
13
SECURITY

Security is an advanced topic. The cryptography component in particular involves lots of esoteric mathematics. But it’s a really important topic. Rather than go into all the gory details, this chapter gives you the lay of the land. While this isn’t enough for you to qualify as a security expert, it should enable you to ask questions about the viability of security implementations. And there are lots of things that you can do without having to be a security expert to make both you and your code more secure.
For the most part, computer security is not very different from regular old security, such as home security. In many respects, the advent of networked computers transformed security issues from those needed for a small apartment to those required to secure a large castle. As you can imagine, a large castle has many more entrances that need guarding and more inhabitants who can compromise the defenses. And it’s bigger, so a lot more trash accumulates, making it harder to keep clean and giving bugs more places to hide.
At its core, security is about keeping you and your stuff safe by your definition of safe. It’s not just a technological issue—it’s a social issue. You and your stuff, along with your definition of safe, must be balanced against everybody else, their stuff, and their definitions.
Security and privacy are intertwined, in part because security comes from keeping your information private. For example, your bank account wouldn’t be secure if everybody had the password. Privacy is difficult to maintain given the number of inane practices at organizations with which we are forced to interact. Every time I see a new doctor, their office asks me for all my personally identifying information. I always ask them, “Why do you need this information?” They always reply, “To protect your privacy.” To which I always ask, “How does giving you and everybody else who asks for it all my personal information protect my privacy?” They just give an exasperated sigh and say, “We just need it.” And whether they do or not, they’re not required to give you a truthful answer. Nowadays, privacy is also impacted by the ease of connecting disparate pieces of information (a topic covered in more detail in the next chapter) resulting from pervasive data collection, which includes surveillance cameras, automatic license plate readers (ALPRs), cell phone surveillance including IMSI catchers (StingRays), internet surveillance (room 641A), facial recognition, and so on. Protecting your privacy is increasingly difficult, which negatively impacts your security.
Good security is hard. The old adage that “a chain is only as strong as its weakest link” describes the situation perfectly. Think about online banking. There are many components ranging from computer hardware, software, and communications networks to people. The best technology won’t protect you if you leave your password written down next to your computer!
Overview of Security and Privacy
This section provides a nontechnical introduction to the issues involved in security and privacy. It defines many of the terms that later sections cover in more depth.
Threat Model
We wouldn’t be talking about security in the absence of threats. There wouldn’t be security worries if everybody behaved nicely. But they don’t.
Security doesn’t exist in a vacuum; it’s relative to a threat model, which lists the things to be secured and enumerates the possible attacks on whatever needs securing so that appropriate defenses can be designed. Contrary to what you might infer from the behavior of “smart devices” such as internet-connected televisions, security cameras, light bulbs, and such, “What could possibly go wrong?” is not a valid threat model.
For example, at the time of writing, Fender had recently introduced a Bluetooth-enabled guitar amplifier. But the company didn’t bother to implement the Bluetooth pairing protocol, which would secure the wireless connection between a performer’s guitar and amp. That means a crafty audience member could connect to the stage amp as well from a cell phone if they were close enough, broadcasting whatever they wanted. (This could become a new art form, but that was likely not Fender’s intent.)
Understanding the threat model is important because there’s no such thing as 100 percent security. You have to design defenses that are appropriate for the threat model. For example, it might be nice to have your own personal armed guard to keep your backpack safe when you’re in class, but it’s not cost-effective and probably wouldn’t go over well with the school administration. A locker is a more appropriate defense for this particular threat.
Here’s another example: I live on a farm in the middle of nowhere. I can put all the expensive locks I want on the doors, but if someone wanted to cut through a wall with a chainsaw or dynamite their way in, nobody would notice because those are normal country sounds. Of course, I do have locks, but in this case, carrying good insurance is a large component of my security because I’m protecting the value of my property, which would be too expensive to secure by physical means.
Many of my neighbors don’t really understand this and engage in practices that decrease their security. It’s unfortunately common for people to move to the country and immediately install streetlights on their property. I’ve asked many of them why they installed the lights, because part of living in the country is being able to see the stars at night and light pollution interferes. The answer is always “for security.” I’ve tried to explain that those lights are just a big advertisement that something is worth stealing and that nobody is home.
Self-defeating security measures are common in the computer world too. For example, many organizations choose to have rules dictating the composition of passwords and how often they must be changed. The result is that people either choose easily guessable passwords or write them down because they can’t remember them.
The upshot is that you can’t do effective security without defining the threat model. There has to be a balance between threats and defending against them. The goal is have inexpensive defenses that are expensive to attack. A side effect of the internet is that it has dramatically reduced attack costs but not defense costs.
Trust
One of the hardest things to do when determining a threat model is deciding what you can trust. Trust in a bygone era came from face-to-face interactions, although people still got taken by charismatic grifters. Deciding who and what to trust is much harder in the modern world. Can you recognize an honest Wi-Fi access point by looking it in the eyes? Not very likely, even if you know where to find its eyes.
You know how important trust is if you’ve ever asked friends to keep a secret. There’s a 50/50 chance that a friend will violate your trust. Probability math tells us that there’s a 75 percent chance that your secret will get out if you tell it to two friends. The odds of your secret getting out increase with each friend; it’s 87 percent with three friends, 94 with four, 97 with five, and so on. You can see that putting trust in anything that you don’t control reduces security; it starts off bad and gets worse from there.
With friends, you get to decide who is worthy of your trust. Your ability to make that choice is very limited in the networked computer world. For example, if you’re one of those rare people who reads terms and conditions before accepting, you might have noticed that almost all of them say something like “Your privacy is very important to us. As a result, you’re going to hold us harmless for breaches of your privacy.” Doesn’t sound very trustworthy. But you have no choice if you want to use the service.
In the computer security world, trust refers to those components that you have no choice but to rely on. Your security depends on the security of those components. As you saw earlier, you want to keep these to the absolute minimum necessary for the greatest security.
When you’re using computers, you’re relying on a huge collection of third-party hardware and software. You don’t have access to the hardware or the software and have no choice but to rely on them, even though they’ve done nothing to earn your trust. Even if you had access, would you really have the time and knowledge to review it all?
The notion of trust comes up again and again in security. For now, consider three classes of trust violations:
Deliberate Examples include the 2005 rootkit (a collection of software that bypasses protections) that Sony BMG installed on customers’ computers and the pop-up ad delivering malware (malicious software) in Lenovo laptops a few years ago. These weren’t programs accidentally installed by users; they were installed by the computer suppliers.
Incompetent Examples of incompetence include unencrypted wireless tire pressure sensors that make it possible for your car to be targeted, the unencrypted RFID tags in newer U.S. passports that make it simple to detect someone carrying one or the proposed vehicle-to-vehicle communications standards being discussed for “safety” that would allow vehicles to be targeted by bad information. Attackers have found a way to get access to and change the settings in a large number of Wi-Fi routers without having to know the administrator password. In the extremely dangerous category, Siemens included a hardcoded password in some of its industrial control systems, meaning that anyone with that password could access equipment that was thought to be supposedly secured. A hardcoded password was just found in some of Cisco’s products as well. The largest DDoS (discussed shortly) attack to date leveraged default passwords in IoT devices made by Hangzhou XiongMai. These sadly all harken back to the “What could possibly go wrong?” threat model combined with the “security by obscurity” mindset (more on this in a moment).
Disingenuous This is when people flat out lie. I talk about this more in “The Social Context” on page 359. A good example is when the American National Institute of Standards and Technology (NIST) was working on encryption standards with the assistance of “experts” from the American National Security Agency (NSA). It turns out that the NSA experts deliberately weakened the standard instead of strengthening it. This made it easier for them to spy while also making it easier for someone to break into your bank account. Trust violations are so common that the term kleptography has been coined to describe the class of violations in which an adversary secretly and securely steals information.
The phrase security by obscurity is used to categorize claims that things are secure because the secret sauce is, well, secret. That’s been repeatedly demonstrated not to be the case. In fact, better security comes from transparency and openness. When as many people as possible are educated about the security methods being used, it fosters discussion and discovery of flaws. History tells us that no one person is perfect or will think of everything. In computer programming, we sometimes call this the thousands of eyeballs principle. This is evident in the industry statistic that Windows has a hundred times more critical vulnerabilities than Linux.
This stuff isn’t easy; it sometimes takes years or even decades to discover security issues, even when smart people are looking for them. For example, the recent “Spectre” and “Meltdown” exploits have their genesis in CPU architectural design decisions made in the 1960s.
Physical Security
Think about a school locker. You put your belongings in it to keep them safe from other people. It’s made of fairly heavy steel and designed to be hard to pry open. Security folks would call the door an attack surface because it’s something that someone trying to break into your locker can attack. It’s a pretty good response to the threat of theft, because you can’t break it open without making a lot of noise. Lots of people are around during the day when your stuff is in your locker, and they would probably notice. Although someone could break in after hours, it’s less likely that things of value would be in the locker at those times.
The combination lock on the door opens only with the correct combination, which you know. When the school gave you the combination, they gave you authorization to open that particular locker. The lock is another attack surface. The lock is designed so that breaking the dial off doesn’t cause it to open and so that it’s hard to get to the innards of the lock with the locker closed. Of course, now some new issues arise. You need to keep the combination secret. You can write it down on a piece of paper somewhere, but someone else might find it. You have to make sure that someone else doesn’t learn your combination by watching you open your locker. And, as you know from watching movies, safecrackers can open combination locks, and it’s not practical for the school to spend the money for really good locks. Devices called autodialers can be attached to a combination lock to try all the possible combinations. They used to be specialty devices, but people have built their own using small, inexpensive microcomputers such as Arduinos combined with cheap stepper motors. But just like with the door, enough people are roaming the halls that a break-in attempt would likely be noticed. It would take either a talented safecracker or a bad lock design (as many “tough-looking” locks are all show). Note that there is a popular brand of combination lock that can easily be opened in less than a minute by anyone with easily obtainable knowledge.
There’s a third attack surface that may have escaped your notice. There’s a keyhole in the middle of the lock. It’s what security people would call a backdoor, even though in this case it’s on the front door. It’s another way of getting into your locker that’s not under your control. Why is it there? Obviously the school knows the combination to your locker, or they wouldn’t have been able to give it to you. This backdoor is there for their convenience so that they can quickly open everybody’s lockers. But it reduces everybody’s security. Locks with keyholes are pretty easy to pick in seconds. And because one key opens everybody’s locker, they’re all vulnerable if someone gets a copy of the key, which isn’t as hard as you might think.
When the school gave you the combination to your locker, they conferred a privilege on you—namely, the ability to get into your locker. Someone with the key has a higher privilege level, as they’re authorized to open all lockers, not just one. Acquiring a copy of the key would raise your privilege level. Many budding engineers, including this author, discovered locksmithing and found ways to become “privileged” in our youths.
Communications Security
Now that we’ve learned a little about keeping stuff secure, let’s tackle a harder problem. How do you transfer something of yours to someone else? Let’s start with an easy case. You have a homework assignment about Orion that’s due, but you have to miss class for a doctor’s appointment. You see your friend Edgar in the hall and ask him to turn in your homework for you. Seems simple enough.
The first step in this process is authentication. This is you recognizing that the person you’re handing your homework to is indeed Edgar. But in your rush, you may have forgotten that Edgar has an evil twin brother. Or “Edgar” could be something wearing Edgar, like an Edgar suit. You really don’t want to accidentally authenticate something buggy (see the 1997 movie Men in Black)!
Edgar impersonators aren’t the only attack surface. All bets are off once your homework is out of your hands; you’re trusting Edgar to act in your best interest. But Edgar could space out and forget to hand it in. Evil Edgar could change your homework so that some of the answers are wrong, or worse, he could make it look like you copied someone else’s work. There’s no way to prove authenticity—that Edgar turned in what you handed him. If you had planned ahead, you could have put your homework into an envelope secured by a wax seal. Of course, these can often be opened and resealed without leaving a trace.
This becomes a much more difficult problem when you don’t have an authenticated, trusted courier delivering your homework. Maybe you had an unplanned absence and your teacher said that you could mail in your homework. Any number of unknown people may handle your letter, making it vulnerable to a man-in-the-middle attack, which is when an attacker gets between parties and intercepts and/or modifies their communications. You don’t know who’s handling your mail, and, unlike with Edgar, you don’t even have an opportunity for authentication.
The solution to these issues is cryptography. You can encrypt your communication using a secret code known only to you and the intended recipient, who can use that code to decrypt it. Of course, like your locker combination, the secret code must be kept secret. Codes can be broken, and you have no way to know if someone knows or broke your code. A properly designed cryptosystem reduces the need to trust components between parties; leaked communications that can’t be read aren’t as big a risk.
Codes get changed when their users figure out that they’ve been broken. An interesting aspect of World War II code breaking was the various ruses concocted to camouflage actions resulting from broken codes. For example, sending out an airplane to “accidentally” spot fleet movements so that the fleet could be attacked hid the fact that code breaking was how the location of the fleet was actually determined. Neal Stephenson’s novel Cryptonomicon is a highly entertaining read about this type of information security.
Modern Times
The “connected computer” age combines the problems of physical security with those of communications security. Psychedelic cowboy, poet, lyricist, and futurist John Perry Barlow (1947–2018) remarked that “cyberspace is where your money is” during a 1990 SIGGRAPH panel. And it’s not just your money. People used to purchase music on records or CDs and movies on videotape or DVDs. Now, this entertainment is mostly just bits on a computer. And of course, banking has moved online.
It would be one thing if those bits were just sitting on your various computers. But your computers, including your phone, are connected to the global internet. This is such a huge attack surface that you have to assume that trust will be violated in at least one place. And the attackers are essentially invisible.
In ancient times, someone who wanted to annoy you could ring your doorbell and run away. You had a good chance of catching them if you were in the right place at the right time and could see them. And there was a limit to how many times someone could do that in a day. On the internet, even if you could see the annoying attacker, there’s not much you could do about it. The attackers are rarely even people anymore; they’re programs. Because they’re programs, they can try to break into your machines thousands of times per second. That’s a whole different game.
Attackers don’t need to break into a machine in order to cause problems. If our doorbell ringer were persistent enough, they’d block others from reaching your door. This is called a denial of service (DoS) attack, because it keeps legitimate folks away. This could put you out of business if you’re running a store. Most attacks of this nature today are distributed denial of service (DDoS), where large numbers of bell ringers coordinate their actions.
One of the things that makes tracking attackers mostly useless is that they’re often using proxies. Launching millions of attacks from their own computer would leave a trail that would be easy to follow. Instead, attackers break into a few machines, install their software (often called malware), and let these other machines do their dirty work for them. This often takes the form of a multilevel tree containing millions of compromised machines. It’s much harder to catch the relatively few command and control messages that tell the other compromised machines what to do. And attack results don’t have to be sent back to the attacker; they can just be posted on some public website in encrypted form, where the attacker can fetch them at their convenience.
How is all this possible? Primarily because a large number of machines in the world run software from Microsoft, which set a standard for buggy and insecure software. This wasn’t accidental. In an October 1995 Focus magazine interview, Bill Gates said, “I’m saying we don’t do a new version to fix bugs. We don’t. Not enough people would buy it.” Microsoft has made some recent improvements, and it’s also losing market dominance in the insecure software sector to Internet-of-Things devices, many of which have more processing power than was available on a desktop computer not that long ago.
There are two major classes of attacks. The first, breaking a cryptography system, is relatively rare and difficult in a well-designed system. Much more common are “social” attacks in which a user is tricked into installing software on their system. The best cryptography can’t protect you if some malicious piece of code that you installed is watching you type your password. Some common social attack mechanisms represent some of the dumbest things ever done by supposedly smart people—running arbitrary programs sent via email or contained on whatever USB drive you find on the ground, for example, or plugging your phone into a random USB port. What could possibly go wrong? These avoidable mechanisms are being replaced by attacks via web browsers. Remember from Chapter 9 how complex these are.
One example of an extremely clever and dangerous attack was a 2009 online banking exploit. When someone logged into their bank account, the attack would transfer some of their money out of their account. It would then rewrite the web page coming back from the bank so that the transfer wouldn’t be detected by the account owner. This made the theft something you’d never notice unless you still received paper statements and carefully checked them.
Another modern-era problem is that messing with bits can have physical repercussions. In the name of progress or convenience, all sorts of critical infrastructure is connected to the internet now. This means an attacker can make a power plant fail or simply turn off the heat in your house in winter so the pipes freeze. And, with the rise of robotics and the Internet of Things, an attacker could potentially program your vacuum cleaner to terrorize your cats or set off burglar alarms when you’re away.
Finally, modern technology has greatly complicated the ability to determine whether something is authentic. It’s pretty trivial to create deep fakes—realistic fake photographs, audio, and video. There’s a theory that a lot of the current batch of robocalls is just harvesting voice samples so that they can be used elsewhere. How long will it be before voice-search data is converted into robocalls that sound like one of your friends is calling?
Metadata and Surveillance
There’s another big change brought about by modern technology. Even if cryptography can keep the contents of communications secret, you can learn a lot by observing patterns of communication. As the late Yogi Berra said, “You can observe a lot by just watching.” For example, even if nobody ever opens your letters, someone can glean a lot by examining who you’re writing to and who’s writing to you, not to mention the size and weight of the envelopes and how often they’re sent. This is unavoidable in America where the post office photographs every piece of mail.
The information on the outside of the envelope is called metadata. It’s data about the data, not the data itself. Someone could use this information to deduce your network of friends. That may not sound so bad to you if you live in a modern Western society. But imagine for a minute if you and your friends lived in a more oppressive society, where having this information about you known could endanger your friends. An example of this is China’s “social credit” score.
Of course, hardly anybody needs to do such things by tracking mail anymore. They can just look at your social media friends. Makes the job much easier. Also, tracking you and yours no longer depends on having a lot of manpower. Nobody has to follow you when you leave your house because your online activities can be tracked remotely, and your movements in the real world can be tracked using an increasing variety of spy cameras. Of course, if you carry a cell phone, you’re tracked all the time because the information that’s used to make the cell phone system function is metadata too.
The Social Context
It’s hard to talk about security without getting political. That’s because there are really two prongs to security. One is the techniques for building robust security. The other is trading off one’s personal security against the security of society as a whole. That’s where it gets complicated, because it’s hard to discuss technical measures absent societal goals.
Not only is security a social issue, but it’s different from country to country because of different laws and norms. That gets especially complicated in an age where communications easily cross national borders and are subject to different regulations. There’s no intent to start a political argument here; it’s just that you can’t discuss security from a solely technological perspective. The political part of this chapter is written from a mostly American perspective.
It’s a common misperception that “national security” is enshrined in the US Constitution. This is understandable because courts routinely dismiss cases about constitutional rights when government officials raise the specters of “national security” and “state secrets.” The Fourth Amendment to the US Constitution has the clearest expression of national security when it says, “The right of the people to be secure in their persons, houses, papers, and effects against unreasonable searches and seizures, shall not be violated.” Unfortunately, unreasonable wasn’t defined, probably because reasonable people understood it at the time. Note that this amendment confers security on the people, not the state—that whole “by the people, for the people” thing.
The heart of the issue is whether or not the government’s duty to protect people is stronger than the rights of those people.
Most people would like to be able to relax knowing that someone else was keeping them safe. One could consider it a social contract. Unfortunately, that social contract has been undermined by violations of trust.
There’s a bias, completely unsupported by fact, that people in government are “better” or “more honest” than everyone else. At best, they’re like people everywhere; some are good, some are bad. There’s more than enough documented evidence of law enforcement personnel committing crimes. An aggravating factor is secrecy; positions lacking oversight and accountability tend to accumulate bad people, which is exactly why the notions of transparency and openness are the foundation of a good trust model. For example, as part of mind-control experiments in the 1960s, the CIA illegally dosed men with LSD and observed their reactions. Known as MKUltra, this program had no oversight and led to at least one known death of an unwitting test subject. After MKUltra was shut down, agent George White said, “Where else could a red-blooded American boy lie, kill, cheat, steal, rape, and pillage with the sanction and blessing of the All-Highest?” And the FBI under J. Edgar Hoover had quite the history of political abuse—not just spying for political purposes but actively sabotaging perceived enemies.
In case you’ve been sleeping under a rock, more and more trust abuses have recently come to light, and these are likely only a small fraction of actual abuses, given the secrecy and lack of oversight. Most relevant to this chapter are Edward Snowden’s revelations about illegal government surveillance.
Without oversight, it’s difficult to tell whether government secrecy is covering up illegal activities or just incompetence. Back in 1998, the US government encouraged the use of an encryption scheme called the Data Encryption Standard (DES). The Electronic Frontier Foundation (EFF) built a machine called Deep Crack for about $250,000 (which was way less than the NSA budget) that broke the DES code. Part of the reason they did so was to be able to point out that either agency experts were incompetent or they were lying about the security of the algorithm. The EFF was trying to expose the disingenuous violation of trust perpetrated for the convenience of American spies. And it worked somewhat—while it didn’t change the behavior of the agency experts, it did spur the development of the Advanced Encryption Standard that replaced DES.
It’s easy to argue that “it’s a dangerous world.” But if lots of bad folks were being caught by these secret programs, we’d be hearing about it. Instead, what we hear about is the entrapment of “clueless and broke” people who weren’t actual threats. Another thing people often say is, “I don’t care if the government looks at my stuff; I have nothing to hide.” That may be true, but it’s a reasonable guess that people saying that do want to hide their bank account password. It often seems like those raising the scariest arguments are actually the ones behaving badly.
Trust violations have international implications. There’s a reluctance to purchase products whose security might be compromised. Outsourcing poses threats too. There may be laws in your country protecting your information, but someone elsewhere might have access to that data. There have been cases of outsourced data being sold. There are recent indications that personal data acquired by outside actors has been used to meddle in political processes, possibly spelling the end of “Westphalian sovereignty.”
Trust violations also impact freedom. A “chilling effect” results when people engage in self-censorship or become afraid of being tracked when meeting or communicating with others online. There’s plenty of historical evidence showing the impact of chilling effects on political movements.
Modern cell phones have several different unlocking options: passcode or pattern, fingerprint reader, facial recognition. Which should you use? At least in America, I recommend using a passcode or pattern, even though they’re slightly less convenient. There are three reasons for this. First, some courts have interpreted the portion of the Fifth Amendment that states “No person . . . shall be compelled in any criminal case to be a witness against himself” to mean that you can’t be ordered to give “testimonial” information that’s in your head. In other words, you can’t be forced to divulge passwords, passcodes, patterns, and so on. But some courts have ruled that you can be compelled to provide your fingerprint or face. Second, there is a trust issue. Even if you don’t mind unlocking your phone on request, how do you know what your phone is doing with your fingerprint or facial data? Is it just unlocking your phone, or is it uploading it to databases for some future undisclosed uses? Will you start getting targeted ads when walking in front of stores that recognize your face? Third, plastic fingerprints and fake retinas, long staples of cheesy movies, have actually been demonstrated in real life. Biometric data is easier to fake than a password.
Authentication and Authorization
I’ve mentioned authentication and authorization. Authentication is proving that someone or something is what it claims to be. Authorization is limiting access to something unless proper “credentials” are presented.
Authorization is arguably the easier of the two; it requires properly designed and implemented hardware and software. Authentication is much trickier. How can a piece of software tell whether it was you who entered a password or someone else?
Two-factor authentication (2FA) is now available on many systems. A factor is an independent means of verification. Factors include things hopefully unique to you (such as a fingerprint), things in your possession (for example, a cell phone), and things that you know (for example, passwords or PINs). Two-factor authentication therefore uses two of these. For example, using a bank card with a PIN or entering a password that sends a message to your phone to supply a one-time code. Some of these systems work better than others; obviously, sending a message to a cell phone that others can access isn’t secure. Parts of the cell phone infrastructure make relying on 2FA dangerous. Attackers can use your email address and other easily available information to port your phone number to a SIM card in a phone that they control. This not only gives them access to your data but locks you out.
Cryptography
As I mentioned earlier, cryptography allows a sender to scramble a communication so that only the designated recipients can decode it. It’s pretty important when you’re taking money out of your bank account; you don’t want someone else to be able to do it too.
Cryptography isn’t important just for privacy and security, however. Cryptographic signatures allow one to attest to the veracity of data. It used to be that physical originals could be consulted if there was some question as to the source of information. Those don’t often exist for documents, audio, video, and so on because the originals were created on computers and never reduced to physical form. Cryptographic techniques can be used to prevent and detect forgeries.
Cryptography alone doesn’t turn your castle into a mighty fortress, though. It’s part of a security system, and all parts matter.
Steganography
Hiding one thing within another is called steganography. It’s a great way to communicate secrets because there’s no traceable connection between the sender and the recipient. This used to be done through newspaper classified ads, but it’s now much easier to do online since there’s a near-infinite number of places to post.
Steganography is not technically cryptography, but it’s close enough for our purposes. Take a look at Figure 13-1. On the left is a photo of Mister Duck and Tony Cat. In the center is that same photo that includes a hidden secret message. Can you tell the two photos apart? On the right is the secret message.

Figure 13-1: Secret message hidden in image
How was this accomplished? On the left is an 8-bit grayscale image. The center image was made by replacing the least significant bit on each pixel of the image with the corresponding least significant bit from the secret message on the right. Recovering the secret message, then, is just a matter of stripping away the seven most significant bits from the center image.
This isn’t the best way to hide a message. It would be much less obvious if the secret message were given in ASCII character codes instead of images of the characters. And it would be pretty much impossible to discover if the secret message bits were scattered throughout the image or encrypted. Another approach, recently published by researchers Chang Xiao, Cheng Zhang, and Changxi Zheng at Columbia University, encodes messages by slightly altering the shape of text characters. This isn’t a completely novel idea; “America’s first female cryptanalyst,” Elizebeth Smith Friedman (1892–1980), used a similar technique to include a secret message on her husband’s tombstone.
Steganograpy is used by advertisers to track web pages that you visit because they don’t get that “no means no” when you block ads. Many websites include a single-pixel image hidden on web pages linked to an identifying URL. This isn’t always innocuous; this type of tracking software was abused to accuse thousands of treason in Turkey in 2016.
This technique isn’t limited to images. Secret messages could even be encoded as the number of blank lines in a blog posting or web page comment. Messages can be scattered among frames in a video or hidden in digital audio in a similar manner to the previous one-pixel example. One crazy-sounding example of the latter is dog-whistle marketing, in which web pages and ads play ultrasonic sounds, which are above the human audio range. These sounds can be picked up by the microphone on your cell phone, allowing advertisers to make connections between your various computing devices and determine what ads you have seen.
Steganography has other uses, too. For example, a studio might embed unique identifying marks in unreleased movies that it sends to reviewers. This would allow them to track down the source if the movie gets leaked. This use is akin to the practice of using a watermark on paper.
Steganography is used in almost every computer printer. The EFF received a document in response to a Freedom of Information Act request that suggests the existence of a secret agreement between governments and manufacturers to make sure that all printed documents are traceable. Color printers, for example, add small yellow dots to each page that encode the printer’s serial number. EFF distributed special LED flashlights that one could use to find them. This could be considered an invasion of privacy.
Substitution Ciphers
If you ever had a secret decoder ring, it probably implemented a substitution cipher. The idea is pretty simple: you build a table that maps each character to another, such as that shown in Figure 13-2. You encrypt a message by replacing each original character with its counterpart from the table and decrypt by doing the reverse. The original message is called cleartext, and the encrypted version is called ciphertext.

Figure 13-2: Substitution cipher
This cipher maps c to a, r to t, y to j, and so on, so the word cryptography would be enciphered as atjgvketqgnj. The reverse mapping (a to c, t to r, and so on) deciphers the ciphertext. This is called a symmetric code, since the same cipher is used to both encode and decode a message.
Why isn’t this a good idea? Substitution ciphers are easy to break using statistics. People have analyzed how often letters are used in various languages. For example, in English the most common five letters are e, t, a, o, n, in that order—or at least they were when Herbert Zim (1909–1994) published Codes & Secret Writing in 1948. Breaking a substitution cipher involves looking for the most common letter in the ciphertext and guessing that it’s an e, and so on. Once a few letters are guessed correctly, it’s easy to figure out some words, which makes figuring out other letters easy. Let’s use the plaintext paragraph in Listing 13-1 as an example. We’ll make it all lowercase and remove the punctuation to keep it simple.
theyre going to open the gate at azone at any moment
amazing deep untracked powder meet me at the top of the lift
Listing 13-1: Plaintext example
Here’s the same paragraph as ciphertext using the code from Figure 13-2:
vnzjtz ekyxe vk kgzx vnz eqvz qv qikxz qv qxj ckczxv
qcqiyxe ozzg lxvtqapzo gkrozt czzv cz qv vnz vkg kw vnz fywv
Listing 13-2 shows the distribution of letters in the enciphered version of the paragraph. It’s sorted by letter frequency, with the most commonly occurring letter at the top.
zzzzzzzzzzzzzzzz
vvvvvvvvvvvvvv
qqqqqqqqq
kkkkkkkk
xxxxxxx
ccccc
eeee
gggg
nnnn
ooo
ttt
yyy
ii
jj
ww
a
f
l
p
r
Listing 13-2: Letter frequency analysis
A code breaker could use this analysis to guess that the letter z in the ciphertext corresponds to the letter e in the plaintext, since there are more of them in the ciphertext than any other letter. Continuing along those lines, we can also guess that v means t, q means a, k means o, and x means n. Let’s make those substitutions using uppercase letters so that we can tell them apart.
TnEjtE eOyNe TO OgEN TnE eATE AT AiONE AT ANj cOcENT
AcAiyNe oEEg lNTtAapEo gOroEt cEET cE AT TnE TOg Ow TnE fywT
From here we can do some simple guessing based on general knowledge of English. There are very few three-letter words that begin with t and end with e, and the is the most common, so let’s guess that n means h. This is easy to check on my Linux system, as it has a dictionary of words and a pattern-matching utility; grep '^t.e$' /usr/share/dict/words finds all three-letter words beginning with a t and ending with an e. Also, there is only one grammatically correct choice for the c in cEET cE, which is m.
THEjtE eOyNe TO OgEN THE eATE AT AiONE AT ANj MOMENT
AMAiyNe oEEg lNTtAapEo gOroEt MEET ME AT THE TOg Ow THE fywT
There are only four words that match o□en: omen, open, oven, and oxen; only open makes sense, so g must be p. Likewise, the only word that makes sense in to open the □ate is gate, so e must be g. There’s only one two-letter word that begins with o, so ow must be of, making the w an f. The j must be a y because the words and and ant don’t work.
THEYtE GOyNG TO OPEN THE GATE AT AiONE AT ANY MOMENT
AMAiyNG oEEP lNTtAapEo POroEt MEET ME AT THE TOP OF THE fyFT
We don’t need to completely decode the message to see that statistics and knowledge of the language will let us do so. And so far we’ve used only simple methods. We can also use knowledge of common letter pairs, such as th, er, on, and an, called digraphs. There are statistics for most commonly doubled letters, such as ss, and many more tricks.
As you can see, simple substitution ciphers are fun but not very secure.
Transposition Ciphers
Another way to encode messages is to scramble the positions of the characters. An ancient transposition cipher system supposedly used by the Greeks is the scytale, which sounds impressive but is just a round stick. A ribbon of parchment was wound around the stick. The message was written out in a row along the stick. Extra dummy messages were written out in other rows. As a result, the strip contained a random-looking set of characters. Decoding the message required that the recipient wrap the ribbon around a stick with the same diameter as the one used for encoding.
We can easily generate a transposition cipher by writing a message out of a grid of a particular size, the size being the key. For example, let’s write out the plaintext from Listing 13-1 on an 11-column grid with the spaces removed, as shown in Figure 13-3. We’ll fill in the gaps in the bottom row with some random letters shown in italics. To generate the ciphertext shown at the bottom, we read down the columns instead of across the rows.

Figure 13-3: Transposition cipher grid
The letter frequency in a transposition cipher is the same as that of the plaintext, but that doesn’t help as much since the order of the letters in the words is also scrambled. However, ciphers like this are still pretty easy to solve, especially now that computers can try different grid sizes.
More Complex Ciphers
There’s an infinite variety of more complex ciphers that are substitution ciphers, transposition ciphers, or combinations of the two. It’s common to convert letters to their numeric values and then convert the numbers back to letters after performing some mathematical operations on the numbers. Some codes include extra tables of numbers added in to inhibit letter-frequency analysis.
The history of code breaking during World War II makes fascinating reading. One of the methods used to break codes was to listen to messages that were transmitted by radio. These intercepts were subjected to exhaustive statistical analysis and were eventually broken. The human mind’s ability to recognize patterns was also a key factor, as was some clever subterfuge.
Clues were also gleaned from messages that were sent about known events. The Americans won a major victory at the Battle of Midway because they knew that the Japanese were going to attack, but didn’t know where. They had broken the code, but the Japanese used code names for targets, in this case AF. The Americans arranged to have a message sent from Midway that they knew could be intercepted, saying that the island was short on fresh water. Shortly, the Japanese re-sent this message in code, confirming that AF was Midway.
The complexity of ciphers was limited by human speed. Although the Americans had some punch-card tabulating machines available to help with code breaking, this was before the computer age. Codes had to be simple so that messages could be encoded and decoded quickly enough to be useful.
One-Time Pads
The most secure method of encryption, called a one-time pad, harkens back to the work of American cryptographer Frank Miller (1842–1925) in 1882. A one-time pad is a set of unique substitution ciphers, each of which is only used once. The name comes from the way in which the ciphers were printed on pads of paper so that the one on top could be removed once it was used.
Suppose we want to encode our earlier message. We grab a page from our pad that looks something like Listing 13-3.
FGDDXEFEZOUZGBQJTKVAZGNYYYSMWGRBKRATDSMKMKAHBFGRYHUPNAFJQDOJ
IPTVWQWZKHJLDUWITRQGJYGMZNVIFDHOLAFEREOZKBYAMCXCVNOUROWPBFNA
Listing 13-3: One-time pad
The way it works is that each letter in the original message is converted to a number between 1 and 26, as is each corresponding letter in the one-time pad. The values are added together using base-26 arithmetic. For example, the first letter in the message is T, which has a value of 20. It’s paired with the first letter in the one-time pad, which is F with a value of 6. They’re added together, giving a value of 26, so the encoded letter is Z. Likewise, the second letter H has a value of 8 and is paired with G, which has a value of 7, so the encoded letter would be O. The fourth letter in the message is Y with a value of 24, which when paired with a D with a value of 4 results in 28. Then, 26 is subtracted, leaving 2, making the encoded letter B. Decryption is performed with subtraction instead of addition.
One-time pads are perfectly secure provided they’re used properly, but there are a couple of problems. First, both parties to a communication must have the same pad. Second, they must be in sync; somehow they need to both be using the same cipher. Communication becomes impossible if someone forgets to tear off a page or accidentally tears off more than one. Third, the pad must be at least as long as the message to prevent any repeating patterns.
An interesting application of one-time pads was the World War II–era SIGSALY voice encryption system that went into service in 1943. It scrambled and unscrambled audio using one-time pads stored on phonograph records. These were not portable devices; each one weighed over 50 tons!
The Key Exchange Problem
One of the problems with symmetric encryption systems is the need for both ends of a communication to be using the same key. You can mail a one-time pad to somebody or use a hopefully trusted courier, but you won’t know if it was intercepted along the way and a copy made. And it’s useless if it gets lost or damaged. It’s just like mailing a house key to a friend; you have no way to know whether or not someone made a copy along the way. In other words, it’s vulnerable to a man-in-the-middle attack.
Public Key Cryptography
Public key cryptography solves many of the problems we’ve discussed so far. It uses a pair of related keys. It’s like a house with a mail slot in the front door. The first key, called the public key, can be given to anybody and allows them to put mail in the slot. But only you, who can unlock the front door using the second or private key, can read that mail.
Public key cryptography is an asymmetric system in that the encoding and decoding keys are different. This solves the key exchange problem because it doesn’t matter if people have your public key since that can’t be used to decode messages.
Public key cryptography relies on trapdoor functions, mathematical functions that are easy to compute in one direction but not in the other without some piece of secret information. The term originates from the fact that it’s easy to fall through a trapdoor, but climbing back out is difficult without a ladder. As a really simple example, suppose we have a function y = x2. Pretty easy to compute y from x. But computing x from y using ![]() is harder. Not a lot harder, because this is a simple example, but you’ve probably discovered that multiplication is easier than finding a square root. There is no mathematical secret for this function, but you could consider having a calculator to be the secret because that makes solving for x as easy as solving for y.
is harder. Not a lot harder, because this is a simple example, but you’ve probably discovered that multiplication is easier than finding a square root. There is no mathematical secret for this function, but you could consider having a calculator to be the secret because that makes solving for x as easy as solving for y.
The idea is that the public and private keys are related by some complicated mathematical function, with the public key as the trapdoor and the private key as the ladder, making messages easy to encrypt but hard to decrypt. A high-level view of this is to have the keys be factors of a really large random number.
Asymmetric encryption is computationally expensive. As a result, it’s often used only to secretly generate a symmetric session key that’s used for the actual message content. A common way to do this is with the Diffie–Hellman Key Exchange, named after American cryptographers Whitfield Diffie and Martin Hellman.
Diffie and Hellman published a paper about public key cryptography in 1976. But it wasn’t until 1977 that an implementation became available because, although the concept of a trapdoor function is relatively simple, it turns out to be very difficult to invent one. It was solved by cryptographer Ronald Rivest in 1977, reportedly after a Manischewitz drinking binge, thus proving that mathematical prowess is unrelated to taste buds. Together with Israeli cryptographer Adi Shamir and American scientist Leonard Adleman, Rivest produced the RSA algorithm, whose name derives from the first letter of each contributor’s last name. Unfortunately, in a trust violation exposed by government contractor-leaker Edward Snowden, it turns out their company, RSA Security, took money from the NSA to install a kleptographic backdoor in their default random-number generator. This made it easier for the NSA, and anyone else who knew about it, to crack RSA-encoded messages.
Forward Secrecy
One of the problems with using a symmetric cipher session key for actual communications is that all messages can be read if that key is discovered. We know that many governments have the technical capability to record and store communications. If, for example, you’re a human rights activist whose safety depends on the security of your communications, you don’t want to take a chance that your key could be discovered and all your messages decoded.
The way to avoid this is with forward secrecy, wherein a new session key is created for each message. That way, discovering a single key is useful only for decoding a single message.
Cryptographic Hash Functions
We touched on hash functions back in Chapter 7 as a technique for fast searching. Hash functions are also used in cryptography, but only functions with certain properties are suitable. Just like with regular hash functions, cryptographic hash functions map arbitrary inputs into fixed-size numbers. Hash functions for searching map their input into a much smaller range of outputs than their cryptographic cousins, as the former are used as memory locations and the latter are just used as numbers.
A key property of cryptographic hash functions is that they’re one-way functions. That means that although it’s easy to generate the hash from the input, it’s not practical to generate the input from the hash.
Another important property is that small changes to the input data generate hashes that aren’t correlated. Back in Chapter 7, we used a hash function that summed the character values modulo some prime number. With such a function, the string b would have a hash value 1 greater than that of the string a. That’s too predictable for cryptographic purposes. Table 13-1 shows the SHA-1 (Secure Hash Algorithm #1) hashes for three strings that differ in only one letter. As you can see, there’s no discernible relationship between the input and the hash value.
Table 13-1: Corned Beef Hash
Input |
SHA-1 Hash Value |
Corned Beef |
005f5a5954e7eadabbbf3189ccc65af6b8035320 |
Corned Beeg |
527a7b63eb7b92f0ecf91a770aa12b1a88557ab8 |
Corned Beeh |
34bc20e4c7b9ca8c3069b4e23e5086fba9118e6c |
Cryptographic hash functions must be hard to spoof; given a hash value, it should be very difficult to come up with input that generates it. In other words, it should be difficult to produce collisions. Using the hash algorithm in Chapter 7 with prime number of 13, we’d get a hash value of 4 for an input of Corned Beef. But we’d get the same hash value for an input of Tofu Jerky Tastes Weird.
For a long time, the MD5 hash function was the most widely used algorithm. But in the late 1990s, a way was found to produce collisions, which you saw back in “Making a Hash of Things.” At the time of writing, MD5 has been replaced by variants of the SHA algorithm. Unfortunately, the SHA-0 and SHA-1 variations of this algorithm were developed by the NSA, which makes them untrustworthy.
Digital Signatures
Cryptography can help to verify the authenticity of data though digital signatures, which provide integrity, nonrepudiation, and authentication.
Integrity verification means we can determine whether or not a message was altered. For example, in ancient times, report cards were actual printed paper cards that listed classes and grades, which students brought home to their parents. I remember a poorly performing classmate in fourth grade adding vertical lines to the right side of his Fs to turn them into As. His parents couldn’t tell that the message was altered.
Integrity verification is accomplished by attaching a cryptographic hash of the data. But, of course, anybody can attach a hash to a message. To prevent this, the sender encrypts the hash using their private key, which the recipient can decrypt using the corresponding public key. Note that for signatures, the roles of the public and private keys are reversed.
The use of the private key provides both nonrepudiation and authentication. Nonrepudiation means it would be hard for a sender to claim that they didn’t sign a message that’s signed with their private key. Authentication means that that the recipient knows who signed the message since their public key is paired with the signer’s private key.
Public Key Infrastructure
There’s a big gaping hole in public key encryption. Suppose you use your web browser to connect to your bank using a secure (HTTPS) connection. The bank sends its public key to your browser so that your browser can encrypt your data, such that the bank can decrypt it using its private key. But how do you know that that public key came from your bank instead of some third party tapping into your communications? How does your browser authenticate that key? Who can it trust if it can’t trust the key?
Though unfortunately not a great solution, what’s used today is a public key infrastructure (PKI). Part of such an infrastructure is a trusted third party called a certificate authority (CA) to vouch for the authenticity of keys. In theory, a CA makes sure that a party is who they say they are and issues a cryptographically signed document called a certificate that one can use to validate their key. These certificates are in a format called X.509, a standard defined by the International Telecommunications Union (ITU).
While PKI generally works, it comes back to the trust problem. CAs have been hacked. Sloppy mistakes at CAs have caused their private keys to be accidentally published, making it possible for anyone to sign bogus certificates (fortunately, there’s a mechanism to revoke certificates). Some CAs have been found to be insecure in that they didn’t authenticate parties requesting certificates. And one can reasonably assume that governments believe that they have the right to force CAs to generate bogus certificates.
Blockchain
Blockchain is another application of cryptography. It’s a pretty simple idea backed by a lot of complicated math. Much of the media discussion of blockchain in connection to Bitcoin and other cryptocurrencies is about its applications, not about how it works.
You can think of blockchain as a mechanism for managing a ledger, similar to your bank account statement. A problem with ledgers is that they’re easy to alter on paper, and even easier to alter electronically since computers don’t leave eraser smudges.
A ledger usually consists of a set of records, each on subsequent lines. The blockchain equivalent of a ledger line is a block. Blockchain adds a cryptographic hash of the previous block (line) and a block creation timestamp to the next block. This makes a chain of blocks (hence the name) linked by the hashes and timestamps, as shown in Figure 13-4.

Figure 13-4: Simplified blockchain
As you can see, if the contents of block n were modified, it would change its hash so that it wouldn’t match the one stored in block n + 1. The properties of cryptographic hashes make it unlikely that a block could be modified in any useful way and still have the same hash. Each block effectively includes a digital signature of the prior block.
The only effective way to attack a blockchain is to compromise the software that manages it, an approach that can be somewhat mitigated by having the blockchain data be both public and duplicated on multiple systems. Attacking such a distributed system would require collusion among a number of people.
Password Management
Another application of cryptography is password management. In the good old days, computers maintained a file of passwords as cleartext. When someone logged in, the password they entered would be compared to the one stored in the file.
This is a bad approach primarily because anyone with access to the file knows everybody’s passwords. Keep in mind that this doesn’t have to be the result of an attack on the computer. Many organizations send their backups to third parties for storage (it’s a good idea to have at least three backups geographically far from each other, preferably on different tectonic plates). We’re back to trust again because someone could access the password file or any other data on these backups. You can encrypt your backups, but that’s a bit more fragile, as small-storage medium defects (such as a bad disk drive block) can render the entire backup unrecoverable. There’s a trade-off between protecting your data and being able to recover it.
A simple solution to this problem is to store the passwords in an encrypted format such as a cryptographic hash. When a user tries to log in, their password is converted to the cryptographic hash, which is then compared to the one on file. The properties of cryptographic hashes make it very unlikely that a password could be guessed. As an additional precaution, most systems prevent the password file from being accessible by normal users.
Passwords are problematic even with these practices, though. In the early days of shared computing, you might have needed passwords for a handful of systems. But now, you need countless passwords for bank accounts, school websites, many different online stores, and so on. Many people navigate this situation by using the same password everywhere; it turns out that the most common password is password, followed by password123 for sites that require numbers in the password. Reusing a password is equivalent to not using forward secrecy; if one site is compromised, your password can be used on every other site. You can have a different password for each site, but then you have to remember them all. You can use a password manager that stores all of your various passwords in one place protected by a single password, but if that password or the password manager itself is compromised, so are all of your other passwords. Probably the most effective but problematic approach is two-factor authentication, mentioned earlier. But that often relies on something like a cell phone and prevents you from accessing your accounts when you’re somewhere without cell service. Also, it’s cumbersome, which causes people to stay logged in to many sites.
Software Hygiene
Now that you know a little about security and cryptography, what can you do about it as a programmer? You don’t need to be a cryptography expert or security wizard to be able to avoid many common pitfalls. The vast majority of security flaws in the wild result from easily avoidable situations, many of which can be found in Henry Spencer’s The Ten Commandments for C Programmers. We’ll look at some of these in this section.
Protect the Right Stuff
When designing a system that keeps things secure, it’s tempting to make it keep everything secure. But that’s not always a good idea. If, for example, you make users log in to view things that don’t need to be secure, it makes users log in and stay logged in. Since logged-in users can access the “secure” content, that increases the chances that someone else can get access—for example, if the user walks away from their computer for a short time.
This is illustrated by the way in which many cell phones work. For the most part, everything is locked up, except possibly the camera. There are things that should be locked up; you don’t necessarily want someone to be able to send messages in your name if you lose your phone. But suppose you and your friends are listening to music. You have to hand your unlocked phone to someone else if they’re picking the tunes, giving them access to everything. Texting a code to your phone is a common second factor in two-factor authentication, and handing that factor to a third party defeats the purpose.
Triple-Check Your Logic
It’s pretty easy to write a program that you think does something when in fact it doesn’t. Errors in logic can be exploited, especially when an attacker has access to the source code and can find bugs that you didn’t. One method that helps is to walk through your code with someone else out loud. Reading aloud forces you to go through things more slowly than when reading silently, and it’s always amazing what you find.
Check for Errors
Code that you write will use system calls and call library functions. Most of these calls return error codes if something goes wrong. Don’t ignore them! For example, if you try to allocate memory and the allocation fails, don’t use the memory. If a read of user input fails, don’t assume valid input. There are many of these cases, and handling every error can be tedious, but do it anyway.
Avoid library functions that can silently fail or overflow bounds. Make sure that error and warning reporting is enabled on your language tools. Treat memory allocation errors as fatal because many library functions rely on allocated memory and they may fail in mysterious ways after an allocation failure elsewhere.
Minimize Attack Surfaces
This section paraphrases some of the April 19, 2016, testimony by cryptography researcher Matt Blaze to a US House of Representatives subcommittee following the San Bernardino shootings. It’s worth reading the whole thing.
We have to assume that all software has bugs because it’s so complex. Researchers have tried to produce “formal methods,” akin to mathematical proofs, that could be used to demonstrate that computer programs are “correct.” Unfortunately, to date this is an unsolved problem.
It follows that every feature added to a piece of software presents a new attack surface. We can’t even prove that one attack surface is 100 percent secure. But we know that each new attack surface adds new vulnerabilities and that they add up.
This is the fundamental reason that actual security professionals, as opposed to politicians, are against the notion of installing backdoors for law enforcement. Not only does it make the software more complicated by adding another attack surface, but just like the locker example earlier in this chapter, there’s a pretty good chance that unauthorized parties will figure out how to access such a backdoor.
It turns out that Matt Blaze really knows what he’s talking about here. The NSA announced its development of the Clipper chip in 1993. The NSA’s intent was to mandate that it be used for encryption. It contained a government-access backdoor. This was a difficult political sell because people in other countries would be reluctant to use American products that could spy on them. The Clipper sank both because of political opposition and because Blaze published a paper titled “Protocol Failure in the Escrowed Encryption Standard” in 1994 that showed how easy it was to exploit the backdoor. As an aside, Blaze found himself completely unprepared to be hauled in front of Congress to testify but is now very good at it. It was a part of the universe that he didn’t understand at the time. Consider learning to speak in public, as it might come in handy someday.
Good security practice is to keep your code as simple as possible, thus minimizing the number of attack surfaces.
Stay in Bounds
Chapter 10 introduced the concept of buffer overflows. They’re one example of a class of bugs attackers can exploit that can remain undetected in programs for a long time.
To recap, a buffer overflow occurs when software doesn’t check for boundaries and can end up overwriting other data. For example, if a “you’re authorized” variable exists past the end of a password buffer, a long password can result in authorization even if it’s not correct. Buffer overflows on the stack can be especially troublesome because they can allow an attacker to change the return address from a function call, allowing other parts of the program to be executed in an unintended manner.
Buffer overflows aren’t just limited to strings. You also must ensure that array indices are in bounds.
Another bounds problem is the size of variables. Don’t just assume, for example, that an integer is 32 bits. It might be 16, and setting the 17th bit might do something unexpected. Watch out for user input, and make sure to check that any user-supplied numbers fit into your variables. Most systems include definitions files that your code can use to ensure that you’re using the correct sizes for things. In the worst case, you should use these to prevent your code from building when the sizes are wrong. In the best case, you can use these definitions to automatically choose the correct sizes. Definitions exist for the sizes of numbers and even the number of bits in a byte. Don’t make assumptions!
It’s also important to stay in memory bounds. If you’re using dynamically allocated memory and allocate n bytes, make sure that your accesses are in the range of 0 to n – 1. I’ve had to debug code in which memory was allocated and then the address of memory was incremented because it was convenient for the algorithm to reference memory[-1]. The code then freed memory instead of memory[-1], causing problems.
Many microcomputers designed for embedded use include much more memory than is needed by a program. Avoid dynamic allocation in these cases and just use static data; it avoids a lot of potential problems. Of course, make sure that your code respects the bounds of the data storage.
Another bounds area is timing. Make sure your program can handle cases where input comes in faster than your interrupt handlers can respond. Avoid allowing your interrupt handlers to be interrupted so that you don’t blow off of the end of the stack.
There’s a testing technique called fuzzing for which tools are available that can help catch these types of bugs. But it’s a statistical technique and not a substitute for writing good code. Fuzzing involves hitting your code with a large number of variations on legal input.
Generating Good Random Numbers Is Hard
Good random numbers are important for cryptography. How do you get them?
The most common random-number generators actually generate pseudorandom numbers. That’s because logic circuits can’t generate true random numbers. They’ll always generate the same sequence of numbers if they start at the same place. A simple circuit called a linear feedback shift register (LFSR), such as that shown in Figure 13-5, can be used as a pseudorandom-number generator (PRNG).

Figure 13-5: Linear feedback shift register
You can see that as the number is shifted right, a new bit comes in from the left that is generated from some of the other bits. The version in the figure generates only 8-bit numbers, but larger versions can be constructed. There are two problems here. The first is that the numbers repeat cyclically. The second is that if you know the most recent random number, you always know the next one; if it just generated 0xa4, the next is always 0x52. Note that although this is a problem for cryptography, it’s useful when debugging programs.
The initial value in the register is called the seed. Many software implementations allow the seed to be set. There have been many improvements on the LFSR, such as the Mersenne Twister, but in the end they all have the same two problems I mentioned. There’s no true randomness.
Modern software addresses this problem by harvesting entropy from a variety of sources. The term entropy was co-opted from thermodynamics, where it refers to the universal tendency toward randomness.
One of the first entropy sources, called LavaRand, was invented at SGI in 1997. It worked by pointing a webcam at a couple of lava lamps. It could generate almost 200Kb of random data per second. The performance of entropy sources is important; if you’re a website generating lots of session identifiers for lots of clients, you need lots of good random numbers quickly.
It’s not practical to ship a pair of lava lamps with every computer, even though it would be groovy. Some chip manufacturers have added random-number generators to their hardware. Intel added an on-chip thermal noise generator random-number generator in 2012 that produced 500MB of random numbers per second. But people refused to use it because it was released right after the Snowden revelations and couldn’t be trusted.
There’s another factor in trusting on-chip random-number generators. A manufacturer could publish its design so that it could be reviewed. You could even decap, or remove the lid from, a chip and examine it using an electron microscope to verify that it matches the design. But it’s possible to undetectably change it during manufacturing. This is the hardware equivalent of a doping scandal. Chapter 2 mentioned doping in our discussion of transistors; dopants are the nasty chemicals that are used to create p and n regions. The behavior of the circuit can be altered by subtly adjusting the dopant levels. The result would be undetectable even through a microscope.
Security professionals have realized that they can’t trust hardware random-number generators. Entropy is harvested from random occurrences that are independent of computer programs, such as mouse movements, time between keyboard clicks, disk access speeds, and so on. This approach works pretty well, but quickly producing large quantities of random numbers is difficult.
Entropy harvesting has run afoul of some major dumb bugs, especially in the Linux-based Android operating system. It turns out that Android phones don’t generate entropy quickly, so random numbers used shortly after booting up aren’t so random. And it turns out that some of the early implementations copied code that harvested entropy from disk access times. Of course, cell phones don’t have disks; they have flash memory with predictable access times, making for predictable entropy.
If your security depends on good random numbers, make sure you understand the system that’s generating them.
Know Thy Code
Large projects often include third-party code, code not written by members of the project team. In many cases, your team doesn’t even have access to the source code; you have to take the vendor’s word that their code works and is secure. What could possibly go wrong?
First of all, how do you know that that code really works and is secure? How do you know that someone working on that code didn’t install a secret backdoor? This isn’t a hypothetical question; a secret backdoor was found in a major networking vendor’s products in 2015. An extra account with a hardcoded password was found in another vendor’s products in 2016. The list goes on, and will continue to grow as long as bad practices are tolerated. Plan for future abuses that are worse than the ones already known.
Ken Thompson’s 1984 Turing Award Lecture entitled “Reflections on Trusting Trust” gives an idea of how much damage a malicious actor can do.
Using third-party code causes another, subtler problem, which shows up with terrifying frequency in physical infrastructure software—the stuff that makes power plants and such work. You would think that critical software like this would be designed by engineers, but that’s the rare case. Engineers may specify the software, but it’s usually constructed by “system integrators.” These are people whose training is similar to what you’re getting under the auspices of “learning to code”; system integration pretty much boils down to importing code that others have written and gluing function calls together. The result is that product code ends up looking like Figure 13-6.

Figure 13-6: Unused vendor code and product code
This means a lot of unused code is included in products; in the figure, there’s more nonproduct code than product code. I once gave a series of talks about this where I labeled it “digital herpes,” because there’s all this code coiled around the central nervous system of your product, waiting for an external stimulus in order to break out, just like the human version of the virus.
This puts a coder into a difficult situation. How do you decide what third-party code is safe to use? Not everybody working on a power plant is an expert in cryptography or networking protocols.
First, this is an area in which open source code has an advantage. You can actually look at open source code and, because you can, there’s a good chance that others are looking at it too. This “more eyeballs” principle means that there’s at least a better chance of bugs being found than in closed source code that is seen by only a few. Of course, this isn’t a panacea. A major bug was discovered in the popular OpenSSL cryptography library in 2014. On the bright side, the discovery of this bug caused a large number of people to eyeball that code plus other security-critical packages.
Another good practice is to keep an eye on the ratio of code that you’re actually using in a third-party package to the overall size of the package. I once worked on a medical instrument project where management said, “Let’s use this cool operating system that we can get for a good price.” But that operating system included all sorts of functionality we weren’t going to use. I pushed back, and we just wrote our own code for the stuff that we needed. This was a couple of decades ago, and bugs have just been found in some deployments of this operating system.
One more area to watch is debugging code. It’s common to include extra code for debugging during product development. Make sure it gets removed before it’s shipped! That includes passwords. If you included default passwords or other shortcuts to make your code easier to debug, make sure that they’re gone.
Extreme Cleverness Is Your Enemy
If you’re using third-party code, avoid using obscure, clever facilities. That’s because vendors often discontinue support for features that aren’t widely used by their customers. When that happens, you’re often locked out of the upgrade path. Vendors often provide fixes only for the latest version of their products, so if your code depends on a no-longer-supported feature, you may not be able to install critical security fixes.
Understand What’s Visible
Think about the ways in which sensitive data can be accessed by programs other than yours—and not just data but metadata too. Who else can see your program’s data? This is an important part of defining a threat model. What could be compromised if someone absconds with your otherwise perfectly secure system? Can an attacker bypass protections by pulling the memory chips out of your device and accessing them directly?
Apart from making your code secure, you need to watch out for side-channel attacks—exploits based on metadata, or side effects, of the implementation. For example, say you have code that checks a password. If it takes longer to run on a password that’s close to correct than it does on one that isn’t, that gives clues to an attacker. This sort of thing is called a timing attack.
A camera pointed at the keypad on an ATM is a side-channel attack.
Attacks based on electromagnetic emissions have been documented. A cool one is called van Eck phreaking, which uses an antenna to pick up the radiation from a monitor to generate a remote copy of the displayed image. It has been demonstrated that ballot secrecy in some electronic voting systems can be compromised in this manner.
Side-channel attacks are really insidious and take serious systems thinking to ameliorate; just knowing how to write code isn’t enough. Examples abound, especially from the World War II era, which was the beginning of modern cryptography. The Germans were able to determine that Los Alamos National Laboratory existed because several hundred Sears catalogs were all being mailed to the same PO box. And British chemical plant locations were determined from the scores of the plant soccer team games published in local newspapers.
In general, make sure that your critical security code’s externally visible behavior is independent of what it’s actually doing. Avoid exposing information via side channels.
Don’t Overcollect
This is so obvious that I shouldn’t need to say anything, but experience demonstrates that few people get this. The best way to keep things secure is not to keep them at all. Don’t collect sensitive information unless you really need to.
A classic example is found on a lot of medical forms. I’m always perplexed when the forms ask for both my birthdate and my age. Do I really want a doctor who can’t figure out one from the other? If you collect them both, you have to protect them both, so collect only the one that you need.
Don’t Hoard
Just because you’ve collected sensitive information doesn’t mean you should keep it around forever. Get rid of it as soon as possible. For example, you may need somebody’s password to log them in to some system. Once you’re done checking the password, it’s no longer needed. Clean it up. The longer you leave it around, the better the chances of someone discovering it.
Cleaning up is becoming more legally important as the world struggles to understand the European Union’s General Data Protection Regulation (GDPR), which adds consequences for leaking personal information.
Dynamic Memory Allocation Isn’t Your Friend
Chapter 7 talked about dynamic memory allocation using the heap. In this section, we’ll look at the C standard library functions malloc, realloc, and free, which can cause a number of different problems.
Let’s start by looking at what happens when dynamically allocated memory is freed; see Figure 13-7.
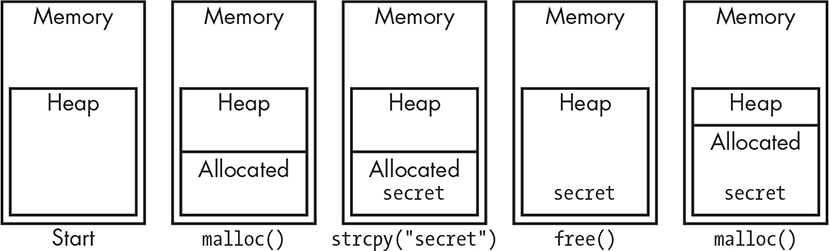
Figure 13-7: Freeing memory
On the left side of Figure 13-8, you can see the heap sitting in memory. Moving to the right, a piece of memory from the heap is allocated for use by the program. Continuing toward the right, a piece of secret information is copied into the allocated memory. At some point later, that memory is no longer needed, so it’s freed and goes back onto the heap. Finally, on the far right, memory is allocated from the heap for some other purpose. But the secret is still in that piece of memory where it can be read. Rule #1 of using dynamic memory is to make sure you erase any sensitive information in memory before freeing.
The realloc function lets you grow or shrink the size of allocated memory. Look at the shrink case in Figure 13-8.
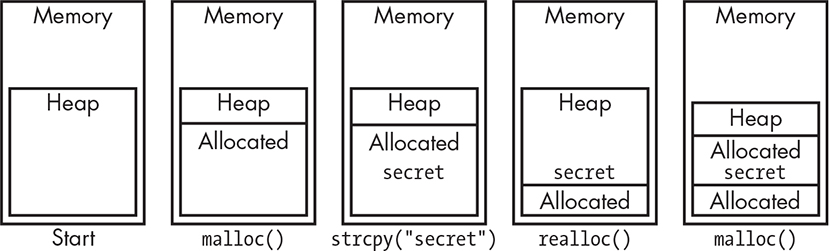
Figure 13-8: Memory shrink
The first steps are the same as in the previous example. But then the amount of allocated memory is shrunk. The secret was in the excess memory, so it goes back onto the heap. Then a later allocation of memory gets a block that contains the secret. Rule #2 of using dynamic memory is to make sure that any memory that’s going back on the heap due to a shrink is erased. This is similar to Rule #1.
There are two cases to consider when using realloc to grow the size of an allocated memory block. The first case is easy and isn’t a security problem. As shown in Figure 13-9, if there’s room above the already allocated block on the heap, the size of the block is increased.

Figure 13-9: Good memory grow
Figure 13-10 shows the case that can cause security problems.
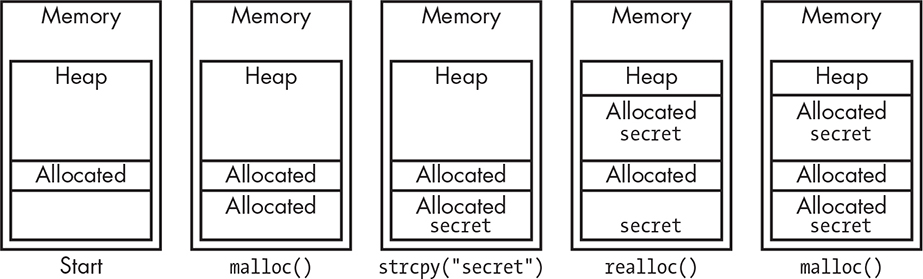
Figure 13-10: Bad memory grow
In this example, there’s another piece of memory that has already been allocated for some other purpose. When we try to increase the size of our allocated memory block, there’s not enough space because of the other block, so the heap is searched for a large enough contiguous block of memory. The memory is allocated, the data from the old block is copied in, and the old block is freed. Now there are two copies of the secret in memory, and one is in unallocated memory that could be allocated. The big problem here is that the realloc caller has no visibility into what’s happening. The only way to tell whether or not the memory block was moved is to compare its address to the original address. But even if it moved, you’ve found out too late because the old block is no longer under your control. This leads to rule #3: Don’t use realloc when security is critical. Use malloc to allocate new memory, copy the old to the new, erase the old, and then call free. Not as efficient, but much more secure.
Garbage Collection Is Not Your Friend Either
I’ve talked about erasing critical data once it’s no longer needed. The preceding section showed that this isn’t as easy to do as it sounds with explicit memory management. Garbage-collected systems have their own set of unique problems. Let’s say we have a program in C that contains something “sensitive,” as shown in Figure 13-11.

Figure 13-11: C string of sensitive data
How do we clean this up once we’re done with it? Because C strings are NUL terminated, we can make it an empty string by setting the first character to NUL, as in Figure 13-12.
Figure 13-12: Poorly erased C string of sensitive data
It wouldn’t be hard for a nefarious individual to guess the contents. We really need to overwrite the entire string.
This string could be in a memory array, or it could be in memory dynamically obtained using malloc. Make sure the string is set to NULs or some recognizable value that’s easy to spot when debugging, erasing every character before calling free; otherwise, the sensitive data just ends up back on the heap and might be given out on a later malloc call.
What if we’re using a language that uses garbage collection instead of explicit memory management? Something like secret = "xxxxxxxxxxxxxxx" doesn’t do what you think in languages like JavaScript, PHP, and Java. Rather than overwrite the sensitive data, these languages might just make a new string for you and add the sensitive data string to the list of things to be garbage-collected. The sensitive data isn’t erased, and you have no ability to force it to be erased.
It would be nice if these sorts of issues were limited to programming languages and environments, but that’s not the case. Flash memory is used in more and more places. One of those places is in solid-state disk drives (SSDs). Because flash memories wear out, these drives use load leveling to equalize the usage among the various flash memory chips. That means that writing something to one of these devices doesn’t guarantee that the old version was erased. It’s just like freeing allocated memory and having it end up on the heap.
As you can see, even the act of erasing something securely is more complex than anything you’re being taught while “learning to code.” You need a thorough understanding of all aspects of an environment in order to do the job well, which is of course why you’re reading this book.
Data as Code
You should be aware by now that “code” is just data in a particular format that’s understood by a computer. That originally meant computer hardware, but now many programs, such as web browsers, execute data including in the form of JavaScript programs. And JavaScript can also execute data; its eval statement treats any string as if it’s a program and runs it.
In Chapter 5, we looked at some of the hardware that prevents computers from treating arbitrary data as code. Memory management units or Harvard architecture machines keep code and data separate, preventing data from being executed. Programs that can execute data don’t have that sort of protection, so you have to provide it yourself.
A classic example is SQL injection. SQL, short for Structured Query Language, is the interface to many database systems. The structured part allows data to be organized into, for example, personnel records. The query part allows that data to be accessed. And, of course, the language is how it’s done.
SQL databases organize data as a set of tables, which are rectangular arrays of rows and columns. Programmers can create tables and specify the columns. Queries insert, remove, modify, or return rows in tables.
You don’t need to know all the details of SQL to understand the following example. What you do need to know is that SQL statements are terminated with semicolons (;) and that comments begin with the number or hash sign (#).
Your school probably has a website you can use to check your grades. Our example uses a SQL database that includes a table called students, as shown in Table 13-2.
Table 13-2: Students Table in Database
student |
class |
grade |
David Lightman |
Biology 2 |
F |
David Lightman |
English 11B |
D |
David Lightman |
World History 11B |
C |
David Lightman |
Trig 2 |
B |
Jennifer Mack |
Biology 2 |
F |
Jennifer Mack |
English 11B |
A |
Jennifer Mack |
World History 11B |
B |
Jennifer Mack |
Geometry 2 |
D |
The website offers an HTML text field in which a student can enter the name of a class. A bit of JavaScript and jQuery sends the class name to the web server and displays the returned grade. The web server has some PHP code that looks up the grade in the database and sends it back to the web page. When a student logs in, the $student variable is set to their name so that they can access only their own grades. Listing 13-4 shows the code.
HTML
<input type="text" id="class"></input>
JavaScript
$('#class').change(function() {
$.post('school.php', { class: $('#class').val() }, function(data) {
// show grades
});
});
PHP
$grade = $db->queryAll("SELECT * FROM students
WHERE class='{$_REQUEST['class']}' && student='$student'");
header('Content-Type: application/json');
echo json_encode($grade);
Listing 13-4: Student website code fragments
The database query is straightforward. It selects all (*) columns from all rows in the students table where the class column matches the class field from the web page and the student column matches the variable containing the logged-in student name. What could possibly go wrong?
Well, David may not be paying much attention to Biology, but he’s good with computers. He logs in to his account. Instead of entering Biology 2 for a class, he enters Biology 2' || 1=1 || '; #. This turns the select statement into what’s shown in Listing 13-5.
SELECT * FROM students WHERE class='Biology 2' || 1=1 || ''; # && student='David Lightman'
Listing 13-5: SQL injection
This reads as “select all columns from students where class is Biology 2 or 1 equals 1 or an empty string.” The semicolon ends the query early, and the rest of the line is turned into a comment. Because 1 always equals 1, David has just gained access to the entire set of student grades. I could go on to show you how David impresses Jennifer by changing her Biology grade, but you can just watch the 1983 movie WarGames. As a teaser, he could enter something in the field with a semicolon, then follow that with a database update command.
These aren’t just theoretical science fiction movie scenarios; see xkcd cartoon #327. As recently as 2017, a major SQL injection bug was found in the popular WordPress website software, which was used by a very large number of websites. This should further demonstrate the problems that can occur when you rely on third-party code.
As another example, many websites allow users to submit comments. You must be careful to sanitize every comment to make sure it doesn’t contain JavaScript code. Otherwise, a user viewing those comments would inadvertently run that code. And if you don’t prevent users from submitting comments in HTML, you’ll likely find the comments filled with advertisements and links to other websites. Make sure user input can never be interpreted as code.
Summary
In this chapter, you’ve gained a basic understanding of security principles. You learned a bit about cryptography, a key computer security technology. You also learned about a number of things that you can do to make your code more secure.
In addition, hopefully you’ve learned that security is very difficult and not for amateurs. Consult experts until you’ve become one. Don’t go it alone.
Just like security, machine intelligence is another advanced topic that’s worth knowing a bit about. We’ll turn our attention to it in the next chapter.