
IN THIS CHAPTER
To let you work with the contents of an XML document, XPath lets you model the data in that document in a specific way called the data model. The data model specifies how XPath sees a document, and that's essential to know if you want XPath to find the data you're looking for.
For example, if you have an XML document and want to pick out all the <friend> elements, you need to know how XPath sees that document to be able to instruct it to do what you want. In this chapter, we're going to take a look at how XPath 1.0 sees the contents of an XML document—that is, we'll be discussing the XPath 1.0 data model.
To handle the data in an XML document, XPath 1.0 lets you work with four different data types. For example, by defining a string data type, XPath lets you handle text strings in XML elements and work with them directly. For instance, if you use the XPath expression //planet[name="Venus"], XPath will return all <planet> children in a document that have <name> children with text equal to “Venus”. This works because XPath lets you work with text strings like “Venus”. You can also work with numbers, like this: //planet[position()=3], which lets you specify that you want the third <planet> element in the document.
There are other data types available besides strings and numbers that you can work with in XPath, and we'll take a look at all the allowable data types here. Then we'll be ready to use those data types with the XPath data model to create XPath expressions of the type XPath processors will be able to understand and use to extract data from XML documents.
Here are the data types in XPath 1.0 (XPath 2.0 adds many more data types, as we'll see in the second half of the book):
A number—. stored as a floating-point number
A string—. a sequence of characters
A Boolean—. a true or false value
A node-set—. an unordered collection of unique nodes
XPath expressions are the fundamental building blocks of XPath, and an XPath expression is anything XPath can evaluate to yield a result (which is not an error). For example, here's an XPath expression: //planet[position() > 3]. This expression returns a node-set containing all the <planet> elements in a document after the first three.
All XPath 1.0 expressions must evaluate to a value that is one of the four data types—number, string, Boolean, or node-set. For example, not only is //planet[position() > 3] an XPath expression (this expression results in a node-set), but so is position() (which results in a number)—and so is 3, all by itself, as well as position() > 3 (this expression yields a Boolean true/false value depending on whether the tested node's position is greater than three).
Let's take a look at all the allowed data types in more detail now.
First of all, you can use numbers as XPath expressions. For example, in the XPath expression //planet[position()=7] (which you might use to match the seventh <planet> element in an XML document), the number 7 is a valid XPath expression, evaluating to itself.
The position() function also evaluates to a number—the position of the current node among its sibling nodes. And there are other functions that evaluate to numbers—for example, the XPath 1.0 floor function returns the largest integer less than the argument you pass to it. That means that floor(4.6) would return a value of 4, for instance, so floor(4.6) is an XPath expression that evaluates to a number.
NUMBERS IN XPATH 1.0
In XPath 1.0, a number represents a floating-point number. A number can have any double-precision 64-bit format that conforms to IEEE 754. These include a special “Not-a-Number” (NaN) value, positive and negative infinity, and positive and negative zero.
All of which is to say that numbers are a valid data type in XPath 1.0—you can use them directly, and expressions can be evaluated to yield a number.
XPath expressions can also be text strings (defined in XPath as “a sequence of zero or more characters,” where the characters are Unicode characters by default). For example, in the XPath expression //planet[name="Mars"], which returns all <planet> children in a document that have <name> children with text equal to “Mars”, “Mars” is an XPath expression of data type string.
Here's another example—if you have an XML element like this: <planet color = "RED">Mars</planet>, the XPath expression attribute::color would return the string “RED”.
So as you can see, XPath expressions can also be of the string type.
Besides numbers and strings, XPath expressions can also be Boolean true/false values. For example, take a look at the XPath expression position()=3. The position() function returns the position of a node among its siblings, and if position() returns 3, the XPath expression position()=3 is true. Otherwise, the expression position()=3 is false.
Here's another example—in the XPath expression //planet[attribute::color = "RED"], which returns all <planet> elements that have a color attribute with value of “RED”, attribute::color = "RED" is an XPath expression that returns a Boolean value. In fact, in the expression //planet[attribute::color], the expression attribute::color is itself a Boolean expression. It's true if the current <planet> element has a color attribute, but false otherwise.
Booleans, then, make up the third data type that XPath expressions can evaluate to, in addition to numbers and strings.
The fourth data type, node-sets, is where all the excitement lies in XPath 1.0. A node-set holds zero or more nodes (note that a node-set might contain only a single node), and working with node-sets is what really lets you work with the data in an XML document.
For example, the XPath expression //planet[position() > 3] returns all the <planet> elements after the first three. That means you get a node-set of <planet> elements when you evaluate this expression. Node-sets are the most interesting data type because a node-set holds actual nodes from the XML document. For example, you can filter a set of nodes that you want to work with into your node-set, ignoring all the rest of the data in the XML document. And treating a whole collection of nodes as one single data item—a node-set—is very handy.
Here's another example—the expression child::planet[attribute::color = "RED"] will return a node-set containing all <planet> children of the context node that have a color attribute with value of “RED”.
Node-sets are data types that are unique to XPath—you may be familiar with strings, numbers, and Booleans already, but node-sets are where the real meat of XPath is. A node-set is really a collection, not just a single data item like a string or a number; a node-set can hold either a single node or multiple nodes, but either way it's still called a node-set.
DATA TYPES IN XPATH 2.0
The data types in XPath 1.0 are pretty primitive—just numbers, strings, Booleans, and node-sets. Augmenting these types was one of the big pushes behind XPath 2.0, which supports data types taken from XML schemas, as we're going to see in the second half of the book. Schemas support a great many data types, such as boolean, byte, date, dateTime, int, long, nonPositiveInteger, normalizedString, positiveInteger, short, unsignedByte, unsignedInt, unsignedLong, unsignedShort, and many more.
If an XPath expression returns a node-set containing multiple nodes, the XPath processor software will return all those nodes to you, as we've seen in the XPath Visualiser.
So what about the actual nodes in a node-set? What kinds of nodes can you have? That's where the data model comes in, and we're going to turn to that topic next.
XPath models an XML document as a tree of nodes. This way of looking at an XML document is called XPath's data model. Different types of nodes are available in XPath, such as element nodes, attribute nodes, and text nodes, and we're going to take a look at the various possibilities now.
There are seven types of nodes in XPath 1.0:
Root nodes
Element nodes
Attribute nodes
Processing instruction nodes
Comment nodes
Text nodes
Namespace nodes
We'll take a look at each of these node types here, using our XML document that holds planetary data, renumbered ch02_01.xml for this chapter, as you can see in Listing 2.1.
Example 2.1. Our Sample XML Document (ch02_01.xml)
<?xml version="1.0"?>
<planets>
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
<day units="days">58.65</day>
<radius units="miles">1516</radius>
<density units="(Earth = 1)">.983</density>
<distance units="million miles">43.4</distance>
<!--At perihelion-->
</planet>
<planet>
<name>Venus</name>
<mass units="(Earth = 1)">.815</mass>
<day units="days">116.75</day>
<radius units="miles">3716</radius>
<density units="(Earth = 1)">.943</density>
<distance units="million miles">66.8</distance>
<!--At perihelion-->
</planet>
<planet>
<name>Earth</name>
<mass units="(Earth = 1)">1</mass>
<day units="days">1</day>
<radius units="miles">2107</radius>
<density units="(Earth = 1)">1</density>
<distance units="million miles">128.4</distance>
<!--At perihelion-->
</planet>
</planets>
We'll begin with the root node.
The root node is the root of the XPath tree for an XML document. This node is not the same as the <planets> element in ch02_01.xml—<planets> is the document element for the XML document, and people often confuse the two.
The root node is really a logical node that serves simply as the root of the whole XPath node tree. The root node gives you access to the whole tree, and in XPath, you use / to stand for the root node. When you use an XPath expression like /planets, you're starting at the root node and searching for <planets> elements that are direct children of the root node. In fact, you can see this XPath expression at work in our XML document in Figure 2.1 in the XPath Visualiser, as we first saw in Chapter 1.
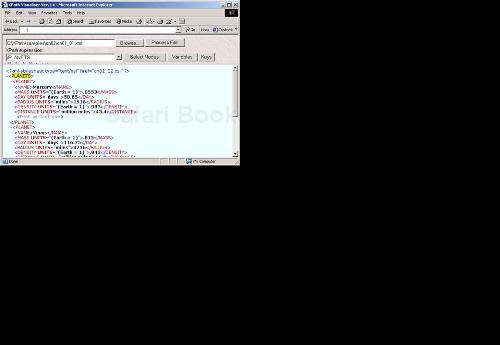
Because the root node is the root of the XPath tree, the root node is the same as the entire document, as far as many applications go. Note also that the root node includes not only the document element (and therefore all its children as well), but also any processing instructions, namespace declarations, and so on that are at the same level as the document element.
We're already familiar with element nodes because they correspond to the elements in an XML document—there is one element node in the XPath node tree for every element in the original XML document. You can see plenty of elements in our sample XML document, ch02_01.xml, such as <planets>, <planet>, and so on:
<?xml version="1.0"?>
<planets>
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
<day units="days">58.65</day>
<radius units="miles">1516</radius>
<density units="(Earth = 1)">.983</density>
<distance units="million miles">43.4</distance>
<!--At perihelion-->
</planet>
.
.
.
Element nodes can also have children, of course. The children of each element node can include element nodes, comment nodes, processing instruction nodes, and text nodes.
Element nodes can also have a unique identifier (ID). For example, if the XML document has an attribute declared to be of type ID, that attribute can serve as the element's ID value. On the other hand, if you do not declare any attributes to be of type ID, no elements can have IDs.
In XPath, you can use an element's name (such as planet for the <planets> element) to match an element, or * to match any element. For example, you can see the XPath expression //* at work in Figure 2.2, matching all element nodes in ch02_01.xml.

Note that if you use an expression such as /planet, you'll get not only a <planet> element (if there is one), but also all its contents. Take a look at this example:
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
</planet>
In this case, /planet will return the <planet> element, which includes all that element's contents. In other words, what you get includes a newline character, some whitespace, the <name> element, another newline character, and some additional whitespace, the <mass> element, and a newline character. So the entire element and all its contents are returned. (As we'll see in Chapter 4, you can suppress leading and trailing whitespace with the normalize-space function.)
We're already familiar with attribute nodes because they correspond to element attributes in XML. For example, this element in ch02_01.xml has an attribute named units with the value “days”:
<?xml version="1.0"?>
<planets>
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
<day units="days">58.65</day>
<radius units="miles">1516</radius>
<density units="(Earth = 1)">.983</density>
<distance units="million miles">43.4</distance>
<!--At perihelion-->
</planet>
.
.
.
Elements can have more than one attribute, of course, and therefore more than one attribute node:
<day units="days" COPYRIGHT="(c) 2003 Steve">1</day>
In XPath terms, the element is the parent of each of its attribute nodes—however, an attribute node is not considered a child of its parent element. Note that this is different from the W3C XML Document Object Model (DOM), which does not treat the element with an attribute as the parent of the attribute.
In XML, you can also have default attributes, where attributes are given default values. For example, some attributes, like xml:lang and xml:space, affect all elements that are descendants of the element with the attribute—but that does not affect where attribute nodes appear in the tree. These attributes, like any other, are only considered attributes of their parent elements in XPath.
In XPath, you can refer to attributes using the attribute axis or its shorthand version, @. For example, to recover the value of the units attribute for an element, you can use the term @units, as we've seen in Chapter 1. To match all attributes in a document, you can use the XPath expression //@*, and you can see that expression at work on ch02_01.xml in the XPath Visualiser in Figure 2.3.

There is a processing instruction node for every XML processing instruction. For example, there's a processing instruction in ch02_01.xml, <?xml-stylesheet?>, which looks like this:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="ch01_02.xsl"?>
<planets>
<planet>
<name>Mercury</name>
.
.
.
Processing instructions are not under the control of any namespace, so they do not have namespace nodes. Also, in XML, their attributes are really pseudo-attributes, which means that XPath will not recognize them as attributes. From an XPath 1.0 point of view, the value of a processing instruction is everything following the processing instruction's target (xml-stylesheet here) up to the final ?. For example, the value of <?xml-stylesheet type="text/xsl" href="ch01_02.xsl"?> is type="text/xsl" href="ch01_02.xsl".
THE XML DECLARATION IS NOT A PROCESSING INSTRUCTION
It's important to realize that the XML declaration is not a processing instruction. That means that there is no processing instruction node corresponding to the XML declaration.
You can use the processing-instruction node test to match processing instructions in XPath, which means that you can match all processing instructions in a document with the expression //processing-instruction()—as you can see in Figure 2.4.
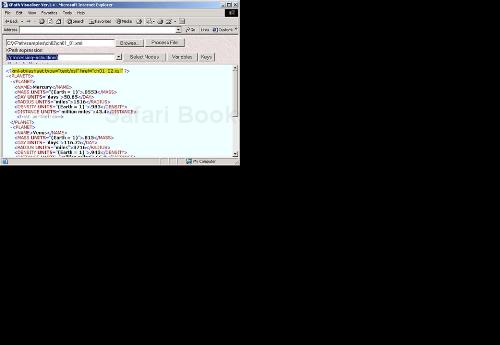
ACCESSING A PROCESSING INSTRUCTION'S PSEUDO-ATTRIBUTES
Although you can't directly address the value of a processing instruction's pseudo-attributes using XPath, you can use the string-handling functions we'll see in Chapter 4 to get their values.
As you'd expect, comment nodes in XPath correspond to comments in XML documents, which are delimited with <!-- and -->. As far as XPath is concerned, the value of a comment node is the text between <!-- and -->. In an XPath document tree, there is a comment node for every comment (except for any comment that occurs in a DTD or schema).
Our XML document contains a few comments, and you can see one of them here:
<?xml version="1.0"?>
<planets>
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
<day units="days">58.65</day>
<radius units="miles">1516</radius>
<density units="(Earth = 1)">.983</density>
<distance units="million miles">43.4</distance>
<!--At perihelion-->
</planet>
.
.
.
In XPath, you can match comments with the comment node test, which means that the expression //comment() matches all comment nodes in a document. You can see this expression at work in the XPath Visualiser in Figure 2.5, where it is matching comment nodes.
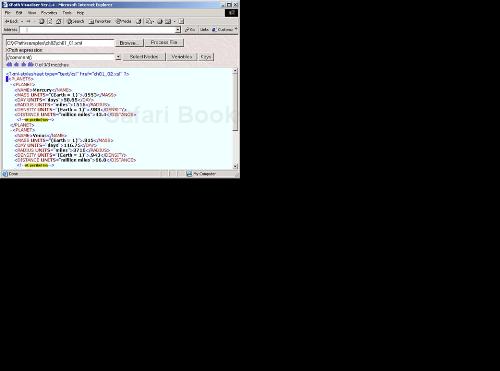
XPath also gives you the means of handling text data in elements as text nodes. For example, the value of the text node in the <name> element here is “Mercury”:
<?xml version="1.0"?>
<planets>
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
<day units="days">58.65</day>
<radius units="miles">1516</radius>
<density units="(Earth = 1)">.983</density>
<distance units="million miles">43.4</distance>
<!--At perihelion-->
</planet>
.
.
.
A text node of an element is just the PCDATA data of that element. Note that if an element contains other elements, processing instructions, or comments, that can break up text into multiple text nodes. For example, the element <planet>Mars<HR/>The Red Planet</planet> contains two text nodes, “Mars” and “The Red Planet”.
HANDLING TEXT IN XML CDATA SECTIONS
How does XPath handle text in XML CDATA sections? Each character within a CDATA section is treated as character data. In other words, a CDATA section is treated as if the <![CDATA[ and ]]> were removed and every occurrence of markup like < and & was replaced by the corresponding character entities like < and &.
Also, characters inside comments, processing instructions, and attribute values do not produce text nodes.
In XPath, you can match text nodes with the text node function, which means that you can match all text nodes throughout a document with the expression //text(), as you see in the XPath Visualiser in Figure 2.6.

Namespace nodes are a little different from other nodes—they're not visible in the same way in a document. Each element has a set of namespace nodes, one for each distinct namespace prefix that is in scope for the element (including the standard XML prefix, which is implicitly declared by the XML Namespaces Recommendation) and one for the default namespace if one is in scope for the element. The element itself is the parent of each of these namespace nodes; however, a namespace node is not considered a child of its parent element. An element will have a namespace node
For every attribute in the element that declares a namespace (that is, whose name starts with
xmlns:).For every attribute in a containing element whose name starts
xmlns:(unless the element itself or a nearer ancestor redeclares the prefix).For an
xmlnsattribute, if the element or some containing element has anxmlnsattribute, and the value of thexmlnsattribute for the nearest such element is not empty.
Namespace nodes are not directly visible in an XML document, so there's no XPath Visualiser example here. But take a look at this XSLT stylesheet, which includes two explicit namespace declarations:
<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://www.w3.org/1999/xhtml"> <xsl:template match="//planets"> <html> <xsl:apply-templates/> </html> </xsl:template> <xsl:variable name="myPosition" select="3"/> <xsl:template match="planet"> <p> <xsl:value-of select="$myPosition"/> </p> </xsl:template> </xsl:stylesheet>
In this case, the prefix xsl is associated with the URI “http://www.w3.org/1999/XSL/Transform”, and any elements whose names are prefixed with xsl will have a namespace node with the value “http://www.w3.org/1999/XSL/Transform”. There's also a default namespace here, “http://www.w3.org/1999/xhtml”, used for any non-prefixed elements. And there's another default namespace here, the implicit XML namespace, which is in effect for all XML elements. The URI for the implicit XML namespace is “http://www.w3.org/XML/1998/namespace”.
That completes our overview of the seven types of nodes in XPath 1.0: root nodes, element nodes, attribute nodes, processing instruction nodes, comment nodes, text nodes, and namespace nodes. However, there's more about nodes to understand from XPath's point of view—nodes can also have various kinds of names, as well as string values, for example.
Most nodes have names—in fact, there are three different types of names that XPath uses:
Qualified names, also called QNames—. This term comes from www.w3.org/TR/REC-xml-names, and it's the name of the node including any applicable namespace prefix. For example, the element
<STARS>has the QName “STARS”, and the element<map:STARS>has the QName “map:STARS”.Local name—. The local name is the same as the QName minus any namespace prefix. For example, the element
<STARS>has the local name “STARS”, and the element<map:STARS>also has the local name “STARS”.Expanded name—. If a node has both a local name and is associated with a namespace, its expanded name is made of a pair of the namespace's URI and the local name.
USING EXPANDED-NAME PAIRS
How does the expanded-name pair work, exactly? That's still an open question. There are XPath functions to return a node's local name and QName, but none to return its expanded name. The editor for the XPath 1.0 specification, James Clark, says at http://xml.coverpages.org/clarkNS-980804.html that the expanded name is made up of the namespace URI, a “+”, and the local name, like this: http://www.starpowder.com+planets. In fact, XPath processors are more likely to use the format {http://www.starpowder.com}planets. So the real answer here is—it's still up to the software you're using.
The most common names are qualified names (QNames) and local names.
Here's how to find the various names for the different types of nodes:
Root nodes—. The root node's local name is an empty string, “”. It does not have an expanded name.
Element nodes—. An element node has a local name that is simply the name of the element without any namespace prefix, a QName that includes any namespace prefix, and an expanded name computed by expanding the QName of the element with the applicable namespace URI.
Attribute nodes—. Like elements, attributes have local names, QNames, and expanded names. But here's something to note—the namespace prefix of the
colorattribute in<my:planet color="RED">is notmy—there is no namespace prefix for this attribute. (In the QName and expanded name for attributes, you only use the actual namespace prefix for the attribute itself, not the element it's an attribute of.)Processing instruction nodes—. The local name is the processing instruction's target. For example, in the processing instruction
<?xml-stylesheet type="text/xsl" href="ch01_02.xsl"?>, the local name isxml-stylesheet. Because processing instructions don't have namespaces, the namespace part in processing instruction QNames and expanded names isnull.Comment nodes—. A comment node does not have a local name, a QName, or an expanded name.
Text nodes—. A text node does not have a local name, QName, or expanded name.
Namespace nodes—. The local name of a namespace node is the namespace prefix itself. A namespace node has an expanded name and QName as well—the local part is the namespace prefix, and the namespace URI is always
null.
Besides node names, XPath also specifies that nodes have string values.
In addition to giving most nodes names, each node in XPath is considered to have a string (that is, text) value. For example, the string value of a comment node is the simple text content of the comment itself. Here's how to get the string value for each of the various types of nodes:
Root nodes—. The string value is the concatenated (joined) string value of all text nodes.
Element nodes—. The string value is the concatenated value of all contained text nodes, including the text nodes in descendant elements.
Attribute nodes—. The string value is the normalized attribute value. (The normalized value of a text string is the same text with leading and trailing whitespace removed, as well as converting multiple consecutive whitespace into a single whitespace character—unless the text string is considered XML character data, CDATA, in which case whitespace is not removed.)
Processing instruction nodes—. The string value is everything in the processing instruction between the target and the closing
?>. For example, in the processing instruction<?xml-stylesheet type="text/xsl" href="ch01_02.xsl"?>, the string value is"type="text/xsl" href="ch01_02.xsl".Text nodes—. The string value is simply the character data in the text node.
For example, take a look at this short XML document:
<?xml version="1.0"?>
<!--Here are the words-->
<words copyright = "(c) 2003 Starpowder Inc.">
<term>Hello</term>
<term>there.</term>
</words>
The string value of the root node of this XML document is the joined string value of the document's text nodes. That looks like this (including whitespace) :
Hello there.
So far, then, we've seen how XPath views the nodes in an XML document. But how are those nodes arranged? There are a few different ways of looking at the order of nodes in an XML document, and the first one we should discuss is document order.
In document order, the nodes in an XML document retain the order in which they appear in the XML document. Some elements contain other elements, and that hierarchical structure is maintained. In addition, the order of sibling nodes, at the same level in the document hierarchy, is preserved. For example, in document order, Mercury's <planet> element comes before Venus's <planet> element here:
<?xml version="1.0"?>
<planets>
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
<day units="days">58.65</day>
<radius units="miles">1516</radius>
<density units="(Earth = 1)">.983</density>
<distance units="million miles">43.4</distance>
<!--At perihelion-->
</planet>
<planet>
<name>Venus</name>
<mass units="(Earth = 1)">.815</mass>
<day units="days">116.75</day>
<radius units="miles">3716</radius>
<density units="(Earth = 1)">.943</density>
<distance units="million miles">66.8</distance>
<!--At perihelion-->
</planet>
.
.
.
In other words, document order simply refers to the order in which nodes appear in an XML document. There's no question about the order when you're dealing with elements that enclose other elements, for example, but when you're dealing with elements on the same level—sibling elements—document order specifies that they should be ordered as they were in the original XML document.
MORE ON DOCUMENT ORDER
Here's one more thing to know about document order—attribute nodes are not in any special order, even in document order. That is, document order says nothing about the order of attributes in an element.
XPath also organizes nodes into node-sets as well as node trees, the next step up from simple document order.
As you know, node-sets are XPath's way of dealing with multiple nodes. For example, you can see the node-set returned by the expression //planet on our sample XML document in the XPath Visualiser in Figure 2.7. But there's more to know about node-sets.

When you're working with a node-set, XPath gives you a variety of resources that are available at any time called the XPath context. You'll see more about what's in the XPath context in the upcoming chapters; here's what in it:
The context node, which is the XML node in the XML document that the XPath expression was invoked on. In other words, XPath expressions are executed starting from the context node. We'll see how to use relative expressions in XPath soon, and such expressions are always relative to the context node.
The context position, which is a nonzero positive integer indicating the position of a node in a node-set. The first node has position 1, the next position 2, and so on.
The context size, which is also a nonzero positive integer, the context size gives the maximum possible value of the context position. (It's the same as the number of nodes in a node-set.)
A set of variables—. you can use variables to hold data in XSLT, and if you do, those variables are stored in the expression's context, which can be accessed in XPath.
A function library full of functions ready for you to call, such as the
sumfunction, which returns the sum of the numbers you pass it.The set of XML namespace declarations available to the expression.
In addition to these context items, there is also the current node, which we've already discussed. The current node is not the same as the context node. The context node is set before you start evaluating an XPath expression—it's the node the expression is invoked on. However, as the XPath processor evaluates an XPath expression, it can work on various parts of that expression piece by piece, and the node that the XPath processor is working on at the moment is called the current node.
Here's an example showing how to work with context nodes and positions. Say that you apply the XPath expression /planets/planet to our planetary data:
<?xml version="1.0"?>
<planets>
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
<day units="days">58.65</day>
<radius units="miles">1516</radius>
<density units="(Earth = 1)">.983</density>
<distance units="million miles">43.4</distance>
<!--At perihelion-->
</planet>
<planet>
<name>Venus</name>
<mass units="(Earth = 1)">.815</mass>
<day units="days">116.75</day>
<radius units="miles">3716</radius>
<density units="(Earth = 1)">.943</density>
<distance units="million miles">66.8</distance>
<!--At perihelion-->
</planet>
.
.
.
The first / in /planets/planet makes the root node the context node for the rest of the expression. The planets part makes the <planets> element the context node for the rest of the expression after that point. That means that the remainder of this expression, /planet, will be evaluated with respect to the <planets> element, so the <planets> element is the context node for the /planet part of this XPath expression.
The whole expression, /planets/planet, matches and returns the three <planet> elements in a node-set. The first <planet> element will have the context position 1, the next will have context position 2, and so on. The context size of the node-set containing the three <planet> elements is three.
Here's an example showing how to work with the variables present in a node-set context. XPath doesn't let you define variables. However, you can create variables in an XSLT stylesheet with the <xsl:variable> element like this, where I'm creating a variable named myPosition with the value 3:
<xsl:variable name="myPosition" select="3"/>
This new XSLT variable, myPosition, can be used in XPath expressions. For example, as we saw in Chapter 1, you can assign XPath expressions to the XSLT <xsl:value-of> element's select attribute. And in XPath, you can refer to the value in a variable by prefacing the variable's name with a $, as you see in ch02_02.xsl in Listing 2.2.
Example 2.2. Using an XSLT Variable (ch02_02.xsl)
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="//planets">
<HTML>
<xsl:apply-templates/>
</HTML>
</xsl:template>
<xsl:variable name="myPosition" select="3"/>
<xsl:template match="planet">
<P>
<xsl:value-of select="$myPosition"/>
</P>
</xsl:template>
</xsl:stylesheet>
This will insert the value of myPosition into the document. This stylesheet just replaces each <planet> element with the value in myPosition, which is 3, in a <P> element, this way:
<HTML>
<P>
3
</P>
<P>
3
</P>
<P>
3
</P>
</HTML>
And we've already seen some of the XPath functions, such as the position function, which we've used like this: //planet[position()=3], where we're using the position() function to return the current node's context position. All the XPath 1.0 functions are coming up in Chapter 4.
We've already seen that nodes have string values, and it turns out that node-sets also have string values in XPath—but a node-set's string value might surprise you. If you followed the discussion earlier about the string value of a root node, which is the concatenation of text nodes in the document, you might expect the string-value of a node-set to be made up of the concatenated string-values of all the nodes in the set.
But that's not so—in XPath, the string-value of a node-set is simply the string-value of the first node in the node set only. For example, if you apply the XPath expression //planet to our planets example, ch02_01.xml, you'll get a node-set holding the three <planet> elements in that document, in document order. However, the string value of this node-set is the string value of the first element only, the Mercury element:
<planet>
<name>Mercury</name>
<mass units="(Earth = 1)">.0553</mass>
<day units="days">58.65</day>
<radius units="miles">1516</radius>
<density units="(Earth = 1)">.983</density>
<distance units="million miles">43.4</distance>
<!--At perihelion-->
</planet>
Here's the string value of this element, and therefore of the entire //planets node-set:
Mercury .0553 58.65 1516 .983 43.4
That completes our look at nodes and node-sets. The next step up in organization in XPath is to start thinking in terms of node trees.
Working with XML documents as node trees is a conceptual way of looking at them. As you can tell from the name, the root node is at the base of the tree, and all other nodes are in a tree structure beginning at the root. Considering XML documents as node trees means that XPath can work with the relationships between nodes in different ways, and those ways are the XPath axes. When you use an axis, you tell XPath what relationships you want to explore in the node tree, starting with the context node—we'll see all the axes at work in Chapter 3.
Let's take a look at an example. You can see a short XML document holding the names of two books in ch02_03.xml in Listing 2.3.
Example 2.3. A Short XML Document (ch02_03.xml)
<?xml version="1.0"?>
<library>
<book>
<title>
I Love XPath
</title>
<title>
XPath is the BEST
</title>
</book>
</library>
Here's how the XML document we just saw looks to an XPath processor as a tree of nodes:
root
|
element: <library>
|
element: <book>
|
|-------------------|
| |
element: <title> element: <title>
| |
text: "I Love XPath" text: "XPath is the BEST"
Actually, the preceding tree diagram does not represent the whole picture from an XPath processor's point of view. I've left out one type of node that causes a great deal of confusion—text nodes that contain only whitespace. Because this causes so much confusion in XPath, it's worth taking a look at. The sample XML document we've been working on so far is nicely indented to show the hierarchical structure of its elements, like this:
<?xml version="1.0"?>
<library>
<book>
<title>
I Love XPath
</title>
<title>
XPath is the BEST
</title>
</book>
</library>
However, from an XPath point of view, the whitespace we've used to indent elements in this example actually represents text nodes. That means that by default, those spaces will be copied to the output document. The way whitespace works is a major source of confusion in XPath, so we'll see how it works in this example.
Four characters are treated as whitespace: spaces, carriage returns, line feeds, and tabs. That means that from an XSLT processor's point of view, the input document looks like this:
<?xml version="1.0"?> <library>....<book>
All the whitespace between the elements is treated as whitespace text nodes in XPath. That means that there are five whitespace text nodes we have to add to our diagram: one before the <book> element, one after the <book> element, as well as one before, after, and in between the <title> elements:
root
|
element: <library>
|
|------------|----------------|
| | |
text:whitespace element: <book> text:whitespace
|
|---------------|-------------------|-----------------|---------------------|
| | | | |
text: whitespace element: <title> text: whitespace element: <title> text:whitespace
| |
text: "I Love XPath" text: "XPath is the BEST"
Whitespace nodes like these are text nodes that contain nothing but whitespace. XPath processors preserve this whitespace by default. Note that text nodes that contain characters other than whitespace are not considered whitespace nodes, and so will never be stripped from a document.
As we know, attributes are treated as nodes as well. Although attribute nodes are not considered child nodes of the elements in which they appear, the element is considered their parent node. Suppose you add an attribute to an element like this:
<?xml version="1.0"?>
<library>
<book>
<title>
I Love XPath
</title>
<title pub_date="2003">
XPath is the BEST
</title>
</book>
</library>
Here's how this attribute would appear in the document tree:
root
|
element: <library>
|
|------------|----------------|
| | |
text:whitespace element: <book> text:whitespace
|
|---------------|-------------------|-----------------|---------------------|
| | | | |
text: whitespace element: <title> text: whitespace element: <title> text:whitespace
| |
text: I Love XPath |------------------------------|
| |
text: XPath is the BEST attribute: pub_date="2003"
When you consider an XML document as a tree of nodes, there are various relationships between those nodes. For example, take our simple example:
root
|
element: <library>
|
element: <book>
|
|-------------------|
| |
element: <title> element: <title>
| |
text: "I Love XPath" text: "XPath is the BEST"
The root node is at the very top of the tree, followed by the root element's node, corresponding to the <library> element. This is followed by the <book> node, which has two <title> node children. These two <title> nodes are grandchildren of the <library> element. The parents, grandparents, and great-grandparents of a node, all the way back to and including the root node, are that element's ancestors. The nodes that are descended from a node—its children, grandchildren, great-grandchildren, and so on—are called its descendants. As we've seen, nodes on the same level are called siblings.
XPath 1.0 formalizes these relationships with its 13 axes, which we're going to start using in Chapter 3. These axes include the child axis, which lets you indicate that you're interested in children of the context node, the descendant axis, which points to descendants of the context node, and so on.
You use these axes to navigate from the context node along the branches of the node tree to the node(s) you want. Here are a few examples:
/descendant::planet[position() = 3]—. Returns the third<planet>element in the document.preceding-sibling::name[position() = 2]—. Returns the second previous<name>sibling element of the context node.ancestor::planet—. Returns all<planet>ancestors of the context node.ancestor-or-self::planet—. Returns the<planet>ancestors of the context node. If the context node is a<planet>as well, also returns the context node.child::*/child::planet—. Returns all<planet>grandchildren of the context node.
That completes our look at the XPath data model in this chapter. We started by taking a look at the various data types you can use in XPath—numbers, strings, Booleans, and node-sets. Then we took a closer look at the different types of XPath nodes that you can use in node-sets, and saw that when nodes are arranged into trees, you can use XPath axes to access them.
Now that we know how the XPath data model works—that is, how XPath views the data in an XML document—and have an introduction to using XPath axes to take advantage of the relationships that XPath knows about between nodes, we're ready to start working with real XPath expressions, and we'll do that in Chapter 3.
Before we finish with data models entirely, however, it's worth noting that there are other XML data models than the XPath data model—the Infoset and DOM models, for example—and we'll take a look at them and how they impact XPath 1.0 next. (If you prefer, you can skip this material and go directly to Chapter 3, or skim over it—I've added it for the sake of completeness for readers who use the Infoset and DOM data models.)
An XML infoset is intended to hold all the information in an XML document in compact form. Reducing an XML document to its infoset is intended to make comparisons between all kinds of XML documents easier by presenting the data in those documents in a standard way. You can find the official XML Information Set specification at www.w3.org/TR/xml-infoset.
To understand what infosets are and what they're used for, imagine searching for data on the World Wide Web. You may want to search for a particular topic, such as XML, and you'd turn up millions of matches. How could you possibly write software to compare those documents? The data in those documents isn't stored in any way that's directly comparable.
That's where infosets come in because the idea is to regularize how data is stored in an XML document, which will, ultimately, let you work with thousands of such documents. The idea behind infosets is to set up an abstract way of looking at an XML document that allows it to be compared to others.
XML infosets have their own data model, which is not the same as the XPath data model. An XML infoset can contain 15 different types of information items:
A document information item
Element information items
Attribute information items
Processing instruction information items
Reference to skipped entity information items
Character information items
Comment information items
A document type declaration information item
Entity information items
Notation information items
Entity start marker information items
Entity end marker information items
CDATA start marker information items
CDATA end marker information items
Namespace declaration information items
Each of these information items themselves have a set of properties, which contain more information—for example, the document information item has properties that let you access the children of the root node.
Over time, several XML standards have developed their own data model, and W3C is trying to get them all reconciled. You won't have to know about infosets in this book, but if you're already familiar with them, it's useful to know how you can derive the nodes in the XPath data model from the information items provided by an XML infoset. Here's how that works:
The root node comes from the Infoset document information item. The children of the root node come from the
childrenandchildren-commentsproperties.Element nodes come from Infoset element information items. The children of an element node come from the
childrenandchildren-commentsproperties. The attributes of an element node come from theattributesproperty.Attribute nodes come from
attributeinformation items. The string-value of the node comes from concatenating the character code property of each member of thechildrenproperty.Text nodes come from one or more consecutive
characterinformation items. The string-value of the node comes from concatenating the character code property of each of thecharacterinformation items.Processing instruction nodes come from
processing instructioninformation items. The local part of the expanded name of the node comes from thetargetproperty. The string value of the node comes from thecontentproperty.Comment nodes come from
commentinformation items. The string value of the node comes from thecontentproperty.Namespace nodes come from a
namespacedeclaration information item. The local part of the expanded-name of the node comes from theprefixproperty. The string value of the node comes from thenamespaceURI property.
In fact, one of the tasks of XPath 2.0 was to reconcile the data models used in XPath and the XML Infoset specifications, and we'll discuss that later in Chapter 7.
There's another popular way of looking at the data in an XML document—the Document Object Model (DOM). If you've done any programming that extracted data from XML documents, you're probably familiar with the DOM, because the DOM specifies a set of programming objects and functions that lets you work with the data in an XML document (the DOM objects are implemented in programming languages like JavaScript and Java). You can find more information on the DOM at www.w3.org/DOM/DOMTR.
Like the XPath data model, the DOM lets you consider an XML document as a tree of nodes, although these nodes are not exactly the same as in XPath. Here are the node types in the DOM:
Element
Attribute
Text
CDATA section
Entity reference
Entity
Processing instruction
Comment
Document
Document type
Document fragment
Notation
Each of these node types corresponds to a programming object with its own methods that let you navigate from node to node or recover the text in a node.
In an attempt to reconcile the data model in the DOM with XPath 1.0, W3C created a version of XPath called “Document Object Model XPath,” and you can find it at www.w3.org/TR/DOM-Level-3-XPath/. The idea was to support the creation of XPath functions that would work with standard DOM objects—in other words, to let you work with a DOM tree of nodes using XPath functions. To do that, the DOM version of XPath connects DOM and XPath nodes by first treating XPath nodes in terms of infosets.
The DOM XPath specification is now in Candidate Recommendation status, and you can read all about it at www.w3.org/TR/DOM-Level-3-XPath/. It's never really become very popular, however, because most people consider it just an interim way of relating the XPath and DOM models.
In fact, as you can see, the situation with XPath 1.0, XML infosets, and the DOM data models is a problem because each of these data models is different. W3C has worked on bringing things together in XPath 2.0, however, with the XPath 2.0 data model (more properly called the W3C XQuery 1.0 and XPath 2.0 Data Model). The XPath 2.0 data model forms the basis of data models for a number of XML-related specification—XPath and others, such as XSLT and XQuery. In this way, W3C is doing what it should have done from the beginning—creating one standard data model that will let you treat the data in an XML document as a tree of nodes. More on the XPath 2.0 data model in Chapter 7.
There are four data types in XPath 1.0:
Numbers
Strings
Booleans
Node-sets
These node types are supported in XPath 1.0:
The root node
Element nodes
Attribute nodes
Processing instruction nodes
Comment nodes
Text nodes
Namespace nodes
Here are some additional concepts from this chapter:
Document order is the order of nodes as they appear in the original document.
Documents are handled by XML processors as node trees.
Infosets hold the data that an XML document contains in standard form.