
![]()
Semantic Search
You have reached the last chapter of this book, and in this journey you have learned about the significant features of Solr and the nitty-gritty of using it. In previous chapters, you also learned about information retrieval concepts and relevance ranking, which are essential for understanding Solr’s internals and the how and why of scoring. This knowledge is indispensable for what you will be doing most of the time: tuning the document relevance. With all of this information, you should be able to develop an effective search engine that retrieves relevant documents for the query, ranks them appropriately, and provides other features that add to the user experience.
So far, so good, but users expect more. If you look at some of the search applications on the market, they are implementing lots of innovative capabilities and plugging in diverse frameworks and components to take the search experience to the next level. As the expectations are set high, matching beyond keywords to understand the underlying semantics and user intent is needed. Google, for example, also acts like a question-answering system. It applies enormous intelligence to understand the semantics of the query and acts accordingly. If you analyze your query logs, you will find that a considerable number of queries contain the user’s intent and not just the keywords, though that depends on the domain.
At this point, you should be able to develop a decent keyword-based search engine, but with a few limitations. When you put it all together, the system won’t understand the semantics. If your application caters to a medical domain, for example, a user query of heart attack will fail to retrieve results for cardiac arrest, which might be more interesting to the medical practitioners.
A semantic search addresses the limitations of a keyword-based search by understanding the user intent and the contextual meaning of terms. The acquired knowledge can be utilized in many ways to improve the search accuracy and relevance ranking.
Semantic search is an advanced and broad topic, and presenting its techniques of text analytics would require a dedicated book. In this chapter, you will learn about some of the techniques in their simplest forms as well as references to resources that can be utilized to explore further. This chapter covers the following topics:
- Limitations of keyword-based systems
- Introduction to semantic search
- Common tools for building the semantic capabilities
- Techniques for integrating semantic capabilities to Solr
- Identifying the part-of-speech of tokens
- Extracting named entities such as person, organization, and location from the unstructured data
- Semantic enrichment
Limitations of Keyword Systems
Keyword-based document ranking fundamentally depends upon the statistical information about the query terms. Although they are beneficial for many use cases, they often do not provide users with valuable results if the user fails to formulate an appropriate query or provides an intent query. If the user is rephrasing the same query multiple times while searching, it implicitly signifies the need for extending the search engine to support advanced text processing and semantic capabilities. Computer scientist Hans Peter Luhn describes the limitations of keyword systems:
This rather unsophisticated argument on “significance” avoids such linguistic implications as grammar and syntax....No attention is paid to the logical and semantic relationships the author has established.
The primary limitations of a keyword-based system can be categorized as follows:
- Context and intent: Keyword-based systems are not context aware and do not consider the cognitive characteristics of the documents. A query of white formal shirt indicates user intent, but a keyword system might retrieve documents that are irrelevant to user expectations. Similarly, in a music search engine, a query for top songs of this year is a pure intent query, and a keyword-based system might end up retrieving albums or titles containing these tokens, which is irrelevant to what the user is looking for.
- Significant terms: A keyword-based search engine determines the importance and significance of terms on the basis of statistical information and ignores the underlying semantics.
- Synonymy: A keyword-based engine retrieves documents containing matching tokens but ignores the terms that linguistically refer to the same thing. These ignored tokens treated as irrelevant by the system can actually be more relevant, as in the previous heart attack example.
- You may debate that synonyms.txt addresses the problem of synonyms, but that has two limitations. First, the file should be manually created and is limited to handcrafted synonyms. Second, it ignores the semantics and the fact that synonyms of a word can differ based on context.
- Polysemy: In English, words are polysemous (a word can have different meanings). The synonyms defined in synonyms.txt can go terribly wrong for such words. For example, if heart is mapped to emotion in the synonyms.txt file, the query heart attack will be expanded to emotion attack, when instead it should have ideally expanded to cardiac arrest.
- Unstructured data: Unstructured data is basically for human consumption, and an enormous amount of information is hidden inside it. The keyword-based system fails to fully utilize the knowledge available in this unstructured data.
Semantic Search
Semantic search refers to a set of techniques that interprets the intent, context, concept, meaning, and relationships between terms. The idea is to develop a system that follows a cognitive process to understand terms similar to the way we humans do. Technopedia.com provides this definition of semantic search:
Semantic search is a data searching technique in which a search query aims to not only find keywords, but to determine the intent and contextual meaning of the words a person is using for search.
The potential of leveraging semantic capabilities in your search application is unbound. The way you utilize them depends a lot on your domain, data, and search requirements. Google, for example, uses semantic capabilities for delivering answers and not just links. Figure 11-1 shows an example of the semantic capabilities of Google, which precisely understands the user intent and answers the query.
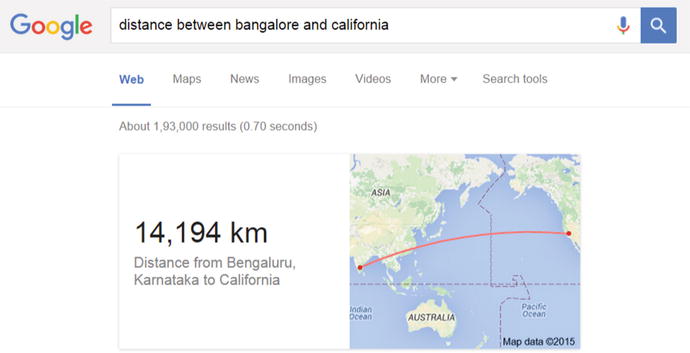
Figure 11-1. An example of the question-answering capability of Google
Historically, search engines were developed to cater to keyword-based queries, but due to their limitations, the engines also provided advanced search capabilities. This is acceptable in some verticals (for example, legal searches), but it is something that very few users find appealing. The user prefers a single box because of its ease of use and simplicity. Since the search box is open-ended (you can type whatever you want), users provide queries in natural language, using the linguistics of day-to-day life. Earlier Google had the advanced search option on its home page, but it was hidden in 2011. Google’s advanced search is now available in its home page settings and requires an extra click, or you need to go to www.google.com/advanced_search. Advanced search is where you provide details about the query terms and the fields to which they apply. It is generally preferred by librarians, lawyers, and medical practitioners.
Figure 11-2 shows an example of an intelligent search, performed by Amazon.com for the user query white formal shirt for men. The search engine finds exactly what you want by using built-in semantic capabilities.
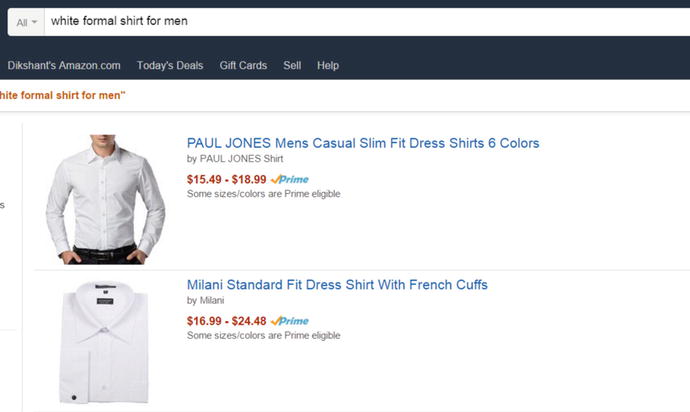
Figure 11-2. An example of query intent mining in Amazon.com
Semantic search techniques perform a deep analysis of text by using technologies such as artificial intelligence, natural language processing, and machine learning. In this chapter, you will learn about a few of them and how to integrate them into Solr.
Semantic capabilities can be integrated in Solr while indexing and searching. If you are dealing with news, articles, blogs, journals, or e-mails, the data will be either unstructured or semistructured. In such cases, you should extract metadata and actionable information from the stream of text. Since unstructured data has been created for human consumption, it can be difficult for machines to interpret, but by using text-processing capabilities such as natural language processing, useful information can be extracted.
Semantic processing broadly depends on the following:
- Knowledge base: The semantic knowledge source contains information regarding the entities or facts related to the terms and concepts. The knowledge can be available as an ontology, taxonomy, thesauri, other controlled vocabulary, trained models, or even a set of rules. The knowledge can be provided by a third-party vendor, crowd-sourced by a community, or developed in-house.
- Text processing: This refers to the processing, inference rules, and reasoning applied on the knowledge to detect the entities, establish the logical connection, or determine the context.
Tools
This section presents some of the tools and technologies that you might want to evaluate while processing text for semantic enrichment. You can extend a Solr component to plug in the tool that suits your text-processing requirements. Before proceeding further in this section, refer to the “Text Processing” section of Chapter 3 for a refresher on these concepts.
The Apache OpenNLP project provides a set of tools for processing natural language text for performing common NLP tasks such as sentence detection, tokenization, part-of-speech tagging and named-entity extraction, among others. OpenNLP provides a separate component for each of these tasks. The components can be used individually or combined to form a text-analytics pipeline. The library uses machine-learning techniques such as maximum entropy and the perceptron to train the models and build advanced text-processing capabilities. OpenNLP distributes a set of common models that perform well for general use cases. If you want to build a custom model for your specific needs, its components provide an API for training and evaluating the models.
This project is licensed under the Apache Software License and can be downloaded at https://opennlp.apache.org/. Other NLP libraries are available, such as Stanford NLP, but they are either not open source or require a GPL-like license that might not fit into the licensing requirements of many companies.
OpenNLP’s freely available models can be downloaded from http://opennlp.sourceforge.net/models-1.5/.
OpenNLP integration is not yet committed in Solr and is not available as an out-of-the-box feature. Refer to the Solr wiki at https://wiki.apache.org/solr/OpenNLP for more details. Later in this chapter, you will see examples of integrating OpenNLP with Solr.
![]() Note Refer to JIRA https://issues.apache.org/jira/browse/LUCENE-2899 for more details on integration.
Note Refer to JIRA https://issues.apache.org/jira/browse/LUCENE-2899 for more details on integration.
As you know, UIMA stands for Unstructured Information Management Architecture, an Apache project that allows you to develop interoperable, complex components and combine them to run together. This framework allows you to develop an analysis engine, which can be used to extract metadata and information from unstructured text.
The analysis engine allows you to develop a pipeline, which you can use to chain the annotators. Each annotator represents an independent component or feature. The annotators can consume and produce an annotation, and the output of one annotation can be input to the next in the chain. The chain can be formed by using XML configuration.
UIMA’s pluggable architecture, reusable components, and configurable pipeline allow you to throw away the monolithic structure and design a multistage process in which different modules need to build on each other to get a powerful analysis chain. This also allows you to scale out and run the components asynchronously. You might find the framework a bit complex; it has a learning curve.
Annotations from different vendors are available for consumption that can be added to the pipeline. Vendors such as Open Calias and AlchemyAPI provide a variety of annotations for text processing but require licenses.
Solr integration for UIMA is available as a contrib module, and Solr enrichments can be done with just a few configuration changes. Refer to the Solr official documentation at https://cwiki.apache.org/confluence/display/solr/UIMA+Integration for UIMA integration.
Apache Stanbol is an OSGi-based framework that provides a set of reusable components for reasoning and content enhancement. The additional benefit it offers is built-in CMS capabilities and provisions to persist semantic information such as entities and facts and define knowledge models.
No Solr plug-in is available, and none is required for this framework as Stanbol internally uses Solr as document repository. It also uses Apache OpenNLP for natural language processing and Apache Clerezza and Apache Jena as RDF and storage frameworks. Stanbol offers a GUI for managing the chains and offers additional features such as a web server and security features.
You might want to evaluate this framework if you are developing a system with semantic capabilities from scratch, as it offers you the complete suite.
Techniques Applied
Semantic search has been an active area of research for quite some time and is still not a solved problem, but lots of advancement has happened in the area. A typical example is IBM’s Watson; this intelligent system, capable of answering questions in a natural language, won the Jeopardy challenge in 2011. Building a semantic capability can be a fairly complex task, depending on what you want to achieve. But you can employ simple techniques to improve result quality, and sometimes a little semantics can take you a long way.
Figure 11-3 provides an overview of how semantic techniques can be combined with different knowledge bases to process input text and build the intelligence. The information gained from these knowledge bases can be used for expanding terms, indicating relationships among concepts, introducing facts, and extracting metadata from the input text. Chapter 3 provides an overview of these knowledge bases. In this section, you will see how to utilize this knowledge to perform a smart search.
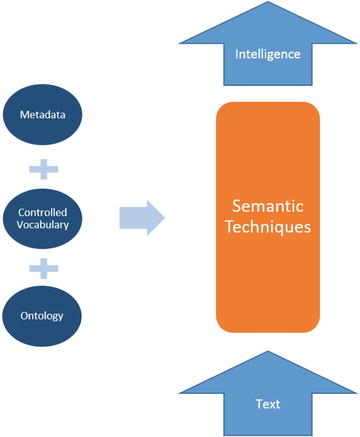
Figure 11-3. Semantic techniques
Earlier in this book, you learned that Solr ranks a document by using a model such as the vector space model. This model considers a document as a bag of words. For a user query, it retrieves documents based on factors such as term frequency and inverse document frequency, but it doesn’t understand the relationships between terms. Semantic techniques such as these can be applied in Solr to retrieve more relevant results:
- Query parsing: Semantic techniques can be applied on the query for mining the user intent. Based on the domain, you can mine the user intent by developing a text classification system or other techniques. The feature can be plugged into Solr by writing a custom query parser. Based on the understanding of the intent, the parser can either reformulate the query or expand the query terms with synonyms and other related concepts. Reformulation can be a difficult task and should be performed with care.
- Text analysis: The tokens can be enriched with semantically related words while performing text analysis, similar to the way you do it using a synonym filter factory. You can plug in the enrichment by writing a custom token filter that can be applied either while indexing the fields of the documents or while querying for a result. A sample implementation for expanding the synonyms automatically is presented later in this chapter.
- Query reranking: Intent mining can even be applied by writing a custom reranking query, which you learned about in Chapter 7, for changing the order of retrieved documents. Query reranking will not introduce a totally new document, as in the case of a custom query parser.
- Indexing documents: Structured content is more valuable than unstructured content. If you are indexing unstructured data, such as the text of a book or journal, you should structure it. You can apply several techniques to extract the entities and hidden facts from such content and automatically generate metadata. Fields containing these extracted entities can be boosted based on its significance, can be used for generating facets and controlling the manner in which results can be represented. Later in this chapter, you will learn to write a custom update request processor for automatically extracting metadata from unstructured content.
- Ranking model: The ranking model used for scoring documents can be tuned to consider the semantic relationship of terms, but that would not be a trivial task. I suggest you consider other approaches that can contribute to the document ranking, by using an existing model such as by applying boosts or payloads.
Figure 11-4 depicts how semantic capabilities can be applied to Solr for improving relevancy.
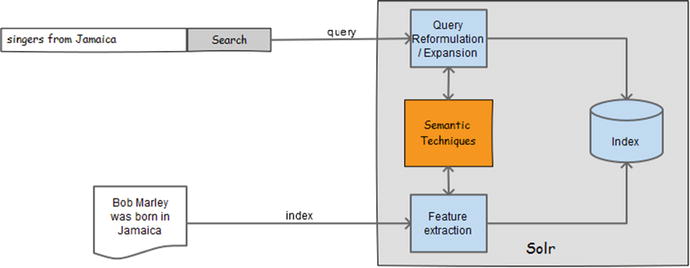
Figure 11-4. Application of semantic techniques in Solr
Next you will look at various natural language processing and semantic techniques that can be integrated in Solr for improving the precision of results.
Each word in a sentence can be classified into a lexical category, also called a part of speech. Common parts of speech include noun, verb, and adjective. These can be further classified—for instance, a noun can be categorized as a common noun or proper noun. This categorization and subcategorization information can be used to discover the significance of terms in context and can even be used to extract lots of interesting information about the words. I suggest that you get a fair understanding of parts of speech, as it may help you decipher the importance and purpose of words. For example, nouns are used to identify people, places, and things (for example, shirt or Joe), and adjectives define the attributes of a noun (such as red or intelligent). Similarly, the subclass, such as common noun, describes a class of entities (such as country or animal), and a proper noun describes the instances (such as America or Joe). Figure 11-5 provides sample text and its parts of speech. In Figure 11-5, the tags NNP, VBD, VBN and IN refer to proper noun (singular), verb (past tense), verb (past participle) and conjunction (preposition or subordinating) respectively.

Figure 11-5. Part-of-speech tagging
With an understanding of parts of speech, you can clearly make out that not all words are equally important. If your system can tag parts of speech, this knowledge can be used to control the document ranking based on the significance of the tokens in the context. Currently, while indexing documents, you boost either a document or a field, but ignore the fact that each of the terms may also need a different boost. In a sentence, generally the nouns and verbs are more important; you can extract those terms and index them to separate fields. This gives you a field with a smaller and more focused set of terms, which can be assigned a higher boost while querying. Solr features such as MoreLikeThis would work better on this field with more significant tokens. You can even apply a payload to them while indexing.
The part-of-speech tagging can be a necessary feature and a prerequisite for many types of advanced analysis. The semantic enrichment example, which you will see later in this chapter, requires POS tagged words, as the meaning and definition of a word may vary based on its part of speech. A POS tagger uses tags from the Penn Treebank Project to label words in sentences with their parts of speech.
In this section, you will learn to extract important parts of speech from a document being indexed and populate the extracted terms to a separate Solr field. This process requires two primary steps:
- Extract the part of speech from the text. In the provided sample, you’ll use OpenNLP and the trained models freely available on its web site. The model can be downloaded from http://opennlp.sourceforge.net/models-1.5/.
- Write a custom update request processor, which will create a new field and add the extracted terms to it.
The steps to be followed for adding the desired part of speech to a separate Solr field are provided next in detail.
- Write a Java class to tag the part of speech by using OpenNLP. The steps for part of-speech tagging in OpenNLP are provided next. These steps doesn’t relate to Solr but is called by the plugin for getting the POS.
- Read the trained model using FileInputStream and instantiate the POSModel with it. The path of model is passed to the InputStream during instantiation. OpenNLP prebundles two POS models for English and a few other languages. You can use en-pos-maxent.bin, a model which is based on maximum entropy framework. You can read more details about maximum entropy at http://maxent.sourceforge.net/about.html.
InputStream modelIn = new FileInputStream(fileName);
POSModel model = new POSModel(modelIn); - Instantiate the POSTaggerME class by providing the POSModel instance to its constructor.
POSTaggerME tagger = new POSTaggerME(model); - POSTaggerME as a prerequisite requires the sentence to be tokenized, which can be done using OpenNLP tokenization. If this code had been part of an analysis chain, the sentence could be tokenized using Solr provided tokenizer. The simplest form of tokenization can even be built using Java String’s split() method, also used in this example, though it’s prone to creating invalid tokens.
String [] tokens = query.split(" "); - Pass the tokenized sentence to the POSTaggerME instance, which returns a string array containing all the tagged parts of speech.
String [] tags = tagger.tag(tokens); - Iterate over the array to map the tags to the corresponding tokens. You have populated the extracted tags to the PartOfSpeech bean that holds the token and its corresponding part of speech.
int i = 0;
List<PartOfSpeech> posList = new ArrayList<>();
for(String token : tokens) {
PartOfSpeech pos = new PartOfSpeech();
pos.setToken(token);
pos.setPos(tags[i]);
posList.add(pos);
i++;
}
- Read the trained model using FileInputStream and instantiate the POSModel with it. The path of model is passed to the InputStream during instantiation. OpenNLP prebundles two POS models for English and a few other languages. You can use en-pos-maxent.bin, a model which is based on maximum entropy framework. You can read more details about maximum entropy at http://maxent.sourceforge.net/about.html.
- Write a custom implementation of UpdateRequestProcessor and its factory method. Follow the next steps to add the terms with specified parts of speech to a separate field. (Refer to Chapter 5 if you want to refresh your memory about writing a custom update request processor.)
- Read the parameters from NamedList in the init() method of POSUpdateProcessorFactory, the custom factory, to populate the instance variables for controlling the tagging behavior. Also, set up the POS tagger that can be used for extraction, as mentioned in step 1.
private String modelFile;
private String src;
private String dest;
private float boost;
private List<String> allowedPOS;
private PartOfSpeechTagger tagger;
public void init(NamedList args) {
super.init(args);
SolrParams param = SolrParams.toSolrParams(args);
modelFile = param.get("modelFile"); src = param.get("src");
dest = param.get("dest"); boost = param.getFloat("boost", 1.0f);
String posStr = param.get("pos","nnp,nn,nns");
if (null != posStr) {
allowedPOS = Arrays.asList(posStr.split(",")); }
tagger = new PartOfSpeechTagger();
tagger.setup(modelFile);
}; - In the processAdd() method of POSUpdateProcessor, a custom update request processor, read the field value of the document being indexed and provide it to the tagger object for tagging the parts of speech. Create a new field and add the important tag to it.
@Override
public void processAdd(AddUpdateCommand cmd) throws IOException {
SolrInputDocument doc = cmd.getSolrInputDocument();
Object obj = doc.getFieldValue(src);
StringBuilder tokens = new StringBuilder();
if (null != obj && obj instanceof String) {
List<PartOfSpeech> posList = tagger.tag((String) obj);
for(PartOfSpeech pos : posList) {
if (allowedPOS.contains(pos.getPos().toLowerCase())) {
tokens.append(pos.getToken()).append(" ");
}
}
doc.addField(dest, tokens.toString(), boost);
}
// pass it up the chain
super.processAdd(cmd);
}
- Read the parameters from NamedList in the init() method of POSUpdateProcessorFactory, the custom factory, to populate the instance variables for controlling the tagging behavior. Also, set up the POS tagger that can be used for extraction, as mentioned in step 1.
- Add the dependencies to the Solr core library.
<lib dir="dir-containing-the-jar" regex=" solr-practical-approach-d.*.jar" /> - Define the preceding custom processor in solrconfig.xml. In the parameters, you need to specify the path of the model, the source field, the destination field, the parts of speech to be extracted, and the boost to be provided to the destination field.
<updateRequestProcessorChain name="nlp">
<processor class="com.apress.solr.pa.chapter11.opennlp.POSUpdateProcessorFactory">
<str name="modelFile">path-to-en-pos-maxent.bin</str>
<str name="src">description</str>
<str name="dest">keywords</str>
<str name="pos">nnp,nn,nns</str>
<float name="boost">1.4</float>
</processor>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain> - Register the defined update chain to the /update handler.
<str name="update.chain">nlp</str> - Restart the instance and index documents. The terms with the specified part of speech will be automatically added to the keywords field, which is defined as a destination field in solrconfig.xml. The following is an example of the resultant document.
{
"id": "1201",
"description": "Bob Marley was born in Jamaica",
"keywords": "Bob Marley Jamaica "
}
Named-Entity Extraction
If your search engine needs to index unstructured content such as books, journals, or blogs, a crucial task is to extract the important information hidden in the stream of text. In this section, you will learn about different approaches to extract that information and leverage it to improve the precision and overall search experience.
Unstructured content is primarily meant for human consumption, and extracting the important entities and metadata hidden inside it requires complex processing. The entities can be generic information (for example, people, location, organization, money, or temporal information) or information specific to a domain (for example, a disease or anatomy in healthcare). The task of identifying the entities such as person, organization, and location is called named-entity recognition (NER). For example, in the text Bob Marley was born in Jamaica, NER should be able to detect Bob Marley as the person and Jamaica as the location. Figure 11-6 shows the entities extracted in this example.

Figure 11-6. Named entities extracted from content
The extracted named entities can be used in Solr in many ways, and the actual usage depends on your requirements. Some of the common uses in Solr are as follows:
- Supporting faceted navigation using the entities
- Sorting the results on the entities
- Finding out entities such as a person’s name for the autosuggestion dictionary
- Assigning different boosts to the entities, to vary their significance in the domain
- Query reformulation to search a limited set of fields based on the detected entity type.
The approaches for NER can be divided into three categories, detailed in the following subsections. The approach and its implementation depend on your requirements, use case, and the entity you are trying to extract. The first two approaches can be implemented by using the out-of-the-box features of Solr or any advanced NLP library. For the third approach, you will customize Solr to integrate OpenNLP and extract named entities. The customization or extraction can vary as per your needs.
Using Rules and Regex
Rules and regular expressions are the simplest approach for NER. You can define a set of rules and a regex pattern, which is matched against the incoming text for entity extraction. This approach works well for extraction of entities that follow a predefined pattern, as in the case of e-mail IDs, URLs, phone numbers, zip codes, and credit card numbers.
A simple regex can be integrated by using PatternReplaceCharFilterFactory or PatternReplaceTokenFilterFactory in the analysis chain. A regex for determining phone numbers can be as simple as this:
^[0-9+()#.s/ext-]+$
For extracting e-mail IDs, you can use UAX29URLEmailTokenizerFactory provided by Lucene. Refer to http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters#solr.UAX29URLEmailTokenizerFactory for details of the tokenizer. You may find it interesting that there is an official standard regex for e-mail, known as RFC 5322. Refer to http://tools.ietf.org/html/rfc5322#section-3.4 for details. It describes the syntax that valid e-mail addresses must adhere to, but it’s too complicated to implement.
If you are looking for complex regex rules, you can evaluate the Apache UIMA-provided regular expression annotator, where you can define the rule set. Refer to https://uima.apache.org/downloads/sandbox/RegexAnnotatorUserGuide/RegexAnnotatorUserGuide.html for details of the annotator. If you are using a rule engine such as Drools, you can integrate it into Solr by writing a custom update processor or filter factory.
If you want to use OpenNLP for regex-based NER, you can use RegexNameFinder and specify the pattern instead of using NameFinderME. Refer to the example in the section “Using a Trained Model”, where you can do the substitution by using RegexNameFinder.
The limitation of this NER approach is that anything unrelated that follows the specified pattern or satisfies the rule will be detected as a valid entity; for example, a poorly formatted five-digit salary could be detected as a zip code. Also, this approach is limited to entity types that follow a known pattern. It cannot be used to detect entities such as name or organization.
Using a Dictionary or Gazetteer
The dictionary-based approach, also called a gazetteer-based approach, of entity extraction maintains a list of terms for the applicable category. The input text is matched upon the gazetteer for entity extraction. This approach works well for entities that are applicable to a specific domain and have a limited set of terms. Typical examples are job titles in your organization, nationality, religion, days of week, or months of year.
You can build the list by extracting information from your local datasource or external source (such as Wikipedia). The data structure for maintaining the dictionary can be anything that fits your requirements. It can be as simple as a Java collection populated from a text file. An easier implementation for a file-based approach to populate the entities in a separate field can be to use Solr’s KeepWordFilterFactory. The following is a sample text analysis for it:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/>
</analyzer>
The list can be maintained in database tables, but a large list is likely to impair performance. A faster and performance-efficient approach is to build an automaton. You can refer to the FST data structure in the Solr suggestions module or one provided by David Smiley at https://github.com/OpenSextant/SolrTextTagger.
If you want to look up phrases along with individual terms, the incoming text can be processed by using either the OpenNLP Chunker component or ShingleFilterFactory provided by Solr. The following is the filter definition for generating shingles of different sizes. The parameter outputUnigrams="true" has been provided to match the single tokens also.
<filter class="solr.ShingleFilterFactory" maxShingleSize="3" outputUnigrams="true"/>
The benefit of this approach is that it doesn’t require training but is less popular as it’s difficult to maintain. It cannot be used for common entities such as name or organization, as the terms can be ambiguous and not limited to a defined set of values. This approach also ignores the context. For example, this approach cannot differentiate whether the text Tommy Hilfiger refers to a person or an organization.
OpenNLP offers a better approach for dictionary-based extraction by scanning for names inside the dictionary and letting you not worry about matching phrases.
Here are the steps for NER in OpenNLP using a dictionary:
- Create an XML file containing the dictionary terms.
<dictionary case_sensitive="false">
<entry ref="director">
<token>Director</token>
</entry>
<entry ref="producer">
<token>Producer</token>
</entry>
<entry ref="music director">
<token>Music</token><token>Director</token>
</entry>
<entry ref="singer">
<token>Singer</token>
</entry>
</dictionary - Create a FileInputStream and instantiate the dictionary with it.
InputStream modelIn = new FileInputStream(file);
Dictionary dictionary = new Dictionary(modelIn);Alternatively, the Dictionary object can be created using a no-arg constructor and tokens added to it as shown here:
Dictionary dictionary = new Dictionary();
dictionary.put(new StringList("Director"));
dictionary.put(new StringList("Producer"));
dictionary.put(new StringList("Music", "Director"));
dictionary.put(new StringList("Singer")); - Create the DictionaryNameFinder instance by using the Dictionary and assigning a name to it.
DictionaryNameFinder dnf = new DictionaryNameFinder(dictionary, "JobTitles");
Refer to the implementation steps in the following “Using a Trained Model” section, as the rest of the steps remain the same.
You can use a hybrid of a rules- and gazetteer-based approach if you feel that it can improve precision.
Using a Trained Model
The approach of using trained models for NER falls under the supervised learning category of machine learning: human intervention is required to train the model, but after the model is trained, it returns a nearly accurate result.
This approach uses a statistical model for extracting entities. It is preferred for extracting entities that are not limited to a set of values, such as in case of name or organization. This approach can find entities that are not defined or tagged in the model. This model considers the semantics and context of the text and easily resolves the ambiguity between entities, as in the case of person name and organization name. These problems cannot be addressed using the earlier approach; the trained model is the only way to go. It doesn’t require creating large dictionaries that are difficult to maintain.
Solr Plug-in for Entity Extraction
In this section, you will learn to extract the named entities from documents being indexed and populate the extracted terms to a separate Solr field. This process requires two primary steps:
- Extract the named entities from the text. In the provided sample, you’ll use OpenNLP and the trained models freely available on its web site. The model can be downloaded from http://opennlp.sourceforge.net/models-1.5/.
- Write a custom update request processor, that will create a new field and add the extracted entities to it.
Here are the detailed steps to be followed for adding the extracted named entities to a separate field:
- Write a Java class to extract the named entities by using OpenNLP. Here are the steps for extraction:
- Read the trained model by using FileInputStream and instantiate the TokenNameFinderModel with it. OpenNLP requires a separate model for each entity type. To support multiple entities, a separate model should be loaded for each entity.
InputStream modelIn = new FileInputStream(fileName);TokenNameFinderModel model = new TokenNameFinderModel(modelIn);
- Instantiate the NameFinderME class by providing the model to its constructor. A separate instance of NameFinderME should be created for each entity type.
NameFinderME nameFinder = new NameFinderME(model); - NameFinderME as a prerequisite requires the sentence to be tokenized, which can be done using the OpenNLP tokenization component. If this code is part of the analysis chain, the sentence can be tokenized by using the Solr-provided tokenizer. The simplest form of tokenization can even be using Java String’s split() method, also used in this example, though it’s prone to creating invalid tokens.
String [] sentence = query.split(" "); - Pass the tokenized sentence to the NameFinderMe instance, which returns the extracted named entity.
Span[] spans = nameFinder.find(sentence); - Iterate the Span array to extract the named entities. We have populated the extracted entities to the NamedEntity bean that holds the entity and its corresponding entity type.
List<NamedEntity> neList = new ArrayList<>();
for (Span span : spans) {
NamedEntity entity = new NamedEntity();
StringBuilder match = new StringBuilder();
for (int i = span.getStart(); i < span.getEnd(); i++) {
match.append(sentence[i]).append(" ");
}
entity.setToken(match.toString().trim.()); entity.setEntity(entityName);
neList.add(entity);
} - After processing the sentences of a document, call clearAdaptiveData() to clear the cache, which is maintained by OpenNLP to track previous entity extraction of a word.
nameFinder.clearAdaptiveData();
- Read the trained model by using FileInputStream and instantiate the TokenNameFinderModel with it. OpenNLP requires a separate model for each entity type. To support multiple entities, a separate model should be loaded for each entity.
- Write a custom implementation of UpdateRequestProcessor and its factory method. The following are the steps to be followed for adding the extracted entities to a separate field. (Refer to Chapter 5, if you want to refresh your memory about writing a custom update request processor.)
- Read the parameters from NamedList in the init() method of NERUpdateProcessorFactory, the custom factory, to populate the instance variables for controlling the extraction behavior. Also, set up the NamedEntityTagger that can be used for extraction as mentioned in step 1.
private String modelFile;
private String src;
private String dest;
private String entity;
private float boost;
private NamedEntityTagger tagger;
public void init(NamedList args) {
super.init(args);
SolrParams param = SolrParams.toSolrParams(args);
modelFile = param.get("modelFile");
src = param.get("src");
dest = param.get("dest");
entity = param.get("entity","person");
boost = param.getFloat("boost", 1.0f);
tagger = new NamedEntityTagger();
tagger.setup(modelFile, entity);
}; - In the processAdd() method of NERUpdateProcessor, a custom update request processor, read the field value of the document being indexed and provide it to the NER object for extracting the entities. Create a new field and add the extracted entities to it.
@Override
public void processAdd(AddUpdateCommand cmd) throws IOException {
SolrInputDocument doc = cmd.getSolrInputDocument();
Object obj = doc.getFieldValue(src); if (null != obj && obj instanceof String) {
List<NamedEntity> neList = tagger.tag((String) obj);
for(NamedEntity ne : neList) {
doc.addField(dest, ne.getToken(), boost);
}
} super.processAdd(cmd);
}
- Read the parameters from NamedList in the init() method of NERUpdateProcessorFactory, the custom factory, to populate the instance variables for controlling the extraction behavior. Also, set up the NamedEntityTagger that can be used for extraction as mentioned in step 1.
- Add the dependencies to the Solr core library.
<lib dir="dir-containing-the-jar" regex=" solr-practical-approach-d.*.jar" /> - Define this custom processor in solrconfig.xml. In the parameters, you need to specify the path of the model, the source field, the destination field, the entity to be extracted, and the boost to be provided to the destination field. The destination field should be multivalued, as multiple entities can be extracted from the text.
<updateRequestProcessorChain name="nlp">
<processor class="com.apress.solr.pa.chapter11.opennlp.NERUpdateProcessorFactory">
<str name="modelFile">path-to-en-ner-person.bin</str>
<str name="src">description</str>
<str name="dest">ext_person</str>
<str name="entity">person</str>
<float name="boost">1.8</float>
</processor>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain> - Register the defined update chain to the /update handler.
<str name="update.chain">nlp</str> - Restart the instance and index documents. The extracted entities will be automatically added to the destination field. The following is an example of a resultant document.
{
"id": "1201",
"description": "Bob Marley and Ricky were born in Jamaica",
"ext_person": [
"Bob Marley ",
"Ricky "
]
}
This source code extracts only one type of entity. In real-life scenarios, you may want to extract multiple entities and populate them to different fields. You can extend this update request processor to accommodate the required capabilities by loading multiple models and adding the extracted terms to separate fields.
OpenNLP uses a separate model for each entity type. In contrast, Stanford NLP, another NLP package, uses the same model for all entities.
This approach of entity extraction is supposed to return accurate results, but the output also depends on tagging quality and the data on which the model is trained (remember, garbage in, garbage out). Also, the model-based approach can be costly in terms of memory requirements and processing speed.
Semantic Enrichment
In Chapter 4, you learned to use SynonymFilterFactory to generate synonyms for expanding the tokens. The primary limitation of this approach is that it doesn’t consider semantics. A word can be polysemous (have multiple meanings), and synonyms can vary based on their part of speech or the context. For example, a typical generic synonym.txt file can have the word large specified as a synonym for big, and this would expand the query big brother as large brother, which is semantically incorrect.
Instead of using a text file that defines the list of terms and its synonyms, more sophisticated approaches can be applied using controlled vocabularies such as WordNet or Medical Subject Headings (MeSH), which require no manual definition or handcrafting. Synonym expansion is just one part of it. The vocabularies and thesauri also contain other useful information such as hypernyms, hyponyms, and meronyms, which you will learn about further. This information can be used for understanding the semantic relationship and expanding the query further.
These thesauri are generally maintained by a community or an enterprise that keeps updating the corpus with the latest words. The vocabulary can be generic or it can be specific to a particular domain. WordNet is an example of a generic thesaurus that can be incorporated into any search engine and for any domain. MeSH is a vocabulary applicable to a medical domain.
You can also perform semantic enrichment by building taxonomies and ontologies containing the concept tree applicable to your domain. The query terms can be matched against a taxonomy for extracting broader, narrower, or related concepts (such as altLabel or prefLabel) and perform the required enrichment. You can get some of these taxonomies over the Web, or you can have a taxonomist define one for you. You can also consume resource such as DBpedia that provide structured information extracted from Wikipedia as RDF triples. Wikidata is another linked database which contains structured data from Wikimedia projects including Wikipedia.
These knowledge bases can be integrated into Solr in various ways. Here are the ways to plug the desired enrichment into Solr:
- Text analysis: Write a custom token filter that expands the tokens with the synonyms or other relationships extracted from the controlled vocabulary. The implementation can be similar to the Solr-provided SynonymFilterFactory that uses a controlled vocabulary file instead of the synonyms.txt file. SynonymFilterFactory has a support for WordNet in its simplest form. You will see a custom implementation for synonym expansion later in this chapter.
- Query parser: Write a query parser for expanding the user query with its related or narrower term. For example, in an e-commerce web site for clothing, the user query men accessories can be expanded to search for belts or watches. This additional knowledge can be extracted from a taxonomy that contains accessories as a broader term, and belts and watches as its narrower terms. Figure 11-7 specifies the relationship between the broader and narrower concepts. Instead of just expanding the query, you can extend the system to reformulate the query to build a new query.
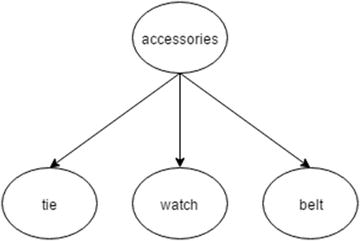
Figure 11-7. Concept tree
In this section, you will learn how to automatically expand terms to include their synonyms. This process requires implementing the following two tasks:
- Knowledge extraction: The first step is to extract the synonyms from the controlled vocabulary. The extraction process depends on the vocabulary and supported format. In the following example, you will extract knowledge from WordNet by using one of the available Java libraries.
- Solr plug-in: The feature can be plugged into any appropriate extendable Solr component. In this section, you will expand the synonym by using a custom token filter.
Before performing these tasks, you’ll learn about the basics of WordNet and the information it offers, and then get hands-on with synonymy expansion.
WordNet is a large lexical database of English. It groups nouns, verbs, adjectives, and adverbs into sets of cognitive synonyms called synsets, each expressing a distinct concept. Synsets are interlinked by means of conceptual, semantic, and lexical relationships. Its structure makes it a useful tool for computational linguistics and natural language processing. It contains 155,287 words, organized in 117,659 synsets, for a total of 206,941 word-sense pairs.
WordNet is released under a BSD-style license and is freely available for download from its web site, https://wordnet.princeton.edu/. You can also evaluate the online version of the thesaurus at http://wordnetweb.princeton.edu/perl/webwn.
The main relationships among words in WordNet is synonymy, as its synset groups words that denote the same concept and are interchangeable in many contexts. Apart from synonyms, the thesaurus also contains the following primary information (among others):
- Hypernymy/hyponymy: This refers to an IS-A relation between words. It links a generic synset such as accessory to a more specific one, like belt. For example, accessory is a hypernym of belt, and belt is a hyponym of accessory. These relationships maintain the hierarchy and are transitive.
- Meronymy: This is a whole-part relationship between words. For example, button is a meronym of shirt.
- Troponymy: This refers to verbs that express increasingly specific manners characterizing an event. For example, whisper is a troponym of talk.
- Gloss: This is a brief definition of a word. In most cases, it also contains one or more short sentences illustrating the use of the synset members.
WordNet requires the part of speech along with the words as a prerequisite.
A handful of Java libraries are available for accessing WordNet, each with its own pros and cons. You can refer to http://projects.csail.mit.edu/jwi/download.php?f=finlayson.2014.procgwc.7.x.pdf for a paper that compares the features and performance of the primary libraries.
Solr Plug-in for Synonym Expansion
This section provides steps for developing a mechanism for a simple expansion of terms. Below are the two steps needed to implement the feature
- Write a client to extract synonmys from wordnet.
- Write a Solr plugin to integrate the extracted synonyms for desired expansion. In this section, the enrichment is integrated to Solr using a custom token filter.
Synonym Expansion Using WordNet
To extract synonyms from WordNet, you have two prerequisites:
- Download the database from WordNet’s download page at https://wordnet.princeton.edu/wordnet/download/current-version/ and extract the dictionary from tar/zip to a folder.
- You will need a Java library to access the dictionary. The example uses the Java WordNet Library (JWNL). You can use any other library that suits your requirements.
This steps provided are in their simplest form; you may need optimizations to make the code production ready. Also, the program extracts only synonyms. You can extend it to extract other related information discussed previously. Another thing to note while extracting related terms from a generic thesaurus such as WordNet is that you may want to perform disambiguation to identify the appropriate synset for the term being expanded; words such as bank, for example, are polysemous and can mean river bank or banking institution, depending on the context. If you are using a domain-specific vocabulary, the disambiguation will not be that important. (Covering disambiguation is beyond the scope of this book.)
Here are the steps for synonym expansion using WordNet:
- The JWNL requires an XML-based properties file to be defined. The following is a sample properties file. The path of the extracted WordNet dictionary should be defined in the dictionary_path parameter in this file.
<?xml version="1.0" encoding="UTF-8"?>
<jwnl_properties language="en">
<version publisher="Princeton" number="3.0" language="en"/>
<dictionary class="net.didion.jwnl.dictionary.FileBackedDictionary">
<param name="dictionary_element_factory" value="net.didion.jwnl.princeton.data.PrincetonWN17FileDictionaryElementFactory"/>
<param name="file_manager"
value="net.didion.jwnl.dictionary.file_manager.FileManagerImpl">
<param name="file_type"
value="net.didion.jwnl.princeton.file.PrincetonRandomAccessDictionaryFile"/>
<param name="dictionary_path" value="/path/to/WordNet/dictionary"/>
</param>
</dictionary>
<resource class="PrincetonResource"/>
</jwnl_properties> - Create a new FileInputStream specifying the path of the JWNL properties file and initialize the JWNL by providing the FileInputStream. Create an instance of Dictionary.
JWNL.initialize(new FileInputStream(propFile));
Dictionary dictionary = Dictionary.getInstance(); - WordNet requires the part of speech to be specified for the tokens, and that value should be converted to a POS enum that is accepted by the dictionary. The part of speech can be tagged by using the OpenNLP part-of-speech tagger, as discussed in the previous example, or any other package you are familiar with.
POS pos = null;
switch (posStr) {
case "VB":
case "VBD":
case "VBG":
case "VBN":
case "VBP":
case "VBZ":
pos = POS.VERB;
break;
case "RB":
case "RBR":
case "RBS":
pos = POS.ADVERB;
break;
case "JJS":
case "JJR":
case "JJ":
pos = POS.ADJECTIVE;
break;
// case "NN":
// case "NNS":
// case "NNP":
// case "NNPS":
// pos = POS.NOUN;
// break;
} - Invoke the getIndexWord() method of the Dictionary instance by providing the word and its POS. The returned value is IndexWord.
IndexWord word = dictionary.getIndexWord(pos, term); - The getSenses() method of IndexWord returns an array of Synset, which can be traversed to get all the synonyms. The synset returned varies on the basis of the POS provided. The following block of code populates the synonyms Java set with all the extracted synonyms.
Set<String> synonyms = new HashSet<>();
Synset[] synsets = word.getSenses();
for (Synset synset : synsets) {
Word[] words = synset.getWords();
for (Word w : words) {
String synonym = w.getLemma().toString()
.replace("_", " ");
synonyms.add(synonym);
}
}
Custom Token Filter for Synonym Expansion
In the previous section, you learned to extract synonyms from WordNet. Now the extracted synonyms have to be added to the terms being indexed. In this section, you will learn to write a custom token filter that can be added to a field’s text-analysis chain to enrich the tokens with its synonyms.
Lucene defines classes for a token filter in the package org.apache.lucene.analysis.*. For writing your custom token filter, you will need to extend the following two Lucene classes:
- TokenFilterFactory: The factory creating the TokenFilter instance should extend this abstract class.
- TokenFilter: In Chapter 4, you learned that a token filter is a token stream whose input is another token stream. TokenFilter is an abstract class that provides access to all the tokens, either from a field of a document or from the query text. The custom implementation should subclass this TokenFilter abstract class and override the incrementToken() method.
The following are the steps to be followed for writing a custom token filter and plugging it into a field’s text-analysis chain:
- Write a custom implementation of TokenFilterFactory that creates the TokenFilter. Here are the steps:
- Extend the TokenFilterFactory abstract class. The ResourceLoaderAware interface is implemented by classes that optionally need to initialize or load a resource or file.
public class CVSynonymFilterFactory extends TokenFilterFactory implements ResourceLoaderAware {
} - Override the create() abstract method and return an instance of the custom TokenStream implementation, which you will create in the next step. You can optionally pass additional parameters to the implementing class. Here you pass the instantiated resources:
@Override
public TokenStream create(TokenStream input) {
return new CVSynonymFilter(input, dictionary, tagger, maxExpansion);
} - If you want to read parameters from the factory definition in schema.xml, you can read it from the map that is available as an input to the constructor. You have read the path of the JWNL properties file, the OpenNLP POS model, and the maximum number of desired expansions.
public CVSynonymFilterFactory(Map<String, String> args) {
super(args);
maxExpansion = getInt(args, "maxExpansion", 3);
propFile = require(args, "wordnetFile");
modelFile = require(args, "posModel");} - Initialize the required resources by overriding the inform() method provided by the ResourceLoaderAware interface.
@Override
public void inform(ResourceLoader loader) throws IOException {
// initialize for wordnet
try {
JWNL.initialize(new FileInputStream(propFile));
dictionary = Dictionary.getInstance();
} catch (JWNLException ex) {
logger.error(ex.getMessage());
ex.printStackTrace();
throw new IOException(ex.getMessage());
}
// initialize for part of speech tagging
tagger = new PartOfSpeechTagger();
tagger.setup(modelFile);
}
- Extend the TokenFilterFactory abstract class. The ResourceLoaderAware interface is implemented by classes that optionally need to initialize or load a resource or file.
- Create a custom class by extending the TokenFilter abstract class that performs the following tasks.
- Initialize the required attributes of the tokens. You have initialized the CharTermAttribute, PositionIncrementAttribute, PositionLengthAttribute, TypeAttribute, and OffsetAttribute that contain the term text, position increment information, information about the number of positions the token spans, the token type, and the start/end token information, respectively.
private final CharTermAttribute termAttr = addAttribute(CharTermAttribute.class);
private final PositionIncrementAttribute posIncrAttr
= addAttribute(PositionIncrementAttribute.class);
private final PositionLengthAttribute posLenAttr
= addAttribute(PositionLengthAttribute.class);
private final TypeAttribute typeAttr = addAttribute(TypeAttribute.class);
private final OffsetAttribute offsetAttr = addAttribute(OffsetAttribute.class); - Define the constructor and do the required initialization.
public CVSynonymFilter(TokenStream input,
Dictionary dictionary, PartOfSpeechTagger tagger, int maxExpansion) {
super(input); this.maxExpansion = maxExpansion;
this.tagger = tagger;
this.vocabulary = new WordnetVocabulary(dictionary);
if (null == tagger || null == vocabulary) { throw new IllegalArgumentException("fst must be non-null");
}
pendingOutput = new ArrayList<String>();
finished = false; startOffset = 0;
endOffset = 0;
posIncr = 1;
} - Override the incrementToken() method of TokenFilter. The method should play back any buffered output before running parsing and then do the required processing for each token in the token stream. The addOutputSynonyms() method extracts the synonym for each term provided. When the parsing is completed, the method should mandatorily return the Boolean value false.
@Override
public boolean incrementToken() throws IOException {
while (!finished) {
// play back any pending tokens synonyms
while (pendingTokens.size() > 0) {
String nextToken = pendingTokens.remove(0);
termAttr.copyBuffer(nextToken.toCharArray(), 0, nextToken.length());
offsetAttr.setOffset(startOffset, endOffset);
posIncAttr.setPositionIncrement(posIncr);
posIncr = 0;
return true;
}
// extract synonyms for each token
if (input.incrementToken()) {
String token = termAttr.toString();
startOffset = offsetAttr.startOffset();
endOffset = offsetAttr.endOffset();
addOutputSynonyms(token);
} else {
finished = true;
}
}
// should always return false
return false;}
private void addOutputSynonyms(String token) throws IOException { pendingTokens.add(token);
List<PartOfSpeech> posList = tagger.tag(token);
if (null == posList || posList.size() < 1) {
return;
}
Set<String> synonyms = vocabulary.getSynonyms(token, posList.get(0)
.getPos(), maxExpansion);
if (null == synonyms) {
return;
}
for (String syn : synonyms) {
pendingTokens.add(syn);
}}
@Override
public void reset() throws IOException {
super.reset();
finished = false;
pendingTokens.clear();
startOffset = 0;
endOffset = 0;
posIncr = 1;}The processing provided here tags the part of speech for each token instead of the full sentence, for simplicity. Also, the implementation is suitable for tokens and synonyms of a single word. If you are thinking of getting this feature to production, I suggest you refer to SynonymFilter.java in the org.apache.lucene.analysis.synonym package and extend it using the approach provided there.
- Initialize the required attributes of the tokens. You have initialized the CharTermAttribute, PositionIncrementAttribute, PositionLengthAttribute, TypeAttribute, and OffsetAttribute that contain the term text, position increment information, information about the number of positions the token spans, the token type, and the start/end token information, respectively.
- Build the program and add the Java binary JAR to the Solr classpath. Alternatively, place the JAR in the $SOLR_HOME/core/lib directory.
<lib dir="./lib" /> - Define the custom filter factory to the analysis chain of the desired fieldType in schema.xml.
<fieldType name="text_semantic" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="com.apress.solr.pa.chapter11.enrichment.CVSynonymFilterFactory" maxExpansion="3" wordnetFile="path-of-jwnl-properties.xml" posModel="path-to-en-pos-maxent.bin" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType> - Restart the instance, and you are good to query for semantic synonyms. If the token filter has been added to index-time analysis, the content should be reindexed. Verify the expansion in the Analysis tab in the Solr admin UI.
Summary
In this chapter, you learned about the semantic aspects of search engines. You saw the limitations of the keyword-based engines and learned ways in which semantic search enhances the user experience and findability of documents. Semantic search is an advanced and broad topic. Given the limited scope of this book, we focused on simple natural language processing techniques for identifying important words in a sentence and approaches for extracting metadata from unstructured text. You also learned about a basic semantic enrichment technique for discovering documents that were totally ignored earlier but could be of great interest to the user. To put it all together, this chapter provided sample source code for integrating these features in Solr.
Here you’ve come to the end of this book. I sincerely hope that its content is useful in your endeavor of developing a practical search engine and that it contribute to your knowledge of Apache Solr.