
![]()
Searching Data: Part 2
This chapter is an extension of the previous chapter. In the previous chapter, you learned about searching data. You saw various components that play an important role in the search process, the various types of queries and parsers supported by Solr, and the request parameters that can be provided to control the search behavior.
This chapter covers other important aspects of searching documents. Beyond the core capabilities, a search engine needs to offer other features that address practical use cases and user needs. Also, each domain has its own unique challenge. A web search engine should group results from the same web site. An e-commerce web site typically offers faceted navigation so that the user can easily browse through the catalog based on features of the products. Solr provides out-of-the-box solutions for such common problems.
Most important, textual similarity between documents is not always the best criteria for computing relevancy. A music discovery web site generally considers a popular and trending song as more relevant than other songs with a similar score. Solr provides the function query to compute scores on such numerical values. Solr allows you to combine all these factors—including text similarity, popularity, and rating—to deduce practical relevance ranking and tame real-world search problems.
This chapter describes Solr’s search features along with practical use cases and prerequisites, so that you can easily analyze whether a certain feature can solve your business problem and understand the challenges in implementing it in your project. As examples are the best way to learn, each section concludes with an example.
This chapter covers the following topics:
- Local parameters
- Result grouping
- Statistics
- Faceted search
- Reranking query
- Join query and block join
- Function query
- ExternalFileField
Local parameters, also called LocalParams, allow you to provide additional attributes in request parameters and customize their behavior. LocalParams are supported only by certain parameters, and their effects are local to that parameter. For example, you can change the QParser used by the q parameter, without changing it for other parameters such as fq. Remember, Solr allows only one LocalParam for each request parameter.
Syntax
To use a LocalParam, it should be added at the beginning of a parameter value. LocalParams should start with {! and end with } and all local parameters should be specified between them as a key-value pair separated by whitespace. The following is the syntax for using a LocalParam in a request parameter:
<query-parameter>={!<key1>=<value1> <key2>=<value2> .. <keyN>=<valueN>}<query>
Specifying the Query Parser
The name of the query parser to be used in the local parameter section can be specified in the type parameter. Solr also offers a short-form representation for it, by allowing you to specify only the value, and Solr assigns it the implicit name type. The following is the syntax:
{!type=<query-parser> <key1>=<value1> .. <keyN>=<valueN>}<query> // explicit
{!<query-parser> <key1>=<value1> .. <keyN>=<valueN>}<query> // implicit
Specifying the Query Inside the LocalParams Section
Instead of specifying the query after the closing brace }, you can also specify it in the LocalParam by using the v key.
<query-paramter>={!<query-parser> <key1>=<value1> .. <keyN>=<valueN> v=<query>}
Using Parameter Dereferencing
Using parameter dereferencing, you can simplify the query further. You specify the query in the same request parameter, either following a closing curly brace or as a value of the key v, but parameter dereferencing allows you to read the query from another parameter. This approach provides a convenience to the client application, which can just provide the value for the additional parameter referenced by LocalParams and configure the LocalParams in solrconfig.xml. The syntax for parameter dereferencing is provided here:
<query-paramter>={!<query-parser> <key>=<value> v=$<param>}¶m=query
Example
In this section, you will see a few examples of LocalParams and their syntax.
The default operator for all the requests is OR, but you can change it to AND for the q parameter, using LocalParams as follows. When you use this syntax, the operator for the fq parameter still remains the same (OR):
$ curl http://localhost:8983/solr/music/select?
q={!q.op=AND}singer:(bob marley)&fq=genre:(reggae beat)
Say you want to find results for the keyword bob marley, ensuring that both the tokens must match and the parser used is Lucene. The following example shows various approaches to the same problem:
q={!type=lucene q.op=AND}bob marley // type parameter specifies the parser
q={!lucene q.op=AND}bob marley // shortened form for specifying the parser
q={!lucene q.op=AND v=’bob marley’} // v key for specifying query
q={!lucene q.op=AND v=$qq}&qq=bob marley // query dereferencing
Result Grouping
Result grouping is a feature that groups results based on a common value. In Solr, documents can be grouped on the values of a field or the results of a function query. For a query, result grouping returns the top N groups and top N documents in each group. This feature is also called field collapsing, as conceptually you collapse the results on the basis of a common value.
Suppose you are building a web search engine, and for a query all the top results are from the same web site. This would lead to a bad user experience, and you would be penalizing all other web sites for no reason. Field collapsing is useful for eliminating the duplicates and collapsing the results of each web site into a few entries. Even Google does this!
Result grouping is also frequently used by e-commerce web sites to address queries that find matches in different categories—for example, shirt can be of type formal, casual, or party wear. Result grouping allows you to return top results from each category.
Prerequisites
The following are the prerequisites for using result grouping:
- The field being grouped should be indexed and should support a function query if you are grouping on function queries.
- The field must be single-valued.
- The field shouldn’t be tokenized.
![]() Note As of now, result grouping on a function query doesn’t work in a distributed search.
Note As of now, result grouping on a function query doesn’t work in a distributed search.
Request Parameters
Solr provides additional request parameters for enabling result grouping and controlling its behavior. The supported parameters are specified in Table 7-1.
Table 7-1. Result Grouping Request Parameters
Parameter | Description |
|---|---|
group | By default, result grouping is disabled. It can be enabled by specifying group=true. |
group.field | Specifies the Solr field that shares the common property and on which the result should be grouped. The parameter can be specified multiple times. |
group.query | All documents matching the query are returned as a single group. The parameter can be specified multiple times. |
group.func | Specifies the function query, on the unique output of which the result will be grouped. It can be specified multiple times. This feature isn’t supported in distributed search. |
start | Specifies the initial offset of the groups. |
rows | Specifies the number of groups to return. By default, it returns 10 groups. |
group.offset | Specifies the initial offset of the documents in each group. |
group.limit | By default, only the top document of the group is returned. This parameter specifies the number of documents to return per group. |
sort | By default, the groups are sorted on score desc. You can change the group sorting order by using this parameter. |
group.sort | This parameter sorts the documents within each group. By default, this is also sorted on score desc. |
group.format | Result grouping supports two response formats: grouped and simple. By default, the results are grouped. The simple format provides a flattened result for easy parsing. In this feature, rows and start perform the task of group.limit and group.offset. |
group.ngroups | This parameter, if set to true, returns the count of matching groups. If for a query there are two matching groups, additional information will be added to the response as shown here: <int name="ngroups">2</int> In a distributed search, this parameter gives the correct count only if all the documents in the group exist in the same shard. |
group.facet | This Boolean parameter defaults to false. If enabled, grouped faceting is performed on the field specified in the facet.field parameter, on the basis of the first specified group. In a distributed environment, it gives a correct count only if all the documents in the group exist in the same shard. |
group.truncate | This Boolean parameter defaults to false. If enabled, the facet count is on the basis of the top document in each group. |
group.cache.percent | If the value is greater than 0, the result grouping enables a cache for the query during the second phase. The default value of 0 disables grouping the cache. As per the official Solr reference guide, caching improves performance with Boolean queries, wildcard queries, and fuzzy queries. For other types of queries, it can have a negative impact on performance. |
group.main | If true, the result of the first field grouping command is used as the main result list in the response, using group.format=simple. It’s mandatory to provide at least one grouping provision (the group.field or group.query or group.func parameter should be provided). If all these parameters are missing, Solr will report the error: <lst name="error"> <str name="msg"> Specify at least one field, function or query to group by. </str> <int name="code">400</int> </lst> |
Example
This section presents an example of each result grouping type: field grouping, query grouping, and function query grouping. The example assumes that you have a core named ecommerce that contains the respective fields satisfying all grouping prerequisites.
Statistics
Solr’s StatsComponent allows you to generate statistics on numeric, date, or string fields. Not all statistics are supported on the string and date fields.
Request Parameters
Before we discuss the methods, let’s have a look at the request parameters supported by the statistics components. The parameters are specified in Table 7-2.
Table 7-2. Statistics Request Parameters
Parameter | Description |
|---|---|
stats | You can enable StatsComponent by setting this Boolean parameter to true. |
stats.field | Specifies the field name on which statistics should be generated. This parameter can be specified multiple times to generate statistics on multiple fields. |
stats.facet | Specifies the facet on each unique value for which statistics will be generated. A better alternative to this parameter is using a stats.field with pivot faceting. You will learn about pivot faceting later in this chapter. |
stats.calcdistinct | When this Boolean parameter is set to true, all the distinct values in the field will be returned along with their counts. If the number of distinct values is high, this operation can be costly. By default, it is set to false. This request parameter is deprecated, and it’s advised to use countDistinct and distinctValues LocalParams. |
Supported Methods
StatsComponent supports a variety of statistical methods. All the methods, except percentiles, countDistinct, distinctValues and cardinality, are computed by default. You can enable the method by specifying it along with its value as a LocalParam. If you explicitly enable any of the statistics, other default statistics will be disabled. The percentiles method accepts numeric values such as 99.9, whereas all other methods are Boolean. Table 7-3 lists the primary statistics.
Table 7-3. Statistical Methods and Types Supported
LocalParam | Description | Supported Types |
|---|---|---|
min | Finds the minimum value in the input set | All |
max | Finds the maximum value in the input set | All |
sum | Computes the sum of all the values in the input set | Date/Number |
count | Counts the number of values in the input set | All |
missing | Counts the number of documents for which the value is missing | All |
mean | Computes the average of all the values in the input set | Data/Number |
stddev | Computes the standard deviation for the values in the input set | Data/Number |
sumOfSquares | Computes the output by squaring each value and then summing it up | Data/Number |
percentiles | Computes the percentile based on the cutoff specified | Number |
countDistinct | Returns the count of distinct values in the field or function in the document set. This computation can be expensive. | All |
distinctValues | Returns all the distinct values in the field or function in the document set. This computation can be expensive. | All |
cardinality | The countDistinct statistical method doesn’t scale well, as it needs to fit everything into memory. The cardinality method uses HyperLogLog, a probabilistic approach for counting distinct values, which estimates the count instead of returning the exact value. Refer to http://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf for details of the HyperLogLog algorithm. A floating point number between 0.0 and 1.0 can be provided as input value to specify the aggressiveness of the algorithm, where 0.0 indicates less aggressive and 1.0 indicates more aggressive. High aggressiveness provides a more accurate count but leads to higher memory consumption. Alternatively, a Boolean value true can be specified to indicate a floating point value of 0.3. | All |
LocalParams
Along with the preceding statistics, StatsComponent also supports the LocalParams in Table 7-4.
Table 7-4. StatsComponent LocalParams
Parameter | Description |
|---|---|
ex | Local parameter to exclude the filter |
key | Parameter to change the display name of a field |
tag | Parameter for tagging the statistics, so that it can be used with pivot faceting |
Example
This section presents examples for generating various types of statistics in Solr.
Faceting
Solr’s faceting feature is nothing less than a Swiss Army knife, one feature that does many things—especially since Solr 5.1, when the component was revamped, and in version 5.2, when more features were added. Faceting is a feature that classifies a search result into several categories, allowing the user to filter out unwanted results or drill down to a more specific result. This feature enables a better user experience, enabling users to easily navigate to a particular document.
Faceting is a kind of must-have feature in e-commerce web sites, especially ones with large product catalogs. The user makes a search request, and the response shows categories either on the left or right of the page—which is the facet. The items in each category are either clickable or come with a check box to filter the results. For a user query such as blue formal shirt, a web site may return hundreds or thousands of results. Faceting lets users easily navigate to products of their choice by filtering the results on preferred brand, favorite color, or fitting size, for example. Figure 7-1 shows an example of a faceted search at Amazon.com; the facets are shown in a rectangular box.
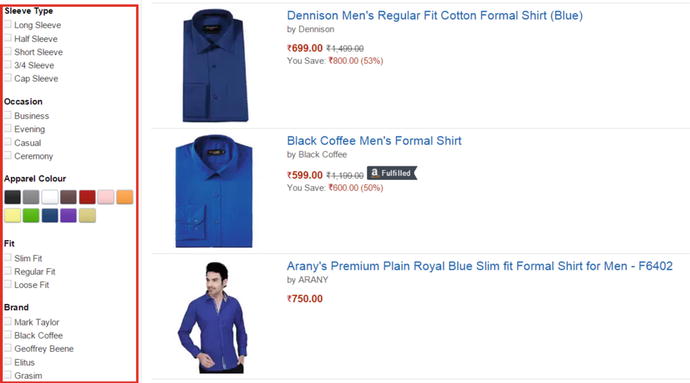
Figure 7-1. Faceting in an e-commerce web site
Faceting is easy to use in Solr. For example, field faceting, a faceting type based on field data, gets the indexed terms from a field and displays the facet values along with search results. Since the values are retrieved from the index, Solr always returns the unique values for that field. When a user selects a faceted value, it can be used to create a new query with an additional filter condition, such as fq=<facet-field>:’<user selected facet value>’ and to get a fresh result, which will be a subset of the original result. Similarly, if a user deselects a facet value, it can be used to make a fresh search request without that clause in the filter query to broaden the search result. This approach allows the user to navigate through the product easily.
Faceting is widely used in the following scenarios:
- Result classification
- Guided navigation
- Autocompletion
- Decision tree
- Analytics and aggregation
- Trend identification
Prior to release 5.1, Solr provided only a count on the facets. But now it supports aggregation, which runs a faceted function to generate statistics on categorized results. Using a faceted function, you can retrieve statistical information such as average, sum, and unique value. Solr 5.1 also supports the new JSON API for making requests, which facilitates providing field-specific parameters and nested commands.
Prerequisites
Here are the prerequisites for using faceting in Solr:
- The field must be indexed or should have docValues.
- Faceting also works on multivalued fields.
Since faceting works on indexed terms, the returned facets will be the indexed value (the tokens emitted after index-time text analysis). Hence, you need to analyze the facet field differently, so that the terms are as per your response needs. You can use copyField to copy the data from the searchable field to the facet field. Some standard practices for faceting are provided next.
If you tokenize a field, faceting will return each token, and that might make no sense to the user. For example, a tokenized brand field will generate facets such as "facet_fields":{"brand":["Giorgio",6,"Armani",8]}, but the user expects "facet_fields":{"brand":["Giorgio Armani",5]}, so that once he selects this brand, he can see results only from this brand. Therefore, tokenization is generally avoided for faceting.
If you apply LowerCaseFilterFactory, the result will be giorgio armani instead of desired Giorgio Armani. Therefore, lowercasing is generally avoided for faceting. If your data is poorly formatted, you can do some cleanup and apply standardization to ensure that formatting is consistent.
Syntax
Solr provides two provisions for faceted searches: traditional request parameters, and the JSON API.
Traditional Request Parameters
You can enable faceting by specifying additional request parameters, the way you do for other features. The syntax is provided here:
facet.<parameter>=<value>
Some of the request parameters can be specified on a per field basis. They follow the syntax f.<fieldname>.facet.<parameter>. For example, if the faceting parameter facet.count is to be applied specifically on the field brand, the request parameter will be f.brand.facet.count.
The nested structure of JSON provides ease of use in constructing requests, especially for field-specific request parameters. Solr provides the new JSON-based API. The JSON is specified as part of the json.facet request parameter:
json.facet={
<facet_name>:{
<facet_type>:{
<param1>:<value1>,
<param2>:<value2>,
..
<paramN>:<valueN>
}
}
}
Example
This section provides examples of both faceting approaches.
This section describes the types of faceting supported by Solr. Each faceting type supports a set of request parameters, a few of which are generic and apply to all faceting types, and a few that are specific to a faceting type. The JSON API identifies the faceting type based on the key type, the value of which corresponds to the type of faceting.
General Parameter
This section specifies the faceting parameter that applies to all types of faceting requests.
Faceting is one of the default components registered in SearchHandler, but its execution is disabled. It can be enabled by providing the parameter facet=true. Along with this parameter, another supporting parameter, which contains information about the type of faceting or how to facet, should be provided.
Field faceting, also called term faceting, allows you to build a facet on the indexed value in a field. You specify the field name on which to facet, and Solr returns all the unique terms in it. Remember, you may want to keep the field on which you build the facet as untokenized.
Specific Parameters
The following are the request parameters specific to field faceting.
This specifies the field for faceting. It can be specified multiple times to generate facets on multiple fields.
This returns the facets that match the specified prefix and is useful for building features such as autosuggestion. This parameter can be applied on a per field basis. In Chapter 9, you will learn to build an autosuggestion feature by using facets.
This returns the facets that contain the specified text. This parameter can be applied on a per field basis.
Set this Boolean parameter to true to ignore case while performing the facet.contains matching.
This parameter supports two values: index and count. By default, the results are sorted on index (lexicographically on the indexed terms), but if the facet.limit parameter is set to a value greater than 0, the results will be sorted on count. This parameter can also be specified on a per field basis.
This specifies the offset for the faceted result. This parameter can be specified on a per field basis. This parameter, along with facet.limit, can be used to enable pagination.
This specifies the maximum number of faceted results to return for each field. A negative value specifies unlimited results. By default, 100 results are returned. This parameter can be specified on a per field basis.
By default, faceting returns all the unique terms in a field. With this parameter, you can filter out the terms with frequency less than a minimum count. It allows faceting to return only those terms that have some minimum prominence. The default value is 0. This parameter can be specified on a per field basis.
On setting facet.missing=true, faceting returns the count for those documents that don’t have a facet value (the documents that match the user query, but the value for that faceted field is missing). By default, this parameter is set to false. This parameter can be specified on a per field basis.
facet.method
The facet.method parameter allows you to choose the algorithm for faceting. This parameter can be specified on a per field basis. The following are the supported methods:
- enum: This method gets all the terms in a field and performs an intersection of all documents matching it with all documents matching the query. Each unique term in the field creates a filter cache, so this approach should be used when the number of unique terms is limited. When using this method, ensure that the size of filterCache is large enough.
- fc: The name fc stands for FieldCache. This method iterates over all the matching documents, counting the terms in the faceted field. This method works faster for indexes where the number of distinct terms in the field is high but the number of terms in the document is low. Also, it consumes less memory than other methods and is the default method. This method creates an uninverted representation of field values for matching, so the first request will be slow.
- fcs: This method works only for single-valued string fields and supports faster faceting for a frequently changing index, as fc does uninversion whenever the index changes.
This parameter is applicable only for the enum faceting method and allows you to tweak caching. By default, the enum method uses filterCache for all the terms. If you set this parameter to value N, then terms with document frequency less than N will not be cached. A higher value will add fewer documents to filterCache, so the memory required will be less but you will have a performance trade-off.
This specifies the maximum number of threads to be spawned for faceting. By default, it uses the thread of the main request. If the value is negative, threads up to Integer.MAX_VALUE will be created. If the value is 0, the request will be served by the main thread.
In a distributed environment, the facet count returned is not accurate. To improve the accuracy, you request more facets from each shard than are specified by facet.limit. The overrequest is based on the following formula:
facet.overrequest.count + (facet.limit * facet.overrequest.ratio)
The default value for facet.overrequest.count is 10.
As you saw in the previous parameter, facet.overrequest.ratio also helps to control the number of facets fetched from each shard by multiplying to the facet.limit. The default value for this parameter is 1.5.
If you don’t specify any of these parameters, Solr by default fetches 25 facets for each field, based on the computation 10 + (10 * 1.5), where the first 10 is the default value for facet.overrequest.count, the second 10 is the default value for facet.limit, and 1.5 is the default value for facet.overrequest.ratio.
Query faceting allows you to provide a Lucene query for faceting. You can specify this parameter multiple times to generate multiple facets.
Specific Parameters
The following is the request parameter for query faceting.
This specifies the Lucene query for generating the facet. If you want to use another query parser, it can be specified using LocalParams. The following is an example of a facet query:
facet=true&facet.query=singer:"bob marley"&facet.query=genre:pop // lucene query
facet=true&facet.query={!dismax}bob marley // faceting with dismax qparser
Suppose you want to build a facet based on the date or price of a product. It would not be a good idea to display all the unique dates or prices. Instead, you should display year ranges, such as 2001–2010, or prices such as $201–$300. A way to build this with a field facet is by indexing the range in a separate field. However, to change the range in the future, you would need to reindex all the documents. Well, that doesn’t seem to be a great idea. You could achieve this with a faceted query, but you would need to specify multiple queries.
Solr provides a built-in solution to the problem through range faceting. This can be applied on any field that supports a range query.
Specific Parameters
The following are the request parameters specific to range faceting.
facet.range
This specifies the field on which the range query should be applied. It can be provided multiple times to perform a range query on multiple fields.
This specifies the lower boundary for the range. Index values lower than the range will be ignored. It can be specified on a per field basis.
This specifies the upper boundary for the range. Index values above the range will be ignored. It can be specified on a per field basis.
This specifies the size of the range. For a date field, the range should adhere to DataMathParser syntax. This parameter can be specified on a per field basis.
Suppose you set the start at 1 and the end at 500, and set a gap of 200. The facets generated will be 1–200, and 201–400, but for the third range there is an ambiguity of whether the range should be 401–500 or 401–600.
The Boolean parameter facet.range.hardend allows you to specify whether the end should be strictly followed. If you set this parameter to true, the last range will be 401–500; if you set it to false, the last range will be 401–600. The default value for this parameter is false, and it is allowed on a per field basis.
This parameter allows you to handle lower and upper boundary values. The following are the options available:
- lower: Include the lower boundary.
- upper: Include the upper boundary.
- edge: Include the edge boundary (include the lower boundary for the first range and upper boundary for the last range).
- outer: When the facet.range.other parameter is specified, its before and after ranges will include the boundary values.
- all: Applies all of the preceding options.
This parameter can be specified multiple times to set multiple options. By default, faceting includes the lower boundary and excludes the upper boundary. If you set both lower and upper or outer or all, the values will overlap, so set it accordingly. This parameter can be applied on a per field basis.
This parameter allows you to get additional counts. Here are the available options:
- below: Facet on all values below the lowest range (facet.range.start).
- above: Facet on all values beyond the highest range.
- between: Facet on all records between the lower and upper boundary.
- all: Apply all of the preceding options.
- none: Do not apply any of these options.
This parameter can be specified multiple times to set multiple options, but the none option overrides all. It can be applied on a per field basis.
This parameter specifies the count below which the range facet should be ignored. You saw this parameter in field faceting also.
Example
This section presents an example of range faceting. In this example, you are applying range faceting on a price field to get the count of products in the price ranges of 201–400; 401–600; 601–800; 801–1,000; and 1,001–1,200. You set hardend=false, so the highest facet is of 1,001–1,200 instead of 1,001–1,100. Create a facet for all values below the minimum range and all values above the maximum range. Include only the terms that have a minimum count of 5.
$ curl http://localhost:8983/solr/ecommerce/select?q=*:*
&facet.range=price&facet.range.start=201&facet.range.end=1100
&facet.range.gap=200&facet.mincount=5&facet=true
&facet.range.hardend=false&f.price.facet.range.include=lower
&f.price.facet.range.other=below&f.price.facet.range.other=above
This form of faceting is an alternate way of performing facet queries with range queries but with a different implementation. Interval faceting works on docValues and so requires docValues to be enabled on fields you facet and offers different performance depending on the content. You need to run some tests to identify whether interval faceting or a facet query with range queries provides better performance for you. Interval faceting provides better performance when getting multiple ranges on the same field, but a faceted query is good for a system with effective caching.
The following are the request parameters specific to interval faceting.facet.interval
This parameter specifies the field name on which interval faceting should be applied. This parameter can be applied on a per field basis.
In this parameter, you specify the syntax for building interval facets. You can specify it multiple times for multiple intervals, and it can be applied on a per field basis. Here is the syntax for setting the interval:
[<start-value>,<end-value>]
The square brackets can be replaced with parentheses. A square bracket means the values are inclusive, and the parentheses means the values are exclusive. An opening square bracket can end with a closing parenthesis, and vice versa. The bracket you choose will depend on your condition. The following are a few examples:
- (1,100): Greater than 1 and less than 100
- [1,100): Greater than or equal to 1, and less than 100
- [1,100]: Greater than or equal to 1, and less than or equal to 100
- (1,100]: Greater than 1, and less than or equal to 100
For an unbounded interval, the special character * can be used as a value.
Example
This section presents examples of interval faceting.
Pivot faceting helps you build multilevel facets (a facet within facet). All the facets previously mentioned provide only top-level facets. Now, to build another facet on that facet, you need to send another request to Solr. But the pivot facet saves the day. You can build a decision tree without sending additional requests to Solr with additional filter queries. Hence, pivot faceting reduces the number of round-trips.
Specific Parameters
The following are the request parameters specific to pivot faceting.
This parameter specifies the comma-separated list of fields to pivot. This parameter can be specified multiple times, and each parameter will add a separate facet_pivot section to the response.
facet.pivot=brand,size
This parameter specifies the lower threshold. Terms with a count less than mincount will be ignored.
Pivot faceting also supports the following request parameters of field faceting (please refer to the field faceting section for details):
- facet.limit
- facet.offset
- facet.sort
- facet.overrequest.count
- facet.overrequest.ratio
Example
This section presents an example of pivot faceting.
Solr 4.9 introduced the reranking query, which allows you to provide an additional query to rerank the top N results returned by the main query. This feature is useful if you want to run a query that is too costly to run on all the documents, or you want to reorder the top N results based on a custom requirement. It’s possible that documents beyond the N result could be of interest and that the reranking query might miss it. But that’s a trade-off for performance.
The reranking attributes can be specified using local parameters in the additional request parameter rq. Solr provides ReRankQParserPlugin, a query parser for parsing the reranking queries. This parser is identified by the name rerank.
The reranking query provides debug and custom explain information, when you set debug=true. You can use this to analyze the reranked score of the document. The reranking query also plays well with other features of Solr, and you can use them together.
The following are the request parameters supported by ReRankQParserPlugin.
This mandatory parameter specifies the query that is parsed by the ReRankQParser to rerank the top documents.
The parameter specifies the minimum number of top documents from the main query to consider for reranking. The default value is 200.
This parameter specifies the factor by which the score of the rerank query is multiplied. The resultant score is added to the score of the main query. The default value is 2.0.
Example
This section presents an example of a reranking query.
This example uses ReRankQParser to rerank the top 200 documents returned by the main query provided in the q parameter. The reranking query is provided in the reRankQuery parameter by dereferencing, using the rrq parameter for convenience. The example queries all rock songs and reranks rock music of type reggae and beat:
$ curl http://localhost:8983/solr/music/select?q=genre:rock
&rq={!rerank reRankQuery=$rrq reRankDocs=200 reRankWeight=3.0}
&rrq=genre:(regge beat)
Generally, you denormalize your data before indexing it to Solr, but denormalization is not always an option. Suppose you have a frequently changing value, and for each change, you need to find all the occurrences of that value and update the documents containing it. For such scenarios, Solr provides the join query, which you can use to join two indexes.
Solr implements this feature by using JoinQParser, which parses the user query provided as a LocalParam and returns JoinQuery. Here is the JoinQuery syntax:
{!join fromIndex=<core-name> from=<from-field> to=<to-field>}
Limitations
A join query in Solr is different from SQL joins, and it has these limitations:
- You can join on from documents but cannot return values from from documents along with the results in the to documents.
- The score of from documents cannot be used for computing the score of to documents.
- Both from and to fields should be compatible and should go through similar analysis in order for documents to match.
- Both from and to indexes should exist on the same node.
Example
This section presents an example of a join query.
A join query performs a join at query time to match related fields in different indexes. Using a block join, you can index nested documents and query them by using BlockJoinQuery. A block join can offer better query-time performance, as the relationship is stored in a block as parent-child, and document matching doesn’t need to be performed at query time.
Prerequisites
The following are prerequisites for a block join:
- Define the additional field _root_ in schema.xml.
- Index the additional field, which differentiates the parent document from the child document.
- During indexing, child documents should be nested inside the parent document.
- When updating nested documents, you need to reindex the whole block at once. You cannot reindex only the child or parent document.
Solr provides two parsers to support the block join: BlockJoinParentQParser and BlockJoinChildQParser.
BlockJoinChildQParser matches the query against the parent documents and returns the child documents in that block. Here is the syntax:
{!child of=<field:value>}<parent-condition>
The LocalParam of contains the field name and value that differentiate the parent document from the children. The condition following the closing brace can be a Lucene query against the parent document for finding the matching child document. The returned result set will be the nested documents in the matched block.
BlockJoinParentQParser matches the query against the child documents and returns the parent document of that block. Here is the syntax:
{!parent which=<field:value>}<children-condition>
The LocalParam which contains the field name and value, which differentiate the parent document from the children. The condition following the closing brace can be a Lucene query against the child documents for finding the matching parent document. The returned result set will be the nested documents in the matched block.
Example
This section presents an example of indexing block documents and performing a search by using a block-join child query and a block-join parent query.
When a search query is submitted to Solr for retrieving documents, it executes a ranking formula for computing the score of each document matching the query terms. The resultant documents are ordered on the basis of relevancy.
Lucene uses a combination of the Boolean model (BM) and a modified form of the vector space model (VSM) for scoring the documents. You learned the basics of these information retrieval models in Chapter 3. The score is primarily based on term frequency (which signifies that documents containing the query terms more often are ranked higher) and inverse document frequency (which signifies that rarer terms are ranked higher). Chapter 8 covers more details on Solr scoring.
Now, assume that you have defined the required searchable fields, given them appropriate boosts, and created a proper text-analysis chain, Solr will match the user query with document terms by using its scoring formula. This scoring algorithm might be doing a great job determining the relevance of documents, but it has a limitation: the score is computed on the basis of textual similarity. The ranking achieved from this score might not consider factors of practical importance and user needs, especially in real-world cases that require other factors to be considered. The following are examples from different domains, where other factors play an important role:
- A music search engine generally considers popularity and user ratings in deciding the relevancy of songs. The idea is that for two textually similar documents, the one with higher popularity and ratings should be ranked higher.
- In a news site, the freshness of news is crucial, so recency and creation time become important factors.
- A restaurant discovery application ranks nearby restaurants higher for users querying to order a pizza. In any geographical search system, the location and coordinates are more important factors than textual similarity.
A function query allows you to compute the score of documents on the basis of external factors such as a numeric value or a mathematical expression, which can complement the existing Solr score to come up with the final score for a document.
Function queries use functions for computing the score, which can be of any of the types listed in Table 7-5.
Table 7-5. Function Types
Type | Description | Example |
|---|---|---|
Constant value | Assigns a constant score. | _val_:2.0 |
String literal | Uses a string literal value for computing the score. A string literal is not supported by all functions. | literal("A literal value") |
Solr field | A Solr field can be specified. The field must exist in schema.xml and follow the prerequisites mentioned in the next section. | sqrt(popularity) |
Function | Solr allows you to use one function inside another. | sqrt(sum(x,100)) |
Parameter substitution | Solr allows you to use parameter substitution as a function. | q=_val_:sqrt($val1)&val1=100 |
Function queries are supported by the DisMax, eDisMax, and standard query parsers.
Prerequisites
If you are using a Solr field in a function query, it has the following prerequisites:
- The field must be indexed and single-valued.
- It must emit only one term from text analysis.
Function queries are not limited to complementing the score for relevance ranking of documents. These queries can also be used for sorting the results or computing the value to be returned in the response. Function queries can be used in Solr in the following ways:
- FunctionQParserPlugin: Solr provides FunctionQParserPlugin, a dedicated QParserPlugin for creating a function query from the input value. It can be invoked by using LocalParams or by specifying the parser in the defType parameter, as shown in this example:
q={!func}sqrt(clicks) // LocalParams
q=sqrt(clicks)&defType=func // defType - FunctionRangeQParserPlugin: This is similar to FunctionQParserPlugin but creates a range query over a function. The Javadoc at https://lucene.apache.org/solr/5_3_1/solr-core/org/apache/solr/search/FunctionRangeQParserPlugin.html provides a list of supported parameters. It can be used in a filter query via LocalParams, as shown here:
fq={!frange l=0 u=2.0}sum(user_rating,expert_rating) - q parameter: The function query can be embedded in a regular search query by using the _val_ hook. All the rules of _val_ apply to it.
q=singer:(bob marley) _val_:"sqrt(clicks)" - bf parameter: The bf parameter in DisMax and Extended DisMax allows you to specify a list of function queries separated by whitespace. You can optionally assign a boost to the queries. The following is an example of a function query applied using the bf parameter.
q=singer:(bob marley)&bf="sqrt(clicks)^0.5 recip(rord(price),1,1000,1000)^0.3" - boost parameter: Similar to bf, function queries can be applied on a boost parameter or boost query parser, as shown here.
q=singer:(bob marley)&boost="sqrt(clicks)^0.5 recip(rord(price),1,1000,1000)^0.3"
q={!boost b=sqrt(popularity)}singer:(bob marley) - sort parameter: Solr allows you to sort the results by using a function query. The following is an example of result sorting in descending order, based on the computed sum of user_rating and expert_rating field:
q=singer:(bob marley)&sort=sum(user_rating,expert_rating) desc - fl parameter: Function queries can be used in the fl parameter to create a pseudo field and return the output of the function query in response. The following example returns the rating of titles computed by taking the average of user_rating and expert_rating:
q=singer:(bob marley)&fl=title,album, div(sum(user_rating,expert_rating),2),score
Function Categories
In the previous section, you saw a few examples of functions such as sqrt(), sum(), and rord(). The functions supported by Solr can be broadly categorized into the following groups:
- Mathematical function: These functions support mathematical computations such as sum(), div(), log(), sin(), and cos(). Refer to java.util.Math Javadocs for details of these mathematical functions.
- Date function: For use cases such as news and blogs, the documents need to be boosted on recency. Solr provides the ms() function to return the millisecond difference since the epoch of midnight, January 1, 1970 UTC. In the next section, you will see an example of boosting recent documents.
- Boolean function: The Boolean functions can be used for taking appropriate action if a condition is met. The following example modifies the previous FunctionQParserPlugin example to assign a default user_rating of 5, if the value is missing in that field:
fq={!frange l=0 u=2.0}sum(def(user_rating,5),expert_rating) - Relevancy function: Solr provides a set of relevancy functions to retrieve information about the indexed terms, such as document frequency and term frequency.
q=idf(color,’red’) - Distance function: Solr provides functions for computing a distance between two points by using, for example, Euclidian distance or Manhattan distance. It also allows you to compute the distance between two strings by using formulas such as the Levenshtein distance or Jaro-Winkler. The following example computes the distance between the terms red and raid by using the Jaro-Winkler edit-distance formula.
strdist("red","raid",jw) - Geospatial search: Solr supports location data and geospatial searches and provides function queries such as geodist(). The preceding functions for computing distance between points are also widely used in spatial searches. Refer to the Solr documentation at https://cwiki.apache.org/confluence/display/solr/Spatial+Search for more details on spatial search.
- Other functions: Solr supports some additional functions such as ord(), which returns the ordinal of the indexed field value within the indexed list of terms for that field.
![]() Note Refer to the Solr official documentation at https://cwiki.apache.org/confluence/display/solr/Function+Queries for a complete list of supported methods and their uses.
Note Refer to the Solr official documentation at https://cwiki.apache.org/confluence/display/solr/Function+Queries for a complete list of supported methods and their uses.
Example
You have already seen a couple of examples in our discussions about the function query. Let’s see a few more examples illustrating some common needs for tuning the relevance ranking of documents by using function query.
A function query is a wonderful tool for addressing real-world ranking needs, but it demands to be used cautiously. The following are some of the important factors to be taken care of while using it:
- The function query should be fair, and its impact should be optimally set. If the output of a function query or the boost value is very high, it can lead to documents with poor textual similarity also ranking very high. In a worst-case scenario, it can be possible that whatever query you give, a document with a very high function score always appears as the most relevant document.
- A function query runs for each matching document. Therefore, costly computation should be avoided, as it can affect the performance drastically. Solr recommends functions with fast random access.
- While writing a mathematical expression, the default values should be handled appropriately. For example, product(x,y) can result in a score of 0 if either of the input values is 0.
![]() Note If there is no value for a field in the index, 0 is substituted for use in the function query.
Note If there is no value for a field in the index, 0 is substituted for use in the function query.
In the previous section, you learned about functions provided by Solr to use in function queries. At times the Solr-provided functions might not fit your business needs, and you may want to plug in your own named function to Solr.
Lucene defines classes for function queries in the package org.apache.lucene.queries.function.*. To write your custom function, you need to extend the following two Lucene classes:
- ValueSourceParser: A factory that parses user queries to generate ValueSource instances.
- ValueSource: An abstract class for creating a function query. The custom function will be defined in the class extending it.
In this section, you will learn to write a custom function.
Assume that you are working for a highly fashionable e-commerce company, where a majority of units sold are of the top trending products. You have analyzed that each trend starts small in your company, grows slowly, reaches a peak, and then begins to fall and slowly go off the chart. The trend moves like a bell curve. For this specific need, you decide to develop a function using a Gaussian formula, which provides a score that follows the bell curve. Here are the steps you need to follow:
- Extend the ValueSourceParser abstract class.
public class GaussianValueSourceParser extends ValueSourceParser {
} - Implement the parse() abstract method and return an instance of the custom ValueSource implementation, which you will create in the next step. Also, get the ValueSource from FunctionQParser and pass it to the custom ValueSource. You will need it in your custom algorithm. You can optionally pass additional parameters, as shown in this example.
@Override
public ValueSource parse(FunctionQParser fp) throws SyntaxError {
ValueSource vs = fp.parseValueSource();
return new GaussianValueSource(vs, stdDeviation, mean);
} - If you want to read parameters from the factory definition in solrconfig.xml, you can optionally extend the init() method. You read the standard deviation and mean values and provide them to the constructor of the custom ValueSource.
public void init(NamedList namedList) {
this.stdDeviation = (Float) namedList.get(STD_DEVIATION_PARAM);
this.mean = (Float) namedList.get(MEAN_PARAM);
} - Create a custom class by extending the ValueSource abstract class. Define the constructor for setting the instance variables.
protected final ValueSource source;
protected float stdDeviation = 1.0f;
protected float mean = 1.0f;
protected float variance = 1.0f;
public GaussianValueSource(ValueSource source, float stdDeviation, float mean) {
this.source = source;
this.stdDeviation = stdDeviation;
this.variance = stdDeviation * stdDeviation;
this.mean = mean;
} - Override the getValues() method of ValueSource. The method should return an implementation of FloatDocValues, an abstract class to support float values. In this method, also get the FunctionValues, using the getValues() method of the ValueSource instance provided by the factory.
@Override
public FunctionValues getValues(Map context, LeafReaderContext readerContext)
throws IOException {
final FunctionValues aVals = source.getValues(context, readerContext);
return new FloatDocValues(this) {
..
};
} - Override the floatVal() method of the FloatDocValues class and get the value from the floatVal() method of the FunctionValues class that you instantiated in the previous step. This value is based on the function query type, such as the value of a Solr field.
@Override
public float floatVal(int doc) {
float val1 = aVals.floatVal(doc);
..
} - Write your custom logic that acts as the value and return the float score. The Gaussian formula is shown here; you can replace it with any other formula.
float score = (float) Math.pow(Math.exp(-(((val1 - mean)
* (val1 - mean)) / ((2 * variance)))), 1 /
(stdDeviation * Math.sqrt(2 * Math.PI)));
return score; - Override the abstract methods toString() in the FloatDocValues implementation.
@Override
public String toString(int doc) {
return "Gaussian function query (" + aVals.toString(doc) + ’)’;
} - Override the abstract method hashCode() in the ValueSource implementation.
@Override
public int hashCode() {
return source.hashCode() + "Gaussian function query".hashCode();
} - Build the program and add the path of Java binary JAR to the lib definition in solrconfig.xml.
<lib dir="./lib" /> - Register the custom ValueSourceParser in solrconfig.xml.
<valueSourceParser name="gaussian"
class="com.apress.solr.pa.chapter07.functionquery.GaussianValueSourceParser" >
<float name="stdDeviation">1.0</float>
<float name="mean">8</float>
</valueSourceParser> - Use the new named function in your search, gaussian in this case.
$ curl http://localhost:8983/solr/ecommerce/select?q=blazer&defType=edismax
&fl=score,product,trendcount&boost=gaussian(trendcount)
Java Source Code
The following is the complete Java source code for the Gaussian ValueSource discussed in this section.
A function query uses information such as user ratings, download count, or trending count to compute the function score. If you look at these values, they change more frequently than values in other fields. For example, a video-sharing web site like YouTube requires updating the trending count every few hours, as it’s common these days for a video to get a million hits in a day.
Indexing this frequently changing information requires updating other fields also, which change less frequently. To address such use cases, Solr provides ExternalFileField, a special implementation of FieldType, which allows you to specify the field values in an external file. The external file contains the mapping from the key field in the document to the external value. Solr allows you to modify the file at a desired frequency without reindexing the other fields.
The caveat is that the external fields are not searchable. They can be used only for function queries or returning a response.
Usage
Following are the steps to configure ExternalFileField in your search engine:
- Define the FieldType for ExternalFileField in schema.xml and specify the appropriate parameters. The following are the special parameters provided by ExternalFileField:
- keyField: Specifies the Solr field that should be used for mapping the value.
- defVal: Defines the default value, if entry for the key is missing in the external file.
- valType: Specifies the type of value in the file. The valid values for this attribute are float, pfloat, and tfloat.
A sample fieldType definition is provided here:
<fieldType name="trendingCount" stored="false" indexed="false"
keyField="trackId" defVal="0" class="solr.ExternalFileField"
valType="pfloat"/> - Create the external file with the name external_<fieldname> in Solr’s index directory, which is $SOLR_HOME/<core>/data by default. The file should contain a key-value pair delimited by =. The external file for the trendingCount field mentioned previously should look like this:
$ cat external_trendingCount
doc1=1.0
doc2=0.8
doc3=2The external file name can also end with an extension, such as external_trendingCount.txt. If Solr discovers multiple files with a .* pattern, it will sort the files on name and refer the last one.
- Solr allows you to define an event listener, which activates whenever a new searcher is opened or an existing searcher is reloaded. Register the ExternalFileField to the desired listener. The following is an example for registering to the listener:
<listener event="newSearcher"
class="org.apache.solr.schema.ExternalFileFieldReloader"/>
<listener event="firstSearcher"
class="org.apache.solr.schema.ExternalFileFieldReloader"/>
After following these steps, ExternalFileField is ready to be configured in any field definition, which can be used in a function query like any other field that you’ve seen.
Summary
The previous chapter focused on the core component of Solr: querying. In this chapter, you learned to get granular control over querying by using LocalParams and the reranking query, to join indexes by using a join query, and to index hierarchical data by using a block join. Then you learned about other features such as result grouping, faceting, and statistics.
You saw how nontextual information such as popularity, recency, and trends are crucial for deciding the relevance ranking of documents, and how to use that information in Solr. You also learned to write a custom named function for use in a function query.
In the next chapter, you will learn about Solr scoring. At the end of that chapter, you will understand how a document ranks at a particular position in the result set and why a document appears before or after another document.