
A common problem that developers find themselves faced with is that they have an operation that spends a lot of time waiting for something to happen, as well as other operations which do not depend on the results of that first operation. It can be frustrating to wait for the slow operation to complete when there are other things the program could be doing. This is the fundamental problem that asynchronous programming tries to solve.
This problem becomes most noticeable during IO operations, such as network requests. In our aggregation process, we have a loop which issues HTTP requests to various endpoints, then processes the results. These HTTP requests can take some time to complete, as they often involve examining external sensors and looking at values over a few seconds. If each request takes 3 seconds to complete, then checking 100 sensors would mean waiting for 5 minutes, on top of all the processing time.

Step-by-step process for connecting to three sensor servers and downloading their data

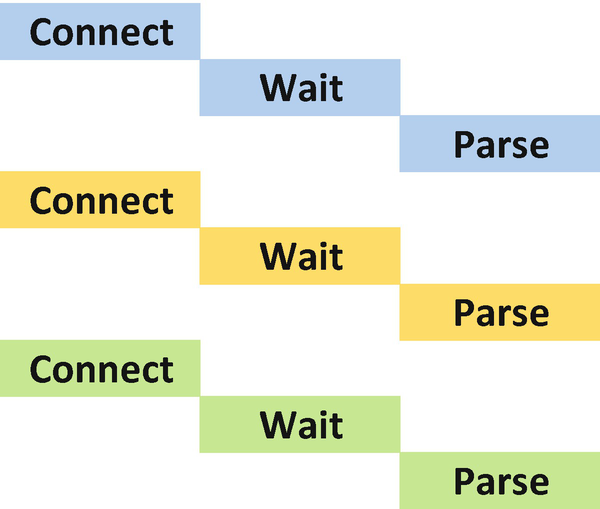
Step-by-step process with parallelized waiting, parsing does not necessarily happen in order
Of course, computers have practical limits on how many network requests can be outstanding at once. Anyone who has copied files to an external hard drive is familiar with the idea that some storage media are better equipped to process multiple sequential accesses than parallel ones. The best fit for parallel programming is when there is a balance between IO-bound and CPU-bound operations that need to be performed. If there is an emphasis on CPU-bound, the only speed increases possible are by committing more resources. On the other hand, if there is too much IO happening, we may have to limit the number of simultaneous tasks to avoid a backlog of processing tasks building up.
Nonblocking IO
The simplest way to write asynchronous functions in Python, and one that has been possible for a very long time, is to write functions that use nonblocking IO operations. Nonblocking IO operations are variants of the standard IO operations that return as soon as an operation starts, rather than the normal behavior of returning when it completes.
Some libraries may use these for low-level operations, like reading from a socket, but it’s rare for them to be used in more complex settings or by most Python developers. There are no widely used libraries to allow developers to take advantage of nonblocking IO for HTTP requests, so I cannot recommend it as a practical solution to the problem of managing simultaneous connections to web servers. Still, it’s a technique that was used more in the Python 2 era, and it’s interesting to look at as it helps us understand the advantages and disadvantages of more modern solutions.
We’ll look at an example implementation here so that we can see the differences in how the code must be structured to take advantage of this. The implementation relies on the select.select(...) function of the standard library, which is a wrapper for the select(2) system call. When given a list of file-like objects (which includes sockets and subprocess calls), select returns the ones that have data ready for reading1 or blocks until at least one is ready.
select represents the key idea of asynchronous code, the idea that we can wait for multiple things in parallel, but with a function that handles blocking until some data is ready. The blocking behavior changes from waiting for each task in turn to waiting for the first of multiple simultaneous requests. It may seem counterintuitive that the key to a nonblocking IO process is a function that blocks, but the intention isn’t to remove blocking entirely, it’s to move the blocking to when there is nothing else we could be doing.
Blocking is not a bad thing; it’s what allows our code to have an easy-to-understand execution flow. If select(...) did not block when there were no connections ready, we’d have to introduce a loop to call select(...) repeatedly until a connection is ready. Code that blocks immediately is easier to understand, as it never has to handle cases where a variable is a placeholder for a future result that is not yet ready. The select approach sacrifices some of that naïve clarity in our program flow by deferring the blocking until a later point, but it allows us to take advantage of parallelized waiting.
The following example functions are very optimistic; they are not standards-compliant HTTP functions, and they make many assumptions about how the server behaves. This is intentional; they are here to illustrate an approach, not as a recommendation for code to be used in the real world. It works well enough for instructional and comparison purposes, and that’s about it.
Optimistic nonblocking HTTP functions – nbioexample.py
The get_http(...) function is what creates the socket. It parses the URL that it has been given and sets up a TCP/IP socket to connect to that server. This does involve some blocking IO, specifically any DNS lookups and socket setup actions, but these are relatively short compared to the time waiting for the body, so I have not attempted to make them nonblocking.
Then, the function sets this socket as nonblocking and uses the h11 library to generate a HTTP request. It’s entirely possible to generate a HTTP request2 with string manipulation alone, but this library simplifies our code significantly.
We call the read_from_socket(...) function once there is data available on the socket. It assumes that there are less than 1000000 bytes of data and that represents a complete response,3 then uses the h11 library to parse this into objects representing the headers and the body of the response. We use that to determine if the request was successful and return either the body of the response or raise a ValueError. The data is decoded as UTF-8 because that’s what Flask is generating for us on the other end. It’s essential to decode with the correct character set; this can be done by providing a header with the character set defined or by having some other guarantee about what the character set is. As we also wrote the server code, we know that we’re using Flask’s built-in JSON support, which uses Flask’s default encoding, which is UTF-8.
In some situations, you may not know for sure which character encoding is in use. The chardet library analyzes text to suggest the most likely encoding, but this is not foolproof. This library, or fallback like try/except blocks with multiple encodings, is only appropriate when loading data from a source that is not consistent and does not report its encoding. In the majority of cases, you should be able to specify the exact encoding, and you must do this to avoid subtle errors.
Making our code nonblocking
Additional glue functions
It may sound minor, but this is sufficient reason to decide against using this method of making HTTP requests in production code. Without a library to simplify the API here, the cognitive load that is added by using nonblocking sockets is, in my opinion, excessive. The ideal approach would introduce no changes to the program flow, but minimizing the changes helps keep code maintainable. The fact that this implementation leaks the raw sockets into application functions is unacceptable.
Overall, while this approach does reduce waiting time, it requires us to restructure our code significantly, and it only provides savings in the wait step, not in the parsing stage. Nonblocking IO is an interesting technique, but it is only appropriate for exceptional cases and requires significant alterations to program flow as well as abandoning all common libraries to achieve even the most basic outcomes. I don’t recommend this approach.
Multithreading and multiprocessing
Parallel tasks when using threading or multiple processes
The code within a thread always executes in order, but when multiple threads are running at once, there is no guarantee that their execution is synchronized in any meaningful way. Even worse than that, there’s no guarantee that the execution of code in different threads is aligned to a statement boundary. When two threads access the same variable, there’s no guarantee that either of the actions are performed first: they can overlap. The internal low-level "bytecode" that Python uses to execute user functions are the building blocks of parallelism in Python, not the statement.
Low-level threads
The two methods of providing the code for a thread to execute
import threading def helloworld(): print("Hello world!") thread = threading.Thread( target=helloworld, name="helloworld" ) thread.start() thread.join() | import threading class HelloWorldThread(threading.Thread): def run(self): print("Hello world!") thread = HelloWorldThread(name="helloworld") thread.start() thread.join() |
The start() method begins the execution of the thread; the join() method blocks the execution until that thread has completed. The name parameter is mostly useful for debugging performance problems, but it’s a good habit always to set a name if you’re ever creating threads manually.
Threads do not have a return value, so if they need to return a computed value, that can be tricky. One way of passing a value back is by using a mutable object that it can change in place or, if using the subclass method, by setting an attribute on the thread object.
An attribute on the thread object is a good approach when there is a single, simple return type, such as a boolean success value, or the result of a computation. It’s a good fit for when the thread is doing a discrete piece of work.
A mutable object is the best fit when you have multiple threads, each working on a part of a common problem, for example, gathering the sensor data from a set of URLs, with each thread being responsible for one URL. The queue.Queue object is perfect for this purpose.
Rather than adjust the function directly, write some code to wrap any arbitrary function and store its results in a queue instead of directly returning, to allow the function to be run cleanly as threads. If you get stuck, look back at Chapter 5 and how to write a decorator that takes arguments.
You must also adjust the get_data_points(...) function to return a list of DataPoint objects, rather than an iterator of them, or to do an equivalent conversion in the wrapper function. This is to ensure that all the data is processed in the thread before it returns its data to the main thread. As generators don’t produce their values until the values are requested, we need to ensure that the requesting happens within the thread.
An example implementation of the wrapper method and a simple threaded version of this program is available in the code samples for this chapter.
Note on __future__ imports
Statements like from __future__ import example are ways of enabling features that will be part of a future version of Python. They must be at the very top of a Python file, with no other statements before them.
In this case, the line q: queue.Queue[t.List[DataPoint]] = queue.Queue() is the problem. The queue.Queue object in the standard library is not a generic type in Python 3.8, so it cannot accept a type definition of the type of objects it contains. This omission is tracked as bug 33315 in Python, where there is justified reluctance to either add a new typing.Queue type or to adjust the built-in type.
or by using the annotations option from __future__, which enables the type annotation parsing logic planned for Python 4. This logic prevents Python from parsing annotations at runtime and is the approach taken in the preceding sample.
This low level of threading is not at all user-friendly. As we’ve seen in the preceding exercise, it is possible to write a wrapper code that makes functions work unchanged in a threaded environment. It would also be possible to write a wrapper for the threading.Thread object that automatically wraps the function being called and automatically retrieves the result from an internal queue and returns it to the programmer seamlessly.
Luckily, we don’t have to write such a feature in production code; there’s a helper built-in to the Python standard library: concurrent.futures.ThreadPoolExecutor. The ThreadPoolExecutor manages the number of threads in use, allowing the programmer to limit the number of threads that execute at once.
Here, we see a context manager that defines the period where the pool of threads is active. As no max_threads argument is passed to the executor, Python picks an amount of threads based on the number of CPUs available on the computer running the program.
If you don’t access the result() method of a future, then any exceptions it raises are never propagated to the main thread. This can make debugging difficult, so it’s best to ensure you always access the result, even if you never assign it to a variable.
If result() is called within the with block, execution blocks until the relevant task has completed. When the with block ends, execution blocks until all scheduled tasks have completed, so calls to the result method after the with block ends always return immediately.
Bytecode
In order to understand some of the limits of threading in Python, we need to look behind the curtain of how the interpreter loads and runs code. In this section, Python code may be shown annotated with the underlying bytecode used by the interpreter. This bytecode is an implementation detail and is stored in .pyc files. It encodes the behavior of the program at the lowest level. Interpreting a complex language like Python is not a trivial task, so the Python interpreter caches its interpretation of code as a series of many simple operations.
When people talk about Python, they generally are talking about CPython, the implementation of Python in the C programming language. CPython is the reference implementation, in that it’s intended to be what people refer to when seeing how Python does things. There are other implementations, the most popular of which is PyPy, an implementation of Python that is written in a specially designed, Python-like language rather than C.4 Both CPython and PyPy cache their interpretation of Python code as Python bytecode.
Two other implementations of Python are worth mentioning: Jython and IronPython. Both of these also cache their interpretation as bytecode, but crucially they use a different bytecode. Jython uses the same bytecode format as Java, and IronPython uses the same bytecode format as .NET. For this chapter, when we talk about bytecode, we’re talking about Python bytecode, as we’re looking at it in the context of how threads are implemented in CPython.
Generally speaking, you won’t have to worry about bytecode, but an awareness of its role is useful for writing multithreaded code. The samples given in the following were generated using the dis module5 in the standard library. The function dis.dis(func) shows the bytecode for a given function, assuming that it’s written in Python, rather than a C extension. For example, the sorted(...) function is implemented in C and therefore has no bytecode to show.
A simple function to increment a global variable
The line num += 1 looks like an atomic operation,6 but the bytecode reveals that the underlying interpreter runs four operations to complete it. We don’t care what these four instructions are, just the fact that we cannot trust our intuition on what operations are atomic and which are not.
If we were to run this increment function 100 times in succession, the result stored to num would be 100, which makes logical sense. If this function were to be executed in a pair of threads, there would be no guarantee that the final result would be 100. In this case, the correct result is only found so long as no thread ever executes the LOAD_GLOBAL bytecode step while another is running the LOAD_CONST, IN_PLACE_ADD, or STORE_GLOBAL steps. Python does not guarantee this, so the preceding code is not thread-safe.

Possible arrangements of two threads executing num += 1 at once. Only the leftmost and rightmost examples produce the correct result
The GIL

Possible arrangements of num += 1 execution with the GIL active. Only the leftmost and rightmost produce the correct result
It might appear that the GIL removes the benefit of threading without guaranteeing the correct result, but it’s not as bad as it immediately appears. We will deal with the benefits of this shortly, but first, we should address this negating the advantages of threading. It’s not strictly true that no two bytecode instructions can run at once.
Bytecode instructions are much simpler than lines of Python, allowing the interpreter to reason about what actions it is taking at any given point. It can, therefore, allow multiple threads to execute when it’s safe to do so, such as during a network connection or when waiting for data to be read from a file.
Specifically, not everything the Python interpreter does requires the GIL to be held. It must be held at the start and end of a bytecode instruction, but it can be released internally. Waiting for a socket to have data available for reading is one of the things that can be done without holding the GIL. During a bytecode instruction where an IO operation is happening, the GIL can be released, and the interpreter can simultaneously execute any code that does not require the GIL to be held, so long as it’s in a different thread. Once the IO operation finishes, it must wait to regain the GIL from whichever thread took it, before execution can continue.
In situations like this, where the code never has to wait for an IO function to complete, Python interrupts the threads at set intervals to schedule the others fairly. By default, this is approximately every 0.005 seconds which happens to be a long enough period that our example works as hoped on my computer. If we manually tell the interpreter to switch threads more frequently, using the sys.setswitchinterval(...) function, we start to see failures.
The default behavior being 100% correct in my test doesn’t mean that it solves the problem. 0.005 is a well-chosen interval that results in a lower chance of errors for most people. The fact that a function happens to work when you test it does not mean that it’s guaranteed to always work on every machine. The trade-off to introducing threads is that you gain relatively simple concurrency but without strong guarantees about shared state.
Locks and deadlocks
By enforcing a rule that bytecode instructions do not overlap, they’re guaranteed to be atomic. There is no risk of two STORE bytecode instructions for the same value happening simultaneously, as no two bytecode instructions can run truly simultaneously. It may be that the implementation of an instruction voluntarily releases the GIL and waits to reobtain it for sections of its implementation, but that is not the same as any two arbitrary instructions happening in parallel. This atomicity is used by Python to build thread-safe types and synchronization tools.
If you need to share state between threads, you must manually protect this state with locks. Locks are objects that allow you to prevent your code from running at the same time as other code that it would interfere with. If two concurrent threads both try to acquire the lock, only one will succeed. Any other threads that try to acquire the lock will be blocked until the first thread has released it. This is possible because the locks are implemented in C code, meaning their execution takes place as one bytecode step. All the work of waiting for a lock to become available and acquiring it is performed in response to a single bytecode instruction, making it atomic.
Code protected by a lock can still be interrupted, but no conflicting code will be run during these interruptions. Threads can still be interrupted while they hold a lock. If the thread that they are interrupted in favor of attempts to take that same lock, it will fail to do so and will pause execution. In an environment with two threads, this means execution would pass straight back to the first function. If more than one thread is active, it may pass to other threads first, but the same inability to take the first thread’s lock applies.
In this version of the function, the lock called numlock is used to guard the actions that read/write the num value. This context manager causes the lock to be acquired before execution passes to the body and to be released before the first line after the body. Although we’ve added some overhead here, it is minimal, and it guarantees that the result of the code is correct, regardless of any user settings or different Python interpreter versions.

Possible arrangements of num += 1 on two threads with explicit locking shown at the start and end
From the perspective of the two threads being used in the thread pool, the with numlock : line may block execution, or it may not. Neither thread needs to do anything special to handle the two cases (acquiring the lock immediately or waiting for a turn), and therefore this is a relatively minimal change to the control flow.
The difficulty comes in ensuring that required locks are in place and that no contradictions exist. If a programmer defines two locks and uses them simultaneously, it’s possible to create a situation where the program becomes deadlocked.
Deadlocks
Three locking approaches for simultaneously updating two variables
Minimizing locked code(resistant to deadlocks) num = 0 other = 0 numlock = hreading.Lock() otherlock = hreading.Lock() def increment(): global num global other with numlock: num += 1 with otherlock: other += 1 return None def decrement(): global num global other with otherlock: other -= 1 with numlock: num -= 1 return None | Using locks in a consistent order (resistant to deadlocks) num = 0 other = 0 numlock = threading.Lock() otherlock = hreading.Lock() def increment(): global num global other with numlock, otherlock: num += 1 cother += 1 return None def decrement(): global num global other with numlock, otherlock: other -= 1 num -= 1 return None | Using locks in an inconsistent order (causes deadlocks) num = 0 other = 0 numlock = hreading.Lock() otherlock = hreading.Lock() def increment(): global num global other with numlock, otherlock: num += 1 other += 1 return None def decrement(): global num global other with otherlock, numlock: other -= 1 num -= 1 return None |
The best option is to ensure that we never hold both locks simultaneously. This makes them truly independent, so there is no risk of deadlock. In this pattern, threads never wait to acquire a lock until they’ve already released the previous lock they held.
This function requires that neither num nor other is being used by another thread while it’s executing, so it needs to keep both numbers locked. Locks are acquired in the same order in the increment() and decrement() (and switch()) functions, so each one tries to acquire numlock before otherlock. If both threads were synchronized in their execution, they would both try to acquire numlock at the same time and one would block. No deadlocks would occur.
The final example shows an implementation where the ordering of the locks in the decrement() function has been inverted. This is very difficult indeed to notice but has the effect of causing deadlocks. It’s possible for a thread running this third version of increment() to acquire the numlock lock at the same time that a thread running decrement acquires the otherlock lock. Now both threads are waiting to acquire the lock they don’t have, and neither can release their lock until after they’ve acquired the missing one. This causes the program to hang indefinitely.
There are a few ways to avoid this problem. As this is a logical assertion about the structure of your code, the natural tool would be to a static checker to ensure that your code never inverts the order in which locks are acquired. Unfortunately, I do not know of any existing implementation of this check for Python code.
The most straightforward alternative is to use a single lock to cover both variables rather than to lock them individually. Although this is superficially attractive, it does not scale well as the number of objects that need protecting grows. A single lock object would prevent any work being done to the num variable while another thread works on the other variable. Sharing locks across independent functions greatly increases the amount of blocking involved in your code, which can serve to negate the advantages brought by threading.
You might be tempted to abandon the with numlock: method of acquiring a lock and calling the lock’s acquire() method directly. While this allows you to specify a timeout and an error handler in case the lock was not acquired within the timeout, I would not recommend it. The change makes the code’s logic harder to follow with the introduction of an error handler, and the only appropriate response to detecting a deadlock in this manner is to raise an exception. This slows down the program because of the timeouts and doesn’t solve the problem. This approach may be useful when debugging locally, to allow you to examine the state during a deadlock, but it should not be considered for production code.
My recommendation would be that you should use all these approaches to preventing deadlocks. Firstly, you should use the minimum amount of locks necessary to make your program thread-safe. If you do need multiple locks, you should minimize the time that they’re held for, releasing them as soon as the shared state has been manipulated. Finally, you should define an ordering of your locks and always use this ordering when acquiring locks. The easiest method to do this is always to acquire locks alphabetically. Ensuring a fixed ordering of locks still requires manual checking of your code, but each use of locks can be checked against your rule independently rather than against all other uses.
Avoiding global state
It’s not always possible to avoid global state, but in many situations, it is. Generally speaking, it’s possible to schedule two functions to run in parallel if neither function depends on the values of shared variables.8 Imagine that instead of 100 calls to increment() and 100 calls to decrement(), we were scheduling 100 calls to increment() and 1 to a function called save_number_to_database(). There is no guarantee how many times increment() will have completed before save_number_to_database() is called. The number saved could be anywhere between 0 and 100, which is clearly not useful. These functions don’t make sense to be run in parallel because they both depend on the value of a shared variable.
There are a couple of main ways that shared data can interrelate. Shared data can be used to collate data across multiple threads, or it can be used to pass data between multiple threads.
Collating data
Our two increment() and decrement() functions are only simple demonstrations. They manipulate their shared state by adding or subtracting one, but normally functions run in parallel would do a more complex manipulation. For example, in apd.aggregation, the shared state is the set of sensor results we have, and each thread adds more results to that set.
Example of using task result to store intended changes
Passing data
The examples we’ve covered so far all involve the main thread delegating work to subthreads, but it’s common for new tasks to be discovered during the processing of the data from earlier tasks. For example, most APIs paginate data, so if we had a thread to fetch URLs and a thread to parse the responses, we need to be able to pass initial URLs to the fetch thread from the main thread and also to pass newly discovered URLs from the parse thread to the fetch thread.
When passing data between two (or more) threads, we need to use queues, either queue.Queue or the variant queue.LifoQueue. These implement FIFO and LIFO9 queues, respectively. While we previously used Queue only as a convenient, thread-safe data holder, now we’ll be using it as intended.
Queues have four primary methods.10 The get() and put() methods are self-explanatory, except to say that if the queue is empty, then the get() method blocks, and if the queue has a maximum length set and is full, then the put() method blocks. In addition, there is a task_done() method , which is used to tell the queue that an item has been successfully processed, and a join() method, which blocks until all items have been successfully processed. The join() method is usually called by the thread that adds the items to the queue, to allow it to wait until all work has been completed.
Because the get() method blocks if the queue is currently empty, it’s not possible to use this method in nonthreaded code. It does, however, make them perfect for threaded code where there is a need to wait until the thread producing data has made it available.
It’s not always clear in advance how many items will be stored in a queue. If get() is called after the last item has been retrieved, then it will block indefinitely. This can be avoided by providing a timeout parameter to get, in which case it will block for the given amount of seconds before raising a queue.Empty exception. A better approach is to send a sentinel value, like None. The code can then detect this value and know that it no longer needs to retrieve new values.
If we were building a threaded program to get information from the GitHub public API, we’d need to be able to retrieve URLs and parse their results. It would be nice to be able to do parsing while URLs are being fetched, so we would split the code between fetching and parsing functions.
Threaded API client
By examining the logged messages from each of the threads, we can view how their work is scheduled in parallel. Firstly, the main thread sets up the necessary queues and subthreads, then waits for all the threads to finish. As soon as the two subthreads start, the fetch thread starts working on the URLs passed by the main thread, and the parse thread quickly pauses while waiting for responses to parse.

Diagram of the timing of the three threads in Listing 7-5
The fetch thread doesn’t use the join() method of any of the queues, it uses get() to block until there is some work to do. As such, the fetch thread can be seen resuming while the parse thread is still executing. Finally, the parse thread sends a sentinel value to the fetch thread to end, and when both exits the thread pool context manager in the main thread exits and execution returns to the main thread.
Other synchronization primitives
The synchronization we used with queues in the preceding example is more complex than the lock behavior we used earlier. In fact, there are a variety of other synchronization primitives available in the standard library. These allow you to build more complex thread-safe coordination behaviors.
Reentrant locks
An example of nested locking using RLocks
The advantage conferred here is that functions that depend on a lock being held can call others that also depend on the same lock being held, without the second blocking until the first releases it. That greatly simplifies creating APIs that use locks.
Conditions
Unlike the locks that we’ve used so far, conditions declare that a variable is ready, not that it is busy. Queues use conditions internally to implement the blocking behavior of get(), put(...), and join(). Conditions allow for more complex behaviors than a lock being acquired.
Conditions are a way of telling other threads that it’s time to check for data, which must be stored independently. Threads that are waiting for data call the condition’s wait_for(...) function inside a context manager, whereas threads that are supplying data call the notify() method. There is no rule that a thread can’t do both at different times; however, if all threads are waiting for data and none are sending, it’s possible to introduce a deadlock.
For example, when calling the get(...) method of a queue, the code immediately acquires the queue’s single lock through its internal not_empty condition, then checks to see if the internal storage of the queue has any data available. If it does, then an item is returned and the lock is released. Keeping the lock for this time ensures that no other users can retrieve that item at the same time, so there is no risk of duplication. If, however, there is no data in the internal storage, then the not_empty.wait() method is called. This releases the single lock, allowing other threads to manipulate the queue, and does not reacquire the lock and return until the condition is notified that a new item has been added.
There is a variant of the notify() method called notify_all(). The standard notify() method only wakes one thread that’s waiting on the condition, whereas notify_all() wakes all threads waiting. It’s always safe to use notify_all() in place of notify(), but notify() saves waking up multiple threads when it’s expected that only one will be unblocked.
A condition alone is only enough to send a single bit of information: that data has been made available. To actually retrieve the data, we must store it in some fashion, like the internal storage of the queue.
An example program using conditions
Barriers
Barriers are the most conceptually simple synchronization objects in Python. A barrier is created with a known number of parties. When a thread calls wait(), it blocks until there are the same number of threads waiting as the number of parties to the barrier. That is, threading.Barrier(2) blocks the first time wait() is called, but the second call returns immediately and releases the first blocking call.
Barriers are useful when multiple threads are working on aspects of a single problem, as they can prevent a backlog of work building up. A barrier allows you to ensure that a group of threads only run as quickly as the slowest member of the group.
A timeout can be included in the initial creation of the barrier or any wait() call. If any wait call takes longer than its timeout, then all waiting threads raise a BrokenBarrierException, as will any subsequent threads that try to wait for that barrier.
Example of using a barrier
Event
Events are another simple synchronization method. Any number of threads can call the wait() method on an event, which blocks until the event is triggered. An event can be triggered at any time by calling the set() method, which wakes all threads waiting for the event. Any subsequent calls to the wait() method return immediately.
As with barriers, events are very useful for ensuring that multiple threads stay synchronized, rather than some racing ahead. Events differ in that they have a single thread that makes the decision for when the group can continue, so they are a good fit for programs where a thread is dedicated to managing the others.
Example of using events to set a minimum wait time
Semaphore
Finally, semaphores are conceptually more complex but are a very old concept and so are common to many languages. A semaphore is similar to a lock, but it can be acquired by multiple threads simultaneously. When a semaphore is created, it must be given a value. The value is the number of times that it can be acquired simultaneously.
Example of using semaphores to ensure only one thread waits at once
ProcessPoolExecutors
Just as we’ve looked at the use of ThreadPoolExecutor to delegate the execution of code to different threads, which causes us to fall foul of the GIL’s restrictions, we can use the ProcessPoolExecutor to run code in multiple processes if we’re willing to abandon all shared state.
When executing code in a process pool, any state that was available at the start is available to the subprocesses. However, there is no coordination between the two. Data can only be passed back to the controlling process as the return value of the tasks submitted to the pool. No changes to global variables are reflected in any way.
Although multiple independent Python processes are not bound by the same one-at-a-time execution method imposed by the GIL, they also have significant overheads. For IO-bound tasks (i.e., tasks that spend most of their time waiting and therefore not holding the GIL), a process pool is generally slower than a thread pool.
On the other hand, tasks that involve large amounts of computation are well suited to being delegated to a subprocess, especially long-running ones where the overhead of the setup is lessened compared to the savings of parallel execution.
Making our code multithreaded
The function that we want to parallelize is get_data_points(...); the functions that implement the command line and database connections do not significantly change when dealing with 1 or 500 sensors; there is no particular reason to split its work out into threads. Keeping this work in the main thread makes it easier to handle errors and report on progress, so we rewrite the add_data_from_sensors(...) function only.
As we will submit all our jobs to the ThreadPoolExecutor before the first time that we call a result() method, they will all be queued up for simultaneous execution in threads. It’s the result() method and the end of the with block that triggers blocking; submitting jobs does not cause the program to block, even if you submit more jobs than can be processed simultaneously.
This method is much less intrusive to the program flow than either the raw threaded approach or the nonblocking IO approaches, but it does still involve changing the execution flow to handle the fact that these functions are now working with Future objects rather than the data directly.
AsyncIO
AsyncIO is the elephant in the room when talking about Python concurrency, thanks mainly to the fact that it’s one of the flagship features of Python 3. It is a language feature that allows for something that works like the nonblocking IO example but with a somewhat similar API to the ThreadPoolExecutor. The API isn’t precisely the same, but the underlying concept of submitting tasks and being able to block to wait for their results is shared between the two.
Asyncio code is cooperatively multitasked. That is, code is never interrupted to allow another function to execute; the switching only occurs when a function blocks. This change makes it easier to reason about how code will behave, as there’s no chance of a simple statement like num += 1 being interrupted.
There are two new keywords that you often see when working with asyncio, the async and await keywords. The async keyword marks certain control flow blocks (specifically, def, for, and with) as using the asyncio flow, rather than the standard flow. The meanings of these blocks are still the same as in standard, synchronous Python, but the underlying code paths can be quite different.
The equivalent of the ThreadPoolExecutor itself is the event loop. When executing asynchronous code, an event loop object is responsible for keeping track of all the tasks to be executed and coordinating passing their return values back to the calling code.
There is a strict separation between code intended to be called from a synchronous context and an asynchronous one. If you accidentally call async code from synchronous contexts, you’ll find yourself with coroutine objects rather than the data types you’re expecting, and if you call synchronous code from an async context, you can inadvertently introduce blocking IO that causes performance problems.
To enforce this separation, and to allow API authors optionally to support both synchronous and asynchronous uses of their objects, the async modifier is added to for and with to specify that you’re using the async-compatible implementation. These variants cannot be used in a synchronous context or on objects that do not have an asynchronous implementation (such as tuples or lists, in the case of async for).
async def
Example of concurrent increment and decrement coroutines
This behaves in the same way: two coroutines are run, their values are retrieved, and the num variable is adjusted according to the result of those functions. The main difference is that instead of these coroutines being submitted to a thread pool, the onehundred() async function is passed to the event loop to run, and that function is responsible for calling the other coroutines that do the work.
The asyncio.run(...) function is the main entrypoint for asynchronous code. It blocks until the passed function, and all other functions which that function schedules, are complete. The upshot is that only one coroutine at a time can be initiated by synchronous code.
await
The await keyword is the trigger for blocking until an asynchronous function has completed. However, this only blocks the current asynchronous call stack. You can have multiple asynchronous functions executing at once, in which case another function is executed while waiting for the result.

Three equivalent uses of the await keyword
An awaitable object is an object that implements the __await__() method . This is an implementation detail; you won’t need to write an __await__() method. Instead, you will use a variety of different built-in objects that provide it for you. For example, any coroutines defined using async def have an __await__() method.
Comparison of tasks and bare coroutines for parallel waiting
Awaiting coroutines directly import asyncio import time async def slow(): start = time.time() await asyncio.sleep(1) await asyncio.sleep(1) await asyncio.sleep(1) end = time.time() print(end - start) >>> asyncio.run(slow()) 3.0392887592315674 | Converting to tasks first import asyncio import time async def slow(): start = time.time() first = asyncio.create_task(asyncio.sleep(1)) second = asyncio.create_task(asyncio.sleep(1)) third = asyncio.create_task(asyncio.sleep(1)) await first await second await third end = time.time() print(end - start) >>> asyncio.run(slow()) 1.0060641765594482 |
There are some useful convenience functions to handle scheduling tasks based on coroutines, most notably asyncio.gather(...) . This method takes any number of awaitable objects, schedules them as tasks, awaits them all, and returns an awaitable of a tuple of their return values in the same order that their coroutines/tasks were originally given in.
async for
The async for construct allows iterating over an object where the iterator itself is defined by asynchronous code. It is not correct to use async for on synchronous iterators that are merely being used in an asynchronous context or that happen to contain awaitables.
None of the common data types we’ve used are asynchronous iterators. If you have a tuple or a list, then you use the standard for loop, regardless of what they contain or if they’re being used in synchronous or asynchronous code.
This section contains examples of three different approaches to looping in an asynchronous function. Type hinting is especially useful here, as the data types here are subtly different, and it makes it clear which types each function expects.
Looping over a list of awaitables
In the add_all(...) function, the loop is a standard for loop, as it’s iterating over a list. The contents of the list are the result of number(2) and number(3), so these two calls need to be awaited to retrieve their respective results.
Awaiting a list of integers
The numbers() coroutine is now responsible for awaiting the individual number(...) coroutines. We still use a standard for loop, but now instead of awaiting the contents of the for loop, we await the value we’re looping over.
With both approaches, the first number(...) call is awaited before the second, but with the first approach, control passes back to the add_all(...) function between the two. In the second, control is only passed back after all numbers have been awaited individually and assembled into a list. With the first method, each number(...) coroutine is processed as it’s needed, but with the second all processing of the number(...) calls happens before the first value is used.
Asynchronous generator
We still need the await keywords in the numbers() method as we want to iterate over the results of the number(...) method, not over placeholders for the results. Like the second version, this hides the details of awaiting the individual number(...) calls from the sum(...) function, instead of trusting the iterator to manage it. However, it also retains the property of the first that each number(...) call is only evaluated when it’s needed: they’re not all processed in advance.
For an object to support being iterated over with for, it must implement an __iter__ method that returns an iterator. An iterator is an object that implements both an __iter__ method (that returns itself) and a __next__ method for advancing the iterator. An object that implements __iter__ but not __next__ is not an iterator but an iterable. Iterables can be iterated over; iterators are also aware of their current state.
Equally, an object that implements an asynchronous method __aiter__ is an AsyncIterable. If __aiter__ returns self and it also provides an __anext__ asynchronous method, it’s an AsyncIterator.
A single object can implement all four methods to support both synchronous and asynchronous iterations. This is only relevant if you’re implementing a class that can behave as an iterable, either synchronous or asynchronous. The easiest way to create an async iterable is using the yield construct from an async function, and that’s enough for most use cases.
Using gather to process tasks in parallel
async with
The with statement also has an async counterpart, async with, which is used to facilitate the writing of context managers that depend on asynchronous code. It’s quite common to see this in asynchronous code, as many IO operations involve setup and teardown phases.
In the same way that async for uses __aiter__ rather than __iter__, asynchronous context managers define the __aenter__ and __aexit__ methods to replace __enter__ and __exit__. Once again, objects can choose to implement all four to work in both contexts, if appropriate.
When using synchronous context managers in an asynchronous function, there’s a potential for blocking IO to happen before the first line and after the last line of the body. Using async with and a compatible context manager allows for the event loop to schedule some other asynchronous code during that blocking IO period.
We will cover using and creating context managers in more detail over the next two chapters, but both are equivalent to try/finally constructions, but standard context managers use synchronous code in their enter and exit methods, whereas async context managers use asynchronous code.
Async locking primitives
Although asynchronous code is less vulnerable to concurrency safety issues than threads are, it is still possible to write asynchronous code that has concurrency bugs. The switching model being based on awaiting a result rather than threads being interrupted prevents most accidental bugs, but it’s no guarantee of correctness.
Example of an unsafe asynchronous program
Although this program should print 100, it may print any number as low as 1, depending on the decisions the event loop makes about scheduling tasks. To prevent this, we need to either move the await offset() call to not be part of the += construction or lock the num variable.
Example of asynchronous locking
Perhaps the biggest difference between threaded and async versions of synchronization primitives is that async primitives cannot be defined at the global scope. More accurately, they can only be instantiated from within a running coroutine as they must register themselves with the current event loop.
Working with synchronous libraries
The run_in_executor(...) function works by switching out the problem to one that is easily made asynchronous. Instead of trying to turn arbitrary Python functions from synchronous into asynchronous, finding the right places to yield control back to the event loop, getting woken up at the correct time, and so on, it uses a thread (or a process) to execute the code. Threads and processes are inherently suitable to asynchronous control by virtue of being an operating system construct. This reduces the scope of what needs to be made compatible with the asyncio system to starting a thread and waiting for it to be complete.
Making our code asynchronous
The first step in making our code work in an asynchronous context is to pick a function to act as the first in the chain of asynchronous functions. We want to keep the synchronous and asynchronous code separate, so we need to pick something that’s high enough in the call stack that all things that need to be asynchronous are (perhaps indirectly) called by this function.
In our code, the get_data_points(...) function is the only one that we want to run in an asynchronous context. It is called by add_data_from_sensors(...), which is itself called by standalone(...), which is called by collect_sensor_data(...) in turn. Any of these four functions can be the argument to asyncio.run(...).
The collect_sensor_data(...) function is the click entrypoint, so it cannot be an asynchronous function. The get_data_points(...) function needs to be called multiple times, so it is a better fit for a coroutine than the main entrypoint into the asynchronous flow. This leaves standalone(...) and add_data_from_sensors(...).
We now need to change our implementations of the lower-level functions to not call any blocking synchronous code. Currently, we are making our HTTP calls using the requests library, which is a blocking, synchronous library.
As an alternative, we’ll switch to the aiohttp module to make our HTTP requests. Aiohttp is a natively asynchronous HTTP library that supports both client and server applications. The interface is not as refined as that of requests, but it is quite usable.
As the name suggests, a ClientSession represents the idea of a session with a shared cookie state and HTTP header configuration. Within this, requests are made with asynchronous context managers like get. The result of the context manager is an object which has methods that can be awaited to retrieve the contents of the response.
The preceding construction, which is admittedly much more verbose than the equivalent using requests, allows for many places where the execution flow could be yielded to work around blocking IO. The obvious one is the await line, which relinquishes control while waiting for the response to be retrieved and parsed as JSON. Less obvious is the entry and exit of the http.get(...) context manager, which can set up socket connections, allowing things like DNS resolution not to block execution. It’s also possible for the execution flow to be yielded when entering and exiting a ClientSession.
All this is to say that while the preceding construction is more verbose than the same code using requests, it does allow for transparently setting up and tearing down of shared resources relating to the HTTP session and is doing so in a way that does not significantly slow the process.
In this function, we define two variables, a list of awaitables that each return a list of DataPoint objects, as well as a list of DataPoint objects that we fill as we process the awaitables. Then, we set up the ClientSession and iterate over the servers, adding an invocation of get_data_points(...) for each server. At this stage, these are coroutines as they are not scheduled as a task. We could await them in turn, but this would have the effect of making each request happen sequentially. Instead, we use asyncio.gather(...) to schedule them as tasks and allow us to iterate over the results, which are each a list of DataPoint objects.
Next, we need to add the data to the database. We’re using SQLAlchemy here, which is a synchronous library. For production-quality code, we’d need to ensure that there is no chance of blocking here. The following implementation does not guarantee that the session.add(...) method can block due to the data being synchronized with the database session.
We will look at methods for dealing with database integration in a parallel execution context in the next chapter, but this is good enough for a prototype.
Finally, we need to do the actual work of getting the data. The method is greatly different to the synchronous version, except that it also requires the ClientSession to be passed in, and some minor changes must be made to accommodate the difference in HTTP request API.
This method makes many different choices when compared to a multithreaded or a multiprocess model. A multiprocess model allows for true concurrent processing, and a multithreaded approach can achieve some very minor performance gains thanks to the less restrictive guarantees about switching, but asynchronous code has a much more natural interface, in my opinion.
The key disadvantage of the asyncio approach is that the advantages can only be truly realized with asynchronous libraries. Other libraries can still be used by combining asyncio and threaded approaches, which is made easy by the good integration between these two methods, but there is a significant refactoring requirement to converting existing code to an asynchronous approach and, equally, a significant learning curve in becoming accustomed to writing asynchronous code in the first place.
Comparison
There are implementations of all four approaches in the code accompanying this chapter, so it’s possible for us to run a simple benchmark to compare their speeds. Benchmarking a proposed optimization in this way is always difficult; it’s hard to get real numbers from anything but a real-world test, so the following should be taken with a pinch of salt.
These numbers were generated by extracting data from the same sensor multiple times in a single invocation. Aside from the other load on the machine timing these invocations, the numbers are unrealistic because they do not involve looking up connection information for many different targets and because the server returning the requested data is limited in the number of simultaneous requests that it can service.
As you can see from Figure 7-9, the threaded and asyncio approaches are almost indistinguishable in terms of time taken. The nonblocking IO method that we rejected due to its complexity is also comparable. A multiprocess approach is noticeably slower, but similar to the other three approaches. The standard, synchronous approach behaves similarly with only one or two sensors to collect data from, but the larger result sets quickly become pathological, taking an order of magnitude longer than the concurrent approaches.
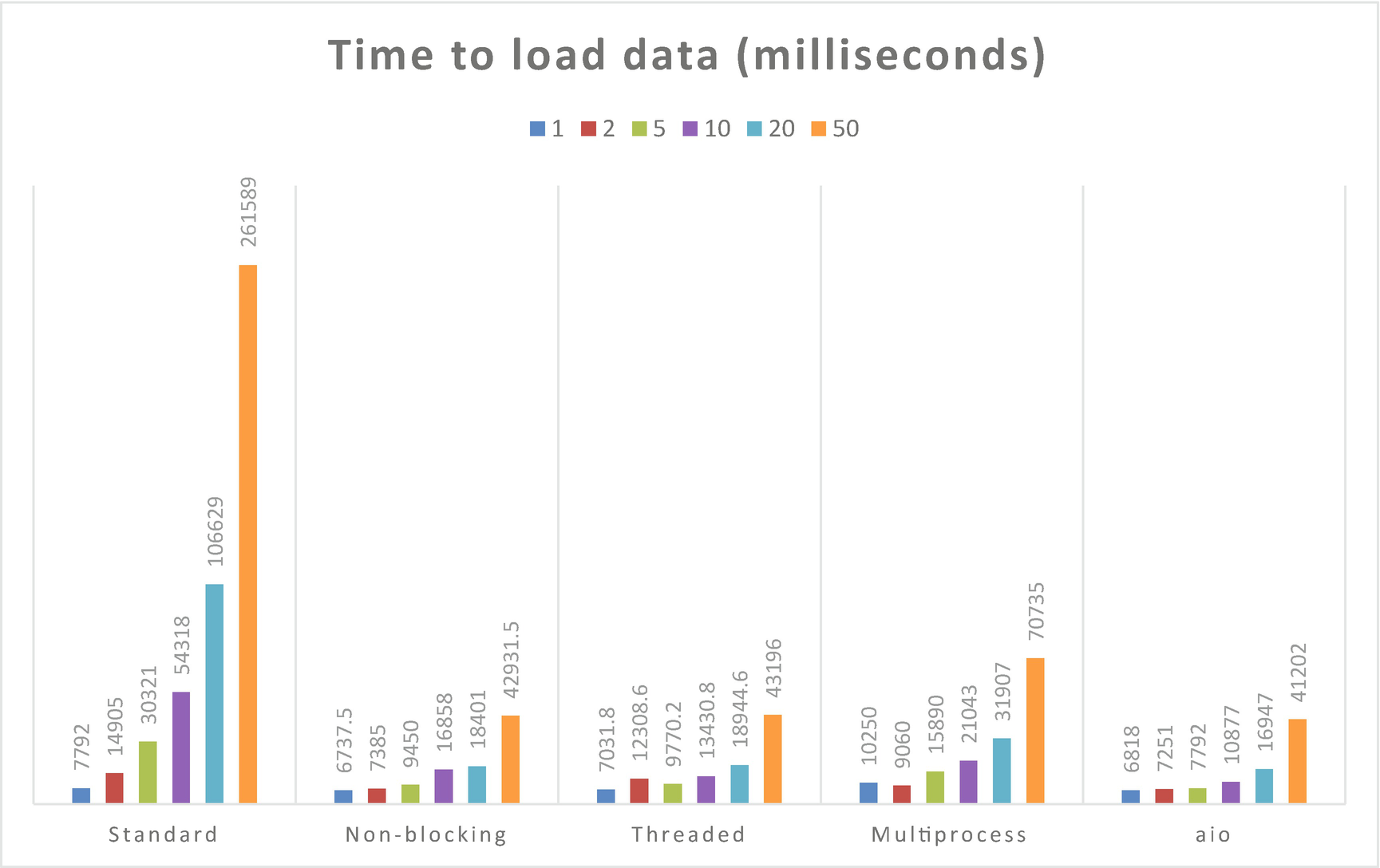
Time taken to load data from 1, 2, 5, 10, 20, or 50 HTTP APIs, using different parallelization methods
Making a choice
There are two pernicious falsehoods about asyncio circulating in the Python community at the time of writing. The first is that asyncio has "won" at concurrency. The second is that it’s bad and should not be used. It should come as no surprise that the truth lies somewhere in the middle. Asyncio is brilliant for network clients that are largely IO-bound but isn’t a panacea.
When deciding between the different approaches, the first question to ask yourself is if your code is spending most of its time waiting for IO or if it’s spending most of its time processing data. A task that waits for a short while and then does a lot of calculation is not a great fit for asyncio as it can parallelize the waiting but not the execution, leaving a backlog of CPU-bound tasks to perform. Equally, it’s not a natural fit for a thread pool, as the GIL prevents the various threads running truly in parallel. A multiprocess deployment has higher overheads but is able to take advantage of true parallelization in CPU-bound code.

Decision tree for parallelization methods in client/server applications
This is not a hard rule; there are too many exceptions to list, and you should consider the details of your application and test your assumptions, but in general, I prefer the robust and predictable behavior of preemptive multitasking13 for a server application.
Our sensor API endpoints are entirely standard Python, but are run through the waitress WSGI server. The WSGI server makes the concurrency decision for us, with waitress-serve instantiating a four-thread thread pool to handle inbound requests.
The collector process involves a large amount of waiting in every invocation and is entirely client side, so using asyncio to implement its concurrent behaviors is a good fit.
Summary
In this chapter, we’ve looked at the two most common types of parallelization, threading and asyncio, as well as other methods that are less widely used. Concurrency is a difficult topic, and we’ve not finished covering the things that you can achieve with asyncio, but we will be leaving threads behind at this point.
Asynchronous programming is a very powerful tool, one that all Python programmers should be aware of, but the trade-offs of threads and asyncio are very different, and generally speaking, only one will be useful in any given program.
If you need to write a program that relies on concurrency in Python, I strongly recommend experimenting with the different approaches to find which matches your problem best. I also would encourage you to make sure you understand the uses of all the synchronization primitives we’ve used in this chapter, as appropriate use of locks can make the difference between a program that’s slow and hard to understand and a program that’s fast and intuitively written.
Additional resources
The HTTP zine by Julia Evans gives a good explanation of the internals of the HTTP protocol and the differences between versions: https://wizardzines.com/zines/http/.
Greenlets are a precursor to native coroutines in Python, which may be of use to people who need to use very old versions of Python: https://greenlet.readthedocs.io/en/latest/.
Similarly, https://github.com/stackless-dev/stackless/wiki covers Stackless Python, which is a variant of Python intended to offer better performance when running many small operations in parallel. Greenlets are derived from the stackless project.
Just as ThreadPools are backed by threads, ProcessPools are backed by processes. Information on Python’s lower-level process management functionality is at https://docs.python.org/3/library/multiprocessing.html.
The slides for David Beazley’s excellent presentation “Understanding the GIL” are available at www.dabeaz.com/GIL/. Although some minor details have changed in the ten years since it was written (such as the concept of “ticks”), the overall description is still very accurate and worth a read.
Information on the PyPy implementation of Python can be found at www.pypy.org/.