
Chapter 8
3D Scene Reconstruction and Structuring
8.1. Problems and challenges
The cinema and video games industries increasingly combine real images with computer-generated images. Today, there is a tendency to mix these techniques at the point of recording so that producers can use a three-dimensional (3D) result to judge whether a scene will appear in the final production and to guide actors, as well allowing the results of filming to be directly inserted into a traditional computer graphics production chain.
To satisfy this growing demand in the image industry, a large body of research has focused on multiview reconstruction. The approaches proposed until now can be split into two families of methods:
– “Model-free methods” that can be distinguished by the fact that no prior knowledge (relating to the nature and number of objects, characters’ morphologies) is given to the system. The silhouette-based reconstruction technique belongs to this family. Due to their general nature, these techniques generate results without any temporal coherence. Indeed, a reconstruction is calculated for each “frame” independently of others.
– “Model-based methods” use a reference geometric description (for example triangular mesh) of the object to be reconstructed. This prior knowledge can be manually constructed or obtained using an acquisition system (for example a 3D scanner). Reconstruction involves evolving the reference form in relation to data taken from multiview capture (silhouettes, optical waves, etc.). These methods are more reliable than model-free methods and present the strong advantage of generating data with strong temporal coherence. However, due to the use of a reference form, they are, in the majority of cases, restricted to reconstructing a single individual with human morphology.
This chapter will focus on silhouette-based reconstruction and its improvement. Following a detailed description of the different stages in this method, its implementation in an industrial context will also be examined. Finally, we will conclude the chapter with an overview of multiview reconstruction analysis techniques to extract temporally stable semantic information to facilitate their integration into the computer graphics production chain.
8.2. Silhouette-based reconstruction
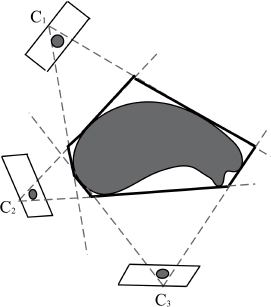
A silhouette is a binary mask associated with a given perspective that includes all pixels corresponding to the projection of a point of the 3D object to be reconstructed. In Figure 8.1, the colored pixels in the images taken by cameras C1, C2 and C3 correspond to silhouettes of the 3D object in each view. Silhouette-based reconstruction [SNO 00] therefore involves estimating the visual hull of the 3D object, represented by a polygon in Figure 8.1.
Figure 8.1. Silhouette-based reconstruction
8.2.1. Silhouette extraction methods
The extraction of a silhouette involves isolating the region of projection for the object to be reconstructed from the scene’s background. There are several methods for arriving at this result, grouped according to the following categories:
– “Color difference-based methods” that use an image from the scene’s background. To extract an object from the background, the technique uses image differences. To overcome the problem of variations in lighting in the background, the “chroma-keying” technique is often favored. “Chroma-keying” is one of the most common and most frequently used semantic segmentation techniques within audiovisual contexts. Video acquisition takes place against a “key color” background, generally blue or green. The problem of shadowing in the background is solved using learning techniques such as Gaussian mixture model or “k-means” [STA 99, ZIV 04].
– “Region based methods” aggregate, step-by-step, pixels with shared colorimetric properties. They establish region filling heuristics within an image by propagating local criteria, often based on the image’s gradient (higher at the edges and lower in the middle of the area). The most commonly used methods in this category include histogram segmentation, region growing and region merging. For a more detailed presentation of region-based segmentation methods, Caillet’s [CAI 06] doctoral thesis is an interesting resource.
– “Contour-based methods” involve extracting the connected components using a threshold of the image’s gradient. Using these methods, the silhouette is characterized by its edge with the background of the scene.
8.2.2. Reconstruction methods
Surface methods deduce the object’s visual hull using the intersection of silhouette cones from each camera. The silhouette cone associated with a camera is defined by the set of infinite triangles delimited by half-lines connecting the optical center with two neighboring pixels in the contour of the silhouette. The reconstructed object is therefore described by its surface, represented in the form of a triangular mesh [LAZ 07].
Volumic methods subdivide the capture space according to a regular grid of basic cells, known as voxels (volume elements). In this approach, the visual hull corresponds to the set of voxels projected into the silhouettes of each camera. The reconstructed object is described by its volume within the discrete grid [SZE 93].
8.2.3. Improving volume reconstruction
The main disadvantage of silhouette-based reconstruction lies in its inability to reconstruct certain details on the object’s surface. The techniques examined in this chapter use color information from each view to select voxels within the bounding volume.
8.2.3.1. Voxel coloring
This technique, proposed by Seitz and Dyer [SEI 99], involves subdividing the regular grid of voxels into successive layers, from the nearest to the farthest in relation to the cameras (the cameras being set out in a semicircle around the object to be reconstructed). Voxel coloring is based on the hypothesis that a voxel on the surface of an object must have the same color in each view, known as a photo-consistent voxel. For example, the object in Figure 8.2 shows a concavity ignored by the silhouette-based reconstruction technique. The voxel V1 found on the visual hull, is projected on different color pixels in views taken from cameras C1 and C2. On the basis of this statement, the voxel coloring algorithm is composed of the following stages:
Algorithm 8.1. The voxel coloring algorithm

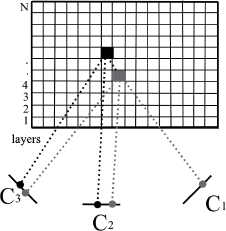
However, this method requires a slight modification to effectively handle the occlusion problem. Two voxels, taken from different layers, can be projected onto the same pixel in a given view. The voxel from the nearest layer occludes the other. To solve this problem, the method takes into account the fact that a voxel from a layer i cannot block a voxel from a layer j when j > i, as illustrated in Figure 8.3.
Figure 8.2. Improvement of the visual hull by identifying concave zones
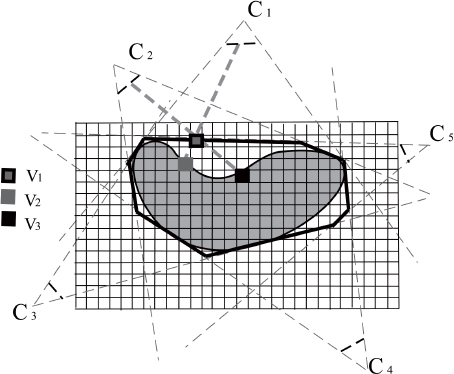
Figure 8.3. The occlusion manipulation proposed by Seitz and Dyer [SEI 99]
8.2.3.2. Space carving
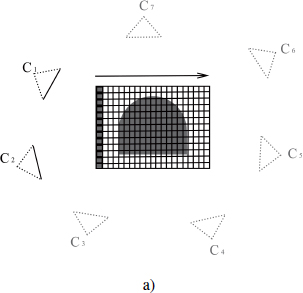
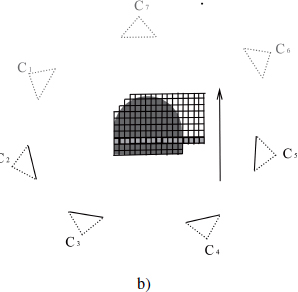
The disadvantage of voxel coloring lies in its inability to completely reconstruct the object due to the arrangement of cameras in a semicircle. The space carving algorithm, introduced by Kutulakos et al. [KUT 00], can be seen as an extension of the previous method adapted to an arbitrary camera arrangement. This relies on sweep planes aligned with the three principal axes x, y and z. Only the cameras behind the sweep plane are used to manage the occlusion. For example, in Figure 8.4(a), the voxels in the plane highlighted in bold are visible via cameras C1 and C2. According to Kutulakos, a voxel is not visible by a camera if it is out of the view frustum or if it is occluded. We will consider a sweep plane in the positive direction from the axis x, the voxel v occludes the voxel w if ![]() . As a result, v is evaluated before w in order to visit the blocking voxel.
. As a result, v is evaluated before w in order to visit the blocking voxel.
Algorithm 8.2. The space carving algorithm

8.3. Industrial application
The industrial use of motion capture requires a real-time visualization of animations on shooting location. This allows directors to guide their actors accurately. In the case of crowded virtual scenery where an avatar can, for example, walk around a virtual table and chairs that are not on the real set, actors can have a video equivalent allowing them to better understand the environment they are supposed to be in, and adapt their performance accordingly. Today, industry is using multiview reconstruction filming sets, seeking to reiterate what has been done for motion capture, to provide the same facilities to teams using the next generation of images.
8.3.1. Hardware acceleration
Real-time visualization now seems possible, despite the significantly more complex algorithms required for animated volume reconstruction than for motion capture. This involves the multiplication of processing units and the use of new parallel calculation possibilities provided by heterogeneous processing systems, composed of central processing units (CPUs) and graphic processing units (GPU) for non-graphic purposes. These computation techniques form part of the “general-purpose processing on graphics processing units” (GPGPU) approach. In this field, Open Calculating Language (OpenCL) [KHR 11] is an example of an emerging technology, combining API1 with a C-derived programming language. OpenCL, suggested as an open standard by the Khronos™ Group, is designed to program heterogeneous parallel systems and proposes a programming model including features from both CPUs and GPUs, the former being increasingly parallel with the latter being more and more programmable.
Figure 8.4. Configuration of cameras for space carving
8.3.2. Results
A complete pipeline of silhouette-based multiview reconstruction must be composed of several processes in order to improve the quality of the obtained result. The process chain may include the following steps that can all be implemented in the form of OpenCL “kernels” such as reconstruction, “marching cubes”, refinement, relaxation and texturing.
The intensive use of hardware acceleration along the whole processing chain satisfies the real-time constraints for reasonable sizes of grids of voxels and a reasonable number of viewpoints. XD Productions has achieved real time (25 images per second) for voxel grids of 1283, covered by 24 red, green and blue (RGB) high-definition cameras (1920 × 1080 pixels).
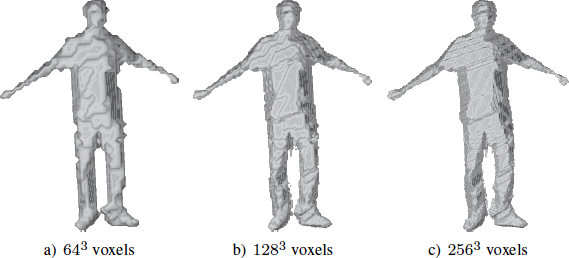
As explained in section 8.2, reconstruction involves subdividing the acquired 3D space into a multitude of voxels split into two categories: voxels inside the object to be reconstructed and voxels outside. The resolution of the subdivision, and therefore the number of voxels, directly influences the quality of the result. Figure 8.5 illustrates a model reconstructed according to three different resolutions.
Figure 8.5. Models of voxel grids with three different solutions (© 2013 XD Productions)
The “Marching Cubes” algorithm deduces a set of triangles describing the surface of the reconstructed model from volumetric data, i.e. voxels. The advantage of a polygonal representation lies in its compatibility with the large majority of 3D modeling software. Figure 8.6(a) shows the triangles obtained on a plane similar to the model in Figure 8.5(c). As explained previously, voxels can be compared to cubes that are clearly visible in the generated models. This lack of quality is not suitable for the broadcast industry, it is thus necessary to refine the model.
”Refining” the model means adapting the position of triangles generated by the “marching cubes” algorithm in order to place them as closely as possible to the character’s silhouette. This removes the step effect created by voxels as illustrated in Figure 8.6(b), compared with Figure 8.5(c). However, a slight aliasing is visible due to the used pixel-mask. To overcome this problem, the 3D model needs to be relaxed.
Figure 8.6. Stages in the graphic pipeline after reconstruction (© 2013 XD Productions)
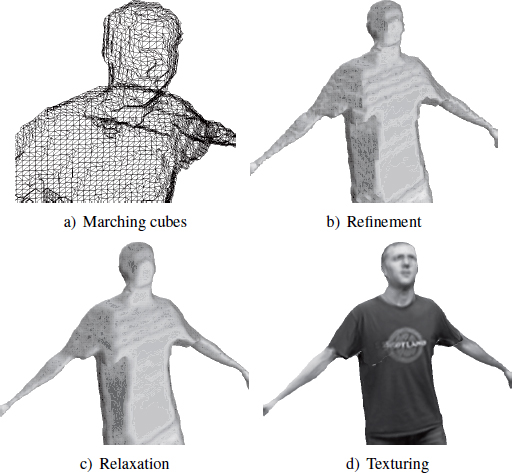
The “relaxation” of the model corrects small defects by smoothing its surface. Figure 8.6(c) illustrates a model after relaxation. Once this stage has been completed, the model is ready to receive a texture.
“Texturing” involves calculating the texture attached to the reconstructed model. To achieve this, source images are projected onto the polygonal surface that connects the nearest pixels with the vertices of the model’s triangles. By interpolation, the triangle is then filled with pixels present in the identified region of interest. Figure 8.6(d) illustrates the result of this last stage.
The reconstruction of a moving person is stored in the form of a sequence of triangular meshes (with the same frequency as the video source) and their associated textures. The use of such sequences in a traditional production “pipeline” is made difficult by the volume of data and their lack of temporal coherence. Triangular meshes have a temporally variable topology that may cause flickering in lighting and shading. Finally, this lack of temporal coherence makes impossible physics simulations involving body parts (for example speed, acceleration, points of inertia, collision volumes to simulate clothes). Solutions can therefore be proposed to structure what is commonly called a “polygon soup”. This has a double objective. First, to provide logically organized mesh data to commercial production tools, in order to relight or redress them and to insert them into a controlled virtual universe. Second, it is also designed to produce coherent sequences qualifying the 3D scene, no longer statically but dynamically. Different stages in the solutions to these problems are examined in the following section.
8.4. Temporally structuring reconstructions
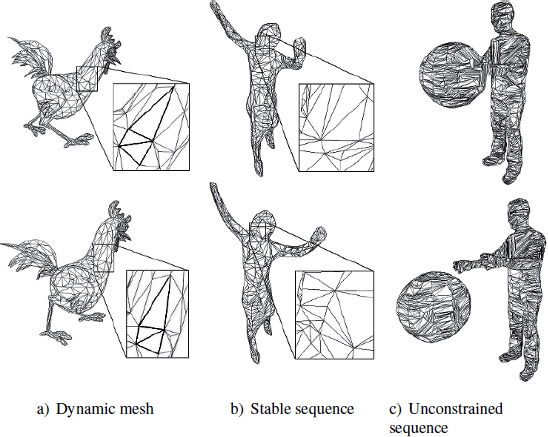
Since a sequence of meshes can take a variety of forms, Arcila [ARC 11] has proposed a formalism for describing the different types of mesh sequences, identifying the following categories: dynamic meshes, stable mesh sequences and unconstrained mesh sequences (see Figure 8.7). These distinctions are based on the existence of temporal coherence in meshes, at both a topological and structural level, as shown in Table 8.1.
Table 8.1. Classification of mesh sequences

Model-free reconstruction methods generally produce stable or unconstrained mesh sequences. The content of the scene is reconstructed in each frame individually. In these conditions, a geometric primitive (a vertex or a triangle) in a given frame does not have any correspondence in the following frame. Indeed, only dynamic meshes with temporal coherence can treat the sequence of meshes as a single animated object. As such, the challenge of temporally structuring multiview reconstructions lies in converting a sequence of meshes into a normalized representation when animating characters. Among the different character animation techniques, skeletal animation and vertex animation seem to be particularly well adapted to mesh sequences.
Figure 8.7. Different types of mesh sequences. a)© 1996 Microsoft Corporation; b) and c) source: GRImage INRIA Rhne-Alpes & 4DView Solutions, http://4drepository.inrialpes.fr
“Skeletal animation” relies on identifying a hierarchized set (generally a tree) of articulations whose configuration is characterized by a rigid transformation (rotation and translation) in relation to their parent in the hierarchy. This skeleton guides the deformation of all the vertices in the mesh. To do so, a “skinning” method is necessary. This involves allocating to each vertex the influence weight of each bone in the skeleton. A bone is a segment linking two adjacent articulations in the tree. As a result, the movement of a vertex is obtained by averaging the movements of all bones in the skeleton, weighted by influence weights. These influence weights can be automatically calculated according to the distance from the vertex to each bone. As such, the “linear blend skinning” (LBS) system calculates the movement of each vertex using a linear interpolation of bone movement. A number of other “skinning” techniques have also been developed such as “skeletal subspace deformation” (SSD) and “multi-weight enveloping” (MWE). A comparison of these methods has been carried out by Jacka et al. [JAC 07]. Unfortunately, the movement obtained by this method is quasi-rigid (rotation and translation component), which means that significant movements with loose clothing, for example, cannot be reproduced.
However, “morph target animation” involves defining the character’s movement using the trajectories of each of the vertices. This technique, equivalent to “morphing”, is much more subtle than skeletal animation and can reproduce far more complex movements. Nevertheless, the animation produced can become unstable due to distortions created by interpolating key positions from the two consecutive frames. Above all, however, this method generates vast quantities of data (3D positions of mesh vertices at each frame), compared with skeletal animation.
8.4.1. Generalized skeletal extraction
The use of skeletons for animation is a modern procedure. It is therefore natural to represent mesh sequences taken from reconstructions in this form in order to make them easier to use within a traditional computer graphics chain. A skeletal model can be provided at the start. However, if we prefer a more generic approach, not restricted to the character’s morphology, several automatic skeleton extraction techniques have been proposed, notably by Baran and Popovic [BAR 07]. However, it should also be noted that the reliability of this kind of approach is less than that of methods using a priori knowledge. Among the methods used to convert a sequence of animated skeleton meshes, the method proposed by De Aguiar et al. [DE 08] has provided convincing results. However, this technique cannot be applied to dynamic meshes.
Skeletal extraction generally involves identifying the different rigid components in a mesh. A rigid component is defined as a set of vertices whose movements are governed by the same rigid transformation. These rigid components define the bones in the skeleton. Searching for rigid components involves a segmentation operation that partitions the object into several subsets of vertices. Segmentation may be based on a convexity criterion. In the case of human morphology, bones are generally described by convex sets and articulations by concave sets.
While the automatic segmentation of static meshes is a problem that has been widely examined, the segmentation of sequences of meshes has been far less so, particularly for unconstrained sequences. In terms of dynamic meshes, some techniques analyze individual vertex trajectories during the sequence in order to regroup them into homogeneous motion “clusters”. Due to their lack of temporal coherence, this approach is difficult to apply to unconstrained sequences. In the latter case, Arcila [ARC 11] has proposed segmenting each mesh independently and then moving the “clusters” from one frame to another.
8.4.2. Calculating displacement fields
Recently, a number of “morphing”-based approaches have led to the development of animation techniques without using skeletons. This change in paradigm has been accompanied by the appearance of new multiview reconstruction approaches using deformable meshes rather than models made up of rigid components. However, while these mesh-based approaches provide a greater degree of flexibility at the point of animation than skeletal-based algorithms, they produce more voluminous representations of dynamic scenes composed of sets of moving positions for each vertex.
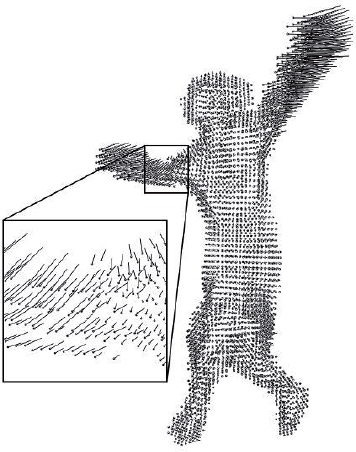
To generate an animation of vertices using multiview reconstruction, equivalent to a dynamic mesh, it is necessary to calculate the individual trajectories of the reference vertices using the series of poses in the sequence. A number of articles examine motion extraction methods within multiview videos using traditional motion capture constraints. These include image-based methods that directly analyze videos and model-based approaches that apply poses taken from videos to an articulated human body in order to generate its movement. This latter approach, restricted to human morphology, is evidently less generic. Weinland et al. provide an overview of current research in this field in [WEI 11]. The extraction of a character’s movement within a 3D scene is generalized by the notion of “scene flow”, introduced by Vedula et al. [VED 05], of which an example is shown in Figure 8.8. It is a 3D version of the optical flow that describes movements identified in a series of images. Two types of methods are most commonly used: image-based techniques and object-based techniques.
Image-based methods calculate the scene flow using all the optical flows that can be extracted from the videos recorded by the cameras. The optical flow is the result of the projection of the scene flow toward the cameras, the method calculates the optical flow of sequences of images from each camera and then retroprojects the obtained vectors in the 3D scene space. Finally, a readjustment obtains the field of 3D vectors that constitute the scene flow.
Object-based methods (also known as “mesh tracking”) establish a correspondence between the vertices in a sequence of meshes in order to follow the evolution of the object. This correspondence, based on criteria such as curvature or texture color, estimate each vertex’s place within the following frame, and as such calculates its trajectory. A good example of this can be found in [PET 11] in which Petit et al. provide an examination of current research in this subject. Finally, the method proposed by Matsuyama et al. [MAT 04] uses sequences of discrete volumes (sets of binary voxels) taken from a silhouette-based reconstruction. Based on a pixel correspondence method for “morphing” images, the method is designed to match voxels from two consecutive frames.
Figure 8.8 Example of the scene flow
8.5. Conclusion
Multiview reconstruction using several synchronized video sequences appears to be the future of the audiovisual industry, providing new perspectives in terms of creating hybrid content, combining live action and image synthesis. It is for this reason that a number of companies have attempted to create industrial solutions to this problem. In addition, within the context of a fragmented TV audience due to the increase in the number of channels and competition between new modes of reception (video on demand (VOD), Internet, etc.), providers and producers are, more than ever, focused on creating quality content, produced in optimal economic conditions. Multiview reconstruction can therefore be used to satisfy these strategic demands.
According to the research carried out by various companies such as 4DViews (Grenoble, France) and XD Productions (Paris, France), it is easy to imagine production studios soon being able to film from all axes using virtual cameras, with actors completely cloned within 3D sets, based on real or completely synthesized objects. We could also create images for a film or television program using virtual video. Technologically, multiview reconstruction will create new dedicated processing tools for the image industry through adjusting and hybridizing multiscopic video streams for reconstructive, relighting and composition purposes. These tools will provide:
− freedom and precision for scaling and movement of recording devices;
− an unlimited number of cameras;
− infinite possibilities for slow motion analysis, production and composition.
8.6. Bibliography
[ARC 11] ARCILA R., Séquences de maillages: classification et méthodes de segmentation, PhD Thesis, Université Claude Bernard - Lyon I, November 2011.
[BAR 07] BARAN I., POPOVIĆ J., “Automatic rigging and animation of 3D characters”, ACM SIGGRAPH 2007 Papers, SIGGRAPH ’07, ACM, New York, NY, 2007.
[CAI 06] CAILLETTE F., Real-time markerless 3D human body tracking, PhD Thesis, University of Manchester, 2006.
[DE 08] DE AGUIAR E., THEOBALT C., THRUN S., et al., “Automatic conversion of mesh animations into skeleton-based animations”, Computer Graphics Forum, vol. 27, pp. 389–397, 2008.
[JAC 07] JACKA D., REID A., MERRY B., et al., “A comparison of linear skinning techniques for character animation”, Proceedings of the 5th international conference on Computer graphics, virtual reality, visualisation and interaction in Africa, AFRIGRAPH ’07, ACM, New York, NY, pp. 177–186, 2007.
[KHR 11] KHRONOS™ GROUP, “OpenCL – the open standard for parallel programming of heterogeneous systems”, available at http://www.khronos.org/opencl/ 2011.
[KUT 00] KUTULAKOS K.N., SEITZ S.M., “A theory of shape by space carving”, International Journal of Computer Vision, vol. 38, no. 3, pp. 199–218, July 2000.
[LAZ 07] LAZEBNIK S., FURUKAWA Y., PONCE J., “Projective visual hulls”, International Journal of Computer Vision, vol. 74, no. 2, pp. 137–165, August 2007.
[MAT 04] MATSUYAMA T., WU X., TAKAIT T., et al., “Real-time 3D shape reconstruction, dynamic 3D mesh deformation, and high fidelity visualization for 3D video”, Computer Vision and Image Understanding, vol. 96, no. 3, pp. 393–434, 2004.
[PET 11] PETIT B., LETOUZEY A., BOYER E., “Flot de surface á partir d’indices visuels”, ORASIS-Congrés des jeunes chercheurs en vision par ordinateur, INRIA Grenoble Rhône-Alpes, Praz-sur-Arly, France, 2011.
[SEI 99] SEITZ S.M., DYER C.R., “Photorealistic scene reconstruction by voxel coloring”, International Journal of Computer Vision, vol. 35, no. 2, pp. 151–173, 1999.
[SNO 00] SNOW D., VIOLA P., ZABIH R., “Exact voxel occupancy with graph cuts”, Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2000, vol. 1, pp. 345–352, 2000.
[STA 99] STAUFFER C., GRIMSON W., “Adaptive background mixture models for real-time tracking”, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 1999, vol. 2, pp. 637–663, 1999.
[SZE 93] SZELISKI R., “Rapid octree construction from image sequences”, CVGIP: Image Understanding, vol. 58, no. 1, pp. 23–32, July 1993.
[VED 05] VEDULA S., BAKER S., RANDER P., et al., “Three-dimensional scene flow”, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 3, pp. 475–480, March 2005.
[WEI 11] WEINLAND D., RONFARD R., BOYER E., “A survey of vision-based methods for action representation, segmentation and recognition”, Computer Vision and Image Understanding, vol. 115, no. 2, pp. 224–241, 2011.
[ZIV 04] ZIVKOVIC Z., “Improved adaptive Gaussian mixture model for background subtraction”, Proceedings of the 17th International Conference on Pattern Recognition, 2004, ICPR 2004, vol. 2, pp. 28–31, August 2004.
1 Application programming interface.