
Chapter 22
Live Game Development
Since the first edition of this book was written, the mobile game market has exploded in size. This market brings many challenges to the traditional model of game development, which aims for a single major release. It also brings significant advantages to studios that have an Agile mindset.
On the last AAA console game I worked on, we were weeks away from alpha, after years of development, when we had a visit from our publisher’s CEO. This CEO was very excited about another game he had recently played, which featured using an AC-130 gunship against enemy artificial intelligence (AI) players. AC-130 gunships are large military cargo planes that have had large-caliber machine guns and cannons built in. They are very impressive and a fun feature to add to games, where appropriate.
The CEO was determined to have us put an AC-130 in our game as well. We argued that our third person action-adventure game didn’t have a place in the story for an AC-130 to be useful because most of the gameplay took place in cities or inside buildings. He insisted that our players would love it. We had little data to support our side of the argument, and the CEO had all the power. So we put an AC-130 into the game. The result? Players never cared for it, and many reviewers thought the addition was stupid.
This highlights one thing I like about live games: You can ask the players what they like. You never have to be so speculative as you do with AAA games, but many live game developers still plan and execute like AAA games developers.
The Solutions in This Chapter
This chapter explores the application of Agile and Lean practices to live games and the teams that support them. It discusses how feedback loops are used to pace development and optimize the delivery of value to the player and how metrics are used to drive the game going forward. The main solutions are to
Speed up the feature pipeline; that is, how to get feature ideas into players’ hands before the competition
Rapidly respond to issues that disrupt the player experience and causes the game to lose players
Use metrics to grow gameplay instead of making big gambles
Games As a Service
Over the past decade, more and more games have shifted to a live model of development, where significant features are continually added to a game already in players’ hands. Mobile games are the most exceptional example, exploring freemium and other various models that monetize the game beyond (or instead of) the initial game purchase.
Subscription models have been around for decades, charging players a fixed price every month to continue to play and build their online character or world. MMOs such as World of Warcraft are examples of games that were very successful in this space.
Lately, even AAA console games have been shifting to this model, often referred to as Games as a Service (GAAS). This approach is especially useful to sports games that, because of their fixed ship dates, can ship a game with the necessary roster and rule changes for the start of the season, but also offer features throughout the rest of the year that improve the player experience.
GAAS will continue to grow with cloud gaming, microtransactions, and season passes. This opens the door for further agility in game development.
“Are You Two Crazy?”
During a conference around 2006, I was approached by two young men who had a bunch of questions about Agile game development. They had started their studio and were building an MMO.
An MMO is probably the most challenging game to build. The complexity of the technology alone can number into millions of lines of code, more than even the most advanced fighter jet. It is a very risky game to take on, especially for a new studio.
But what they said next went beyond that challenge: They told me they were going to give the game away and rely on microtransactions. I wished them luck, and privately hoped they wouldn’t suffer too much with their crazy idea.
The two of them, Marc Merrill and Brandon Beck, the founders of Riot Games, went on to release League of Legends a few years later, which went on to become one of the most successful MMOs.
Why Agility for Live Games?
Live games and markets have created more opportunities for game developers, but have also introduced challenges:
More competition: App stores now offer more than a million titles. Compare this to a decade ago when a console or PC gamer had only a few hundred titles to choose from.
Increased pressure to respond: There are many examples of successful titles being edged out by similar games with faster development cycles.
Slow to grow, fast to shrink: It takes time to build active player communities, and one broken or ill-conceived build can drive many of them into the arms of competitors.
Agile practices offer a response to these challenges by increasing response time to player metrics and focusing the team on deploying rock-solid quality.
DevOps and Lean Startup
Readers familiar with DevOps and Lean Startup will recognize some of the approaches in this chapter. Both DevOps and Lean Startup have emerged from Agile and Lean practices over the past decade to address the challenges of live product support. If you are not familiar with these approaches, I highly recommend reading the Dev Ops Handbook (Kim, et al., 2016) and The Lean Startup (Ries, 2011) for more detail on specific practices as well as reviewing the practices presented in Chapter 11, “Faster Iterations,” and Chapter 12, “Agile Technology.”
Feedback Loops
A feedback loop is part of a system where an output is fed back into the input of the system, which further influences the output. Feedback loops are important not only for gameplay mechanics, but also for the development of games. Using player reaction to a game, teams can shift their focus toward adding features that players prefer.
For AAA games that are many months away from their first deployment, there is no feedback loop with players. The reaction from stakeholders, who represent the potential player, after every Sprint is still a guess of what will succeed in the market, such as our ill-fated AC-130. Traditionally, AAA games have a single, major feedback with players when they ship.
Live games have a continuous feedback loop, which is a major advantage. They can deploy a minimally viable game at lower cost and, based on player response, deploy features that have the highest return on investment.
Live Games and Fighter Aircraft
Early in my career, working on fighter aircraft, I learned about John Boyd. A former fighter pilot and military strategist, Boyd was instrumental in the design of the highly successful F-16 aircraft. Unlike other heavier fighters that were stuffed with too many requirements, these aircraft were far lighter and built around a philosophy called the “OODA loop.”
The OODA loop is a decision cycle used to defeat enemy aircraft in a dogfight. OODA stands for
Observation: The collection of data
Orientation: The analysis and synthesis of that data to form a current perspective
Decision: Determining a course of action based on the current perspective
Action: The playing-out of decisions
The focus of the OODA loop was to get “inside the decision cycle” of the enemy to gain an advantage. The superiority and low cost of the F-16 proved this philosophy.
Boyd later applied this philosophy to business, and it applies directly to live game development. In many cases we’ve seen that the approach of slowly deploying a complete feature set isn’t as critical as quickly deploying individual features that the market desires. As a result, small upstarts can upstage more established teams whose process overhead drags them down.
Live Game Feedback Loops
Rather than killing enemy pilots, the measurable goal for live game development is to grow the number of players who are enjoying the game as expressed through metrics, often referred to as Key Performance Indicators (KPIs). To execute and measure these metrics, live games implement a short feedback loop.
The most straightforward live game feedback loop is shown in Figure 22.1.

Figure 22.1 A live game feedback loop
This chapter describes each step of this feedback loop:
Part One: Plan—What players might want from your game and how you would measure their response to what you give them
Part Two: Develop—The next set of features at the highest speed and quality
Part Three: Deploy and Support—The game
Part Four: Measure and Learn—How the players respond to the game and what that means to the next set of deployments
How Fast Should Our Feedback Loop Be?
Studios often struggle with how frequently they can and should release updates to a live game.
I once visited a studio that made web-based games. It released updates once or twice a week, which were mostly for A/B testing updates: minimal changes that the studio could measure and use to make the next round of updates and tests. The challenge it faced was that the updates rarely had significant improvements. As a result, the games suffered a slow decline in daily active users.
Later on, after the studio transited to mobile, the opposite occurred. It released only once every three to six months (not including patches to fix bugs and vulnerabilities). As a result, the games were now suffering because
The studio couldn’t respond to the competition quickly enough.
The players were impatient waiting for improvements.
The prominent new features that were eventually rolled out weren’t always what the players wanted.
U-Curves Help You Decide
I am a fan of Donald Reinertsen’s writings (Reinertsen, 2009). He puts Lean and Agile practices under an analytical lens that helps visualize the big picture and examine measurable trade-offs.
One of the tools he frequently uses is the U-curve. Figure 22.2 demonstrates the two costs (transaction cost and holding costs) measured over a batch size (the size of new features released at once), which produces the total cost.

Figure 22.2 Cost versus batch size U-curve
The goal of the tool is to help you find the ideal batch size where the total cost is at a minimum.
U-curves can be applied anywhere! My favorite example refers to the question of how often you should wash your dishes. There is a transaction cost of washing dishes that is independent of the number of dishes you wash. For instance, you could fill the sink, pour detergent in and wash and dry a single dish every time you use it, but that’s a lot of effort for each dish. Alternatively, you could let them pile up for a week or two, but the holding cost (running out of plates and having a messy kitchen) would be too much. Most of us find a happy medium, perhaps once a day, where we batch up the daily dishes and wash them in one go. (Ironically, most studios I visit have a kitchen with a sign reminding people to increase the frequency of washing their dishes (that is, reduce the batch size).
Back to an example of live games, U-curves are applied in the following way:
Batch size: The number of new features and content in the game
Transaction cost: The amount of cost, proportional to the batch size of testing, fixing, and submitting a build that is successfully released, including the time for first party (for example, app store) approval
Holding cost: The cost to your game in the market from holding back the features ready for releases (impatient players and the competition beating you to market)
When the studio mentioned earlier was releasing updates once or twice a week, most of the cost of development was invested in getting a build prepared for deployment. For example, a test might involve changing the behavior of some UI elements in the game. The actual change took an hour, but submitting the changes for review/approval, creating the build, doing regression testing, deploying the build, and addressing any deployment problems took days. That’s a 90 percent overhead! The fixed cost of deploying so frequently also took time away from implementing the features players cared about. This is the transaction cost. Transaction costs shrink proportionally as the deployment frequency drops.
For the holding cost, delaying the delivery of larger features will increase the chance that players will shift their attention to another game, which is especially impactful when you have a free-to-play game that derives its income from the average revenue per daily active users (ARPDAU). Holding cost can also come from technical debt that accumulates over time. If a team is allowing debt to grow (for example, by dumping bugs into a database instead of resolving them), then the cost of fixing those before a large deployment increases.
So how often should you release a new version of the game? Reinertsen describes how this is determined by adding the transaction and holding costs. Because these costs move in opposite directions, then there results a minimum (the low point of the ‘U’ in Figure 22.2) in the total costs, which defines the ideal “batch size” or amount of new scope that is released. Because the rate of new scope is relatively constant, this can be fed into a predicted time frame, like every two to three Sprints.
Holding cost is fixed, so instead we focus on reducing the transaction cost by speeding up the planning-development-deployment pipeline and by reducing the batch size of new features.
Reducing Transaction Costs
Many of the development and test automation tools we’ll discuss are like adding a dishwasher to the dishwashing analogy: It reduces the transaction costs and allows us to speed up the feedback loop.
Measuring the Feedback Loop
As Peter Drucker said, “You can’t manage what you can’t measure.”
There are many things we can measure with live games. Most of them are useless and lead to the Cobra effect as described in Chapter 9, “Agile Release Planning.” This is often exhibited with games that focus primarily on monetization.
The primary metric for a live game feedback loop is the lead time between when an idea is proposed and when we’ve learned the player’s reaction to it. This is more important than just the internal metrics of how fast the development team is or the amount of scope it can deploy per month. If it takes many months to learn how players are reacting to the new scope or we aren’t measuring the entire loop, then we don’t learn as much as we could.
Part One: Plan
Many live game teams struggle to plan further out than a few deployments. Part of the problem is with the gap between KPI-driven short-term focus and the goals for the longer term. The business side still needs long-term vision for where the game is headed (portfolio, Backlog, product canvas, and so on), but the connection between long-term vision and developmental goals for live games is often poorly defined with long-term goals for player retention and growth merely being guesses.
Figure 22.3 shows the flow of connecting the vision and goals of the game with the model we have of the player to identify the next steps for development and how we are going to test the results of those steps.
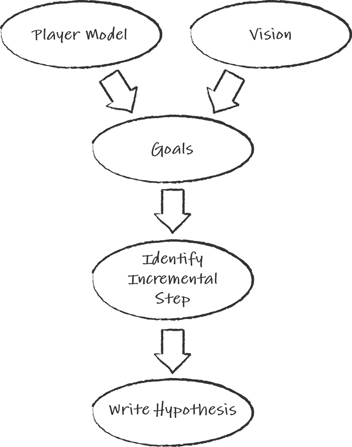
Figure 22.3 Flow of planning
Have a Vision
A game needs a strong vision. Without a vision, there is no focus. A vision should define the major pillars of the game and a backlog of feature goals. As with AAA games, it’s easy to define too much detail here, which is speculative, which is even less necessary with live games.
An example vision would be to grow the social aspect of a single player puzzle game.
Model the Players
Who plays your game? What do they want to do with it? What frustrates them? What problems are they trying to solve? What is the competition doing or not doing? What are your strengths?
These are typical questions that live games allow us to measure and experiment with. The goal of planning is not only to answer such questions but to learn more about our players and what the market wants so that we can grow that community of players.
Our model might reveal that players want to demonstrate their skill against other players rather than sharing techniques for how to improve solving puzzles.
Lean Startup, UX, and Design Thinking
The feedback loop we’re using reflects Lean startup, UX, and design thinking, which focus on the users’ needs and experience, asking questions such as “Who are our users?” and “Why would they use our software?” and creates a fast feedback loop of experimentation to provide answers to those questions.
As with DevOps, exploring all of these practices are outside the scope of the book. The books in the later “Additional Reading” section are good resources for further information.
Establish the Goals
Goals could be epic stories, which would take multiple iterations to fully deploy. A goal example, given the vision and model of the player, would be tournament gameplay, where players could complete in head-to-head competitions over a weekend with the victory in each category winning a cash prize.
Identify an Incremental Step
Instead of designing the entire tournament with ladders and player ranking systems, start with an epic story and split out some initial incremental steps to prove or disprove the assumptions of each goal.
For the tournament goal example, we want to identify a first step that will provide the most information. In this case, the tournament goal will succeed or fail based on the core head-to-head gameplay. If players don’t care for that, then there is no reason to waste any more time on that goal, so that would be the step we want to test.
Develop the Hypothesis
As in scientific research, a hypothesis is a guess that we have which we then use to design experiments around to either prove or disprove it. Ideally, these experiments should be able to produce answers quickly so that we can build on success or learn from failure and move on to the next hypothesis.
Adding anticipated KPIs to a PBI can better connect the two. A typical format would be to add the hypothesis to a user story in the form:
We believe that <doing something> will <result in this measurable change> <within a constraint>.
How are we going to measure whether players like the new mechanic? Measuring how many players try the mechanic versus how many keep playing it after trying it is an excellent place to start.
Note
Keep in mind that raw numbers might not tell the full story. If the mechanic is hard to find or the interface for playing it is confusing, then the retention numbers might be too low. Player interviews and subjective analysis can be as useful as data in getting answers.
Depending on how “experimental” the mechanic is, consider a canary deployment (see the later section, “Canary Deployments”) to a limited audience. Throwing many experiments at players may confuse them over time.
Here is an example of a hypothesis:
“We believe that head-to-head play will be used by 25 percent of our daily active users within a week of its deployment and 50 percent of those players will play multiple times.”
Constraints are usually time-based and short (one to three weeks) to allow for sufficient iteration if we want to try a few iterations.
This hypothesis would be fed into the development pipeline (see “Part Two: Develop”).
Refining the Backlog of Goals
A Product Backlog for a game that hasn’t yet deployed has a lot of flexibility. We can keep adding features to it and not worry too much about how big it’s getting (within reason).
For live games, constraining the size of the Product Backlog is essential. Its size impacts how long feature ideas linger and potentially miss their market window. Therefore, it’s more important for the Product Owner to do two things:
Say “no” more often
Retire PBIs from the Product Backlog that are no longer relevant or valuable
These are typically done during Backlog Refinement sessions that should occur every few weeks.
Part Two: Develop
For live games, simply improving development speed isn’t enough. To better compete, live games have to be improved along the entire pipeline, from the point a feature idea is generated to the time the player can actually use that feature in game. Figure 22.4 shows the feedback loop for mapping, measuring, and improving the development flow.

Figure 22.4 Development feedback loop
Map and Measure the Entire Pipeline
The first step in improving a live game development pipeline is to visualize and measure the value stream. A value stream is similar to the production stream discussed in Chapter 10, “Video Game Project Management.” Figure 22.5 shows an example.

Figure 22.5 Simple feature pipeline value stream
A value stream shows all the major stages of development for features, including the time between stages of work (that is, “waiting”), when a specification, code, or assets are waiting for the next stage.
Identify Ways to Improve the Pipeline
The total time to deploy a new feature, from idea to delivery, is commonly referred to as lead time. Lead time includes all the time between start and finish, including the time the feature spends simply sitting around waiting to be released. Lead time represents just how responsive we can be to our players and market.
Lead Time Versus Cycle Time
In contrast to lead time, cycle time is the time between when work actually begins on a feature and when it is deployed (see Figure 22.6). Lead time also includes the time between when a feature is identified and when it is deployed. As a result, lead time is impacted by the length of features in a backlog that are waiting around.
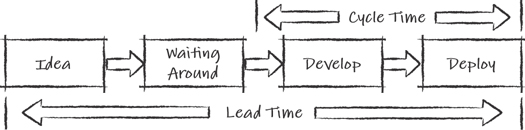
Figure 22.6 Lead versus cycle time
It doesn’t matter if we can develop and deploy a game in two weeks if the idea has been languishing in a list for over a year. That means that we’ve given the competition a year to come up with the same idea and beat us to market.
To reduce the lead time, we can do several things:
Reduce the batch size of features through the pipeline. Instead of shipping an update with 10 features, deploy each feature as it’s ready.
Reduce the amount of time features are waiting around. This is done by pruning the list from time to time and prioritizing the features that players want (see “Refining the Backlog” later in this chapter).
Improve development and testing practices. Both this chapter and the methods described in Part IV, “Agile Disciplines,” describe how to reduce development time and measure how the players respond to them to build up to epic features, as described in the following case study.
Case Study: Speeding Up a Feature Pipeline
A mobile studio I worked with had a live single-player puzzle game that had been very successful. Money from in-game purchases had been pouring in for years, but the competition had been heating up, and revenues were slowly falling. The major problem was that it was taking six months to implement significant new features. Although the team was using Scrum to implement features, it needed to eliminate a lot of waste outside of Sprints.
The first thing to do was to map the value stream for a new feature from concept to player delivery. Figure 22.7 shows the results.
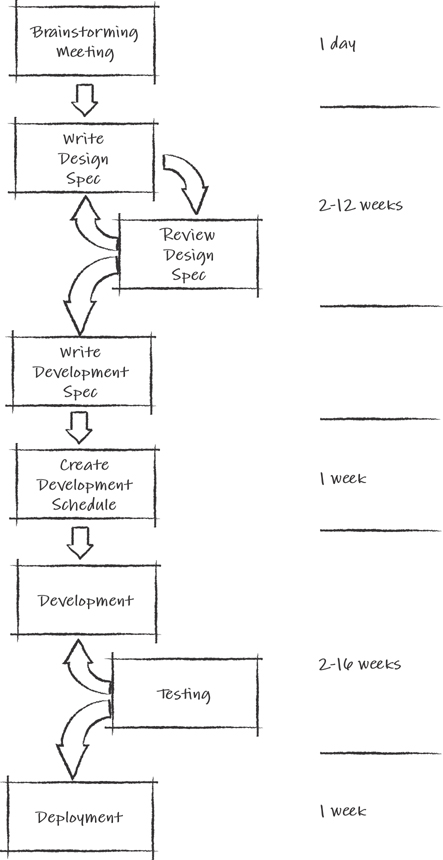
Figure 22.7 Feature pipeline before
This exposed the following:
New feature ideas were enormous; they were captured in 20–30 page documents.
Because features were so significant, they went through numerous revisions and reviews that took one to two months.
Shooting down a revision was easier than approving it due to its risk and cost.
Gathering all the principles for a review (at best, twice a month) took time.
The Sprints were not addressing debt as well as they could have, which resulted in a lot of rework in subsequent Sprints after a quality assurance (QA) team found problems trying to validate builds for submission.
To address this, we implemented two main changes, one hard, one harder:
The hard change: Improving the Definition of Done with the Scrum teams to address debt, which required some automated testing, QA joining the teams, and improved practices such as test-driven development. Implementing these changes was difficult because it asked developers to change how they worked and required fundamental reorganization at the team level.
The harder change: Weaning management off of their need to make big gambles with major features, which led to the big design documents. The new approach was to create smaller experiments that could be tested with players and could inform product ownership.
This change in design culture took a while to optimize, but seeing the metrics of the flow proved motivational for the leads, and they embraced being part of the solution.
Ultimately, the business metrics saw a benefit from this new approach. The throughput of new features (albeit smaller, incremental features) increased from one every three to six months to one every four to six weeks (see Figure 22.8). As a result, revenues started growing again.

Figure 22.8 Feature pipeline after
Reduce the Batch Size
The larger the plan, the more massive the gamble you take on its success. When the risk is large, stakeholders very often get nervous and want assurances that it will pay off. These assurances are usually offered in the form of large documents or very detailed task plans, which seem assuring, but are just wild guesses that diminish exploration.
The impact on the lead time is tremendous due to three factors:
Larger designs take longer to write.
Stakeholders are more likely to reject a part of the plan, which leads to more iteration.
Stakeholders can also rubber-stamp a larger design without fully comprehending the outcome, which can lead to late rejections and rework.
As shown in the case study, smaller features developed for live games avoid these problems by
Being faster to describe
Being easy to comprehend and approve or provide fast feedback
Allowing early deployment and player feedback and measurement
QA for Live Games
Live games with quality issues can die very quickly. Although building up daily active user counts might take months, losing them can take days if a problem-filled build is deployed.
This highlights the need to ensure that quality is foremost in everyone’s mind throughout the development pipeline. Due to the risks, live game development tends to demand even greater investments in quality practices and test automation than more traditional game models.
QA Engineering at IMVU
“Most features go through some level of manual testing. Minimally, the engineer who pushes code verifies the functionality in production. In many cases, features get dedicated testing time from a QA engineer. By the time a feature is ready for QA testing, our QA engineers can focus on using the feature much like a customer would. They expose bugs by doing complex, multi-dimensional manual testing based on more complicated use cases. People are good at this work, which is more difficult to cover with automated testing.
“Our teams are always reviewing QA priorities to see which features get attention. In some cases, there is so much important QA work needed that we organize group tests, either with the team or the entire company, to quickly find and fix issues. Our software engineers are also becoming skilled in carrying out manual testing and following our QA test plans. When this happens, it is more akin to classic Scrum, where all tasks (including QA tasks) are shared among the team.
“From a process standpoint, we integrate QA engineers into our product design process as early as possible. They provide a unique and valuable point of view for developing customer use cases and exposing potential issues before engineering begins work. The collaboration between our product owners and QA engineers adds tremendous value.”
—James Birchler, Engineering Director, IMVU
Part Three: Deploy and Support
I’m slightly embarrassed to admit that the mobile game I play the most is Solitaire. Solitaire is a great game to play when you are waiting to board an airplane or when trying to fall asleep in a hotel. I do both of those things quite often.
The first mobile Solitaire game I played had great graphics and some useful features. It also did a few things that annoyed me such as having slow animations when “undoing” moves and not having a feature that quickly completed the hand after all cards were exposed (a Solitaire hand is “solved” once all cards are face up).
Then one day, after Apple upgraded iOS, the game began crashing on startup. This kept up for a few days. Because I was traveling that week, I was having some withdrawal symptoms. I ended up trying a few competitive Solitaire games and found one that not only worked with the latest iOS, but also had fast undo animations and the autocomplete feature. I ended up buying that game and never going back.
By chance, I started working with the studio that made the Solitaire game that had all those crashes. It was a bit upset to hear that I had switched to their main competitor’s game. This act was being mirrored by many of its players, and it was losing market share.
It was an eye-opening experience that such a simple game could suffer from the problems that larger games could as well. The mobile game market can be very fickle. Crashes, exploits, or the emergence of a similar game: Doing something better can change your market overnight.
This section explores support teams and how live support can help address emergent issues quickly and avoid losing players.
Continuous Delivery
Chapter 12 discussed the benefits of continuous integration meant to reduce the number of team and feature branches into one development branch. The advantage of this is to shorten change merge cycles and reduce the number of problems that large merges create.
This is the same principle of reducing batch sizes in Lean thinking. Smaller batches of change mean that we can respond to problems more quickly and have a higher rate of iteration on improving practices.
This section extends the idea of continuous integration to continuous delivery. Continuous delivery is an approach of frequently creating a deployable build through automation, sometimes throughout the day.
Continuous Deployment
Continuous deployment is the actual delivery of new features to players through automation. Because most live games have to go through first-party approval such as a console or phone app store, continuous deployment is less applicable than continuous delivery for games.
Feature Toggles
Feature toggles are a technique for hiding, enabling, or disabling a feature during runtime, which is an alternative to code branching that allows a feature not ready for deployment to be turned off.
Feature toggles shouldn’t be overused or abused. Things to watch out for include the following:
Toggle debt: Having a lot of incomplete features toggled off.
Building large features before the player sees them toggled on: Releasing smaller features to the player that build up over time is a better practice.
Toggles can be hacked: The most famous feature toggle hack was the “Hot Coffee Mod” in Grand Theft Auto: San Andreas that players found and toggled on.1 This exposed an X-rated feature that was never meant to be shipped with the game, which led to a massive product recall and an initial rerating of the game.
1. https://www.theverge.com/2012/5/6/3001204/hot-coffee-game
Canary Deployments
Sometimes you want to deploy a version of the game to a much smaller audience to measure how they respond. A canary deployment is a way to do that. It can be used in conjunction with feature toggles to target specific sets of player and feature combinations. For example:
We only want players in Tasmania to fight the zombie wallabies.
We want to disable the red blood in Germany.
We want to try out the new tournament mode with our most active players.
“We Can’t Use Scrum Because of Valentine’s Day!”
One of the most unusual reasons I’ve heard for not adopting Agile practices was from a mobile game developer who claimed that Scrum only allowed deployments at the end of a Sprint.
The game in question would release specific features aimed at holidays and the next holiday on the calendar was Valentine’s Day.
There is nothing inherent in Scrum or iterative development in an Agile practice that prevents teams from deploying any time during a Sprint. It turns out that this team didn’t have any integration, test, or deployment automation and that it needed at least three weeks to harden and test a build to deploy manually.
Because its Sprint didn’t end precisely three weeks before Valentine’s Day, the team concluded that Scrum didn’t work for it. I suggested that the team have the build ready four weeks early when the previous Sprint ended or have a shorter Sprint and work on improving its tools, but it had made up its mind that the current set of practices, with all the manual overhead cost for deployment, shouldn’t be changed.
Live Support Tools
A live support team is a form of a support team, described in Chapter 21, “Scaling Agile Game Teams,” that focuses on addressing issues with a live game. Instead of a backlog of feature requests from development teams, a live support team handles problems that come up with a deployed game. Typical issues are
Fixing client or service crashes
Dealing with emerging exploits
Collecting live game metrics
Working with teams to improve deployment quality
Our first support team was focused on promoting practices throughout the studio to improve build stability. It became such an important part of their job that members renamed themselves the “Stability Team.” The team’s job wasn’t to fix the problems being caused by other teams, but to capture the patterns of failure and to promote practices that eliminated their repetition.
Tools were key to doing this work. One tool team members used was to have a crashing build send an email containing stack dumps and other debug data to an email address that was constantly monitored. Having a Stability Team member visit you within minutes of a build crashing to ask you what you were doing at the time was not unusual.
Another tool was used to measure, on a day-to-day basis, the average stability of builds. This would show the trend of build stability over time (see Figure 22.9).
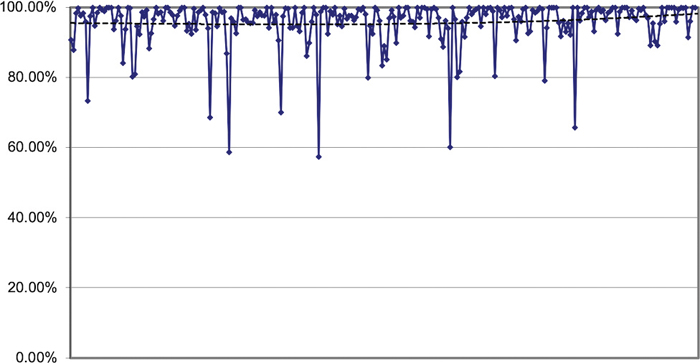
Figure 22.9 A stability trend chart example
Many tools are available that live support teams can use. The recommended books describe hundreds of them. This section lists a few that are more commonly used.
Emergency Swim Lanes
The last thing you want to tell a live MMO team you support is, “We’ll put ‘fix the server crash’ on the Backlog and deliver the fix two weeks later”!
Instead, a useful practice for addressing emergencies is to have an emergency swim lane (or emergency lane). When a request is in the emergency lane, it signals the team members just downstream to suspend their current work and focus on pulling the request further downstream. Figure 22.10 illustrates the emergency lane. In it, a crash bug has been placed in the lane by the Product Owner. This is the only person allowed to do that. This signals the developers to stop what they are doing and pull the request, called “Crash!” into the ready column by planning the work needed to address it. After it is done, they’ll pull it into the develop column. When it’s ready to be tested, the testers will pull it into the test column and verify the crash is resolved before deploying it.

Figure 22.10 An emergency swim lane
Other Types of Swim Lanes
Kanban teams have used a large variety of useful swim lane types, such as bug fixing. Agile Project Management with Kanban (Brechner, 2015) is a great resource for examples of these.
Recommended Reading
My favorite book on Kanban is Agile Project Management with Kanban (Brechner, 2015), written by the person who managed Xbox live services at Microsoft. This chapter cannot possibly cover the 160 pages of wisdom in this book. I highly recommend it.
Amplify Failure Signals
I recently visited a studio that had a live action-adventure multiplayer game that was doing well in the market. Halfway through the training session, a number of attendees started to race out of the room looking panicked. It turns out that players had suddenly discovered a way to hack administrative access for their accounts, which gave their characters unlimited powers in the game. By the time it was discovered a large percentage of the players had this hack, and the impact to the entire audience was significant. Removing the access didn’t take long, but the damage was done.
Finding ways to identify problems as early as possible can be more important than their fix. Instead of burying the signals for failures in a log file, finding ways to amplify them at the appropriate level (such as sending an email about a crash as mentioned earlier) can avoid catastrophic consequences.
Of course, you don’t want support teams bombarded with hundreds of signals a day, so a system for prioritization and triage is useful.
Incident Retrospectives
Whenever a launch failure occurs at NASA, the flight controller orders all the doors in launch control to be locked. Following this, all telemetry data is saved, and everyone is interviewed. The purpose of this is to capture the most accurate information possible to help the failure investigation find the root cause and, ultimately, some measures to prevent its recurrence in future missions.
Similarly, when a crisis such as the Solitaire crash occurs, there should be an immediate discussion on the causes and practices to prevent it from happening in the future. This is where an incident retrospective comes in.
An incident retrospective is a Retrospective held immediately after a problem is fixed. The steps taken in the retrospective are
Construct a timeline of the problem and gather the contributing details leading up to it.
Identify root causes and new practices to avoid them in the future.
Identify signals for future failures and ways they can be amplified for the earliest possible detection.
These meetings need to be open and blameless as possible.2 When blame is assigned, communication gets hampered, and facts are hidden.3
2. https://codeascraft.com/2012/05/22/blameless-postmortems/
3. The deaths of the astronauts on both the Challenger and Columbia were attributed to cultural and communication issues at NASA. None of the root causes of the accidents were unknown.
Blue-Green Deployment
Blue-Green Deployment4 is a practice of having multiple instances of a deployed version running in parallel. The production environment can fail over to the “last good version” when a problem occurs.
4. https://martinfowler.com/bliki/BlueGreenDeployment.html
For live apps that must be approved by a first party (for example, App Store), this switchover is not immediate, but having a known good version of a client app that is ready to go can save time when addressing a major incident.
Chaos Engineering
After Netflix moved its streaming services to Amazon Web Services, it created a tool called the Chaos Monkey to test system stability by triggering failures within Netflix’s architecture. This tool identified many shortcomings in the architecture before its customers did, which led to significant improvements.
Live app developers have expanded on this idea, which has led to the discipline of chaos engineering, which is useful for live games as well.
Chaos engineering can be used by games to discover how they react to
High latency
Loss of connectivity
App crashes
App server downtime
All of these issues and others can be tested before your customers encounter them.
Measuring Incidence Response Time
The most critical metric for live support teams is the time it takes between an incident being reported to when it is addressed in the live game. This time, called the Incidence Response Time, should improve as the team introduces better practices and tools.
Because there are separate types of incidents classified by their urgency, live support teams will often have a few response times to track.
Nothing is New
In the late eighties, I used to play an online air combat game called Air Warrior. This game allowed more than 100 players from around the world to dog-fight in World War II planes and locations.
Kesmai, the game’s developers, were kept on their toes fixing exploits we pilots were always discovering. One time, we discovered that by dropping dozens of AI paratroopers from high altitude bombers over their territory, we could overwhelm the enemy’s radar and defeat them.
Part Four: Measure and Learn
After the game is deployed with the new feature, we gather the data identified with the hypothesis. In addition to the subjective metrics, we can gather other data as well.
Measure Results
A wide range of approaches exist for evaluating player engagement with features implemented in the game. Some games use a complex statistical analysis,5 whereas others use a less formal subjective approach, communicating with players directly using forums and other social media channels. Some use a combination of both. Under certain circumstances each approach can work.
Do Retrospective Actuals and Update Your Vision
After reaching the constraint, hold a Retrospective to review the collected data and discuss the next steps. Include the team and stakeholders.
Remember the lessons from Nintendo and Atari from decades ago, described in Chapter 1. Focus on finding the fun first. If a mechanic fails early, it’s still a win. You’ve avoided the cost of developing a major feature that would have failed!
Aiming for Failure
I worked with a team that was trying to create an algorithm to solve a tricky augmented reality device problem. There were dozens of potential approaches to use, and the team had spent months trying one approach at a time before giving up after spending one or two months trying to make each work.
A Retrospective revealed that although proving an approach would work took a long time, proving it wouldn’t work was far quicker. As a result, the team shifted its efforts to eliminate as many of the potential approaches as possible and quickly narrowed them down to a remaining few that eventually worked for its device.
What Good Looks Like
In 2012, Supercell released Hay Day, a farm simulation game, on iOS. By releasing a minimally viable game to mobile, it was able to beat the existing market leader to mobile by almost two years. Its strategy of subsequently growing the game’s features based on player feedback resulted in Hay Day becoming the fourth-highest game in revenue generated in 2013.6
6. https://qz.com/172349/why-free-games-are-increasingly-the-most-profitable-apps/
Summary
Games as a Service is the future of the industry. Even large AAA franchises are transitioning to shipping minimal games that they can use to grow through live support over time.
This transition requires a rethinking of how we plan. Many live developers are stuck between executing on large speculative designs that are large gambles and short-term KPIs that lead to short term gains but long-term extinction.
It’s a fertile ground for exploring and innovating in the Agile space, and next decade will see even more new practices emerge than the last.
Additional Reading
Brechner, E., and J. Waletzky. 2015. Agile Project Management with Kanban. Redmond, WA: Microsoft Press.
Garrett, J. 2011. The elements of user experience. Berkeley, Calif.: New Riders.
Gothelf, Jeff, and Josh Seiden. 2016. Lean UX: Designing Great Products with Agile. O’Reilly.
Ideo Tools. https://www.ideo.com/tools.
Keith, C., and G. Shonkwiler. 2018. Gear Up!: 100+ ways to grow your studio culture, Second Edition.
Kim, A.J. 2018. Game thinking: innovate smarter & drive deep engagement with design techniques from hit games. Burlingame, CA: Gamethinking.io.
Kim, G., P. Debois, J. Willis, J. Humble, and J. Allspaw. 2016. The DevOps handbook: how to create world-class agility, reliability, and security in technology organizations. Portland, OR: IT Revolution Press, LLC.
Reinertsen, Donald G. 2009. The Principles of Product Development Flow: Second Generation Lean Product Development. Celeritas.
Ries, Eric. 2011. The Lean Startup: How Today’s Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses, NY: Crown Publishing.