column name. If :table_name is specified, Active Record will look for tableid instead of id as the primary column. If :table_name_with_underscore is specified, Active Record will look for table_id instead of id.
table_name_prefix
Some departments prefix table names with the name of the database. Set this attribute accordingly to avoid having to include the prefix in all of your model class names.
table_name_suffix
Similar to prefix, but adds a common ending to all table names.
5.3 Defining Attributes
The list of attributes associated with an Active Record model class is not coded explicitly. At runtime, the Active Record model examines the database schema directly from the server. Adding, removing, and changing attributes and their type is done by manipulating the database itself via Active Record migrations.
The practical implication of the Active Record pattern is that you have to define your database table structure and make sure it exists in the database prior to working with your persistent models. Some people may have issues with that design philosophy, especially if they’re coming from a background in top-down design.
The Rails way is undoubtedly to have model classes that map closely to your database schema. On the other hand, remember you can have models that are simple Ruby classes and do not inherit from ActiveRecord::Base. Among other things, it is common to use non-Active Record model classes to encapsulate data and logic for the view layer.
5.3.1 Default Attribute Values
Migrations let you define default attribute values by passing a :default option to the column method, but most of the time you’ll want to set default attribute values at the model layer, not the database layer. Default values are part of your domain logic and should be kept together with the rest of the domain logic of your application, in the model layer.
A common example is the case when your model should return the string “n/a” instead of a nil (or empty) string for an attribute that has not been populated yet. Seems simple enough and it’s a good way to learn how attributes exist at runtime.
To begin, let’s whip up a quick spec describing the desired behavior.

We run that test and it fails, as expected. Active Record doesn’t provide us with any class-level methods to define default values for models declaratively. So it seems we’ll have to create an explicit attribute accessor that provides a default value.
Normally, attribute accessors are handled magically by Active Record’s internals, but in this case we’re overriding the magic with an explicit getter. All we need to do is to define a method with the same name as the attribute and use Ruby’s || operator, which will short-circuit if @category is not nil.

Now we run the test and it passes. Great. Are we done? Not quite. We should test a case when the real category value should be returned. I’ll insert an example with a not-nil category.

Uh-oh. The first example fails. Seems our default ‘n/a’ string is being returned no matter what. That means that @category must not get set. Should we even know that it is getting set or not? It is an implementation detail of Active Record, is it not?
The fact that Rails does not use instance variables like @category to store the model attributes is in fact an implementation detail. But model instances have a couple of methods, write_attribute and read_attribute, conveniently provided by Active Record for the purposes of overriding default accessors, which is exactly what we’re trying to do. Let’s fix our TimesheetEntry class.

Now the test passes. How about a simple example of using write_attribute?

Alternatively, both of these examples could have been written with the shorter forms of reading and writing attributes, using square brackets.

5.3.2 Serialized Attributes
One of Active Record’s coolest features is the ability to mark a column of type text as being serialized. Whatever object (more accurately, graph of objects) you assign to that attribute will be stored in the database as YAML, Ruby’s native serialization format.
Sebastian says ...
TEXT columns usually have a maximum size of 64K and if your serialized attributes exceeds the size constraints, you’ll run into a lot of errors. On the other hand, if your serialized attributes are that big, you might want to rethink what you’re doing. At least move them into a separate table and use a larger column type if your server allows it.
One of the first thing that new Rails developers do when they discover the serialize declaration is to use it to store a hash of arbitrary objects related to user preferences. Why bother with the complexity of a separate preferences table if you can denormalize that data into the users table instead?
class User < ActiveRecord::Base
serialize :preferences, Hash
end
The optional second parameter (used in the example) takes a class that limits the type of object that can be stored. The serialized object must be of that class on retrieval or SerializationTypeMismatch will be raised. Similarly to readonly attributes, access to the list of serialized attributes is handled through serialized_attributes.
The API does not give us an easy way to set a default value. That’s unfortunate, because it would be nice to be able to assume that our preferences attribute is already initialized when we want to use it.

Unless a value has already been set for the attribute, it’s going to be nil. You might be tempted to set a default YAML string for the serialized attribute at the database level, so that it’s not nil when you’re using a newly created object:
add_column :users, :preferences, :text, :default => "--- {}"
However, that approach won’t work with MySQL 5.x, which ignores default values for binary and text columns. One possible solution is to overload the attribute’s reader method with logic that sets the default value if it’s nil.
![]()
I prefer this method over the alternative, using an after_initialize callback, because it incurs a small performance hit only when the preferences attribute is actually used and not at instantiation time of every single User object in your system.
5.4 CRUD: Creating, Reading, Updating, Deleting
The four standard operations of a database system combine to form a popular acronym: CRUD. It sounds somewhat negative, because as a synonym for garbage or unwanted accumulation the word crud in English has a rather bad connotation. However, in Rails circles, use of the word CRUD is benign. In fact, as in earlier chapters, designing your app to function primarily as RESTful CRUD operations is considered a best practice!
5.4.1 Creating New Active Record Instances
The most straightforward way to create a new instance of an Active Record model is by using a regular Ruby constructor, the class method new. New objects can be instantiated as either empty (by omitting parameters) or pre-set with attributes, but not yet saved. Just pass a hash with key names matching the associated table column names. In both instances, valid attribute keys are determined by the column names of the associated table—hence you can’t have attributes that aren’t part of the table columns.
You can find out if an Active Record object is saved by looking at the value of its id, or programmatically, by using the methods new_record? and persisted?:

Active Record constructors take an optional block, which can be used to do additional initialization. The block is executed after any passed-in attributes are set on the instance:

Active Record has a handy-dandy create class method that creates a new instance, persists it to the database, and returns it in one operation:
![]()
The create method takes an optional block, just like new.
5.4.2 Reading Active Record Objects
Finding an existing object by its primary key is very simple, and is probably one of the first things we all learn about Rails when we first pick up the framework. Just invoke find with the key of the specific instance you want to retrieve. Remember that if an instance is not found, a RecordNotFound exception is raised.

By the way, it is entirely common for methods in Ruby to return different types depending on the parameters used, as illustrated in the example. Depending on how find is invoked, you will get either a single Active Record object or an array of them.
For convenience, first, last and all also exist as syntactic sugar wrappers around the find method.
![]()
Finally, the find method also understands arrays of ids, and raises a RecordNotFound exception if it can’t find all of the ids specified:
![]()
5.4.3 Reading and Writing Attributes
After you have retrieved a model instance from the database, you can access each of its columns in several ways. The easiest (and clearest to read) is simply with dot notation:

The private read_attribute method of Active Record, covered briefly in an earlier section, is useful to know about, and comes in handy when you want to override a default attribute accessor. To illustrate, while still in the Rails console, I’ll go ahead and reopen the Client class on the fly and override the name accessor to return the value from the database, but reversed:

Hopefully it’s not too painfully obvious for me to demonstrate why you need read_attribute in that scenario. Recursion is a bitch, if it’s unexpected:

As can be expected by the existence of a read_attribute method (and as we covered earlier in the chapter), there is also a write_attribute method that lets you change attribute values. Just as with attribute getter methods, you can override the setter methods and provide your own behavior:

The preceding example illustrates a way to do basic validation, since it checks to make sure that a value is not blank before allowing assignment. However, as we’ll see in Chapter 8, Validations, there are better ways to do this.
Hash Notation
Yet another way to access attributes is using the [attribute_name] operator, which lets you access the attribute as if it were a regular hash.

String versus symbol
Many Rails methods accept symbol and string parameters interchangeably, and that is potentially very confusing. Which is more correct? The general rule is to use symbols when the string is a name for something, and a string when it’s a value. You should probably be using symbols when it comes to keys of options hashes and the like.
The attributes Method
There is also an attributes method that returns a hash with each attribute and its corresponding value as returned by read_attribute. If you use your own custom attribute reader and writer methods, it’s important to remember that attributes will not use custom attribute readers when accessing its values, but attributes= (which lets you do mass assignment) does invoke custom attribute writers.
>> first_client.attributes
=> {"name"=>"Paper Jam Printers", "code"=>"PJP", "id"=>1}
Being able to grab a hash of all attributes at once is useful when you want to iterate over all of them or pass them in bulk to another function. Note that the hash returned from attributes is not a reference to an internal structure of the Active Record object. It is copy, which means that changing its values will have no effect on the object it came from.

To make changes to an Active Record object’s attributes in bulk, it is possible to pass a hash to the attributes writer.
5.4.4 Accessing and Manipulating Attributes Before They Are Typecast
The Active Record connection adapters, classes that implement behavior specific to databases, fetch results as strings. Rails then takes care of converting them to other datatypes if necessary, based on the type of the database column. For instance, integer types are cast to instances of Ruby’s Fixnum class, and so on.
Even if you’re working with a new instance of an Active Record object, and have passed in constructor values as strings, they will be typecast to their proper type when you try to access those values as attributes.
Sometimes you want to be able to read (or manipulate) the raw attribute data without having the column-determined typecast run its course first, and that can be done by using the attribute_before_type_cast accessors that are automatically created in your model.
For example, consider the need to deal with currency strings typed in by your end users. Unless you are encapsulating currency values in a currency class (highly recommended, by the way) you need to deal with those pesky dollar signs and commas. Assuming that our Timesheet model had a rate attribute defined as a :decimal type, the following code would strip out the extraneous characters before typecasting for the save operation:

5.4.5 Reloading
The reload method does a query to the database and resets the attributes of an Active Record object. The optional options argument is passed to find when reloading so you may do, for example, record.reload(:lock => true) to reload the same record with an exclusive row lock. (See the section “Database Locking” later in this chapter.)
5.4.6 Cloning
Producing a copy of an Active Record object is done simply by calling clone, which produces a shallow copy of that object. It is important to note that no associations will get copied, even though they are stored internally as instance variables.
5.4.7 Dynamic Attribute-Based Finders
Since one of the most common operations in many applications is to simply query on one or two columns, Rails has an easy and effective way to do these queries without having to resort to where. They work thanks to the magic of Ruby’s method_missing callback, which is executed whenever you invoke a method that hasn’t been defined yet.
Dynamic finder methods begin with find_by_ or find_all_by_, indicating whether you want a single value or array of results returned. The semantics are similar to calling the method first versus the all option.

It’s also possible to use multiple attributes in the same find by separating them with “and”, so you get finders like Person.find_by_user_name_and_password or even Payment.find_by_purchaser_and_state_and_country.
Dynamic finders have the benefits of being shorter and easier to read and understand. Instead of writing
Person.where("user_name = ? AND password = ?", user_name, password)
try writing1
Person.find_by_user_name_and_password(user_name, password)
You can customize dynamic finder calls by chaining them to the end of scopes or relations, however they must be the last call since they themselves return the actual results.
Payment.order("created_on).find_all_by_amount(50)
The same dynamic finder style can be used to create the object if it doesn’t already exist. This dynamic finder is called with find_or_create_by_ and will return the object if it already exists and otherwise creates it, then returns it.

Use the find_or_initialize_by_ finder if you want to return a new record without saving it first.
![]()
All of the find_* dynamic finder methods are incompatible with Arel and feel archaic in Rails 3, although they’re still supported. The only type of dynamic finder that I use on any sort of regular basis is the convenient find_or_create_by_.
5.4.8 Dynamic Scopes
Dynamic scopes are similar to dynamic finders in that they operate via method_missing. Since they are based on Arel, they allow the kind of method chaining that is preferred in Rails 3.

Since method_missing is costly in terms of execution performance, dynamic methods are created on the fly as needed. The following example picks up where the previous one left off, and shows that scoped_by_state is now a method on the AreaCode class, but scoped_by_location, which has not been invoked yet, is not.
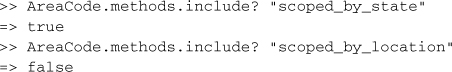
5.4.9 Custom SQL Queries
The find_by_sql class method takes a SQL select query and returns an array of Active Record objects based on the results. Here’s a barebones example, which you would never actually need to do in a real application:
![]()
I can’t stress this enough: You should take care to use find_by_sql only when you really need it! For one, it reduces database portability. When you use Active Record’s normal find operations, Rails takes care of handling differences between the underlying databases for you.
Note that Active Record already has a ton of built-in functionality abstracting SELECT statements. Functionality that it would be very unwise to reinvent. There are lots of cases where at first glance it might seem that you might need to use find_by_sql, but you actually don’t. A common case is when doing a LIKE query:
![]()
Turns out that you can easily put that LIKE clause into a conditions option:

Preventing SQL injection attacks
Under the covers, Rails sanitizes2 your SQL code, provided that you parameterize your query. Active Record executes your SQL using the connection.select_all method, iterating over the resulting array of hashes, and invoking your Active Record’s initialize method for each row in the result set.
What would this section’s example look like un-parameterized?
![]()
Notice the missing question mark as a variable placeholder. Always remember that interpolating user-supplied values into a SQL fragment of any type is very unsafe! Just imagine what would happen to your project if a malicious user called that unsafe find with params[:code] set to
"Amazon'; DELETE FROM users;'
This particular example might fail in your own experiments. The outcome is very specific to the type of database/driver that you’re using. Some popular databases drivers may even have features that help to prevent SQL injection. I still think it’s better to be safe than sorry.
The count_by_sql method works in a manner similar to find_by_sql.
![]()
Again, you should have a special reason to be using it instead of the more concise alternatives provided by Active Record.
5.4.10 The Query Cache
By default, Rails attempts to optimize performance by turning on a simple query cache. It is a hash stored on the current thread, one for every active database connection. (Most Rails processes will have just one.)
Whenever a find (or any other type of select operation) happens and the query cache is active, the corresponding result set is stored in a hash with the SQL that was used to query for them as the key. If the same SQL statement is used again in another operation, the cached result set is used to generate a new set of model objects instead of hitting the database again.
You can enable the query cache manually by wrapping operations in a cache block, as in the following example:
User.cache do
puts User.first
puts User.first
puts User.first
end
Check your development.log and you should see the following entries:
User Load (1.0ms) SELECT * FROM users LIMIT 1
CACHE (0.0ms) SELECT * FROM users LIMIT 1
CACHE (0.0ms) SELECT * FROM users LIMIT 1
The database was queried only once. Try a similar experiment in your own console without the cache block, and you’ll see that three separate User Load events are logged.
Save and delete operations result in the cache being cleared, to prevent propagation of instances with invalid states. If you find it necessary to do so for whatever reason, call the clear_query_cache class method to clear out the query cache manually.
The active record context plugin
Rick Olson extracted a plugin from his popular Lighthouse application that allows you to easily seed the query cache with sets of objects that you know you will need. It’s a powerful complement to Active Record’s built-in caching support. Learn more about it at http://activereload.net/2007/5/23/spend-less-time-in-the-database-and-more-time-outdoors.
Logging
The log file indicates when data is being read from the query cache instead of the database. Just look for lines starting with CACHE instead of a Model Load.
![]()
Default Query Caching in Controllers
For performance reasons, Active Record’s query cache is turned on by default for the processing of controller actions.
Limitations
The Active Record query cache was purposely kept very simple. Since it literally keys cached model instances on the SQL that was used to pull them out of the database, it can’t connect multiple find invocations that are phrased differently but have the same semantic meaning and results.
For example, “select foo from bar where id = 1” and “select foo from bar where id = 1 limit 1” are considered different queries and will result in two distinct cache entries. The active_record_context plugin3 by Rick Olson is an example of a query cache implementation that is a little bit smarter about identity, since it keys cached results on primary keys rather than SQL statements.
5.4.11 Updating
The simplest way to manipulate attribute values is simply to treat your Active Record object as a plain old Ruby object, meaning via direct assignment using myprop=(some_value)
There are a number of other different ways to update Active Record objects, as illustrated in this section. First, let’s look at how to use the update class method of ActiveRecord::Base

The first form of update takes a single numeric id and a hash of attribute values, while the second form takes a list of ids and a list of values and is useful in scenarios where a form submission from a web page with multiple updateable rows is being processed.
The update class method does invoke validation first and will not save a record that fails validation. However, it returns the object whether or not the validation passes. That means that if you want to know whether or not the validation passed, you need to follow up the call to update with a call to valid?

A problem is that now we are calling valid? twice, since the update call also called it. Perhaps a better option is to use the update_attributes instance method:

And of course, if you’ve done some basic Rails programming, you’ll recognize that pattern, since it is used in the generated scaffolding code. The update_attributes method takes a hash of attribute values, and returns true or false depending on whether the save was successful or not, which is dependent on validation passing.
5.4.12 Updating by Condition
Active Record has another class method useful for updating multiple records at once: update_all. It maps closely to the way that you would think of using a SQL update...where statement. The update_all method takes two parameters, the set part of the SQL statement and the conditions, expressed as part of a where clause. The method returns the number of records updated.4
I think this is one of those methods that is generally more useful in a scripting context than in a controller method, but you might feel differently. Here is a quick example of how I might go about reassigning all the Rails projects in the system to a new project manager.
Project.update_all({:manager => 'Ron Campbell'}, :technology => 'Rails')
The update_all method also accepts string parameters, which allows you to leverage the power of SQL!
Project.update_all("cost = cost * 3", "lower(technology) LIKE
'%microsoft%'")
5.4.13 Updating a Particular Instance
The most basic way to update an Active Record object is to manipulate its attributes directly and then call save. It’s worth noting that save will insert a record in the database if necessary or update an existing record with the same primary key.
>> project = Project.find(1)
>> project.manager = 'Brett M.'
>> project.save
=> true
The save method will return true if it was successful or false if it failed for any reason. There is another method, save!, that will use exceptions instead. Which one to use depends on whether you plan to deal with errors right away or delegate the problem to another method further up the chain.
It’s mostly a matter of style, although the non-bang save and update methods that return a boolean value are often used in controller actions, as the clause for an if condition:

5.4.14 Updating Specific Attributes
The instance methods update_attribute and update_attributes take one key/ value pair or hash of attributes, respectively, to be updated on your model and saved to the database in one operation.
The update_attribute method updates a single attribute and saves the record, but updates made with this method are not subjected to validation checks! In other words, this method allows you to persist an Active Record model to the database even if the full object isn’t valid. Callbacks are also skipped, but the updated_at is still bumped.
On the other hand, update_attributes is subject to validation checks and is often used on update actions and passed the params hash containing updated values.
Courtenay says ...
If you have associations on a model, Active Record automatically creates convenience methods for mass assignment. In other words, a Project model that has_many :users will expose a user_ids attribute writer, which gets used by its update_attributes method. This is an advantage if you’re updating associations with checkboxes, because you just name the checkboxes project[user_ids][] and Rails will handle the magic. In some cases, allowing the user to set associations this way would be a security risk. Definitely consider using attr_accessible to prevent mass assignment whenever there’s a possibility that your application will get abuse from malicious users.
5.4.15 Convenience Updaters
Rails provides a number of convenience update methods in the form of increment, decrement, and toggle, which do exactly what their names suggest with numeric and boolean attributes. Each has a bang variant (such as toggle!) that additionally invokes update_attribute after modifying the attribute.
5.4.16 Touching Records
There may be certain cases where updating a time field to indicate a record was viewed is all you require, and Active Record provides a convenience method for doing so in the form of touch. This is especially useful for cache autoexpiration, which is covered in Chapter 17 “Caching and Performance.”
Using this method on a model with no arguments updates the updated_at timestamp field to the current time without firing any callbacks or validation. If a timestamp attribute is provided it will update that attribute to the current time along with updated_at.
![]()
If a :touch option is provided to a belongs to relation, it will touch the parent record when the child is touched.

5.4.17 Controlling Access to Attributes
Constructors and update methods that take hashes to do mass assignment of attribute values are susceptible to misuse by hackers when they are used in conjunction with the params hash available in controller methods.
When you have attributes in your Active Record class that you want to protect from inadvertent or mass assignment, use one of the following two class methods to control access to your attributes:
The attr_accessible method takes a list of attributes that will be accessible for mass assignment. This is the more conservative choice for mass-assignment protection.
On the other hand, if you’d rather start from an all-open default and restrict attributes as needed, then use attr_protected. Attributes passed to this method will be protected from mass-assignment. Their assignment will simply be ignored. You will need to use direct assignment methods to assign values to those attributes, as illustrated in the following code example:

5.4.18 Readonly Attributes
Sometimes you want to designate certain attributes as readonly, which prevents them from being updated after the parent object is created. The feature is primarily for use in conjunction with calculated attributes. In fact, Active Record uses this method internally for counter_cache attributes, since they are maintained with their own special SQL update statements.
The only time that readonly attributes may be set are when the object is not saved yet. The following example code illustrates usage of attr_readonly. Note the potential gotcha when trying to update a readonly attribute.
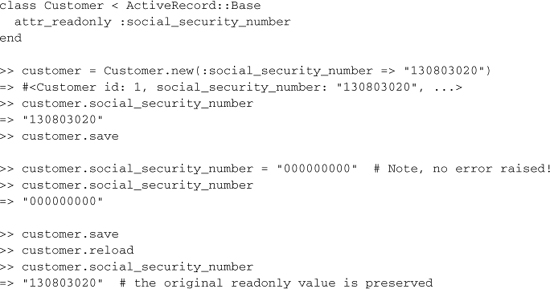
The fact that trying to set a new value for a readonly attribute doesn’t raise an error bothers my sensibilities, but I understand how it can make using this feature a little bit less code-intensive.
You can get a list of all readonly attributes via the method readonly_attributes.
5.4.19 Deleting and Destroying
Finally, if you want to remove a record from your database, you have two choices. If you already have a model instance, you can destroy it:

The destroy method will both remove the object from the database and prevent you from modifying it again:
![]()
Note that calling save on an object that has been destroyed will fail silently. If you need to check whether an object has been destroyed, you can use the destroyed? method.
You can also call destroy and delete as class methods, passing the id(s) to delete. Both variants accept a single parameter or array of ids:
Timesheet.delete(1)
Timesheet.destroy([2, 3])
The naming might seem inconsistent, but it isn’t. The delete method uses SQL directly and does not load any instances (hence it is faster). The destroy method does load the instance of the Active Record object and then calls destroy on it as an instance method. The semantic differences are subtle, but come into play when you have assigned before_destroy callbacks or have dependent associations—child objects that should be deleted automatically along with their parent object.
5.5 Database Locking
Locking is a term for techniques that prevent concurrent users of an application from overwriting each other’s work. Active Record doesn’t normally use any type of database locking when loading rows of model data from the database. If a given Rails application will only ever have one user updating data at the same time, then you don’t have to worry about it.
However, when more than one user may be accessing and updating the exact same data simultaneously, then it is vitally important for you as the developer to think about concurrency. Ask yourself, what types of collisions or race conditions could happen if two users were to try to update a given model at the same time?
There are a number of approaches to dealing with concurrency in database-backed applications, two of which are natively supported by Active Record: optimistic and pessimistic locking. Other approaches exist, such as locking entire database tables. Every approach has strengths and weaknesses, so it is likely that a given application will use a combination of approaches for maximum reliability.
5.5.1 Optimistic Locking
Optimistic locking describes the strategy of detecting and resolving collisions if they occur, and is commonly recommended in multi-user situations where collisions should be infrequent. Database records are never actually locked in optimistic locking, making it a bit of a misnomer.
Optimistic locking is a fairly common strategy, because so many applications are designed such that a particular user will mostly be updating with data that conceptually belongs to him and not other users, making it rare that two users would compete for updating the same record. The idea behind optimistic locking is that because collisions should occur infrequently, we’ll simply deal with them only if they happen.
Implementation
If you control your database schema, optimistic locking is really simple to implement. Just add an integer column named lock_version to a given table, with a default value of zero.

Simply adding that lock_version column changes Active Record’s behavior. Now if the same record is loaded as two different model instances and saved differently, the first instance will win the update, and the second one will cause an ActiveRecord::StaleObjectError to be raised.
We can illustrate optimistic locking behavior with a simple spec:

The spec passes, because calling save on the second instance raises the expected ActiveRecord::StaleObjectError exception. Note that the save method (without the bang) returns false and does not raise exceptions if the save fails due to validation, but other problems such as locking in this case, can indeed cause it to raise exceptions.
To use a database column named something other than lock_version change the setting using set_locking_column. To make the change globally, add the following line to your config/application.rb:
config.active_record.set_locking_column = 'alternate_lock_version'
Like other Active Record settings, you can also change it on a per-model basis with a declaration in your model class:
class Timesheet < ActiveRecord::Base
set_locking_column 'alternate_lock_version'
end
Handling StaleObjectError
Now of course, after adding optimistic locking, you don’t want to just leave it at that, or the end user who is on the losing end of the collision would simply see an application error screen. You should try to handle the StaleObjectError as gracefully as possible.
Depending on the criticality of the data being updated, you might want to invest time into crafting a user-friendly solution that somehow preserves the changes that the loser was trying to make. At minimum, if the data for the update is easily re-creatable, let the user know why their update failed with controller code that looks something like the following:

There are some advantages to optimistic locking. It doesn’t require any special feature in the database, and it is fairly easy to implement. As you saw in the example, very little code is required to handle the StaleObjectError.
The main disadvantages to optimistic locking are that update operations are a bit slower because the lock version must be checked, and the potential for bad user experience, since they don’t find out about the failure until after they’ve potentially lost data.
5.5.2 Pessimistic Locking
Pessimistic locking requires special database support (built into the major databases) and locks down specific database rows during an update operation. It prevents another user from reading data that is about to be updated, in order to prevent them from working with stale data.
Pessimistic locking works in conjunction with transactions as in the following example:
Timesheet.transaction do
t = Timesheet.lock.first
t.approved = true
t.save!
end
It’s also possible to call lock! on an existing model instance, which simply calls reload(:lock => true) under the covers. You wouldn’t want to do that on an instance with attribute changes since it would cause them to be discarded by the reload. If you decide you don’t want the lock anymore, you can pass false to the lock! method.
Pessimistic locking takes place at the database level. The SELECT statement generated by Active Record will have a FOR UPDATE (or similar) clause added to it, causing all other connections to be blocked from access to the rows returned by the select statement. The lock is released once the transaction is committed. There are theoretically situations (Rails process goes boom mid-transaction?!) where the lock would not be released until the connection is terminated or times out.
5.5.3 Considerations
Web applications scale best with optimistic locking, which as we’ve discussed doesn’t really use any database-level locking at all. However, you have to add application logic to handle failure cases. Pessimistic locking is a bit easier to implement, but can lead to situations where one Rails process is waiting on another to release a database lock, that is, waiting and not serving any other incoming requests. Remember that Rails processes are typically single-threaded.
In my opinion, pessimistic locking should not be super dangerous as it is on other platforms, because in Rails we don’t ever persist database transactions across more than a single HTTP request. In fact, it would be impossible to do that in a shared-nothing architecture. (If you’re running Rails with JRuby and doing crazy things like storing Active Record object instances in a shared session space, all bets are off.)
A situation to be wary of would be one where you have many users competing for access to a particular record that takes a long time to update. For best results, keep your pessimistic-locking transactions small and make sure that they execute quickly.
5.6 Where Clauses
In mentioning Active Record’s find method earlier in the chapter, we didn’t look at the wealth of options available in addition to finding by primary key and the first and all methods. Note that this book covers a querying style that is new to Rails 3. Each method discussed here returns an ActiveRecord::Relation - a chainable object that is lazy evaluated against the database only when the actual records are needed.
5.6.1 where(*conditions)
It’s very common to need to filter the result set of a find operation (just a SQL SELECT under the covers) by adding conditions (to the WHERE clause). Active Record gives you a number of ways to do just that with the where method.
The conditions parameter can be specified as a string or a hash. Parameters are automatically santized to prevent SQL-injection attacks.
Passing a hash of conditions will construct a where clause containing a union of all the key/value pairs. If all you need is equality, versus, say LIKE criteria, I advise you to use the hash notation, since it’s arguably the most readable of the styles.
Product.where(:sku => params[:sku))
The hash notation is smart enough to create an IN clause if you associate an array of values with a particular key.
Product.where(:sku => [9400,9500,9900])
The simple string form can be used for statements that don’t involve data originating outside of your app. It’s most useful for doing LIKE comparsions, as well as greater-than/less-than and the use of SQL functions not already built into Active Record. If you do choose to use the string style, additional arguments to the where method will be treated as query variables to insert into the where clause.
Product.where('description like ? and color = ?', "%#{terms}%", color)
Product.where('sku in (?)', selected_skus)
Bind Variables
When using multiple parameters in the conditions, it can easily become hard to read exactly what the fourth or fifth question mark is supposed to represent. In those cases, you can resort to named bind variables instead. That’s done by replacing the question marks with symbols and supplying a hash with values for the matching symbol keys as a second parameter.
![]()
During a quick discussion on IRC about this final form, Robby Russell gave me the following clever snippet:
Message.where("subject LIKE :foo OR body LIKE :foo", :foo => '%woah%')
In other words, when you’re using named placeholders (versus question mark characters) you can use the same bind variable more than once. Like, whoa!
Simple hash conditions like this are very common and useful, but they will only generate conditions based on equality with SQL’s AND operator.
User.where(:login => login, :password => password).first
If you want logic other than AND, you’ll have to use one of the other forms available.
Boolean Conditions
It’s particularly important to take care in specifying conditions that include boolean values. Databases have various different ways of representing boolean values in columns. Some have native boolean datatypes, and others use a single character, often 1 and 0 or T and F (or even Y and N). Rails will transparently handle the data conversion issues for you if you pass a Ruby boolean object as your parameter:
Timesheet.where('submitted = ?', true)
Nil Conditions
Rails expert Xavier Noria reminds us to take care in specifying conditions that might be nil. Using a question mark doesn’t let Rails figure out that a nil supplied as the value of a condition should probably be translated into IS NULL in the resulting SQL query.
Compare the following two find examples and their corresponding SQL queries to understand this common gotcha. The first example does not work as intended, but the second one does work:

5.6.2 order(*clauses)
The order method takes one or more symbols (representing column names) or a fragment of SQL, specifying the desired ordering of a result set:
Timesheet.order('created_at desc')
The SQL spec defaults to ascending order if the ascending/descending option is omitted, which is exactly what happens if you use symbols.
Timesheet.order(:created_at)
Wilson says ...
The SQL spec doesn’t prescribe any particular ordering if no ‘order by’ clause is specified in the query. That seems to trip people up, since the common belief is that ‘ORDER BY id ASC’ is the default.
Random Ordering
The value of the :order option is not validated by Rails, which means you can pass any code that is understood by the underlying database, not just column/direction tuples. An example of why that is useful is when wanting to fetch a random record:

Remember that ordering large datasets randomly is known to perform terribly on most databases, particularly MySQL.
Tim says ...
A clever, performant, and portable way to get a random record is to generate a random offset in Ruby.
Timsheet.limit(1).offset(rand(Timesheet.count)).first
5.6.3 limit(number) and offset(number)
The limit method takes an integer value establishing a limit on the number of rows to return from the query. The offset method, which must be chained to limit, specifies the number of rows to skip in the result set and is 0-indexed. (At least it is in MySQL. Other databases may be 1-indexed.) Together these options are used for paging results.
For example, a call to find for the second page of 10 results in a list of timesheets is:
Timesheet.limit(10).offset(10)
Depending on the particulars of your application’s data model, it may make sense to always put some limit on the maximum amount of Active Record objects fetched in any one specific query. Letting the user trigger unbounded queries pulling thousands of Active Record objects into Rails at one time is a recipe for disaster.
5.6.4 select(*clauses)
By default, Active Record generates SELECT * FROM queries, but it can be changed if, for example, you want to do a join, but not include the joined columns. Or if you want to add calculated columns to your result set, like this:
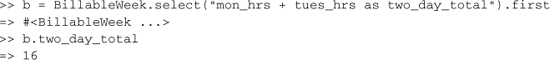
Now, if you actually want to fully use objects with additional attributes that you’ve added via the select method, don’t forget the * clause:

Keep in mind that columns not specified in the query, whether by * or explicitly, will not be populated in the resulting objects! So, for instance, continuing the first example, trying to access created_at on b has unexpected results:
ActiveModel::MissingAttributeError: missing attribute: created_at
5.6.5 from(*tables)
The from method allows you to modify the table name(s) portion of the SQL statements generated by Active Record. You can provide a custom value if you need to include extra tables for joins, or to reference a database view.
Here’s an example of usage from an application that features tagging:

(If you’re wondering why table_name is used instead of a an explicit value, it’s because this code is mixed into a target class using Ruby modules. That subject is covered in Chapter 9, Advanced Active Record.)
5.6.6 group(*args)
Specifies a GROUP BY SQL-clause to add to the query generated by Active Record. Generally you’ll want to combine :group with the :select option, since valid SQL requires that all selected columns in a grouped SELECT be either aggregate functions or columns.
![]()
Keep in mind that those extra columns you bring back might sometimes be strings if Active Record doesn’t try to typecast them. In those cases, you’ll have to use to_i and to_f to explicitly convert the string to numeric types.
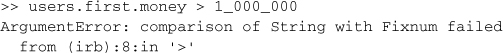
5.6.7 having(*clauses)
If you need to perform a group query with a SQL HAVING clause, you use the having method
![]()
5.6.8 includes(*associations)
Active Record has the ability to eliminate “N+1” queries by letting you specify what associations to eager load using the includes method or option in your finders. Active Record will load those relationships with the minimum number of queries possible.
To eager load first degree associations, provide includes with an array of association names. When accessing these a database hit to load each one will no longer occur.

For second degree associations, provide a hash with the array as the value for the hash key.
>> clients = Client.includes(:users => [:avatar])
=> [#<Client id: 1, name: "Hashrocket">]
You may add more inclusions following the same pattern.

Similarly to includes, you may use eager_load or preload with the same syntax.

5.6.9 joins
The joins method can be useful when you’re grouping and aggregating data from other tables, but you don’t want to load the associated objects.

However, the most common usage of the join method is to allow you to eager-fetch additional objects in a single SELECT statement, a technique that is discussed at length in Chapter 7.
5.6.10 readonly
Chaining the readonly method marks returned objects as read-only. You can change their attributes, but you won’t be able to save them back to the database.

5.6.11 exists?
A convenience method for checking the existence of records in the database is included in ActiveRecord as the aptly named exists? method. It takes similar arguments to find and instead of returning records returns a boolean for whether or not the query has results. Note that the :conditions key is not used here, only supply the conditions themselves.

5.6.12 arel_table
For cases in which you want to generate custom SQL yourself through Arel, you may use the arel_table method to gain access to the Table for the class.

You can consult the Arel documentation directly on how to construct custom queries using its DSL.5
5.7 Connections to Multiple Databases in Different Models
Connections are created via ActiveRecord::Base.establish_connection and retrieved by ActiveRecord::Base.connection. All classes inheriting from ActiveRecord::Base will use this connection. What if you want some of your models to use a different connection? You can add class-specific connections.
For example, let’s say you need to access data residing in a legacy database apart from the database used by the rest of your Rails application. We’ll create a new base class that can be used by models that access legacy data. Begin by adding details for the additional database under its own key in database.yml. Then call establish_connection to make LegacyProjectBase and all its subclasses use the alternate connection instead.

Incidentally, to make this example work with subclasses, you must specify self.abstract_class = true in the class context. Otherwise, Rails considers the subclasses of LegacyProject to be using single-table inheritance (STI), which we discuss at length in Chapter 9.
Xavier says ...
You can easily point your base class to different databases depending on the Rails environment like this:

Then just add multiple entries to database.yml to match the resulting connection names. In the case of our example, legacy_development, legacy_test, etc.
The establish_connection method takes a string (or symbol) key pointing to a configuration already defined in database.yml. Alternatively, you can pass it a literal hash of options, although it’s messy to put this sort of configuration data right into your model file instead of database.yml

Rails keeps database connections in a connection pool inside the ActiveRecord::Base class instance. The connection pool is simply a Hash object indexed by Active Record class. During execution, when a connection is needed, the retrieve_connection method walks up the class-hierarchy until a matching connection is found.
5.8 Using the Database Connection Directly
It is possible to use Active Record’s underlying database connections directly, and sometimes it is useful to do so from custom scripts and for one-off or ad-hoc testing. Access the connection via the connection attribute of any Active Record class. If all your models use the same connection, then use the connection attribute of ActiveRecord::Base.
ActiveRecord::Base.connection.execute("show tables").all_hashes
The most basic operation that you can do with a connection is simply to execute a SQL statement from the DatabaseStatements module. For example, Listing 5.1 shows a method that executes a SQL file statement by statement.
Listing 5.1. Execute a SQL file line by line using active record’s connection

5.8.1 The DatabaseStatements Module
The ActiveRecord::ConnectionAdapters::DatabaseStatements module mixes a number of useful methods into the connection object that make it possible to work with the database directly instead of using Active Record models. I’ve purposely left out some of the methods of this module (such as add_limit! and add_lock) because they are used internally by Rails to construct SQL statements dynamically and I don’t think they’re of much use to application developers.
For the sake of readability in the select_examples below, assume that the connection object has been assigned to conn, like this:
conn = ActiveRecord::Base.connection
begin_db_transaction()
Begins a database transaction manually (and turns off Active Record’s default autocommitting behavior).
commit_db_transaction()
Commits the transaction (and turns on Active Record’s default autocommitting behavior again).
delete(sql_statement)
Executes a SQL DELETE statement provided and returns the number of rows affected.
execute(sql_statement)
Executes the SQL statement provided in the context of this connection. This method is abstract in the DatabaseStatements module and is overridden by specific database adapter implementations. As such, the return type is a result set object corresponding to the adapter in use.
insert(sql_statement)
Executes an SQL INSERT statement and returns the last autogenerated ID from the affected table.
reset_sequence!(table, column, sequence = nil)
Used in Oracle and Postgres; updates the named sequence to the maximum value of the specified table’s column.
rollback_db_transaction()
Rolls back the currently active transaction (and turns on auto-committing). Called automatically when a transaction block raises an exception or returns false.
select_all(sql_statement)
Returns an array of record hashes with the column names as keys and column values as values.

select_one(sql_statement)
Works similarly to select_all, but returns only the first row of the result set, as a single Hash with the column names as keys and column values as values. Note that this method does not add a limit clause to your SQL statement automatically, so consider adding one to queries on large datasets.
>> conn.select_one("select name from businesses")
=> {"name"=>"New York New York Salon"}
select_value(sql_statement)
Works just like select_one, except that it returns a single value: the first column value of the first row of the result set.
>> conn.select_value("select * from businesses limit 1")
=> "Cimino's Pizza"
select_values(sql_statement)
Works just like select_value, except that it returns an array of the values of the first column in all the rows of the result set.
![]()
update(sql_statement)
Executes the update statement provided and returns the number of rows affected. Works exactly like delete.
5.8.2 Other Connection Methods
The full list of methods available on connection, which returns an instance of the underlying database adapter, is fairly long. Most of the Rails adapter implementations define their own custom versions of these methods. That makes sense, since all databases have slight variations in how they handle SQL and very large variations in how they handle extended commands, such as for fetching metadata.
A peek at abstract_adapter.rb shows us the default method implementations:
In the following list of method descriptions and code samples, I’m accessing the connection of our sample time and expenses application in the Rails console, and again I’ve assigned connection to a local variable named conn, for convenience.
active?
Indicates whether the connection is active and ready to perform queries.
adapter_name
Returns the human-readable name of the adapter, as in the following example:
>> conn.adapter_name
=> "SQLite"
disconnect! and reconnect!
Closes the active connection or closes and opens a new one in its place, respectively.
raw_connection
Provides access to the underlying database connection. Useful for when you need to execute a proprietary statement or you’re using features of the Ruby database driver that aren’t necessarily exposed in Active Record. (In trying to come up with a code sample for this method, I was able to crash the Rails console with ease. There isn’t much in the way of error checking for exceptions that you might raise while mucking around with raw_connection.)
supports_count_distinct?
Indicates whether the adapter supports using DISTINCT within COUNT in SQL statements. This is true for all adapters except SQLite, which therefore requires a workaround when doing operations such as calculations.
supports_migrations?
Indicates whether the adapter supports migrations.
tables
Produces a list of tables in the underlying database schema. It includes tables that aren’t usually exposed as Active Record models, such as schema_info and sessions.

verify!(timeout)
Lazily verify this connection, calling active? only if it hasn’t been called for timeout seconds.
5.9 Other Configuration Options
In addition to the configuration options used to instruct Active Record on how to handle naming of tables and primary keys, there are a number of other settings that govern miscellaneous functions. Set them in an initializer.
ActiveRecord::Base.default_timezone
Tells Rails whether to use Time.local (using :local)or Time.utc (using :utc) when pulling dates and times from the database. Defaults to :local
ActiveRecord::Base.schema_format
Specifies the format to use when dumping the database schema with certain default rake tasks. Use the :sql option to have the schema dumped as potentially database-specific SQL statements. Just beware of incompatibilities if you’re trying to use the :sql option with different databases for development and testing. The default option is :ruby, which dumps the schema as an ActiveRecord::Schema file that can be loaded into any database that supports migrations.
ActiveRecord::Base.store_full_sti_class
Specifies whether Active Record should store the full constant name including namespace when using Single-Table Inheritance (STI), covered in Chapter 9, “Advanced Active Record”.
5.10 Conclusion
This chapter covered the fundamentals of Active Record, the framework included with Ruby on Rails for creating database-bound model classes. We’ve learned how Active Record expresses the convention over configuration philosophy that is such an important part of the Rails way, and how to make settings manually, which override the conventions in place.
We’ve also looked at the methods provided by ActiveRecord::Base, the parent class of all persistent models in Rails, which include everything you need to do basic CRUD operations: Create, Read, Update, and Delete. Finally, we reviewed how to drill through Active Record to use the database connection whenever you need to do so.
In the following chapter, we continue our coverage of Active Record by learning about how related model objects interact via associations.