
12
DEADLOCKS AND RACE CONDITIONS

We’ve talked about multitasking, or computers doing more than one thing at a time. Originally we were just pretending that computers could do this, because really there was only one computer switching between tasks. But now that multicore processors are the norm, computers are actually doing more than one thing at a time. Multiprocessing isn’t a particularly new concept; single-core processors have long been connected together to achieve higher performance. It’s just easier and more common now. A multiprocessor system isn’t an expensive special-purpose machine anymore—it’s your phone.
Sometimes the order in which things are done is important. For example, let’s say you have a joint bank account (one that you share with someone else) that has a balance of $100. The other account owner goes to an ATM to withdraw $75 at the same time that you go into the bank to withdraw $50. This is what’s known as a race condition. The bank software needs to be able to lock one of you out so that only one withdrawal can be processed at a time to prevent the account from becoming overdrawn. This essentially means turning off multitasking for certain operations. It’s tricky to do that without losing the benefits of multitasking, however, as this chapter will show.
What Is a Race Condition?
A race condition occurs when two (or more) programs access the same resource and the outcome is dependent on timing. Take a look at Figure 12-1, where two programs are trying to deposit money into a bank account.

Figure 12-1: Race condition example
The shared resource in this example is the account balance. As you can see, the result depends on the timing of the two programs accessing this resource.
Another way of looking at it is best expressed by the T-shirt shown in Figure 12-2.

Figure 12-2: Racing attire
Shared Resources
What resources can be shared? Pretty much anything. In the previous section, we saw memory being shared. Memory is always involved in sharing, even if the end result of the sharing isn’t memory. That’s because there must be some indication that a shared resource is in use. This memory may not be what we typically think of as memory; it may just be a bit in some piece of input/output (I/O) device hardware.
Sharing I/O devices is also very common—for example, sharing a printer. It obviously wouldn’t work very well to mix pieces of different documents together. I mentioned back in “System and User Space” on page 133 that operating systems handle I/O for user programs. That really only applies to I/O devices that are part of the machine, like the USB controller. While the operating system ensures that USB-connected devices communicate correctly, it often leaves the control of these devices up to user programs.
Field-programmable gate arrays, or FPGAs (see “Hardware vs. Software” on page 90), are an exciting frontier in resource sharing. You might want to program an FPGA to provide a special hardware function to speed up a particular piece of software. You’d want to make sure that nothing replaces the hardware programming that’s expected by the software.
It’s less obvious that programs running on different computers communicating with each other can also share resources.
Processes and Threads
How can multiple programs get access to the same data? We briefly touched on operating systems back in “Relative Addressing” on page 128. One of the functions of an operating system is to manage multiple tasks.
Operating systems manage processes, which are programs running in user space (see “System and User Space” on page 133). Multiple programs can be running simultaneously with multicore processors, but that’s not enough for a race condition by itself—programs must have shared resources.
There’s no magic way, at least since Thor took the Tesseract back to Asgard, for processes to share resources; they must have some kind of arrangement to do so. This implies that processes sharing resources must somehow communicate, and this communication can take many forms. It must be prearranged either by being built into a program or via some sort of configuration information.
Sometimes a process needs to pay attention to multiple things. A good example is a print server—a program that other programs can communicate with to get things printed. Before networking, it was difficult to use a printer that wasn’t connected to an I/O port on the machine you wanted to print from. The networking code developed in the 1980s at the University of California, Berkeley, made it easier to for computers to communicate with each other by adding several system calls. In essence, a program could wait for incoming activity from multiple sources and run the appropriate handler code. This approach worked pretty well, mainly because the handler code was fairly simple and was run before waiting for the next activity. Print server code could print an entire document before worrying about the next one.
Interactive programs with graphical user interfaces changed all that. Activity handlers were no longer simple tasks that ran from start to finish; they may have to pause and wait for user input in multiple places. Although programs could be implemented as a swarm of cooperating processes, that’s pretty cumbersome because they need to share a lot of data.
What’s needed is a way for handlers to be interruptible—that is, for them to be able to stop where they are, saving their state so that they can resume execution where they left off at a later time. Well, this is nothing new. Where is that state? On the stack. Problem is, there’s only one stack per process, and it sounds like we need one for every handler in a process. Enter threads of execution. We saw how operating systems arrange process memory in “Arranging Data in Memory” on page 136. A thread is a piece of a program that shares the static data and heap but has its own stack, as shown in Figure 12-3. Each thread believes it has sole access to the CPU registers, so the thread scheduler must save and restore them when switching from one thread to another, in a manner similar to what the OS does when switching from one process to another. Threads are also called lightweight processes because they have much less context than a regular process, so switching between threads is faster than switching between processes.

Figure 12-3: Memory layout for threads
Early implementations of threads involved some custom assembly language code that was by definition machine specific. Threads turned out to be sufficiently useful that a machine-independent API was standardized. Threads are interesting to us here because they make race conditions within a single process possible. Not only is this an issue in low-level C programs, but JavaScript event handlers are also threads.
But just because threads exist doesn’t mean they’re the right solution for everything. Thread abuse is responsible for a lot of bad user experience. When Microsoft first introduced Windows, it was a program that ran on top of MS-DOS, which was not a state-of-the-art operating system that supported multitasking. As a result, Microsoft built parts of an operating system into each of its applications so that users could, for example, have several documents open at once. Unfortunately, some people brought this approach to programs running on complete operating systems. This method shows up in tabbed applications (for example, LibreOffice and Firefox) and user interfaces (for example, GNOME).
Why is that a bad idea? First of all, threads share data, so it’s a security issue. Second, as you’ve probably experienced, a bug or problem with one tab often kills the entire process, resulting in lost work in what should be unrelated tasks. Third, as you’ve also likely experienced, a thread that takes a long time to complete prevents all other threads from running, so, for example, a slow-loading web page often hangs multiple browser instances.
The moral of the story here is to code smartly. Use the operating system; that’s why it’s there. If it doesn’t perform as needed or is missing a critical feature, fix that. Don’t make a mess of everything else.
Locks
The problem at hand isn’t really sharing resources. It’s how to make operations atomic (that is, indivisible, uninterruptible) when they’re made up of a series of smaller operations.
We wouldn’t be having this discussion if computers had instructions like adjust the bank balance. But of course they don’t, because we’d need an infinite number of such instructions. Instead, we have to make critical sections of code appear atomic using some sort of mutual exclusion mechanism. We do that by creating advisory locks that programs follow to avoid conflicts (see Figure 12-4).
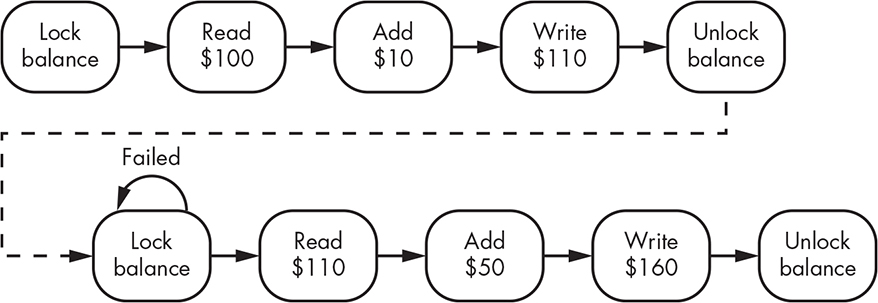
Figure 12-4: Advisory lock
As you can see in Figure 12-4, the upper program grabbed the lock first, so the lower program had to wait until the lock was released. The lock is advisory because it’s up to the programs to follow it; there is no enforcement mechanism. This might seem pretty useless because it wouldn’t stop anyone from robbing a bank. But it’s a matter of where the lock resides. As you can see in Figure 12-5, the lock is at the bank, which does the enforcement, so that makes it work.

Figure 12-5: Lock location
This solves one problem but creates others. What happens if the communication between program #1 and the bank is slow? Clearly, program #2 is going to have to wait a while, which means we’re losing some of the benefits of multitasking. And what happens if program #1 dies or just behaves badly and never releases the lock? What does program #2 do while it’s waiting?
We’ll look at these issues in the next few sections.
Transactions and Granularity
Every operation performed by program #1 in Figure 12-5 requires some sort of communication with the bank. This needs to be two-way communication because we need to know whether or not each operation succeeds before doing the next. The easy way to improve the performance is to bundle the set of operations into a transaction, which is a group of operations that either all succeed or all fail (see Figure 12-6). The term transaction stems from the database world. Rather than sending each operation separately, we’ll bundle them.
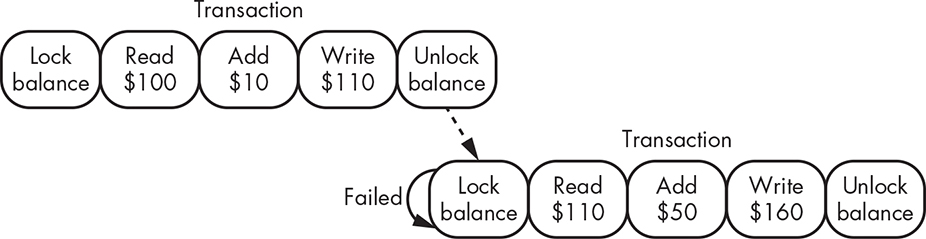
Figure 12-6: Transactions
An obvious guideline is to minimize the amount of time in which something is locked, because that reduces concurrency. One guideline that’s not quite so obvious, however, is to minimize the granularity of locks—that is, the amount of stuff covered by the lock. We’re locking the balance in our example; it’s implied that we’re just locking the balance of one account. Locking the entire bank every time one customer needs to update a balance would not be a great solution. The X Window System is an example of poorly designed locking. Although it has many types of locks, there are many instances where locking everything is the only option, but that eliminates concurrency.
Locks that cover a small part of a system are called fine-grained; locks covering larger parts are called coarse-grained.
NOTE
Processor interrupt handling includes a locking mechanism. When an interrupt is received, a mask is set that prevents the processor from receiving any more interrupts of the same type, unless explicitly allowed, until the interrupt handler is done.
Waiting for a Lock
It doesn’t do a lot of good to use transactions and fine-grained locks if a program waiting for a lock can’t do anything useful while waiting. After all, the “multi” is the whole point of multitasking.
Sometimes there’s nothing useful to do while waiting for a lock, which is why you have to stand in the rain waiting for an ATM to respond. There are two ways of doing nothing, though. We can spin, which means we can try the lock over and over until we successfully grab it. Spinning often involves using a timer to space out the tries. Going full speed on a machine chews up a lot of power unnecessarily. Going full speed on a network can be like having a mob of people trying to get into a store on Black Friday. In some circumstances—and this is the second way of doing nothing—an entity requesting a lock can register that request with the lock authority and get notified when the request is granted. This allows the requestor to go do something more useful while waiting. This approach doesn’t scale particularly well and is explicitly not supported by the architecture of the internet, although it can be layered on top.
We learned in Chapter 6 that Ethernet takes an interesting approach to waiting. It doesn’t have locks, but if multiple devices collide while trying to access the shared resource (the wire), they each wait a random amount of time and then try again.
Some operating systems provide locking functionality, usually associated with a handle similar to a file descriptor. Locking can be attempted in blocking or nonblocking modes. Blocking means that the system suspends the calling program (that is, stops it from executing) until the lock is available. Nonblocking means that the program keeps running and receives some indication that it did not get the lock.
Deadlocks
You’ve seen that programs must do some sort of waiting around when they need locks that aren’t available. Complicated systems often have multiple locks, though, so what happens in the case shown in Figure 12-7?
Program #1 successfully grabs Lock A, and program #2 successfully grabs Lock B. Next, program #1 tries to grab Lock B but can’t because program #2 has it. Likewise, program #2 tries to grab Lock A but can’t because program #1 has it. Neither program can proceed to the point where it releases the locks it holds. This is situation is called a deadlock, which is not a multi-threaded hairstyle.

Figure 12-7: Deadlock
There are few great solutions to deadlocks other than to write code well. In some situations, it’s possible to manually clear a lock without causing a lot of damage. You’ve probably come across some situation where a program refuses to run because it can’t get a lock and prompts you as to whether or not you’d like to clear it. This situation arises when a program that holds a lock croaks unexpectedly without releasing it.
Short-Term Lock Implementation
There is really only one way to implement locks, but there are many ways to present them to programs. Lock implementation requires hardware support in the form of special instructions to support locking. Software solutions designed decades ago no longer work due to advances in processor technology, such as out-of-order execution and multiple cores.
Many processors have a test and set instruction that exists explicitly for locking. This is an atomic instruction that tests to see whether a memory location is 0 and sets it to 1 if it isn’t. It returns a 1 if it was successful in changing the value and 0 otherwise. Thus, it directly implements a lock.
An alternate version that works better in situations where lots of programs are contending for a lock is compare and swap. This instruction is similar to test and set, but instead of just using a single value, the invoker provides both an old and a new value. If the old value matches what’s in the memory location, it’s replaced by the new value and the lock is grabbed.
Use of these instructions is usually restricted to system mode, so they’re not available to user programs. Some of the more recent language standards, such as C11, have added user-level support for atomic operations. Various locking operations have also been standardized and made available in libraries.
Additional code can be attached to locks to make them more efficient. For example, queues can be associated with locks to register programs waiting for locks.
Long-Term Lock Implementation
We’ve mostly been talking about locks that are held for as short a time as possible, but sometimes we want to hold a lock for a long time. This is usually in situations where access by multiple programs is never permitted—for example, a word processor that’s designed to prevent multiple parties from editing the same document at the same time.
Long-term locks need to be kept in more persistent storage than memory. They’re often implemented through files. System calls exist that allow exclusive file creation, and whatever program gets there first succeeds. This is equivalent to acquiring a lock. Note that system calls are a high-level abstraction that uses atomic instructions underneath the hood.
Browser JavaScript
Writing JavaScript programs that run in a browser is the first place where, as a new programmer, you’re likely to have to pay attention to concurrency. This may sound surprising if you’ve read any JavaScript documentation, because JavaScript is defined as single-threaded. So how can concurrency be an issue?
The reason is that JavaScript wasn’t originally designed for the uses it’s being put to today. One of its original purposes was to provide faster user feedback and to reduce internet traffic, back when the internet was much slower. For example, imagine a web page containing a field for a credit card number. Before JavaScript, the number would have to be sent to a web server that would verify that it contained only digits and either send an error response or further process the number if it was okay. JavaScript allowed the credit card number to be checked for digits in the web browser. This meant that the user didn’t have to wait in the event of a typo and that no internet traffic was required in order to detect and report the typo. Of course, there’s still lots of bad JavaScript out there that can’t handle spaces in card numbers, as you’ve probably discovered.
Since JavaScript was created to run short programs in response to user events, it’s implemented using an event loop model, the workings of which are shown in Figure 12-8.

Figure 12-8: JavaScript event loop
What happens is that tasks to be performed are added to the event queue. JavaScript pulls these tasks from the queue one at a time and executes them. These tasks are not interruptible because JavaScript is single-threaded. But you as the programmer don’t have control over the order in which events are added to the queue. For example, say you have an event handler for each mouse button. You don’t control the order in which mouse buttons are clicked, so you can’t control the ordering of events. Your program must reliably deal with events in any order.
Asynchronous communications weren’t designed into JavaScript when it debuted in 1995. Up until that point, browsers submitted forms and servers returned web pages. Two things changed that. First came the publication of the Document Object Model (DOM) in 1997, although it didn’t become stable (more or less) until around 2004. The DOM allowed existing web pages to be modified instead of just being replaced. Second, the XMLHttpRequest (XHR) arrived on the scene in 2000, which became the basis of AJAX. It provided background browser-server communications outside of the existing “load a page” model.
These changes triggered a dramatic increase in the complexity of web pages. Much more JavaScript was written, making it a mainstream programming language. Web pages became increasingly reliant on background asynchronous communication with servers. There were a lot of growing pains, because this wasn’t something JavaScript was designed to do, especially because the single-threaded model was at odds with asynchronous communications.
Let’s contrive a simple web application to display the art for an album by an artist. We’ll use some hypothetical website that first requires us to convert the album and artist name into an album identifier and then uses that identifier to fetch the album art. You may try writing the program as shown in Listing 12-1, where the code in italics is supplied by the user.
var album_id;
var album_art_url;
// Send the artist name and album name to the server and get back the album identifier.
$.post("some_web_server", { artist: artist_name, album: album_name }, function(data) {
var decoded = JSON.parse(data);
album_id = decoded.album_id;
});
// Send the album identifier to the server and get back the URL of the album art image.
// Add an image element to the document to display the album art.
$.post("some_web_server", { id: album_id }, function(data) {
var decoded = JSON.parse(data);
album_art_url = decoded.url;
});
$(body).append('<img src="' + album_art_url + '"/>');
Listing 12-1: First-try album art program
The jQuery post function sends the data from the second argument to the URL in the first argument, and calls the function that’s the third argument when it gets a response. Note that it doesn’t really call the function—it adds the function to the event queue, so that the function gets called when it reaches the front.
This seems like a nice, simple, orderly program. But it won’t work reliably. Why not? Let’s look at what’s happening in detail. Check out Figure 12-9.

Figure 12-9: Album art program flow
As you can see, the program doesn’t execute in order. The post operations start threads internally that wait for the server to respond. When the response is received, the callback functions are added to the event queue. The program shows the second post responding first, but it could just as easily be the first post responding first; that’s out of our control.
There’s a good chance, then, that our program will request the album art before it obtains the album_id from the first post. And it’s almost guaranteed that it will append the image to the web page before it obtains the album_art_url. That’s because, although JavaScript itself is single-threaded, we have concurrent interactions with web servers. Put another way: although the JavaScript interpreter presents a single-threaded model to the programmer, it’s actually multithreaded internally.
Listing 12-2 shows a working version.
$.post("some_web_server", { artist: artist_name, album: album_name }, function(data) {
var decoded = JSON.parse(data);
$.post("some_web_server", { id: decoded.id }, function(data) {
var decoded = JSON.parse(data);
$(body).append('<img src="' + decoded.url + '"/>');
});
});
Listing 12-2: Second-try album art program
Now we’ve moved the image append to be inside of the second post callback, and we’ve moved the second post callback to be inside of the first post callback. This means we won’t make the second post until the first one has completed.
As you can see, nesting is required to ensure that the dependencies are met. And it gets uglier with error handling, which I didn’t show. The next section covers a different way to approach this issue.
Asynchronous Functions and Promises
There’s absolutely nothing wrong with the program in Listing 12-2. It works correctly because jQuery implemented the post function correctly. But just because jQuery did it correctly doesn’t mean other libraries do, especially in the Node.js world, where bad libraries are being created at an astonishing rate. Programs that use libraries that don’t properly implement callbacks are very difficult to debug. That’s become a problem because, as I mentioned in the book’s introduction, so much of programming is now taught as if it’s just the process of gluing together functions in libraries.
JavaScript has recently addressed this by adding a new construct called a promise. The computing concept of a promise stems from the mid-1970s and is having a renaissance since its addition to JavaScript. Promises move the mechanics of asynchronous callbacks into the language proper so that libraries can’t screw them up. Of course, it’s a moving target because you can’t add to the language every time a programmer makes a mistake. This particular case, however, seemed common enough to be worthwhile.
Explanations of JavaScript promises can be hard to understand because two independent things are jumbled together. Promises are easier to understand if these components are separated out. The important part is that there’s a better chance that libraries for asynchronous operations will function correctly if they use promises. The less important part, which gets talked about more, is a change in the programming paradigm. There’s a lot of “religion” around programming paradigms, which I talk about more in the final chapter. At some level, the promise construct is syntactic sugar, a sweetener that makes certain types of programming easier at the expense of fattening the programming language.
Taken to extremes, code for JavaScript asynchronous requests starts to look like what some call the pyramid of doom, as shown in Listing 12-3. I personally don’t see anything wrong with writing code this way. If indenting offends you, then stay away from the Python programming language; it’ll bite your legs off.
$.post("server", { parameters }, function() {
$.post("server", { parameters }, function() {
$.post("server", { parameters }, function() {
$.post("server", { parameters }, function() {
...
});
});
});
});
Listing 12-3: Pyramid of doom
Of course, some of this results from the way the program was written. The anonymous functions require all the code to be written inline. These can be eliminated, as shown in Listing 12-4, which eliminates the pyramid of doom but is harder to follow.
$.post("some_web_server", { artist: artist_name, album: album_name }, got_id);
function
got_id(data)
{
var decoded = JSON.parse(data);
$.post("some_web_server", { id: decoded.id }, got_album_art);
}
function
got_album_art(data)
{
var decoded = JSON.parse(data);
$(body).append('<img src="' + decoded.url + '"/>');
}
Listing 12-4: Rewrite eliminating anonymous functions
What programmers really want is a more straightforward way of writing code. This is easy in many other programming languages but difficult in JavaScript because of its single-threaded model. In a hypothetical multithreaded version of JavaScript, we would just create a new thread to run the code in Listing 12-5. This code assumes that the post blocks until completed; it’s synchronous instead of asynchronous. The code is clear and easy to follow.
var data = $.post("some_web_server", { artist: artist_name, album: album_name } );
var decoded = JSON.parse(data);
var data = $.post("some_web_server", { id: decoded.id }, got_album_art);
var decoded = JSON.parse(data);
$(body).append('<img src="' + decoded.url + '"/>');
Listing 12-5: Hypothetical blocking JavaScript example
If you could write code like this in JavaScript, it wouldn’t work well. The single-threaded nature of JavaScript would prevent other code from running while the posts were waiting, which means that event handlers for mouse clicks and other user interactions wouldn’t get run in a timely manner.
JavaScript promises have some similarity to Listing 12-4 in that the definition of a promise is akin to the function definitions; the definition of a promise is separated out from its execution.
A promise is created as shown in Listing 12-6. Although this doesn’t look much different from other JavaScript code, such as a jQuery post that takes a function as an argument, the function is not executed. This is the setup phase of a promise.
var promise = new Promise(function(resolve, reject) {
if (whatever it does is successful)
resolve(return_value);
else
reject(return_value);
});
Listing 12-6: Promise creation
Let’s look at this in more detail. You supply the promise with a function that performs some asynchronous operation. That function has two arguments that are also functions: one (resolve in Listing 12-6) that’s appended to the JavaScript event queue when the asynchronous operation completes successfully, and one (reject in Listing 12-6) that’s added to the JavaScript event queue if the asynchronous operation fails.
The program executes a promise using its then method, as shown in Listing 12-7. This method takes a pair of functions as arguments that are matched to the resolve and reject functions supplied during promise creation.
promise.then(
function(value) {
do something with the return_value from resolve
},
function(value) {
do something with the return_value from reject
}
);
Listing 12-7: Promise execution
This isn’t very exciting. We could write code to do this without using promises, as we did before. So why bother? Promises come with a bit of syntactic sugar called chaining. It allows code to be written in a something().then().then().then() . . . style. This works because the then method returns another promise. Note that, in a manner similar to exceptions, the second argument to then can be omitted and errors can be fielded with a catch. Listing 12-8 shows the album art program rewritten using promise chaining.
function
post(host, args)
{
return (new Promise(function(resolve, reject) {
$.post(host, args, function(data) {
if (success)
resolve(JSON.parse(data));
else
reject('failed');
});
}));
}
post("some-web-server, { artist: artist_name, album: album_name } ).then(function(data) {
if (data.id)
return (post("some-web-server, { id: data.id });
else
throw ("nothing found for " + artist_name + " and " + album_name);
}).then(function(data) {
if (data.url)
$(body).append('<img src="' + data.url + '"/>');
else
throw (`nothing found for ${data.id}`);
}).catch(alert);
Listing 12-8: Album art program using promise chaining
Now, I don’t find this code easier to follow than the pyramid-of-doom version, but you may feel differently. The versions of code in Listings 12-2 and 12-8 raise another point about the art of programming: trading off the ease of code development versus maintenance. In the grand scheme of a product’s lifecycle, maintainability is more important than writing code in some personally preferred style. I talk about this a little more in Chapter 15. Promise chaining allows you to write code in a function().function().function() . . . style instead of the pyramid-of-doom style. While the first style makes keeping track of parentheses slightly easier, JavaScript—unlike Ruby, for example—was designed with the second style, and having two styles in the same language likely increases confusion, resulting in decreased programmer productivity. Although promises might reduce the instances of one class of programming errors, don’t mistake them as a cure-all for poorly written code.
Promises are syntactic sugar that reduce the amount of nesting. But if we really want code that’s easier to follow, we want something more like Listing 12-5. JavaScript includes yet another way to write “asynchronous” programs that builds on promises but mirrors the synchronous coding style: async and await.
Listing 12-9 shows an implementation of the album art program using async and await.
function
post(host, args)
{
return (new Promise(function(resolve, reject) {
$.post(host, args, function(data) {
if (success)
resolve(JSON.parse(data));
else
reject('failed');
});
}));
}
async function
get_album_art()
{
var data = await post("some-web-server, { artist: artist_name, album: album_name } );
if (data.id) {
var data = await post("some-web-server, { id: data.id });
if (data.url)
$(body).append('<img src="' + data.url + '"/>');
}
}
Listing 12-9: Album art program using async and await
To me, this looks more straightforward than Listing 12-8.
Of course, what’s going on here is that the single-threaded JavaScript model has been severely bent, if not broken. Asynchronous functions are essentially threads that are not interruptible.
Summary
In this chapter, you learned about some of the issues that result from using shared resources. You learned about race conditions and deadlocks, and about processes and threads. You also learned a little bit about concurrency in JavaScript and new ways in which it’s being approached. At this point, we’ve covered the basics. We’ll move on to one of our two advanced topics—security—in the next chapter, which uses many of the technologies that you’ve learned about so far.