
![]()
Additional Features
The purpose of developing a search engine is to help users find the most relevant information in the most convenient way. In Chapters 6 and 7, you learned about various approaches for retrieving documents and implementations provided by Solr to achieve that.
In this chapter, you will learn about other important features of Solr that will bring in convenience and add to the user experience. You also will see other features that can be used to control document ranking and recommend other documents of interest to the user.
This chapter covers the following topics:
- Sponsored search
- Spell-checking
- Autosuggestion
- Document similarity
Sponsored Search
For a given query, you may want a set of handpicked documents to be elevated to the top of the search result. You generally need such a feature either to allow a sponsored search or to support editorial boosting. Google AdWords is a typical example of a sponsored search. In addition, at times a relevant document might rank low or an irrelevant document might rank high in the response, and you’ll need a quick solution to fix these problems, especially when they are discovered in production.
Solr provides QueryElevationComponent as a quick and easy solution to address these needs. For a specified query, it supports the following behaviors, irrespective of the score of the document:
- Bringing a desired set of documents to the top of the search result
- Excluding a set of documents from the search result
![]() Note QueryElevationComponent requires the uniqueKey field to be defined in schema.xml. It works in a distributed environment also.
Note QueryElevationComponent requires the uniqueKey field to be defined in schema.xml. It works in a distributed environment also.
Usage
Here are the steps for using the query elevation component:
1. Define the elevation file. This file contains the rules for elevating and excluding documents.
The filename must map to the name provided in the config-file parameter in QueryElevationComponent. The following is a sample query elevation file.
The text attribute of the query element specifies the query to be editorially boosted. The doc element represents the documents to be manipulated. Its id attribute marks the document that should be elevated, and if the additional attribute exclude="true" is specified, the document is marked for exclusion. The provided id should map to the uniqueKey of a document.
The elevation file must exist either in the $SOLR_HOME/<core>/conf/ or $SOLR_HOME/<core>/data directory. If it exists in conf, modifications to the file will reflect on core reload; and if it exists in data, modifications will reflect for each IndexReader.
![]() Note The component first looks for elevate.xml in the conf directory (or ZooKeeper, if applicable) and then in data. If you have the file in both directories, conf will get the priority.
Note The component first looks for elevate.xml in the conf directory (or ZooKeeper, if applicable) and then in data. If you have the file in both directories, conf will get the priority.
2. Configure the QueryElevationComponent in solrconfig.xml. Table 9-1 describes the arguments supported to control the behavior of the component. The following is an example configuration.
<searchComponent name="elevator" class="solr.QueryElevationComponent" >
<str name="config-file">elevate.xml</str>
<str name="queryFieldType">string</str>
</searchComponent>
Table 9-1. QueryElevationComponent Parameters
Parameter | Description |
|---|---|
config-file | Specifies the name of the file that contains the query elevation rules. |
queryFieldType | Specifies the fieldType that should be used to analyze the user query. The analyzed terms are matched against the query defined in the elevation file. The specified fieldType must exist in schema.xml. If you want no analysis to be performed, specify string as the queryFieldType. |
forceElevation | Query elevation introduces or eliminates documents from the result set as configured but respects sorting. If you apply any sorting other than score desc, the elevated documents will change their order based on the sort condition. Setting this parameter to true overrides this behavior. |
editorialMarkerFieldName | This parameter helps to differentiate the elevated documents from organically ranked documents. The elevated documents get an additional field with this name. The default name is editorial. The marker is enabled when the assigned name is added to the fl request parameter. An example of using this marker has been provided further. |
markExcludes | By default, the excluded documents are removed from the search result. Setting this parameter to true marks such documents as excluded instead of removing them altogether. |
excludeMarkerFieldName | This parameter assigns a fieldname to the excluded documents. It works only with the markExcludes parameter. The default name assigned is excluded. |
3. Register the component to the last-components list of the desired handler.
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
</lst>
<arr name="last-components">
<str>elevator</str>
</arr>
</requestHandler>
4. Provide additional request parameters for the component. Table 9-2 lists the additional parameters supported.
Table 9-2. QueryElevationComponent Request Parameters
Parameter | Description |
|---|---|
enableElevation | This parameter enables the QueryElevationComponent. |
exclusive | This Boolean parameter, if enabled, returns only elevated results. Organic results will be ignored. |
elevateIds | This parameter specifies the comma-separated list of document IDs to be elevated. |
excludeIds | This parameter specifies the comma-separated list of document IDs to be excluded. |
5. Query for results. The following are some sample queries.
Spell-Checking
User queries are prone to error, so almost all popular search engines support a spell-checking feature. For a misspelled query, this feature suggests the corrected form of text. You will generally see the suggestion appear just below the search box. For example, go to Amazon.com and search for laptap (a misspelled form of laptop) and the response will contain additional information such as Did you mean: laptop.
Search engines take two approaches to spell-checking. They either execute the original query and provide a spelling suggestion or they execute a spell-corrected query with the option to run the original query instead. Web search engines such as Google, Bing, and Yahoo! take the optimistic approach of spell correction. They retrieve the result for the corrected form of the query and provide the user with an option to execute the original query.
Figure 9-1 depicts a typical spell-checking example (from Google), where the misspelled query wikipadia is spell-corrected to wikipedia, and a result is provided for it.
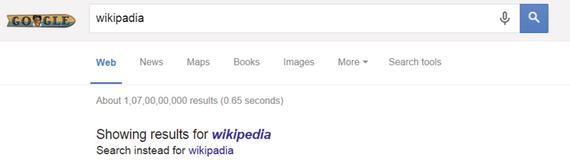
Figure 9-1. Example of spell-checking in Google
Solr provides out-of-the-box support for spell-checking. It allows you to provide suggestions based on terms maintained in a Solr field, an external Lucene index, or an external text file. Solr provides SpellCheckComponent, which extends SearchComponent to implement this feature and can be configured to any SearchHandler to get it to work.
If you just want to provide a spelling suggestion to the user, asking, for example, “Did you mean?”, configure the SpellCheckComponent to the query handler, such as /select, and display the response from this component at an appropriate position for user’s action. If your intention is to provide an autocorrected result to the user, configure the SpellCheckComponent in a separate handler, such as /spell, and query with collation enabled. You will learn about collation later in this section. The spell-corrected response returned by this handler should be used by the client to make a fresh request to the query handler, such as /select. This process of autocorrection requires two Solr requests.
SpellCheckComponent provides a set of alternative options for spell-checking, which can be specified in the classname parameter. Multiple spell-checkers can be configured to execute at once.
You should perform minimal analysis on the field used for spell-checking. Analysis that transforms the tokens to a totally different form, such as stemming or synonym expansion, should be avoided. For a Solr field–based spell-checker, it would be a good idea to have a separate field for spell-checking, to which the content of all fields that require spell suggestion can be copied.
SpellCheckComponent supports distributed environment.
Generic Parameters
Table 9-3 refers to the generic parameters, which can be used in any of the spell-checker implementations.
Table 9-3. SpellCheckComponent Generic Parameters
Parameter | Description |
|---|---|
name | Assigns a name to the spell-checker definition. This parameter is useful when configuring multiple spell-checkers to the component. |
classname | Specifies the spell-checker implementation to use. The value can be specified as solr.<implementation-class>, such as solr.FileBasedSpellCheck. The default implementation is IndexBasedSpellCheck. |
Implementations
This section explains the spell-checker implementations available in Solr. Each provides a set of specific parameters that can be used along with the generic parameters in Table 9-3.
IndexBasedSpellChecker uses a separate index for maintaining the spell-checker dictionary. This index is an additional index, also called a sidecar index, which is created and maintained separately from the main index. While configuring the spell-checker, you specify the source field to use for creating the sidecar index.
This is the default spell-checker implementation registered in SpellCheckComponent.
Table 9-4 specifies the additional parameters for configuring IndexBasedSpellChecker.
Table 9-4. IndexBasedSpellChecker Parameters
Parameter | Description |
|---|---|
field | Specifies the Solr field, defined in schema.xml, to use for building the dictionary. |
sourceLocation | Instead of loading the terms from the Solr field, this spell-checker also allows you to load it from an arbitrary Lucene index. This parameter specifies the directory of the Lucene index. |
spellcheckIndexDir | Specifies the directory where the sidecar index will be created. |
buildOnCommit | Setting this Boolean parameter to true builds the dictionary on each commit. By default, this parameter is set to false. |
Instead of building an additional index specifically for spell-checking, this implementation uses the main Solr index. Because of the use of the main index, the spell-checker always has the latest terms available and also saves you from rebuilding the index regularly.
Table 9-5 specifies the additional parameters for configuring DirectSolrSpellChecker.
Table 9-5. DirectSolrSpellChecker Parameters
Parameter | Description |
|---|---|
field | Specifies the Solr field, defined in schema.xml, to be used for spell- checking. |
accuracy | Specifies the accuracy level for suggestion. The default value is 0.5. |
maxEdits | Specifies the maximum number of modifications allowed in the term. |
minPrefix | Specifies the minimum number of initial characters after which edits are allowed. A higher value will lead to better performance. Also, you will notice that the first few characters are generally not misspelled. The default value is 1. |
maxInspections | Specifies the maximum number of matches to inspect before returning the suggestion. The default value is 5. |
minQueryLength | Specifies the minimum number of characters in the query for generating suggestions. No suggestion will be generated if the query is shorter than this length. |
maxQueryFrequency | Specifies the maximum number of documents the query terms should appear in. If the count is more than the threshold specified, that term will be ignored. The value can be absolute (for example, 5) or a percentage (such as 0.01 or 1%). The default value is 0.01. |
thresholdTokenFrequency | Specifies the minimum number of documents the query terms should appear in. If the count is less than the threshold specified, that term will be ignored. Similar to maxQueryFrequency, either absolute value or percentage can be specified. The default value is 0.0. |
FileBasedSpellChecker
FileBasedSpellChecker uses an external text file as a source for spellings and builds a Lucene index out of it. This implementation is helpful when you don’t want the spell-checker to be based on terms in the indexed documents, but extracted from another source such as log analysis of frequent queries or external thesauri.
The source file should be a simple text file having one word defined per line. Here is a sample file.
Table 9-6 specifies the additional parameters for configuring FileBasedSpellChecker.
Table 9-6. FileBasedSpellChecker Parameters
Parameter | Description |
|---|---|
sourceLocation | Specifies the path of the text file that contains the terms. |
characterEncoding | Specifies the encoding of terms in the file. |
spellcheckIndexDir | Specifies the directory where the index will be created. |
This implementation focuses on performing spell-check to detect spelling mistakes due to missing or unwanted whitespace. It is highly probable that the user can split a word into two words or join two words into one. A typical example is spell checker and spellchecker. WordBreakSolrSpellCheckeris developed to address this particular problem. It combines and breaks terms to offer suggestions.
Table 9-7 specifies the additional parameters for configuring WordBreakSolrSpellChecker.
Table 9-7. WordBreakSolrSpellChecker Parameters
Parameter | Description |
|---|---|
field | Specifies the Solr field, defined in schema.xml, to use for building the dictionary. |
combineWords | Specifies whether the adjacent terms should be combined. The default value is true. |
breakWords | Specifies whether the spell-checker should try to break the term into multiple terms. The default value is true. |
maxChanges | Specifies the maximum number of collation attempts the spell-checker should make. |
How It Works
The SpellCheckComponent class in Solr implements SearchComponent, which utilizes the SpellChecker implementation provided by Lucene. The steps followed by the SpellCheckComponent for processing the requests are as follows:
- The client makes a request to a SearchHandler that has SpellCheckComponent registered to it.
- The SpellCheckComponent, like any other SearchComponent, executes in two phases, namely prepare and process.
- If the received request is to build or reload the dictionary, it is done in the prepare phase. DirectSolrSpellChecker and WordBreakSolrSpellChecker don’t require a build or reload.
- In the process phase, Solr tokenizes the query with the applicable query analyzer and calls the appropriate SpellChecker with the provided request parameters.
- The spell-checker implementation generates suggestions from the loaded dictionary or field as applicable.
- If collation is required, Solr calls the SpellCheckCollator to collate the spellings.
- The generated responses are returned to the client.
![]() Note If you are interested in details of internal processing or are planning customization, you can refer to these steps; otherwise, Solr doesn’t require you to know them.
Note If you are interested in details of internal processing or are planning customization, you can refer to these steps; otherwise, Solr doesn’t require you to know them.
Usage
Following are the steps to integrate and use spell-checker:
- Define the SpellCheckComponent in solrconfig.xml, specify the implementation classname, and add the parameters from the table of corresponding classnames.
Register a single spell-checker
<searchComponent name="spellcheck" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="classname">solr.IndexBasedSpellChecker</str>
<str name="spellcheckIndexDir">./spellchecker</str>
<str name="field">spellings</str>
<str name="buildOnCommit">true</str>
</lst>
</searchComponent>Register multiple spell-checkers
<searchComponent name="spellcheck" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="name">primary</str>
<str name="classname">solr.IndexBasedSpellChecker</str>
..
</lst>
<lst name="spellchecker">
<str name="name">secondary</str>
<str name="classname">solr.FileBasedSpellChecker</str>
..
</lst>
</searchComponent> - Register the component to the desired SearchHandler. You can register it either to your primary handler that serves the search request or a separate handler dedicated for spell-checking. The following is an example configuration that registers multiple spell-checkers to the /select handler.
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="spellcheck.dictionary">primary</str>
<str name="spellcheck.dictionary">secondary</str>
</lst>
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>Table 9-8 lists the request parameters supported by SpellCheckComponent.
Table 9-8. SpellCheckerComponent Request Parameters
Parameter
Description
spellcheck
By default, spell-checking is disabled. Set spellcheck="true" to turn on the feature.
spellcheck.q
Specifies the query for spell-checking. If this parameter is not specified, the component takes the value from the q parameter.
spellcheck.count
Specifies the maximum number of suggestions to return. The default value is 1.
spellcheck.dictionary
Specifies the dictionary to be used for the request.
spellcheck.build
This parameter clears the existing dictionary and creates a fresh copy with latest content from the source. This operation can be costly and should be triggered occasionally.
spellcheck.reload
Setting this parameter to true reloads the spell-checker and the underlying dictionary.
spellcheck.accuracy
Specifies the desired accuracy level as a float value. Suggestions with scores less than this value will not be provided.
spellcheck.alternativeTermCount
Specifies the number of suggestions to return for each query term. This can be helpful in building context-sensitive spell correction.
spellcheck.collate
If there are multiple suggestions or you want to provide the results of a spell-corrected query to the user, setting this parameter to true is a good choice. This feature takes the best suggestion for each token in the query and combines them to form a new query, which you can execute to get the suggested result.
spellcheck.maxCollations
By default, Solr returns one collation. You can set this parameter to get more collations.
spellcheck.maxCollationTries
The feature of collation ensures that the collated query finds a match in the index. This feature specifies the number of tests to attempt on the index. While testing, the original query is substituted with collation and tried for a match. The default value of 0 can skip the test and hence lead to no match. A higher value ensures better collation but would be costly.
spellcheck.maxCollationEvaluations
Specifies the maximum number of combinations to evaluate and rank, for forming the collation to test on the index. The default value has been optimally set to 10,000 combinations.
spellcheck.collateExtendedResult
Setting this parameter to true extends the response to contain details of the collation.
spellcheck.collateMaxCollectDocs
While testing for a collation, if the hit count is not desired, this parameter helps in achieving performance improvement. For value 0, the exact hit-count is extracted by running a test on all the documents. For a value greater than 0, an estimation is provided based on those documents.
spellcheck.collateParam.*
You can use this prefix to override the default query parameter or provide an additional query parameter to the collation test query. All the fq parameters can be overridden by specifying the overridden value in spellcheck.collateParam.fq.
spellcheck.extendedResults
This Boolean parameter specifies whether to use the extended response format containing more detailed information. The extended response format is different from the standard suggestion; for each suggestion it provides the document frequency, and for each term it provides a suggestion block containing additional information such as term frequency The default value is false.
spellcheck.onlyMorePopular
If this parameter is set to true, suggestions are returned only if the suggested token has higher document frequency than the original term. By default, this parameter is set to false.
spellcheck.maxResultsForSuggest
By default, the correctlySpelled response parameter is set to false, and the suggestion is returned only if a query term is missing in both the dictionary and index. Setting this parameter to a value greater than 0 returns a suggestion if the index has results of up to the specified number. For example, a value of 10 will return a suggestion if the response has up to 9 results, and no suggestion if there are 10 or more results.
- Query for search results with the spell-checking feature enabled.
Any request for a spelling suggestion will fetch a result only when the dictionary has been built. Hence, spellcheck.build=true should be triggered at least once before requesting a spelling suggestion. The build operation can be costly and should be triggered infrequently.
Autocomplete is a crucial feature for the user search experience. It’s a type ahead search, which completes the word or predicts the rest of words as soon as the user types in a few characters. The suggestions are refined for each additional character typed by the user. Most modern search engines support this feature.
Here are some of the key reasons for implementing autocomplete:
- The simplest reason for implementing autocomplete is to avoid spelling mistakes. If the suggestion provided is correct and the user selects it, the query will be free of spelling mistakes.
- If the prediction is correct, the user won’t need to key in the complete query. The user can choose one of the suggestions and press Enter.
- At times users knows what they want but don’t know how to express it in words. You may have experienced this when a search keyword has many common synonyms or you are seeking an answer to a question. Google autocomplete does a decent job with this, and if a suggestion pops up, you can be fairly confident that you are formulating a correct query.
- Autocomplete helps in query classification and applying filters. In e-commerce, suggestions are provided to classify products based on their primary facets. For example, the query jeans may give you suggestions such as jeans (for men) or jeans (for women), and the query apple may give you suggestions such as apple (in mobiles) or apple (in laptops).
- The feature is also used for generating recommendations based on a query. It’s again widely used in e-commerce to suggest top-selling products to the user with respect to the query. For example, as soon as you type Nikon, autocomplete will suggest top-selling products such as Nikon 3200 along with its price and probably even an image.
Autosuggestion can be of various types and can be based on various sources. The suggestion provided to the user can be a complete phrase or a specific word. Phrases can be extracted either from a Solr index or from user logs. If the search engine is being used widely and has a large user base, the phrases extracted from the log can generate more-practical suggestions. The queries from logs should go through a chain of processing, such as filtering out queries that result in no match in an index; queries with a spelling error should either be filtered out or spell-corrected; a web search engine would filter out queries on sensitive topics and objectionable content before being consumed for generating phrases. The phrases should be collapsed before suggesting so that the same or a similar phrase is not suggested multiple times.
Phrase suggestion can be combined with other approaches such as token suggestion, which can act as a fallback mechanism. When no phrase suggestion is available for the user-typed query, the system can complete the word being typed by the user.
Solr provides multiple provisions and implementations to achieve autocompletion. Each has its own benefits and limitations. The one or combination you choose depends on your requirements. Since a suggestion is provided for each key pressed by the user, whichever approach you take should not ignore performance, and suggestions should be generated fast. The implementations offered by Solr can be broadly categorized into two types of approaches:
- Traditional approach: This approach leverages the existing analyzers and components of Solr to get the feature in place.
- SuggestionComponent: A component developed specifically to support the feature of autocompletion.
Traditional Approach
The traditional approach of autosuggestion refers to the provisions introduced in Solr prior to release 3.0. In this approach, autocompletion is implemented by leveraging the features already available in Solr. All you need to do is configure it appropriately to get it to work.
In this approach, appropriate analyzers should be configured on the field depending on the type of suggestion you want to generate. For suggesting a phrase, KeywordTokenizerFactory is appropriate; and for suggesting words, StandardTokenizerFactory or WhitespaceTokenizerFactory is appropriate. You can use both, giving a higher weightage to phrase fields.
The field for generating suggestions should be analyzed to lowercase to perform a case-insensitive search. Some components (discussed in detail next) don’t support query-time analysis, and in those cases, the client program might need to convert the query to lowercase. Any other processing can be handled at index-time analysis for matching the tokens appropriately.
The following are the traditional approaches for implementing autosuggestion.
TermsComponent
TermsComponent provides direct access to terms indexed in a field and returns the count of documents containing the term. This component directly accesses the Lucene term dictionary, so retrieval is fast.
Benefits
Following are the benefits of using TermsComponent for autosuggestion:
- TermsComponent directly looks up the term dictionary and so is the fastest among all traditional approaches of autosuggestion.
- It allows you to execute a prefix as well as an infix query.
Limitations
Following are the limitations of this approach:
- TermsComponent directly looks up the term dictionary, so a filter cannot be applied to restrict the result to a subset of documents. For example, you cannot retrieve only products that are in stock.
- Another limitation due to direct lookup is that it also considers the terms that are marked for deletion.
- TermsComponent doesn’t analyze the query.
The following are the steps for configuring TermsComponent for autosuggestion:
- Define the TermsComponent in solrconfig.xml.
<searchComponent name="terms" class="solr.TermsComponent"/> - Register the component to the desired request handler.
<requestHandler name="/terms" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<bool name="distrib">true</bool>
</lst>
<arr name="components">
<str>terms</str>
</arr>
</requestHandler>Table 9-9 defines the important parameters of TermsComponent for supporting autocomplete.
Table 9-9. TermsComponent Important Request Parameters
Parameter
Description
terms
Specifying terms="true" enables TermsComponent. By default, the component is disabled.
terms.fl
Specifies the field name from which the terms should be retrieved.
terms.limit
Specifies the maximum number of terms to retrieve.
terms.prefix
Specifies the user-typed query in this parameter to retrieve all the tokens that start with it.
terms.regex
Specifies the regex pattern for retrieving the terms. It’s useful for infix autocompletion. This operation can be costlier to execute than terms.prefix but allows an infix operation. The user query will require preprocessing to form the regex before requesting the handler.
terms.regex.flag
Specifies terms.regex.flag=case_insensitive to execute case-insensitive regex.
terms.mincount
Terms with document frequency less than the value specified will not be returned in the response. This parameter can be useful in avoiding misspelled content, assuming them to have low frequency.
terms.maxcount
Terms with document frequency more than the value specified will not be returned in the response. This parameter can be useful to eliminate terms that can be prospective stopwords.
terms.sort
Specifying terms.sort=count sorts the terms with highest frequency first, and specifying terms.sort=index sorts in index order.
- No specific text analysis is required on the fieldType. You may just want to convert all tokens to lowercase for case-insensitive matching. A typical fieldType is defined as follows:
<fieldType name="autocomplete" class="solr.TextField" positionIncrementGap="100" >
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType> - Define the field for autosuggestion. The field need not be stored.
<field name="brand" type="autocomplete" indexed="true" stored="false" /> - Send a request for each character typed by the user.
Facets
Faceting can be used to implement autosuggestion. It’s beneficial for generating suggestions on fields such as category. Facets also return the count along with the term. Chapter 7 provides details on faceting.
Benefits
The following is a benefit of using FacetComponent for autosuggestion:
- It allows you to filter the suggestion to be run on a subset of documents. For example, you can retrieve only products that are in stock.
Limitations
The following are the limitations of this approach:
- Faceting is a memory-intensive process, especially if the number of unique tokens is high. Also its response time is high compared to TermsComponent.
- It doesn’t support retrieving infix terms.
- It doesn’t analyze the query.
Usage
The FacetComponent is by default available to the handler and doesn’t require it to be registered. The following are the steps to configure autosuggestion using faceting:
- Define the fieldType for text analysis of the faceted field.
<fieldType name="autocomplete" class="solr.TextField" positionIncrementGap="100" >
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType> - Define the field for autosuggestion. The field need not be stored.
<field name="autocomplete" type="autocomplete" indexed="true" stored="false" /> - Leverage the facet.prefix request parameter provided by faceting for generating a suggestion. The value supplied to this parameter is not analyzed, so as a convention always lowercase the value before supplying it to the field.
Table 9-10 describes the important parameters of FacetComponent for supporting autosuggestion.
Table 9-10. FacetComponent Parameters for Autosuggestion
Parameter | Description |
|---|---|
facet | Specifying facet=true enables the FacetComponent. |
rows | Set rows=0, as you don’t need to fetch search results from Solr. |
facet.prefix | Specifies the user query to retrieve all the suggestions that start with it. |
facet.field | Specifies the field on which faceting should be performed. |
facet.mincount | This parameter can be used to avoid misspelled content, assuming that terms with a count less than a threshold might not be of interest. |
facete.limit | This parameter limits the number of suggestions generated. |
EdgeNGram
We discussed NGram while discussing schema design in Chapter 4. EdgeNGram breaks the token into subtokens of different sizes from one of the edges. For autocomplete, only the tokens created from the front edge would be of interest.
Benefits
Following are the benefits of using EdgeNGram for autosuggestion:
- EdgeNGram is useful for generating suggestions when you need to search the whole document instead of just the spelling suggestion. A typical example in e-commerce is suggesting popular products to the user, where you also want to return the image of the product as well as its price.
- It allows you to restrict the result to a subset of documents. For example, you can retrieve only the in-stock products.
- Documents can be boosted—for example, if you want popular matching documents to rank higher in the suggestion list.
- Query-time analysis can be performed.
Limitations
Following are the limitations of this approach:
- This approach generates many tokens, increasing the index size.
- EdgeNGram can have performance issues and slow type-ahead defies the purpose of autocompletion.
- The search query is executed on the EdgeNGram field, and the response can contain duplicate tokens. Thus multiple documents should not have the same value for the suggestion field. If you cannot remove the redundant documents, you need to use a hybrid approach of EdgeNGram with faceting. EdgeNGram can be beneficial when you have a separate index created out of a user query log for generating suggestions.
Usage
Here are the steps to configure autosuggestion using EdgeNGram:
- Define a fieldType to use EdgeNGram.
<fieldType name="edgengram" class="solr.TextField" positionIncrementGap="100"
omitNorms="true" omitTermFreqAndPositions="true">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>Set the attribute minGramSize to specify the minimum characters from which suggestions should start coming up. Specify the attribute maxGramSize to specify the characters beyond which you don’t want to provide any refinement. The EdgeNGramFilterFactory should be applied only at index time.
In the preceding fieldType text analysis, you have defined EdgeNGramFilterFactory to generate grams from a minimum size of 3 to a maximum size of 15.
- Define the field for generating suggestions.
<field name="autocomplete" type="edgengram" indexed="true" stored="true" /> - Execute the query to generate suggestions.
$ curl "http://localhost:8983/solr/hellosolr/select?q=autocomplete:lapt"
Solr 3.1 introduced a dedicated component to address the problems of autosuggestion. This approach uses the suggester module of Lucene and is more powerful and flexible than the previously discussed approaches.
The two important aspects of SuggestComponent are dictionary and lookup algorithm. You need to choose the implementation for both while configuring the suggester. Both aspects are described next.
Dictionary
The dictionary specifies the source for maintaining the terms. The implementations offered by Solr use the Dictionary interface. Broadly speaking, the dictionary can be of the following two types:
- Index-based: Uses a Lucene index as the source for generating the suggestion
- File-based: Uses text files from the specified location for generating the suggestion
Following are the implementations provided by Solr.
DocumentDictionaryFactory is an index-based dictionary that uses terms, weights, and optionally payloads for generating the suggestion. The following are the additional parameters supported by this implementation.
- weightField: If you want to assign weight to the terms, specify in this parameter the fieldname that contains the weight. The default weight assigned is 0. This field should be stored.
- payloadField: If you want to assign a payload to the terms, specify in this parameter the fieldname that contains the payload. This field should be stored.
DocumentExpressionDictionaryFactory
This factory provides an implementation of DocumentValueSourceDictionary that extends the DocumentDictionary to support a weight expression instead of a numeric weight.
Following are the additional parameters supported by this implementation:
- weightExpression: You can specify an expression to compute the weight of the terms. It uses a Lucene expression module for computing the expression. The expression definition is similar to the function query expressions. For example, "((div(rating,10) + 1) + sqrt(popularity))" is a valid expression. The fields specified in the expression should be numeric. This parameter is mandatory.
- payloadField: If you want to assign a payload to the terms, specify in this parameter the fieldname that contains the payload. This field must be stored.
This is the default implementation for an index-based dictionary, which allows you to consider only the frequent terms for building the dictionary. Terms with frequency less than the threshold are discarded.
Following is the additional parameter supported by this implementation:
- threshold: This parameter specifies the threshold for the terms to be added to the dictionary. The value can be between 0 and 1, which signifies the fraction of documents in which the term should occur. This parameter is optional. If not specified, all terms are considered.
This is the only file-based dictionary implementation supported, which allows you to read suggestions from an external file. Similar to an index-based dictionary, weights and payloads are allowed, which can be specified following the term separated by a delimiter.
Following is the additional parameter supported by this implementation:
- fieldDelimiter: Specifies the delimiter for separating the terms, weights, and payloads. The default value is tab.
Here is a sample file for maintaining the suggestions.
After selecting the suitable dictionary implementation, you need to choose the lookupImpl that best fits your usecase. Lucene supports a set of algorithms (or data structures) and provides different implementations for them. All the implementing classes extend the Lookup abstract class.
The following are the broad definitions of data structures supported:
- Finite state transducer (FST): The suggester builds an automaton with all the terms, which is used to cater to all the autosuggestion requests.
- The automaton offers fast searches and has a low memory footprint, but the process of building the automaton is slowest among all the data structures supported. Also, terms cannot be appended to automata. For adding terms, it should be built from scratch. The automata can be persisted to disk as a binary blob for fast reload on Solr restart or core reload.
- Ternary search tree (TST): A ternary search tree is similar to a binary search tree, but can have up to three children. It offers a fast and flexible approach for term lookup. The tree can be updated dynamically.
- JaSpell algorithm: This algorithm, written by Bruno Martins, uses a ternary tree to provide highly sophisticated suggestions. It builds the data structure fast. It supports fuzzy lookup based on the Levenshtein distance and is more sophisticated than FST. Refer to the Jaspell website at http://jaspell.sourceforge.net/.
- The suggestions can be ordered alphabetically or on parameters such as rating, popularity, and so forth.
- Index-based: This approach uses a Lucene index for the lookup.
The following are the implementations provided by Solr for lookup. Each defines its own set of parameters to support the functionality offered.
This implementation provides lookup based on a ternary search tree. Its suggester doesn’t support a payload and doesn’t require any additional parameters to be specified.
This implementation provides automaton-based lookup and is very fast. It makes a good suggester unless you need a more sophisticated one. Table 9-11 specifies the parameters supported by FSTLookupFactory.
Table 9-11. FSTLookupFactory Parameters
Parameter | Description |
|---|---|
weightBuckets | Specifies the number of buckets to create for weights. The count can be between 1 and 255. The default number of buckets is 10. |
exactMatchFirst | If set to true, exact suggestions are returned first, irrespective of prefixes of other strings being available in the automaton. |
This implementation is based on a weighted FST algorithm. It uses the shortest path method to find top suggestions. It supports the exactMatchFirst parameter. Table 9-11 provides information on this parameter.
This implementation is based on the JaSpell algorithm. It’s fast at execution and is useful for a broad range of problems.
This implementation uses weighted FST for lookup. It’s called AnalyzingLookupFactory because it analyzes the text before building the FST and during lookup. The analysis prior to the lookup offers powerful and flexible autosuggestion. The analysis chain can be configured to use features such as stopwords and synonym expansion. For example, if cell phone and mobile phone are defined as synonyms, the user text cell can provide suggestions such as mobile phone cases.
The analyzers should be configured carefully, as features like stopwords can lead to no suggestion. Also, the suggestions returned are the original text and not the analyzed form of the text. Table 9-12 specifies the parameters supported by AnalyzingLookupFactory.
Table 9-12. AnalyzingLookupFactory Parameters
Property | Description |
|---|---|
suggestAnalyzerFieldType | Specifies the fieldType to use for the analysis. |
exactMatchFirst | If set to true, exact matches are returned as top suggestions, irrespective of other suggestions with higher weights. By default, it’s set to true. |
preserveSep | If set to true, a token separator is preserved (that is, cellphone and cell phone are different). By default, it’s set to true. |
preservePositionIncrements | If set to true, position increments are preserved. If set to false, a user query such as best 20 would generate suggestions like best of 2015, assuming that of is a stopword. By default, it’s set to false’. |
FuzzyLookupFactory extends the features of AnalyzingLookup, by allowing fuzzy matching on the analyzed text based on the Levenshtein distance. It supports all the parameters of AnalyzingLookupFactory, along with the additional parameters mentioned in Table 9-13.
Table 9-13. FuzzyLookupFactory Parameters
Property | Description |
|---|---|
maxEdits | Specifies the maximum number of edits allowed. The default value is 1. A hard limit on the value has been specified as 2. |
transpositions | If true, transposition will be computed using a primitive edit operation. If false, the Levenshtein algorithm will be used. |
nonFuzzyPrefix | Specifies the length of a lookup key, the characters at a position beyond which fuzzy matching will be performed. Only matches that contain the initial prefix characters of the key should be suggested. The default value is 1. |
minFuzzyLength | Specifies the length below which the edit will not be performed on the lookup key. The default value is 3. |
unicodeAware | By default, this parameter is set to false, and the preceding four parameters are measured in bytes. If this parameter is set to true, they will be measured in actual characters. |
AnalyzingInfixLookupFactory uses a Lucene index for its dictionary and offers flexible prefix-based suggestions on indexed terms. Similar to AnalyzingLookupFactory, it also analyzes the input text while building the dictionary and for lookup. Table 9-14 specifies the parameters supported by AnalyzingInfixLookupFactory.
Table 9-14. AnalyzingInfixLookupFactory Parameters
Parameter | Definition |
|---|---|
indexPath | Specifies the directory where the index will be stored and loaded from. By default, the index is created in the data directory. |
allTermsRequired | If true, applies the Boolean operator AND on a multiterm key; otherwise, it applies the operator OR. The default value is true. |
minPrefixChars | Specifies the minimum number of characters from which onward the prefixQuery is used. N-grams are generated for prefixes shorter than this length, which offers faster lookup but increases the index size. The default value is 4. |
highlight | If true, which is the default value, suggestions are highlighted. |
This implementation is an extension of AnalyzingInfixLookupFactory, which allows you to apply weights on prefix matches. It allows you to assign more weight based on the position of the first matching word. It supports all the parameters of AnalyzingInfixLookupFactory, along with the additional parameters mentioned in Table 9-15.
Table 9-15. BlendedInfixLookupFactory Parameters
Parameter | Description |
|---|---|
blenderType | Specifies the blender type to use for calculating the weight coefficient. Following are the supported blender types: • linear: Computes the weight using the formula weight×(1 - 0.10×position). It gives higher weight to matches in the start. This is the default blenderType. • reciprocal: Computes the weight using the formula weight/(1+position). It gives higher weight to matches in the end. |
numFactors | Specifies the multiplication factor for the number of results. The default value is 10. |
This suggester has been implemented with the need for fallback suggestions when other suggesters don’t find a match. It builds N-grams of the text at the time of building the dictionary and at lookup considers the last N words from the user query. It’s suitable for handling queries that have never been seen before. Table 9-16 specifies the parameters supported by FreeTextLookupFactory.
Table 9-16. FreeTextLookupFactory Parameters
Parameter | Description |
|---|---|
suggestFreeTextAnalyzerFieldType | Specifies the fieldType to use for the analysis. This field is required. |
ngrams | Specifies the number of last tokens to consider for building the dictionary. The default value is 2. |
The autosuggestion feature in Solr is provided by SuggestComponent, which interacts with SolrSuggester to generate suggestions. The following are the steps followed by the component:
- The client makes a request to a SearchHandler, which has SuggestComponent registered to it.
- The SuggestComponent, like any other SearchComponent, executes in two phases, namely prepare and process.
- If the received request is to build or reload the dictionary, in the prepare phase the component calls the SolrSuggester to perform the task. SolrSuggester is responsible for loading the lookup and dictionary implementations specified in the configuration.
- In the process phase, the component calls all the registered SolrSuggesters for getting the suggested results.
- SolrSuggestor calls the appropriate implementation, which looks up a key and returns the possible completion for this key. Depending on the implementation, this may be a prefix, misspelling, or even infix.
- The component converts the suggested results to an appropriate form and adds to the response.
Here are the steps for configuring and using SuggestComponent in Solr:
- Define the SuggestComponent in solrconfig.xml. Table 9-17 specifies the parameters supported by the component.
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">analyzedSuggestion</str>
<str name="lookupImpl">AnalyzingLookupFactory</str>
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">brand</str>
<str name="weightField">popularity</str>
<str name="suggestAnalyzerFieldType">string</str>
<str name="buildOnStartup">false</str>
</lst>
</searchComponent>Table 9-17. SuggestComponent Parameters
Parameter
Description
name
Specifies the name of the suggester for generating suggestions.
dictionaryImpl
Specifies the dictionary implementation to use. By default, HighFrequencyDictionaryFactory is used for index-based, and FileDictionaryFactory is used for a file-based data structure. If the sourceLocation parameter is present, the component assumes a file-based dictionary to be used.
lookupImpl
Specifies the lookup implementation to use. If this parameter is not provided, by default JaspellLookupFactory will be used.
field
For an index-based dictionary, this parameter specifies the field to be used by the lookup implementation.
sourceLocation
If using FileDictionaryFactory, this parameter specifies the dictionary file path.
storeDir
The directory to which the dictionary will be persisted.
buildOnStartup
Setting this Boolean parameter to true builds the data structure on Solr startup and core reload.
buildOnCommit
Setting this Boolean parameter to true builds the data structure on commit.
buildOnOptimize
Setting this Boolean parameter to true builds the data structure on optimize.
- Register the component to the desired SearchHandler. Generally, if you like to have a dedicated endpoint for autosuggestion, add it to components instead of last-components. Table 9-18 specifies the parameters that can be configured in the handler or provided in the search request.
<requestHandler name="/suggest" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="suggest">true</str>
<str name="suggest.count">10</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>Table 9-18. SuggestComponent Parameters for the Request Handler
Parameter
Description
suggest
Setting this Boolean parameter to true enables the SuggestComponent.
suggest.q
The user query for which the suggestion should be retrieved. If this parameter is not specified, the component looks for a value in the q parameter.
suggest.dictionary
This parameter is mandatory. It specifies the name of the suggester component to use for generating suggestions.
suggest.count
Specifies the maximum number of suggestions to retrieve.
suggest.build
Setting this parameter to true builds the suggester data structure. The build operation can be costly, so trigger the process as per your need. Table 9-17 provides other options for building the suggester.
suggest.buildAll
Setting this parameter to true builds the data structure for all the suggesters registered in the component.
suggest.reload
Setting this parameter to true reloads the suggester data structure.
suggest.reloadAll
Setting this parameter to true reloads the data structure for all the suggesters registered in the component.
- Define the fieldType for text analysis.
<fieldType class="solr.TextField" name="textSuggest"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType> - Define the field. The field must be set as stored. You might want to copy all the fields on which the suggestion should be generated to this field.
- Query for results. If you are using a dedicated handler for suggestions, you can set suggest=true and other infrequently changing parameters in it, so that you don’t need to provide those parameters with each request. The following are the sample queries for generating suggestions.
The primary purpose of developing a search engine is to retrieve documents that are most relevant to the user query. Once the user previews a retrieved document, it’s highly probable that he might be interested in other similar documents. If the application is being developed for searching news, journals, and blogs, suggesting similar documents becomes even more crucial. Another area where you may be interested in finding similar documents is duplicate detection, plagiarism, and fingerprinting.
Solr provides the MoreLikeThis feature to address the problem of finding similar documents. This feature can also be used for building a content-based recommendation system, which is basically a machine-learning problem. The content-based recommendation systems use the items features or keywords to describe the items, which you already have available in Solr fields. Now, if you maintain a user profile or extract common attributes of the products from the user’s purchase history and “likes,” you can query MoreLikeThis with these common keywords or attributes to generate recommendation for the users.
MoreLikeThis takes the bag-of-words approach for similarity detection. It takes a document or arbitrary text as input and returns matching documents. It allows you to control the matching capabilities through configuration definition and request parameters.
Similar document detection in MoreLikeThis is a two-phase process. The following are the details of processing in the phases:
- Detect interesting keywords: The algorithm statistically determines the important and interesting terms in the document for which similar documents are to be retrieved. It optionally ignores the terms that are very common, very rare, very short, or very long. If boost is enabled, they are added to the terms based on TF-IDF coefficient.
- Query for matching documents: The terms qualified in the first phase are submitted as a search request, and the most relevant documents are retrieved.
Prerequisites
The following are the prerequisites for using the MoreLikeThis component:
- The uniqueKey field should be stored.
- Fields used in this component should store term vectors (termVectors="true"). The following is a sample field definition:
<field name="product" type="text_general" indexed="true" stored="true" termVectors="true" />
- If term vectors are disabled, the component generates terms from the stored field. Hence, at least the field should be stored (stored="true").
![]() Caution MoreLikeThis supports distributed search but has an open bug https://issues.apache.org/jira/browse/SOLR-4414. The shard serving the request should contain the document; otherwise, MoreLikeThis doesn’t find any matches.
Caution MoreLikeThis supports distributed search but has an open bug https://issues.apache.org/jira/browse/SOLR-4414. The shard serving the request should contain the document; otherwise, MoreLikeThis doesn’t find any matches.
Implementations
MoreLikeThis has three implementations in Solr to address different user requirements. The implementations are listed here:
- MoreLikeThisComponent: This can be registered to the components list of any SearchHandler. It is useful if you want to retrieve documents similar to each document retrieved by the main query.
- MoreLikeThisHandler: This handler allows you to provide a document or content stream and retrieve documents similar to that.
- MLTQParserPlugin: This query parser forms a MoreLikeThisQuery by using the document ID and other statistical information provided.
Generic Parameters
Table 9-19 specifies the generic parameters that are applicable for all the implementations.
Table 9-19. MoreLikeThis Generic Parameters
Parameter | Description |
|---|---|
mlt.fl | Specifies the fields in which interesting terms should be identified to determine the similarity. This parameter is not applicable for MLTQParserPlugin. |
mlt.qf | Specifies the field to be queried for determining similar documents. These fields must also be specified in the mlt.fl parameter. The field name can be followed by a carat operator (^) and respective boost. |
boost | If this parameter is set to true, the interesting terms in the query will be boosted. This parameter is not applicable for MLTQParserPlugin. |
mlt.mintf | Specifies the minimum term frequency. Terms with a count less than the specified value will be ignored from the interesting terms list. The default value is 2. |
mlt.mindf | Specifies the minimum document frequency. Terms that occur in fewer documents will be ignored. The default value is 5. |
mlt.maxdf | Specifies the maximum document frequency. Terms that occur in documents more than the value specified will be ignored. |
mlt.minwl | Specifies the minimum word length. Words of smaller length will be ignored. The default value is 0, which is programmed to have no effect. |
mlt.maxwl | Specifies the maximum word length. Words that are longer than this will be ignored. The default value is 0, which is programmed to have no effect. |
mlt.maxqt | Specifies the maximum number of terms to be used in the second phase for forming the query. The default value is 25. |
mlt.maxntp | If the term vector is disabled, this parameter specifies the maximum number of tokens to parse for each stored field. The default value is 5000. |
![]() Note Prior to Solr 5.3, MLTQParserPlugin doesn’t support these generic parameters. The parameters should not be prefixed with mlt. in MLTQParserPlugin.
Note Prior to Solr 5.3, MLTQParserPlugin doesn’t support these generic parameters. The parameters should not be prefixed with mlt. in MLTQParserPlugin.
If you configure the MoreLikeThisComponent to any handler, it returns similar documents for each document returned by the main query. The operation would be costly to execute, and it’s less likely that a user will want similar documents for all results of the main query. It can be suitable for scenarios such as fingerprinting and duplicate detection, for processing a batch of documents. Table 9-20 represents the generic parameters.
Table 9-20. MoreLikeThisComponent Specific Parameters
Parameter | Description |
|---|---|
mlt | If set to true, this Boolean parameter enables the MoreLikeThis component. By default, it’s set to false. |
mlt.count | Specifies the number of similar documents to return for each result of the main query. The default value is 5. |
Here are the steps followed by the MoreLikeThisComponent for processing requests:
- The client requests a SearchHandler that has MoreLikeThisComponent registered to it. The handler invokes the MoreLikeThisComponent.
- The MoreLikeThisComponent does no processing in the prepare phase.
- In the process phase, all the matching documents retrieved by the main query are provided to MoreLikeThisHelper for retrieving similar documents.
- This helper class creates a new Query object by extracting the interesting terms from the documents and executes it on index to retrieving similar documents. This process is followed for each document retrieved by the main query and so is costly to execute.
- The retrieved documents are added to response and returned to the client.
![]() Note If you are interested in the details of internal processing or are planning customization, you can refer to these steps; otherwise, Solr doesn’t require you to know them.
Note If you are interested in the details of internal processing or are planning customization, you can refer to these steps; otherwise, Solr doesn’t require you to know them.
MoreLikeThisComponent is among the default components for all SearchHandlers, so it doesn’t need to be registered. Here is a sample query:
$ curl ’http://localhost:8983/solr/hellosolr/select?q=apple
&mlt=true&mlt.fl=product&mlt.mindf=5&mlt.mintf=3&fl=product’
MoreLikeThisHandler is a dedicated handler provided by Solr for finding similar documents. Unlike MoreLikeThisComponent, the handler will return documents similar to the document specified in the request. This is the preferred approach of using MoreLikeThis and can be invoked when the user previews a document. You can find similar documents by providing a query or a ContentStream. This handler supports common parameters such as fq, defType, and facets. Along with the generic MoreLikeThis parameters, Table 9-21 mentions the additional parameter supported by the MoreLikeThisHandler.
Table 9-21. MoreLikeThisHandlerSpecific Parameters
Parameter | Description |
|---|---|
mlt.match.include | This Boolean parameter specifies whether the matching document should be included in the response. The default value is true. It applies only when using a query for finding similar documents. |
mlt.match.offset | Specifies the offset of the document returned in response to the main query, for which similar documents should be retrieved. It applies only when using a query for finding similar documents. |
mlt.interestingTerms | Specifies how the interesting terms should be returned in the response. Solr supports three styles for interesting terms: • none: Disables the feature. This is the default value. • list: Shows the terms as a list • details: Show the terms along with its boosts. |
How It Works
Here are the steps followed by MoreLikeThisHandler for processing requests:
- MoreLikeThisHandler accepts either a content stream or a query.
- If a query is provided, the handler parses it by using a defined query parser and forms a Solr Query object. If a content stream is provided, it creates a Reader object.
- Solr runs the query, if applicable, on the index and retrieves matching document IDs but considers only the first retrieved document for MoreLikeThis matching.
- The document ID or the reader is provided to MoreLikeThisHelper for retrieving similar documents.
- This helper class creates a new Query object by extracting the interesting terms from the document or content stream and executes it on index to retrieve the matching documents.
- The retrieved documents are added to the response, as well as the interesting terms and facets if specified.
- The generated response is returned to the client.
![]() Note If you are interested in the details of internal processing or are planning customization, you can refer to these steps; otherwise, Solr doesn’t require you to know them.
Note If you are interested in the details of internal processing or are planning customization, you can refer to these steps; otherwise, Solr doesn’t require you to know them.
It’s easy to use the MoreLikeThis handler. Here are the steps:
- Define MoreLikeThisHandler in solrconfig.xml.
<requestHandler name="/mlt" class="solr.MoreLikeThisHandler" /> - Query for MoreLikeThis documents.
Find documents similar to document with id APL_1001
$ curl "http://localhost:8983/solr/mlt?q=id:APL_1001
&mlt.fl=product&mlt.mintf=2&mlt.mindf=5"
MLTQParserPlugin is a factory for the query parser, which allows you to retrieve documents similar to the document specified in the query. This provision allows you to enable highlighting and pagination and can be mentioned either in q, fq, or bq. The parser expects the uniqueKey of the document as a value, and the Lucene internal document ID or any arbitrary query is not supported.
Starting in Solr 5.3, this parser supports all the generic parameters except fl and boost. The parameter name should not be prefixed with mlt.
How It Works
Here are the steps followed by Solr for parsing a query using MLTQParserPlugin:
- The parser creates a query by using the document ID provided and retrieves the matching document. If document with the specified ID doesn’t exist, Solr will report an exception.
- For the retrieved document, Solr extracts the vector and term frequency of all the terms in the field list.
- Using the terms and frequency, it filters out unnecessary terms and creates a PriorityQueue.
- Finally, it creates MoreLikeThisQuery from terms in PriorityQueue.
![]() Note If you are interested in the details of internal processing or are planning customization, you can refer to these steps; otherwise, Solr doesn’t require you to know them.
Note If you are interested in the details of internal processing or are planning customization, you can refer to these steps; otherwise, Solr doesn’t require you to know them.
MLTQParserPlugin doesn’t require any definition in solrconfig.xml. The value of the UniqueKey field should be provided as a document identifier. The parser can be used as follows. Specifying at least one qf field is mandatory. The following is a sample query:
$ curl "http://localhost:8983/solr/hellosolr/select?
q={!mlt qf=product mintf=2 mindf=5 maxdf=100}APL_1001"
Summary
This chapter covered the following Solr features in detail: sponsored search, spell-checking, autocompletion, and document similarity. You learned about the approaches for getting these features in place and how to tune the configuration to customize and control the behavior of results.
In the next chapter, you will learn various approaches for scaling Solr, including the SolrCloud mode. You will see what makes Solr a highly scalable and distributed search engine and how to set it up in your environment.