
Chapter 14. Creating and Configuring VMware Clusters
This chapter covers the following subjects:
![]() DRS Virtual Machine Entitlement
DRS Virtual Machine Entitlement
![]() Creating/Deleting a DRS/HA Cluster
Creating/Deleting a DRS/HA Cluster
![]() Adding or Removing Virtual Machines
Adding or Removing Virtual Machines
![]() Configuring VM Component Protection
Configuring VM Component Protection
![]() Configuring Migration Thresholds for DRS and Virtual Machines
Configuring Migration Thresholds for DRS and Virtual Machines
![]() Configuring Admission Control for HA and Virtual Machines
Configuring Admission Control for HA and Virtual Machines
![]() Determining Appropriate Failover Methodology and Required Resources for HA
Determining Appropriate Failover Methodology and Required Resources for HA
The good news that goes with enterprise data center virtualization is that you can use fewer physical machines because you can host many virtual servers on one physical machine. That’s good news with regard to resource utilization, space utilization, power costs, and so on. However, it does mean that you have all, or at least a lot, of your “eggs in one basket.” In other words, what would happen if your physical machine that is hosting many of your virtual servers should fail? You probably don’t want to leave that up to chance. In this chapter, you learn about creating and administering clusters of physical servers that can keep watch over each other and share the load. In addition, you see how you can configure those clusters to share their resources so that all the VMs on them benefit.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should read this entire chapter or simply jump to the “Exam Preparation Tasks” section for review. If you are in doubt, read the entire chapter. Table 14-1 outlines the major headings in this chapter and the corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes and Chapter Review Questions.”

1. Which of the following will occur on a cluster that is undercommitted for resources? (Choose two.)
a. A VM will be capped only by its available memory setting.
b. A VM will be capped by its available memory setting or its limit, whichever is higher.
c. A VM will be capped by its available memory setting or its limit, whichever is lower.
d. A VM with no limit will receive whatever it demands for memory.
2. Which of the following are true in regard to creating a DRS/HA cluster? (Choose two.)
a. After you create a host outside of a cluster, you cannot join it to a cluster.
b. You can join a host that is already on a vCenter to a cluster by dragging and dropping it.
c. You can join a host to your vCenter and install it into the cluster at the same time.
d. After you create a cluster, you must enable both HA and DRS at a minimum.
3. What does it mean to “graft in” a host’s resource settings when you create a cluster?
a. You are adding a host that is not ESXi 6.0.
b. You are using DRS but not HA.
c. You are maintaining the hierarchy that was set by the host’s Resource Pools.
d. You will add the host only for a temporary project.
4. If you have clicked on a cluster in the Navigator, which tab would you click next to expose the Virtual Machines tab?
a. Manage
b. Monitor
c. Summary
d. Related Objects
5. Which of the following is an optional parameter for Storage DRS configuration?
a. Capacity
b. I/O performance
c. CPU
d. Memory
6. Which of the following are true regarding storage event types? (Choose two.)
a. A PDL occurs when a storage array issues a SCSI sense code that informs the host that the storage array is down.
b. An APD occurs when a storage array issues a SCSI sense code that informs the host that the storage array is down.
c. Only PDLs have a timeout setting, not APDs.
d. Only APDs have a timeout setting, not PDLs.
7. Which of the following are true regarding configuring migration thresholds in DRS?
a. A setting that is too conservative may cause the VMs to move more often than might be necessary.
b. A setting that is too aggressive may cause the VMs to move more often than might be necessary.
c. The most aggressive setting is 5, farthest to the right.
d. The least aggressive setting is 5, farthest to the right.
8. Which of the following are true regarding HA Admission Control settings? (Choose two.)
a. Percentage of Cluster Resources Reserved as Failover Spare Capacity uses a slot size that might allow fewer VMs to be started versus other options.
b. Specify failover hosts is the best practice preferred method because it uses passive standby hosts.
c. You can specify a different percentage for CPU versus memory when you use the Define Failover Capacity by Reserving a Percentage of the Cluster Resources setting.
d. The Define Failover Capacity by Reserving a Percentage of the Cluster Resources method can be configured for a cluster of up to 64 hosts.
9. Which of the following are true regarding admission control for HA?
a. In most cases you should use the Do Not Reserve Failover Capacity setting.
b. You should use the Do Not Reserve Failover Capacity setting only as a temporary override.
c. The Do Not Reserve Failover Capacity setting will free up resources that would otherwise be reserved.
d. The Do Not Reserve Failover Capacity setting has no effect on resources available to start VMs.
10. Which of the following is true regarding the various methods of Admission Control Policy?
a. Disabling Admission Control frees up the most resources and should be used whenever possible.
b. Host failures that a cluster will tolerate can be constricting to resources because of its conservative slot size.
c. Disabling Admission Control should be used only as a temporary override to another policy.
d. Percentage of cluster resources can be constricting to resources because of its conservative slot size.
Foundation Topics
When you decide to create a cluster by combining the resources of two or more hosts (physical servers), you are generally doing it primarily for one or both reasons: Distributed Resource Scheduler (DRS) and/or High Availability (HA). This section discusses many aspects of both of these vSphere features and how they can improve the reliability, performance, and survivability of your VMs. In particular, you learn about DRS VM entitlement, creating and deleting DRS/HA clusters, and adding/removing VMs from a cluster. In addition, you learn about features that were new to vSphere 5.x and some that are new to vSphere 6 that ensure the survivability and continued performance of your VMs. Finally, enabling and configuring the many aspects of DRS and HA are covered so that you can take advantage of automatic restarts of VMs when needed and load balancing of VMs on an ongoing basis.
Note
Even though the hosts in my lab environment are named with a somewhat legacy name of “esx,” rest assured that they are all vSphere 6 ESXi hosts. Old habits die hard!
DRS Virtual Machine Entitlement
All the VMs that are in the same cluster are using everything at their disposal to fight for the RAM (physical memory from the hosts) that they need to satisfy the expectations of their guest OS and applications. When a cluster is undercommitted (has plenty of physical memory), each VM’s memory entitlement will be the same as its demand for memory. It will be allocated whatever it asks for, which will be capped by its configured limit if that is lower than its available memory setting.
Now, what happens if the cluster becomes overcommitted (less physical memory than demand)? That’s an important question to answer, because when there isn’t enough physical RAM to go around, some VMs are going to have to use their swap file (at least in some portion), which means their performance will take a hit because using memory from a disk is much slower than using physical RAM. So, how does the VMkernel decide which VMs take priority and which VMs will be forced to use their swap file?
When the cluster is overcommitted, DRS and the VMkernel work together to allocate resources based on the resource entitlement of each VM. This is based on a variety of factors and how they relate to each other. In a nutshell, it is based on configured shares, configured memory size, reservations, current demands on the VMs and the Resource Pools that contain them, and on the working set (active utilization of the VM at a particular point in time). In Chapter 20, “Performing Basic Troubleshooting of ESXi and vCenter Server,” you learn much more about DRS and its capability to control and balance resources while providing you with troubleshooting information.
Creating/Deleting a DRS/HA Cluster
After you have connected to your vCenter Server with your vSphere Client, creating a cluster is simply a matter of adding the Cluster inventory object, dragging your ESXi hosts into it, and configuring the options that you need. You can independently configure options for DRS, HA, and other related settings. To create a DRS/HA cluster, follow the steps outlined in Activity 14-1.

Activity 14-1 Creating a DRS/HA Cluster
1. Log on to your vSphere Web Client.
2. Select Home and then Hosts and Clusters.
3. Right-click your data center and select New Cluster, as shown in Figure 14-1.

4. Enter a name for your new cluster and then select to Turn ON vSphere HA and/or Turn ON DRS, and then click OK, as shown in Figure 14-2. You can also enable EVC and vSAN.

5. You can then select what else to configure in the left pane by opening each arrow. Separate settings will be available for each feature of your cluster.
Adding/Removing ESXi Hosts
After you have created a cluster, you can use the tools to add hosts to your cluster, or you can drag and drop the hosts into the cluster. Adding a host to a cluster is like creating a “giant computer.”
Note
Before the host was in the cluster, you might have established a hierarchy of Resource Pools on the host. In this case, when you add the host to a cluster, the system asks if you want to “graft” that hierarchy into the cluster or start a new hierarchy in the new cluster. This is an important decision and not just one regarding what the inventory will look like when you get done. If you have created Resource Pools on your host, and you want to retain that hierarchy, you will need to “graft” it in; otherwise, all the Resource Pools will be deleted when you add the host to the cluster.
To add a new host to a new cluster, follow the steps outlined in Activity 14-2.
Activity 14-2 Adding a Host to a Cluster
1. Log on to your vSphere Web Client.
2. Select Home and then Hosts and Clusters.
3. Right-click your cluster and select Add Host, as shown in Figure 14-3.

4. Enter the IP address or fully qualified domain name (FQDN) of the host that you want to add, as shown in Figure 14-3. If the host is not currently in your vCenter, this will likely be a root account or an account with root privileges. If the host is already member of your vCenter, the credentials are not required, and you could just drag and drop the host into the cluster. In this case, I am assuming that I’m adding a newly created host, host esx60a, to my newly created Lab Cluster.
5. Enter the credentials for the host as it sits right now, out of the cluster (in this case “root”), as shown in Figure 14-4. Click Next.
6. Verify that you are adding the right host, as shown in Figure 14-5. Click Next.

7. In the Assign License screen, you can assign a license that you have already entered or add a new license. You can also elect to use the 60-day evaluation mode, as shown in Figure 14-6.

8. Choose whether or not to enable lockdown mode. Beginning with vSphere 6, you have two levels of lockdown mode from which to choose—normal or strict—as shown in Figure 14-7.

9. Review the Ready to Complete page and click Finish, as shown in Figure 14-8.
You might think that removing a host from a cluster would be as simple as dragging it out, but that would not be wholly correct. If you have been using a host within a cluster for any time at all, you will likely have VMs on the host. You will first need to either migrate all the VMs off the host or shut them down. You can begin this process by entering Maintenance Mode.
When you place a host in Maintenance Mode, you are in essence telling the rest of the hosts in the cluster that this host is “closed for new business” for now. When a host enters Maintenance Mode, no VMs will be migrated to that host, you cannot power on any new VMs, and you cannot make any configuration changes to existing VMs. With the proper configuration of DRS (which is discussed later in the section “Configuring Automation Levels for DRS and Virtual Machines”), all the VMs that can use vMotion to “automatically migrate” will immediately do so. You then decide whether to shut down the others and move them to another host, or just leave them on the host that you are removing from the cluster. Figure 14-9 shows a newly configured two-host cluster.

After you have made these preparations, it is a matter of reversing the steps covered earlier. In fact, the easiest way to remove a host from a cluster after the host is in Maintenance Mode is to drag the host object back to the data center. More specifically, to remove a host from an existing cluster, follow the steps outlined in Activity 14-3.
Activity 14-3 Removing a Host from a Cluster
1. Log on to your vSphere Client.
2. Select Home and then Hosts and Clusters.
3. Right-click the host that you want to remove and select Enter Maintenance Mode, as shown in Figure 14-10.

4. Confirm that you want to enter Maintenance Mode, and select whether you want to also move powered-off and suspended VMs to other hosts in the cluster, and then click OK, as shown in Figure 14-11. If you choose not to move the VMs, they will be “orphaned” while the host is in Maintenance Mode because they will logically remain on that host.
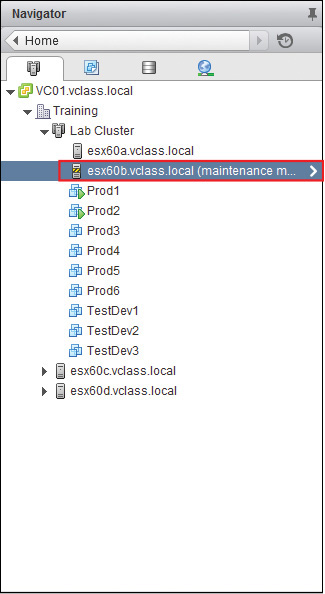
5. Click and hold the host that you want to remove from the cluster and drag the host to another inventory object, such as your data center or a folder that is higher in the hierarchy than the cluster. Figure 14-12 shows esx60b.vclass.local in Maintenance Mode.
Adding or Removing Virtual Machines
As I said earlier, after you have created a cluster, in essence you have a giant computer that combines the aggregate resources of the hosts in the cluster. Notice that I didn’t say “super computer.” You can’t total up all the resources in a large cluster and assign them all to one VM and then play Jeopardy with it! In fact, a VM will always take all its CPU and memory from one host or another, depending on where it is powered on and whether it has been migrated to another host. You will, however, have larger pools of resources from which you can create more VMs or larger VMs.
Adding or removing a VM with regard to the cluster is no different than with a host. In other words, you can start by dragging and dropping the VM to the appropriate place in your hierarchy, whether that place happens to be a host in a cluster or a host that is not in a cluster. In Chapter 17, “Migrating Virtual Machines,” this is discussed in much greater depth.
To determine which of your VMs are in a specific cluster, you can click the cluster in the Navigator (left pane), then on the Related Objects tab, and finally on the Virtual Machines tab, as shown in Figure 14-13.

Configuring Storage DRS
As your network grows, you need to use your resources in the most efficient manner, so having a tool that balances the loads of VMs across the hosts is very useful. If you’ve configured it properly, DRS does a wonderful job of balancing the loads of the VMs by using algorithms that take into account the CPU and the memory of the VMs on each host. This has the effect of strengthening two of the critical resources on each VM, namely CPU and memory.
If CPU and memory were the only two resources on your VMs, this would be the end of the story, but you also have to consider network and storage. Because networking was covered in Chapters 4 and 5, we’ll focus on storage. As you know, the weakest link in the chain will determine the strength of the chain. By the same logic, if you took great care to provide plenty of CPU and memory to your VMs, but you starved them with regard to storage, the end result might be poorly performing VMs.
Too bad you can’t do something with storage that’s similar to what DRS does with CPU and memory; but wait, you can! What if you organized datastores into datastore clusters made of multiple datastores with the same characteristics? Then, when you created a VM, you would place the VM into the datastore cluster, and the appropriate datastore would be chosen by the system based on the available space on the logical unit numbers (LUNs) of each datastore and on the I/O performance (if you chose that, too). Better yet, in the interim, the datastore cluster would monitor itself and use Storage vMotion whenever necessary to provide balance across the datastore cluster and to increase the overall performance of all datastores in the datastore cluster.
This is what Storage DRS (SDRS) can do for your virtual data center. When you set it up, you choose whether to take I/O into consideration with regard to automated Storage vMotions, and it always takes the available storage into consideration. After you have configured it, SDRS runs automatically and, in a very conservative way (so as not to use Storage vMotion resources too often), maintains balance in the datastore clusters that you have configured. This results in an overall performance increase in “storage” for your VMs to go right along with the performance increases in CPU and memory that DRS has provided—a nice combination.
To configure SDRS, you first create the datastore clusters. This configuration includes selecting the automation level and runtime rules for the cluster, as well as selecting the datastores that you will include in the cluster. The datastores should have equal capabilities so that one is “as good as the other” to the SDRS system. To create an SDRS datastore cluster, follow the steps outlined in Activity 14-4.
Activity 14-4 Creating and Configuring an SDRS Datastore Cluster
1. Log on to your vSphere Web Client.
2. Select Home and then Storage, as shown in Figure 14-14.
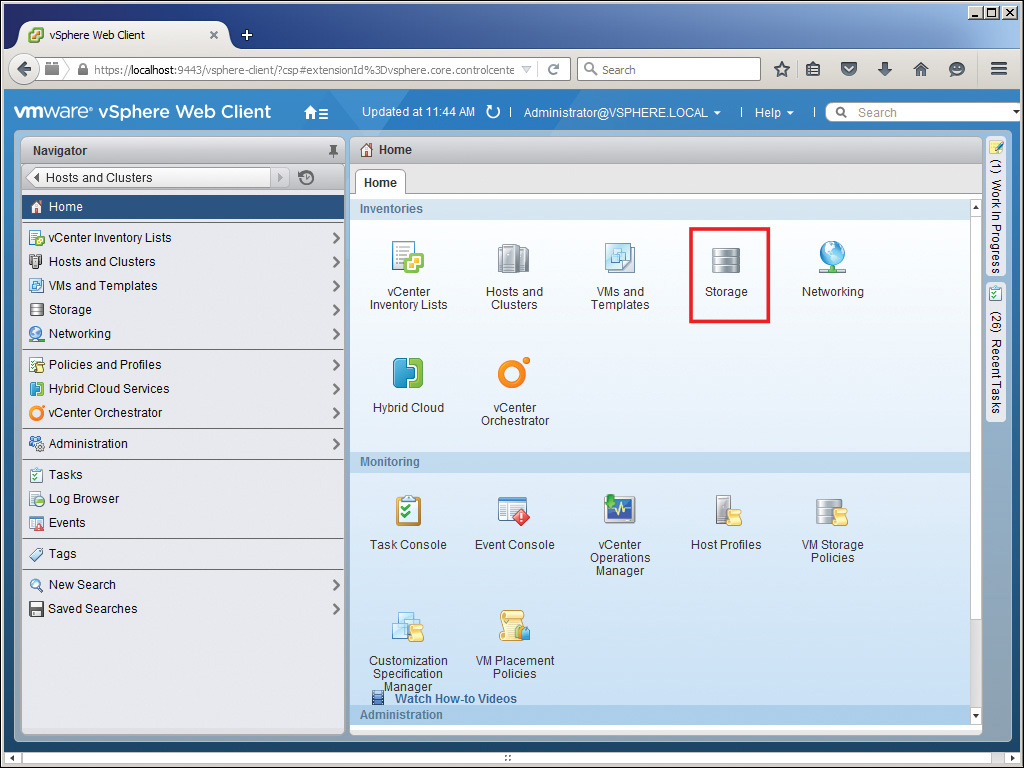
3. Right-click the data center in which you want to create the datastore cluster and select Storage and then New Datastore Cluster, as shown in Figure 14-15.

4. On the General page, enter a name for your datastore cluster and leave the check box selected to Turn ON Storage DRS, as shown in Figure 14-16, and click Next. (If you are creating the datastore cluster for future use but not for immediate use, you can uncheck the Turn ON Storage DRS box.)
5. From SDRS Automation, select the automation level for your datastore cluster in regard to space, I/O balance, rules, policy enforcement, and VM evacuation, and click Next, as shown in Figure 14-17. Selecting No Automation will only provide recommendations and will not cause the system to use Storage vMotion on your VM files without your intervention. The Fully Automated setting will use Storage vMotion to migrate VM files as needed based on the loads and on the rest of your configuration.

6. From SDRS Runtime Rules, select whether you want to enable I/O Metric Inclusion. This is available only when all the hosts in the datastore cluster are at least ESXi 5.x. Select the DRS thresholds for Utilized Space and I/O Latency. You can generally leave these at their default settings, at least to get started. There is also an Advanced Options setting, as shown in Figure 14-18, that you can almost always leave at the default but that you can tweak if needed. When you are finished with all these settings, click Next to continue.

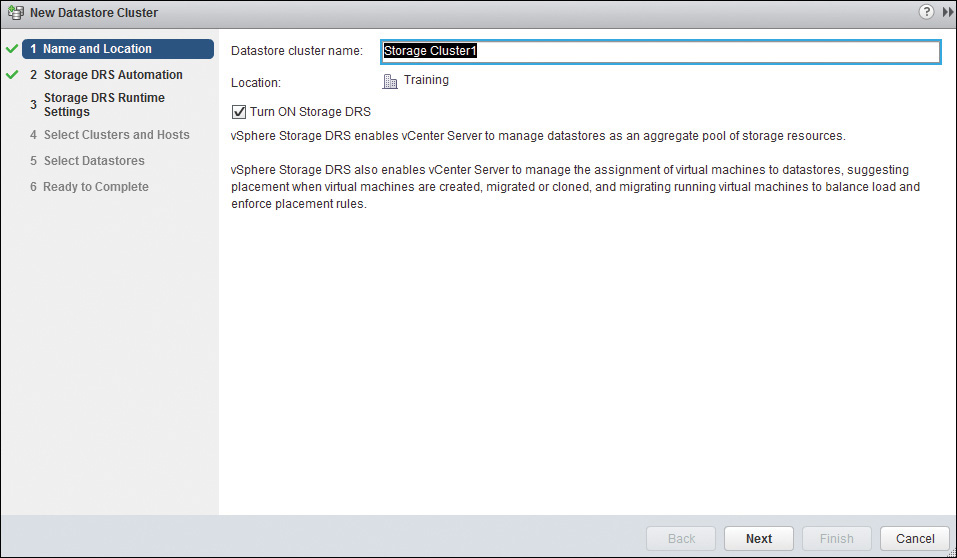
7. Select the Hosts and Clusters that you want to include in your datastore cluster, as shown in Figure 14-19, and click Next.
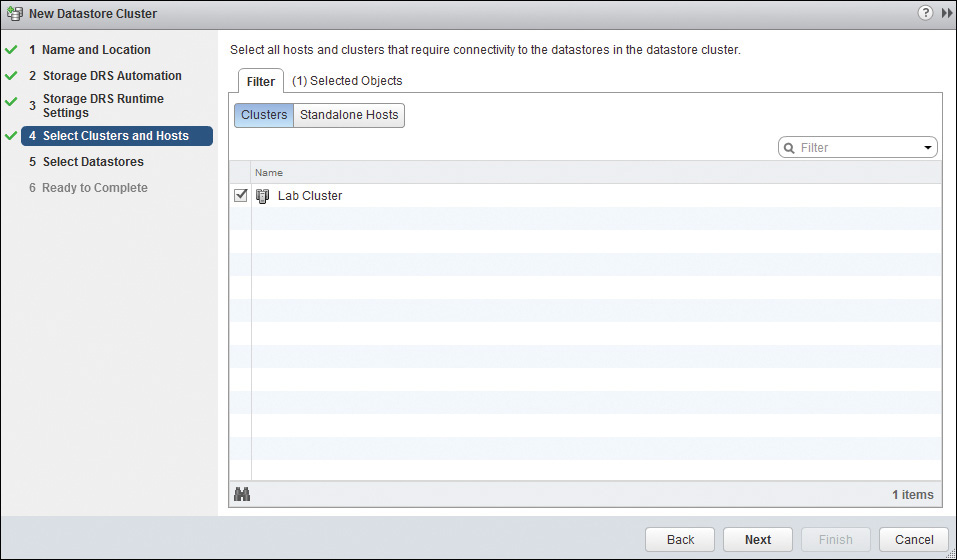
8. Select the datastores that you want to include in your datastore cluster and click Next. The status of each datastore will be listed along with its capacity, free space, and so on. If the datastore does not have a connection to all the hosts you have chosen, it will be indicated in the Host Connection Status, as shown in Figure 14-20.
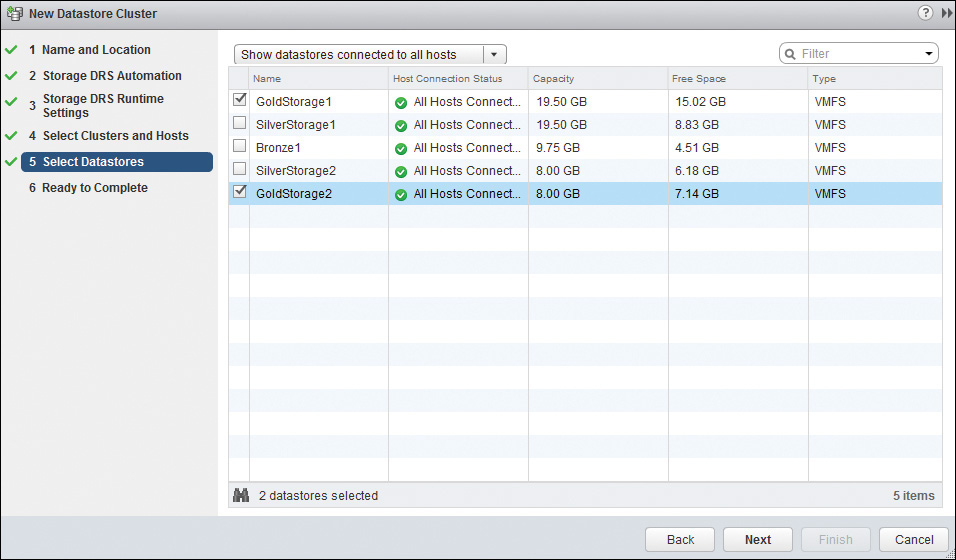
9. On the Ready to Complete page, you can review your selections, address any configuration issues, and then click Finish, as shown in Figure 14-21.

10. Monitor your inventory and the Recent Tasks pane for the creation of your new datastore cluster, as shown in Figure 14-22.

Configuring VM Component Protection
As you probably know, vSphere HA has always been good for restarting your VMs on a new host when the current host is down or has lost connectivity to the network. However, what if the host is not down and has not lost connectivity to the network but has lost connectivity to the storage that it was providing the VM? Earlier versions of vSphere provided some configuration for this event on the command line only, but vSphere 6 makes this additional protection available with a single click, as shown in Figure 14-23.

There are two types of storage events for which VM Component Protection can monitor and react, each of which could cause a VM to be unusable because it can no longer reach its storage:
![]() Permanent Device Loss (PDL): A PDL occurs when a storage array issues a SCSI sense code informing that the device is unavailable. This might happen if a LUN were to fail on a storage array or if an administrator inadvertently removed critical storage configuration, such as a WWN from a zone configuration. When a host receives this type of code, it ceases sending I/O requests to that array.
Permanent Device Loss (PDL): A PDL occurs when a storage array issues a SCSI sense code informing that the device is unavailable. This might happen if a LUN were to fail on a storage array or if an administrator inadvertently removed critical storage configuration, such as a WWN from a zone configuration. When a host receives this type of code, it ceases sending I/O requests to that array.
![]() All Paths Down (APD): An APD event is different from a PDL because the host cannot reach the storage, but no PDL SCSI code is received either. For this reason, the host does not “know” whether the disconnection is temporary or whether it might continue for some time. The host will therefore continue to try the storage until a set timeout is reached. This timeout value is 140 seconds by default and can be changed using the Misc.APDTimeout advanced setting.
All Paths Down (APD): An APD event is different from a PDL because the host cannot reach the storage, but no PDL SCSI code is received either. For this reason, the host does not “know” whether the disconnection is temporary or whether it might continue for some time. The host will therefore continue to try the storage until a set timeout is reached. This timeout value is 140 seconds by default and can be changed using the Misc.APDTimeout advanced setting.
Now that you understand what could happen, you might be asking what VMCP is going to do about it. That’s pretty much up to you and how you configure it. You can configure each type of event independently, in regard to whether it’s enabled and what actions it will take for your VMs. When you change the configuration, a table is automatically created that illustrates your configuration and its result, as shown in Figure 14-24.
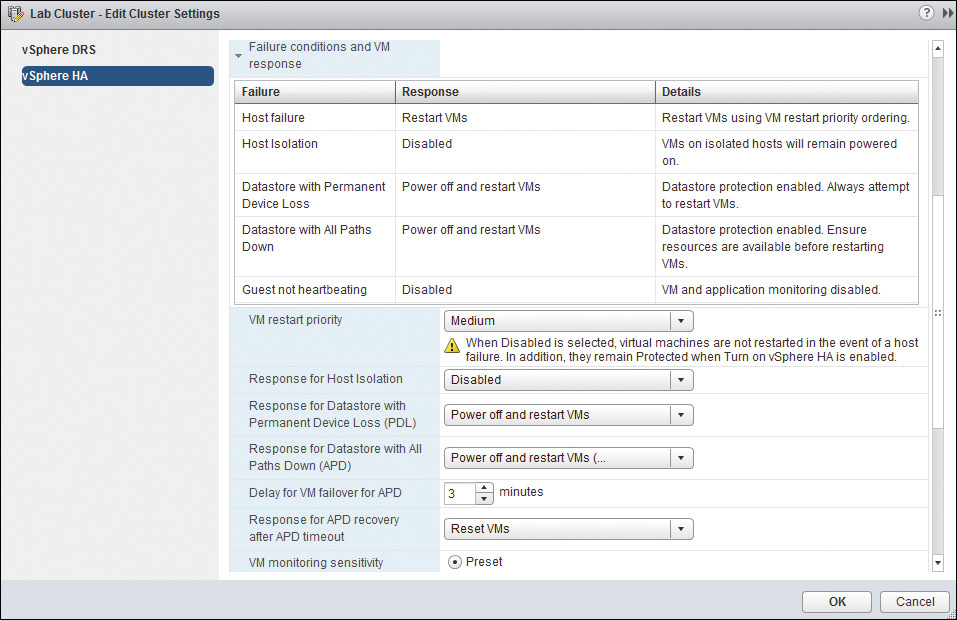
Some of these settings require a little more explanation, so each of them is described separately.
![]() Response for Datastore with Permanent Device Loss (PDL): This setting has three options:
Response for Datastore with Permanent Device Loss (PDL): This setting has three options:
![]() Disabled means that no action will be taken and no notification will be sent to the administrator.
Disabled means that no action will be taken and no notification will be sent to the administrator.
![]() The Issue Events setting will notify the administrator that a PDL has occurred, but no action will be taken for the VMs.
The Issue Events setting will notify the administrator that a PDL has occurred, but no action will be taken for the VMs.
![]() The Power Off and Restart VMs setting will attempt to restart the VMs on a host that still has connectivity to the storage device.
The Power Off and Restart VMs setting will attempt to restart the VMs on a host that still has connectivity to the storage device.
![]() Response for Datastore with All Paths Down (APD): This setting has four options:
Response for Datastore with All Paths Down (APD): This setting has four options:
![]() Disabled means that no action will be taken.
Disabled means that no action will be taken.
![]() Issue events will notify the administrator but take no further action.
Issue events will notify the administrator but take no further action.
![]() Power Off and Restart VMs (conservative) will not attempt to restart the VMs until it has determined that there is another host that has the needed storage and the compute capacity to restart the VMs. It does this by communicating with the master host. If it cannot communicate with the master host, no further action will be taken. The assumption is that “the grass may not be greener on the other side of the fence.”
Power Off and Restart VMs (conservative) will not attempt to restart the VMs until it has determined that there is another host that has the needed storage and the compute capacity to restart the VMs. It does this by communicating with the master host. If it cannot communicate with the master host, no further action will be taken. The assumption is that “the grass may not be greener on the other side of the fence.”
![]() Power Off and Restart VMs (aggressive), by contrast, will terminate the connection of the affected VMs in the “hopes” that another host that has the needed storage will have the compute capacity as well. The assumption is that “anyplace else is better than here.”
Power Off and Restart VMs (aggressive), by contrast, will terminate the connection of the affected VMs in the “hopes” that another host that has the needed storage will have the compute capacity as well. The assumption is that “anyplace else is better than here.”
![]() Delay of VM Failover for APD: This one is tricky because it’s not the same as the timeout, but instead an additional timer is added to the timeout. As mentioned earlier, the default for the timeout value is 140 seconds. However, the default for the delay timer is an additional 3 minutes. The end result is (with default settings) that VMCP will not begin taking action in regard to an APD event for 5 minutes and 20 seconds—the sum of the timeout and the delay. This total figure is also known as the VMCP Timeout.
Delay of VM Failover for APD: This one is tricky because it’s not the same as the timeout, but instead an additional timer is added to the timeout. As mentioned earlier, the default for the timeout value is 140 seconds. However, the default for the delay timer is an additional 3 minutes. The end result is (with default settings) that VMCP will not begin taking action in regard to an APD event for 5 minutes and 20 seconds—the sum of the timeout and the delay. This total figure is also known as the VMCP Timeout.
![]() Response for APD Recovery After APD Timeout: This is what you are configuring to happen if the storage event clears after the timeout expires but before the additional delay expires. There are two options. Disabled means that no additional action will be taken, with the assumption that the VMs will now be able to connect to the storage as before. Reset VMs will cause a hard reset of the VMs to ensure that they can connect the storage. This will cause a temporary outage that might not have been necessary if the VMs were able to connect without it, but it will ensure that they have the best chance going forward.
Response for APD Recovery After APD Timeout: This is what you are configuring to happen if the storage event clears after the timeout expires but before the additional delay expires. There are two options. Disabled means that no additional action will be taken, with the assumption that the VMs will now be able to connect to the storage as before. Reset VMs will cause a hard reset of the VMs to ensure that they can connect the storage. This will cause a temporary outage that might not have been necessary if the VMs were able to connect without it, but it will ensure that they have the best chance going forward.
Configuring Migration Thresholds for DRS and Virtual Machines
DRS uses algorithms to balance the loads of VMs based on the CPU and memory resources that they are using on a host. The main premise is that by balancing the resources across the hosts, you can improve the overall performance of all the VMs, especially when the physical resources of CPU and memory are much more heavily used on one host than on another. When this occurs, DRS can use vMotion to automatically move the state of one or more VMs on one host to another host. Moving the state of the VMs means moving them to another physical place (host). As an alternative, DRS can also just make recommendations to move the VMs, which you can then read and follow.
If you decide to let DRS in essence read its own recommendations and then automatically migrate the VMs (this is a called Fully Automated Mode, and it is discussed next), the question then becomes, “How far off balance does the resource usage have to be to create a situation where a migration is actually performed?” The answer to this question can be configured in the Migration Threshold setting for DRS on the cluster, as shown in Figure 14-25. If you configure this setting too conservatively, you might not get the balance that you desire, but if you configure it too aggressively, any imbalance might cause a system to use vMotion to migrate the VMs and thereby use resources needlessly.

To help you make the right decision, the Migration Threshold slider control identifies five settings and the expected impact of that setting. You should read over each of the settings and make the choice that will work best for you. The settings on the Migration Threshold are as follows:
![]() Setting 1: This is the left-most setting on the slider and the most conservative. It will apply only the most important, Priority 1, recommendations. As indicated below the slider, these recommendations “must be taken to satisfy cluster constraints like affinity rules and host maintenance.”
Setting 1: This is the left-most setting on the slider and the most conservative. It will apply only the most important, Priority 1, recommendations. As indicated below the slider, these recommendations “must be taken to satisfy cluster constraints like affinity rules and host maintenance.”
![]() Setting 2: One notch to the right from Setting 1, this will apply only Priority 1 and Priority 2 recommendations. These are deemed by the vCenter, based on its calculations, to “promise a significant improvement to the cluster’s load balance.”
Setting 2: One notch to the right from Setting 1, this will apply only Priority 1 and Priority 2 recommendations. These are deemed by the vCenter, based on its calculations, to “promise a significant improvement to the cluster’s load balance.”
![]() Setting 3: One more over to the right, this will apply Priority 1, 2, and 3 recommendations. These “promise at least good improvement to the cluster’s load balance.”
Setting 3: One more over to the right, this will apply Priority 1, 2, and 3 recommendations. These “promise at least good improvement to the cluster’s load balance.”
![]() Setting 4: One more to the right, as you can imagine, this one applies Priority 1, 2, 3, and 4 recommendations. These are expected to “promise even a moderate improvement to the cluster’s load balance.”
Setting 4: One more to the right, as you can imagine, this one applies Priority 1, 2, 3, and 4 recommendations. These are expected to “promise even a moderate improvement to the cluster’s load balance.”
![]() Setting 5: Farthest to the right and most aggressive, this setting will apply recommendations that “promise even a slight improvement to the cluster’s load balance.”
Setting 5: Farthest to the right and most aggressive, this setting will apply recommendations that “promise even a slight improvement to the cluster’s load balance.”
Configuring Automation Levels for DRS and Virtual Machines
You might think that this was already covered in the previous paragraphs, but that would not be totally correct. In addition to making the recommendations and decisions with regard to balancing cluster loads, DRS is involved with choosing the host to which the VM is powered on in the first place. This is referred to as initial placement. Because of this, there are three automation levels you can choose from when you configure DRS for your cluster. Each level addresses who will decide initial placement and, separately, who will decide on load balancing, you or DRS? The three possible DRS automation levels you can choose from, also shown in Figure 14-25, are the following:
![]() Manual: In this mode, vCenter will only make recommendations about initial placement and load balancing. You can choose to accept the recommendation, accept some of them (if there are more than one at a time), or ignore them altogether. For example, if vCenter makes a recommendation to move a VM and you accept it, DRS will use vMotion (if configured) to migrate the VM while it’s powered on, with no disruption in service.
Manual: In this mode, vCenter will only make recommendations about initial placement and load balancing. You can choose to accept the recommendation, accept some of them (if there are more than one at a time), or ignore them altogether. For example, if vCenter makes a recommendation to move a VM and you accept it, DRS will use vMotion (if configured) to migrate the VM while it’s powered on, with no disruption in service.
![]() Partially Automated: In this mode, vCenter will automatically choose the right host for the initial placement of the VM. There will be no recommendations with regard to initial placement. In addition, vCenter will make recommendations with regard to load balance in the cluster, which you can choose to accept, partially accept, or ignore.
Partially Automated: In this mode, vCenter will automatically choose the right host for the initial placement of the VM. There will be no recommendations with regard to initial placement. In addition, vCenter will make recommendations with regard to load balance in the cluster, which you can choose to accept, partially accept, or ignore.
![]() Fully Automated: As you might expect, this setting allows vCenter to make all the decisions on your behalf. These include initial placement and load balance. DRS uses algorithms to generate recommendations and then “follow its own advice” based on the Migration Threshold, as discussed earlier. This mode also ensures that all VMs that are compatible for vMotion will automatically migrate when you place your host in Maintenance Mode.
Fully Automated: As you might expect, this setting allows vCenter to make all the decisions on your behalf. These include initial placement and load balance. DRS uses algorithms to generate recommendations and then “follow its own advice” based on the Migration Threshold, as discussed earlier. This mode also ensures that all VMs that are compatible for vMotion will automatically migrate when you place your host in Maintenance Mode.
Now, you might be thinking that these cluster settings will be fine for most of your VMs, but that some VMs are different, and you need more flexibility in their settings. For example, what if you have a VM that is connected to a serial security dongle on a single host and, therefore, will need to stay on that host? If you are in Manual Mode, will you have to constantly answer those recommendations? If you are in Fully Automated Mode, can it ignore that one?
Thankfully, there are DRS settings for each of the VMs in your cluster. These Virtual Machine Options settings default to the cluster setting unless you change them, as shown in Figure 14-26. For example, the setting that would be best for the security dongle scenario would be Disabled, which does not disable the VM but rather disables DRS for the VM and therefore does not create recommendations. To make this available, you must first enable the option by checking the box labeled Enable Individual Virtual Machine Automation Levels, as shown previously in Figure 14-25. After this is done, you can configure the individual VMs in the VM Overrides section under Manage, Settings for the cluster, as shown in Figure 14-27.


Configuring Admission Control for HA and Virtual Machines
vSphere HA provides for the automatic restart of VMs on another host when the host on which they are running has failed or has become disconnected from the cluster. If you think about it, how could the other hosts help out in a “time of crisis” if they themselves had already given all of their resources to other VMs? The answer is, they couldn’t! For this reason, Admission Control settings cause a host to “hold back” some of its resources by not allowing any more VMs to start on a host so that it can be of assistance if another host should fail. The amount of resources held back is up to you. In fact, this is the central question that you are answering when you configure Admission Control for HA.
This section discusses two topics: Admission Control and Admission Control Policy. As shown in Figure 14-28, Admission Control Policy can be configured in a few ways. First, Admission Control is discussed in general, followed by the finer points of configuring Admission Control Policy.
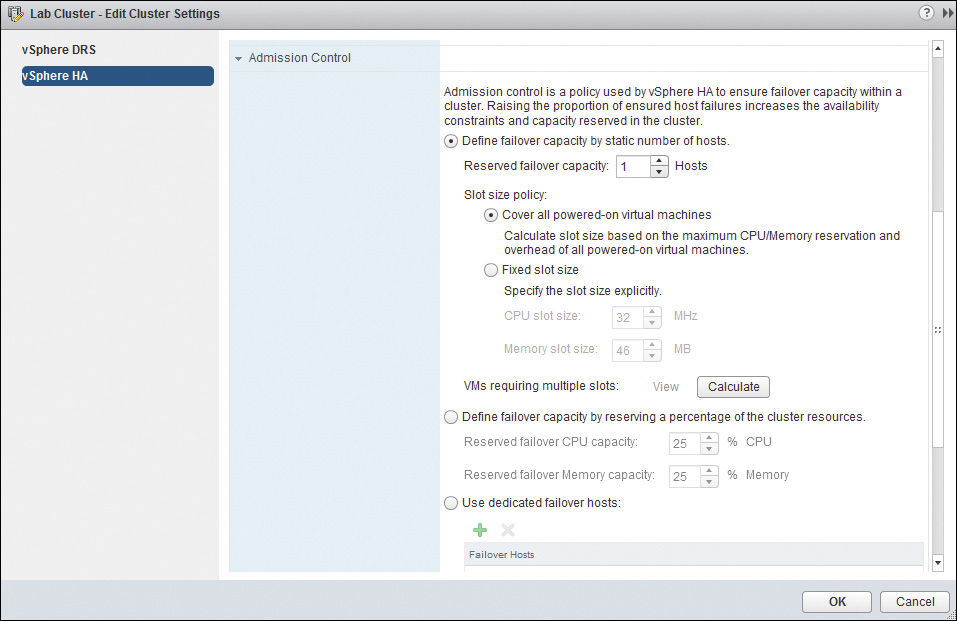
Admission Control
In most cases, you want to make sure that Admission Control is enabled by your Admission Control Policy setting. In some unusual cases, when you need to start a critical VM and the system won’t let you, you can use the Do Not Reserve Failover Capacity option to temporarily override the HA Admission Control and get the VM started. If you do this, you should address the real resource issue and enable Admission Control as soon as possible. It is not a best practice to leave Admission Control disabled.
Admission Control Policy
You can choose between three options for Admission Control Policy. The central question is this: “If HA is supposed to make the hosts save enough resources so that VMs on a failed host can be restarted on the other hosts, how is it supposed to know how much to save?” When you configure Admission Control Policy, you answer two questions. First, how many hosts will I “allow” to fail and still know that the VMs on the failed hosts can be restarted on the remaining hosts? Second, how will I tell HA how to calculate the amount of resources to “hold back” on each host?
The following is a brief description of each of the three Admission Control Policies:
![]() Define failover capacity by static number of hosts: This setting is configurable from 1–31, although, in most cases, you probably wouldn’t configure it any higher than 2. This policy is the oldest of the three and is sometimes used in organizations today, although it might no longer be considered the favorite. It relies on a “slot size,” which is a calculation that it determines to be an estimate of CPU and memory needs for every VM in the cluster. A setting of 2 means that two hosts could fail at the same time in a cluster and all the VMs that are on the failed hosts could be restarted on the remaining resources of the other hosts in the cluster. You can imagine the additional resources that would have to be “held back” to allow for this setting. In most cases, organizations use a setting of 1, unless they are configuring very large clusters.
Define failover capacity by static number of hosts: This setting is configurable from 1–31, although, in most cases, you probably wouldn’t configure it any higher than 2. This policy is the oldest of the three and is sometimes used in organizations today, although it might no longer be considered the favorite. It relies on a “slot size,” which is a calculation that it determines to be an estimate of CPU and memory needs for every VM in the cluster. A setting of 2 means that two hosts could fail at the same time in a cluster and all the VMs that are on the failed hosts could be restarted on the remaining resources of the other hosts in the cluster. You can imagine the additional resources that would have to be “held back” to allow for this setting. In most cases, organizations use a setting of 1, unless they are configuring very large clusters.
![]() Define failover capacity by reserving a percentage of the cluster resources: If you choose this method, you then set the percentages that you need for your organization. In addition, you can set a different percentage for CPU than you do for memory. After you have chosen your settings, HA continually compares the total resource requirements for all VMs with the total failover capacity that it has derived from your settings. When you are attempting to power on a VM that would cause the first calculation to become higher than the second, HA will prevent the VM from being powered on. How you derive the percentages is beyond the scope of this book, but know that this option should be used when you have highly variable CPU and memory reservations.
Define failover capacity by reserving a percentage of the cluster resources: If you choose this method, you then set the percentages that you need for your organization. In addition, you can set a different percentage for CPU than you do for memory. After you have chosen your settings, HA continually compares the total resource requirements for all VMs with the total failover capacity that it has derived from your settings. When you are attempting to power on a VM that would cause the first calculation to become higher than the second, HA will prevent the VM from being powered on. How you derive the percentages is beyond the scope of this book, but know that this option should be used when you have highly variable CPU and memory reservations.
![]() Use dedicated failover hosts: If you choose this option, you then choose a host or hosts that are in your cluster that will become a passive standby host or hosts. Failover hosts should have the same amount of resources as any of the hosts in your cluster, or more. This option at first seems to violate all that HA stands for, because part of the goal is to provide fault tolerance without the need for passive standby hardware, but there is a reason that it’s there, as you’ll see very soon when I discuss determining the most appropriate methodology to use.
Use dedicated failover hosts: If you choose this option, you then choose a host or hosts that are in your cluster that will become a passive standby host or hosts. Failover hosts should have the same amount of resources as any of the hosts in your cluster, or more. This option at first seems to violate all that HA stands for, because part of the goal is to provide fault tolerance without the need for passive standby hardware, but there is a reason that it’s there, as you’ll see very soon when I discuss determining the most appropriate methodology to use.
Finally, as with DRS, you have options, through VM Overrides with regard to each VM that can be different from what is set for the cluster, as shown in Figure 14-29.

These options do not have anything to do with admission control, or at least not directly. However, they do have an impact on what happens to each VM when HA is used. The list that follows provides a brief description of each of these two settings.
![]() VM Restart Priority: The default configuration in the cluster is Medium. If you leave the default setting, all VMs will have the same priority on restart; in other words, no VMs will have any priority over any others. If there are some VMs that you want to have a greater priority (closer to the front of the line), you can change the restart priority on the specific VMs. Only by leaving the cluster setting at the default of Medium will you allow yourself the option to give each VM a priority that is lower or higher than the default setting. You can also change the default setting on the cluster, although it’s not often needed.
VM Restart Priority: The default configuration in the cluster is Medium. If you leave the default setting, all VMs will have the same priority on restart; in other words, no VMs will have any priority over any others. If there are some VMs that you want to have a greater priority (closer to the front of the line), you can change the restart priority on the specific VMs. Only by leaving the cluster setting at the default of Medium will you allow yourself the option to give each VM a priority that is lower or higher than the default setting. You can also change the default setting on the cluster, although it’s not often needed.
![]() Host Isolation Response: This setting determines what the host does with regard to VMs when the host is not receiving heartbeats on its management network. The options are to leave it powered on, or power off, or gracefully shut down the VMs. The default setting in the cluster is Leave Powered On, but this can be set specifically for each VM in the cluster. In most cases, you do not want to power off a server that has applications running on it because it can corrupt the applications and cause a very long restart time. For this reason, you should generally use either the default setting of Leave Powered On or a setting of Shut Down VMs to shut down the servers gracefully and not corrupt the applications that they are running.
Host Isolation Response: This setting determines what the host does with regard to VMs when the host is not receiving heartbeats on its management network. The options are to leave it powered on, or power off, or gracefully shut down the VMs. The default setting in the cluster is Leave Powered On, but this can be set specifically for each VM in the cluster. In most cases, you do not want to power off a server that has applications running on it because it can corrupt the applications and cause a very long restart time. For this reason, you should generally use either the default setting of Leave Powered On or a setting of Shut Down VMs to shut down the servers gracefully and not corrupt the applications that they are running.
Determining Appropriate Failover Methodology and Required Resources for HA
The main focus here is to analyze the differences between the three Admission Control methods. In addition, you learn about the use of each method and when one would be more appropriate than another. You should understand your options with regard to configuring HA and the impact of each possible decision on your overall failover methodology.
Host Failures the Cluster Tolerates
To use this methodology, you choose the Define failover capacity by static number of hosts setting. Then, by default, HA calculates the slot size for a VM in a very conservative manner. It uses the largest reservation for CPU of any VM on each host in a cluster and then the largest reservation for memory plus the memory overhead. These numbers are used, in essence, to assume that every VM is that size, a value called slot size. This calculation is then used to determine how many “slots” each host can support; however, it’s entirely possible that no VM may have both of those values, so the calculation can result in a much larger slot size than actually needed. This, in turn, can result in less capacity for VMs in the cluster.
You can use advanced settings to change the slot size, but that will be valid only until you create a VM that is even larger. The actual calculations to make advanced settings changes are beyond the scope of this book, but you should know how the default slot size is determined. The only factor that might make this option appropriate and simple is if your VMs all have similar CPU and memory reservations and similar memory overhead.
Percentage of Cluster Resources as Failover Spare Capacity
To use this methodology, you choose the Define failover capacity by reserving a percentage of the cluster resources setting. Unlike the previous option, the Percentage of Cluster Resources as Failover Spare Capacity option works well when you have VMs with highly variable CPU and memory reservations. In addition, you can now configure separate percentages for CPU and memory, making it even more flexible and saving your resources. How you derive the percentages is beyond the scope of this book, but you should know that this option should be used when you have highly variable CPU and memory reservations. This method is generally most preferred now because it uses resources in an efficient manner and does not require the manipulation of slot sizes.
Specify Failover Hosts
To use this methodology you select the Use dedicated failover hosts setting. If you think about it, part of the reason that you used HA rather than clustering was to avoid passive standby hosts, so why does VMware even offer this option? The main reason Specify Failover Hosts is an option is that some organizational policies dictate that passive standby hosts must be available. To provide flexibility in these instances, VMware offers this option, but it should not be considered a best practice.
Exam Preparation Tasks
Review All the Key Topics
Review the most important topics from the chapter, noted with the Key Topic icon in the outer margin of the page. Table 14-2 lists these key topics and the page numbers where each is found.
Review Questions
The answers to these review questions are in Appendix A.
1. Which of the following can you configure in the setting of a host cluster? (Choose two.)
a. Virtual Machine Monitoring
b. SDRS
c. FT
d. EVC
2. Which of the following can be used only on a host that is part of a cluster? (Choose two.)
a. vMotion
b. DRS
c. Resource Pools
d. HA
3. Which Admission Control method would be best for an organization that has many VMs with highly variable reservations?
a. Specify failover hosts.
b. Percentage of cluster resources reserved as failover spare capacity
c. Host failures that the cluster tolerates
d. Any of these methods would work fine.
4. Which of the following are true regarding SDRS? (Choose two.)
a. I/O is always taken into consideration.
b. Capacity is always taken into consideration.
c. Datastores are managed through host clusters.
d. Datastores are managed by adding similar datastores to datastore clusters.
5. Which of the following are storage events that can be monitored using VCMP?
a. FT
b. APD
c. PDL
d. SDRS
6. If the timeout value for VCMP APD is set to the default of 140 seconds and the delay is set to the default of 3 minutes, how long will it take for the system to act on the VM?
a. 40 sec
b. 140 sec
c. 3 min
d. 5 min 20 sec
7. Which of the following is a DRS Automation Level that will make recommendations but will not perform an action of any kind on VMs?
a. Partial
b. Manual
c. Disabled
d. Fully Automatic
8. Which of the following DRS Automation Levels will perform initial placement of VMs but will not move them to balance loads?
a. Manual
b. Partial
c. Fully Automated
d. Disabled
9. Which of the following is the default setting for Host Isolation Response in vSphere HA?
a. Leave Powered On
b. Shut Down
c. Power Off
d. Disabled
10. Which cluster setting of VM Restart Priority offers the greatest flexibility for VM overrides?
a. High
b. Medium
c. Low
d. Disabled