
6
The Requirements and Architectural Advances to Support URLLC Verticals
Ulas C. Kozat1, Amanda Xiang2, Tony Saboorian2, and John Kaippallimalil2
1 Futurewei Technologies, Santa Clara, CA, USA
2 Futurewei Technologies, Plano, TX, USA
Abstract
This chapter provides a self-contained overview of the vertical requirements as well as the technical and architectural concepts that is critical in delivering ultra-reliable and lowlatency communications (URLLC) services. It presents a number of popular URLLC use cases. The chapter focuses on the new 5G network architecture and how it can be interfaced with URLLC applications. It explains the evolution of software defined networking and network function virtualization concepts, 5G core network and notions such as application specific slicing. A cloud-native architecture divides the tightly integrated and virtualized network functions-specific software stack into more scalable, reusable and efficiently deployable software components. The implications of cloud native network functions and architecture on provisioning URLLC services should be carefully considered. The 5G system service-based architecture and extensions for vertical and URLLC applications are under discussion in 3GPP standards.
Keywords 5G network architecture; cloud native architecture; deployable software components; software stack; ultra reliable and low latency communications vertical; virtualized network functions
6.1 Introduction
Vertical applications will be the main driving force for 5G deployments, and ultra‐reliable and low‐latency communications (URLLC) capability is one of the key 5G features attracting many vertical industries and applications, such as industrial Internet of Things (IoT), smart grid, vehicle to X, and professional multi‐media production industry. Because of the nature of their application requirements, these vertical industries provide unprecedented use cases and requirements for 5G URLLC services, which guides the communication industry to develop suitable 5G technologies and deployment options. Our goal in this chapter is to provide a self‐contained overview of the vertical requirements as well as the technical and architectural concepts that will be critical in delivering URLLC services.
The organization of this chapter is divided into two parts. In the first part of the chapter, a number of popular URLLC use cases are presented. As will become clearer later in that part, URLLC use cases are quite broad and even within the same vertical use case (e.g. factory automation) there are various payloads with quite diverse requirements. Furthermore, some of these vertical use cases have quite different privacy, isolation, and control requirements impacting their network deployment scenarios. The most recent focus in standardization organizations is overviewed accordingly.
In the absence of a single dominating killer application, a network architect can design a URLLC service either based on the most stringent requirements or design a system that covers as many use cases as possible under the cost budget. Neither of these options, however, is desirable as they do not reflect the evolving market needs appropriately. As standardization and deployment of networks that cover these cases take many years, once the network is deployed, it has to generate net revenue from the considered use cases for further investment, which can cripple the adoption of new services and creation of new markets on time. This brings us to the notion of decoupling the infrastructure from the network functionality and services. While the former is purely about the fixed assets that are once deployed, they must have a long enough lifetime to amortize their investment, the latter constitutes the real added value that the networks are providing. Thus, the notion of network programmability and more modular network stack through functional disaggregation, network virtualization, network function virtualization (NFV), and software defined networks are indispensable for the overall success of URLLC services.
In the second part of the chapter, the focus is therefore shifted toward the new 5G network architecture and how it can be interfaced with URLLC applications. The evolution of software defined networking SDN and NFV concepts, 5G core network and notions such as application specific slicing are explained in more detail. In particular, the content covers: (i) the three phases of SDN research and development, (ii) NFV background and its evolution into the cloud native era, (iii) the functional disaggregation, flattened and micro‐service‐based evolution of the control plane, control plane and user plane separation, and mobility in 5G core networks, and (iv) network slicing as the key interfacing between URLLC applications and the network.
By the end of the chapter, the reader will gain significant insights on URLLC use cases and the key architectural concepts needed for their success.
6.2 URLLC Verticals
In this section, we summarize a few of the new use cases proposed by the vertical industry players that drive the 5G URLLC discussions in standardization organizations and industrial forums.
6.2.1 URLLC for Motion Control of Industry 4.0
Industry 4.0, or smart manufacturing, is becoming a global industry trend to transform traditional factories into smart factories. Instead of being fixed constructs, these smart factories have modular structures and can be reorganized according to evolving business and manufacturing processes. They are augmented to cyber‐physical systems that monitor physical processes, create a virtual copy of the physical world, and make decentralized decisions. Following the IoT paradigm, cyber‐physical systems communicate and cooperate with each other and with humans in real‐time. Such communication and cooperation occurs both internally and across organizational boundaries. Services are offered and used by participants of the value chain [1]. As a mandatory step toward such a transformation, smart factories must host highly reliable and fast communication networks. Some use cases in Industry 4.0, such as motion control in the assembly line, provides very rigid performance targets for 5G URLLC services as explained next.
A motion control system is responsible for controlling the moving and/or rotating parts of machines in a well‐defined manner, for example in printing machines, machine tools, or packaging machines. In a typical assembly line, the motion control system contains a closed loop control system with controller, actuator, and sensors (Figure 6.1) [2].
The interaction among components follows a strictly cyclic and deterministic pattern with a short cycle time (it can be as short as 0.5 ms), and these interactions rely on a URLLC link. Table 6.1 presents three application scenarios and communication service requirements. Considering that these applications require ultra‐low latency for transmitting the control information between the components and their deployments are local and close to each other within the boundaries of the service area, an edge cloud collocated with the access network functions is naturally desired.

Figure 6.1 Motion control system in factory assembly line.
6.2.2 Multi‐Media Productions Industry
Professional culture and creative multi‐media industry has been using wireless technologies for a while, such as using wireless for audio (e.g. microphones, in‐ear monitor), video (e.g. cameras, displays, and projectors), and stage control systems for concerts, filming, and conferences. However, the existing wireless, such as WiFi, Bluetooth, and 4G technologies have their limitations, especially the lack of high reliability and low‐latency capabilities. Therefore, the industry is looking into 5G to provide the industry the suitable communication services that can satisfy the demanding requirements of these professional applications. Let us examine one such application, namely live performance. Figure 6.2 shows the system topology of a live audio performance [2].
In live performance scenarios, artists on stage carry wireless microphones while listening to their own voice through a wireless in‐ear‐monitor (IEM) that is connected to the live audio mixing machine (the artist's voice is fed back to the mixer and transferred back to the artist's ear). Artists may be moving with considerable speeds (up to 50 km/h) around the service area, for instance when they wear roller skates. In the live performance case, the latency of the wireless audio‐production system is much lower and the reliability requirement much higher than other speech transmissions systems because not only does live performance require higher quality audio and real‐time performance to give the best experience to the audience but also the audio source (e.g. a microphone) and the audio sink (e.g. an IEM) are co‐located on the head of the performing artist. Due to human physiology (i.e. cranial bone conduction), an end‐to‐end application latency greater than 4 ms would confuse the performing artist while hearing through the IEM.
Table 6.2 summarizes some of the typical performance requirements for the live performance application [3]. Note that the wireless link latency here is naturally much stricter than the user experienced mouth‐to‐ear latency budget of 4 ms that includes application processing and interfacing latencies.
6.2.3 Remote Control and Maintenance for URLLC
As more augmented reality (AR) devices, robots, and automation systems are being deployed in smart factories and power plants, conducting the operations and maintenance remotely from a control center becomes more desirable to the industry from the cost, safety, and productivity perspectives. For example, the engineers can reside in the central office using AR devices to stream video from a remote and hazardous plant (e.g. mining or drilling site, chemicals factory, etc.) while controlling one or more robots at the same time to conduct maintenance and repair work (e.g. fixing leaks, cooling systems, ventilation, etc.). In some deployments, the distance between the remote plant and the central control office can be up to 5000 km [2]. In this case, highly reliable (999 999–999 999 999% service availability), low latency (end‐to‐end latency <100 ms) and long distance communication links (up to 5000 km) that may span different regions or wide area network are desired.
Table 6.1 Examples of motion control scenarios and characteristics (3GPP TR 22.804) [2].
| Application | No. of sensors / actuators | Typical message size (byte) | Transfer cycle time Tcycle (ms) | Service area | End‐to‐end latency: target value | Communication service availability (%) |
| Printing machine | >100 | 20 | <2 | 100 m × 100 m × 30 m | <Transfer interval | 999 999–99 999 999 |
| Machine tool | ~20 | 50 | <0.5 | 15 m × 15 m × 3 m | <Transfer interval | 999 999–99 999 999 |
| Packaging machine | ~50 | 40 | <1 | 10 m × 5 m × 3 m | <Transfer interval | 999 999–99 999 999 |

Figure 6.2 System diagram for live audio performance.
Table 6.2 Quality of service requirements for live performance.
| Characteristic system parameter | |
| End‐to‐end latency | <600 μs |
| Audio data rate | 100 kbit/s to 54 Mbit/s |
| Packet error ratio | <10−4 |
| No. of audio links | 5–300 |
| Service area | ≤10 000 m2 |
| User speed | ≤50 km/h |
6.2.4 Vehicle‐to‐Everything
Vehicle‐to‐everything (V2X) encompasses various type of vehicular application namely vehicle‐to‐vehicle (V2V), vehicle‐to‐infrastructure (V2I), vehicle‐to‐network (V2N), and vehicle‐to‐pedestrian (V2P). As the industry moving closer to the premise of the connected and autonomous vehicles, the V2X applications are evolving and the performance requirements are becoming more constrained. Basic requirements for exchange of status information of vehicles, position, speed, direction of travel, etc., are strengthened by higher reliability and lower latency targets to meet advanced and emerging V2X applications. The requirements are becoming more restricted with the levels of automation (LoA). The SAE International Standard J3016 defines six levels of driving automation with performance requirements ranging from a human driver to a fully automated system. The LoA are: 0, no automation; 1, driver assistance; 2, partial automation; 3, conditional automation; 4, high automation; and 5, full automation.
3GPP has defined the cellular standards for LTE‐based V2X communication and is currently working on defining 5G‐based V2X communication to meet the advanced requirements. Vehicles Platooning, Advanced Driving (i.e. semi‐automated or fully automated driving), Extended Sensors, and Remote Driving are among V2X scenarios that benefit from the 5G technology. As an example, 3GPP TS22.186 (Enhancement of 3GPP support for V2X scenarios – Stage 1, table 5.5‐1) defines the performance requirements for remote driving as maximum end‐to‐end latency of 5 ms at a reliability of 99.999% and at speeds up to 250 km/h, for information exchange between a user equipment (UE) supporting V2X application and a V2X Application Server.
6.3 Network Deployment Options for Verticals
Traditionally, public mobile network operators (PMNOs) provide the network communication service to the vertical industry companies using cellular technologies to meet their connectivity needs, or the vertical players to develop and manage their own network using unlicensed spectrum, such as WiFi. The existing deployments, however, are rigid and cannot meet the fast growing communication service needs from the verticals, especially to meet the custom and vast requirements on performance, security and privacy dictated by the new business models of the verticals. There is a strong emerging demand from vertical players that there should be a dedicated and isolated URLCC 5G network for them to run their specialized applications. 5G not only introduces new disruptive technologies, but also provides flexible deployment options for new networks, e.g. verticals can own and manage their 5G URLCC network over their own or leased spectrum, or run their applications over specific network slices provisioned by PMNOs. Currently, there are several potential network deployments options for verticals being studied and developed in the industry, which can be divided into two main categories:
- PMNOs work with vertical service owners to provide the desired network services for the verticals.
- Vertical service owners run their isolated and dedicated private 5G URLCC networks without any involvement of the PMNOs.
In the first category, PMNOs would work with verticals to provide certain communication infrastructure and communication service based on the service agreement. Because the data privacy, security, and service assurance for some high priority traffic are critical to the verticals, certain isolation between the vertical's traffic with the rest of the traffic running on the same public mobile network is required. Mobile network operators and verticals have the following deployment options where Multi‐Operator Core Network (MOCN) [4] and network slicing [5–7] have been standardized but need to be further enhanced in order to meet the new requirements from verticals:
- Mobile operator creates Virtual Private Network (VPN) on top of the underlying public network for the verticals by using the well‐defined APN (Access Point Name) concept, where the traffic of the vertical service owner would be associated with and routed within the mobile operator's public network to the vertical's application server. In this option, verticals do not need their own mobile radio access network (RAN) or core network (CN). Instead, they reuse the network of the mobile operator.
- MOCN where the vertical would share the same RAN and same spectrum owned and operated by mobile operators but verticals would have their own mobile CN. The vertical's traffic will be separated and routed from the shared RAN to the vertical's own mobile CN.
- MORAN (Multi‐Operator RAN) is similar to the MOCN case but the main difference is that (in MORAN case) the vertical would have a dedicated frequency in the shared RAN. Thus, MORAN provides better isolation and service assurance for vertical traffic than MOCN.
- Mobile network operator uses network slicing technology to create a dedicated network slice for the vertical network on top of its public network infrastructure.
In the second category, verticals would (i) acquire a dedicated spectrum, (ii) lease the spectrum from the mobile network operator, or (iii) rely on third party neutral host operator to construct and manage its own private network. In some of these private network deployments, verticals may deploy their own non‐3GPP compliant authentication and authorization mechanisms to leverage their existing non‐cellular networking stack. This category of private network deployment options is considered as completely isolated from PMNOs, and may or may not have interaction or service continuity with the public mobile networks. There are also industry efforts being initiated in several industry consortiums and standard organizations to identify and develop the potential solutions to achieve service continuity and mobility between certain private network deployment and public mobile network, such as 5G ACIA, 3GPP, CBRS, and MultiFire.
As covered so far, URLLC vertical has quite broad application requirements and deployment scenarios. Combined with the other services such as enhanced mobile broadband (eMBB) and massive IoT, 5G networks should be very flexible in terms of how services are defined and deployed rather than providing a single network solution for all services. As SDN and NFV concepts have been the key technology areas to bring such flexibility into the communication networks, the next section takes a closer look at SDN and NFV topics as well as how they are adopted in 5G architecture in the context of supporting URLLC verticals.
6.4 SDN, NFV and 5G Core for URLLC
It is widely acknowledged that the 5G system is more than a new radio interface, it is about the new network infrastructure, where programmability, virtualization, network slicing, and cloudification are widely acknowledged and intertwined themes. This section is divided into three parts that overview SDN, NFV, and 5G core concepts to support URLLC services.
6.4.1 SDN for URLLC
SDN simplifies the transport network by removing intelligence from the individual forwarding elements to logically centralized network controllers through which all the control plane functions interact with the state of the forwarding elements. Such an architecture allows to run network controllers and control plane functions over commodity servers and add more services into the control plane in a much more scalable manner independent of the forwarding plane. Furthermore, forwarding plane capacity can be expanded independently as more bandwith is needed.
The first generation of SDN solutions based on OpenFlow specification required switch vendors to follow a particular abstraction: first a single flow table then a pipeline of flow tables and metadata that can be programmed with match and action rules on network flows. First OpenFlow specifications fixed the set of protocols and fields that can be parsed, modified, added, and removed. Later specifications allowed for extensibility of north bound interface (NBI) as more protocols and header fields are supported by vendors.
The second generation of SDN solutions based on OpenFlow or NetConf interfaces allowed modeling of internal pipeline and programmability (e.g. APIs) of each forwarding element separately rather than fixing these models as in the case of the first generation. Thus, network controllers could control a heterogeneous set of network equipment varying from physical layer (e.g. optical and microwave equipment), layer 2 (e.g. Ethernet, MPLS), layer 3 (e.g. IPv4, IPv6), and layer 4 (e.g. TCP, UDP).
The third generation of SDN solutions brought more protocol independence by making the pipeline of the forwarding element itself programmable while deployed on the field (e.g. protocol‐oblivious switching [8], P4 [9], OpenState [10], Programmable Buffers [11], etc.). Thus, it has become possible to support new user plane functionality on the transport network without changing any deployed physical equipment.
The first two generations of SDN solutions greatly helped toward the management and orchestration of network services as it made it simpler to program/change the forwarding behavior of the network while making it possible to run computation and data intensive operations outside the CPU and memory constrained forwarding elements. As SDN flattened the forwarding topology, it opened up new avenues for providing flexibility in traffic engineering and steering in the forms of multi‐path routing, load balancing, anycasting, network slicing, etc., to support network flows that require URLLC services. The third generation of SDN solutions further enabled on path and in‐band solutions to the problem where the control plane itself could be the bottleneck in reacting to network events such as link failures/degradations or sudden changes in traffic patterns. Thus, URLLC services can be better supported.
SDN provides a unified picture to program and configure the underlay (i.e. the transport fabric) and overlay network functions (e.g. all the functions running over the IP network). NFV as covered in the next section is considered as a way of evolving the overlay functions, while SDN is considered as the piece that stitches these overlay functions together and configures them to deliver a particular network service.
6.4.2 NFV for URLLC
6.4.2.1 NFV Background
As the wireless access moves toward a cloud‐based infrastructure, many network functions are no longer hardwired to specific physical nodes in the network. Instead, they become Virtualized Network Functions (VNFs) that can run anywhere in the wireless access cloud and service capacity can be scaled based on the actual realized demand. This flexibility, however, comes with a performance penalty. The first iteration for NFV has heavily relied on virtual machines (VMs) as many network functions are designed as software monoliths that work on a particular hardware configuration and with a particular software stack. The standard ETSI NFV models network services in the form of a topology graph with VNFs as the vertices of that service graph [12]. Furthermore, VNFs themselves are modeled as a topology graph with VNF components (VNFCs) corresponding to the vertices in that graph. Figure 6.3 depicts the high‐level model for a network service example with three VNFs. Each VNF has external and internal (if modeled with more than one VNFC) virtual links, which typically corresponds to a L1, L2 or L3 network or a point‐to‐point connection. In the figure, these external and internal virtual links are enumerated with prefixes eVL and iVL, respectively. If the underlying networking infrastructure is based on SDN, such virtual links (as specified in network service and VNF models) are created and managed by network controller(s). Each VNFC instance is encapsulated in a software container (e.g. VM image) called a Virtualization Deployment Unit (VDU). In many cases (e.g. firewall, customer premise equipment), a VNF is simply composed of one VNFC. In mobile networks, they may have more complex structures with many VNFCs (e.g. vEPC, vIMS, vRAN, etc.). How network functions are bundled together or disaggregated can be vendor or operator specific. The ETSI model is generic enough to cover both legacy and future deployment needs. Although not shown in the figure, ETSI model also incorporates VNF forwarding graphs, where different service function chains can be defined for distinct groups of network flows. Independent of VNF complexity, there is a one‐to‐one relationship between a VNFC instance and a VM instance. As such, the choice of virtualization technologies and stack have direct impact on network latency, throughput and isolation.

Figure 6.3 ETSI model for network service and virtualized network functions.
6.4.2.2 Reducing Virtualization Overhead on a Single Physical Server
As VNFs are deployed on commodity servers, additional processing latency is incurred due to the virtualization layer. Figure 6.4 provides a high‐level view of various external and internal networking scenarios. In Figure 6.4a, the VM is connected to the external networking fabric through the physical hardware (i.e. network interface card). For maximum portability, the virtualization layer can emulate the physical hardware. In this case, network packets to/from the VM follow path 1 in the figure. This path requires CPU interrupts, multiple memory copying, and context switching. Utilizing mature technologies such as SR‐IOV, compatible hardware and modified drivers in VMs, the virtualization layer can be completely bypassed (path 2) preventing CPU interrupts and unnecessary memory copying [13]. In this scenario, the hardware itself supports virtualization and provides per VM packet filtering, buffering, and forwarding. Since the virtualization layer is bypassed and hardware dependency is formed, important features of machine virtualization such as live migration and VM portability cannot be supported.
In Figure 6.4b, a service function chaining scenario is depicted where multiple functions are collocated on the same physical host and process packets of a flow in a chain. When a packet is passed from one VM to the next, various options exist and three of them are enumerated in the figure. In the first option, VMs exchange packets directly via shared memory without any software or hardware switch involvement [14]. This is the fastest option as it eliminates unnecessary memory copies across stacks and interrupts. However, memory isolation is violated and control/management of function chaining becomes more convoluted. In the second option, VMs exchange packets through the virtualization layer utilizing a software switch. This is a relatively slower option particularly for small payloads (e.g. 64 bytes) and longer chains (e.g. one to two orders of magnitude less throughput) even when the software switch is implemented using technologies such as DPDK. Hence, the processing overheads and extra memory copying are still substantial in this option [14, 15]. Nonetheless, it provides a clear separation, extensibility, and controllability. In the third option, VMs exchange packets through the physical hardware bypassing the networking stack in the virtualization layer. This option is fast when packets are outbound/inbound from/to the physical host and few functions in the same chain are collocated. For longer chains, however, this option reaches the limits of the hardware capabilities and does not scale well.

Figure 6.4 Various external and internal networking scenarios for VMs exist with different latency, throughput and isolation properties. (a) External networking and (b) function chaining on the same host.
Network functions need to process millions of packets per second to support data speeds in the order of Gbps. To achieve such fast data paths, there are a number of technical concepts that are applied by different solutions [1,13–18] and we summarize them in the following paragraphs.
Batching. Interrupting CPU processing or performing context switching at such high rates would starve the network functions to perform their tasks. Aggregating processed packets in output buffers at each layer and function, then passing them as a batch to the next layer and function for batch processing substantially reduces the overhead of interrupts and context switching. Vector Packet Processing (VPP) for instance deploys such batch processing aggressively [1]. Batching can be done based on a mixed policy of maximum batch size and maximum timeout value to avoid unnecessary latency. When traffic rate is high, the maximum batch size limits the packet latency. When traffic rate is low (thus it takes a long time to reach the maximum batch size), maximum timeout value limits the packet latency.
Polling. Instead of resorting to I/O interrupts to notify the next network function about the presence of a new packet (or batch of packets) to process, network traffic can be buffered until the next function is scheduled and it polls for the packets [15]. Polling can be done dynamically. When traffic rate is high, every scheduled function will likely have a backlog of traffic and thus the system can achieve maximum throughput. In contrast when traffic rate is low, the CPU resources are heavily under‐utilized, thus rather than waiting for the network function to poll for the packets, an I/O interrupt would reduce the packet latency.
Zero‐copy. Every time a packet is copied from one memory location to another, it adds significant overhead without actually performing useful work on the packet. If the NFV stack is not optimized, a packet can be easily copied several times, e.g. between physical network interface controller (NIC) and host machine kernel, between host machine kernel and guest machine virtual NIC, between virtual NIC and guest machine kernel, between guest machine kernel and guest machine user space, etc. At the expense of additional complexity, zero‐copy‐based systems do not copy the packets from one layer to the next or from one function to the next but provide libraries for direct memory access for reading, modifying and redirecting packet contents [15, 18].
Run‐to‐completion. When user plane functions (UPFs) perform small and well‐defined tasks (e.g. checking IP header and selecting output port), they require a small and well‐defined number of computational cycles. Under such circumstances, it is not worth pre‐empting a currently executing function in order to schedule another function with a newly arriving but higher priority packet. The savings for the higher priority packet would be negligible, thus the tasks queued for pre‐empted function would experience unwarranted delay spurs. Therefore, to streamline the packet processing and provide a steady progress, it is preferable to avoid the overheads of context switching and pre‐emption. Many solutions such as DPDK, NetBricks, and SoftNIC adopt this method [15–17].
Hardware offloading. All the techniques summarized so far fundamentally try to eliminate the idle processing times and the processing cycles wasted toward non‐application related tasks. Even when all such waste is prevented, a software‐based solution over a general‐purpose CPU cannot match the speed, density, and power efficiency of a purpose‐built hardware‐based solution. Offloading tasks such as encryption/decryption, check sum computation, compression, etc., are typical examples for computationally heavy and repeatedly performed tasks in the data plane. Programmable hardware such as P4, FPGA, and GPUs are also getting more attention for deploying hardware accelerated network functions [9, 19, 20].
6.4.2.3 Evolution of NFV toward Cloud Native Network Functions
Decoupling network functions from a specific hardware instance is not the end target but a critical step toward converting access and CNs into a utility‐based computing, storage and communication infrastructure. Rather than dividing the network into silos of integrated boxes, in a cloudified architecture, all the underlying hardware resources are pooled together and utilized as needed, where needed, and in a fine‐grain fashion by many network services. A cloud‐native architecture further divides the tightly integrated and VNF‐specific software stack into more scalable, reusable, and efficiently deployable software components. Adding and removing network function instances without disrupting existing services and user sessions becomes the new norm of scaling the service capacity. Seamless load balancing, routing, traffic engineering, and traffic migration should be supported by the network architecture in support of such capacity scaling. In return, cloud‐native network functions should handle dynamics of instances being popped up or destroyed without any side effects on other instances and ongoing sessions.
Figure 6.5 shows an example service model for cloud native architecture that is being utilized in popular cloud platforms such as Kubernetes [21]. The ETSI NFV model supports a broad class of network services and transport technologies. Thus, operators can utilize their existing transport networks that can be quite heterogeneous. In contrast to the ETSI NFV model for network services and functions depicted in Figure 6.3, the service model in Figure 6.5 provides a much simpler and cleaner service infrastructure as it assumes a homogeneous transport network (e.g. IPv4 or IPv6) and no‐state sharing across deployment instances. The overall emphasis is on how to group functional components, how to scale them, and how to hide cardinality of each functional group behind a single connection used as a service access point. Functional components that are grouped together form a replication group (or unit) that is scaled in that granularity (e.g. leftmost replication group has VNFC‐11 and VNFC‐12, thus adding one more unit adds one more VNFC‐11 and VNFC‐12). Each functional group shares the same memory space and network name space, allowing very fast information exchange/sharing across components in the same group. Each group has a single connection point to the external network and that connection is also shared across the functional components in each group. Cloud native platform distributes incoming traffic on service connection points (e.g. CP‐01 through CP‐04) toward the actual VNFC groups (e.g. CP‐11 through CP‐1N for the first replication group). State‐of‐the‐art platforms perform a load balancing service based on various scheduling policies that enable control over what percentage of traffic is steered toward each group. Such control enables not only more even load distribution but it also simplifies the process of phasing in the new software and phasing out the old software for the VNFC groups.
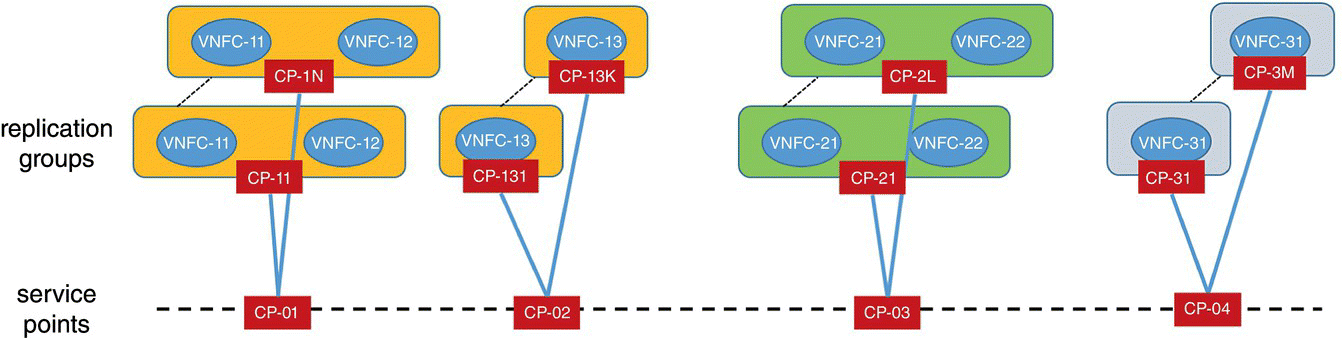
Figure 6.5 An example service model for cloud native architecture.
The implications of cloud native network functions and architecture on provisioning URLLC services should be carefully considered. On the one hand, cloud native systems make it simpler to launch many function instances over a distinct set of physical resources dynamically as a function of load, proximity, and efficiency. As such, it can provide a higher resilience against hardware failures and it also makes it easier to bypass hot spot areas for URLLC services. Figure 6.6 depicts the situation where three VNFCs that have high inter‐component network traffic utilize the same amount of computing resources in a non‐cloud native system (upper row) and cloud native system (lower row). A cloud native system can sustain network service up to two host failures, whereas a non‐cloud native system cannot handle any host failure. Furthermore, a cloud native system can pack component instances that have high traffic volume among each other on the same host, hence facilitating much higher throughput and reduced latency. On the other hand, cloud native systems may have performance issues in this particular set up as follows: Even when network functions are stateless, as soon as some VNFCs are bundled together to optimize the networking performance that would create a state for session processing in the system such that a flow packet processed by a first function on a given host must be processed by a second function on the same host. Otherwise, bundling does not provide any gains in networking performance. Thus, when we admit a number of sessions, each session is assigned to a chain and cannot move to another chain unless it is interrupted and redirected. Assuming an even load balancing of sessions in the example in Figure 6.6, each chain receives one third of all sessions in the cloud native case versus in the non‐cloud native case all sessions are served by the same chain. Thus, there is more statistical multiplexing in the case where VNFCs are not bundled. Nonetheless, this is not a shortcoming of the cloud native design but of the particular configuration and placement choice. Alternatively, all VNFCs of the same type can be collocated to match the configuration of non‐cloud native VNF deployments.
3GPP has already adopted SDN and NFV concepts along with micro‐services in its specifications particularly for the CN as discussed next.
6.4.3 5G Core and Support for URLLC
3GPP specifications [5, 6] include control plane and user plane functionality that provide many basic capabilities to support low‐latency and high‐reliability application flows. Control plane functions in the mobile core have been further disaggregated in comparison with 4G. To support low‐latency and highly reliable applications, 3GPP has initiated new studies on key aspects for URLLC. Enhanced service‐based architecture (eSBA) will study flexibility of UPFs and architectural support for micro‐services and NFV in highly reliable deployments. Several other areas under study for URLLC include support for redundant transmissions, low latency and jitter during handover, session continuity during UE mobility, and QoS monitoring. SDN and NFV make it possible to address these issues in a flexible manner but also require the application of various techniques and optimizations to offer low‐latency and high‐reliability services.

Figure 6.6 Cloud native systems can provide higher service resiliency and faster networking between VNFCs.
Section 6.2 covered various use cases and requirements including motion control for Industry 4.0 and V2X. These services require short end‐to‐end user plane path to support high levels of QoS in terms of latency, bandwidth, and reliability. The control plane that manages the user plane for these services is also distributed significantly to be able to setup connections and manage high speed mobility.
3GPP TS 23.501 [5] specifies the architecture for the 5G system in detail. Figure 6.7 represents a subset of the functionality that is most relevant in the context of vertical URLLC services. This may represent a set of slices for URLLC that has specific supported features and network function optimizations as identified by S‐NSSAI (Subscribed‐Network Slice Selection Assistance Identifier) in the NSSF (Network Slice Selection Function). User plane flows between UE and application function (AF) (e.g. V2X) as well as among UEs (e.g. controller–sensor) need optimization since traversing the default IP gateway (UPF1 that serves as the session anchor point) would result in triangular routing. Low latency flows may also exist between two operators where the source UE and terminating UE are in separate service provider networks. Several other functions – Authentication Server Function (AUSF) for user authentication, NSSF for slice selection, Network Exposure Function for exposing capabilities to the application, Network Repository Function (NRF) for discovering function instances, Policy Control Function (PCF) for providing user and network policies, Network Data Analytics Function (NWDAF) for getting operator specific and slice specific data analytics – provide supporting services and are described further in TS 23.501 [5].
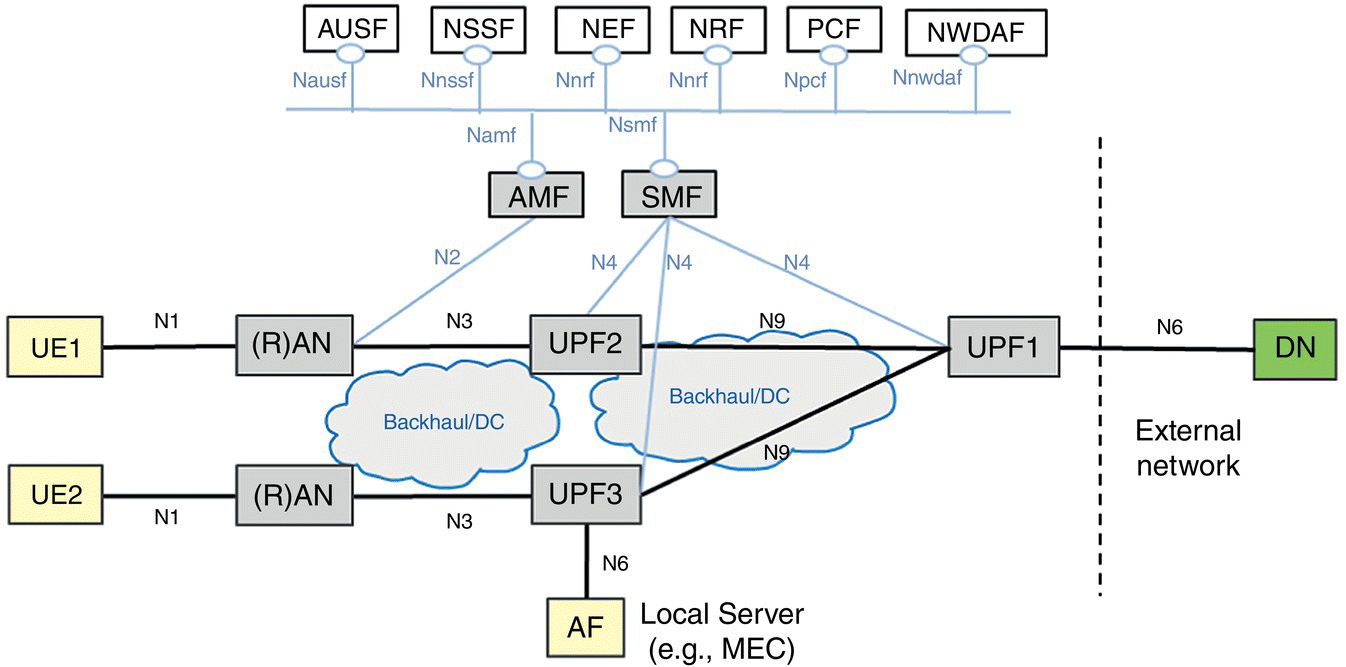
Figure 6.7 5G architecture.
Many vertical applications require a short, low latency, QoS and policy constrained end‐to‐end transport path across radio and IP networks. The Access and Mobility Management Function (AMF) that is responsible for authorizing access and managing mobility of the UE should be able to cope with frequent and high rates of mobility for these applications. User plane path in the radio network (UE–RAN) is handled by the radio access controller and the SMF (Session Management Function) sets up the path across the UPF instances. Service end points are usually close to the UE – for example an end‐to‐end path from UE1 to UE2, or UE1 to AF. Disaggregation of control and user plane functions, and the ability to orchestrate them dynamically with NFV and SDN allow many possibilities for optimization.
SMF and UPF for a flow can be placed optimally. However, programming the forwarding plane and installing routes through the network for large numbers of flows that are also highly mobile is challenging. 5G specifications support three service and session continuity (SSC) modes: in mode 1, a PDU session anchor is kept for the duration of the session, in mode 2 (make‐after‐break) the network may signal the release of the PDU session and request UE to establish a new PDU session to the data network immediately after, and in mode 3 (make‐before‐break), users are allowed to have a new PDN session to the same data network before the old PDU session is released.
SSC modes 2 and 3 are useful for URLLC services that have to also support end‐user mobility. Connectionless services or connection oriented services that are able to tolerate service interruption may use SSC mode 2. Services that are not tolerant of service interruptions can use SSC mode 3 and multi‐homed transports such as MPTCP (Multipath TCP). For low latency end‐to‐end transport of application packets it is necessary to select the shortest paths that traffic engineered to support QoS, other policy constraints and which can be re‐programmed as the UE moves. For the SMF to reprogram the UPF mid‐session, they need to be flexibly provisioned, and NFV and SDN are essential tools. The flexibility that NFV and SDN provide are also necessary to keep the state associated with a session in close proximity. For example, in the flow in Figure 6.8, the (R)AN, AMF, SMF and multiple UPF instances contain soft‐state for the PDU session. These disaggregated functions can be orchestrated to be proximate (i.e. it is a flexible composition of the functions) to deliver optimal control and user plane path.
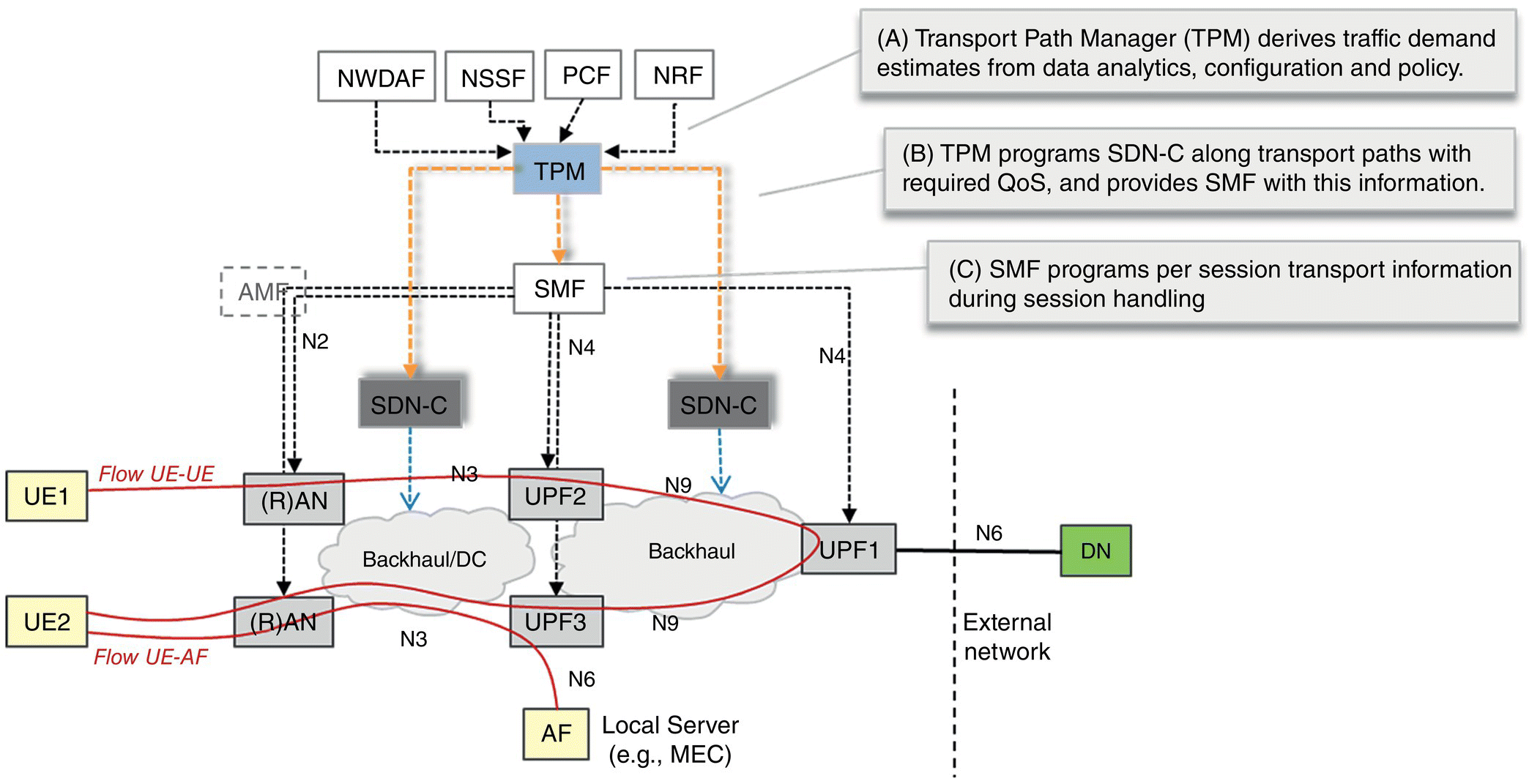
Figure 6.8 Transport path management.
Many end‐to‐end user plane paths for vertical applications terminate within the local network as these applications carry large amounts of data, or are highly latency sensitive. For low latency and high reliability, the transport paths need to be traffic engineered. Figure 6.8 shows a Transport Path Manager (TPM) function that derives traffic demand and programs the routers (via SDN‐C) prior to the SMF setting up session transport paths during PDN attachment. Paths using default routes may not be the shortest – for example, in Figure 6.8, the default path between UE1 and UE2 are via UPF1 (PDU Session Anchor for both UEs). Flexibility in locating user plane functionality with NFV and SDN closer to the RAN can allow for more optimal paths. However, IP addresses allocated by highly distributed UPFs may change quickly as the UE moves to another UPF (more proximate but different IP subnet). For low latency services with high rates of mobility, multi‐homed PDN connections and transports like MPTCP can be a better approach than handovers with IP address change. In all cases, IP transport congestion control actions due to slow‐start, retransmission timeouts, and out‐of‐order delivery and jitter need to be considered. The control plane for managing mobility with IP address change requires a large amount of signaling during PDU session mobility. It is well known that the control plane operates at speeds that are orders of magnitude slower than the data plane [6]. NFV/SDN function placement as well as signaling mobility events in‐band with the data packet can improve high‐speed mobility performance.
The route management mechanisms for mobility considered so far have been based on anchored mobility. Anchor‐based mobility mechanisms have been proven to scale well but they also require a large amount of signaling that can be a problem for high‐speed mobility. With SDN and dynamic reprogramming of network functions, it is feasible to consider rendezvous or anchor‐less mobility [22] or some combination to get better reactivity to fast mobility. However, there are many challenges in terms of scaling as well as modification to end‐hosts (UE) that need further work.
End‐to‐end transport paths that provide guarantees in terms of QoS and resilience are needed in addition to route management. As a result of disaggregation and distribution of UPFs, the available backhaul transport path bandwidth between the micro‐data centers can vary significantly even if the aggregate demand stays the same. Carrying traffic for content delivery, fixed and enterprise networks in an area on the same backhaul network allows for gains with statistical multiplexing. However, it is still necessary to dynamically provision transport paths that can meet the demand in terms of bandwidth and latency. This is illustrated in Figure 6.8 with the SDN Controller (SDN‐C) that can provision requests in the backhaul and data center transports. The TPM collects input on expected session requirements from 3GPP functions such as SMF or NWDAF and provides this to the SDN‐C to provision the traffic matrix. The TPM is a logical function that may be part of the NSSMF (Network Slice Selection Management Function). While the estimation of traffic demand and provisioning of resources is dynamic, i.e. in the order of several minutes, transient change in conditions of a path is signaled via IGP. IGP extensions to protocols such as OSPF to signal preferred path routing to satisfy a policy is being considered in the IETF routing area. These extensions along with the ability to signal OAM and route information in‐band with the data packet allows for disaggregated functions like the UPF to implement policy‐based routing at line speed.
The 5G control plane that is also disaggregated benefits from using NFV and SDN to orchestrate and place functions. For vertical applications, as with the user plane, the control plane is distributed such that the user plane can be controlled efficiently for users requiring low latency and high speed mobility. The 5G system SBA (service‐based architecture) and extensions for vertical and URLLC applications are under discussion in 3GPP standards. It is possible to dynamically instantiate an NF instance and to scale the processing capacity of a function by adding or removing instances. Discovery of these function instances are managed by the NRF. The NRF maintains instance identifier, PLMN identifier, slice information, NF capacity, and IP address among other parameters. Since in an SBA these instances are dynamic, lookups and entry caching need to be enhanced. On path service routers that steer control plane signaling requests to the right instance can be much faster than a service discovery query‐response followed by the signaling message. Performance with caching such dynamic instance information throughout the network versus using service routers and an intermediate hop for signaling requests need to be studied further.
Caching and replication of state information along with function virtualization can be used to design scalable and robust services. For the 5G system, subscriber information, policy, and other data that change less frequently can be cached – with cache coherency mechanisms to ensure that the latest copy of data is read. The volume of data for subscriber and policy information is relatively low and thus the storage overhead for multiple replicas should be acceptable. Signaling and memory/processing overheads are also manageable for synchronizing data that change less frequently (e.g. the system can be optimized for read heavy patterns by keeping write quorums large while read quorums small). This allows such functions to be distributed close to the control functions such as AMF or SMF that requests the data.
For data that changes during the handling of a session (mobility, connection data), it can be replicated to provide fault tolerance against failure of the server. In appliance‐based realizations, as was common with 4G, fault tolerance is handled by replication across one or more cards within the system (N + k, hot or cold standby, etc.). The node (processing cards, system interconnect, etc.) is engineered to tolerate failures needed for the system. Network functions that are virtualized on the other hand can replicate and store data across the network and be more resilient to single point failures. However, they must also be able to handle race conditions as a result of replicating state across a shared network. A simple example is shown in Figure 6.9.

Figure 6.9 Race conditions in distributed functions.
Figure 6.9 is a simplified diagram that shows the outlines of a signaling exchange between the UE and AMF (to signal some access or mobility conditions). The AMF‐a may contact other servers in the system before writing some new state and responding – these details are ignored in the diagram for simplicity. The AMF‐a data stored in the UDSF on Server‐X and replicated to UDSF in Server‐Y and Server‐Z with high system availability. Normally, AMF‐a has session data to process requests from the UE (request/response 1–2). However, after AMF‐a responds to the second sequence (RESPONSE 2), network congestion delays the replication of this information and Server‐X fails. The NRF routes the next request to AMF‐a″ on Server‐Y which has a stale state (state‐1) with which the subsequent request from the UE is processed.
In the above example, it may be noted that Server‐X and Server‐Y may be in the same data center and thus the chance of network congestion or failure there versus that across an access network maybe relatively rare. However, with increasing access speeds and design for vertical applications, these inherent conditions should be designed to be detected and handled in such a way that the processing is consistent.
As with control plane function virtualization, application services (AF in Figure 6.7) can be virtualized with caching and replication for scale and fault tolerance. The 5G system describes using NEF (Network Exposure Function) to expose network capability and events to the AF to support connection and mobility awareness. In this case, the capability is exposed by the control plane entities via a publish‐subscribe mechanism. The subscription and publishing of information is handled on a per UE basis. An alternative approach to selecting AF would be by using IP anycast addressing. Depending on the location at which the UE requests the service, the IP routing can direct it to the appropriate/close instance of that AF. In case of failure (or mobility), a new instance of the AF is selected (e.g. via utilizing IGP routing updates and metrics). The IP anycast solution is known to be highly robust to failure and distributed denial‐of‐service attacks while being scalable as the updates happen per server instance and not per UE. The NEF approach on the other hand provides very fine grained control.
How 5G networks evolve is largely dependent on the successful interfacing between the applications and the network. We present a particular view on such interfacing in the next section.
6.5 Application and Network Interfacing Via Network Slicing
In mobile Internet, applications and networks are decoupled from each other; applications have no direct control over how their packets are processed in the network and the network has no direct control over how the applications perform their end‐to‐end adaptation. In cellular networks, application traffic is classified and marked at the packet gateway for the downstream traffic and at the UE for the upstream traffic to obtain the desired quality of service (QoS). The traffic classification can be based on policies derived via offline methods or can be based on online methods, e.g. utilizing deep packet inspection (DPI). Network elements can utilize certain packet fields (e.g. ECN bits) or selectively drop packets (e.g. employ active queue management) to signal traffic conditions (e.g. congestion) in the network as packets traverse the network. These explicit or implicit signals eventually propagate back to the traffic source through acknowledgments and/or measurement reports from the traffic sink, upon which the traffic source adjusts the sending rate at the session transport (e.g. TCP) or application layer.
The aforementioned mode of operation is seemingly straightforward but in practice it involves multiple control loops at different timescales operating under different objectives and constraints that often negatively interfere with each other. For instance, the end‐to‐end methods for available rate estimation can easily overshoot the instantaneously available rate in the network leading to large queuing delays. End‐to‐end methods can also miss instantaneous high rate transmission opportunities if they underestimate the available rate. Furthermore, providing a number of QoS classes and mapping individual traffic flows in a static manner onto these QoS classes either lead to over‐provisioning or under‐provisioning.
When there is a single class of URLLC applications that have predictable patterns (e.g. payload size and packet inter‐arrival times) with well‐characterized operational environment and communication constraints, one can engineer a network accordingly. Although some use cases satisfy such conditions, many URLLC applications exhibit more complex application traffic patterns and operational characteristics (e.g. see the listed requirements in Section 6.2). Further, in many cases the requirements are not absolute but conservatively estimated figures.
When NFV and SDN are brought into the picture, the overall latency, throughput and reliability are no longer simply a matter of how packets are routed or how link capacities are shared but also depend on how functional composition and configuration is done, where functional components are placed, and how computational resources are scheduled and consumed. Thus, interfacing between applications and network should have the agility to take advantage of such flexibility. Below, we summarize some considerations on how such interfacing can be done.
Figure 6.10 provides a high level view of interaction of application and access cloud that includes RAN, CN, and multi‐access edge computing (MEC). Today, it is very common to have an application with client side code running on the user device and server side code running inside over‐the‐top (OTT) cloud. It is also very common for web services to offload their content to content delivery networks (CDNs) to improve latency, throughput, and scalability. However, CDNs themselves have no control over the access networks and cannot provide guaranteed services that URLLC applications would require. Thus, it is necessary that access clouds not only offer hosting services for application code and data but also network slices extending from the UE to the application code in order to guarantee end‐to‐end QoS.

Figure 6.10 High level view on how UEs and applications utilize access cloud.
In Figure 6.10, computation and data offloading can happen both from OTT cloud to MEC as well as from UEs to MEC [23]. The application logic that runs on the MEC side is labeled as applet, which could be deployed within lightweight containers. Note that in various scenarios the complete application stack might reside at the edge (i.e. in MEC and UEs). The application specific network slices are created both in CN and RAN with application‐specific user plane as well as control plane functions. Common examples of control plane functions would be related to monitoring, pricing, mobility management, and slice configuration. Examples of UPFs include tunneling, encryption, traffic filtering, metering, marking, active queue management, caching, deduplication, transcoding, network coding, routing (multi‐path, anycast, multicast), load balancing, etc.
Network slicing serves as the main abstraction that interfaces applications with the network. Unlike the case where one network carries all workloads, network slicing provides an explicit intent on communication services offered by the network and communication services requested by the applications. Thus, the objectives of the applications and the network can be aligned. In the current 5G spec (i.e. Release 15), only three broad slice types are defined, namely, eMBB, URLLC, and massive IoT. These are envisioned as quasi‐static network services that are available in large service areas utilizing NFV in the core and slice‐aware provisioning in the RAN. Thus, Service Level Agreements (SLAs) and capacities for each network slice are provisioned in a proactive manner with the mindset of traditional top‐down network planning. Application‐specific slicing that is imagined as a real‐time interface between applications and the network is beyond the current 3GPP specification.
Figure 6.11 shows the benefit of providing application specific slicing. With pre‐built generic slice types, a new type of URLLC application needs to be admitted into either a slice type that can provide performance that provides higher than targeted performance at a higher cost or lower than the targeted performance albeit at a lower cost. When the performance utility curve as a function of the amount of consumed resources is concave (e.g. with diminishing returns as in Figure 6.11), providing an application‐specific slice can deliver just the right performance consuming the minimum amount of resources.
Network slices are created and modified based on the network service requests coming from UE or the server side of the application layer. The application programming interfaces (APIs) for network service requests might be intent‐based APIs. Intent‐based APIs do not specify how the network service is delivered and applications themselves are unaware of the network slices. One level of intent can be directly based on SLA targets and specify a request such as “provide a downlink bandwidth of 1Gbps from Applet X to UE Y with a maximum packet latency of 5 ms”. However, application level intents need not be intrinsically unique values, i.e. intents might change as context such as network conditions, pricing, location, customer preferences, etc. change. For more dynamic and iteratively refined service provisioning, the network should support APIs to provide real‐time availability as well as pricing information of various SLA levels. Machine learning based algorithms can be used to steer the slice functionality and resources toward the desired level of service for the end users given a particular context.

Figure 6.11 The trade‐off between resource efficiency and performance in network slicing.
For ultra‐low latency, once the geographical proximity is shortened, the most critical aspect is the queueing delay. In cellular networks, it is typical for base stations to isolate traffic coming from distinct UEs and provide a fair scheduling across them. Thus, most queueing occurs at the bottleneck wireless link due to self‐congestion, i.e. source rate exceeding what is actually available based on the presence of other flows and channel states. The network can provide resource allocation guarantees to network slices but cannot guarantee the actual transmission capacity realized over these resources as capacity is dictated by the channel states. However, the network has all the information available to forecast the available capacity per application flow and how it fluctuates. Feeding such information to applications via open (potentially slice‐specific) APIs can eliminate almost all queueing delays while closely following the available capacity. As the slices are application specific, different applications are isolated and protected against each other at the slice level. Thus, misbehaving applications simply hurt themselves. For different network flows of the same application, the corresponding network slice instance should have the right end‐to‐end buffer isolation and fair scheduling among network flows within its realm in line with how rate estimations are performed.
One major concern against the paradigm shift of application‐specific slicing is about the system complexity and its scalability as the number of potential applications can be tremendously high. Since mobile networks are fluid in nature with demand and wireless link capacities shifting in time and space, network slices also need to be fluid in terms of functional composition, placement, and resource allocation [24]. The introduction of micro‐services and function as service concepts [25] into the CN and RAN infrastructure will enable fine‐grain and fast resource allocation/deallocation of computing and memory resources. Complementing the fine‐grain dynamic allocation of traditional network resources (e.g. link bandwidth, spectrum, power, beams, etc.), they have the potential to pave the way for application‐specific slicing. As a stepping stone toward this paradigm shift, the telephone companies can initially focus on two pillars on top of their programmable cloudified networks: (i) delivering dynamically scalable network slices with fewer broad categories as defined in Release 15 and address spatio‐temporal dynamics of demand as well as radio network capacity, and (ii) network automation based on data analytics and machine learning. Once these building blocks are in place, the network operators can naturally evolve their infrastructure to support application‐specific slicing as monetization opportunities emerge with high‐end applications.
6.6 Summary
URLLC is the new frontier for the wireless networks. New markets within the realm of public networks as well as in the context of private isolated networks is emerging. The success of URLLC depends on how network operators (in both public and private settings) can trade off capacity, delay, mobility, energy efficiency, and reliability in a dynamic manner based on the specific applications and network environment. Network slicing adopted in 5G networks makes it possible to pick different trade‐off points for different use cases. As more and more services are being adopted, there is a need to provide a continuum of these trade‐off points to most effectively utilize the system resources. We have presented how new architectural concepts and network programmability are taking the next generation networking many steps closer to that target.
References
- 1 FD.io (2017). The Vector Packet Processor (VPP) https://fd.io/vppproject/vpptech/ (accessed 27 November 2019)
- 2 3GPP TR 22.804 (2018). Study on Communication for Automation in Vertical Domains.
- 3 3GPP TR 22.827 (2018). 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Study on Audio‐Visual Service Production (Release 17).
- 4 3GPP TS 23.251 (2018). 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Network Sharing; Architecture and Functional Description (Release 15).
- 5 3GPP TS 23.501 (2018). 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; System Architecture for the 5G System (Release 15).
- 6 3GPP TS 23.502 (2018). 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Procedures for the 5G System; Stage 2 (Release 15).
- 7 3GPP TS 28.531 (2018). 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Management and Orchestration; Provisioning (Release 15).
- 8 Song, H. (2013). Protocol‐oblivious forwarding: unleash the power of SDN through a future‐proof forwarding plane. Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking (HotSDN '13). New York, NY, USA: ACM, pp. 127–132.
- 9 Bosshart, P., Daly, D., Gibb, G. et al. (2014). P4: programming protocol‐independent packet processors, ACM SIGCOMM. Computer Communication Review 44 (3).
- 10 Bianchi, G., Bonola, M., Capone, A., and Cascone, C. (2014). OpenState: programming platform‐independent stateful openflow applications inside the switch. Computer Communication Review 44 (2): 44–51.
- 11 Lin, Y., Kozat, U.C., Kaippallimalil, J. et al. (2018). Pausing and resuming network flows using programmable buffers. Proceedings of the Symposium on SDN Research (SOSR '18). Los Angeles, CA, USA: ACM.
- 12 ETSI (2014). Network Functions Virtualisation (NFV); Management and Orchestration. ETSI GS NFV‐MAN 001 V1.1.1 (2014‐12).
- 13 Intel (2011). PCI‐SIG SR‐IOV Primer: An Introduction to SR‐IOV Technology. https://www.intel.com/content/dam/doc/application‐note/pci‐sig‐sr‐iov‐primer‐sr‐iov‐technology‐paper.pdf (accessed 18 October 2019).
- 14 Bernal, M.V., Cerrato, I., Risso, F., and Verbeiren, D. (2016). A Transparent Highway for inter‐Virtual Network Function Communication with Open vSwitch. Proceedings of the 2016 ACM SIGCOMM Conference (SIGCOMM '16). New York, NY, USA: ACM, pp. 603–604.
- 15 Intel (2013). DPDK: Data Plane Development Kit. http://dpdk.org.
- 16 Panda, A., Han, S., Jang, K. et al. (2016). NetBricks: taking the V out of NFV. Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (OSDI’16). Berkeley, CA, USA: USENIX Association, pp. 203–216.
- 17 Han, S., Jang, K., Panda, A. et al. (2015). SoftNIC: A Software NIC to Augment Hardware. Technical Report UCB/EECS‐2015‐155, EECS Department, University of California, Berkeley, USA.
- 18 Rizzo, L. (2012). Netmap: a novel framework for fast packet I/O. Proceedings of the 2012 USENIX Conference on Annual Technical Conference (USENIX ATC '12). Berkeley, CA, USA: USENIX Association, p. 9‐9.
- 19 AWS (2018). Amazon EC2 F1 Instances. https://aws.amazon.com/ec2/instance‐types/f1 (accessed 18 July 2018).
- 20 Yi, X., Duan, J., and Wu, C. (2017). GPUNFV: a GPU‐Accelerated NFV System. Proceedings of the First Asia‐Pacific Workshop on Networking (APNet '17). New York, NY, USA: ACM, pp. 85–91.
- 21 Kubernetes (2018). Learn Kubernetes Basics. https://kubernetes.io/docs/tutorials/kubernetes‐basics (accessed 24 July 2018).
- 22 Auge, J., Carofiglio, G., Grassi, G. et al. (2015). Anchor‐less producer mobility in ICN. Proceedings of the 2nd ACM Conference on Information‐Centric Networking (ICN’15). New York, NY, USA: ACM, pp. 189–190.
- 23 Satyanarayanan, M., Bahl, P., Caceres, R., and Davies, N. (2009). The Case for VM‐Based Cloudlets in Mobile Computing. IEEE Pervasive Computing 8 (4): 14–23.
- 24 Leconte, M., Paschos, G.S., Mertikopoulos, P., and Kozat, U.C. (2018). A resource allocation framework for network slicing. IEEE Infocom 2018, Hawaii, USA (April 2018).
- 25 Hendrickson, S., Sturdevant, S., Harter, T. et al. (2016). Serverless computation with OpenLambda 8th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud’16), Denver, CO, USA (June 2016).