
Focusing XML and DM on Enterprise Application Integration (EAI)
Introduction
Enterprise Application Integration, or EAI, is yet another one of those buzzwords that we in technology have heard repeatedly over the years. Everyone was going to work on large EAI projects that would yield astounding results. A number of promises were made about EAI, but the end products were decidedly mixed. As with many ideas and technologies, ultimately the benefit derived is closely related to the way in which the idea is implemented. Throughout this book, we have talked about the importance of good data management as part of an XML-based approach to a problem. This chapter will continue along those lines with a discussion of the way EAI and XML work together, the pitfalls that others have encountered in the past, and what data managers can do to avoid those problems.
Even if EAI has been over-hyped in the past, it is still an important topic for a number of reasons.
1. As many systems develop along different paths over the life of an organization, the need to integrate those different sources of information and functionality becomes inevitable.
2. EAI is frequently found as a component of reengineering efforts. Reengineering is an attempt to realign existing resources more efficiently, and changing the way things communicate and the results of that communication typically requires EAI work.
3. Since the amount of money spent on integration in the past has been so substantial, it is worth looking into more efficient technology to reduce the total expenditure necessary to connect systems within an organization.
Let us also look at a few key points that we can call the “IT Facts of Life,” since they are relevant to the discussion of EAI in this chapter, and many other situations as well:
![]() No single vendor can provide all of the products and services to run an organization. This is intuitive, since vendors necessarily have to develop generic software that will run for many clients, and that does not take into account the specific challenges of a particular organization.
No single vendor can provide all of the products and services to run an organization. This is intuitive, since vendors necessarily have to develop generic software that will run for many clients, and that does not take into account the specific challenges of a particular organization.
![]() Technologists are frequently left with the task of cobbling together solutions from many different packages.
Technologists are frequently left with the task of cobbling together solutions from many different packages.
![]() Companies are increasingly unprepared to effectively integrate as they shed in-house developers. For cost reasons, development often moves out of the organization, ultimately meaning that integration work must be done by external sources that know little about internal systems and integration needs.
Companies are increasingly unprepared to effectively integrate as they shed in-house developers. For cost reasons, development often moves out of the organization, ultimately meaning that integration work must be done by external sources that know little about internal systems and integration needs.
![]() Buying more COTS (commercial off-the-shelf) software packages increases the dependence on software vendors and their support.
Buying more COTS (commercial off-the-shelf) software packages increases the dependence on software vendors and their support.
![]() The integration work being done is crucial. If links between the warehouse operation and the financial system break down, the ability to move goods and close out the books grinds to a halt. Many large companies have recently found that the inability to master links between complicated software packages can put their survival at risk.
The integration work being done is crucial. If links between the warehouse operation and the financial system break down, the ability to move goods and close out the books grinds to a halt. Many large companies have recently found that the inability to master links between complicated software packages can put their survival at risk.
The process of integrating systems and applications frequently involves shuttling complex data back and forth between various systems. While XML was not developed specifically as a technology to aid EAI, its utility within the field rapidly became apparent as developers of new EAI systems and ideas looked around for existing components with which to build. The flexibility, extensibility, and semantic richness possible with XML made it a natural choice as a vital part of the overall EAI picture.
Traditional EAI approaches create a message bus between two applications, and then spend a lot of time and energy focusing on the low-level technical aspects of putting messages onto that bus, and decoding them on the other end. That type of drudgery is precisely one of the areas where XML can help the most. Where the previous technical solutions were specific to the integrated applications, XML provides a framework that can be evolved to fit the needs of new data syntax and semantics.
Some of the first adopters of EAI were those who had large main-frames and who needed to move data to client/server applications. Perhaps the mainframe would house the authoritative source of information, while other machines would serve it up in different formats for various purposes. This tended to create point-to-point interfaces between all of the applications that were not always the same. In extreme situations, if there were 10 systems within an organization, there would be 10 corresponding applications, all of which had to be separately maintained and whose job it was to move data from the central mainframe to the systems surrounding it. In Figure 8.1, we see an example of this type of integration, with data being moved back and forth from a mainframe system using IMS and CICS to Lotus Notes.

More recently, when people refer to EAI, they are often talking about various toolkits and approaches commonly used to build EAI solutions. Specifically, the Distributed Component Object Model (DCOM) and the Common Object Request Broker Architecture (CORBA) have been the popular technologies used to integrate applications. While these technologies certainly have their place, they have tended to focus attention on the wrong level of integration. Many organizations have successfully put EAI solutions in place using DCOM or CORBA. On the other hand, others have put something in place only to find that it is brittle, difficult to maintain, and limited in functionality. Certainly there are some positive aspects to these technologies; for one, they encourage building connections in a hub-and-spoke model as opposed to a point-to-point model, and they put in place the basics of a common metadata model that is so important to this work. Still, the reality of implementation did not live up to the hype of the idea.
One of the drawbacks of the DCOM and CORBA approaches to EAI has to do with the way those technologies are structured. Both based on the object-oriented programming paradigm, they tend to suggest a pairing of data structures with functionality that may or may not accurately represent the way the data was stored. Since object-oriented development involves designing data packages (objects) with their associated operations, it is easy to see that the way data was represented within a CORBA-or DCOM-based application might be radically different from the way the source or target systems dealt with the data.
This creates another mapping and interfacing problem. Now, not only must the EAI solution move data from one application to another, it must first figure out how to move the source data into its own transport format, and then back out again once it arrives at its destination. Converting nonnormalized mainframe-based flat files into dynamic CORBA objects can be quite a challenge. While this is appropriate in some instances, in others it has created a situation where developers were forced to pound a square peg (the source data) into a round hole (the object model and design of a CORBA-based EAI solution). Add to this problem the fact that most programmers doing this work are not trained in data design to begin with, and cost overruns paired with less-than-desired functionality start to become more understandable.
This often created the strange situation in which the EAI solution in question just sent data from one application to another, without much logic or processing in the middle. The result was that some EAI solutions ended up reinventing the wheel, doing something with complex and expensive software that could have been accomplished with an existing technology such as automated FTP, or secure copy.
For example, this type of middleware might have been used to send payroll data to the personnel department, and then shuttle personnel department data back the other way. In effect, this was an automation of flat-file transfer that might have been more appropriate for a simpler technology. The reason that these situations arose is that the data managers in question did not know what they needed in order to do the job correctly. The problem was not only that the simple functionality might have been better implemented with other technologies, but also that a large amount of opportunity was missed since data-engineering concepts were not applied throughout the process.
Figure 8.2 illustrates the topological complexities of the EAI game. Requirements are expressed in terms of point-to-point connectivity. Certain data sources must connect with other sources using specifically developed and maintained point-to-point connections. As an illustration, Figure 8.2 works at multiple levels that we will label as micro, mid, and macro.

![]() On the micro level, the application architecture would dictate that the applications shown in the figure would instead be sub-routines passing data back and forth. An ERP software package would be an easy-to-visualize example of this type of point-to-point connectivity below the application level.
On the micro level, the application architecture would dictate that the applications shown in the figure would instead be sub-routines passing data back and forth. An ERP software package would be an easy-to-visualize example of this type of point-to-point connectivity below the application level.
![]() One the mid level, the separate application programs communicate with each other. A good example of this is just about any environment within a mid-sized or larger organization, for example, a payroll system communicating with a human resources system.
One the mid level, the separate application programs communicate with each other. A good example of this is just about any environment within a mid-sized or larger organization, for example, a payroll system communicating with a human resources system.
![]() One the macro level, the systems connect with each other across organizational boundaries. For example, take a common situation where payroll is outsourced, and data has to flow over lines into and out of the company.
One the macro level, the systems connect with each other across organizational boundaries. For example, take a common situation where payroll is outsourced, and data has to flow over lines into and out of the company.
What Is It About XML That Supports EAI?
Effective EAI requires semantic information about the data structures that are being moved back and forth. We have seen examples in previous sections of why it is beneficial to use data structures rather than data fields, and why semantics are important. XML supports EAI in that it provides metadata along with the actual data that is being sent, and allows the semantics that are so critical to the process to move right along with the data.
Frequently, when data managers ask their workers for the first time if they are using XML or not, they are surprised to find that its use is widespread. This turns out to be the case even if XML was not officially sanctioned within the organization. The next step in finding out how XML may already be used inside the organization is the discovery that two different groups have created two different sets of labels for various data items that must be reconciled if either is to be used. The good news is that not all of this effort will have been wasted. The syntax and semantics of tags can be translated back and forth to allow this reconciliation to occur. Just as this process can be used to take advantage of preexisting XML work, it is also possible to use it in EAI.
Flexibility and Structure
Technology is constantly moving and changing, and whatever EAI solution is put in place must have maximal flexibility to evolve along with the systems that it supports, so that when the inevitable change happens, the solution can adapt. For example, when data structures and semantics in one of the two applications begin to change, suddenly there is a need to translate that semantic difference between the two systems. Using purely technical approaches that only shuffle data back and forth, semantic translation is very difficult because the information is not aggregated at that level to begin with, and there is no additional contextual data about the structure. Rather than having information on an employee, the system might only have a bunch of strings labeled “first name,” “last name,” or “title.”
When EAI is developed using XML as the lingua franca, XML’s power can be used to refine things, even to the point of changing underlying semantics, within reason. Some elements of EAI implementation are ultimately going to be done right, while others will be done wrong. Looking to the future, putting in place a structure that is malleable, and that the organization is not permanently married to, will create cost savings right away, as well as down the line when the inevitable change becomes reality. Aspects of change, flexibility, and metadata malleability are the strategic applications of XML within the area of EAI. Next, we will take a look at the specific technical components of XML most frequently used in EAI.
From a more technical perspective, XML has two main “branches” that are most frequently used in EAI. The first we will call “XML Messaging,” and the second we will call “Domain-Specific Languages.” In Figure 8.3, these two branches are shown along with common examples of specific technology components.

XML Messaging
For projects that are more focused on loose integration of systems, typically what is needed is something of an XML messaging bus, across which data is sent to and from the various systems. From this perspective, XML can provide a facility at a technically low level for getting data back and forth. The actual data interchange format is XML, and the transport protocols and associated technologies are those that have sprung up around XML. The examples of these seen in Figure 8.3 are XML-RPC (Remote Procedure Calls), SOAP, WSDL, UDDI, and ebXML. In these situations, the total solution is bound to be a mix of XML, the use of TCP/IP communication, and various pre-fabricated software components on either end that handle the connection and interpretation details of XML.
Figure 8.4 shows one possible representation of the common use of XML messaging in EAI. In the center of the diagram, there are various cubes stacked on top of one another, representing aspects of applications and systems that need to be integrated. Surrounding the entire cube is an XML messaging bus that can take information from various components and transport it to others. The third aspect of this diagram is the external object-based components. Frequently in XML messaging situations, it is possible to take common bits of functionality out of the applications and systems being integrated and put them inside object-based components, which are then reused by attaching them to the XML messaging bus. Rather than having functionality duplicated in multiple systems, these components can communicate with any system via the XML messaging bus. In this situation, XML provides a common way for system components and applications to communicate, while reducing the duplication of functionality in different applications represented by those common components.

Domain-Specific Languages
Domain-Specific Languages are ready-made XML languages that come with a set of definitions and a metadata model. These languages are also known as industry vocabularies. They are popular in XML-based EAI work because they present mature solutions to problems that data managers encounter. The examples listed in Figure 8.3 cover the areas of chemicals, mathematical formulas, and news releases, but there are many other accepted vocabulary standards available in just about every area imaginable.
To understand why domain-specific languages are attractive for XML EAI work, let us examine the situation of a media company that needs to distribute documents such as press releases. After being created in a particular application, these press releases are put into systems that distribute them via web sites and other mediums. The data manager is presented with a situation in which an EAI solution must be created to connect the publishing and distribution applications. Rather than going through the lengthy process of developing a common metadata model for the data that must be transmitted, he or she can use ready-made XML components such as RDF and NewsML to do the representational work. The use of these languages has several key advantages:
1. Using a domain-specific language obviates the need for an organization to develop its own XML component serving the same purpose. The readily available components prevent having to “reinvent the wheel.”
2. Since the languages are already peer-reviewed and mature, they come with a pre-identified set of advantages and pitfalls. Data managers can make their decisions based on the requirements, rather than the hypothetical good and bad points of something they might develop themselves.
3. The fact that these languages are also used elsewhere aids further integration down the line. Tools already exist that understand standard domain-specific languages, while there is no existing software support for home-brewed XML languages that are specific to one or two EAI solutions.
Given these advantages, it is easy to see why preexisting XML components are attractive for integration work. Using them in concert with XML-messaging technologies is a solid instance of the cardinal IT rule—”Work smarter, not harder.”
The Pundits Speak
Many different writers in the business media have also addressed the potential benefits of XML in EAI environments. We have taken a few of their perspectives and presented them here to provide different angles on the discussion. Frank Coyle of the Cutter Consortium made reference to the older, object-based models and to the XML messaging-bus concepts we have covered when he said,
XML is revolutionizing distributed computing by providing an alternative to the object-based models of CORBA, RMI, and DCOM. XML in combination with HTTP opens the door to making remote procedure calls (RPCs) using the same basic web technology used to pass HTML data across the web. [This] simple but profound concept has revolutionized the distributed computing landscape and forced a rethinking of distributed protocols.*
We also present statements, made as part of a Gartner Group report from October of 2000, related to XML:
XML represents a critical future direction for the management of metadata, data, [and] business rules and will play an increasingly important role in business and systems engineering…. Loosely coupled, asynchronous XML messaging infrastructures will dominate as the mode of communication for B2B integration. †
EAI Basics
Integration means different things to different people. The dictionary definition of integration tells us that it means to “join or unite” two things, or to make part of a larger unit. For our purposes, there are two different levels of integration that have very different characteristics.
1. Loosely coupled integration. This is the process of interconnecting two applications, and allowing for communication between the two. It is a cheaper and less complex level of integration that typically moves slowly and is error prone. Errors occur in loose integration because the two applications are different and only communicate for mutual convenience—they may have radically different ideas about what some pieces of data or processes mean. Applications are typically loosely integrated when they retain a degree of independence, but occasionally work together.
2. Tightly coupled integration. This is integration in its truest sense—two applications that are built using the same technologies and a common metadata model. This tends to be far morecomplex. One might say that this integration is the point at which the two applications have more similarities than they do differences. The functionality need not be similar, but the mode of operation, data concepts, and semantics are the same. Two applications are tightly integrated when each of their individual processing is dependent on the other.
It is important to note that tight integration is initially more expensive than loose integration. The initial investment has to do with thoroughly understanding and reconciling the data structures of the applications that are being integrated. In the loose-integration scenario, two applications with different data structures can only be integrated by creating a third data structure that maps between the two.
Like most other distinctions, the polar states of loose integration or extremely tight integration ultimately have many shades of gray between them. Regardless of which point in the continuum is ultimately chosen for a particular situation, it is important to have the two opposites in mind, along with their relative advantages and disadvantages. This perspective helps to identify which problems in EAI solutions come as a result of the architectural decisions, and which can be more immediately addressed. Now that we have seen the two extremes, we will take a brief look at the different components of an EAI solution, regardless of how tight or loose the integration is.
EAI Components
One of the most common factors that determines if IT projects succeed or fail is whether or not the project takes into account all of the different facets of what needs to be done. For example, some projects take a strictly technical approach, ignoring the data-architecture portion of the project, and end up with a corresponding set of drawbacks. In other situations, project teams become enamored of specific technical solutions and miss the larger context that the solution needs to operate within.
Figure 8.5 displays the three critical components that need to be considered in order to deliver successful EAI solutions. While it is possible to deliver a solution without considering all three aspects, such systems often are delivered either over budget, past deadline, with less than expected functionality, or all of the above.

1. Application Architecture. The Application Architecture component of an EAI solution takes into account the “style” and approach of the solution. Will the solution be client-server based? Will it be built in an object-oriented way? With a fourth-generation programming language? How will the application be put together, and how does it logically attack the core issues of the problem it is trying to solve?
2. The Technical Architecture. This component is the one that project teams often spend too much time considering. The technical architecture deals with questions of what operating systems, hardware, platform, and network facilities will be used. It also encompasses a host of other non-software, non—data-related system and infrastructure questions. Technical facilities are the bricks that are used to build larger systems. While care should be taken to make sure that the right bricks are selected, the form and characteristics of the brick definitely should not dictate how the finished building or solution will be created.
3. The Data Architecture. This component is typically the one that too little time is spent considering. The data architecture component of an EAI solution addresses issues of which data structures will be used, which access methods will be employed, and how data is coordinated throughout the system.
Throughout this chapter, XML is discussed particularly as it applies to the data architecture component of EAI above. Traditionally, when building systems that were focused around the use of toolkits like DCOM and CORBA, the most focus was put on the application architecture component. XML encourages architects to take a hard look at their data architecture through the facilities that XML provides, and to spend the appropriate amount of time in each area. For an EAI project to be a true success, focus is needed in each of the areas, rather than skewing analysis to one particular part of the picture.
The difficulty here is that focusing on three different areas requires three different sets of expertise. IT and systems infrastructure people are best suited to deal with the technical architecture; programmers and program architects are best equipped for the application architecture component; while data managers are in the best position to take care of the data architecture. Given these three areas of expertise, data managers still seem to be the ones who end up leading these efforts, for several reasons. Data managers typically have a higher-level view of the business and its technology needs, since they coordinate data resources in many different places. They also are often better suited to understanding the issues of integration that frequently come down to sticky data architecture questions.
These components come together to form the basis for technically effective EAI—in other words, an EAI system that delivers what was promised in the way of system integration. There are other definitions of a successful EAI system, however, particularly from the business and financial perspectives. In the next section, we will take a look at the motivation for why businesses want to approach EAI in the first place, and what financial incentives and pitfalls surround its use.
EAI Motivation
Despite some EAI promises that have not panned out, interest remains high and continues to grow. This is because data managers and their respective organizations are just now starting to measure how much lack of effective integration is costing them. In the past, data managers have frequently been aware of the consequences of poor or non–existent integration, but have not been able to make the business case to fix it, lacking solid numbers. This short section is intended to give data managers the ammunition they need to make just this case.
According to John Zachman, organizations spend between 20%and 40% of their IT budgets evolving their data.* Other sources say that 80% of data warehouse development costs are spent configuring the extraction, transformation, and loading (ETL) aspects of the warehouse. This includes three key components:
1. Data migration, or moving data from one system or application to another
2. Data conversion, or moving data from one format to another
3. Data scrubbing, or the process of comprehensively inspecting and manipulating data into another form or state for subsequent use
This data evolution in many cases is not adding additional value; the data is simply being changed or moved to fit the peculiarities or specifics of another place in order to add value down the line. That these activities take up 20% to 40% of IT budgets means that they are an area to focus on in search of savings. In fact, all of these activities are heavily involved in the process of EAI, and reducing expenditures on them ultimately means saving on IT.
In Figure 8.6, taken from a Gartner Group survey report, we can see the breakdown of IT spending by activity and function in 1999 and 2000. Typically, EAI costs will fall into the first three categories: new development, major enhancements, and applications support, as well as the last two: administration and IT planning, and “other.” All together, these represent more than 40% of IT spending. While there are other activities funded by these categories, it is typical to see the support and evolution of less-than-adequate EAI solutions eating up a good portion of the budget. This is one perspective on the different cost areas involved in EAI and their associated allotments. Another perspective would be to look at how much money will be spent across all industries on integration within a particular year.

In Figure 8.7, we can see that the total market for integration technology will grow from an estimated $1 billion in 2003 to $9 billion or more by the year 2008. With the importance of EAI within organizations and the amount of money being spent, it is worthwhile to take a hard look at the cost effectiveness and functionality of existing systems. EAI can become a component critical to keeping an organization running. Older systems built without the benefit of a data engineering perspective typically cost quite a bit more to maintain, just as a rental car company will spend more to maintain a fleet of older vehicles. One key to getting the maximal return out of an investment is minimizing the recurring maintenance costs that eat away at the savings the system should be providing in the first place. The economics of XML are such that this technology will appeal to small and mid-size organizations as well as large ones.

Figure 8.7 Total market for integration. (Taken from International Data Corporation’s DM Review, 8/2001.)
Typically, when data managers successfully sell EAI projects internally, it is based on standard return on investment calculations, like many other business decisions. Specifically, the investment can be justified by demonstrating that the proposed system has a lower maintenance cost, and that the difference between the current maintenance cost and that of the proposed system is enough to recoup the cost of the project within a particular time frame. In the past, organizations have not made much of an attempt to show a return on investment related to EAI. With figures related to how much is spent maintaining existing systems internally, data managers can make a financial case for their ideas as well as a technical and functional case. In business, new things are done for three core reasons:
1. The new way costs less than the old way. Given current EAI expenditures, this case can now be made.
2. The new way can do something that the old way could not. Combining EAI with XML opens up a multitude of new possibilities.
3. The new way does something faster than the old way. Reusing XML data structures in EAI systems allows proposed systems to be put together more quickly than their predecessors.
EAI implementation should not be done simply for its own sake, though. The best approach is to pick an area where the organization is experiencing quite a bit of pain, either financially or functionally, and attempt to find a solution. Often these solutions may take the form of EAI, since making the most of existing resources frequently means piping the output of one application or process into the input of another to provide more functionality. This piping is integration work focusing on coupling components more tightly–in other words, everything that EAI is about.
The major pitfall to avoid is creating a solution that is primarily focused on the technical level. Certainly the technical aspects of how integration is accomplished are important, but they should not drive the architecture and design of the solution. The real reason why EAI is needed rarely has anything to do with data formatting or transport details. Rather, the motivation is more at a semantic level: the meaningful outputs of one application need to be communicated to another to continue the value chain. When organizations focus on the semantic aspects of their EAI investments, the true expressive power of XML begins to shine through, and it distinguishes itself from other technologies.
EAI Past and Current Focus
The earliest authoritative academic definition appears to have been from 1992, and it stated that EAI was about “improving the overall performance of large, complex systems in areas such as
Enterprise integration efforts seek to achieve improvements by facilitating the interaction among: Organizations, Individuals, and Systems” (Petrie, 1992).
As we have briefly addressed earlier in the chapter, the past focus on EAI has been at a rather low level technically. The questions EAI has been used to address have involved, for example, how to make an SQL server instance talk to CICS, or how to connect a Power Builder application with another program running on the company’s mainframe. While those are important areas, they have tended to redirect focus from important issues of data semantics toward issues of data syntax. Technical integration of different products can often be accomplished either with ready-made tools that come with those products or with drop-in components.
It is vital that the semantic issues that prompted the integration effort play a primary role in the architecture of the solution. Too often, organizations build an extremely competent and technically sound EAI solution, only to spend the rest of their time doing technical acrobatics to make it actually accomplish what they want. The construction of an approach should be focused on the data structure level and the semantic level of the issue at hand. If a solution is based on a great way to transmit individual fields back and forth between applications, another layer of work must be done to package together various fields in some way that the solution can handle so that entire structures can be sent back and forth. What we are suggesting here is simply this: the form of the solution should follow the form of the problem; moving semantic data structures rather than building the solution based on the form of the source and the target systems.
Let us take a look at the difference between focus on the semantic and syntactic levels for EAI solutions. In order to illustrate more clearly why the semantic approach is important, we will use a very typical EAI example—an organization needs to move data from a personnel application to the payroll application.
In Figure 8.8, we see the syntactic and technical approach to EAI. A solution has been built that allows us to move data fields flawlessly from application to application. In this case, we are transmitting the information about a particular employee to the payroll application. The data moves through just fine, and once the individual fields arrive in the target system, they are reassembled into a complete picture of the employee including first name, last name, and title. This is like creating the idea of an employee in the other system by breaking it down into individual components like bricks, sending them through, and assembling those bricks into the complete brick wall or brick house on the other end. Certainly this approach will work, but the drawback is that effort and time must be spent on exactly how to construct the individual bricks, and how to put them together into a complete brick house on the other end. In addition, ach individual piece of data was properly transmitted and understood. The target system must also make sense of the actual items coming across the line, particularly in the common situation where its definition of employee may be different.

By contrast, in Figure 8.9, we see an example of a complete data structure being moved from the source system to the target system. Rather than sending individual snippets of data or XML, a complete XML document is sent that describes all that we want to communicate to the target system—an employee record. It is accomplished in one step, since the target system need only acknowledge the proper receipt of the data it was sent. There is no disassembly work done on the source side, and there is no reassembly work done on the target side. The associated errors that are possible as part of those processes are correspondingly eliminated.

The technical approach to EAI is focused on getting the bits and the bytes of EAI correct, at the expense of meaning and the purpose. After all, the point of this example is that the organization does not simply want to properly transmit first names, last names, titles, or strings of characters. It needs to transmit information properly about an entire employee. Using a data-structure perspective rather than a data field perspective allows the form of the solution to be dictated by what the organization is trying to accomplish, rather than the technical details of what types of strings a particular application can accept.
Generalized Approach to Integration
Each model (tightly coupled applications and loosely coupled applications) has costs and benefits when integrating with internal or external applications. Both types can include XML as a data format, but the tightly coupled model does not exploit all its advantages. Tightly coupled applications are designed to operate in tandem and to receive and send data while providing the highest performance and least latency when linking applications. Organizations that rely on tightly coupled applications must typically account for any future changes to application or data and create upfront agreements that applications use when communicating. Practically speaking, this means either purchasing the same application or codeveloping applications with partner enterprises. These inherent rigidities may not allow an enterprise to take advantage of the free flow of e-commerce.
Messaging technologies enable loosely coupled architectures. In loosely coupled architectures, applications are designed to accommodate XML and can make sense of “data on the fly.” Of course, since the exact shape of the data cannot always be controlled, as the initial enforcement of business rules and validation of data might take place outside of an application’s context, an application must include logic for accepting data that is perhaps not complete or contains too much information.
Resource Efficiencies
EAI should not be approached as something to be used because of industry trends, or even because this book told you that XML can help the process. It should be used because it will make an organization more efficient and nimble.
Do not approach EAI as “We need to do this.” Just ask yourself, “What needs to be fixed?” Then make the business case, and go after the solution. What we are trying to achieve is resource efficiencies. If it takes 14 people to do maintenance, then we want to do the same job with fewer people, based on the EAI solution. This perspective should permeate data manager’s thinking about EAI. Further, focusing on returns tends to make people less susceptible to the claim of the silver-bullet, solve-everything magic solution.
Engineering-Based Approach
Based on the lessons of the past and what data managers now know about EAI, tacking another letter onto the acronym—EAIE, or Enterprise Application Integration Engineering—refers to the new flavor of how these solutions are being created. The approach is to use the data-engineering principles that are discussed throughout this book as a core part of the development process, rather than an add-on at the end if budgeting allows. Within EAIE (sometimes pronounced “aieeeeeeee!” as a shrill cry of anguish at yet another acronym), the use of common metadata models is important.
Rather than viewing an EAI project as an island unto itself, work that was done on either of the systems being connected should be brought into the picture. The effort that was put into previous system projects should act as a solid foundation for the subsequent work of integrating those systems. Instead of looking at EAI as a simple connection between two things, it should be viewed within the context of the larger business systems network within an organization, and as such should be coordinated and planned like other organization-wide IT initiatives. This process requires involvement from data-management groups and architectural groups, in addition to the direct business users of the two systems being integrated, and the technical workers developing the solution.
One perceptual pitfall of EAIE to keep in mind is that since it is done at a high level, looking at a particular EAI solution as part of a larger architecture, people figure that this work will be accomplished in one big piece. The thought process is that if the scope is expanded, all of the organization’s problems can be solved within one project. While it’s tempting to think this, it is important to avoid anything that does not produce benefits within one calendar year. This effectively forces organizations to look only at the areas of biggest need, and to focus on addressing those issues while preparing for the solution. It is this prudence and occasional bit of restraint that prevents organizations from catching on to a new fad and implementing it everywhere. Too often in those situations, organizations find at a later point that technological developments have made their investment less valuable than previously expected, or that their grand unified solution might not have addressed requirements that a more step-wise process would have uncovered. Take the lesson from the Oracle CPG example (presented in the next sections), and slow down.
So how do effective EAI solutions get built? Figure 8.10 shows the typical process of developing successful EAI architectural components—or how to make sure that any particular EAI effort fits in with the overall architecture. There are two key things to note about this diagram. First, the main input of the entire process in the upper left-hand corner is the organizational strategy. Second, the output of the process is an architecture component. The characteristics of these components are that they are well understood, they are reusable, and they take into account the business requirements from the start.

Using the EAIE approach, solutions may be built in a component manner like good software. EAI should not be like a freestanding house or edifice, but rather a solid brick wall, the construction of which can be easily duplicated in other places. The resulting components can then be appropriately assembled into larger system structures, while architects oversee the process, ensuring that everything falls into its proper place.
Key Factor: Scalability = EAI Success
One last very important concept that needs to be included in the discussion of EAI and XML is the technology’s inherent scalability. While XML’s scalability is useful in a number of different ways, its contributions to EAI-and in particular, EAI project and implementation scalability—are of particular note. EAI projects must prove themselves against negative perception. The ability to “XML-ize” applications and systems in small but meaningful ways is of critical importance to data managers.
Scalability can occur first in the project scope dimension—that is, how many data items and how much data are you going to try to cover with the XML vocabulary? Let us return to the example shown in Figure 8.11, presented earlier in this chapter, of wrapping the data in XML to facilitate interchange. The first part of the project might wrap only a portion of finance data and the payroll data to address a particularly thorny problem surrounding the management of cash flow around pay dates. The first XML components would be implemented to wrap just the targeted finance and payroll data. In the diagram below, when we mention “parser” we are referring to a software component that allows access to the data in the XML. The logic of what happens with that data of course depends on the application and system.

Once the organization has successfully implemented the first phase, it can then decide to scale the project in one of two ways: by adding more data items or by adding new parsers. Adding more data items—expanding the organization’s XML vocabulary—can be done on a currently unwrapped set of data items without building new capabilities. Adding more parsers to the mix by, for example, enabling the personnel data, will increase the scope of the EAI effort to previously un-integrated data. Having this amount of flexibility gives integration specialists more feasible options when planning these complex tasks.
The key to successfully engineering XML-based EAI projects is to select the right-sized “chunks” to “XML-ize.” If the chunk is too small, then results will be difficult to demonstrate. On the other hand, if the chunk is too large, you will have difficulty achieving those results. In some instances, it will be necessary to achieve data understanding at the third normal form level in order to implement a syntactically correct XML-based vocabulary and associated dialects. This is not to say that the XML data structures will be normalized in the way that relational structures are (which rarely happens), but simply that the data must be understood and well structured.
Somewhere in between the two extremes are a series of chunk-sized EAI projects that will complement existing integration efforts. The key for your effort to be successful is to define projects that are of the right size and scope, that are technically feasible, and that can be scaled up to build on success. The technological feasibility determination will require a good understanding of the tools and technologies described in the Data-Management Technologies chapter.
EAI Challenges
In order to understand what works about EAI, it is helpful to take a look at what has been difficult—the integration requirements. In this section, we will examine an example of a well-studied EAI failure, and learn its lessons of complexity and scope (Koch, 2001). By the way, our intention is not to pick on Oracle as used in this illustration. All big vendors have made similar miscalculations (recall IBM’s AD/Cycle?), and we use the public Oracle example to avoid nondisclosure agreement–related issues. In 1996, part of Oracle’s vision was their concept of Oracle CPG, or Consumer Packaged Goods.

This vision promised to integrate four completely different packages from different vendors into a seamless whole. The packages that were being dealt with were:
1. Oracle’s own Enterprise Resource Planning (ERP) software
2. Indus’s Enterprise Asset Management package
Consumer Packaged Goods companies manufacture and distribute just about anything that one might find on a grocery store shelf. The integration effort promised to run all aspects of CPG companies’ businesses, handling everything from estimating future product demand to manufacturing scheduling and delivery of the product. In addition, Oracle pledged to take responsibility for the support and integration of the various software packages within the overall vision.
Kellogg was chosen to be the first customer and featured user, or “poster child,” of the Oracle CPG effort, and stood to gain quite a bit if the system worked as promised. According to various sources, Kellogg spent over $10 million on the project, devoting more than 30 programmers and 3 years of time to Oracle to help them develop the CPG product. Assuming a cost of at least $60,000 per year for a full-time programmer, 30 programmers for 3 years comes out to $5.4 million in salary expenses alone. It is unclear whether that expense was figured into the $10 million price tag on the project. This also does not account for what Oracle spent on similar work as part of the venture. In return for this investment, Kellogg expected to be able to influence the CPG system’s features in order to aid their specific objectives.
The results were mixed. Despite Oracle’s statement to the contrary, some former customers claim that Oracle failed to finish CPG, and that failure cost the customers millions.
As part of this effort, Oracle had purchased Datalogix, and rewritten parts of this software to fit with Oracle’s own technology and data model. Other pieces, however, were not integrated to become a single product. Instead, Oracle and CPG partners wrote software interfaces to translate information among the various CPG components. While this was cheaper and less complex than tight integration in the short term, the integration was very prone to error and ended up moving information more slowly than true integration would have. With more than 100 interfaces tied together with high levels of complexity, problems cropped up without end, and CPG release deadlines were missed.
What the CPG debacle demonstrates with frightening clarity is that the task of getting a host of different vendors to integrate complex software programs to the level that Oracle aspired to with CPG is more than difficult—it is impossible. “If you had to point a finger at the root of the problem, it was the integration,” says Boulanger. “They could never get the different systems to talk to each other adequately. It was like trying to tie them together with bailing wire.” “It’s impossible to try to integrate four pieces like that from different vendors into a single product,” agrees Barry Wilderman, a vice president for Stamford, Connecticut–based Meta Group (Koch 2001).
Now that we have seen some of the potential consequences of EAI integration challenges, as well as Oracle’s particular approach to its situation, what lessons can we take from this failure to prevent the same from happening elsewhere?
Lesson One: All About Data Integration
Rather than focusing on tight integration and creating similarities between the different software packages that made integration natural, Oracle focused on creating a complicated set of communication links between the software. This is a typical approach taken in loose integration efforts, where communication between software packages is all that is desired, no matter how dissimilar they are. No common data model was developed, and there does not seem to be any evidence that effort was put in at the data structure level. The focus was simply on getting data from place to place between the applications.
The way this pitfall can be avoided is by planning out an integration effort thoroughly before beginning, and focusing on integrating applications as tightly as the time and budget will realistically allow. To determine whether loose or tight integration is more appropriate, try asking a simple question: Which is preferable, two systems that act as two arms of a unified approach to a problem, or two systems that do completely different things and that communicate from time to time for mutual convenience?
Lesson Two: Start Small
One of the most startling aspects of the Oracle CPG example is its sheer scope. When an organization is interested in integration work, it very much helps to start small and to focus on the area where there is the most pain, rather than attempting to take on the entire universe of problems and solutions simultaneously. Some people refer to the “phased approach” of implementation—putting various pieces in place as they are developed—and the “big bang” approach, which is to develop the entire system and put it into place all at once. Typically, the “big bang” approach lives up to its name—what organizations get is a really big explosion.
Integrating four totally different systems to create a unified system that runs an entire class of companies is biting off quite a lot. If a person were interested in mechanics and engineering, it might be wise not to attempt to build a toolshed instead of a whole house as a first project. Similarly, organizations that would like to improve their EAI could benefit by dividing the issues they have into different groups and conquering them individually, rather than all at once.
One of the sanity checks that are important to run on proposed ideas and projects is a simple examination of the complexity of the overall effort. If things have been constructed correctly, the chances are good that from an architectural perspective things will seem relatively straight-forward. Those simple understandings may translate into quite a bit of underlying work, but all the same, the overall vision should have some simple, central idea. Looking at the Oracle CPG example, the simultaneous loose integration of four separate and massive systems does not seem very simple. It is possible that with more time for analysis, along with a more concerted effort to break down the whole project into smaller manageable components, the CPG project would have had a chance for success.
Another lesson that might have been learned is about data quality and EAI. The goal of the project is the formulation of technology that permits the automated data exchange of hundreds of data structures automatically. The old adage “garbage in—garbage out” becomes “garbage in—garbage throughout” when input data of insufficient quality is used to pollute other formerly decent-quality data. These situations are the impetus for data-quality initiatives, which are growing in organizational importance (for an example, see Allen, 2003).
Lesson Three: Core Technologies Lack EAI Support
This section leaves the Oracle example behind and will address technology and support for XML. We have discussed core XML technologies supporting EAI such as repositories, CASE tools, and translation technologies in previous chapters. However, a few observations are appropriate at this point to address the state of repository technology. Our surveys show that many organizations are not using best practices to manage their data sources (Aiken, 2002). Few organizations reported higher than a level three score on their data management maturity measurement (DM3).
![]() About half responded yes to the question, “Do you use any metadata catalog tools?”
About half responded yes to the question, “Do you use any metadata catalog tools?”
![]() About 1 in 5 organizations are cataloging their metadata using any form of software tool support.
About 1 in 5 organizations are cataloging their metadata using any form of software tool support.
![]() Almost half the projects are proceeding ad hoc.
Almost half the projects are proceeding ad hoc.
![]() The most popular repository technologies control only 16% of the market (see Figure 8.13).
The most popular repository technologies control only 16% of the market (see Figure 8.13).
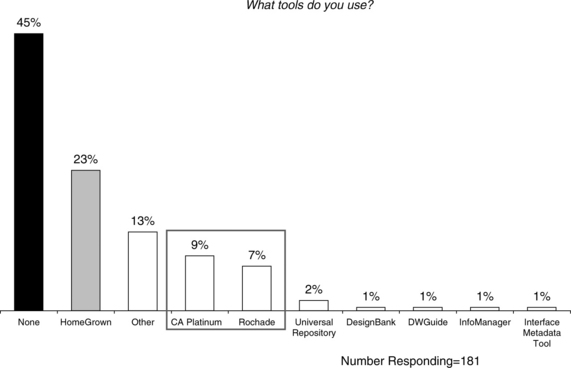
The lesson here is that vendors are not yet providing us with the tools and technologies that we need. Much will have to be home grown and assembled from existing components and even (dare we say it) web services.
Conclusion
XML + DM = EAI makes a powerful motivation—XML provides the vocabulary and describes the content of messages, while EAI helps to define the business value. In order to take full advantage of the potential that XML offers, it is necessary that you examine your EAI-related business requirements and explore the alternatives presented in this chapter. You will likely discover how XML-based integration technologies will permit you to replace key system-problem areas with cleaner, more manageable data-integration management solutions.
References
Aiken, P., Keynote address: Trends in Metadata, Speech given at the 2002 DAMA International Conference. San Antonio, TX. 2002.
The discussion of the controversy over the Oracle CPG project was taken from Christopher Koch’s article Koch, C. Why your integration efforts end up looking like this …. CIO. 2001, November 15.
Petrie, C. Forward to the conference proceedings. In: Enterprise Integration Modeling: Proceedings of the First International Conference. Cambridge, MA: MIT Press; 1992.
*http://cutter.com, accessed 10/03.
†http://cutter.com, accessed 10/03.
*John Zachman, Personal communication, May 2003.