
Expanded Data-Management Scope
Introduction
Data management has been largely focused on the data at rest problem and not on the data movement problem so well articulated by Francis Hsu (2003).. Only recently has anyone collected statistics on the movement of data and the associated costs (e.g., Zachman and IDC). It turns out that we may have been solving the wrong problem all along. If we consider DM to be only focused on management of data at rest as per our data modeling, we may be neglecting a far more important focus—how to manage data in motion, since the nature of the most important information is that it is constantly changing to reflect the business situation.
Now that we have seen the role XML plays as an enabling technology, it is easy to see that this is a most opportune time to work in information and data management. With the technologies at our command, we are able to create automated data management facilities to a greater degree than ever before. The previous chapters have indicated many of the existing technology directions that XML can significantly enhance (reengineering, EAI, metadata recovery, etc.). This last chapter will cover how XML actually expands the overall role of data management. While DM is a critical business support operation, we also find that it can have strategic implications for business.
Unfortunately, one significant aspect of the post-dot.com bust is that job security and the technology boom are things of the past. For many years, banks in New York City could lure experienced technical workers with the promise of more “causal dress” days. Those days are long gone and “lean” would be the appropriate adjective for the operations of the very same companies today. Inspired by the effectiveness argument advanced in “IT Doesn’t Matter,” by Nicholas Carr (2003) (see Figure 11.1), organizations are unwilling to support data management efforts that have solely a policy focus—instead, they want to see data management efforts that provide a strategic advantage, or solve newly arising business challenges.

For years, this has been the old joke:
Question: During cost cutting, how does a manager decide whether a report is used by anyone?
Answer: Stop generating the report and wait to see if anyone complains.
While elder information processing professionals laugh nervously, we acknowledge the wisdom of the tactic. Unfortunately, it is being used in a newer, more relevant sense.
Some managers cannot quite figure out what those folks in “the Data Department” do to contribute to the bottom line. It is easy to imagine the managers talking on the golf course, “So did you ever figure out what those data people are doing for you?” Finally, the manager had encountered someone who did like the reports, and laid off the data manager responsible for the report stoppage. The question naturally follows, “What happened? How did the company go on operating without them?” The answer is usually that they hadn’t been missed—just like the reports!
More and more, employees who perform data job functions are being asked to demonstrate what they are doing directly to help organizations achieve strategic (much less tactical-level) objectives. It is becoming increasingly clear that the best way for the value of data management to be understood by upper management is by making the case that by investing X in data management, the organization will achieve a payback the original investment plus a premium. XML provides the means for data managers to take advantage of key strategic investments in datamanagement practices to reduce price, while increasing quality and speed.
As data managers, your goals include understanding and improving the management of information and data as key enterprise assets. Understanding how to manipulate data structures represents the next plateau in the use of data management technologies. Data managers will be taking on expanded roles. By this, we mean leading the reengineering of processes and systems, capacity planning advising, XBP development, and business-driven data integration, just to name a few future possibilities. Once mastered, organizations will possess very different abilities from the ones taught currently in business courses at all levels. The data management challenges listed below are explained in the remainder of the chapter.
2. Understanding important data structures as XML
3. Resolving differing priorities
4. Expanding data management’s mission: producing innovative XML-based IT savings
5. Expanding data management’s mission: increasing scope and volume of data
6. Greater payoff for preparation
7. Understanding the growth patterns in your operational environment
8. (And let’s not forget) standard data names, value representations, source analysis, increased data access and provisioning, and increased value of the organizational data assets.
There are differing perspectives on the role of data management within organizations. For the purpose of our seven data management challenges described in this chapter, we are looking at the practice of data management as a strategic as well as a support effort. The earliest efforts at data management were focused solely on technical issues surrounding getting the right information to the business to support operations and decision making. In this chapter, we focus on how XML will expand the traditional role of data management, which necessarily requires thinking about the practice outside of its normal roles.
Thought Versus Action
Data management challenge #1: thought versus action.
This can be summed up very quickly: Is data management a practice that requires thinking of things and coordinating policy, or actually doing things and producing results?
One of the authors of this book held the title “Reverse Engineering Program Manager” for the Department of Defense (DoD) and recalls the long debate over the role of data administration within the Department. Funding within most large bureaucracies has traditionally been competitive, and the program operated under constant threat of being cut or sub-sumed by another organization. Within the Center for Information Management, two schools of thought emerged about how DoD data management should operate.
One school reasonably argued that the US Department of Defense needed guidance and that the mission of our group, charged with “DoD data management,” was to focus our entire effort on the development of policy that would be used by the rest of the DoD. From a policy perspective, they believed that the group was charged with developing and communicating DoD-wide guidance.
The school that the author was a part of insisted that a “policy only” focus would leave the program vulnerable to being labeled as unnecessary overhead. In order to keep the program alive, it had to demonstrate results that clearly illustrated progress, or the group would lose its funding. This second school of thought constantly attempted to demonstrate results that produced positive investments for the department by implementing data reengineering projects and producing real results. Perhaps the most notable was the development of a DoD-wide enterprise model (Aiken, Muntz, et al., 1994). In short, the real mission of a data administration group was to produce project results and to mentor other parts of the organization, as well as develop policy.
Eventually, the program mission was changed to “policy only.” After a period of time, its effectiveness was questioned and the second school of thought appeared to have been right. Those remaining with the organization were perceived as a “think tank” that didn’t impact daily operations. Directing all organizational efforts to policy only doomed the program to less effectiveness because the group lacked any enforcement mechanism for the policies they developed.
The DoD example is in some ways better and certainly no worse than the general population of data managers—take for example the data-administration work going on in the area of medical data administration. To provide a comparison, consider that 95% of all organizations are only at Level One—the initial level—of five possible levels on the Capability Maturity Model. As in most large organizations, effectiveness of data management or applications development is linked to an enforcement mechanism. Without it, software development groups do not understand the importance of data-centric development and thus are not motivated to develop the ability to correctly implement the policy. The results were less than had been hoped for from the effort (Aiken & Yoon, 1999). The moral of this little story is that the mission of policy development is a noble one, but leaves a working group open to attack in the future, and is of little value without the corresponding ability to enforce the policies that are developed.
Unfortunately, these types of stories are not widely known in the datamanagement community, and quite a number of organizations are going through similar thought-versus-action debates internally. With the arrival of XML, data management now has a set of technologies available that enable it to implement initiatives. These initiatives in turn can produce savings that exceed their cost. In short, now it is so much easier to implement projects and technologies resulting in savings; therefore there is no excuse not to do projects as well as implement policy. Should data management be involved in thought or action? The answer is both!
Incidentally, data management policy implementation is far easier now than it was in the past. As of fall 2003, most policy can be begged, bought, or borrowed in the form of templates. Relatively little effort is required to formulate data management policies for your organization. DAMA—the premiere organization for data professionals worldwide—is a great place to start the process of locating suitable resources.*
So at this point, the notion of a data management group providing advice and guidance to the remainder of the organization is pretty much history. Data management groups must produce results that demonstrate to the remainder of the organization that they more than pay for them-selves. They must demonstrate this by producing their own type of products. This newer approach moves data managers from thought into action, and lessens the chance of unfortunate management discussions on golf courses, negatively impacting contributing data workers.
A very simple illustration of this concept would be a definable data-quality organization. Once an organization has committed to labeling one or more individuals as “focused on data quality” issues, or “improving data quality,” those individuals must be able to demonstrate positive annual payback. Hypothetically speaking, consider a sizable data quality effort. The group consists of 10 persons paid $10,000 annually, including one-third overhead for taxes, and so on. The data quality group must demonstrate at least $100,000 of positive benefits realized in the first calendar year.
Before protesting, consider the alternate message sent by a data management group that costs an organization $100,000. And consider trying to pitch that amount of investment to management when it is not able to produce positive results. Perhaps management might hear that it will require more than $200,000 (for example, $100,000 for two years) before achieving positive results. This is typically unacceptable in this post-dot.com bust economy. Organizations have become leaner in part by rejecting these types of unacceptable proposals. Future data management operations will be bottom-up justified with real and visible results. The widespread knowledge of how XML can be used to finish projects rapidly makes it simple for data-administration groups to avoid confusion developing about their role. Future data management groups will be both thinkers and doers, and will show a positive return on investment in many situations.
This first item of thinking versus doing deals with the strategic placement of the data management operation within the larger organization. It also addresses how the data management operation is perceived, but does not go into how this magic will actually be accomplished. The first step of pulling off this transformation is covered next.
Understanding Important Data Structures as XML
Data management challenge #2: Understanding important data structures as XML.
Once a decision has been made to do something instead of just communicating how to do something, determining what to do becomes relatively easy. The first step is the process of understanding your important data structures in XML. Specifically, this means understanding the documented and articulated digital blueprint illustrating the commonalities and interconnections among the component metadata. “Understanding” is a shorthand reference for use of data-centric techniques to represent, manage, and develop system component models within a formally defined context. XML is not directly understood by applications in a human sense, but rather provides the ability to create rich taxonomies from which inference can be made. That inference represents real understanding.
The component models we are referring to are represented using the standardized CM2 notation (Common Metadata Model). The models are also sufficiently detailed to permit both business analysts and technical personnel to read the same model separately, and come away with a common understanding. These models must be developed in a cost-effective manner. Figure 11.2 shows the CM2 and how understood system components flow through to provide benefit to various business areas.
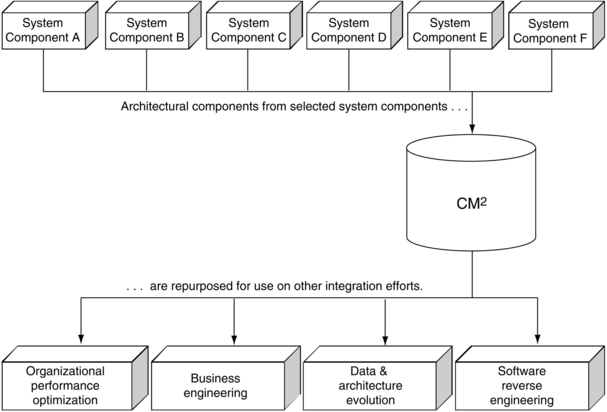
Figure 11.2 “Understood” data structures contributing to numerous business areas such as business engineering and performance optimization.
The first thing to “get” about understanding structures as XML is that your important data structures often include other nested data structures that are not within your stewardship. Sometimes these are external to your organization or even national boundaries. Some structures will come from systems belonging to partners, suppliers, service providers, and so on. This is typically the case for many companies that purchase data lists from other suppliers and partners, such as credit card companies that purchase lists from credit reporting bureaus. These data sources must be examined and ranked along with internal systems to determine which are important.
Keep in mind as well that the most typical use of XML is to wrap data items instead of data structures. Figure 11.3 illustrates how this lack of structure management results in organizations being able to apply just a fraction of the true power of XML. The result correlates with the low industry-wide maturity rankings.

XML lets data managers quickly implement systems that “under-stand” their important data structures. By maintaining even the most elementary of repository technologies, data managers can show organizations direct benefits in areas ranging from capacity management to legacy application maintenance to business engineering. While many other contributions are possible, we will take a look at specific examples of each of these three to illustrate the range of contributions, starting with capacity management.
Example: Capacity Management with XML
The particular data warehouse involved in this example already supported large volumes of data, and had quite a bit more waiting “in the wings” to be included. XML-based metadata management played a significant role in postponing capacity-related hardware upgrades. These were upgrades that everyone thought were necessary to increase the amount of data that could be held in the warehouse. Analysis of the data warehouse metadata revealed that some tables were not relationally normalized, and as a result, significant amounts of space were being wasted.
The XML-based metadata permitted data managers to model the effects of various normalization approaches and other data structure rearrangement schemes. The analysis identified more than 4.7 billion empty bytes in just three data warehouse tables, making a strong case for normalization and reducing the need to upgrade company infrastructure capacity (see Figure 11.4). Without understanding of the data structure, these “empty bytes” that came from duplication of information that was not there in the first place could not have been identified. In this particular situation, of course a data manager could have let the situation continue without addressing it, since storage space is very inexpensive. However, minor inefficiencies like this, which come as a result of poor structure, tend to turn into major inefficiencies over the long haul. Those problems are never cheap, even if the stopgap solution of throwing more hardware at the problem might be.

Figure 11.4 Population of data warehouse tables. (Note: Since one of the key foundations of data quality is having good data names, please note that the attribute names have been purposely butchered.)
The analysis yielded insight that led to further normalization of the data, permitting a huge hardware purchase to be postponed thanks to the use of software XML portals, not to mention more sound understanding of the data. This understanding using XML lets data managers implement automated means of measuring the cost of integration quickly so that they can apply XML more effectively.
The next example outlines a situation that every data manager deals with—the maintenance of legacy systems. It is sometimes said that any system that has been running for more than 5 minutes is a legacy system, and it is therefore important to see what XML can do in an area of common frustration.
Example: Legacy Application Maintenance Reduction
XML-based technologies, including WSDL, SOAP, and XML-based metadata, were used to transform an organization’s legacy environment to the tune of more than $200 million in annual savings. Targeted legacy systems were systematically reduced to 20% of their original code size. The old systems that implemented the core business value consisted of a series of algorithms for implementing various production recipes. These functions were transformed into callable routines that are accessed through a portal. This granular approach allowed the knowledge worker to obtain required data, permitting various combinations of services to be developed, and supporting the individual needs of the knowledge worker as shown in Figure 11.5.

This example looks at XML from the perspective of technical systems, and reducing ongoing overhead associated with them, but what about how XML impacts business engineering efforts? The next example addresses how XML can aid this process by improving the nature and structure of the data provided to business processes.
Example: Business Engineering
In this example, understanding the relevant data structures facilitated the implementation of a business engineering project, replacing legacy pay and personnel systems. Figure 11.5 ahows how process, system, and data structure metadata were extracted before encoding them in XML and using them to support the project from a number of different perspectives.
One unexpected benefit resulted from the use of process metadata to estimate change propagation effects. Use of metadata in business-engineering projects helps accumulate a number of facts, such as exactly how much impact a proposed change would have, that are later used during the analysis.
Another example focuses solely on the replacement of legacy systems whose job was simple data transformation. This movement of data from one format to another format is a common process performed within organizations that has its own set of “gotchas” and drawbacks. As shown in Figure 9.5, once the transformation was understood, the legacy code was replaced with three sets of transformations that were maintained using XML in databases. It is important to note that each replacement must be examined for efficacy. Not all systems should be replaced with XML-based transformations simply for their own sake; like the other recommendations in this book, it should be followed only where it makes economic sense.
Understanding your important data structures, wrapping them in XML, and maintaining them in a simple repository or file system go a long way toward understanding the sources and uses of the data, organization-wide. Once everyone understands the easy accessibility of XML-based data, future development efforts will more frequently take advantage of XML capabilities. This is because it will end up being cheaper to implement interfaces and transformations using XML than without it. This will permit implementation of automated metadata management that greatly decreases maintenance costs. Through automated generation of metadata, such as data-structure sources and uses (CRUD matrices), business processes can obtain the maximum advantage from data.

Resolving Differing Priorities
Data-management challenge #3: Resolving differing priorities. Every organization has more priorities than they have time, people, and money. How do we determine which issues get attention?
Meta-analysis of CIO and data management practitioner surveys shows that each role possesses different views as to what the development priorities should be. In Figure 11.8, we can see just how divergent their respective priorities and expectations are.
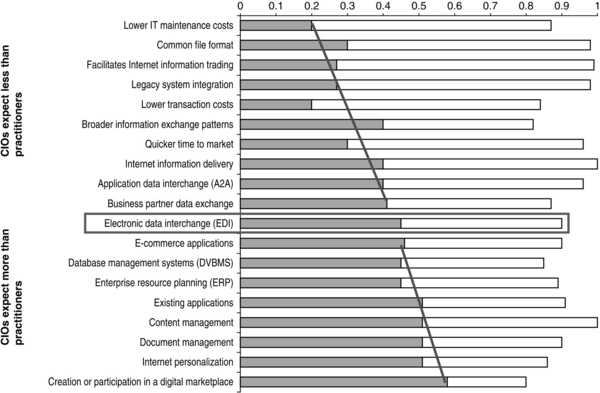
According to surveys, CIOs are looking to XML to apply and to drive the program as a broadly focused effort. Items such as e-commerce, database-management systems, enterprise resource planning (ERP), and digital marketplaces require a longer-term payout than organizations are currently willing to stomach. Practitioners, on the other hand, are focused on providing a more granular level of XML support. This more bottom-up approach permits implementation of results that are oriented toward direct benefits such as lower IT maintenance costs, reduced legacy system integration costs, and application data interchange. These goals appear as projects in very different ways. The key to achieving perceptible results is to obtain common understanding of the agreed-upon approach to XML implementation.
It is important to note that the newly acquired XML-based datamanagement capabilities and their related savings do not show up in the CIO management priorities as shown in Figure 11.9. This represents a vast untapped potential to demonstrate relevance early in the effort. Rapid results are likely obtainable in 95% of all organizations, and the benefits are greater if the data management maturity score is higher than the initial Level One. In short then, resolving differing developmental priorities will lead to clearer understanding of project objectives and approach.

Producing Innovative XML-Based IT Savings
Data management challenge #4: producing innovative XML-based IT savings,
The key to this area is to identify areas of “pain” experienced by the organization and address the data-management aspect of it using XML. Other chapters have contained descriptions of XML being used to increase the relative capacity of servers and other data storage technologies using technologies such as XLink. Many other types of IT savings can be gained by the application of XML-based technologies. The following are some examples from the PeopleSoft model.
![]() XML-based system metadata was used to determine the requirements that a software package could meet, and to document discrepancies between system capabilities and actual needs. XML-based data management capabilities were used to document discrepancies between capabilities and requirements. Panels were incorporated into the XML-based metadata to assist user visualization and recognition of the system functions.
XML-based system metadata was used to determine the requirements that a software package could meet, and to document discrepancies between system capabilities and actual needs. XML-based data management capabilities were used to document discrepancies between capabilities and requirements. Panels were incorporated into the XML-based metadata to assist user visualization and recognition of the system functions.
![]() XML-based metadata types were used to assess the magnitude and range of proposed changes. For example, it is important to have facts such as the number of panels requiring modification if a given field length is changed. This information was used to analyze the costs of changing the system versus changing the organizational processes. It is only possible to do this type of impact analysis if the actual connections between components are known. Discovering that information and having it on hand in XML form opens up many new possibilities; this particular example is just one.
XML-based metadata types were used to assess the magnitude and range of proposed changes. For example, it is important to have facts such as the number of panels requiring modification if a given field length is changed. This information was used to analyze the costs of changing the system versus changing the organizational processes. It is only possible to do this type of impact analysis if the actual connections between components are known. Discovering that information and having it on hand in XML form opens up many new possibilities; this particular example is just one.
![]() Business practice analysis was conducted to identify gaps between the business requirements and the PeopleSoft software. XML-based metadata was used to map the appropriate process components to specific existing user activities and workgroup practices. The mapping helped users to focus their attention on relevant subsets of the metadata. For example, the payroll clerks accessed the metadata to determine which panels ‘belonged’ to them.
Business practice analysis was conducted to identify gaps between the business requirements and the PeopleSoft software. XML-based metadata was used to map the appropriate process components to specific existing user activities and workgroup practices. The mapping helped users to focus their attention on relevant subsets of the metadata. For example, the payroll clerks accessed the metadata to determine which panels ‘belonged’ to them.
![]() Business practice realignment addressed gaps between system functionality and existing work practices. Once users understood the system’s functionality and could navigate through their respective process component steps, they compared the system’s inputs and outputs with their own information needs. If gaps existed, the XML-based metadata was used to assess the relative magnitude of proposed changes to add functionality. This information was then used to forecast system customization costs.
Business practice realignment addressed gaps between system functionality and existing work practices. Once users understood the system’s functionality and could navigate through their respective process component steps, they compared the system’s inputs and outputs with their own information needs. If gaps existed, the XML-based metadata was used to assess the relative magnitude of proposed changes to add functionality. This information was then used to forecast system customization costs.
![]() User training specialists also used the metadata to obtain mappings between business practices and system functions to determine which combinations of mapped “panels,” “menuitems,” and “menubars” were relevant to user groups. A repository was used to display panels in the sequence expected by the system users. By reviewing panels as part of the system processes, users were able to swiftly become familiar with their areas. Additional capabilities for screen session recording and playback were integrated into the toolkit to permit development of system/user interaction “sequences.”
User training specialists also used the metadata to obtain mappings between business practices and system functions to determine which combinations of mapped “panels,” “menuitems,” and “menubars” were relevant to user groups. A repository was used to display panels in the sequence expected by the system users. By reviewing panels as part of the system processes, users were able to swiftly become familiar with their areas. Additional capabilities for screen session recording and playback were integrated into the toolkit to permit development of system/user interaction “sequences.”
The XML-based metadata helped the team to organize the analysis of the PeopleSoft physical database design systematically. Project documentation needs were simplified when a CASE tool was integrated to extract the database design information directly into XML from the physical database. The XML was also used to support the decomposition of the physical database into logical user views. Additional metadata was collected to document how user requirements were implemented by the system.
Statistical analysis was also useful for guiding metadata-based data integration from the legacy systems. For example, XML was used to map the legacy system data into target data structures. Statistical metadata summaries were also used to describe the system to users. For example, Figure 11.10 illustrates use of workflow metadata showing the number of processes in each home page and the Administer Workforce process components. It indicates the number of processes associated with each home page and that the two with the highest number are Develop Workforce, and Administer Workforce. The same chart was used to show users of the Administer Workforce why the recruiters were receiving separate training based on the relative complexity of the components comprising the Administer Workforce process.

Figure 11.10 An example of a statistically derived introduction to the PeopleSoft Administer Workforce business process showing the relative complexity of the six components and how they fit into the home page structure.
These types of IT savings that can be produced through the use of XML address part of the financial case for XML, and how data management groups can show a positive return on investment. In the next example, we will take a look at how the scope and volume of data management can be increased, effectively expanding data management’s reach and impact.
Increasing Scope and Volume of Data Management
Data management challenge #5: Increasing data management scope and volume.
Before illustrating how the scope and volume of data that data managers are expected to manage can be expanded, it will be useful to explain the distinction between structured and unstructured data.
Recall that structured data in many cases should really be referred to as tabular data, because it almost always occurs in rows and columns (see the spreadsheet shown in Figure 11.6). This is what data management has traditionally focused on in the past, because it seems that all of the software and theory is geared toward it. More recently, data managers are increasingly called on to manage increasing amounts of unstructured and semi-structured data. The volume of data requiring management by data managers is estimated to multiply perhaps as much as five times, as organizational support for management of unstructured data increases. Figure 7.17 illustrated the portion of Microsoft’s implementation of unstructured document metadata. Accessing the “properties” selection under the “file” menu of any Office 2000+ document can preview this metadata—some default fields are provided, but others can be designed at the user’s whim. This slightly increased degree of structuring permits queries to be developed for slide titles or other document structures. If these documents were to be centrally housed throughout an organization, imagine the benefit of being able to issue queries along the lines of “Show me all presentations created by Bob between these dates that contain the term ‘System X Integration Project.’”

Figure 11.6 PeopleSoft process metadata structure. Each business “process” was comprised of one or more “components,” which were in turn comprised of one or more “steps.”
Unstructured and semi structured data will require understanding and development of new data management capabilities. As different as rela- tional data is from hierarchical data, unstructured data differs even more from conventional formats, precisely because it is unstructured. New types of data management will help organizations use their existing datamanagement capabilities on new types of data, ranging from PowerPoint presentations to MPEG-based movies. While no complete toolset exists to simplify the problem, many vendors are providing the foundations of solutions—more development breakthroughs in this area are likely. Currently, claims of a total software solution to automatically translate unstructured formats into XML or some structured format should be viewed skeptically, but there are certainly packages that exist already that may aid the process, even if they cannot perform the process completely.
Greater Payoff for Preparation
Data management challenge #6: Greater payoff for preparation.
Preparation of organizational data, including data quality, permits rapid implementation of new EAI architectures and services. Because of XML’s support for semantic understanding, the actual volume of data being maintained drops somewhat as well, as redundant data are identified and eliminated. This is one of the reasons why the semantic understanding that XML brings to the table is important, because misused data resources are frequently misunderstood data resources. Increasing the reuse and relative velocity of data results in higher returns. This reduction of data being maintained due to the elimination of redundancies still cannot keep pace with the increasing scope of data management due to new data sources falling under the control of data management. While XML may help reduce the volume of existing managed data in some cases, the overall trend is clear: new types of data that require management for the first time will expand the global volume of data to be managed.
Understanding the Growth Patterns in Your Operational Environment
Data management challenge #7: identifying growth patterns.
It seems to us that a formal evaluation of how to incorporate XML most profitably into your mix will certainly uncover various important data growth patterns. These can be used to help determine the most effective upstream sources of data that can then be more effectively corrected. Understanding growth patterns can help to predict the effectiveness of alternative data correction strategies. After all, solutions that are built today should address today’s problems, but should also at the very least attempt to look forward to what might be coming around the bend.
Chapter Summary
In addition to existing data management roles and responsibilities, the maturing of XML technologies means that you will have to gear up to face new data management challenges. These will occur as organizations spend proportionally less on IT, as they abandon the “bleeding edge” of technologies and choose to follow what has already worked for others, and as they finally settle on risk-averse postures with respect to technology support. Our savings will come about in the form of:
References
Aiken, P.H., Yoon, Y., et al. Requirements-driven data engineering. Information & Management. 1999;35(3):155–168.
Aiken, P.H., Muntz, A., et al. DoD legacy systems: Reverse engineering data requirements. Communications of the ACM. 1994;37(5):26–41.
Carr, N.G. IT doesn’t matter. Harvard Business Review. 2003:1–11.
Hsu, F. Software Architecture Axiom 1: No Moving Parts, Washington, DC. 2003.
*See the DAMA web site at: http://dama.org/.