
![]()
Searching Data
All the previous chapters have been a stepping stone to this chapter. By now, you know the basics of Solr, configuring the core, defining a schema, and indexing documents. After your documents are indexed successfully, you are ready to search for results.
Solr offers a wide range of search capabilities such as querying, faceting, hit-highlighting, spell-checking, suggestions, and autocompletion. This chapter presents the search process, followed by an overview of the primary components. Then it gets into the details of querying for results. This chapter covers the following topics:
- Prerequisites
- Search process
- Search components
- Types of queries
- Query parsers
- JSON Request API
- Custom SearchComponent
- Frequently asked questions
In the previous chapter, you looked at tools for indexing documents. The same tools can be used for searching results. You can also execute your query from a browser or any GET tool such as Wget.
For analysis and development, the Solr admin console is the best place to run your query, as it provides a rich GUI and comes in handy even if you don’t remember the URL and request parameters. For a standard set of features, the console provides relevant text boxes; and relevant new boxes load automatically based on the feature you choose. If there is no text box for your request parameters, you can supply the key-value pair in the Raw Query Parameters text box. In this text box, each pair should be delimited by an ampersand (&), and the rules of standard HTTP request parameters apply.
The following is a sample user query: the request is sent to the /select endpoint of the hellosolr core with the q parameter, which contains the user query solr search engine:
$ curl http://localhost:8983/solr/hellosolr/select?q=solr search engine
For those who are new to Solr and who want to compare querying in Solr with querying in SQL databases, the mapping is as follows. Remember, the results returned by SQL and Solr can be different.
- SQL query:
select album,title,artist
from hellosolr
where album in ["solr","search","engine"]
order by album DESC limit 20,10; - Solr query:
$ curl http://localhost:8983/solr/hellosolr/select?q=solr search engine
&fl=album,title,artist&start=20&rows=10&sort=album desc
Prerequisites
Solr search capabilities and behavior depend a lot on the field properties, which are based on the field definitions in schema.xml. You can verify the field properties in schema.xml itself or in the Schema Browser in the Solr admin UI. To search fields and display matching documents, the following are some prerequisites:
- The searchable fields (the fields on which you query) should be indexed. This requires you to specify the indexed="true" attribute in the field definition in schema.xml. Here is a sample field definition with the indexed attribute marked in bold:
<field name="name" type="text_general" indexed="true" stored="true"/>
- The fields to be retrieved as part of a Solr response (the fields in the fl parameter) should be stored. This requires you to specify the stored="true" attribute in the field definition in schema.xml. Here is a sample field definition with the stored attribute marked in bold:
<field name="name" type="text_general" indexed="true" stored="true"/>
Chapter 4 provides more details on field definitions and how attributes affect search behavior.
Solr Search Process
This section presents the underlying querying process with respect to the /select endpoint, which is the most frequently used and the default endpoint in the Solr admin console. When you make a request to /select, it gets processed by SearchHandler, which is the primary request handler for querying documents. If you go through solrconfig.xml, you will find this handler defined and mapped to /select, as shown here:
<requestHandler name="/select" class="solr.SearchHandler">
<!-- default values for query parameters can be specified, these
will be overridden by parameters in the request -->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
</lst>
</requestHandler>
The SearchHandler executes a chain of SearchComponents to process the search request. QueryComponent, the SearchComponent responsible for addressing search queries, executes the configured QueryParser, which parses the raw query to translate it into a format that Solr understands. The parsed query is used by SolrIndexSearcher for matching indexed documents. The matched documents are formatted by ResponseWriter on the basis of the wt request parameter, and then the user finally gets the response. Figure 6-1 depicts how the search query flows through various components to retrieve the matching documents.

Figure 6-1. Search request flow
SearchHandler
SearchHandler is the controller responsible for handling search requests. The handler declares a chain of components and hands over the processing of requests to them. The components execute in the order they are registered in the chain. Each component in the chain represents a search feature such as querying or faceting.
Registered Components
The following are components that are by default registered in SearchHandler:
- QueryComponent
- FacetComponent
- MoreLikeThisComponent
- HighlightComponent
- StatsComponent
- DebugComponent
- ExpandComponent
Among these components, QueryComponent executes for all requests. All other components execute only if the request contains an appropriate parameter. For example, FacetComponent executes only when the facet=true parameter is provided in the search request.
SearchHandler enables you to add a component to the beginning or end of a chain, by registering it in the first-components or last-components section of the handler in solrconfig.xml:
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
..
</lst>
<arr name="first-components">
<str>terms</str>
</arr>
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
The left side of Figure 6-2 provides the final list of components registered to the SearchHandler after declaring the preceding first-components and last-components. These components will execute in the same order as they appear in the list.

Figure 6-2. Chain of SearchComponents
You can override the default components and execute only the components you desire by registering them in the components section. For example, if you want to execute only the QueryComponent, FacetComponent, MoreLikeThisComponent, and TermsComponent, you can register them in the components section as shown next. The chain of components will look like the table on the right side of Figure 6-2.
<arr name="components">
<str>query</str>
<str>facet</str>
<str>mlt</str>
<str>terms</str>
</arr>
You are not allowed to register first-components and last-components along with the components section, and such an attempt will throw SolrException:
SolrException: First/Last components only valid if you do not declare ’components’
The component name that you register to components, first-components, or last-components must be defined in solrconfig.xml for Solr to map it to the corresponding executable Java class. For example, if you register terms as a component in SearchHandler, solrconfig.xml should have the following definition:
<searchComponent name="terms" class="solr.TermsComponent"/>
![]() Note If using the first-components or last-components section, the DebugComponent is designed to always occur last. If this is not desired, you must explicitly declare all the components in the components section.
Note If using the first-components or last-components section, the DebugComponent is designed to always occur last. If this is not desired, you must explicitly declare all the components in the components section.
Declare Parameters
SearchHandler enables you to control the values of request parameters by specifying the parameters within various lists, based on desired manipulation of the user provided request parameters. It allows you to declare parameters in three ways.
defaults
The defaults value specifies the list of parameters and their default values. This value will be overridden if the user request contains the same parameter. In the following example, rows is declared in the default list; if the user request doesn’t contain this parameter, by default 10 documents will be returned in the response.
<lst name="defaults">
<int name="rows">10</int>
</lst>
appends
The appends value specifies the list of parameters that should be appended to all search requests instead of being overridden, as in the case of the defaults section. For the following example, if the user request is q=bob marley, the appends section will add fq=genre:reggae to the request. It even appends if the same parameter is specified in the defaults section.
<lst name="appends">
<int name="fq">genre:reggae</int>
</lst>
invariants
The invariants value specifies the list of parameters whose values are mandatorily applied and cannot be overridden by any other definition of the parameter, such as in the user query request or defaults section. This is a good place to configure features whose behavior you don’t want to let the user control. The following is an example definition of request parameters in invariants section.
<lst name="invariants">
<str name="fq">country:usa<str>
</lst>
SearchComponent
SearchComponent is an abstract Java class, and each implementation of this class represents a search feature. The implementing class should be declared in solrconfig.xml and then registered in the handler. Here is the configuration of TermsComponent, a component to access indexed terms, in solrconfig.xml:
<searchComponent name="terms" class="solr.TermsComponent"/>
<requestHandler name="/terms" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<bool name="terms">true</bool>
<bool name="distrib">false</bool>
</lst>
<arr name="components">
<str>terms</str>
</arr>
In this example, TermsComponent is registered in the components section, so no other component such as query or facet will be registered by default.
Table 6-1 provides key information about the primary components provided by Solr. In the table, the Name column signifies the default name of the components, and you can change it. The Default column lists the components that are by default configured in SearchHandler. To use a component that is not the default, you need to register it to an existing handler or configure a new handler and register it to that.
Table 6-1. Solr Primary Components

For each incoming request, a SearchComponent executes in two phases: prepare and process. The SearchHandler executes all the prepare methods in the order they appear in the chain and then executes all the process methods. The prepare method does the initialization for the request, and the process method does the actual processing. All the prepare methods are guaranteed to execute before any process method.
You will learn about some of these important components in detail in Chapters 7 and 9.
QueryParser
QueryParser parses the user query to convert it into a format understood by Solr. QueryComponent invokes an appropriate parser based on the defType request parameter. The same query can fetch different results for a different query parser, as each parser interprets the user query differently. Some of the query parsers supported by Solr are the standard, DisMax, and eDisMax query parsers. You will learn more about QueryParser later in this chapter.
By default, Solr returns responses to queries in XML format. To get a response in another supported format, the wt parameter can be specified in the request or configured in the handler. The other supported formats are JSON, CSV, XSLT, javabin, Velocity, Python, PHP, and Ruby.
A javabin response returns a Java object that can be consumed by Java clients. It’s the preferred response format for requests using the SolrJ client. Similarly, Python, PHP, and Ruby formats can be directly consumed by clients available for those languages. Velocity is another interesting response format that’s supported, which allows you to transform a response into web page by using the Apache Velocity templating engine.
Solr 5.3.0 supports a new smile format, a binary format that can be used by non-Java languages for efficient responses. Refer to http://wiki.fasterxml.com/SmileFormat to learn about this format.
Solr Query
You have already done some querying and know that you send a query request by using the q parameter. But there is more to it. In this section, you will look at query syntax, used to control the behavior of document matching and ranking. Then you will look at various parsers.
Your query sent with the q parameter is checked for syntax and parsed by the query parser. The query is tokenized during the analysis phase of the field, and the generated tokens are matched against the index and ranked on the basis of a scoring algorithm.
Figure 6-3 depicts how the user query is processed to search for relevant results. This figure provides the flow for search requests for retrieving relevant documents and doesn’t cover components such as SearchHandler. Refer to Figure 6-1 for the broader view of the flow, which applies to any search feature such as faceting and suggestions, and not specifically to retrieving documents.
The example in Figure 6-3 depicts the search flow for the user query kills the mockingbird. Chapter 4 used this example in covering field analysis. I intentionally used this partially matching query to give you an understanding of matching in real scenarios. Also, let’s assume that the handler is configured to use ExtendedDismaxQParser for query parsing, which allows you to perform a free text search similar to that in Google.
Here are the steps performed by Solr as depicted in Figure 6-3:
- The user-provided query is passed to the query parser. The purpose of the query parser is to parse the user query and convert it into a format that Lucene understands.
- The query parser sends the query to appropriate analyzers to break the input text into terms. In this example, the analyzer for the title and artist fields are invoked, which is based on the qf parameter provided in the request.
- The query parser returns the Query object, which is provided to SolrIndexSearcher for retrieving the matching documents. The Query object contains the parsed query, which you can see if you execute the search request in debug mode (by providing the additional request parameter debug="true").
- SolrIndexSearcher does lots of processing and invokes all the required low-level APIs such as for matching and ranking the documents. It also performs several other tasks such as caching.
- SolrIndexSearcher returns the TopDocs object, which is used to prepare the response to send it back to the application.
All the tasks specified in Figure 6-3 (and explained in the preceding steps) are coordinated by the QueryComponent class, which is a SearchComponent responsible for executing the search requests.
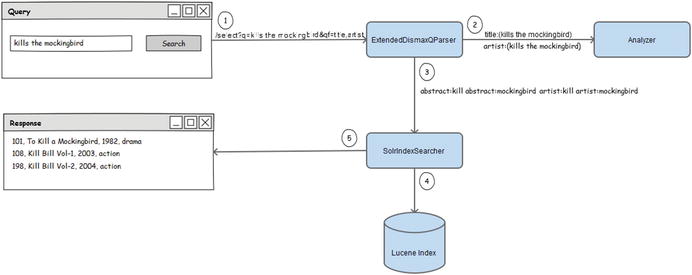
Figure 6-3. Search request processing
Default Query
In Solr, when we say query, by default we mean matching on the basis of terms. The terms are the smallest unit for matching. A term can be composed of a word, subsequent words, or a portion of a word. Suppose, you want to match parts of words, you can create smaller terms by using N-grams, which create tokens of N characters in the word. This section describes how you query.
Query a Default Field
When you specify only the query string along with the q parameter, you are querying the default field for results:
q=to kill a mockingbird
You can specify the default field by using the df parameter. In the following example, Solr will perform a query on the field album:
q=to kill a mockingbird&df=album
Query a Specified Field
The standard syntax for querying a specific field uses a field name followed by a colon and value, as shown here:
title:mockingbird
This will search for the term mockingbird in the title field.
Now, what if your query contains multiple tokens and you specify it as follows:
q=title:to kill a mockingbird&df=album
This will query the title field for to, and the album field for the tokens catch a mockingbird. If you want to search a field for multiple tokens, you need to surround it with parentheses:
q=title:(to kill a mockingbird)&df=album
This will query the title field for the tokens, and the album field will not be queried at all.
Match Tokens in Multiple Fields
The standard query parser offers granular control for querying documents. You can query different fields for different terms. The following query will search for the tokens buffalo soldier on the title field, and the tokens bob marley on the artist field:
q=title:(buffalo soldier) artist:(bob marley)
The default operator applied between the fields and tokens is OR. Solr supports a set of operators that allows you to apply Boolean logic to queries for specifying conditions for matching documents. The preceding query can also be expressed by explicitly specifying the operator:
q=title:(buffalo OR soldier) OR artist:(bob OR marley)
Hence, both of the preceding queries will retrieve all the documents that contain any of those terms.
Query Operators
The following are operators supported by query parsers:
- OR: Union is performed and a document will match if any of the clause is satisfied.
- AND: Association is performed and a document will match only if both the clauses are satisfied.
- NOT: Operator to exclude documents containing the clause.
- +/-: Operators to mandate the occurrence of terms. + ensures that documents containing the token must exist, and - ensures that documents containing the token must not exist.
Please note that AND/OR/NOT are case sensitive in the standard query parser. Hence the query bob and marley is not the same as bob AND marley. The first query will search for documents that contain any of the tokens bob, and, or marley. The second query will search for documents that contain both the tokens bob and marley.
Also, you can format your query in multiple ways. For example, q=(Bob AND marley) and q=(+bob +marley) form the same query.
Phrase Query
The preceding query matches all the documents in which the terms exist anywhere in the stream. If you want to find documents with consecutive terms, you need to perform a phrase search. A phrase search requires the query to be specified within double quotes. For example, q="bob marley" is a phrase query.
Proximity Query
A proximity query matches terms that appear in proximity to one another. You can view it as a liberal phrase query, which considers nearby terms. A proximity query requires the phrase query to be followed by the tilde (~) operator and a numeric distance for identifying the terms in proximity.
To help you understand all these concepts, consider the following example index that contains four documents and supports case insensitive matching.
Index
doc1: While Bob took the initial lead in race Marley finally won it.
doc2: Bob Marley was a legendary Jamaican reggae singer.
doc3: Jamaican singer Bob Marley has influenced many singers across the world.
doc4: Bob is a renowned rugby player.
Query
q=bob marley \ Default operator OR. All 4 documents match
q=(bob AND marley) \ AND operator. Both the terms must exist. First 3 documents match
q="bob marley" \ Phrase query. doc2 and doc3 matches
q="jamaican singer" \ Phrase query. Only doc3 matches
q="jamaican singer"~1 \ Proximity query. Both doc2 and doc3 match
q="singer jamaican"~1 \ Proximity query. Only doc3 matches
q="jamaican singer"~3 \ Proximity query. Both doc2 and doc3 match
Specifying the numeric value 1 in the proximity query q="jamaican singer"~1 matches doc2 and doc3 because moving one term in doc2’s Jamaican reggae singer sequence would form the phrase. But in the query q="singer jamaican"~1, only doc3 matches, as singer precedes jamaican and would require more movement to match doc2’s phrase. As you see in the last example, the numeric value 3 in the query will make it match both doc2 and doc3.
Fuzzy Query
Along with matching terms exactly, if you want similar terms to match, you can use a fuzzy query. A fuzzy query is based on the Damerau-Levenshtein Distance or Edit Distance algorithm, which identifies the minimum number of edits required to convert one token to another. To use it, the standard query parser expects a tilde (~) symbol after the term, optionally followed by a numeric value. The numeric value can be in the range of 0 to 2. The default value 2 matches the highest number of edits, and value 0 means no edit and is the same as a term query. The score of a fuzzy query is based on the number of edits: 0 edits means the highest score (because it’s least lenient), and 2 edits means the lowest score (because it’s most lenient). Here is the syntax for a fuzzy query:
Syntax
q=<field>:<term>~
q=<field>:<term>~N // N specifies the edit distance
Example
q=title:mockingbird~2
q=title:mockingbird~ // effect is same as above
q=title:mockingbird~1.5 // invalid
Earlier, Solr allowed specifying N as a float value in the range of 0.0 to 1.0, which was converted to an appropriate edit distance. In release 4.0, a more straightforward approach of specifying an integer value of 0, 1 or 2 was introduced, where indicates N insertions, deletions, or substitutions. Solr doesn’t allow a fractional edit distance and will respond with the following error if your query contains one:
"error": {
"msg": "org.apache.solr.search.SyntaxError: Fractional edit distances are not allowed!",
"code": 400
}
A fuzzy query works as a good solution for searching text that is prone to spelling mistakes (such as for tweets, SMS, or mobile applications), where stemming and phonetic techniques are not enough.
The tilde in a fuzzy query is not to be confused with that in a proximity query. In a proximity query, the tilde is applied after the quotation mark (for example, q="jamaican singer"~1). A fuzzy query has no quotation mark, and the tilde is applied after the token (for example, q=bob~1 marley~1).
Wildcard Query
The Solr standard query parser supports wildcard searches for single-term queries. You can specify the wildcard character ?, which matches exactly one character, or *, which matches zero or more characters. They cannot be applied to numeric or date fields. The following is a sample wildcard query:
q=title:(bob* OR mar?ey) OR album:(*bird)
A classic example of a wildcard query is *:*, which matches all terms in all fields and retrieves all the documents in the corpus. Note that you cannot use a wildcard on field names to search for a term or terms following a pattern (you can search a term or terms following a pattern over a complete index). The following queries are invalid and will throw an exception:
q=*:mockingbird // undefined field *
q=ti*:mocking* // SyntaxError: Cannot parse ’ti*:mocking*’
A wildcard query can be slow to execute, as it needs to iterate over all the terms matching the pattern. You should avoid queries starting with a wildcard, as they can be even slower. Wildcard queries return a constant score of 1.0 for all the matching documents.
Range Query
A range query supports matching field values between a lower and upper boundary. Range queries are widely used for numeric and date fields but can be used for text fields also. Range queries allow the boundary to be inclusive, exclusive, or a combination of both. They also support wildcards. Here are example range queries:
q=price:[1000 TO 5000] // 1000 <= price <= 5000
q=price:{1000 TO 5000} // 1000 < price > 5000
q=price:[1000 TO 5000} // 1000 <= price > 5000
q=price:[1000 TO *] // 1000 <= price
The query parser’s syntax requires square brackets, [], to denote inclusive values and curly braces, {}, to denote exclusive values. The connector TO should be specified in uppercase; otherwise, the parser will throw an exception. A range query provides a constant score of 1.0 to all the matching documents.
In a real-world scenario, you don’t always want documents to be ranked only on the basis of TF-IDF matching. Other factors can play a role, and you might want those factors to contribute to the overall document ranking. For example, a popularity count plays an important role in product ranking in an e-commerce website, a user rating plays a role in movie or product reviews, and spatial information plays a role in a local search.
The function query’s parser enables you to define a function query, which generates a score on the basis of a numeric value (either a constant or a value indexed in a field or a calculation from another function).
A function query gets its name from using a function to derive the value. The function queries can be applied while computing a score, returning a field value, or sorting documents. This topic is covered in depth in Chapter 7, where you will see how function queries can help in deducing a practical relevancy score.
Filter Query
A filter query helps you filter out documents that are not relevant to the request, leaving you with a subset of documents on which the main query executes. The filter clauses are only matched against the index and not scored and the documents that don’t match the filter conditions are rejected outright. The filter query should be specified in the request parameter fq. The filter clauses can be specified in the main query also, but the filter query proves advantageous in getting a fast response time. Solr maintains a separate cache for filter queries. When a new query comes with the same filter condition, a cache hit occurs that results in reduced query time. Parsers allow multiple filter queries, and a separate cache is created for each fq parameter. Hence, you can either have all filter clauses in the same fq parameter, or each filter clause in a different fq parameter. The choice of where to put the condition depends totally on your business case. This example specifies the same query clauses in different ways:
// no filter cache
q=singer(bob marley) title:(redemption song) language:english genre:rock
// one cache entry
q=singer(bob marley) title:(redemption song)&fq=language:english AND genre:rock
// two cache entry
q=singer(bob marley) title:(redemption song)&fq=language:english&fq=genre:rock
The fq parameters are associative. If multiple fq parameters are specified, the query parser will select the subset of documents that matches all the fq queries. If you want the clauses to be OR’ed, the filter query should be part of a single fq parameter.
For example, in a legal search engine, lawyers generally search for cases from a court of law in a specific country. In this scenario, the country name makes a good filter query, as shown here:
q=labour laws&fq=country:usa
Similarly, in a spatial search such as a local deals search, the city and deal categories can use the fq parameter, as follows:
q=product:restaurant&fq=city:california&fq=category:travel
But if most of the queries in the city Las Vegas are for travel deals, the request can be formed as follows:
q=product:hotel&fq=city:"las vegas" AND category:travel
Query Boosting
Not all terms are equally important in a query, so Solr enables you to boost query terms to specify their significance. A query boost is a factor that Solr considers when computing a score; a higher boost value returns a higher score. The factor by which you boost the term depends on your needs, the relative importance of terms, and the degree of desired contribution by the term. The best way to come up with an optimal value is through experimenting.
A boost is applied by specifying a carat (^) operator after the token, followed by the boost factor. The DisMax and eDisMax query parsers allow you to boost the query fields, resulting in boosting all the terms searched on that field. By default, all the fields and tokens get a boost of 1.0.
The following is an example query with a boost applied. This query specifies that redemption and song are the most significant terms, with a boost of 2.0, followed by the terms bob and marley, with a boost of 1.4; all other terms get the default boost of 1.0.
q=singer(bob marley)^1.4 title:(redemption song)^2.0 language:english genre:rock
You will learn how query boosting contributes to document scores in Chapter 8.
Solr provides a set of query parameters. Some are generic and work for all kind of search requests, and others are specific to the query parser used for processing the request.
This is a comprehensive reference section for the query parameters that are applicable to all search requests. The request parameters that are specific to query parsers are covered in the “Query Parsers” section in this chapter.
q
This parameter defines the main query string for retrieving relevant documents. This is a mandatory parameter, and if not specified, no other parameter will have any effect.
Filter queries are specified with this parameter. A request can have multiple fq parameters, each of which is associative. You learned about this parameter previously, in the “Filter Query” section.
Specifies the number of documents to be retrieved in the result set. The default value is 10. Don’t specify a very high value, as that can be inefficient. A better alternative is to paginate and fetch documents in chunks. You can specify rows=0, when you are interested only in other search features such as facets or suggestions.
Specifies the offset from which the documents will be returned. The default value is 0 (which returns results from the first matching document). You can use start and rows together to get paginated search results.
Specifies the query parser to be used for parsing the query. Each parser differs in behavior and supports specialized parameters.
Specifies the comma-separated list of fields on which the result should be sorted. The field name should be followed by the asc or desc keyword to sort the field in ascending or descending order, respectively. The fields to be sorted upon should be single valued (multiValued=false) and should generate only one token. Non-numeric fields are sorted lexicographically. To sort on score, you can specify score as the field name along with the asc/desc keyword. By default, the results are sorted on score. Here is an example:
sort=score desc,popularity desc
Specifies the comma-separated list of fields to be displayed in the response. If any field in the list doesn’t exist or is not stored, it will be ignored. To display a score in the result, you can specify the score as the field name. For example, fl=score,* will return the score of the documents along with all the stored fields.
Specifies the format in which the response should be returned, such as JSON, XML, or CSV. The default response format is XML. The response is formatted by the response writer, which was covered at the beginning of this chapter.
This Boolean parameter works wonders to analyze how the query is parsed and how a document got its score. Debug operations are costly and should not be enabled on live production queries. This parameter supports only XML and JSON response format currently.
explainOther
explainOther is quite useful for analyzing documents that are not part of a debug explanation. debugQuery explains the score of documents that are part of the result set (if you specify rows=10, debugQuery will add an explanation for only those 10 documents). If you want an explanation for additional documents, you can specify a Lucene query in the explainOther parameter for identifying those additional documents. Remember, the explainOther query will select the additional document to explain, but the explanation will be with respect to the main query.
Specifies the maximum time in milliseconds that a query is allowed to execute. If this threshold is reached, Solr will return a partial result.
A Solr response by default contains responseHeader, which provides information such as response status, query execution time, and request parameters. If you don’t want this information in response, you can specify omitHeader=true.
By default, caching is enabled. You can disable it by specifying cache=false.
Query Parsers
You have already learned a bit about query parsers and know that the defType parameter specifies the query parser name. In this section, you will look at the primary query parsers: standard, DisMax, and eDisMax.
Standard Query Parser
The standard query parser is the default parser in Solr. You don’t need to specify the defType parameter for this. The standard query parser is suitable for a structured query and is a wonderful parser for forming complex queries, but it has some limitations. It expects you to tightly adhere to syntax, and if it encounters any unexpected characters, it will throw an exception. Special characters and symbols should be properly escaped, or Solr will throw a syntax error:
<lst name="error">
<str name="msg">org.apache.solr.search.SyntaxError:
Cannot parse ’article:mock:bird’: Encountered " ":" ":
“” at line 1, column 12.
Was expecting one of:
<EOF>
<AND> ...
<OR> ...
<NOT> ...
"+" ...
"-" ...
<PREFIXTERM> ...
<LPARAMS> ...
...
<NUMBER> ...
</str>
<int name="code">400</int>
The standard query parser is the default Solr parser, but it provides little flexibility as it is structure-based and accepts Boolean queries such as title:(buffalo OR soldier) OR singer:(bob OR marley) that must be syntactically correct. If the syntax is incorrect, or the user query contains a symbol that has special meaning in the syntax, Solr will throw an exception.
Solr provides the DisMax parser to handle human-like natural queries and phrases. It allows organic searches across fields, such that it is not limited by values in a particular field. It also allows you to add weight to fields, which is a more practical way of querying any search domain. For example, for a typical e-commerce website, a brand would have a high associated search relevance.
Using the DisMax Query Parser
The DisMax parser makes a better candidate for a search engine like Google, and the standard parser is preferred for advanced searches, where the user explicitly specifies what to search on which field. For example, in a legal search, advocates might prefer specifying a litigation detail in one box, a petitioner detail in another, and the court name in yet another box.
Because DisMax is meant for natural user queries, it makes its best attempt to gracefully handle error scenarios and hardly throws any query parse exceptions.
Another difference is that the standard parser sums up the scores of all the subqueries, whereas DisMax considers the maximum of the scores returned by all the subqueries—hence the name DisMax, which means disjunction maximum. If you want DisMax scoring to behave like the standard parser, you can apply a tiebreaker, which can make it score like the standard parser.
If you are building your first search engine, DisMax is an easier alternative to start with than standard.
Here is an example DisMax query:
$ curl http://localhost:8983/solr/hellosolr/select?
q=to kill a mockingbird&qf=movie^2 artist^1.2 description
&rows=10&fl=score,*&defType=dismax
Query Parameters
Along with the common query parameters previously mentioned, DisMax supports additional parameters that are specific to it. These parameters can be used to control the matching and ranking of documents, without making any changes to the main query. The Query tab in the Solr admin console provides a check box for the DisMax parser; after you click it, parameters specific to the parser will automatically become visible. Here are additional parameters supported by DisMax:
q
Specifies the user query or phrase. The values provided to this parameter are natural queries and are not structured as in the standard query.
This parameter specifies the list of fields on which the query provided in the q parameter should be applied. All the query terms are matched in all the specified fields, and you cannot selectively specify different terms to match different fields. If a query contains a string but your qf parameter specifies an int or date field, don’t worry; that will be handled gracefully, and only the integers in the query will be matched to an int field.
All the fields in the qf parameter should be separated by whitespace and can optionally have boosts, as shown next. If your list specifies a field that is not defined in schema.xml, it will be ignored.
qf=album^2 title^2 description
DisMax has a fallback mechanism for a query. If the q parameter is missing, it will parse the query specified in the q.alt parameter by using the standard query parser.
In the standard query parser, you explicitly apply the Boolean operator on terms and subqueries. The mm parameter, which means minimum should match, provides a more practical approach to the problem by allowing you to control the number of clauses that should match. Its value can be either an integer, a percentage, or a complex expression. Here are the details:
- Integer: This specifies the minimum number of clauses that must match. You can also specify a negative value, which means the maximum number of nonmatching optional clauses that are acceptable. For example, if a query contains four clauses, mm=1 means that at least one clause must match, and mm=-1 means that at least three clauses must match. A higher value makes the search stricter, and a lower value makes it more lenient.
- Percentage: An integer applies hard values and is fixed. A percentage specifies the minimum number of clauses to match with respect to the total number of optional clauses. For example, if a query contains four clauses, mm=25% means that at least one clause should match, and mm=-25% means that at least three clauses (75%) should match. Specifying mm=100% means that all the clauses must match, and the behavior will be the same as applying the AND operator on all query clauses. Specifying mm=0% means that there is no minimum expectation, and the behavior will be the same as applying the OR operator on all query clauses. If the number computed from the percentage contains a decimal digit, it gets rounded to the nearest lower integer.
- Expression: You can apply one or more conditional expressions separated by a space in the format n<integer|percent. An expression specifies that if the number of optional clauses is more than n, the specified condition applies; otherwise, all the clauses are mandatory. If multiple conditions are specified, each one is valid only for the value of n greater than the one specified in the condition before it. For example, the expression 2<25% 4<50% specifies that if the query has up to two optional clauses, they all are mandatory; if it has three or four optional clauses, at least 25% of them should match; and if it has more than four clauses, at least 50% should match.
A query phrase slop allows you to control the degree of proximity in a phrase search. In a standard query parser, you perform a proximity search by specifying a tilde (~) followed by a proximity factor. The DisMax parser provides an additional parameter, qs, to control the proximity factor and keep the main query simple. The following is an example that applies the same proximity when using standard and DisMax parsers:
q="bob marley"~3&defType=standard
q="bob marley"&qs=3&defType=dismax
The DisMax parser enables you to boost matched documents. You specify a list of fields along with the boost in the pf parameter, and the matching phrases in those fields are boosted accordingly. It’s important to remember that this parameter plays a role in ranking the matched phrase higher and doesn’t affect the number of documents matched. The pf parameter can reorder the result, but the total result count will always remain unchanged.
pf=album^2 title^2
This parameter allows you to apply a proximity factor to the phrase field and has no meaning without the pf parameter. As pf contributes only to matched document ranking and plays no role in deciding the match count, the same rule applies to ps.
The standard parser sums up the scores of subqueries, but DisMax takes the maximum of the scores of subqueries—and hence the name (dis)max. Once you apply the tie, DisMax starts summing up the scores, and the computation behaves similarly to the standard parser. A float value in the range of 0.0 to 1.0 is allowed. tie=0.0 will take the maximum score among the subqueries, and tie=1.0 will sum up the score of all the subqueries. DisMax uses the following algorithm to compute the score:
score = max(subquery1,..,subqueryn) + (tie * sum(other subqueries)
If two documents get the same score, you can use this parameter to let subqueries influence the final score and break the tie between them.
The boost query parameter enables you to add a query clause to boost the score of matching documents. Multiple bq parameters can be provided, and the score of clauses in each parameter gets added to the score of the main query. For example, you can use bq to boost titles with a high rating:
q=bob marley&bq=rating:[8 TO *]
bf
Boost functions can be used to boost documents by applying function queries. The boost function is provided in the bf request parameter. As with bq, you can specify this parameter multiple times, and the score is additive. The following is an example of a boost function that uses the sqrt() function query to compute the boosting factor by taking the square root of the rating. Chapter 7 covers the function query in more detail.
q=bob marley&bf=sqrt(rating)
Sample DisMax Query
Here is an example for an almost full-blown DisMax query:
$ curl http://localhost:8983/solr/hellosolr/select?
q=to kill a mockingbird&qf=album^2 title^2 description
&rows=10&fl=album,title&defType=dismax&qs=3&mm-25%
&pf=album^3 title^3&ps=2&tie=0.3
&bf=sqrt(rating)&bq=rating:[8 TO *]
As its name indicates, the Extended DisMax query parser is an extension of the DisMax query parser. It supports the features provided by DisMax, adds smartness to some of them, and provides additional features. You can enable this query parser by setting defType=edismax.
The eDisMax query parser supports Lucene query parser syntax, which DisMax doesn’t support. DisMax doesn’t allow you to search specific fields for specific tokens. You specify the sets of fields to search in the qf parameter, and your query gets applied to all those fields. However, because eDisMax supports Lucene queries, you can execute a specific token on a specific field also. Here is an example query:
Query
$ curl http://localhost:8983/solr/hellosolr/select?
q=buffalo soldier artist:(bob marley)&debugQuery=true
&defType=dismax&qf=album title
DebugQuery
<str name="parsedquery">
(+(DisjunctionMaxQuery((title:buffalo | album:buffalo))
DisjunctionMaxQuery((title:soldier | album:soldier))
DisjunctionMaxQuery(((title:artist title:bob) | (album:artist album:bob)))
DisjunctionMaxQuery((title:marley | album:marley))) ())/no_coord
</str>
In this debug query, you can see that DisMax considers the artist field as a query token and searches for it on all the fields specified in the qf parameter. We expect that the parser will search for bob marley in the field artist. Because eDisMax supports Lucene queries, it will meet your expectation.
Query
$ curl http://localhost:8983/solr/hellosolr/select?
q=buffalo soldier artist:(bob and marley)
&debugQuery=true&defType=edismax&qf=album title
DebugQuery
<str name="parsedquery">
(+(DisjunctionMaxQuery((title:buffalo | album:buffalo)) DisjunctionMaxQuery((title:soldier | album:soldier)) (+artist:bob +artist:marley)))/no_coord
</str>
Also, you can notice that eDisMax parsed and as the Boolean operator and mandated the tokens bob and marley by applying the + operator before them. eDisMax supports Boolean operators such as AND, OR, NOT, + and -. The Lucene query parser doesn’t consider lowercase tokens and/or as Boolean operators, but eDisMax treats them as valid Boolean operators (equivalent to AND/OR).
The request parameters of DisMax are supported by eDisMax. The following are the additional request parameters that eDisMax provides:
In the preceding example, you saw that eDisMax considers the lowercase and as the Boolean operator AND. If you want to disable this feature and let eDisMax treat and and or as any other token, you can set lowercaseOperators=false. By default, this Boolean parameter is set to true.
boost
The functionality of the boost parameter is similar to that of bf, but its score is multiplied to the score of the main query, whereas the bf score is added. eDisMax allows multiple boost parameters and uses BoostedQuery to multiply the score of each of them to the score of the main query.
Query
boost=log(popularity)&boost=sum(popularity)
DebugQuery
<str name="parsedquery">
BoostedQuery(boost...,
product(log(int(popularity)),sum(int(popularity)))))
</str>
The pf parameter boosts the score of documents that match the exact phrase. pf2 and pf3 create shingles of size 2 and 3, respectively, and matches against the documents to boost them. For the query top songs of bob marley, the phrases created will be as follows:
pf=[’top songs of bob marley’]
pf2=[’top songs’,’songs of’,’of bob’,’bob marley’]
pf3=[’top songs of’,’songs of bob’,’of bob marley’]
As with pf, multiple pf2/pf3 parameters can be specified in the request.
As with the pf parameter, slop can be applied on pf2 and pf3 by using ps2 and ps3, respectively. If this parameter is not specified, the value of the ps parameter becomes its default value.
eDisMax allows you to bypass the StopFilterFactory configured in the analysis chain of fields by setting the Boolean parameter stopwords=false.
This parameter specifies the user fields (which fields the user is allowed to query). The value can be a specific field name or a wildcard pattern for the fields. Any alias name can also be used as a field name.
Just as SQL databases allow you to provide an alias name to the columns, eDisMax supports an alias name for the fields. The alias name can map to a single field or a set of fields defined in schema.xml. The parameter can be configured as follows:
f.song.qf=title
This also proves helpful when you want to club the fields related to a concept together, as shown in this example:
f.artist.qf=singer,musician,actor,actress
Throughout this chapter, you have used request parameters for querying results, but this approach has the following limitations:
- It is unstructured, so specifying parameters that apply to a specific field is inconvenient. You will see field-level parameters in features such as faceting and terms component, where you generally want to search different fields differently. Chapter 7 presents examples of these queries.
- Creating requests with a large number of parameters is inconvenient, and you may end up adding the same parameter multiple times because of a lack of readability.
- It is untyped and treats everything as a string.
- A wrong parameter name gets silently ignored, and there is no way to validate it.
To address all these limitations of query parameters, Solr 5.1 introduced the JSON Request API. This API allows you to specify requests in JSON format, which can be sent in either the request body or as part of the json request parameter. Solr also allows you to combine the JSON and request parameters in a query such that some of the parameters can be in the JSON body while others can be in the request parameters separated by an ampersand (&).
Table 6-2 provides a sample query for each JSON request provision supported by the API. The first request in the table is based on the standard request parameter to help you compare both types of requests. Also, the examples use the /query endpoint instead of /select as it is by default configured in solrconfig.xml to return a JSON response. Note that all the requests in the table return the same JSON response.
Table 6-2. Approaches for Search Queries
Request Type | Sample Query | Description |
|---|---|---|
Request parameter | $ curl http://localhost:8983/solr/hellosolr/query?q=bobmarley&rows=20 | Standard approach that we have been using throughout this book. |
GET request body | $ curl http://localhost:8983/solr/hellosolr/query -d ’{ "query":"bob marley", "limit":20 }’ | Query in JSON format is specified in the request body by using the GET method. If you are using any other client, you may need to specify Content-Type: application/json in the request. |
POST request body | $ curl -H "Content-Type: application/json" -X POST http://localhost:8983/solr/hellosolr/query -d ’{ "query":"bob marley", "limit":20 }’ | Query in JSON format is specified in the request body by using the POST method. This approach is useful if you are using a REST client such as Postman. |
JSON in request parameter | $ curl http://localhost:8983/solr/hellosolr/query?json=’{ "query":"bob marley", "limit":20 }’ | Query is specified in the json request parameter. |
Combination of both | $ curl http://localhost:8983/solr/hellosolr/query?json=’{ "query":"bob marley" }’&rows=20 | Query uses a combination of both JSON API and request parameter. |
Request parameter in JSON | $ curl http://localhost:8983/solr/hellosolr/query -d ’{ params: { q:"bob marley", rows:20 } }’ | Query with JSON body that specifies standard request parameter within the params block. The params block allows you to specify any standard request parameter in the JSON body. |
Parameter substitution | $ curl http://localhost:8983/solr/hellosolr/query?QUERY=bob marley&RESULTCOUNT=20 -d ’{ "query":"${QUERY}", "limit":${RESULTCOUNT} }’ | JSON body uses parameter substitution for populating the parameter values. JSON request body is fully compatible with parameter substitution, which you will learn about in Chapter 7. |
The JSON request API has yet to mature to incorporate all the request parameters. As of now, it supports only a subset of parameters supported by Solr. Also, the names of the JSON body parameters are different from the standard request parameters. For example, if you specify the defType parameter in the JSON body, which is a valid request parameter, Solr will report the following exception:
error":{
"msg":"Unknown top-level key in JSON request : defType",
"code":400
}
Table 6-3 lists JSON body parameters and the standard request parameters that they correspond to. Solr throws the same exception mentioned previously if you provide an invalid JSON parameter.
Table 6-3. JSON API Parameter Name Mapping
Standard Request Parameter | JSON API Parameter |
|---|---|
q | Query |
fq | Filter |
fl | Fields |
start | Offset |
rows | Limit |
sort | Sort |
In this chapter, you learned about search handlers, search components, and query parsers, and their implementations provided by Solr. These implementations work great for standard use cases, and Solr tries to make them highly configurable to accommodate a wide variety of requirements. However, you may still have a case that is specific to your needs, or you may be developing something that would make a good contribution to Solr. In these scenarios, you may want to write a custom component and hook it to Solr.
Solr provides an extensive option for hooking your plug-in, an example of which you have already seen in Chapter 5. You can find the list of pluggable classes in Solr in the official documentation at https://cwiki.apache.org/confluence/display/solr/Solr+Plugins. The integration process is fairly straightforward and doesn’t require you to modify the Solr source code. You can consider your plug-in as similar to those provided by the Solr contrib module.
Following are the high-level steps for adding any custom plug-in to Solr:
- Create a Java project and define your class, which extends an API provided by Solr based on where you want to hook your implementation in Solr. You need to add the required Solr dependencies to your project to access the API classes.
- Add your custom functionality by overriding the API methods. This requires you to understand the input parameters of the API, to read the required values from them, and to add your functionality for processing. You may also need to consider other factors such as how your custom functionality would affect the other components downstream in the chain, if applicable.
- Package your project as a JAR file and add it to lib directory, which is available in Solr’s classpath.
- Define the feature in either solrconfig.xml, schema.xml, or another file where it fits.
- Wire your named definition to the appropriate component. As Solr assembles the customizable components through XML configuration to build a feature, you either need to replace the existing name with what you defined in step 4 or add your name to the chain, if applicable.
In the next section, you will learn to hook a custom SearchComponent in Solr with an example.
Assume that you want to perform a spell-check on the basis of common spelling errors uploaded in a file. The Solr-provided SpellCheckComponent, described in Table 6-1, will not be of help in that case. In such a scenario, you may want to write your own implementation for a spell-checker. You can hook this custom functionality to Solr by extending the SearchComponent API and plugging it into Solr.
The following are the steps to be followed for plugging in a custom SearchComponent.
Extend SearchComponent
Create a Java class and extend the SearchComponent abstract class. You need to add the required dependencies to your project.
public class CustomSearchComponent extends SearchComponent {
}
You can add solr-core-5.3.1 from the $SOLR_DIST/dist directory to your project classpath or Maven dependency, whichever is applicable, as follows:
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>5.3.1</version>
</dependency>
Override the Abstract Methods
Override the prepare(), process(), and getDescription() methods. In the getDescription() method, provide a short description of the component. The prepare() methods execute before the process() method of any of the registered components. If the purpose of your component is to modify the processing of any other component, the prepare() method is a good place to modify the request parameter that is used by the process method of the component whose behavior you want to change. The process() method is the place where you can write all the custom logic.
@Override
public String getDescription() {
return null;
}
@Override
public void prepare(ResponseBuilder rb) throws IOException {
}
@Override
public void process(ResponseBuilder rb) throws IOException {
}
Get the Request and Response Objects
Get the request and response objects from ResponseBuilder to fetch the information required for custom processing:
@Override
public void process(ResponseBuilder rb) throws IOException {
SolrQueryRequest req = rb.req;
SolrQueryResponse rsp = rb.rsp;
// your custom logic goes here
}
Add the JAR to the Library
Add the executable JAR to the Solr library.
To execute the custom component, it should be defined in solrconfig.xml and registered to the desired handler.
Sample Component
The following is a simple SearchComponent implementation that mandates a JSON response. If the wt parameter is not specified in the request, it sets it to JSON. If it’s specified as something else, it resets it to JSON and responds in JSON along with the appropriate message. The message is returned in a separate section. If you are implementing a new feature, you can similarly return the result in a separate section.
The following example also modifies the request parameter. The SolrParams retrieved from the request object is read-only, so you need to create an instance of ModifiableSolrParams, copy all the existing parameters, and do all the modifications and set it in the request, replacing the existing value.
All the logic in the following example is written in the prepare() method, as you want it to execute before the actual processing of the request is done.
Java Source Code
package com.apress.solr.pa.chapter06.component;
import java.io.IOException;
import org.apache.solr.common.params.CommonParams;
import org.apache.solr.common.params.ModifiableSolrParams;
import org.apache.solr.common.params.SolrParams;
import org.apache.solr.common.util.NamedList;
import org.apache.solr.common.util.SimpleOrderedMap;
import org.apache.solr.handler.component.ResponseBuilder;
import org.apache.solr.handler.component.SearchComponent;
import org.apache.solr.request.SolrQueryRequest;
import org.apache.solr.response.SolrQueryResponse;
public class JsonMandatorComponent extends SearchComponent {
public static final String COMPONENT_NAME = "jsonmandator";
@Override
public String getDescription() {
return "jsonmandator: mandates JSON response.";
}
@Override
public void prepare(ResponseBuilder rb) throws IOException {
SolrQueryRequest req = rb.req;
SolrQueryResponse rsp = rb.rsp;
SolrParams params = req.getParams();
ModifiableSolrParams mParams
= new ModifiableSolrParams(params);
String wt = mParams.get(CommonParams.WT);
if(null != wt && !"json".equals(wt)) {
NamedList nl = new SimpleOrderedMap<>();
nl.add("error",
"Only JSON response supported. Ignoring wt parameter!");
rsp.add(COMPONENT_NAME, nl);
}
mParams.set(CommonParams.WT, "json");
req.setParams(mParams);
}
@Override
public void process(ResponseBuilder rb) throws IOException {
}
}
solrconfig.xml
Following are the changes to be done in solrconfig.xml:
<lib dir="directory" regex="solr-practical-approach-1.0.0.jar" />
<searchComponent name="jsonmandator"
class="com.apress.solr.pa.chapter06.component.JsonMandatorComponent" />
<requestHandler name="/select" class="solr.SearchHandler">
<!-- default values for query parameters can be specified, these
will be overridden by parameters in the request
-->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
</lst>
<arr name="first-components">
<str>jsonmandator</str>
</arr>
</requestHandler>
Query
Create a query by specifying the response format as XML, which is not supported for search requests, in the wt parameter:
$ curl http://localhost:8983/solr/hellosolr/select?q=product:shirt&wt=xml&indent=true
The custom components force a JSON response and add a section with an appropriate error message. Figure 6-4 shows the response returned by Solr for the preceding query.

Figure 6-4. Search request manipulation by the custom SearchComponent
Frequently Asked Questions
This section presents some of the common questions asked while searching results.
I have used KeywordTokenizerFactory in fieldType definition but why is my query string getting tokenized on whitespace?
The unexpected tokenization can be due to the query parser, and there should be no problem in query-time field analysis. The query parser tokenizes on whitespace to identify the query clauses and operators, so by the time the query reaches the filter, it’s already tokenized. You can handle this problem by escaping the whitespaces in the query string. The following is a sample escaped query which exhibits your expected behavior.
q=bob marley&debugQuery=true&defType=edismax&qf=album title
How can I find all the documents that contain no value?
You can find all the documents that contain a blank or null value for a field by using a negation operator. Here is an example:
-field:* or -field:[’’ TO *]
How can I apply negative boost on terms?
The default boost in Solr is 1.0, and any value higher than this is a positive boost. Solr doesn’t support negative boosting, and you cannot specify a boost such as music:jazz^-5.0.
If you apply a low boost on the terms such as music:rock^100 music:metal^100 music:jazz^0.02, the documents containing jazz will still rank above the documents containing only rock and metal, because you are still giving some boost to jazz. The solution is to give a very high boost to documents that don’t contain jazz. The query should be boosted as follows:
q=music:rock^100 music:metal^100 (*:* -music:jazz)^1000
Which are the special characters in query string. How should they be handled?
Special characters are the characters that have special meaning in Solr. For example, a plus sign (+) before a clause signifies that it’s mandatory. What if your query also contains a + symbol? The query parser cannot make out that it’s a valid term. To make the parser understand that the symbol is a valid term and not a special instruction, it should be escaped. You can escape such characters by using a slash () before them. Following is the current list of valid special characters:
+ - && || ! ( ) { } [ ] ^ " ~ * ? : /
If you are using a Lucene query parser, you need to escape these special characters before making a request. Otherwise, Solr might throw an exception. But the DisMax query parser handles these exceptions gracefully, and you need to escape only if your query contains quotes or +/- operators. Here is an example that escapes a special character:
a + b
Summary
This chapter covered the most important aspect of Solr: searching for results. You saw how Solr processes a query, the components involved, and the request flow. You learned about the various types of queries and their significance, as well as query parsers and their request parameters. You saw how the DisMax and eDisMax parsers can be used to build a Google-like search engine, and how the Lucene parser can be used to get finer control. You learned to extend the SearchComponent to customize the search process. As in previous chapters, you learned about some practical problems and their solutions.
The next chapter covers the search process in more detail and presents other important aspects of searching.