
Chapter 10
Multiview Video Coding (MVC)
10.1. Introduction
Compression is today a fundamental part of digital communications. Different technological advances in screen devices, both in terms of their resolution (increasing use of ultra HD formats) and their refresh rate, have produced increasingly large volumes of data. This phenomenon is even more significant given the appearance of 3DTV which allows viewers to watch stereoscopic (two views) or multiview (N views) media.
To demonstrate the indispensable nature of compression within the context of multiview video (MVV), we will use a simple example. We will consider a video sequence of eight views in full HD resolution (1,920 × 1,080), at 30 images per second with a duration of 5 min in which each pixel is coded on 24 bits. The memory required for this multiview sequence is therefore (8 × 1,920 × 1,080 × 30 × 300 × 24)/8 = 417.13 Go with a rate of 11 Gbits/s. It is soon apparent that, without this crucial compression stage, disseminating and storing these kinds of sequences is almost completely impossible.
However, one of the fundamental characteristics of multiview media is the fact that there is a strong correlation between each view. This correlation is therefore used by compression schemes using 3D formats (for both stereoscopy and multiview) and specific coding techniques. This chapter is designed to present 3D formats and coding techniques for stereoscopic vision as well as for multiview examples.
10.2. Specific approaches to stereoscopy
10.2.1. Formats
10.2.1.1. Frame-compatible formats
Frame-compatible (FC) formats involve sub-sampling and multiplexing the images from left- and right-hand views into a single image or sequence of images [VET 10]. As a result, the new resulting stream has the same number of samples as a monoscopic video sequence. It can therefore be effectively encoded with a standard compression method such as H.264/MPEG-4 AVC [ITU 10].
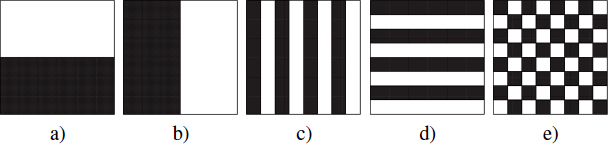
With FC formats, multiplexing can be carried out spatially or temporally. With spatial multiplexing, left- and right-view images are first sub-sampled and then combined into a single image. The two views can, for example, be broken down vertically or horizontally and arranged in configurations side by side, as illustrated in Figure 10.1(a) and (b).
Equally, the data can be interleaved by columns, lines or diagonally, in line with the motifs in Figure 10.1(c), (d) and (e).
Figure 10.1. FC formats side by side: a) top to bottom b) left-right; interleaved FC formats: c) by columns, d) by lines, and e) diagonally
With temporal multiplexing, left- and right-hand images are sub-sampled and combined alternately into a single sequence, as shown in Figure 10.2.
In order to interpret and deinterleave samples, the FC formats require auxiliary information. As such, supplementary enhancement information (SEI) messages are normalized within the context of H.264/MPEG-4 AVC [ITU 10].
Figure 10.2. Temporal FC formatting

The inherent advantage of FC formats is their backward compatibility with distribution infrastructures as well as with current equipment. Deploying this kind of solution is therefore quick and easy. For this reason, these formats have been widely adopted for the first stereoscopic 3DTV services by reusing encoders, transmission channels, receivers and current decoders. Generally, side by side FC formats are the most frequently used due to their high visual quality after compression.
However, FC formats have two major disadvantages. First, spatial or temporal resolution is reduced which can result in a loss of quality even if the impact is partially limited by binocular fusion properties in human visual systems. Second, even if formats are backward compatible, current receivers are not yet able to correctly decode SEI messages and cannot therefore correctly interpret multiplexed data. This is a major obstacle for transmission given that equipment is difficult to upgrade.
10.2.1.2. Mixed resolution stereo
The mixed resolution stereo (MRS) format is based on the principle of binocular suppression in the human visual system. Symmetric representation, where one view has significantly reduced quality in relation to another, has a slight effect on overall perceived quality [STE 98, STE 00]. This property can be exploited using a low-pass filter on one of the views, a rough quantification or even sub-sampling.
The MRS format involves a spatial sub-sampling of one of the views from the stereoscopic pair. The horizontal and vertical resolutions can, for example, be divided into two in relation to the basic view (see Figure 10.3). As a result, the number of samples (and consequently the output rate) is strongly reduced.
Figure 10.3. Format MRS
10.2.1.3. 2D-plus-depth
The 2D-plus-depth format takes a single view (left or right) from the stereoscopic pair as well as a depth (or disparity, the two concepts being closely related), in line with Figure 10.4. A depth map is a gray scale image which shows the position of different objects relative to the scene in relation to the image plane. This can be obtained using specific devices (such as “time-of-flight” cameras or can be generated from the stereoscopic pair via depth estimation algorithms, such as those proposed by [NIQ 10]. During the reconstruction stage, the missing view can be reconstructed using depth-image-based rendering (DIBR) methods [FEH 02, FEH 04, SMO 08].
Figure 10.4. The 2D-plus-depth format

Use of the 2D-plus-depth format significantly reduces the volume of data. It is generally estimated that the rate associated with depth or disparity information generally represents 10–20% of the total budget [EKM 08, MAR 06]. This format also provides backward compatibility in relation to display for standard 2D screens. However, the quality of the synthesized view is strongly related to the precision of depth maps as well as the presence (or not) of overlap zones in the scene which are too large (in this case, the missing information cannot be deduced).
10.2.2. Associated coding techniques
10.2.2.1. Simulcast
Simulcast multiview video coding involves encoding N video streams (N = 2 in the case of a stereoscopic sequence) independently using standard tools (such as H.264/MPEG-4 AVC, for example). Figure 10.5 illustrates the simulcast coding process for a stereoscopic sequence.
Figure 10.5. Simulcast encoding of a stereoscopic sequence
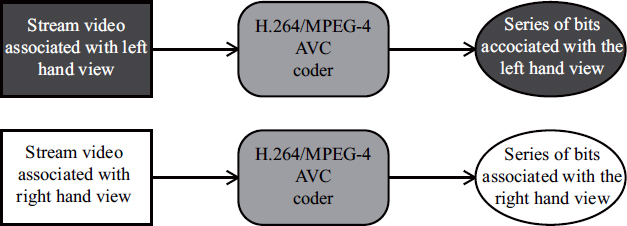
This technique does not require the deployment of infrastructures specific to stereoscopic and multiview sequence compression. However, the strong inter-view correlation is not used and the output rate is generally equal to N times that associated with single-view coding. It is for this reason that simulcast encoding is considered more as a basis for comparison for multiview compression algorithms than as a viable coding technique.
10.2.2.2. MPEG-C and H.264/MPEG-4 AVC auxiliary picture syntax
The MPEG-C and H.264/MPEG-4 AVC (auxiliary picture syntax) standards (presented in [BOU 06] and [MER 09]) are specifically designed for coding 2D-plus-depth multiscopic media. These standards allow an auxiliary video stream to be combined with a standard video stream. However, they still differ from one another, as detailed below.
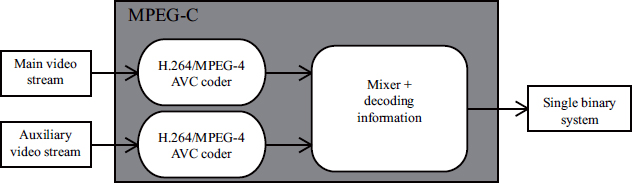
MPEG-C part 3 provides a high-level syntax which allows the decoder to interpret data contained in the auxiliary stream. At this point in time, there are just two types of data: depth maps and disparity maps. The coding process, compatible with the majority of current codecs such as H.264/MPEG-4 AVC, is illustrated in Figure 10.6. The two streams, corresponding to 2D video and depth information, respectively, are coded independently in order to produce two distinct binary streams. These two streams are then recombined as a single stream by temporally interleaving their constituent frames. Another possibility with MPEG-C part 3 is the ability to sub-sample (spatially or temporally) the auxiliary stream, thereby adapting to small rates.
Figure 10.6. 2D-plus-depth stream encoding using MPEG-C part 3
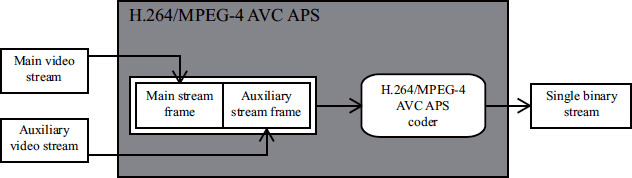
H.264/MPEG-4 AVC APS, in addition, associates an auxiliary component with a standard video stream and encodes these two sequences simultaneously but independently in order to produce a single binary stream (see Figure 10.7). No additional information is added and the interpretation of the data is left to the user (in contrast to MPEG-C part 3). In addition, each frame in the auxiliary stream must contain the same number of macro blocks as a frame belonging to the main stream (sub-sampling depth information is not allowed).
Figure 10.7. Encoding a 2D-plus-depth stream using H.264/MPEG-4 AVC APS
10.2.2.3. H.264/MPEG-4 multiview video coding stereo profile
The multiview video coding (MVC) extension of the H.264/MPEG-4 AVC standard [ITU 10, VET 11] was introduced to provide a standardized representation of stereoscopic and MVV while maintaining the same structure as the original standard as far as possible. The basic idea is to allow images taken from other cameras as a reference to predict the current image. Its coding and syntax are also very similar to H.264/MPEG-4 AVC in order to obtain the best possible level of quality while limiting complexity and demands on memory.
The MVC norm is used to code stereoscopic and MVV using two profiles known as “stereo high” and “multiview high”, based on the H.264/MPEG-4 AVC “high” profile. More precisely, the MVC extension has been developed so that it is always possible to decode a specific view (known as the base view) from a stereo or multiview stream with an ordinary H.264/MPEG-4 AVC decoder. A binary MVC stream is composed of a part specifically for the base view (identical to an H.264/MPEG-4 AVC stream) and a part for other views. The two parts can be identified using two types of Network Abstraction Layer (NAL) unit; an H.264/MPEG-4 AVC decoder which correctly recognizes the base view while ignoring others, as well as an MVC decoder which can decode all views.
In terms of the compression algorithm, MVC introduces a major tool: interview prediction. Using this tool, it is possible to construct a prediction of a block of pixels from a current image, not only using past or future images from the same camera but also images from other views. This is made possible by modifying the list of H.264/MPEG-4 AVC reference images. For the base view, this list is not modified because backwards compatibility must be maintained. For the remaining views, images belonging to other views can be inserted into the reference list but must necessarily correspond to the same temporal point as the current image.
The stereo high profile encodes a video with two views which is either progressive or interleaved. The base view, generally the left-hand view, can therefore be decoded independently of the right-hand view. However, for each image in this right-hand view, the list of references will also contain the image corresponding to the left-hand view. An example of this prediction structure is shown in Figure 10.8, where the lines in bold represent temporal predictions and the dotted lines are inter-view predictions. The stereo high profile is currently used for 3D Blu-ray formats.
Figure 10.8. Possible prediction structure for MVC, with stereo profile. The base view is shown above

10.3. Multiview approaches
10.3.1. Formats
10.3.1.1. Multivew video and Multiview plus depth
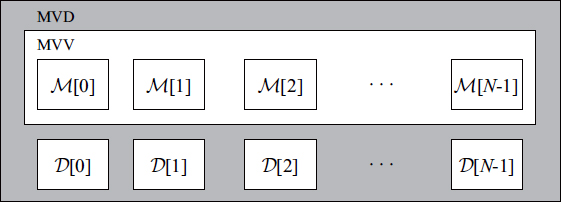
Multiview video (MVV) and multiview-plus-depth (MVD) formats are two basic MVV formats. When a sequence with N views is stored using MVV format, the user has access to different viewpoints from N recording systems (either real or virtual), noted as ![]() (where
(where ![]() ) in Figure 10.9. The MVD format, on the other hand, takes the information in MVV format but adds the associated depth/ disparity maps (represented by D[i] in Figure 10.9).
) in Figure 10.9. The MVD format, on the other hand, takes the information in MVV format but adds the associated depth/ disparity maps (represented by D[i] in Figure 10.9).
Figure 10.9. MVV and MVD formats
As with the 2D-plus-depth format, the MVD format only considers a restricted set of viewpoints in order to reduce the amount of data to be transmitted. The missing views are then reconstructed using DIBR algorithms.
10.3.1.2. Layered-depth image and layered-depth video
The concept of layered-depth image (LDI) was first introduced by Shade et al. [SHA 98], reused by Yoon et al. [YOO 05] and adapted to multiview compression by Yoon et al. [YOO 07].
An LDI is an image which contains several layers in which each pixel contains not only colorimetric information but also depth information. The LDI format is principally designed to only keep non-redundant information in the scene. Using depth/disparity information, available for each pixel from the N original views, it is possible to project the pixels from a view i toward a view j. This 3D format is sometimes mistaken for layered-depth video (LDV), which is a temporal extension of the LDI format.
The general construction process for LDI is as follows: we first select a reference view ![]() from the N original views (generally M[0]) and take this as our layer 0 in the LDI (noted as
from the N original views (generally M[0]) and take this as our layer 0 in the LDI (noted as ![]() [0]). For each of the pixels r =(p, i) from the other views (where 0 < i < N indicates the view number and p = (x, y) indicates the pixel in position (x, y)), we project this onto
[0]). For each of the pixels r =(p, i) from the other views (where 0 < i < N indicates the view number and p = (x, y) indicates the pixel in position (x, y)), we project this onto ![]() using its depth/disparity information.
using its depth/disparity information.
This pixel (situated in position (x′,y′) in the referential of view ![]() after projection) is compared to pixel r’ = (p’, ref), where p’ = (x′,y′), using a decision function (based on a relative comparison of colorimetry, depth, mixed or other), thereby qualifying (or not) the redundant pixel. If the pixel is not considered redundant (generally due to an overlapping area in view
after projection) is compared to pixel r’ = (p’, ref), where p’ = (x′,y′), using a decision function (based on a relative comparison of colorimetry, depth, mixed or other), thereby qualifying (or not) the redundant pixel. If the pixel is not considered redundant (generally due to an overlapping area in view ![]() but shown in view i) a new layer is added to the position (x′,y′) in the LDI and we add colorimetric and depth/disparity information associated with r. If it is judged redundant, it is simply ignored. The LDI is completely constructed when all the pixels from the multiview set have been processed. Figure 10.10 illustrates three LDI layers obtained for the break dancers multiview sequence using the approach proposed by [YOO 07].
but shown in view i) a new layer is added to the position (x′,y′) in the LDI and we add colorimetric and depth/disparity information associated with r. If it is judged redundant, it is simply ignored. The LDI is completely constructed when all the pixels from the multiview set have been processed. Figure 10.10 illustrates three LDI layers obtained for the break dancers multiview sequence using the approach proposed by [YOO 07].
Figure 10.10. Three layers taken from the LDI generated for the break dancers sequence using the method proposed by [YOO 07]: a) ![]() [0],b)
[0],b) ![]() [2] and c)
[2] and c) ![]() [4]
[4]

There are a number of variations on the LDI format [BAT 11, JAN 09, SMO 09] which differ in terms of their level of decision function as well as LDI formatting. Table 10.1 describes the different approaches for the LDI format.
Figure 10.11 shows three LDI layers obtained using the approach proposed by [BAT 11] on the image with seven views of dolls shown on the Middlebury Stereo Vision site1.
Table 10.1. Different possible approaches for the LDI format
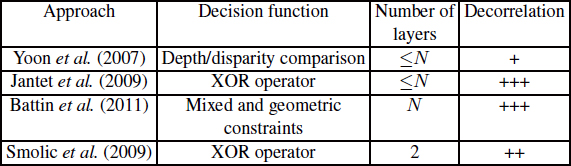
Figure 10.11. Three layers taken from the LDI generated for the doll sequence using the method proposed by [BAT 11]: a) ![]() [0],b)
[0],b) ![]() [2] and c)
[2] and c) ![]() [4]
[4]

10.3.1.3. Depth-enhanced stereo
The depth-enhanced stereo (DES) format was introduced by [SMO 09] in 2009. This format is a compromise between the LDI and MVD formats (see sections 10.3.1.2 and 10.3.1.1). In contrast to the LDI format, which takes a reference view from the N input views to generate the LDI, the DES format takes two adjacent reference views and for each generates an associated LDI. Figure 10.12. (taken from [SMO 09]) presents the information related to the DES format.
Figure 10.12. DES format (figure taken from [SMO 09]): a) LDI associated with the first reference view, and b) LDI associated with the second reference view

Thanks to these reference views, the DES format provides direct backward compatibility in relation to stereoscopic display (using the first layer from each LDI). In addition, it has a greater amount of information and therefore provides better quality intermediary viewpoints. However, the amount of information is greater than in the LDI approach while the memory required for the DES format is also greater.
10.3.2. Associated coding techniques
10.3.2.1. H.264/MVC multiview profile
The MVC extension of H.264/MPEG-4 AVC [ITU 10, VET 11] is designed for multiview videos with a number of views between 2 and 1,024. As for stereo, a single view is encoded as a base view and can also be decoded independently of other views. Every other view can only be decoded after the base view and potentially other views. However, the inter-view prediction structure is very flexible. With the “view-progressive” configuration, for example, only the first image from a group of pictures (GOP) is coded with the inter-view prediction, while the others use only temporal prediction. In addition, inter-view prediction uses only a single reference per image (“P” type prediction). This configuration provides access to each view with minimal computational cost (in relation to the number of images from other views to be decoded).
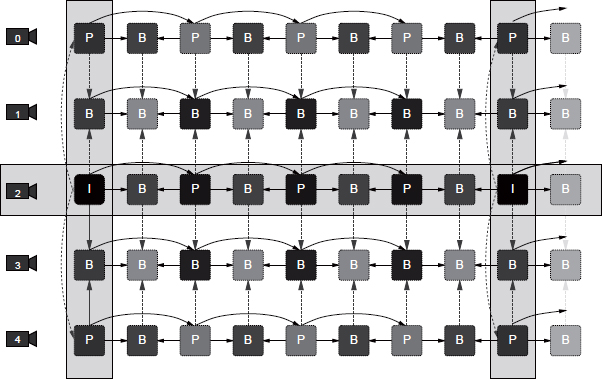
A more complex configuration is “fully hierarchical coding” where bi-directional inter-view predictions are possible. The aim is to optimize rate-distortion performance by exploiting the maximum amount of correlations between views. An example of this structure is shown in Figure 10.13, where the base view is shown in the center (view 2). Views 0 and 4 are coded using inter-view prediction only for the first image in the GOP. This is therefore the same prediction structure as that used for “progressive view” examples. Finally, for intermediary views 1 and 3, each image can use bi-directional inter-view prediction (dotted line).
The multiview profile can be used to code a stereoscopic video but, in contrast to the stereo profile, it does not allow interleaving. A bitstream may therefore be compatible with both profiles if it is coded with the stereo high profile but without interleaving.
10.3.2.2. LDI format coding
There is currently no specific coding standard for the 3D LDI format (nor for the DES format). However, there are several possible approaches used in the literature to solve this problem.
Figure 10.13. Possible prediction structure for the multiview profile using the H.264/MVC format. The base view is shown in the center
In [YOO 07], two methods are used to compress an LDI. The first involves bringing together the pixels from the LDI in a single texture by horizontal successive aggregation of its different layers. This texture as well as the additional information required to reconstruct the original views is then coded using H.264/MPEG-4 AVC. This first approach has a major disadvantage: horizontally aggregating the pixels taken from different layers of the LDI prevents spatial correlation which is critical for H.264/MPEG-4 AVC block coding. To overcome this problem, Yoon [YOO 07] has proposed a second method which entails combining the missing information from different locations in the N – 1 final layers with those present in layer 0 and then encoding them using H.264/MPEG-4 AVC. This second method obtains compression ratios two times greater than the first approach.
Another possible approach, proposed by [JAN 10], involves compressing the I-LDI (variation of the LDI proposed in [JAN 09] which uses redundancy between different views more effectively) using H.264/MVC. Jantet [JAN 10] proposes creating an MVD using only the two first I-LDI layers where information missing from the second layer is combined with that found in the first layer. This solution is possible because the I-LDI approach provides strong decorrelation and the first two layers contain the majority of information present in the original multiview set (around 90%). This MVD is then compressed using H.264/MVC with the same coding parameters. This approach has a significant reduction in output with equal quality in relation to the original MVD coding with H.264/MVC with output being less than 3 Mbits/s.
Finally, [BAT 11] proposes a real-time compression of his LDI approach based on DCT 3D. A horizontal aggregation of the pixels taken from each layer is carried out first and the different layers are then reassembled within a 3D volume. This 3D volume is then compressed using a DCT/quantification/entropic coding pipeline in order to obtain the compressed stream. While this last approach does not obtain the compression rates found in [JAN 10], it can carry out LDI generation and coding in real-time using the GPU.
10.4. Conclusion
With a view to improving performance and increasing functionality in current formats, MPEG has recently undergone a new normalization phase for 3D video coding (3DVC).
There are two main objectives of this. First, 3DVC combines the video format with display technology. It specifically includes advanced processing techniques to adjust the stereoscopic reference base and therefore control the perception of depth according to the visualization environment. This aspect is crucial in order to minimize visual fatigue and maximize the user’s experience. Then, 3DVC must also take into account multiview autostereoscopic screens which are beginning to appear on the market. More specifically, 3DVC must allow the synthesis of several high-quality views with a strongly limited bit rate. As such, 3DVC uses depth map coding in order to separate the coding bit rate from the number of viewpoints.
Three approaches are currently used in normalization. The first is a backward compatible extension of MVC [VET 11]. More specifically, a second stream encodes the depth information independently of the stream representing textural information. The high-level syntax is adapted in order to signal this additional information, although there is no change regarding syntax or the decoding process in the macro block. A second approach involves a backward compatible extension of H.264/MPEG-4 AVC [ITU 10, WIE 03]. A basic video stream encodes texture information of a view with H.264/MPEG-4 AVC. For other views, as well as for depth maps, the syntax and decoding process in the macro block are modified in order to improve the efficacy of compression. A significant benefit must be evident in order to justify the normalization of this approach. Finally, a third approach uses a backward compatible extension of high efficiency video coding (HEVC) [BRO 12, OHM 13]. First, a simple multiview extension of HEVC is made using a schema identical to MVC. The depth map coding as well as the improvement in view resolution using scalability are then considered.
10.5. Bibliography
[BAT 11] BATTIN B., NIQUIN C., VAUTROT P., et al., “Multiview image compression based on LDV scheme”, Proc. SPIE 7863, Stereoscopic Displays and Applications XXII, 78630G, February 15, 2011.
[BOU 06] BOURGE A., GOBERT J., BRULS F., “MPEG-C part 3: enabling the introduction of video plus depth contents”, Proceedings of IEEE Workshop on Content Generation and Coding for 3D-Television, 2006.
[BRO 12] BROSS B., HAN W.-J., OHM J.-R., et al., “High efficiency video coding (HEVC) text specification draft 9”, ITU-T SG16 WP3 & ISO/IEC JTC1/SC29/WG11 JCTVC-K1003, October 2012.
[EKM 08] EKMEKCIOGLU E., WORRALL S.T., KONDOZ A.M., “Bit-rate adaptative down-sampling for the coding of multi-view video with depth information”, 3DTV Conference: The True Vision-Capture, Transmission and Display of 3D Video, pp. 137–140, 2008.
[FEH 02] FEHN C., KAUFF P., BEECK M., et al., “An evolutionary and optimized approach on 3D-TV”, Proceedings of International Broadcast Conference, pp. 357–365, September 2002.
[FEH 04] FEHN C., “3D-TV using depth-image-based rendering (DIBR)”, Proceedings of Picture Coding Symposium, San Francisco, USA, December 2004.
[ITU 10] ITU-T, “Advanced video coding for generic audiovisual services”, ITU-T Recommendation H.264 and ISO/IEC 14496-10 (MPEG-4 AVC), 2010.
[JAN 09] JANTET V., MORIN L., GUILLEMOT C., “Incremental-LDI for multi-view coding”, 3DTV Conference: The True Vision - Capture, Transmission and Display of 3D Video, Potsdam, Germany, 2009.
[JAN 10] JANTET V., MORIN L., GUILLEMOT C., “Génération, compression et Rendu de LDI”, COmpression et REpresentation des signaux AUdiovisuels (CORESA), Lyon, France, 2010.
[MAR 06] MARTINIAN E., BEHRENS A., XIN J., et al., “Extensions of H.264/AVC for multiview video compression”, IEEE International Conference on Image Processing, Atlanta, USA, 2006.
[MER 09] MERKLE P., WANG Y., MULLER K., et al., “Video plus depth compression for mobile 3D services”, 3DTV Conference: The True Vision – Capture, Transmission and Display of 3D Video, Potsdam, Germany, 2009.
[NIQ 10] NIQUIN C., PRÉVOST S., REMION Y., “An occlusion approach with consistency constraint for multiscopic depth extraction”, International Journal of Digital Multimedia Broadcasting (IJDMB), Special Issue Advances in 3DTV: Theory and Practice, vol. 2010, pp. 1–8, February 2010.
[OHM 13] OHM J.-R., SULLIVAN G., “High efficiency video coding: the next frontier in video compression”, IEEE Signal Processing Magazine, vol. 30, no. 1, pp. 152–158, 2013 .
[SHA 98] SHADE J., GORTLER S., HE L., et al., “Layered depth images”, Proceedings ACM SIGGRAPH, ACM, pp. 231–242, 1998.
[SMO 08] SMOLIC A., MULLER K., DIX K., et al., “Intermediate view interpolation based on multiview video plus depth for advanced 3D video systems”, 15th IEEE International Conference on Image Processing, 2008, ICIP 2008, pp. 2448–2451, October 2008.
[SMO 09] SMOLIC A., MUELLER K., MERKLE P., et al., “An overview of available and emerging 3D video formats and depth enhanced stereo as efficient generic solution”, Picture Coding Symposium, Chicago, USA, 2009.
[STE 98] STELMACH L., TAM W.J., “Stereoscopic image coding: effect of disparate image-quality in left- and right-eye views”, Signal Processing: Image Communication (Elsevier Science), vol. 14, pp. 111–117, 1998.
[STE 00] STELMACH L., TAM W.J., MEEGAN D., et al., “Stereo image quality: Effects of mixed spatio-temporal resolution”, IEEE Transactions on Circuits and Systems for Video Technology, vol. 10, no. 2, pp. 188–193, 2000.
[VET 10] VETRO A., “Frame compatible formats for 3D video distribution”, Proceedings of the IEEE International Conference on Image Processing, vol. 17, pp. 2405–2408, 2010.
[VET 11] VETRO A., WIEGAND T., SULLIVAN G.J., “Overview of the stereo and multiview video coding extensions of the H.264/MPEG-4 AVC standard”, Proceedings of the IEEE, vol. 99, no. 4, pp. 626–642, 2011.
[WIE 03] WIEGAND T., SULLIVAN G., BJØNTEGAARD G., et al., “Overview of the H.264/AVC video coding standard”, IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 7, pp. 560–576, 2003.
[YOO 05] YOON S.-U., KIM S.-Y., HO Y.-S., “Preprocessing of depth and color information for layered depth image coding”, Advances in Multimedia Information Processing – PCM 2004, vol. 3333, pp. 622–629, 2005.
[YOO 07] YOON S., LEE E., KIM S., et al., “A framework for representation and processing of multi-view video using the concept of layer depth image”, Journal of VLSI Signal Processing, vol. 46, pp. 87–102, 2007.