
In the process of identifying and describing use cases, one might recognize the same subflow in two or more use cases. Obviously, if the purposes and the goals of these use cases are identical, if they interact with the same actors, and if the subflow constitutes most of the use cases, one should consider merging the use cases into one use case or introduce a generalization relationship (see Chapter 11, “Use-Case Generalization: Classification and Inheritance”). If both use cases include a certain subflow that is exactly the same in both flows, but otherwise are disparate and with different purposes and goals, however, it would be a mistake to join them. The resulting use case would not be easily understood, and eventually the merged use case would have to be split because it encompasses disjoint goals.
The issue here is to ensure that the common part-flow stays identical, and to minimize maintenance of the descriptions. The solution is the include relationship, which means that one use case includes the flow described in another use case in its own declaration—that is, the sequence of the first use case includes the whole sequence of the other as a subsequence.
In a warehouse system, there is one use case for registering new items and another use case for ordering items (see Figure 7.1). In both cases, the system will check whether the person performing the operation is allowed to do so. The checking of the access rights is therefore extracted and described in a separate use case. This use case is included in the
Register Itemuse case as well as in theOrder Itemuse case, which implies that the checking procedure is described only once and referenced from all other places where it is to be included.
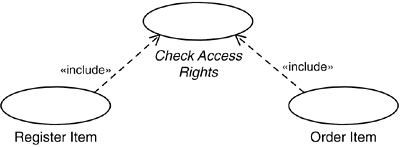
Figure 7.1. In both use cases, the access rights must be checked. herefore, the checking is extracted into a third use case, which is included by the original two.
The include relationship is mainly a reuse mechanism: The flow defined in a use case is reused in the including use case. In this way, a subflow that is common to multiple use cases can be defined just once instead of in all the use cases. Changes to the definition of the common flow will take place in only one use case and then be propagated into all the including use cases.
When discussing the use cases involved in an include relationship, it becomes awkward referring to them as “the included use case” and the “including use case,” because the terms are more or less alike, and this might even lead to unnecessary misunderstandings. It is therefore common vocabulary to refer to the including use case as the base use case, and the included one as the inclusion use case (see Figure 7.2). Note, however, that this labeling is relative to the include relationship at hand; the same use case may be the base use case in one include relationship, and the inclusion use case in another one—that is, it does not characterize the use case itself in any way.

Note that an include relationship does not imply communication between instances of the use cases, or the like (which is not possible, as discussed in Chapter 4, “Use Cases,” in the section Use-Case Instance). It just indicates that a part of the description of the complete flow of a use case is described in the description of another use case. The sequence of actions performed when executing one of the base use cases will include the actions defined in the inclusion use case (see Figure 7.3).
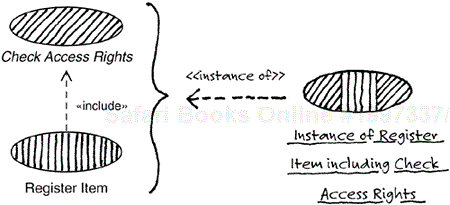
Figure 7.3. The use-case instance to the right follows the description of the Register Item use case, which includes the description of the Check Access Rights use case, as indicated by the hatching.
A use-case instance performing the actions of a base use case, like Register Item in Figure 7.3, encounters at some point an instruction to include another use case (Check Access Right, in this case). At that point, the instance performs the actions of the inclusion use case, and then resumes obeying the description of the base use case after the include instruction (see Figure 7.3). Any results from performing the included actions (in this case, the result of checking the access rights) are then available within the use-case instance.
It is usually not possible to perform solely the inclusion use case. Often, such a use case does not define a complete usage offered by the system, but only part of one or several of the ways the system can be used. Inclusion use cases are therefore often declared to be abstract.
An abstract use case will never be instantiated; that is, it will never be performed on its own. Its only purpose is to model and describe a (sub-)flow which can be reused by or have other kinds of relationships to other flows—just like abstract classes. In UML, an abstract element is denoted by putting its name in italics. The opposite of abstract is concrete; a concrete use case can be instantiated—that is, it is a complete flow that can be performed on its own.
Note, however, that there is no constraint on an inclusion use case that it must be abstract. Situations where a certain subflow of one use case may also be performed on its own are not uncommon, and the include relationship is most useful in these situations as well (see Chapter 19, “Concrete Extension or Inclusion”).
Sometimes the include relationship is used to factor out part of a flow, even if it is used in just one use case. This is not always considered bad modeling. Possible reasons for using it are the option to reuse it in later iterations or versions of the system, or the option to make a subflow explicit in the model, which might be important for the stakeholders. However, avoid introducing include relationships that are not prompted by common parts for two or more use cases! The included use case must have some merits as a use case of its own, because it is to be reviewed and maintained and above all because it will increase the size and the complexity of the use-case model and hence often make it more difficult to understand. It is essential to keep the number of include relationships between use cases at a minimum. It is particularly important not to define such relationships too early on in the process of identifying use cases, unless there is an explicit requirement that a subflow be common to multiple use cases. Otherwise, there is a risk that later descriptions will have to be made according to an include relationship that actually should not have been available because later descriptions show that the flows have precious little in common.
Include: A Picture from Real Life
To get an intuitive feeling for the include relationship, consider what happens in a kitchen when a person (let's call him Viktor) is about to prepare a blueberry pie. Viktor is not a very experienced cook, so he will use a cookbook recipe. The blueberry pie recipe can be compared with a use-case description: in this case, Make Blueberry Pie. An instance of this use case will correspond to somebody baking a blueberry pie.

When Viktor reads the recipe, he finds that the cookbook writer has made use of the fact that many kinds of pies are partly made in the same way. In particular, the dough of many of the pies is prepared in the same way. The writer has therefore described the dough in a separate recipe, and the recipes of various kinds of pies refer to it. This is the same mechanism as an include relationship; instead of repeating how the dough is prepared in every pie recipe, this is described once, and this description is to be included in the recipe of the blueberry pie, for example.
When Viktor makes his blueberry pie—that is, when the instance of Make Blueberry Pie is executed—he starts by following the description in the blueberry pie recipe. At some point in this pie recipe, there is a reference to the dough recipe, so he turns the page and continues by following the instructions there. When that is done, he returns to where he was in the blueberry pie recipe and continues making the pie by following that part of the description. This is clearly one flow. The fact that Viktor needs to look at two places in the cookbook does not contradict the statement that baking a blueberry pie is only one sequence of events. There is only one use-case instance performed, regardless of whether the description is to be found in one place or split into two parts to be found in different places. And, obviously, it would not be meaningful to say that the flow of the preparation of blueberry pie communicates with the flow of the preparing of dough.
The include relationship is documented in the description of the including use case (see Chapter 13, “Describing Use Cases”). The inclusion itself is just stated in the flow of events section of the use-case description, as described in Figure 7.4.

Figure 7.4. In the description of the Withdraw Money use case, there is an explicit reference as to where to include the Check PIN Code use case.
In principle, the inclusion use case is described as any other use case. However, because it usually models part of a usage and not the complete usage, an inclusion use case is often abstract. This means that it does not necessarily start with an input from an actor, nor is it required to include any output or to have a well-defined end of the sequence of actions. However, an inclusion use case must form a continuous sequence, because the whole inclusion use case is to be inserted at one location of the base use case; it must not be distributed over multiple locations of the base use case.
The start and the end of the description of an inclusion use case differ slightly from the ones of a use case that is not to be included in other use cases (see Figure 7.5). Note that the end section of an inclusion use case explicitly states which information is available in the base use case after the inclusion—that is, the result of the included flow, if any, because this is important information when reusing this use case (see also Chapter 19, “Concrete Extension or Inclusion”).

When two use cases are connected by an include relationship, the base use case is dependent on the inclusion use case, but not the other way around, just as in other reuse situations. This is also shown in the notation of the relationship: The base use case's dependency on the inclusion use case is shown, as always in UML relationships, with the direction of the arrow (see Figure 7.6).

The reuse aspect of the relationship implies some additional constraints on the participating use cases. First, as mentioned previously, an inclusion use case must not be dependent on any of its base use cases. Therefore, it must not be dependent on the structure of its base use cases or on how they are described. For example, an inclusion use case must not depend on a base use case's association to an actor, or on the terminology used in the description of a base use case. If the definition of the inclusion use case were to be dependent on a base use case, it would not be suitable for reuse because all its base use cases would then have to be defined in a specific way. Furthermore, the amount of information in the system accessed both by actions in an inclusion use case and by actions in its base use cases should be minimized, although it is often impossible to make it go away completely.
Moreover, the base use cases must not depend on what is inside the inclusion use case, because any change there would then affect the base use cases. The base use cases must depend only on the result of the execution of the actions defined in the inclusion use case's sequences of actions and not on any specific action or relationship to other elements (for instance, actors). We say that the inclusion use case must be encapsulated—its interior must not be exposed to or used by the base use cases.
However, the definition of the base use case is dependent on the existence of the inclusion use case. Remove the latter and the former will break.