
Understanding the professional approach to software development
Building a software development toolbox
Seeing why component-based software is superior
Peeking at how programs are executed in .NET
Discovering automatic memory management
This chapter offers an abbreviated history of software development by discussing where the process now stands and how it got there. You also find out about some of the inner workings of .NET as it relates to modern development approaches.
Even if you've never worked in software development, you've no doubt heard about many of the problems associated with software development projects, such as
Frequent schedule and budget overruns
Software that doesn't do what it's supposed to do
Software that's obsolete by the time it gets finished
Software that ships with security flaws
Over the years, the software development industry has created a number of approaches and tools to help better manage software development. I discuss several approaches in more detail in the upcoming section "Have process, will repeat." However, some of these approaches can be categorized in one of these two main approaches, although most real-life situations are a hybrid of the two:
Ad hoc, or hotshot: In this approach, characterized by nonexistent development practices, no standard exists for how software is developed. Hotshot programmers often work all night and come in at noon the next day. You usually get no documentation, and only the programmer understands how the code works.
Rigorous and slow: As a rejection of the other approach, this one takes an engineering view of software development. The argument is that dotting all your i's and crossing all your t's, and then getting proper sign-off at each step along the way, gives software development a process that's repeatable and — most importantly — accountable. Unfortunately, the engineering approach adeptly creates mountains of documentation but doesn't adeptly create working software on budget and on time. It also squelches the creativity that truly phenomenal innovations rely on.
After producing many failed projects, software developers have started to get the message that ad hoc approaches are too immature and the rigors of an engineering mentality probably too inflexible. At the same time, most companies have learned that relying on hotshot developers is a recipe for disaster. Instead, many firms now hire developers who write manageable code, rather than someone who can write code faster than anyone else.
Of course, in spite of everyone's best efforts, sometimes a superhuman effort may be required for several days. One particular project that comes to mind involved training that was to take place on Monday. On Saturday, several severe software flaws were discovered that had to be fixed. They were all fixed by Monday at 2 a.m. But, as you can likely guess, no one got a lot of sleep that weekend.
Over the years, a number of methodologies and tools were created in an attempt to solve the problems involved in software development, with each solution promising to deliver software development projects from the evils of scope creep and second system syndrome. (Scope creep occurs when additional features that weren't originally planned for find their way into the software.)
If you've ever worked on the second incarnation of an existing system, you've no doubt experienced second system syndrome. In this case, the project quickly gets bloated because developers and users see so many opportunities to improve the existing system. Unfortunately, many methodologies and tools designed to keep projects on track are not only very expensive, but their implementation also requires significant overhead. As a result, companies spend a lot of money but don't always see results. And, on a personal note, any time that the marketing department has input, runaway feature creep is a real danger.
Now that software developers have had some time to see what doesn't work, they've started to create a living framework of what does work:
Repeatable processes: Rather than treat every project as if it's shiny and new, developers have started to acknowledge that they should take some common steps. Also, by acknowledging that different kinds of software development projects exist, developers are rejecting the notion of a one-size-fits-all process and are instead creating processes that can scale up or down to fit the project.
Best practices: By creating a body of industry best practices, software developers are sharing and reusing their knowledge of how to solve problems.
Multiple tools: Developers have learned that no single tool can do the job. Instead, tools from many different vendors and the open source community is a better approach than putting all your eggs in one basket with a single vendor.
Note
You can find a list of best practices at this book's companion Web site. You can link to it from the page at www.dummies.com/go/vs2010.
When they're ready to start a new software development project, many developers aren't sure where to begin. Depending on your role in the project, the project may not actually start for you until after somebody else completes his responsibilities. Does the project start before or after the kick-off meeting? Should you even have a kick-off meeting — and, if so, who should attend? These questions are answered by the management style and processes that your company adopts for developing software.
Managing a software development project tends to fall somewhere between these two approaches:
Waterfall: In the waterfall approach, one phase of the project completely ends before another phase can start. In this way, the project "waterfalls" through the stages.
Iterative: Projects that are developed iteratively go through the same phases multiple times. Developers can move backward and forward through the development phases several times to iteratively develop their understanding of both the problem and the solution.
A process for developing software is like any other process: It's a set of steps you go through to achieve an outcome. Your company has a process for paying bills and entering into contracts. Some business processes are more strictly defined and closely adhered to than others. The same is true for developing software. Some companies have strict rules about how projects are initiated and how they progress. Other companies approach each project like it's their first.
This list offers a few of the popular process approaches:
Software engineering: The rigorous engineering approach brings an engineering mindset to software projects. A body of standards outlining the kinds of documentation and processes that should support a project is defined in the Institute of Electrical and Electronics Engineers (IEEE) software engineering standards.
Agile: This approach embraces change as part of the software development process. In most approaches, change is usually considered a bad word. Agile developers work in pairs, create many prototypes of their solutions, and incorporate user feedback throughout the entire process.
Test-driven: This newer approach to building software involves building test harnesses for all code. These tests, written from the requirements documentation, ensure that code can deliver promised features.
Rational Unified Process (RUP): The RUP commercial process uses the IBM suite of Rational tools to support software development. Its noncommercial equivalent is the Unified Process (UP). RUP and UP are iterative approaches.
What's common to all these approaches is the acknowledgment of a software development life cycle (SDLC). Most processes account for the fact that all software progresses through a life cycle that has similar stages:
Initiation: Project planning and justification get the project up and running.
Requirements gathering: After the project is approved, developers start talking with users about what they expect the software to do. Frequently, this phase requires re-examining the planning and feasibility efforts from the preceding stage.
Analysis: At this stage, developers analyze the requirements they have gathered to make sure that they understand what end users want.
Design: Developers start to work out models that describe what the requirements might look like in software.
Construction and implementation: Developers write the programs that execute the models created in the design stage.
Testing: The programs are tested to ensure that they work properly and meet the requirements that the end user specified.
Deployment: Software is installed, and end users are trained.
Maintenance: After the software has passed all its tests and been implemented, it must still be supported to ensure that it can provide many years of service to the end user community.
In a project that uses a waterfall management approach, the software is likely to progress through the stages of the life cycle in chronological order. A project managed iteratively cycles back through the phases while it makes forward progress. On larger projects, people usually fill specialized roles at different stages of the SDLC. One person often fills multiple roles. Table 3-1 lists some common roles in the SDLC.
Table 3-1. Roles in a Software Project
SDLC Phase | Role or Job Title |
|---|---|
Initiation | Project manager, project sponsor |
Requirements gathering | Analyst, subject matter expert |
Analysis | Analyst, subject matter expert |
Design | Designer, architect (possibly specialized, such as software architect or technical architect) |
Construction and implementation | Programmer |
Testing | Tester, quality assurance (QA) personnel |
Deployment | Installer, trainer, technician, technical architect |
Maintenance | Support personnel, programmer, tester |
A software project generally doesn't flow like a waterfall through stages of the SDLC, so that's a big reason why the waterfall approach has fallen out of favor. In most cases, the stages of the SDLC are either
Iterative: The stages are repeated multiple times throughout the project. For example, developers commonly loop through the initiation, requirements, and analysis phases several times until they get a handle on what they're expected to build. Each loop delves progressively deeper into the details. You'll frequently question the assumptions of the requirements and analysis stages after you start building models in the design stage.
Concurrent: Stages often occur at the same time. For example, a group of developers might analyze requirements while another group starts to build the design models. The design group can start to validate (or invalidate) the analysis assumptions.
Tip
Choosing a process isn't an either/or proposition. Many teams like to combine the features they like best from several different approaches. For example, your team might like the change-management features of the agile approach. If you have doubts as to which way to go, you can refer to the IEEE software engineering standards.
Regardless of the approach you decide to take, here's some advice to take into consideration:
Use a process — any process. Homegrown processes are sometimes better than store-bought ones. If everyone gets to participate in creating a process, they're more likely to want to see it succeed.
Repeat the process. A process becomes a process only after it has been repeated multiple times. Doing something once and then abandoning it doesn't create a process.
Improve the process. You can't improve your process unless it has some means of providing feedback and metrics for measuring. Without metrics, you have no way of knowing when something has improved. If you're unsure how to approach collecting project metrics or improving your process, take a peek at other methodologies to get some ideas.
A body of knowledge has started to develop around software development. Developers realize that many businesses are trying to solve the same kinds of problems. Rather than treat each project as a one-off experience, developers know that elements of the project are common to other projects that they need to develop. When a problem gets solved the same way over and over again, the solution is often referred to as a best practice. For a best practice to develop, many people must be trying to solve the same problem. For example, the following list includes several problems that Web site developers try to solve:
Providing secure access
Logging errors
Accessing data
Businesses also need to solve a common set of problems, such as the following:
Capture and fulfill orders
Manage customer information
Invoice and receive payments
Rather than try to solve all these problems on your own, an entire community of developers, authors, and companies are sharing their experiences and guidance on how to approach these problems.
This shared knowledge can be called best practices, design patterns, frameworks, or models. Microsoft's own vision for sharing knowledge includes patterns, practices, and software factories.
In fact, the underlying premise of runtime environments, such as the Microsoft .NET Framework and the Java Virtual Machine, is that all programs need common features, such as portability and memory management. Frameworks, patterns, practices, and models are all knowledge repositories that enable developers to reuse the work of other developers. Modern software development makes extensive use of all these knowledge-sharing tools.
According to Professor Joe Hummel, of Lake Forest College, some of the best practices for software development include these elements:
Object-oriented programming: This style of programming makes programs easier to understand and test.
Components: Software that's broken into components is easier to deploy. The upcoming section "Components Defeat Monoliths" expands on the benefits of using components.
Testing: Integration testing, or repeated automated testing, is important in order to see how components work together.
Code reviews: Standards are crucial for identifying how code should look. Having peers review each other's code enforces standards and exposes developers to new styles. (As the adage goes, "Two heads are better than one.")
Prototyping: You should build your software frequently, not only to make sure that it works, but also to get it in front of end users early and often so that they can validate your progress.
Tools, tools, tools: Use tools to help you manage your process and projects. See the next section for more about using tools.
Tip
Another best practice to keep in mind is that when it comes to developing software, less is more. A team of four to six developers can usually develop higher-quality software than larger teams can. As team size increases, so does the complexity of keeping everyone in the loop. Keep your team sizes small.
Note
When you're using best practices, you have to keep things in context. The tools and processes you use for building commercial-quality software may not be the same tools and processes you should use to build software for an internal department that has a closed information technology environment.
Just like plumbers and auto mechanics have toolboxes, software developers have toolboxes, too. Your software development toolbox should include all the usual suspects:
Integrated development environment (IDE), such as Visual Studio
Third-party tools that you like to use for testing or logging
Tip
Many developers take advantage of open source software, such as NUnit for unit testing and Log4Net for logging application errors.
Project management software, such as Microsoft Project, or maybe even a simple spreadsheet program
Collaboration software, such as Windows SharePoint Services, that you can use to store your project's artifacts
Source code-control software so that you can keep all your source code safe and secure. Some popular source code control applications are Perforce, Microsoft Team Foundation Server, and Subversion.
You should build a toolbox of resources to which you can turn for advice about how to handle security, build secure Web sites, and face any other kind of software challenge. Sure, you could just Google whatever you're looking for. You have more success, though, if you turn to a common set of resources. Here's a start:
Tip
You may have more success using a Google site search for something on the MSDN or the Microsoft Knowledge Base by going to www.google.com/advanced_search?hl=en and providing an entry in the Search Within a Site or Domain Field.
Software Engineering Institute (SEI): The SEI plays a huge role in defining software engineering. You can find SEI on the Web at
www.sei.cmu.edu.Software Engineering Body of Knowledge (SWEBOK): The SWEBOK represents the consensus among academicians and practitioners for what the processes for software development should look like. If you have never thought about what it means to engineer software, the SWEBOK is a great place to start. You can download it at
www.swebok.org.Microsoft patterns and practices: A few years ago, Microsoft finally started sharing with the world how it thinks that software developed by using Microsoft tools should be developed. Microsoft patterns and practices is a combination of books, articles, software, and other resources that help you write software the way Microsoft believes it should be written. Find patterns and practices at
http://msdn.microsoft.com/practices/GettingStarted.Rational Unified Process (RUP): RUP is one of the more popular development processes. You can find tons of books and articles on the subject. Note that you can use the RUP without buying any of the tools that IBM makes to support the process.
Agile Manifesto: The manifesto for agile software development can change the way you think about software development. Read the manifesto at
http://agilemanifesto.org.MSDN Webcasts: The Microsoft Developer Network, or MSDN, presents Webcasts on every kind of software subject imaginable. You can find Webcasts at
http://msdn.microsoft.com/events. Read more about MSDN in Book II, Chapter 3.
Tip
A Webcast that you may find valuable is the series Modern Software Development in .NET, by Professor Joe Hummel. Dr. Hummel has a series on C# and on Visual Basic; you can download his Webcasts from www.microsoft.com/events/series/modernsoftdev.mspx.
Note
Much of the advice you find tells you how software should be developed, but not so much how it is developed. Become familiar with how things are supposed to be done as you continue learning the techniques that other developers use to solve real-world problems.
The most important lesson that software developers have learned is that "it takes a village." Long gone are the days when hotshot programmers were expected, or allowed, to hole up in their offices for weeks while they created the next big application.
Now, software development is recognized as a team effort. Although some teams still place people in specialized roles, such as programmers, people are more commonly filling multiple roles on a project. The lines between analysts, designers, programmers, and testers are becoming more blurred.
The blurred roles are part of the reason that many developers objected to Microsoft's planned release of different versions of Visual Studio based on the roles of a development team. As roles blur, developers are expected to be more flexible.
Not all developers work a 40-hour week, of course, although the length of that workweek is becoming the norm. Many consulting houses are becoming more reasonable about creating a work-life balance for their employees, and an increasing number of developers are maintaining reasonable hours. There are even rumors that developers at Microsoft, known for working extremely long hours, are now working regular hours.
Developers are sometimes expected to work extra hours, of course. Sometimes, during the software development life cycle, extra work is required, although it's becoming more of an exception than the norm.
Older software that was developed before the creation of modern software development techniques, or that uses outdated practices or obsolete development tools, is sometimes called legacy software. Almost all businesses support at least a few legacy applications. Sometimes, a company's legacy software is limited to a few non-essential utilities used by a single department. At other times, the legacy application is a mission-critical application that must be kept running. Either way, at some point, you'll be asked to support a legacy application.
Here are some of the challenges you might encounter in supporting legacy applications:
Minimal, missing, or out-of-date documentation: Although documentation usually isn't the strong suit of most developers, the complexity of some legacy applications can be overwhelming. Newer development techniques favor simplicity and allow the code to be self-documenting. At the same time, more intelligent tools, such as Visual Studio 2010, can update modeling documentation to reflect changes made in the source code.
Components that are tightly coupled: A legacy application sometimes has dependencies on other software that can cause the application to crash. Components are considered tightly coupled when you can't separate them from each other. If the software is broken into pieces, those pieces, or components, can't be reused for other software. New applications must be created, which leads to the same logic being deployed in multiple applications.
The use of nonstandard protocols: Software that was developed before the creation of standards, such as XML, often use proprietary file formats and communications protocols. This situation makes it difficult for the software to interoperate with other software.
Spaghetti source code: The emphasis in coding hasn't always been on readability. As a result, programmers write programs that are cryptic and hard to understand. This can happen for two reasons. One, as you may expect, is from poor planning and a low skill level. The second, though, is because developers sometimes have to write code with limitations that are imposed upon them by situations, such as hardware limitations.
General deployment and maintenance difficulties: Many legacy applications were intended to be deployed in much simpler hardware configurations than the ones in use now. Software written in the mid- to late 1990s was probably never intended to be used over the Internet, for example.
You can, of course, find software developed by using all the latest tools and practices that have all these characteristics. However, developers who are paying attention to industry best practices and working with, rather than against, modern tools should find that they have to go out of their way to write bad software.
Software written with these drawbacks is monolithic. With a monolithic application, you can imagine the developer sitting down and writing one long piece of source code that does 25 different things. Although the software might work and be efficient, this approach is hard to maintain and scale.
Software developers now focus on
Readability: Writing software shouldn't be a contest to see how cryptic you can be. Today's approach favors a programming style that avoids shortcuts and abbreviations and instead uses an implementation designed to be transparent to future developers. This technique makes the code self-documenting because you don't have to write additional documentation that explains what the code does. One thing to note is that the compiler is very smart when it comes to optimizing the output. Most of the time, clearly understandable code compiles to the same thing that seemingly efficient but cryptic code compiles to.
Components: Breaking down software into discrete, manageable components is favored over creating one huge application. Components can be reused in some cases and are easier to deploy.
One reason why these changes have come about is that management has realized that hiring and retaining people is expensive. Even though modern tools and practices may be more verbose and require more processing power than legacy code, using modern tools and practices is acceptable because the power of hardware has increased relative to its price. Buying more hardware is cheaper than hiring additional developers.
Another reason why components have become more important is the expanded use of networking and the Internet. Developers found that by breaking applications into components that could be deployed across multiple servers and connected by a network, they could get around the monolithic applications that didn't run.
The 1990s approach to component-based design was most often implemented in a physical, two-tier architecture: In this client/server architecture, some part of the application resides on the client, and another part resides on the server. A network connects the client to the server. In most cases, the data resided on the server, while the program to access the data resided on the client.
As time went on, developers became craftier at carving up their applications to run on multiple servers. This approach is generally referred to as n-tier design because an application can have any number, or n number, of tiers.
In reality, most applications stick with a two- or three-tier design. The standard for many applications is a logical three-tier design that looks like this:
Presentation layer: The code for the graphical user interface
Business object layer: The code that deals with the logic for your business domain, such as customers and orders
Data access layer: The code that handles the process of moving data from the business objects into the data store, such as a database
One reason why this approach is popular is that it allows you to mix and match layers. Suppose that you create a business object layer that recognizes how your company manages its customers and orders. You can then create a Windows-based presentation layer and a Web-based presentation layer. Because all your business logic is specified only once in your business object layer, you have to maintain only one set of business objects. What's more, if you decide that users of smartphones need to be able to access your business object layer, you only have to create an additional presentation layer.
Contrast this approach with a monolithic application, in which you create separate applications for each user interface you need. You then have a Windows application, a Web-based application, and a third application for your smartphones. Each application has its own set of business logic for handling customers and orders. If you discover a bug or your business decides to changes its rules, you have to make changes in all three applications. With a tiered approach, the change is limited to your business object layer.
You still have to test your application before you roll it out. For example, you may need to modify the user interfaces so that they can handle a new field. Still, this technique is much preferred to having three sets of business logic.
You can implement this logical three-tier design in several ways in the physical world:
Two tiers: In this typical client/server model, the presentation and business object layers might reside on the client, while the data access layer resides on the server.
Three tiers: In this model, a different computer can host each layer.
More than three tiers: If any of the layers is especially complex or requires significant processing power, each layer can further be divided and implemented on multiple computers.
No tiers: If all the code resides on a single computer, it can be said to have one tier or no tiers.
The unit of deployment in .NET is an assembly. In an application with three tiers (physical, business, and data access), as described in the preceding section, each tier would likely have its own assembly. Of course, that's not to say you can have only one assembly per tier. Each tier can have as many assemblies as necessary to adequately organize the source code. The application may look something like Figure 3-1.
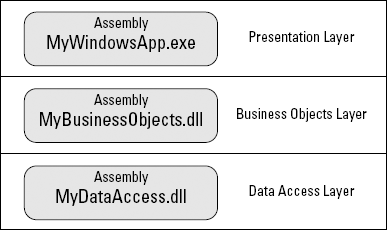
When an application is compiled, you can choose whether to compile it as an executable or a class library. In a three-tiered application, you might have the following assemblies:
MyWindowsApp.exe: The file you would execute on a client PC. The file contains all the code for the presentation layer. The presentation layer consumes code from the other two layers by creating a reference to that code.
MyBusinessObjects.dll: The class library that contains all the code for your business logic.
MyDataAccess.dll: Another class library that contains all the code for getting data to and from the data store.
The reason that the business objects and data access layers are compiled as class libraries and not as executables is to prevent users from executing the files directly. Because no user interface is in those layers, users have no reason to execute them directly. The assemblies are just libraries of code that you can reference from other code.
To use the code that's in the business objects or data access class libraries, you create a reference in the executable file of the presentation layer, as shown in Figure 3-2.
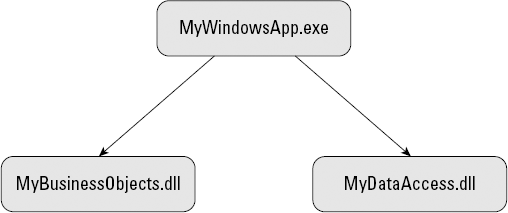
After you create a reference to the assembly, you can access the code inside the assembly. Suppose that MyBusinessObjects.dll contains code to get a customer's address. To display the customer's address on-screen in your application, however, the presentation layer must reference the MyBusinessObjects.dll so that .NET knows where to get the code that gets the customer's address. See Book IV, Chapter 3 to read about referencing a class library.
After the reference is created, your presentation layer can access the code, which might look something like this:
MyApp.MyBusinessObjects.Customer customer;
customer =
new MyApp.MyBusinessObjects.Customer("Smith, John");
MyDataList.DataSource = customer.GetCustomerAddress();The first line of this code asks that the Customer class in the MyBusinessObjects class library set aside some memory for the customer Smith, John. The code that asks the data record for Smith, John from the database is stored in the MyBusinessObjects class library. Herein lies the beauty of assemblies: You can use this logic to retrieve the customer information in any of the presentation layers you create. Figure 3-3 demonstrates how the presentation layer accesses the code in MyBusinessObjects.dll.

Note
In the real world, you'd probably use a customer identification number rather than the customer's name. What if the database had two entries for Smith, John? You'd need some way to deal with the inevitability of having two or more different customers with the same name.
The second line of code tells .NET to use the customer name Smith, John from the preceding line to call the code that retrieves the customer address. The code then assigns whatever value is returned to a data list, which presumably is used to display the customer's address onscreen.
All the software that makes up the .NET Framework Class Library is made up of assemblies. Microsoft created a special place to store all the assemblies for .NET called the Global Assembly Cache, or GAC. (Yes, it's pronounced gack.) The GAC stores all versions of an assembly in a folder on your computer. You can store the assemblies you create in the GAC folder or in an application folder. See Book VI, Chapter 2 for more information on installing applications in the GAC.
Before the GAC came along, developers had no easy way to manage the versions of an application, so many people began to refer to the deployment of Windows applications as DLL hell. This term reflected the fact that the files that contain the code libraries — DLL files — could quickly become your worst enemy if you realized that you didn't have the right version of the file you needed in order to make your application work.
Note
The term DLL hell was originally coined in an article entitled "The End of DLL Hell," which you can read at http://msdn2.microsoft.com/en-us/library/ms811694.aspx.
One hallmark of modern software development is the way software is executed on a computer. Previously, software deployment and execution worked like this:
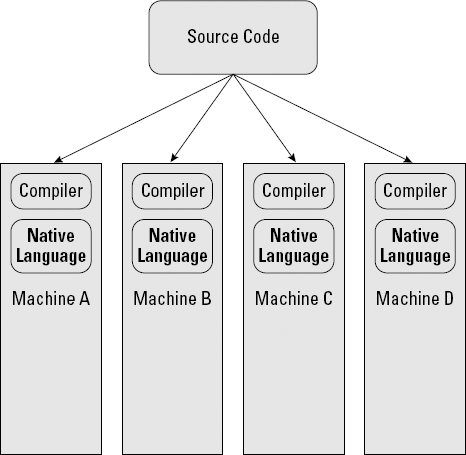
A programmer wrote source code, using some higher-level language, such as C# or Visual Basic.
Before the computer could understand the source code, it had to be compiled, or converted to the native language that the machine understands.
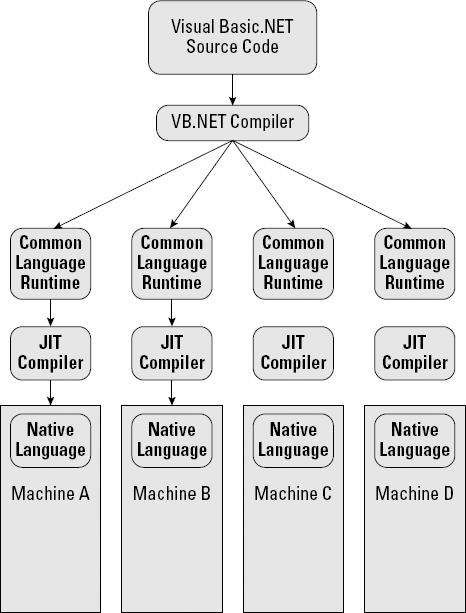
Because each kind of computer has its own native language, the code had to be compiled each time the programmer wanted to use it on a different kind of machine. There wasn't much compatibility between machines, so you often had to modify the existing source code to address the subtleties of the new hardware environment, as shown in Figure 3-4.
Because the code was converted to the native language of the machine, the code, when it was executed, had direct access to the operating system and the machine's hardware. This access not only made programming complex, but it also created an unstable operating environment.
Note
The compiled .NET code that the CLR (Common Language Runtime) consumes is known as managed code. That's different than native code. Native code compiles into something that the CPU can directly use. Managed code must undergo the just-in-time (JIT) process by the CLR before the CPU can use it.
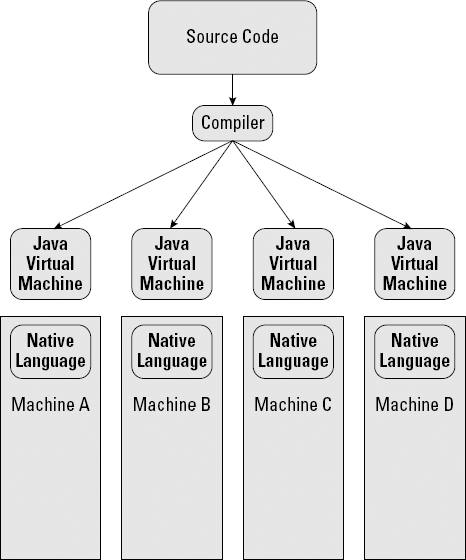
Back in the 1990s, the folks over at Sun had the bright idea of creating a programming language that could work on any machine. The Java Virtual Machine (JVM) that they built creates, on the hardware, a mini-environment that allows the software to be executed without touching the hardware, as shown in Figure 3-5. The JVM was smart enough to know how to make the software work with the hardware. Because of the resulting stable environment and simplified programming, Java was widely embraced.
Ever mindful of its competition, Microsoft sneaked a peek at the Sun JVM and liked what it saw. Over time, all the different Microsoft teams that were working on building development tools and languages started coalescing to work on their implementation of the virtual machine. The Microsoft .NET Framework was born.
The Microsoft version of the virtual machine is slightly different in implementation from Java, although they're similar conceptually. The virtual machine in .NET is the CLR. These steps show how using virtual machines changed the deployment and execution of software:
A programmer writes source code, using a higher-level language, such as Visual Basic .NET.
The VB.NET compiler converts the source code into Microsoft Intermediate Language (MSIL), which is the native language of the CLR virtual machine. Rather than convert the source code into the hardware's native machine language, the compiler creates intermediate code that the CLR understands. Source code compiled into MSIL is managed code.
Note
All language compilers that target the .NET CLR convert the source code into MSIL. Programmers can develop the source code using multiple programming languages, and the compiler can compile this code to create a single application.
The compiler also creates metadata about the source code. The metadata identifies to the CLR all the assemblies and other files that the source code needs in order to be executed properly. The CLR is responsible for resolving dependencies before the code is executed.
When the code's assembly is executed, it's compiled a second time from the MSIL into the native code for the hardware platform on which the code is being executed. This second compiler is the just-in-time (JIT) compiler because the MSIL code is compiled just before it's executed.
Note
When code is compiled by using the JIT compiler, the compiled code is stored in memory. If the code is used again, it doesn't have to be compiled again. Rather, the copy of the code that's in memory is used. When the execution is complete, the code is removed from memory. If the code is called again after being removed from memory, it must be compiled into native machine code again by the JIT compiler.
Managed code (code that runs in the CLR) is executed within the CLR virtual machine. As a result, the code doesn't have direct access to the hardware and operating system. The code is more stable and less likely to crash the system. To read more about the benefits of running code in the CLR virtual machine, see the sidebar "The CLR virtual machine."
Figure 3-6 diagrams how code is executed by using the CLR.
Note
The architecture used by the JVM and Microsoft .NET is part of an international standard for how software execution should be managed. The languages of .NET are expected to conform to the Common Language Specification. The CLR of .NET is the Microsoft implementation of the Common Language Infrastructure.
One big service of the .NET Framework is automatic memory management, or garbage collection. Microsoft didn't make up the term garbage collection — it's an authentic computer science term that applies to computer memory.
Before a computer program can use a resource, such as a database, the program must request that the computer set aside memory for the resource. After the program stops using the memory, the data stored in the memory is referred to as garbage because it's no longer useful. To reclaim the memory for another use, the CLR determines when it's no longer in use and disposes of it.
A garbage collector, such as the one in the .NET Framework, takes care of the business of asking for memory and then reclaiming it after the program is done using it. The garbage collector collects the garbage memory and then makes it available for use again.
Memory is used to store the resources a program needs to complete tasks, such as
The garbage collector frees the developer from having to perform these tasks:
Tracking how much memory is available and how much is used
Assigning memory to program resources
Releasing memory when resources are done using it
The garbage collector allows developers who are creating a program to focus on customers, orders, and other business domain entities, rather than on memory management. Using a garbage collector eliminates two common errors that developers make when they have to manage their own memory:
Forgetting to free memory: When a program doesn't release a computer's memory after the program's done using it, the memory is quickly filled with garbage and can't be used for useful tasks. This error is often called a memory leak. When a program runs out of memory, it crashes. What's worse is that memory leaks can cause other programs — and even your whole computer — to crash.
Trying to use memory that has already been freed: Another common error that developers make is trying to access a resource that has already been removed from memory. This situation can also cause a program to crash unless the developer makes the program test whether the resource is still available. A developer who forgets that the resource is freed probably won't remember to test the resource before trying to use it.
To prevent you from having to manage the memory yourself, the CLR allocates memory for program resources this way:
The CLR reserves a block of memory, which is the managed heap.
When you ask for resources, such as to open network connections or files, the CLR allocates memory for the resource from the managed heap.
The CLR notes that the block of memory is full so that it knows to use the next block of memory when you ask for a resource the next time.
Although you still have to tell the CLR that you need the resource, all the details about which memory addresses are occupied, as well as what they're occupied with, are handled by the CLR on your behalf.
This section describes how the CLR knows when to release the memory.
The CLR divides the memory in the managed heap logically into manageable pieces, or generations. The garbage collector (GC) uses three generations: 0, 1, and 2. The GC operates under the assumption that newly created objects will have shorter life spans than older objects.
Whenever you ask for a new resource, memory is allocated from the portion of the memory block designated as Generation 0. When Generation 0 runs out of memory, the GC starts a collection process that examines the resources in memory and frees anything it deems as garbage (anything that's unusable to the application). After freeing as much memory as possible, the GC compacts the memory so that all the remaining resources are placed next to each other in a neat stack. Compacting memory is something the developer doesn't have to do.
How do resources get into Generations 1 and 2? If the GC can't reclaim enough memory from Generation 0 to accommodate your new requests, it tries to move the resources from Generation 0 to Generation 1. If Generation 1 is full, the GC tries to move them to Generation 2. This process is how older resources that are still in use graduate through the generations.
Note
Garbage collection isn't something you should try to control—it happens automatically.
The GC doesn't know what to do with certain kinds of resources after it realizes that you aren't using them any more — for example, resources from the operating system when you work with files, windows, or network connections. .NET provides you with special methods — named Close, Finalize, and Dispose — that you can use to tell the GC what to do with these resources.
The vast majority of resources you use in .NET don't require you to release them. If you're unsure whether you should make method calls before you're completely done with an object, go ahead and call the Close, Finalize, or Dispose method while the object is still in scope. See Book V, Chapter 3 to get the skinny on how to use methods such as Finalize.
Garbage collection isn't unique to .NET. Java also provides garbage-collection services to its developers. Read the article that describes how garbage collection works in Java at www.javaworld.com/javaworld/jw-08-1996/jw-08-gc.html.
You'll find that the process is remarkably similar to garbage collection in .NET.